 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Robustness with Image Filtering
Dec 21, 2021

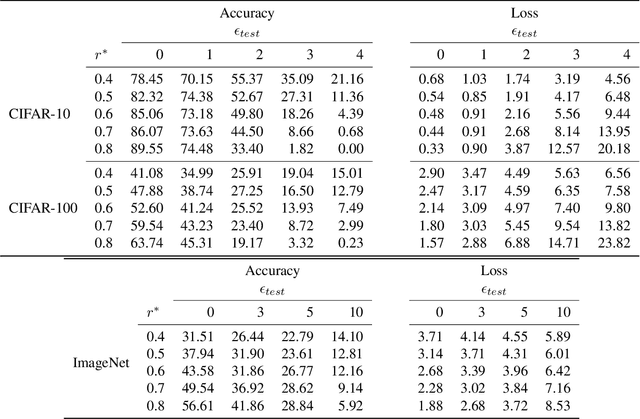
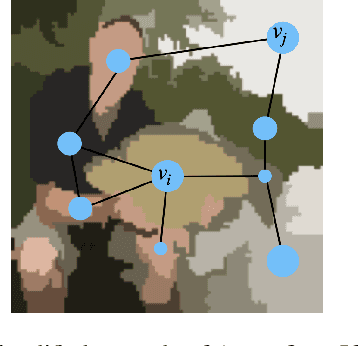
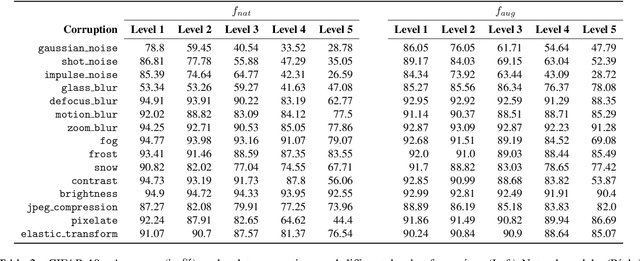
Adversarial robustness is one of the most challenging problems in Deep Learning and Computer Vision research. All the state-of-the-art techniques require a time-consuming procedure that creates cleverly perturbed images. Due to its cost, many solutions have been proposed to avoid Adversarial Training. However, all these attempts proved ineffective as the attacker manages to exploit spurious correlations among pixels to trigger brittle features implicitly learned by the model. This paper first introduces a new image filtering scheme called Image-Graph Extractor (IGE) that extracts the fundamental nodes of an image and their connections through a graph structure. By leveraging the IGE representation, we build a new defense method, Filtering As a Defense, that does not allow the attacker to entangle pixels to create malicious patterns. Moreover, we show that data augmentation with filtered images effectively improves the model's robustness to data corruption. We validate our techniques on CIFAR-10, CIFAR-100, and ImageNet.
DEFER: Distributed Edge Inference for Deep Neural Networks
Jan 18, 2022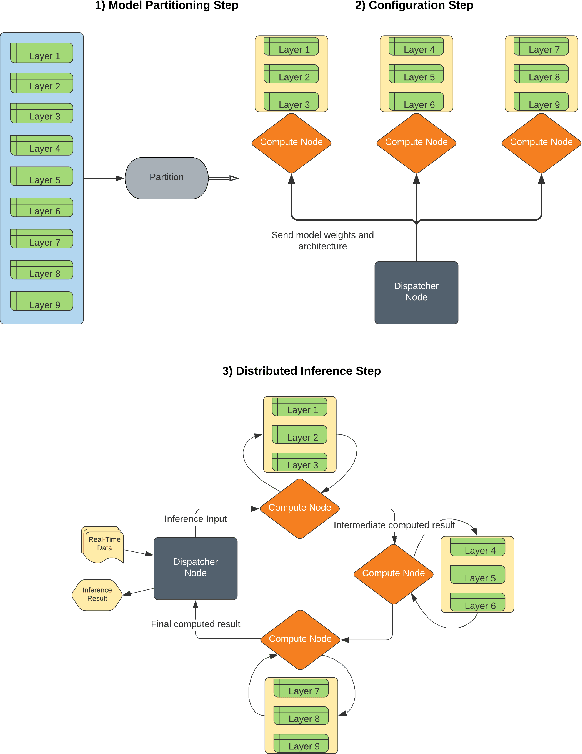
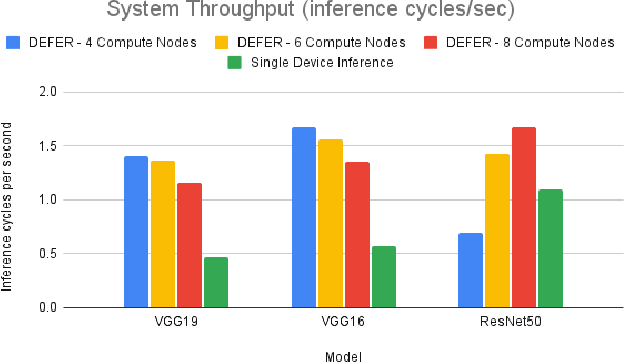
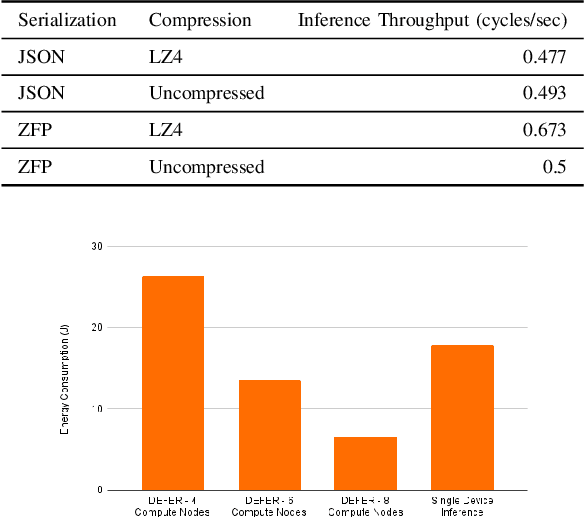
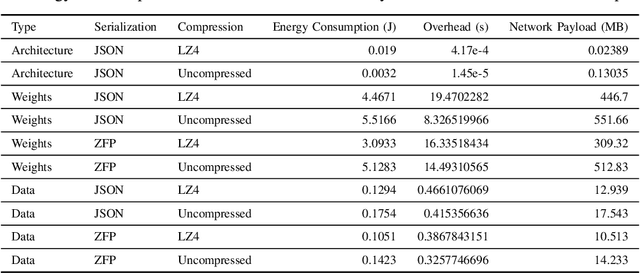
Modern machine learning tools such as deep neural networks (DNNs) are playing a revolutionary role in many fields such as natural language processing, computer vision, and the internet of things. Once they are trained, deep learning models can be deployed on edge computers to perform classification and prediction on real-time data for these applications. Particularly for large models, the limited computational and memory resources on a single edge device can become the throughput bottleneck for an inference pipeline. To increase throughput and decrease per-device compute load, we present DEFER (Distributed Edge inFERence), a framework for distributed edge inference, which partitions deep neural networks into layers that can be spread across multiple compute nodes. The architecture consists of a single "dispatcher" node to distribute DNN partitions and inference data to respective compute nodes. The compute nodes are connected in a series pattern where each node's computed result is relayed to the subsequent node. The result is then returned to the Dispatcher. We quantify the throughput, energy consumption, network payload, and overhead for our framework under realistic network conditions using the CORE network emulator. We find that for the ResNet50 model, the inference throughput of DEFER with 8 compute nodes is 53% higher and per node energy consumption is 63% lower than single device inference. We further reduce network communication demands and energy consumption using the ZFP serialization and LZ4 compression algorithms. We have implemented DEFER in Python using the TensorFlow and Keras ML libraries, and have released DEFER as an open-source framework to benefit the research community.
* Received the Best Paper Award at the COMSNETS 2022 MINDS Workshop
Using Online Customer Reviews to Classify, Predict, and Learn about Domestic Robot Failures
Jan 10, 2022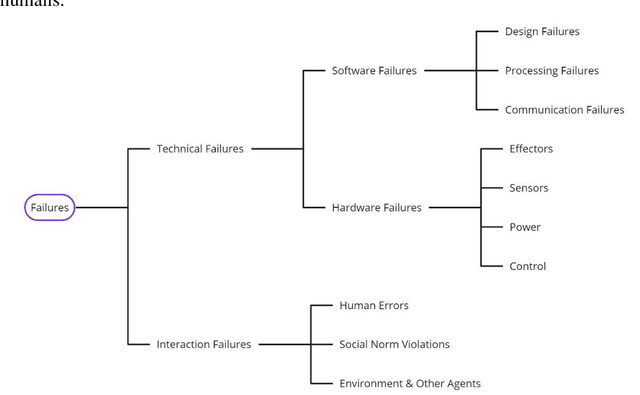

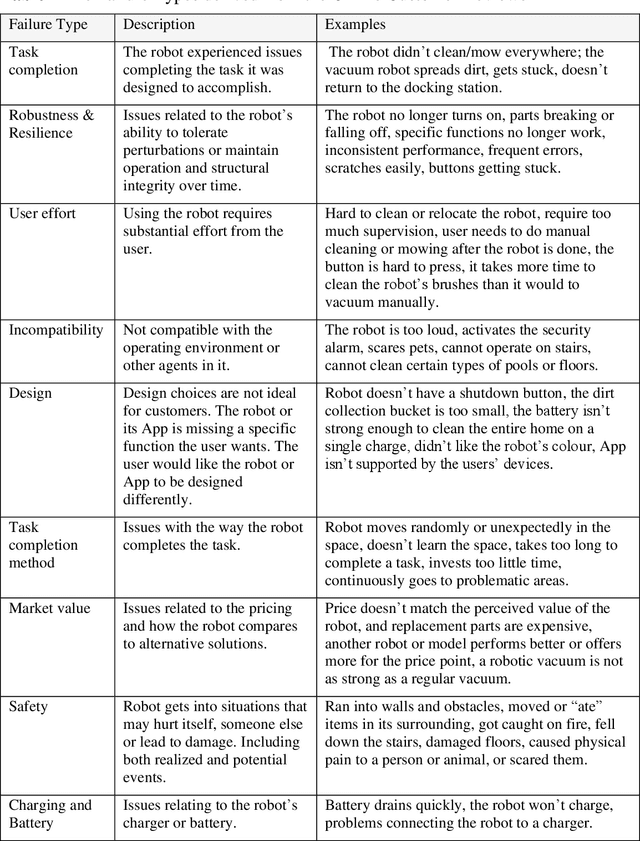
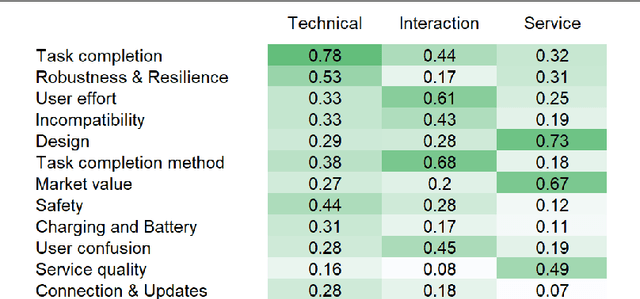
There is a knowledge gap regarding which types of failures robots undergo in domestic settings and how these failures influence customer experience. We classified 10,072 customer reviews of small utilitarian domestic robots on Amazon by the robotic failures described in them, grouping failures into twelve types and three categories (Technical, Interaction, and Service). We identified sources and types of failures previously overlooked in the literature, combining them into an updated failure taxonomy. We analyzed their frequencies and relations to customer star ratings. Results indicate that for utilitarian domestic robots, Technical failures were more detrimental to customer