 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerating Fully Connected Neural Network on Optical Network-on-Chip (ONoC)
Sep 30, 2021
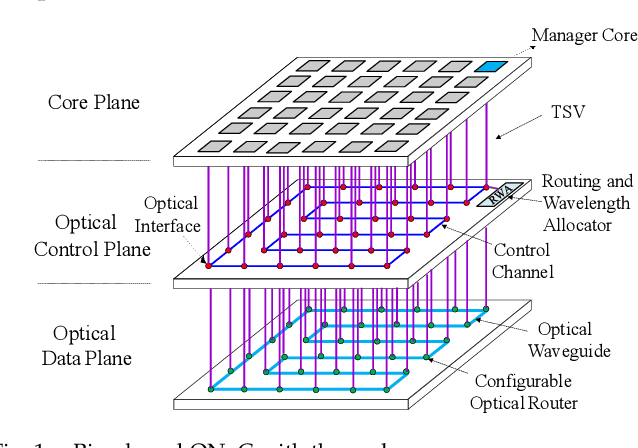

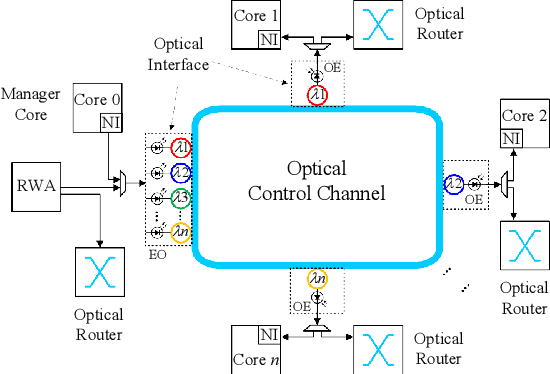
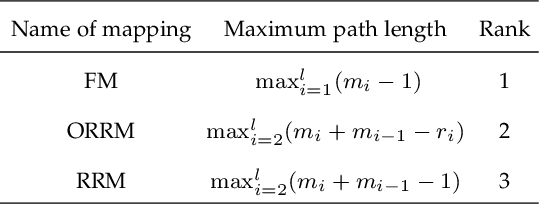
Fully Connected Neural Network (FCNN) is a class of Artificial Neural Networks widely used in computer science and engineering, whereas the training process can take a long time with large datasets in existing many-core systems. Optical Network-on-Chip (ONoC), an emerging chip-scale optical interconnection technology, has great potential to accelerate the training of FCNN with low transmission delay, low power consumption, and high throughput. However, existing methods based on Electrical Network-on-Chip (ENoC) cannot fit in ONoC because of the unique properties of ONoC. In this paper, we propose a fine-grained parallel computing model for accelerating FCNN training on ONoC and derive the optimal number of cores for each execution stage with the objective of minimizing the total amount of time to complete one epoch of FCNN training. To allocate the optimal number of cores for each execution stage, we present three mapping strategies and compare their advantages and disadvantages in terms of hotspot level, memory requirement, and state transitions. Simulation results show that the average prediction error for the optimal number of cores in NN benchmarks is within 2.3%. We further carry out extensive simulations which demonstrate that FCNN training time can be reduced by 22.28% and 4.91% on average using our proposed scheme, compared with traditional parallel computing methods that either allocate a fixed number of cores or allocate as many cores as possible, respectively. Compared with ENoC, simulation results show that under batch sizes of 64 and 128, on average ONoC can achieve 21.02% and 12.95% on reducing training time with 47.85% and 39.27% on saving energy, respectively.
