 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Divide-and-Merge Point Cloud Clustering Algorithm for LiDAR Panoptic Segmentation
Sep 16, 2021
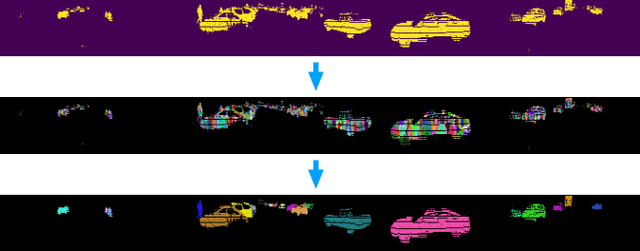
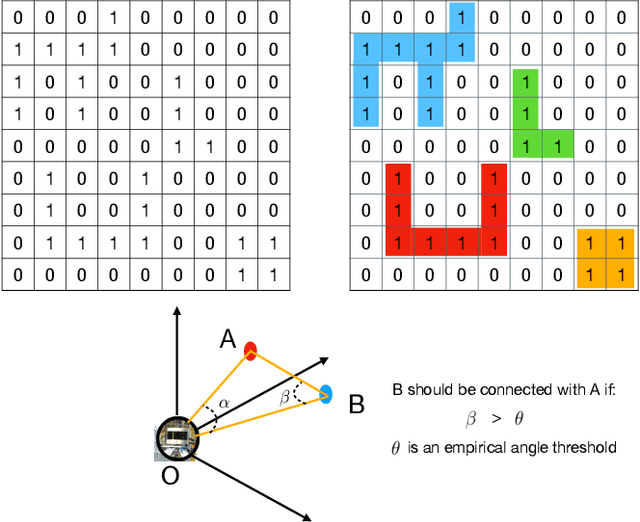
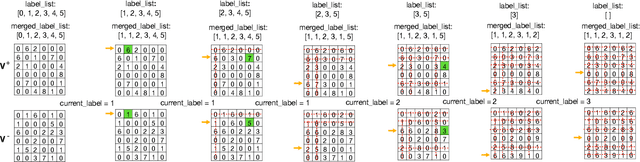

Clustering objects from the LiDAR point cloud is an important research problem with many applications such as autonomous driving. To meet the real-time requirement, existing research proposed to apply the connected-component-labeling (CCL) technique on LiDAR spherical range image with a heuristic condition to check if two neighbor points are connected. However, LiDAR range image is different from a binary image which has a deterministic condition to tell if two pixels belong to the same component. The heuristic condition used on the LiDAR range image only works empirically, which suggests the LiDAR clustering algorithm should be robust to potential failures of the empirical heuristic condition. To overcome this challenge, this paper proposes a divide-and-merge LiDAR clustering algorithm. This algorithm firstly conducts clustering in each evenly divided local region, then merges the local clustered small components by voting on edge point pairs. Assuming there are $N$ LiDAR points of objects in total with $m$ divided local regions, the time complexity of the proposed algorithm is $O(N)+O(m^2)$. A smaller $m$ means the voting will involve more neighbor points, but the time complexity will become larger. So the $m$ controls the trade-off between the time complexity and the clustering accuracy. A proper $m$ helps the proposed algorithm work in real-time as well as maintain good performance. We evaluate the divide-and-merge clustering algorithm on the SemanticKITTI panoptic segmentation benchmark by cascading it with a state-of-the-art semantic segmentation model. The final performance evaluated through the leaderboard achieves the best among all published methods. The proposed algorithm is implemented with C++ and wrapped as a python function. It can be easily used with the modern deep learning framework in python.