experience than Interaction or Service failures. Issues with Task Completion and Robustness & Resilience were commonly reported and had the most significant negative impact. Future failure-prevention and response strategies should address the technical ability of the robot to meet functional goals, operate and maintain structural integrity over time. Usability and interaction design were less detrimental to customer experience, indicating that customers may be more forgiving of failures that impact these aspects for the robots and practical uses examined. Further, we developed a Natural Language Processing model capable of predicting whether a customer review contains content that describes a failure and the type of failure it describes. With this knowledge, designers and researchers of robotic systems can prioritize design and development efforts towards essential issues.
Convergence of GANs Training: A Game and Stochastic Control Methodology
Dec 27, 2021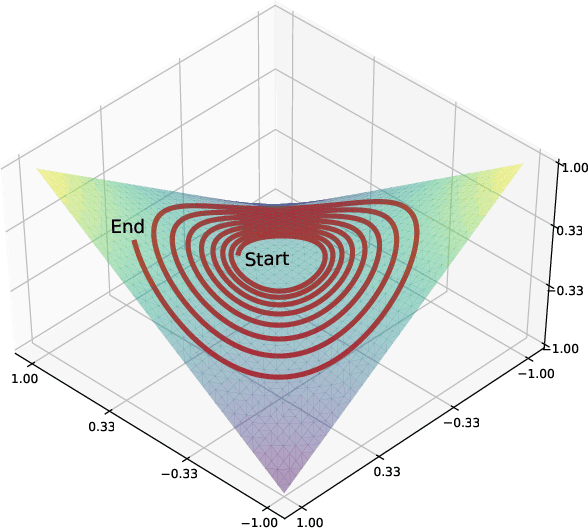
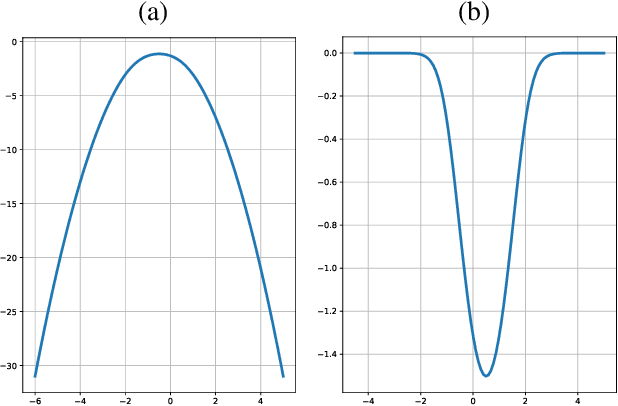
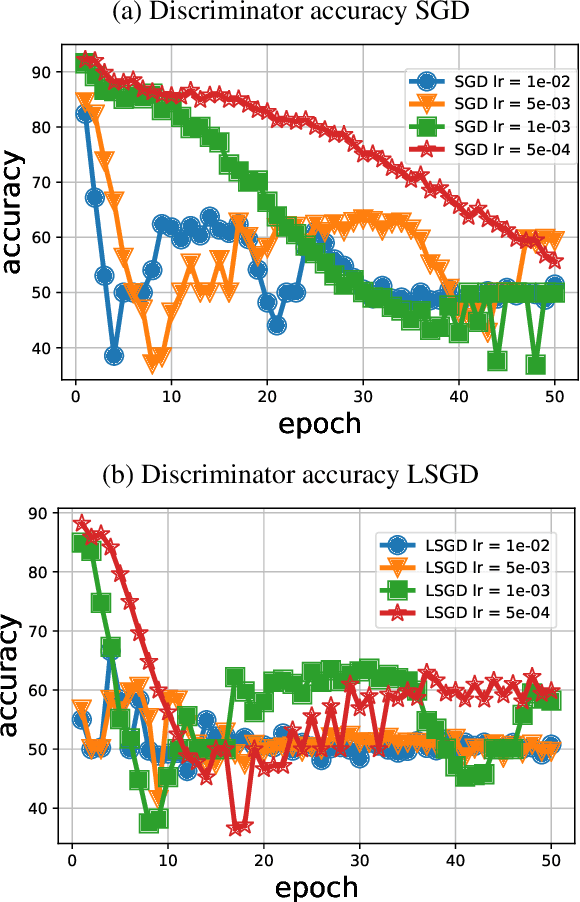
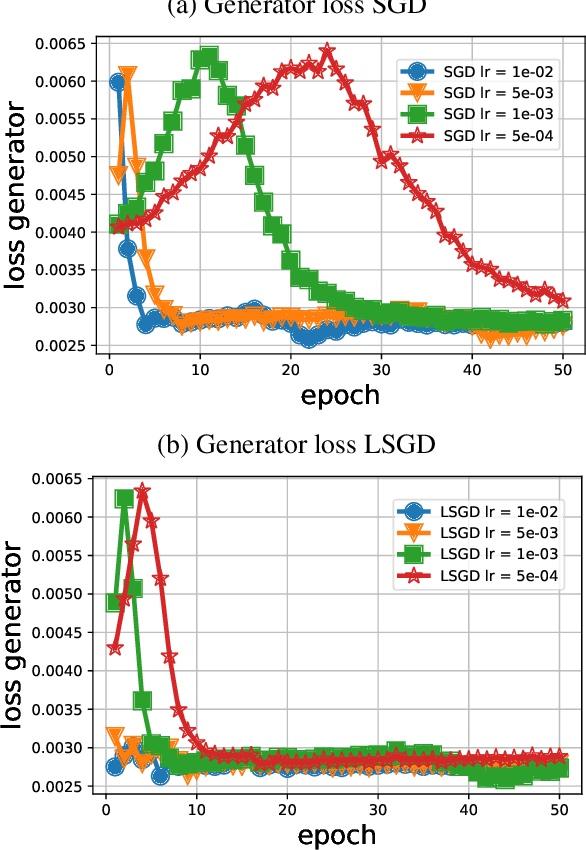
Training generative adversarial networks (GANs) is known to be difficult, especially for financial time series. This paper first analyzes the well-posedness problem in GANs minimax games and the convexity issue in GANs objective functions. It then proposes a stochastic control framework for hyper-parameters tuning in GANs training. The weak form of dynamic programming principle and the uniqueness and the existence of the value function in the viscosity sense for the corresponding minimax game are established. In particular, explicit forms for the optimal adaptive learning rate and batch size are derived and are shown to depend on the convexity of the objective function, revealing a relation between improper choices of learning rate and explosion in GANs training. Finally, empirical studies demonstrate that training algorithms incorporating this adaptive control approach outperform the standard ADAM method in terms of convergence and robustness. From GANs training perspective, the analysis in this paper provides analytical support for the popular practice of ``clipping'', and suggests that the convexity and well-posedness issues in GANs may be tackled through appropriate choices of hyper-parameters.
