 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Path Regularization: A Convexity and Sparsity Inducing Regularization for Parallel ReLU Networks
Oct 25, 2021
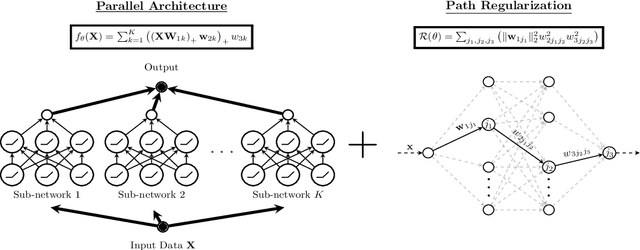

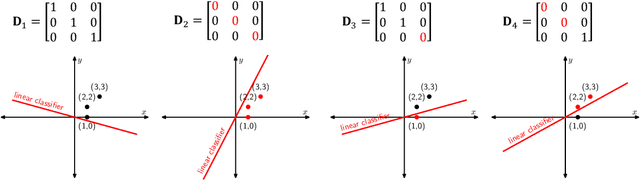
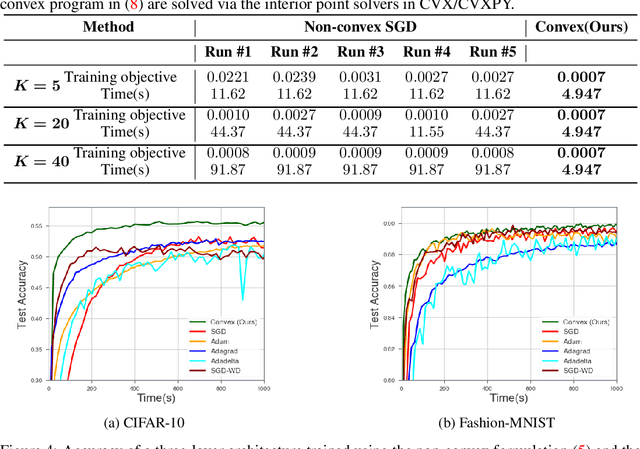
Despite several attempts, the fundamental mechanisms behind the success of deep neural networks still remain elusive. To this end, we introduce a novel analytic framework to unveil hidden convexity in training deep neural networks. We consider a parallel architecture with multiple ReLU sub-networks, which includes many standard deep architectures and ResNets as its special cases. We then show that the training problem with path regularization can be cast as a single convex optimization problem in a high-dimensional space. We further prove that the equivalent convex program is regularized via a group sparsity inducing norm. Thus, a path regularized parallel architecture with ReLU sub-networks can be viewed as a parsimonious feature selection method in high-dimensions. More importantly, we show that the computational complexity required to globally optimize the equivalent convex problem is polynomial-time with respect to the number of data samples and feature dimension. Therefore, we prove exact polynomial-time trainability for path regularized deep ReLU networks with global optimality guarantees. We also provide several numerical experiments corroborating our theory.