WaveTTS: Tacotron-based TTS with Joint Time-Frequency Domain Loss
Feb 02, 2020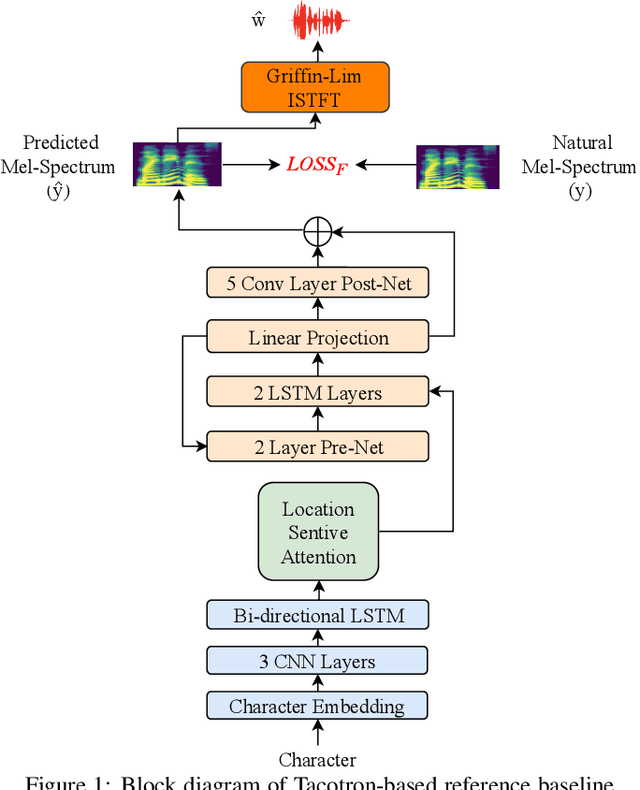

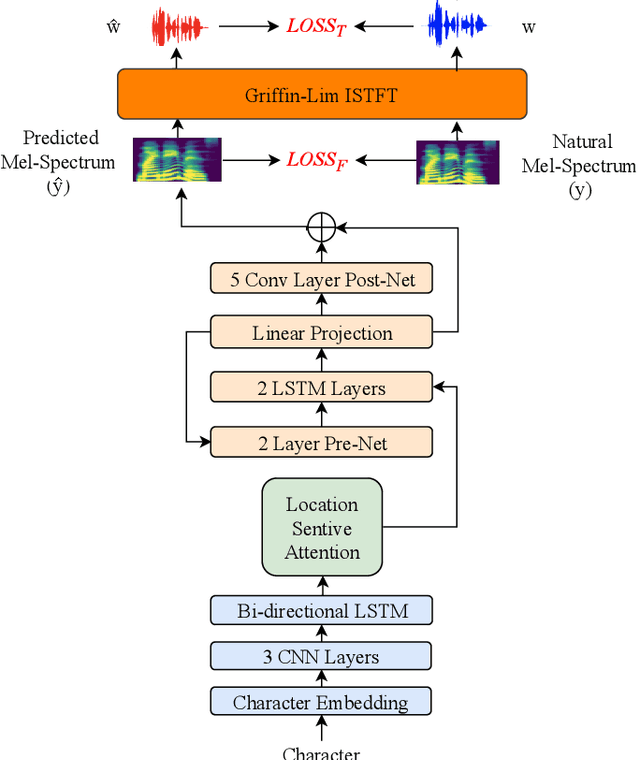
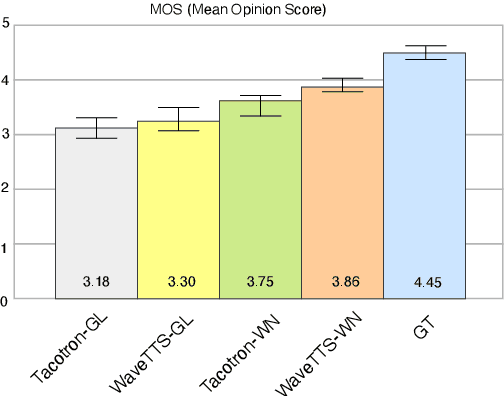
Tacotron-based text-to-speech (TTS) systems directly synthesize speech from text input. Such frameworks typically consist of a feature prediction network that maps character sequences to frequency-domain acoustic features, followed by a waveform reconstruction algorithm or a neural vocoder that generates the time-domain waveform from acoustic features. As the loss function is usually calculated only for frequency-domain acoustic features, that doesn't directly control the quality of the generated time-domain waveform. To address this problem, we propose a new training scheme for Tacotron-based TTS, referred to as WaveTTS, that has 2 loss functions: 1) time-domain loss, denoted as the waveform loss, that measures the distortion between the natural and generated waveform; and 2) frequency-domain loss, that measures the Mel-scale acoustic feature loss between the natural and generated acoustic features. WaveTTS ensures both the quality of the acoustic features and the resulting speech waveform. To our best knowledge, this is the first implementation of Tacotron with joint time-frequency domain loss. Experimental results show that the proposed framework outperforms the baselines and achieves high-quality synthesized speech.