Integration of Explainable Artificial Intelligence to Identify Significant Landslide Causal Factors for Extreme Gradient Boosting based Landslide Susceptibility Mapping with Improved Feature Selection
Jan 10, 2022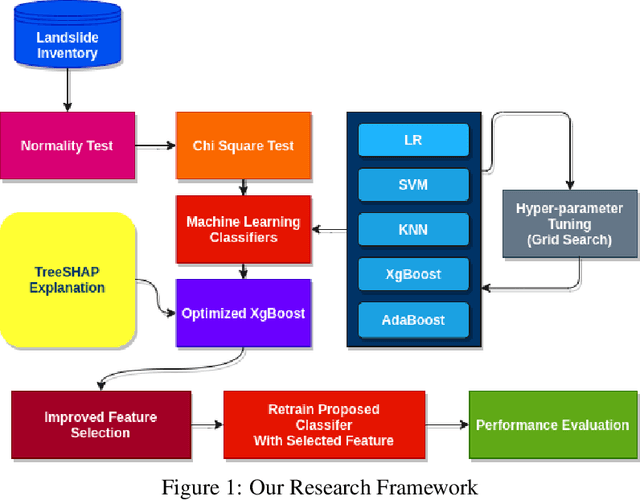
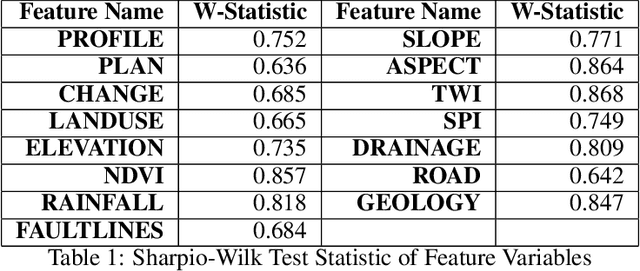
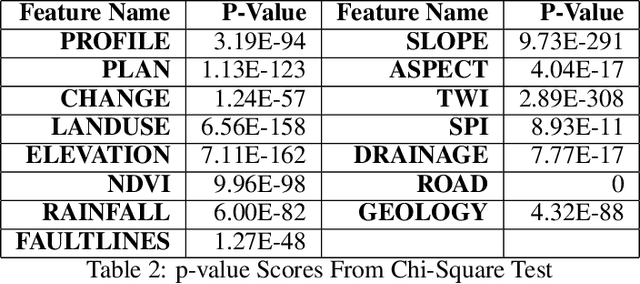
Landslides have been a regular occurrence and an alarming threat to human life and property in the era of anthropogenic global warming. An early prediction of landslide susceptibility using a data-driven approach is a demand of time. In this study, we explored the eloquent features that best describe landslide susceptibility with state-of-the-art machine learning methods. In our study, we employed state-of-the-art machine learning algorithms including XgBoost, LR, KNN, SVM, Adaboost for landslide susceptibility prediction. To find the best hyperparameters of each individual classifier for optimized performance, we have incorporated the Grid Search method, with 10 Fold Cross-Validation. In this context, the optimized version of XgBoost outperformed all other classifiers with a Cross-validation Weighted F1 score of 94.62%. Followed by this empirical evidence, we explored the XgBoost classifier by incorporating TreeSHAP and identified eloquent features such as SLOPE, ELEVATION, TWI that complement the performance of the XGBoost classifier mostly and features such as LANDUSE, NDVI, SPI which has less effect on models performance. According to the TreeSHAP explanation of features, we selected the 9 most significant landslide causal factors out of 15. Evidently, an optimized version of XgBoost along with feature reduction by 40%, has outperformed all other classifiers in terms of popular evaluation metrics with a Cross-Validation Weighted F1 score of 95.01% on the training and AUC score of 97%.