Sparse Distillation: Speeding Up Text Classification by Using Bigger Models
Oct 16, 2021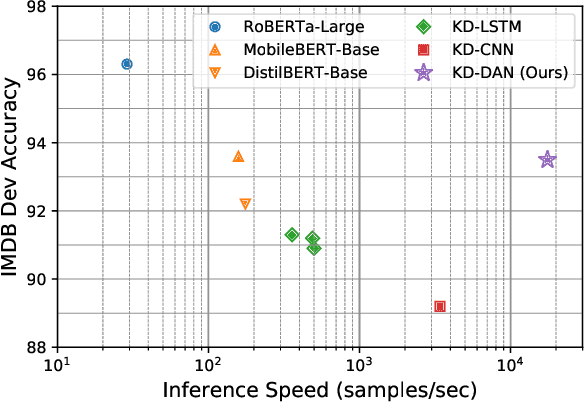
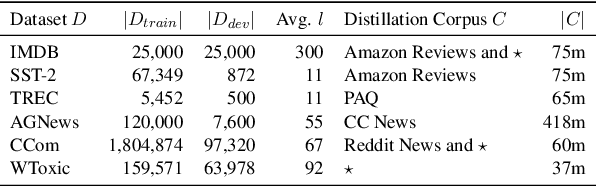
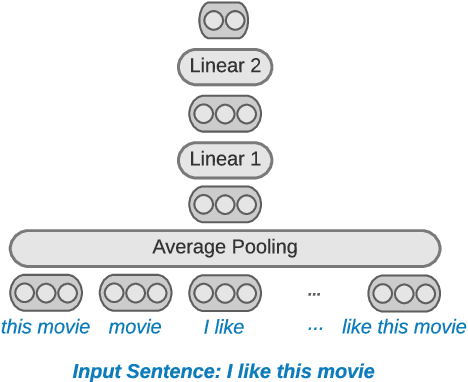
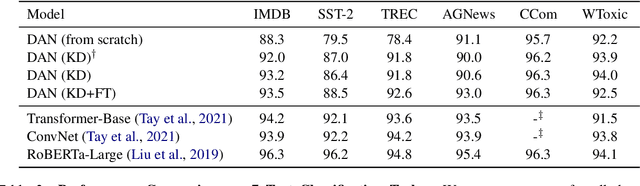
Distilling state-of-the-art transformer models into lightweight student models is an effective way to reduce computation cost at inference time. However, the improved inference speed may be still unsatisfactory for certain time-sensitive applications. In this paper, we aim to further push the limit of inference speed by exploring a new area in the design space of the student model. More specifically, we consider distilling a transformer-based text classifier into a billion-parameter, sparsely-activated student model with a embedding-averaging architecture. Our experiments show that the student models retain 97% of the RoBERTa-Large teacher performance on a collection of six text classification tasks. Meanwhile, the student model achieves up to 600x speed-up on both GPUs and CPUs, compared to the teacher models. Further investigation shows that our pipeline is also effective in privacy-preserving and domain generalization settings.
Fooling the Eyes of Autonomous Vehicles: Robust Physical Adversarial Examples Against Traffic Sign Recognition Systems
Jan 17, 2022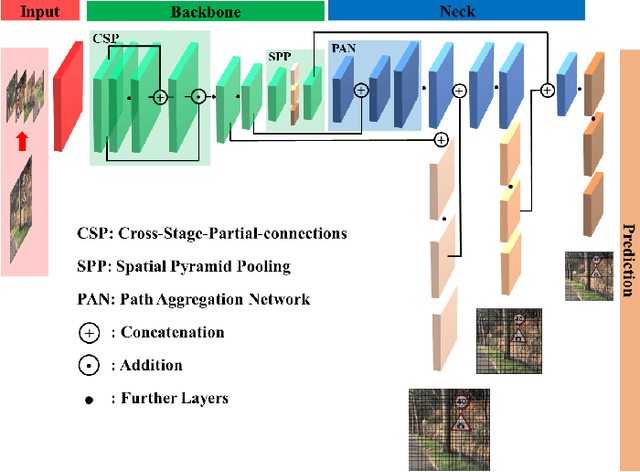
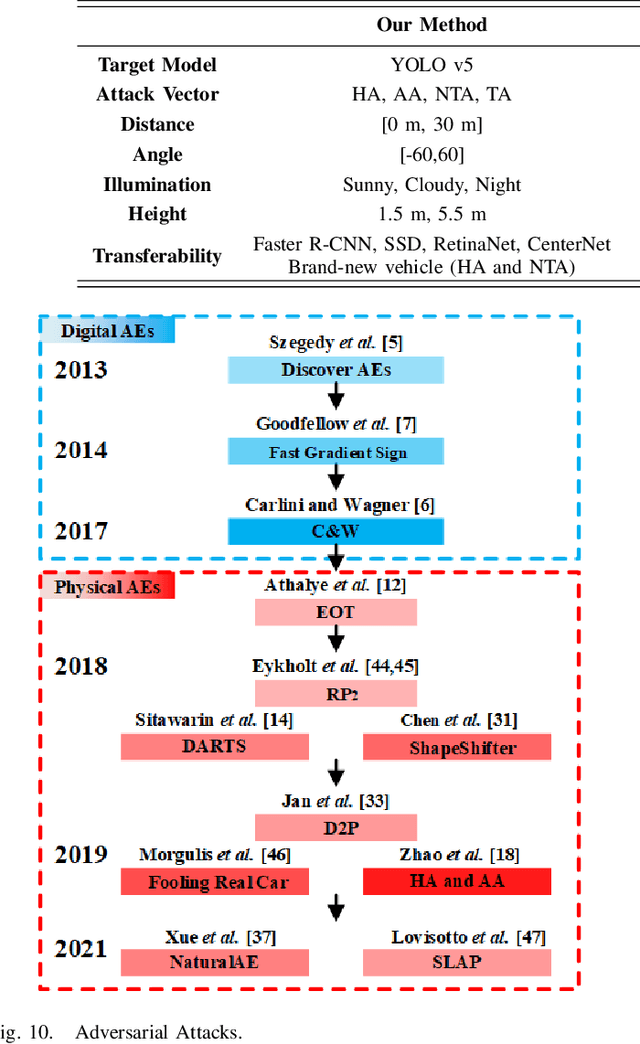
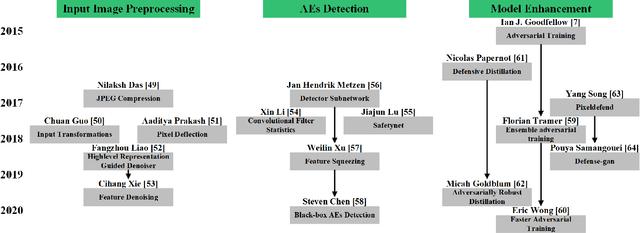