Fish sounds: towards the evaluation of marine acoustic biodiversity through data-driven audio source separation
Jan 14, 2022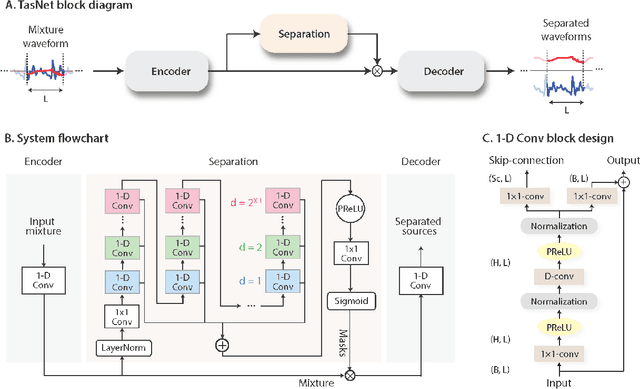
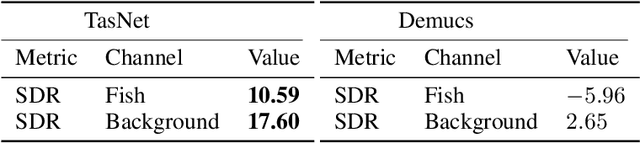
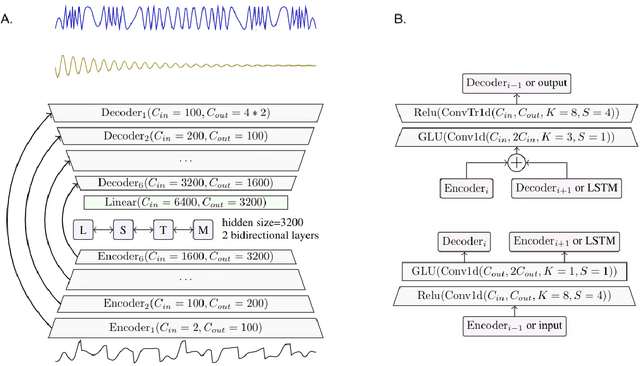
The marine ecosystem is changing at an alarming rate, exhibiting biodiversity loss and the migration of tropical species to temperate basins. Monitoring the underwater environments and their inhabitants is of fundamental importance to understand the evolution of these systems and implement safeguard policies. However, assessing and tracking biodiversity is often a complex task, especially in large and uncontrolled environments, such as the oceans. One of the most popular and effective methods for monitoring marine biodiversity is passive acoustics monitoring (PAM), which employs hydrophones to capture underwater sound. Many aquatic animals produce sounds characteristic of their own species; these signals travel efficiently underwater and can be detected even at great distances. Furthermore, modern technologies are becoming more and more convenient and precise, allowing for very accurate and careful data acquisition. To date, audio captured with PAM devices is frequently manually processed by marine biologists and interpreted with traditional signal processing techniques for the detection of animal vocalizations. This is a challenging task, as PAM recordings are often over long periods of time. Moreover, one of the causes of biodiversity loss is sound pollution; in data obtained from regions with loud anthropic noise, it is hard to separate the artificial from the fish sound manually. Nowadays, machine learning and, in particular, deep learning represents the state of the art for processing audio signals. Specifically, sound separation networks are able to identify and separate human voices and musical instruments. In this work, we show that the same techniques can be successfully used to automatically extract fish vocalizations in PAM recordings, opening up the possibility for biodiversity monitoring at a large scale.
Stochastic Saddle Point Problems with Decision-Dependent Distributions
Jan 07, 2022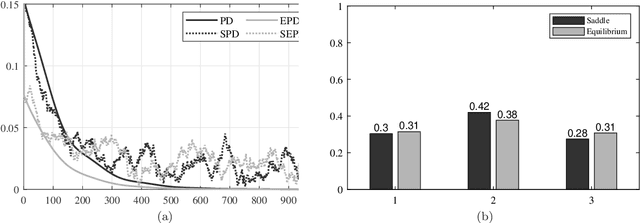
This paper focuses on stochastic saddle point problems with decision-dependent distributions in both the static and time-varying settings. These are problems whose objective is the expected value of a stochastic payoff function, where random variables are drawn from a distribution induced by a distributional map. For general distributional maps, the problem of finding saddle points is in general computationally burdensome, even if the distribution is known. To enable a tractable solution approach, we introduce the notion of equilibrium points -- which are saddle points for the stationary stochastic minimax problem that they induce -- and provide conditions for their existence and uniqueness. We demonstrate that the distance between the two classes of solutions is bounded provided that the objective has a strongly-convex-strongly-concave payoff and Lipschitz continuous distributional map. We develop deterministic and stochastic primal-dual algorithms and demonstrate their convergence to the equilibrium point. In particular, by modeling errors emerging from a stochastic gradient estimator as sub-Weibull random variables, we provide error bounds in expectation and in high probability that hold for each iteration; moreover, we show convergence to a neighborhood in expectation and almost surely. Finally, we investigate a condition on the distributional map -- which we call opposing mixture dominance -- that ensures the objective is strongly-convex-strongly-concave. Under this assumption, we show that primal-dual algorithms converge to the saddle points in a similar fashion.