Time2Vec: Learning a Vector Representation of Time
Jul 11, 2019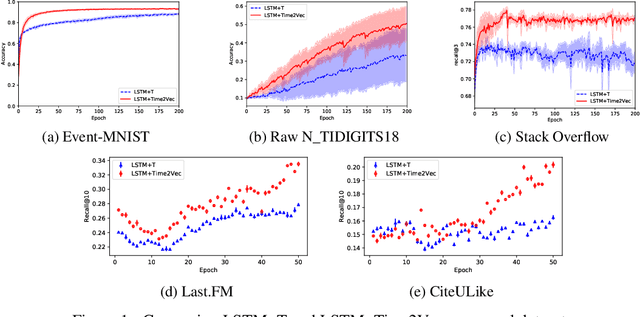
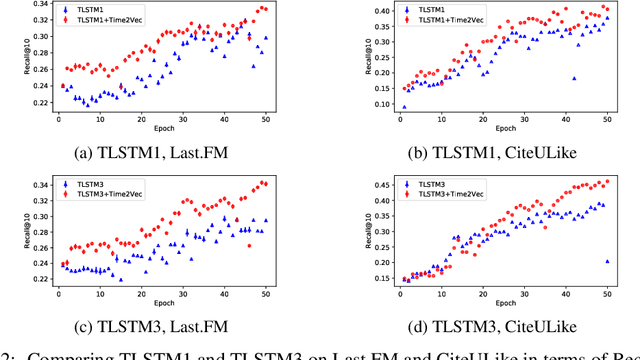
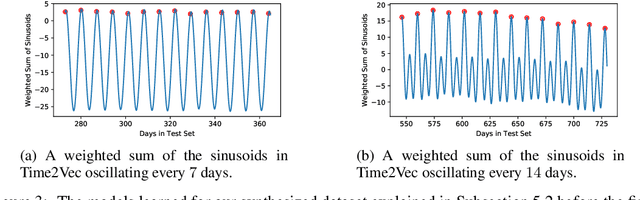
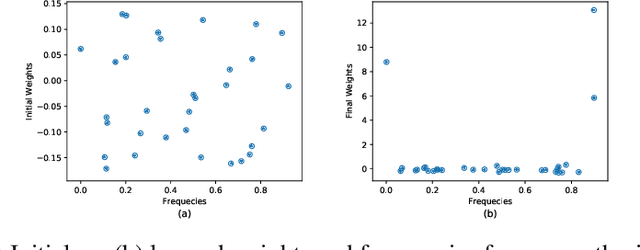
Time is an important feature in many applications involving events that occur synchronously and/or asynchronously. To effectively consume time information, recent studies have focused on designing new architectures. In this paper, we take an orthogonal but complementary approach by providing a model-agnostic vector representation for time, called Time2Vec, that can be easily imported into many existing and future architectures and improve their performances. We show on a range of models and problems that replacing the notion of time with its Time2Vec representation improves the performance of the final model.