TransVOD: End-to-end Video Object Detection with Spatial-Temporal Transformers
Jan 17, 2022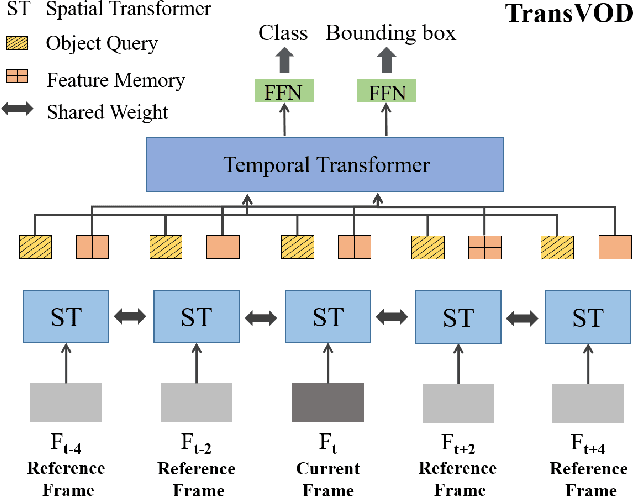
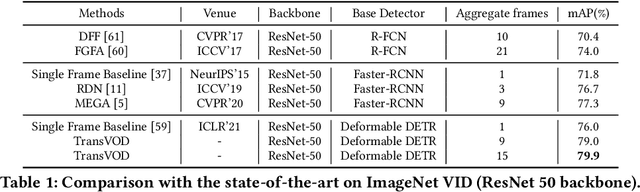
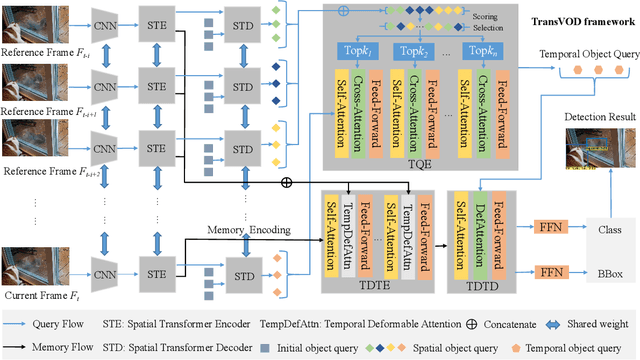
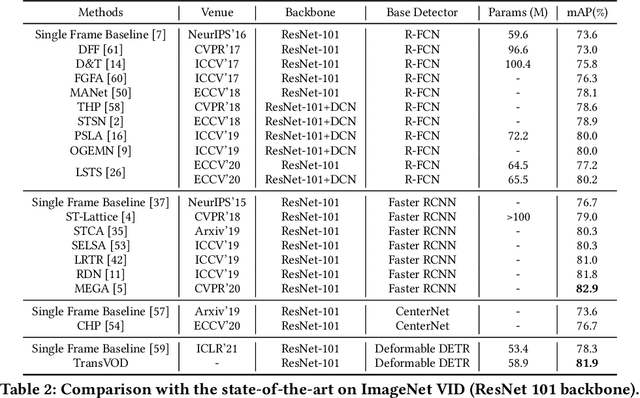
Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.
Training Feedback Spiking Neural Networks by Implicit Differentiation on the Equilibrium State
Sep 29, 2021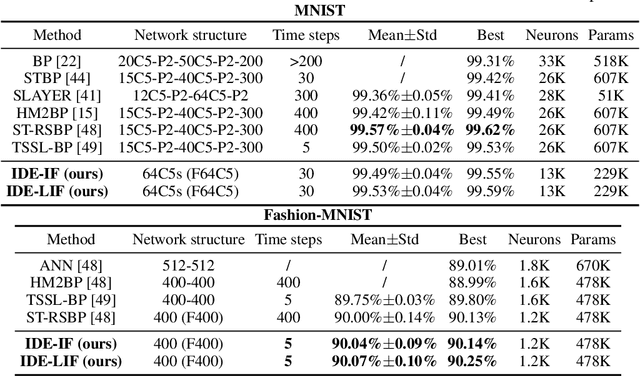
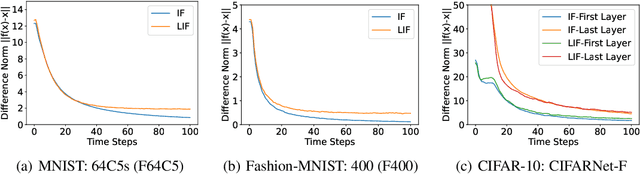
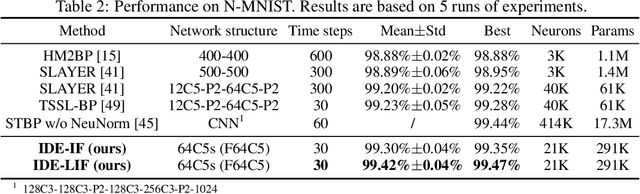
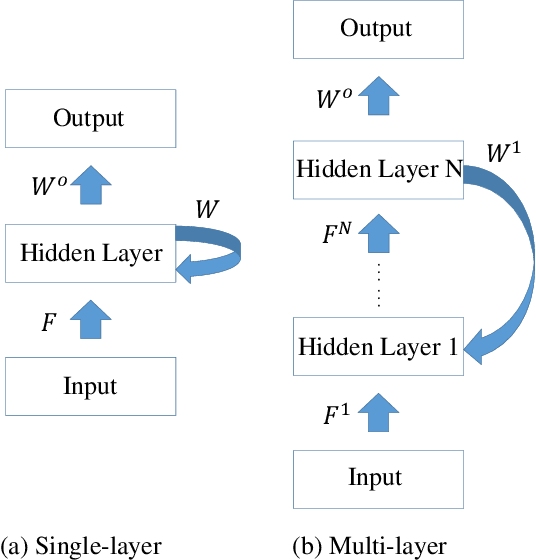
Spiking neural networks (SNNs) are brain-inspired models that enable energy-efficient implementation on neuromorphic hardware. However, the supervised training of SNNs remains a hard problem due to the discontinuity of the spiking neuron model. Most existing methods imitate the backpropagation framework and feedforward architectures for artificial neural networks, and use surrogate derivatives or compute gradients with respect to the spiking time to deal with the problem. These approaches either accumulate approximation errors or only propagate information limitedly through existing spikes, and usually require information propagation along time steps with large memory costs and biological implausibility. In this work, we consider feedback spiking neural networks, which are more brain-like, and propose a novel training method that does not rely on the exact reverse of the forward computation. First, we show that the average firing rates of SNNs with feedback connections would gradually evolve to an equilibrium state along time, which follows a fixed-point equation. Then by viewing the forward computation of feedback SNNs as a black-box solver for this equation, and leveraging the implicit differentiation on the equation, we can compute the gradient for parameters without considering the exact forward procedure. In this way, the forward and backward procedures are decoupled and therefore the problem of non-differentiable spiking functions is avoided. We also briefly discuss the biological plausibility of implicit differentiation, which only requires computing another equilibrium. Extensive experiments on MNIST, Fashion-MNIST, N-MNIST, CIFAR-10, and CIFAR-100 demonstrate the superior performance of our method for feedback models with fewer neurons and parameters in a small number of time steps. Our code is avaiable at https://github.com/pkuxmq/IDE-FSNN.