Adversarial Examples (AEs) can deceive Deep Neural Networks (DNNs) and have received a lot of attention recently. However, majority of the research on AEs is in the digital domain and the adversarial patches are static, which is very different from many real-world DNN applications such as Traffic Sign Recognition (TSR) systems in autonomous vehicles. In TSR systems, object detectors use DNNs to process streaming video in real time. From the view of object detectors, the traffic sign`s position and quality of the video are continuously changing, rendering the digital AEs ineffective in the physical world. In this paper, we propose a systematic pipeline to generate robust physical AEs against real-world object detectors. Robustness is achieved in three ways. First, we simulate the in-vehicle cameras by extending the distribution of image transformations with the blur transformation and the resolution transformation. Second, we design the single and multiple bounding boxes filters to improve the efficiency of the perturbation training. Third, we consider four representative attack vectors, namely Hiding Attack, Appearance Attack, Non-Target Attack and Target Attack. We perform a comprehensive set of experiments under a variety of environmental conditions, and considering illuminations in sunny and cloudy weather as well as at night. The experimental results show that the physical AEs generated from our pipeline are effective and robust when attacking the YOLO v5 based TSR system. The attacks have good transferability and can deceive other state-of-the-art object detectors. We launched HA and NTA on a brand-new 2021 model vehicle. Both attacks are successful in fooling the TSR system, which could be a life-threatening case for autonomous vehicles. Finally, we discuss three defense mechanisms based on image preprocessing, AEs detection, and model enhancing.