Modeling and Predicting Blood Flow Characteristics through Double Stenosed Artery from CFD simulation using Deep Learning Models
Dec 04, 2021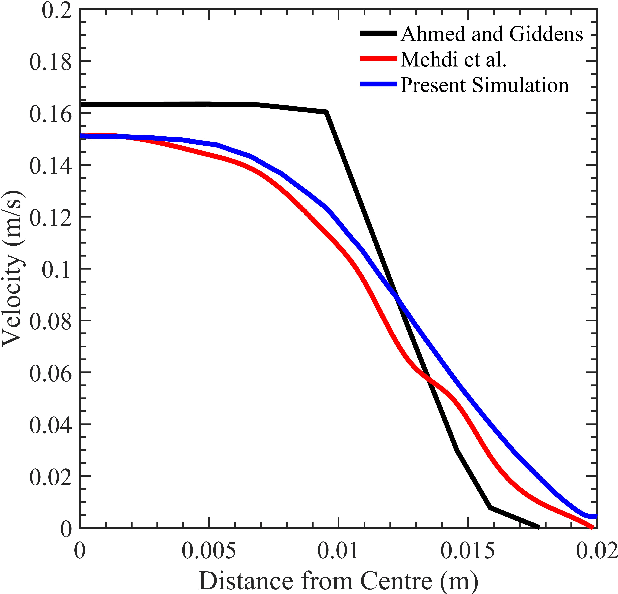
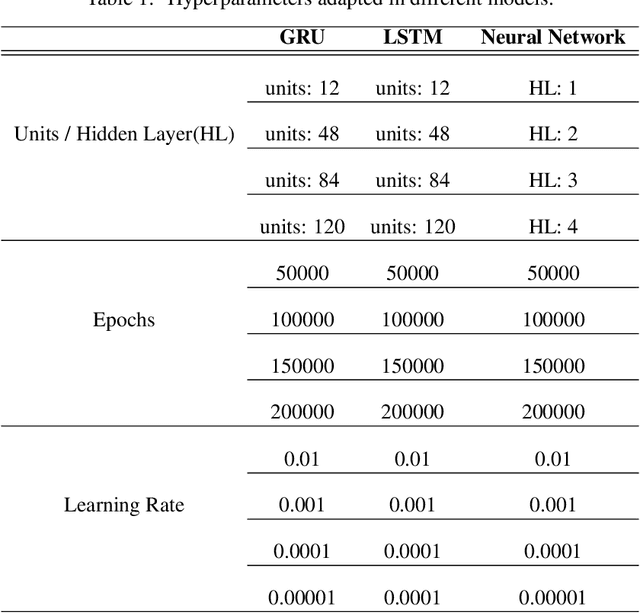
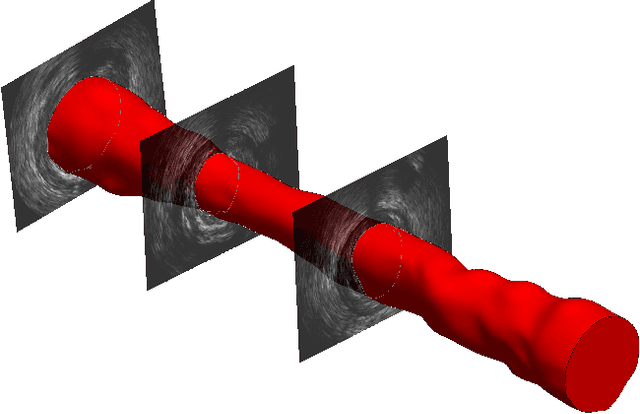
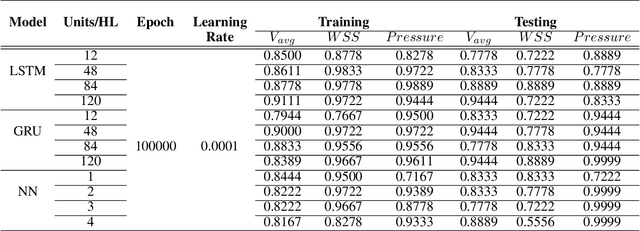
Establishing patient-specific finite element analysis (FEA) models for computational fluid dynamics (CFD) of double stenosed artery models involves time and effort, restricting physicians' ability to respond quickly in time-critical medical applications. Such issues might be addressed by training deep learning (DL) models to learn and predict blood flow characteristics using a dataset generated by CFD simulations of simplified double stenosed artery models with different configurations. When blood flow patterns are compared through an actual double stenosed artery model, derived from IVUS imaging, it is revealed that the sinusoidal approximation of stenosed neck geometry, which has been widely used in previous research works, fails to effectively represent the effects of a real constriction. As a result, a novel geometric representation of the constricted neck is proposed which, in terms of a generalized simplified model, outperforms the former assumption. The sequential change in artery lumen diameter and flow parameters along the length of the vessel presented opportunities for the use of LSTM and GRU DL models. However, with the small dataset of short lengths of doubly constricted blood arteries, the basic neural network model outperforms the specialized RNNs for most flow properties. LSTM, on the other hand, performs better for predicting flow properties with large fluctuations, such as varying blood pressure over the length of the vessels. Despite having good overall accuracies in training and testing across all the properties for the vessels in the dataset, the GRU model underperforms for an individual vessel flow prediction in all cases. The results also point to the need of individually optimized hyperparameters for each property in any model rather than aiming to achieve overall good performance across all outputs with a single set of hyperparameters.