Path Regularization: A Convexity and Sparsity Inducing Regularization for Parallel ReLU Networks
Oct 25, 2021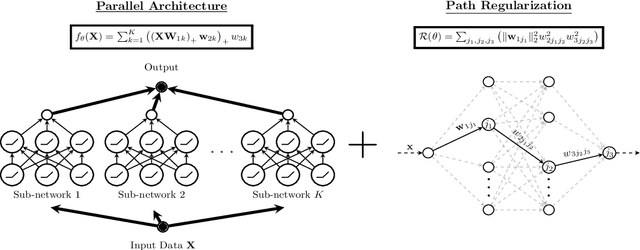

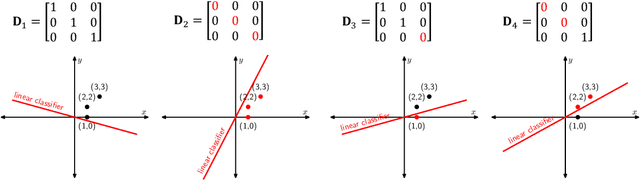
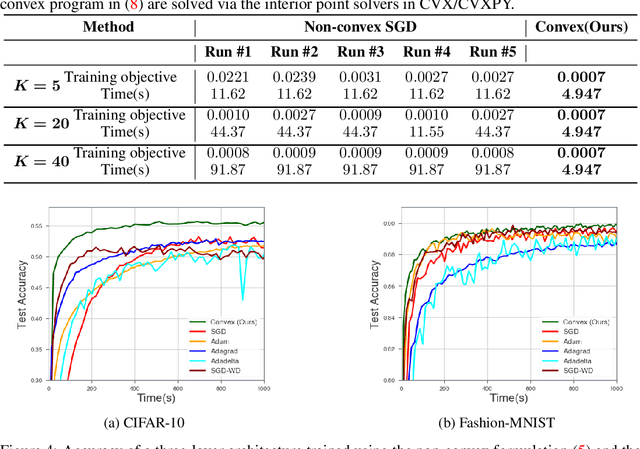
Despite several attempts, the fundamental mechanisms behind the success of deep neural networks still remain elusive. To this end, we introduce a novel analytic framework to unveil hidden convexity in training deep neural networks. We consider a parallel architecture with multiple ReLU sub-networks, which includes many standard deep architectures and ResNets as its special cases. We then show that the training problem with path regularization can be cast as a single convex optimization problem in a high-dimensional space. We further prove that the equivalent convex program is regularized via a group sparsity inducing norm. Thus, a path regularized parallel architecture with ReLU sub-networks can be viewed as a parsimonious feature selection method in high-dimensions. More importantly, we show that the computational complexity required to globally optimize the equivalent convex problem is polynomial-time with respect to the number of data samples and feature dimension. Therefore, we prove exact polynomial-time trainability for path regularized deep ReLU networks with global optimality guarantees. We also provide several numerical experiments corroborating our theory.