TransVOD: End-to-end Video Object Detection with Spatial-Temporal Transformers
Jan 17, 2022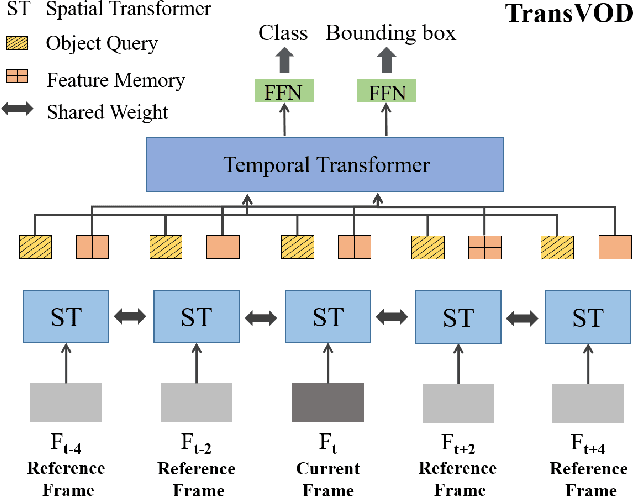
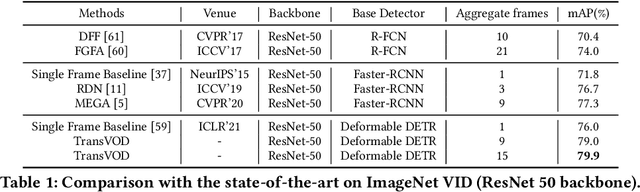
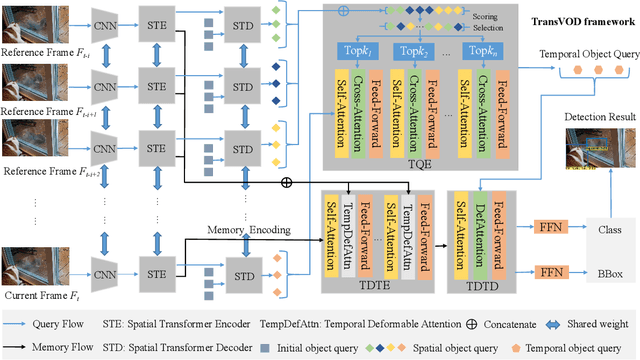
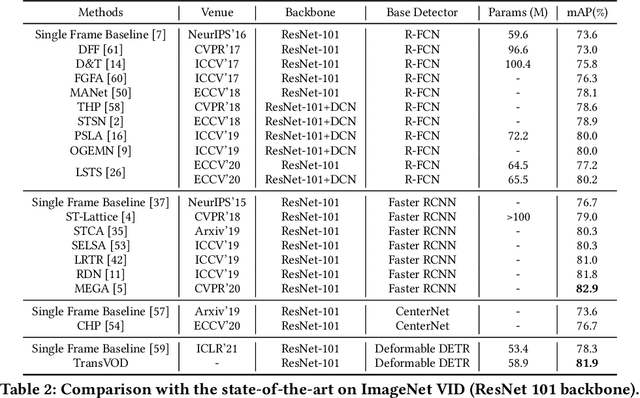
Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.
A Study on Token Pruning for ColBERT
Dec 13, 2021
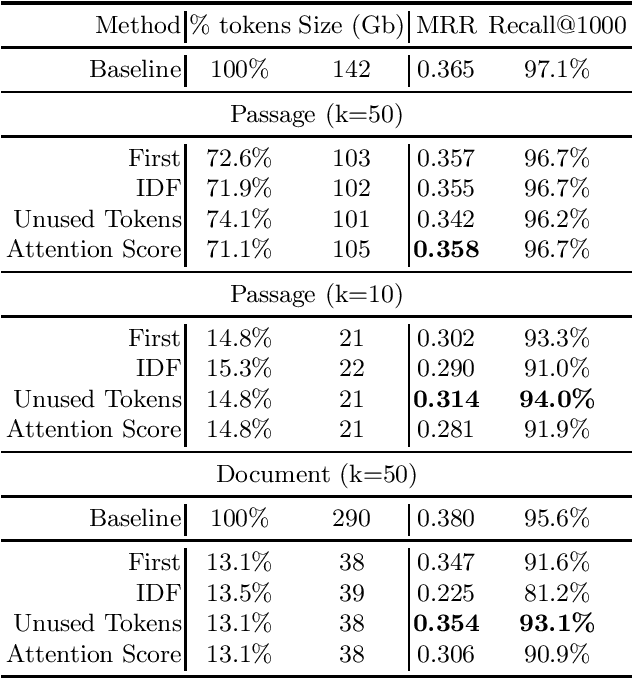
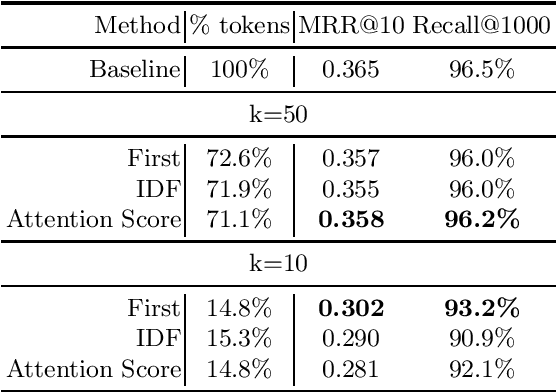
The ColBERT model has recently been proposed as an effective BERT based ranker. By adopting a late interaction mechanism, a major advantage of ColBERT is that document representations can be precomputed in advance. However, the big downside of the model is the index size, which scales linearly with the number of tokens in the collection. In this paper, we study various designs for ColBERT models in order to attack this problem. While compression techniques have been explored to reduce the index size, in this paper we study token pruning techniques for ColBERT. We compare simple heuristics, as well as a single layer of attention mechanism to select the tokens to keep at indexing time. Our experiments show that ColBERT indexes can be pruned up to 30\% on the MS MARCO passage collection without a significant drop in performance. Finally, we experiment on MS MARCO documents, which reveal several challenges for such mechanism.