High-Throughput and Configurable Preprocessor for ICA-based Self-interference Cancellation
Jan 10, 2022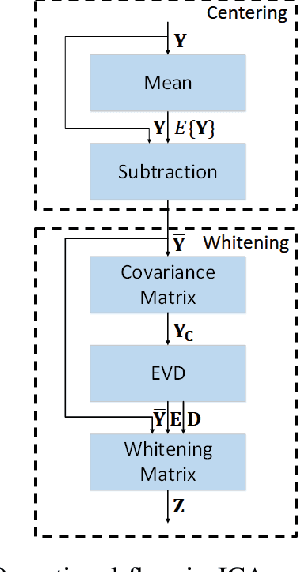

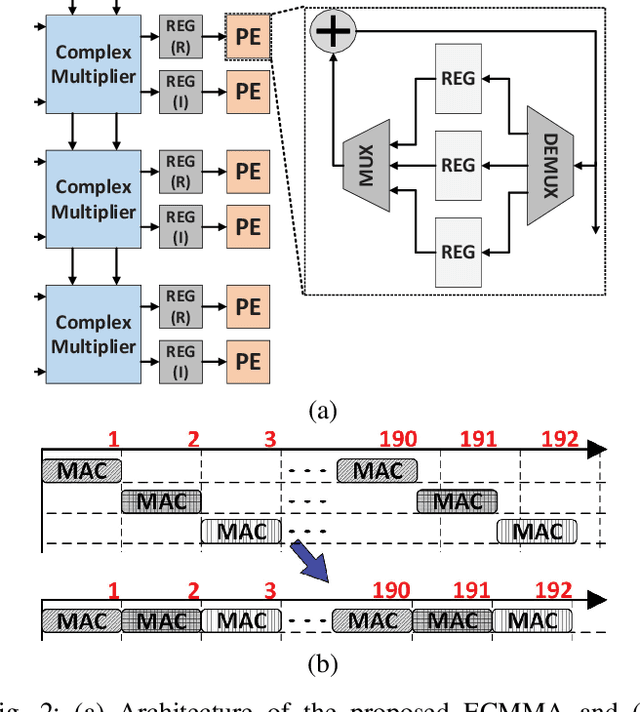

Independent component analysis (ICA) has been used in many applications, including self-interference cancellation in in-band full-duplex wireless communication systems. This paper presents a high-throughput and highly efficient configurable preprocessor for the ICA algorithm. The proposed ICA preprocessor has three major components for centering, for computing the covariance matrix, and for eigenvalue decomposition (EVD). The circuit structures and operational flows for these components are designed both in individual and in joint sense. Specifically, the proposed preprocessor is based on a high-performance matrix multiplication array (MMA) that is presented in this paper. The proposed MMA architecture uses time-multiplexed processing so that the efficiency of hardware utilization is greatly enhanced. Furthermore, the novel processing flow of the proposed preprocessor is highly optimized, so that the centering, the calculation of the covariance matrix, and EVD are conducted in parallel and are pipelined. Thus, the processing throughput is maximized while the required number of hardware elements can be minimized. The proposed ICA preprocessor is designed and implemented with a circuit design flow, and performance estimates based on the post-layout evaluations are presented in this paper. This paper shows that the proposed preprocessor achieves a throughput of 40.7~kMatrices per second for a complexity of 73.3~kGE. Compared with prior work, the proposed preprocessor achieves the highest processing throughput and best efficiency.
Towards realistic symmetry-based completion of previously unseen point clouds
Jan 05, 2022
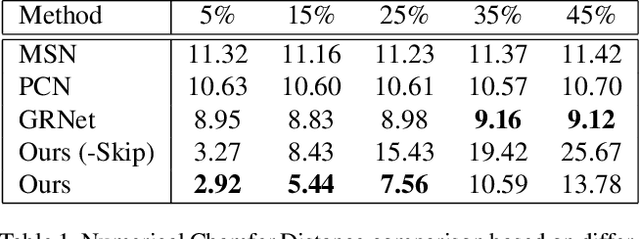
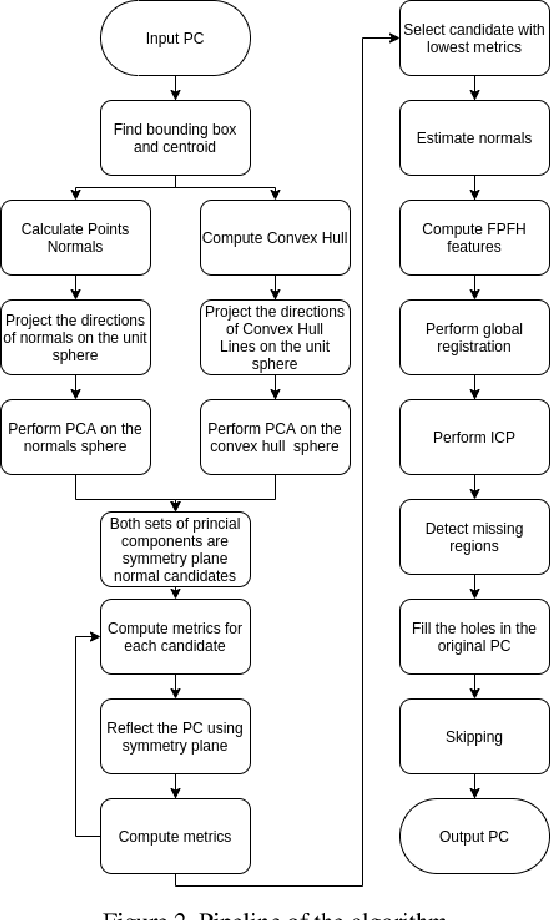

3D scanning is a complex multistage process that generates a point cloud of an object typically containing damaged parts due to occlusions, reflections, shadows, scanner motion, specific properties of the object surface, imperfect reconstruction algorithms, etc. Point cloud completion is specifically designed to fill in the missing parts of the object and obtain its high-quality 3D representation. The existing completion approaches perform well on the academic datasets with a predefined set of object classes and very specific types of defects; however, their performance drops significantly in the real-world settings and degrades even further on previously unseen object classes. We propose a novel framework that performs well on symmetric objects, which are ubiquitous in man-made environments. Unlike learning-based approaches, the proposed framework does not require training data and is capable of completing non-critical damages occurring in customer 3D scanning process using e.g. Kinect, time-of-flight, or structured light scanners. With thorough experiments, we demonstrate that the proposed framework achieves state-of-the-art efficiency in point cloud completion of real-world customer scans. We benchmark the framework performance on two types of datasets: properly augmented existing academic dataset and the actual 3D scans of various objects.