Real-Time Radio Technology and Modulation Classification via an LSTM Auto-Encoder
Nov 16, 2020
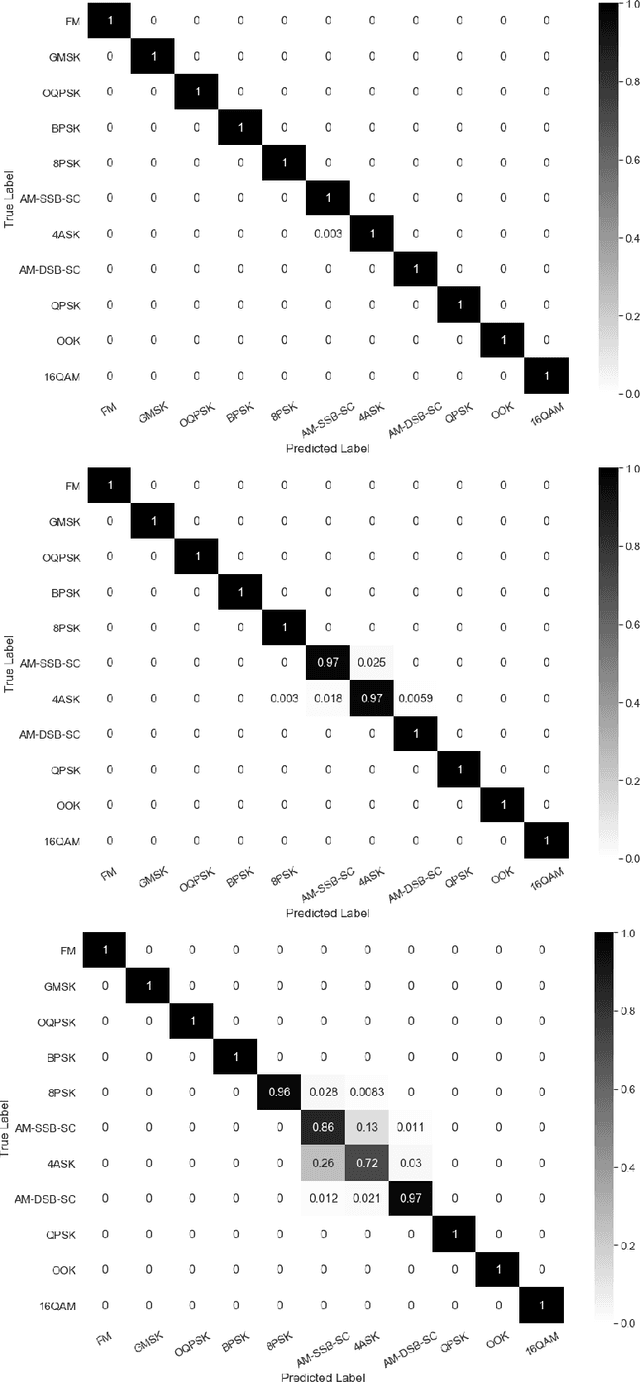
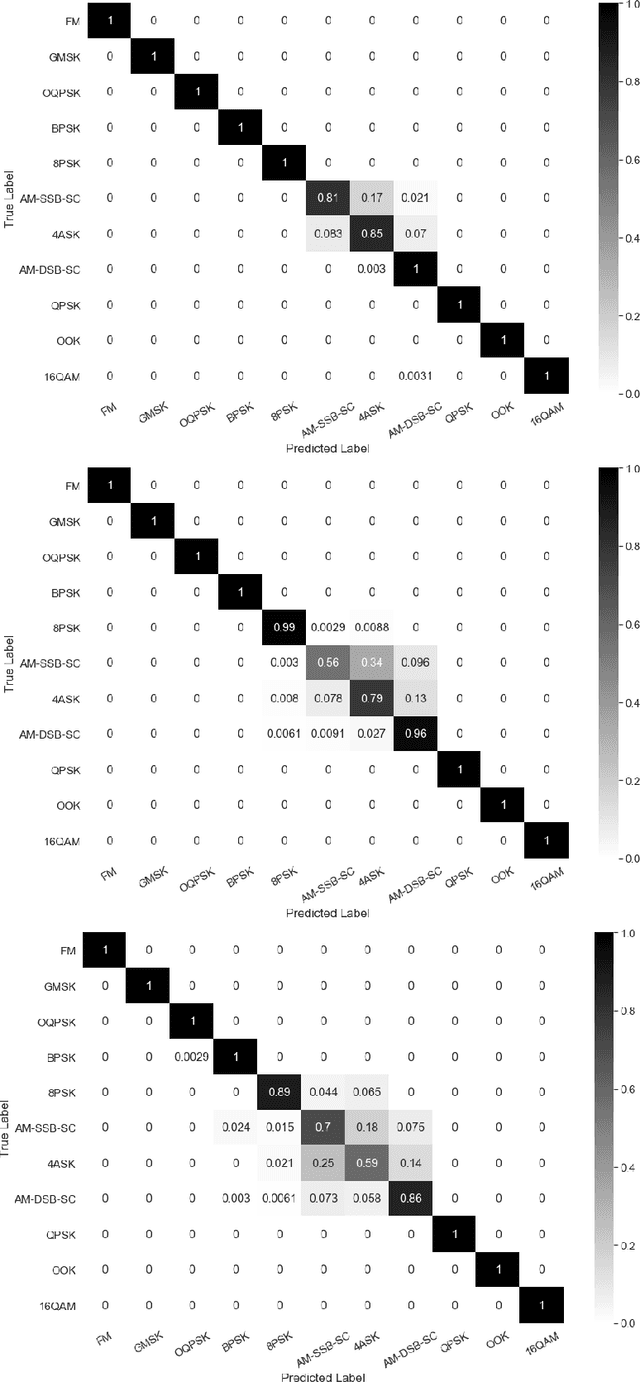
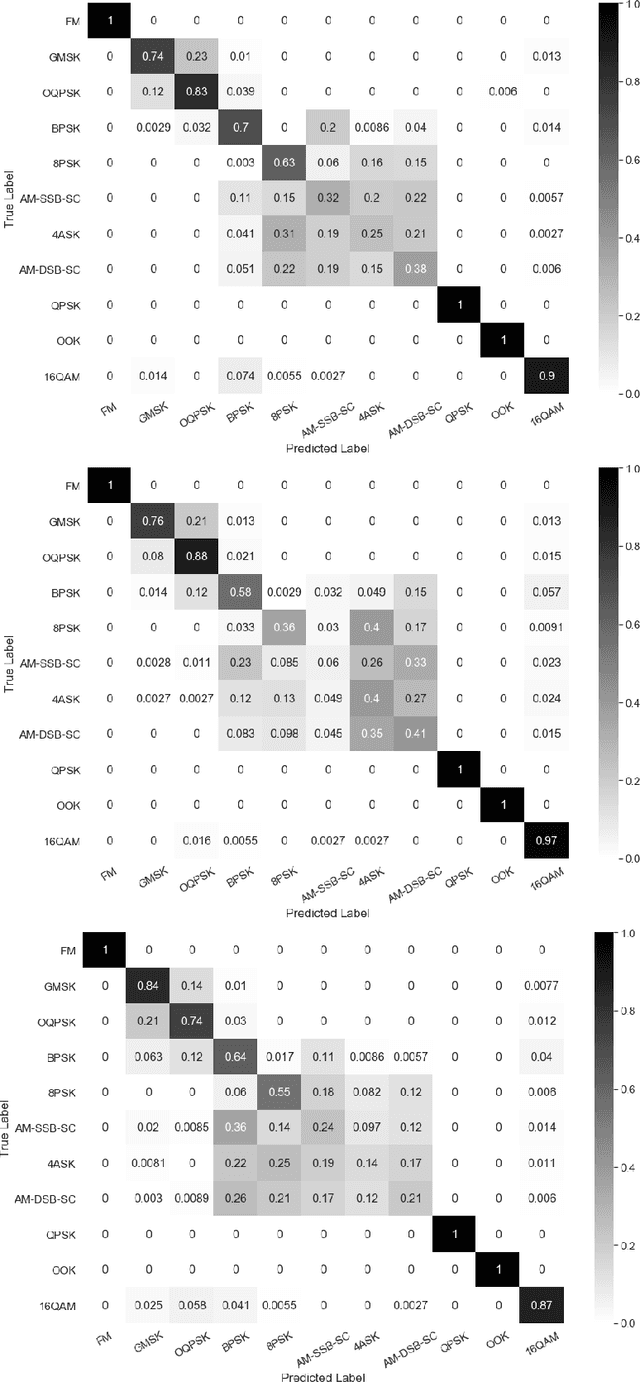
Identification of the type of communication technology and/or modulation scheme based on detected radio signal are challenging problems encountered in a variety of applications including spectrum allocation and radio interference mitigation. They are rendered difficult due to a growing number of emitter types and varied effects of real-world channels upon the radio signal. Existing spectrum monitoring techniques are capable of acquiring massive amounts of radio and real-time spectrum data using compact sensors deployed in a variety of settings. However, state-of-the-art methods that use such data to classify emitter types and detect communication schemes struggle to achieve required levels of accuracy at a computational efficiency that would allow their implementation on low-cost computational platforms. In this paper, we present a learning framework based on an LSTM denoising auto-encoder designed to automatically extract stable and robust features from noisy radio signals, and infer modulation or technology type using the learned features. The algorithm utilizes a compact neural network architecture readily implemented on a low-cost computational platform while exceeding state-of-the-art accuracy. Results on realistic synthetic as well as over-the-air radio data demonstrate that the proposed framework reliably and efficiently classifies received radio signals, often demonstrating superior performance compared to state-of-the-art methods.