Finite-Time Analysis of Decentralized Stochastic Approximation with Applications in Multi-Agent and Multi-Task Learning
Oct 28, 2020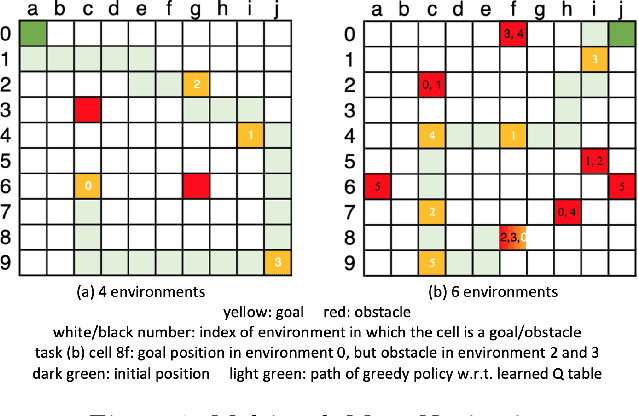
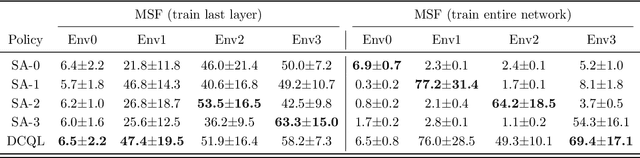

Stochastic approximation, a data-driven approach for finding the fixed point of an unknown operator, provides a unified framework for treating many problems in stochastic optimization and reinforcement learning. Motivated by a growing interest in multi-agent and multi-task learning, we consider in this paper a decentralized variant of stochastic approximation. A network of agents, each with their own unknown operator and data observations, cooperatively find the fixed point of the aggregate operator. The agents work by running a local stochastic approximation algorithm using noisy samples from their operators while averaging their iterates with their neighbors' on a decentralized communication graph. Our main contribution provides a finite-time analysis of this decentralized stochastic approximation algorithm and characterizes the impacts of the underlying communication topology between agents. Our model for the data observed at each agent is that it is sampled from a Markov processes; this lack of independence makes the iterates biased and (potentially) unbounded. Under mild assumptions on the Markov processes, we show that the convergence rate of the proposed methods is essentially the same as if the samples were independent, differing only by a log factor that represents the mixing time of the Markov process. We also present applications of the proposed method on a number of interesting learning problems in multi-agent systems, including a decentralized variant of Q-learning for solving multi-task reinforcement learning.