A Minmax Utilization Algorithm for Network Traffic Scheduling of Industrial Robots
Nov 02, 2021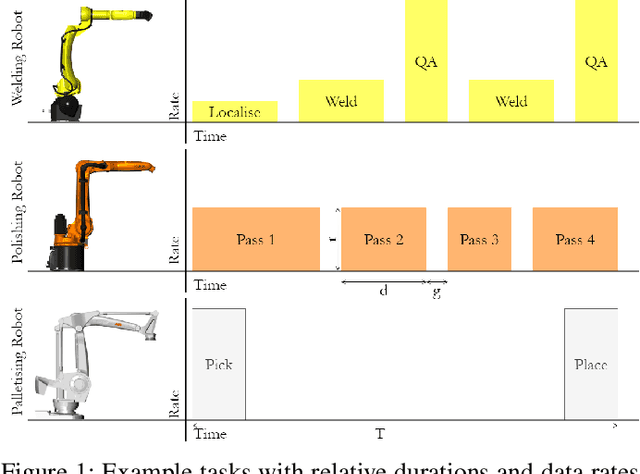
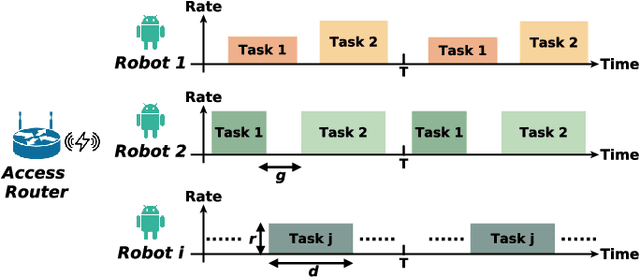
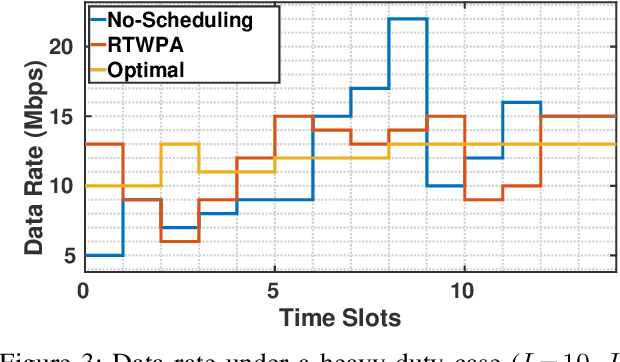
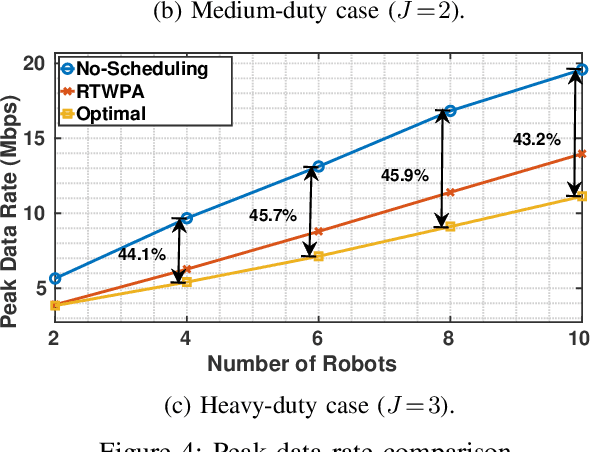
Emerging 5G and beyond wireless industrial virtualized networks are expected to support a significant number of robotic manipulators. Depending on the processes involved, these industrial robots might result in significant volume of multi-modal traffic that will need to traverse the network all the way to the (public/private) edge cloud, where advanced processing, control and service orchestration will be taking place. In this paper, we perform the traffic engineering by capitalizing on the underlying pseudo-deterministic nature of the repetitive processes of robotic manipulators in an industrial environment and propose an integer linear programming (ILP) model to minimize the maximum aggregate traffic in the network. The task sequence and time gap requirements are also considered in the proposed model. To tackle the curse of dimensionality in ILP, we provide a random search algorithm with quadratic time complexity. Numerical investigations reveal that the proposed scheme can reduce the peak data rate up to 53.4% compared with the nominal case where robotic manipulators operate in an uncoordinated fashion, resulting in significant improvement in the utilization of the underlying network resources.