A Study on Token Pruning for ColBERT
Dec 13, 2021
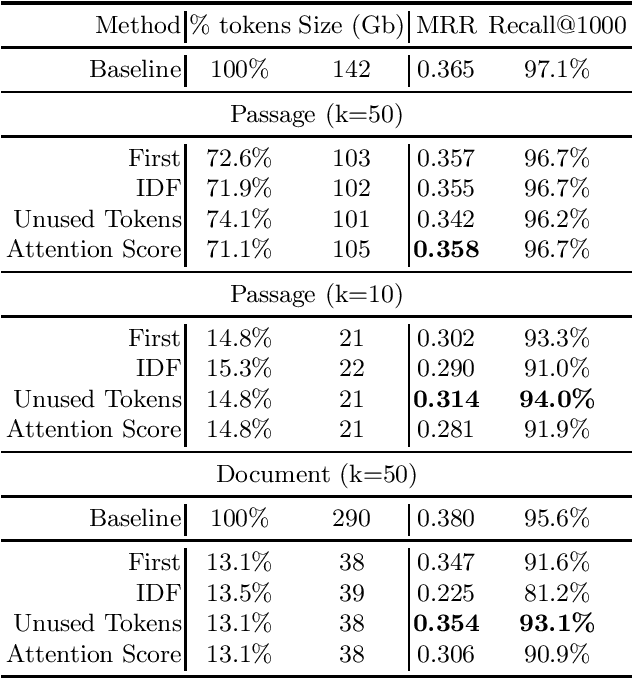
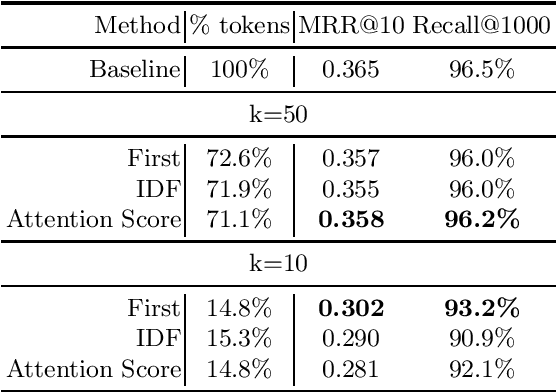
The ColBERT model has recently been proposed as an effective BERT based ranker. By adopting a late interaction mechanism, a major advantage of ColBERT is that document representations can be precomputed in advance. However, the big downside of the model is the index size, which scales linearly with the number of tokens in the collection. In this paper, we study various designs for ColBERT models in order to attack this problem. While compression techniques have been explored to reduce the index size, in this paper we study token pruning techniques for ColBERT. We compare simple heuristics, as well as a single layer of attention mechanism to select the tokens to keep at indexing time. Our experiments show that ColBERT indexes can be pruned up to 30\% on the MS MARCO passage collection without a significant drop in performance. Finally, we experiment on MS MARCO documents, which reveal several challenges for such mechanism.
Counterfactual Memorization in Neural Language Models
Dec 24, 2021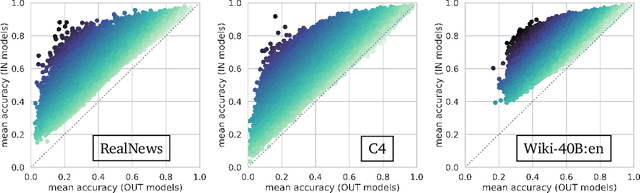
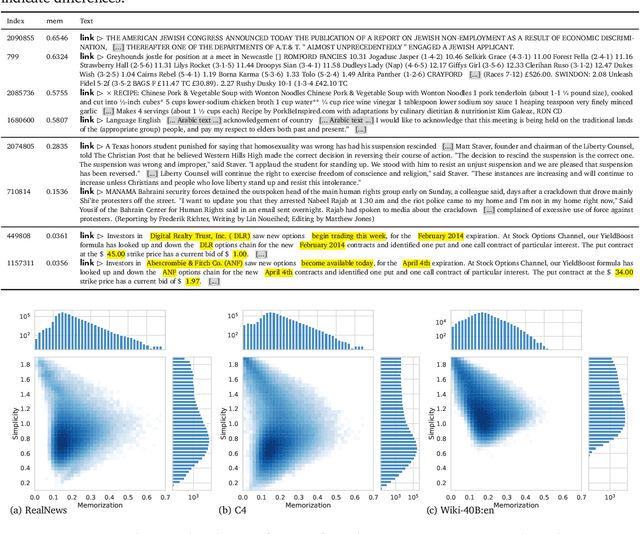

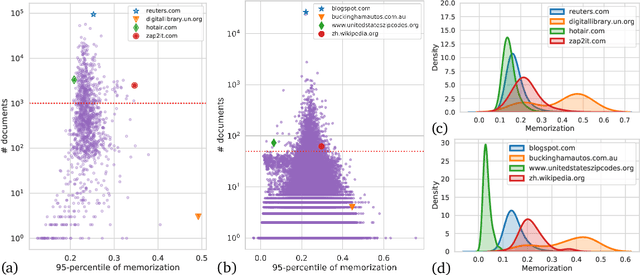
Modern neural language models widely used in tasks across NLP risk memorizing sensitive information from their training data. As models continue to scale up in parameters, training data, and compute, understanding memorization in language models is both important from a learning-theoretical point of view, and is practically crucial in real world applications. An open question in previous studies of memorization in language models is how to filter out "common" memorization. In fact, most memorization criteria strongly correlate with the number of occurrences in the training set, capturing "common" memorization such as familiar phrases, public knowledge or templated texts. In this paper, we provide a principled perspective inspired by a taxonomy of human memory in Psychology. From this perspective, we formulate a notion of counterfactual memorization, which characterizes how a model's predictions change if a particular document is omitted during training. We identify and study counterfactually-memorized training examples in standard text datasets. We further estimate the influence of each training example on the validation set and on generated texts, and show that this can provide direct evidence of the source of memorization at test time.