Counterfactual Memorization in Neural Language Models
Dec 24, 2021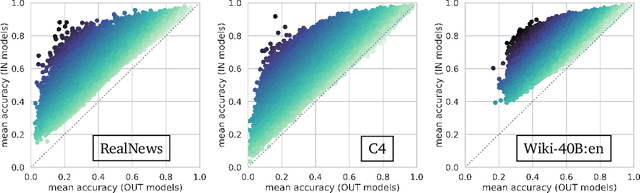
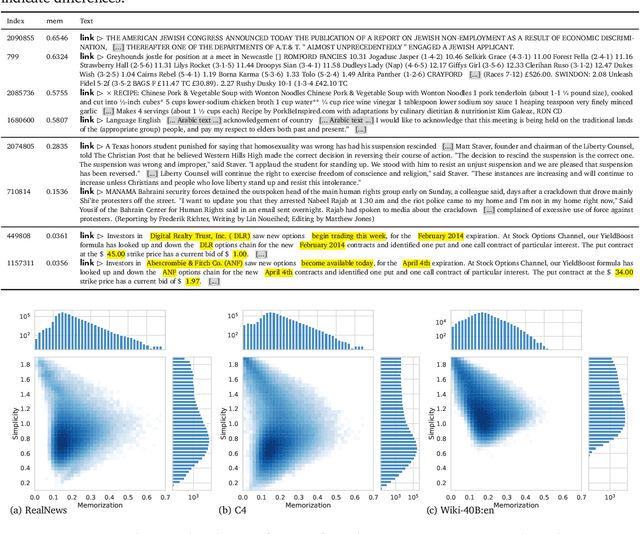

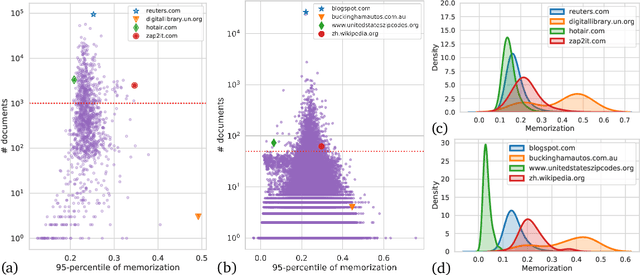
Modern neural language models widely used in tasks across NLP risk memorizing sensitive information from their training data. As models continue to scale up in parameters, training data, and compute, understanding memorization in language models is both important from a learning-theoretical point of view, and is practically crucial in real world applications. An open question in previous studies of memorization in language models is how to filter out "common" memorization. In fact, most memorization criteria strongly correlate with the number of occurrences in the training set, capturing "common" memorization such as familiar phrases, public knowledge or templated texts. In this paper, we provide a principled perspective inspired by a taxonomy of human memory in Psychology. From this perspective, we formulate a notion of counterfactual memorization, which characterizes how a model's predictions change if a particular document is omitted during training. We identify and study counterfactually-memorized training examples in standard text datasets. We further estimate the influence of each training example on the validation set and on generated texts, and show that this can provide direct evidence of the source of memorization at test time.
SP-SEDT: Self-supervised Pre-training for Sound Event Detection Transformer
Nov 30, 2021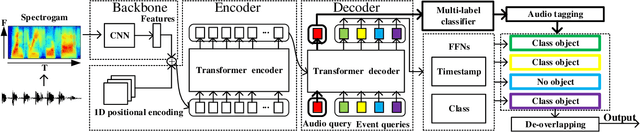
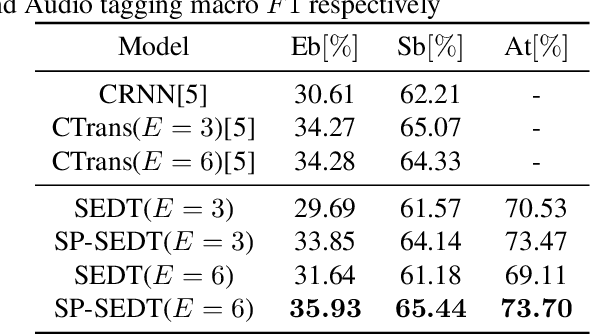
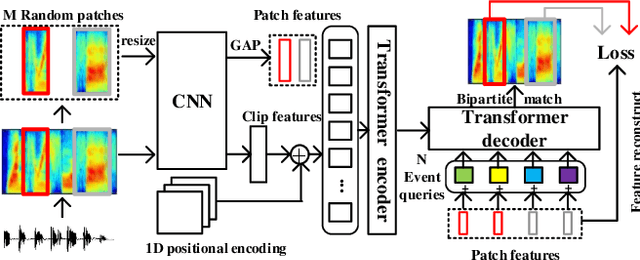
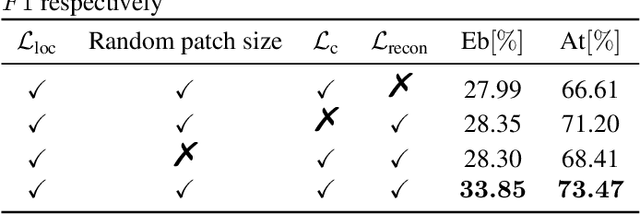
Recently, an event-based end-to-end model (SEDT) has been proposed for sound event detection (SED) and achieves competitive performance. However, compared with the frame-based model, it requires more training data with temporal annotations to improve the localization ability. Synthetic data is an alternative, but it suffers from a great domain gap with real recordings. Inspired by the great success of UP-DETR in object detection, we propose to self-supervisedly pre-train SEDT (SP-SEDT) by detecting random patches (only cropped along the time axis). Experiments on the DCASE2019 task4 dataset show the proposed SP-SEDT can outperform fine-tuned frame-based model. The ablation study is also conducted to investigate the impact of different loss functions and patch size.