Scalable Dictionary Classifiers for Time Series Classification
Jul 26, 2019


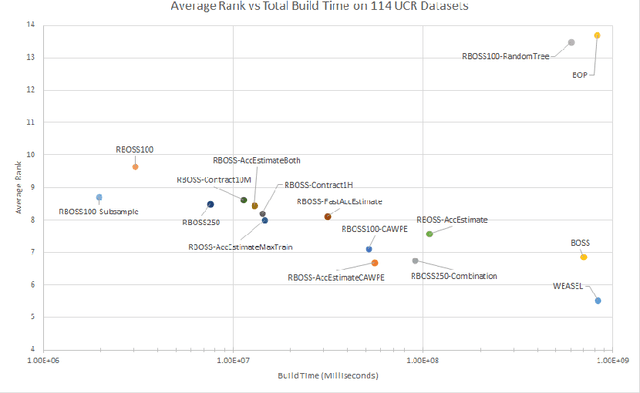
Dictionary based classifiers are a family of algorithms for time series classification (TSC), that focus on capturing the frequency of pattern occurrences in a time series. The ensemble based Bag of Symbolic Fourier Approximation Symbols (BOSS) was found to be a top performing TSC algorithm in a recent evaluation, as well as the best performing dictionary based classifier. A recent addition to the category, the Word Extraction for Time Series Classification (WEASEL), claims an improvement on this performance. Both of these algorithms however have non-trivial scalability issues, taking a considerable amount of build time and space on larger datasets. We evaluate changes to the way BOSS chooses classifiers for its ensemble, replacing its parameter search with random selection. This change allows for the easy implementation of contracting, setting a build time limit for the classifier and check-pointing, saving progress during the classifiers build. To differentiate between the two BOSS ensemble methods we refer to our randomised version as RBOSS. Additionally we test the application of common ensembling techniques to help retain accuracy from the loss of the BOSS parameter search. We achieve a significant reduction in build time without a significant change in accuracy on average when compared to BOSS by creating a size $n$ weighted ensemble selecting the best performers from $k$ randomly chosen parameter sets. Our experiments are conducted on datasets from the recently expanded UCR time series archive. We demonstrate the usability improvements to RBOSS with a case study using a large whale acoustics dataset for which BOSS proved infeasible.
Sparse Distillation: Speeding Up Text Classification by Using Bigger Models
Oct 16, 2021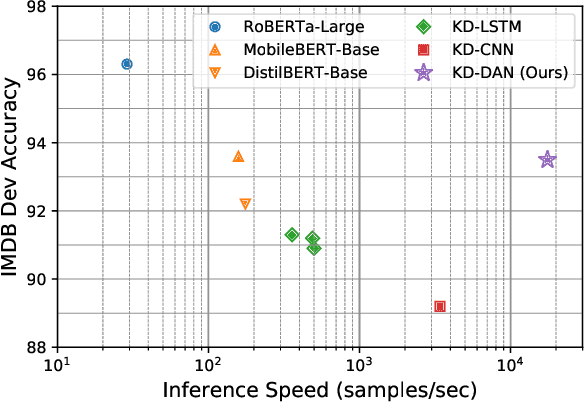
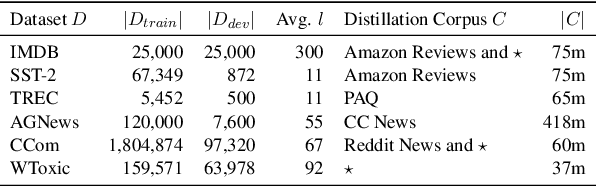
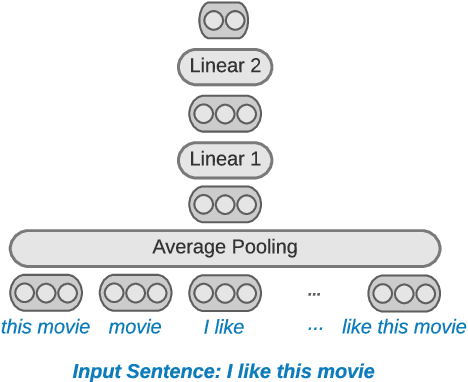
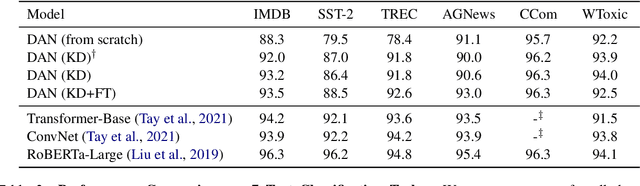
Distilling state-of-the-art transformer models into lightweight student models is an effective way to reduce computation cost at inference time. However, the improved inference speed may be still unsatisfactory for certain time-sensitive applications. In this paper, we aim to further push the limit of inference speed by exploring a new area in the design space of the student model. More specifically, we consider distilling a transformer-based text classifier into a billion-parameter, sparsely-activated student model with a embedding-averaging architecture. Our experiments show that the student models retain 97% of the RoBERTa-Large teacher performance on a collection of six text classification tasks. Meanwhile, the student model achieves up to 600x speed-up on both GPUs and CPUs, compared to the teacher models. Further investigation shows that our pipeline is also effective in privacy-preserving and domain generalization settings.