You May Not Need Order in Time Series Forecasting
Oct 21, 2019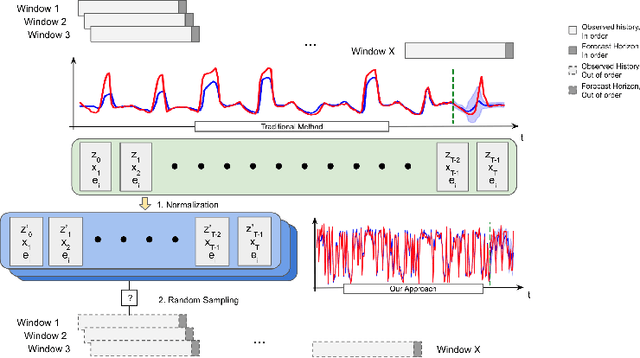
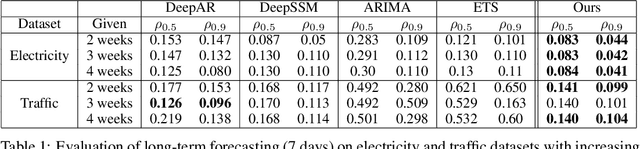
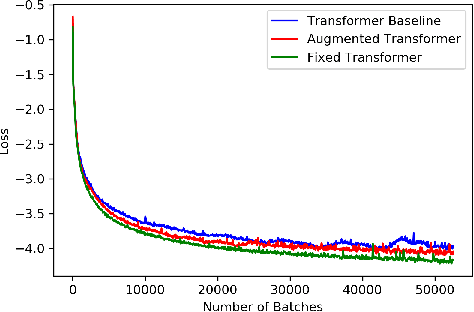
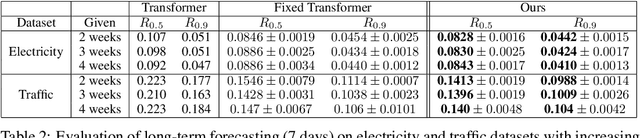
Time series forecasting with limited data is a challenging yet critical task. While transformers have achieved outstanding performances in time series forecasting, they often require many training samples due to the large number of trainable parameters. In this paper, we propose a training technique for transformers that prepares the training windows through random sampling. As input time steps need not be consecutive, the number of distinct samples increases from linearly to combinatorially many. By breaking the temporal order, this technique also helps transformers to capture dependencies among time steps in finer granularity. We achieve competitive results compared to the state-of-the-art on real-world datasets.
PyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
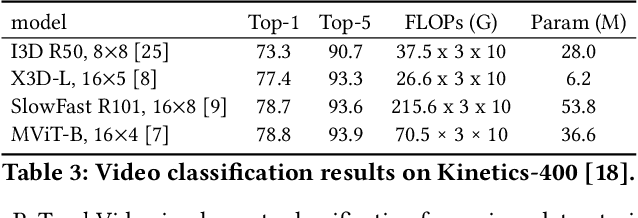

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/