Transformer Networks for Data Augmentation of Human Physical Activity Recognition
Sep 04, 2021
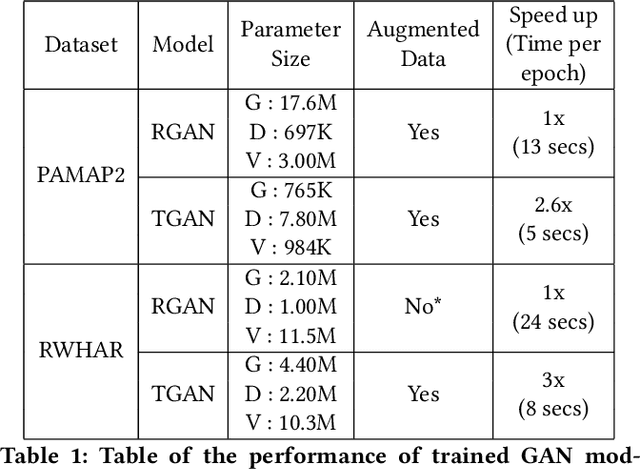
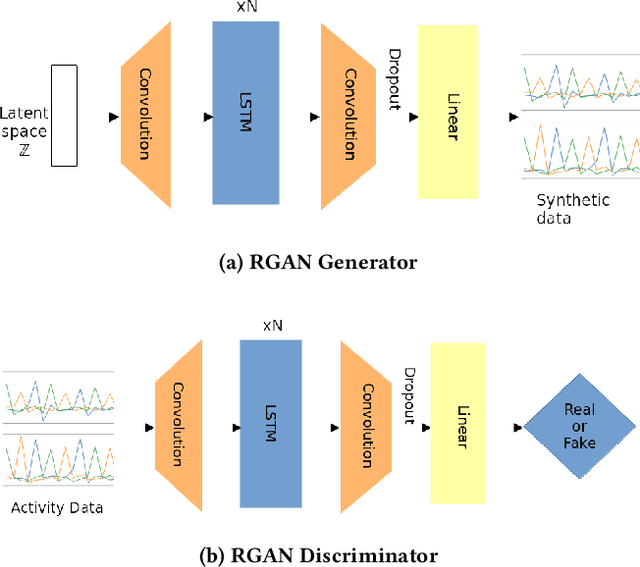
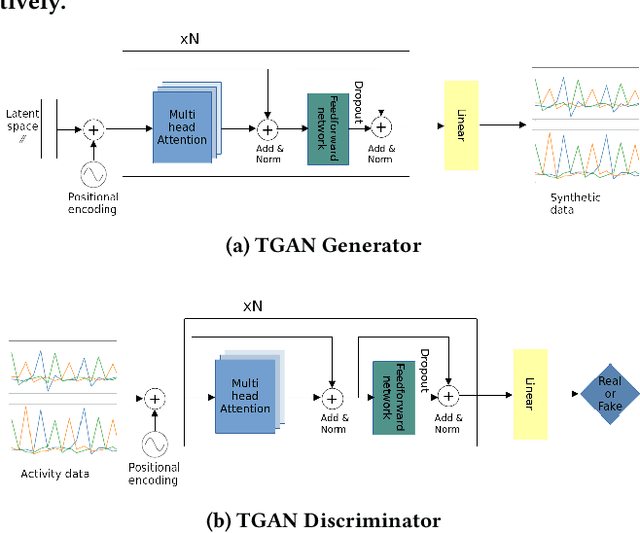
Data augmentation is a widely used technique in classification to increase data used in training. It improves generalization and reduces amount of annotated human activity data needed for training which reduces labour and time needed with the dataset. Sensor time-series data, unlike images, cannot be augmented by computationally simple transformation algorithms. State of the art models like Recurrent Generative Adversarial Networks (RGAN) are used to generate realistic synthetic data. In this paper, transformer based generative adversarial networks which have global attention on data, are compared on PAMAP2 and Real World Human Activity Recognition data sets with RGAN. The newer approach provides improvements in time and savings in computational resources needed for data augmentation than previous approach.