Unsupervised Deep Representation Learning for Real-Time Tracking
Jul 22, 2020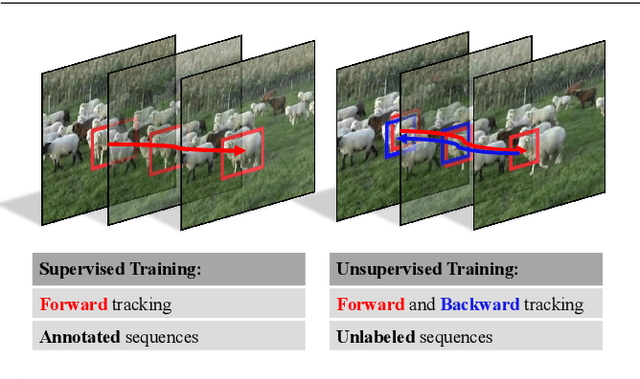
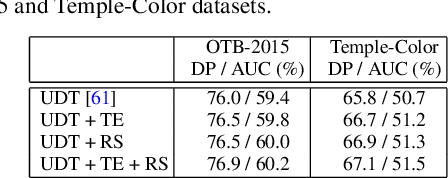
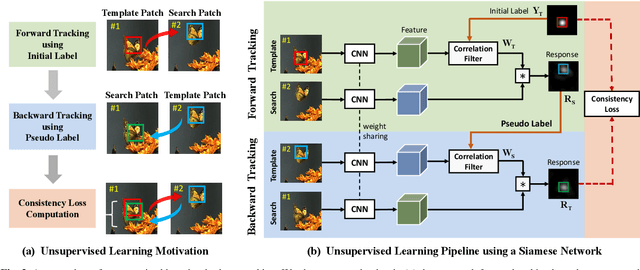
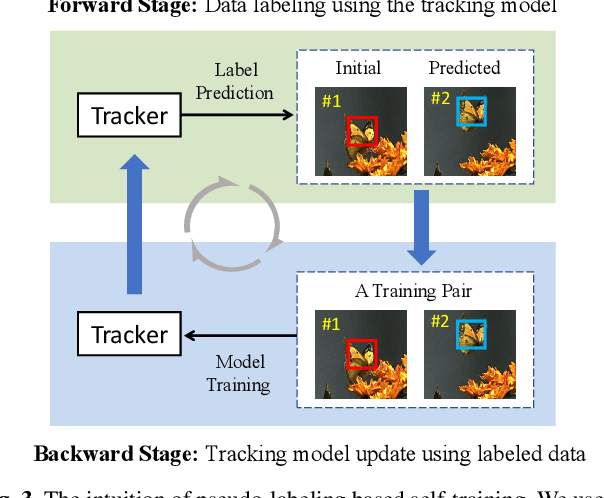
The advancement of visual tracking has continuously been brought by deep learning models. Typically, supervised learning is employed to train these models with expensive labeled data. In order to reduce the workload of manual annotations and learn to track arbitrary objects, we propose an unsupervised learning method for visual tracking. The motivation of our unsupervised learning is that a robust tracker should be effective in bidirectional tracking. Specifically, the tracker is able to forward localize a target object in successive frames and backtrace to its initial position in the first frame. Based on such a motivation, in the training process, we measure the consistency between forward and backward trajectories to learn a robust tracker from scratch merely using unlabeled videos. We build our framework on a Siamese correlation filter network, and propose a multi-frame validation scheme and a cost-sensitive loss to facilitate unsupervised learning. Without bells and whistles, the proposed unsupervised tracker achieves the baseline accuracy as classic fully supervised trackers while achieving a real-time speed. Furthermore, our unsupervised framework exhibits a potential in leveraging more unlabeled or weakly labeled data to further improve the tracking accuracy.
State Selection Algorithms and Their Impact on The Performance of Stateful Network Protocol Fuzzing
Dec 24, 2021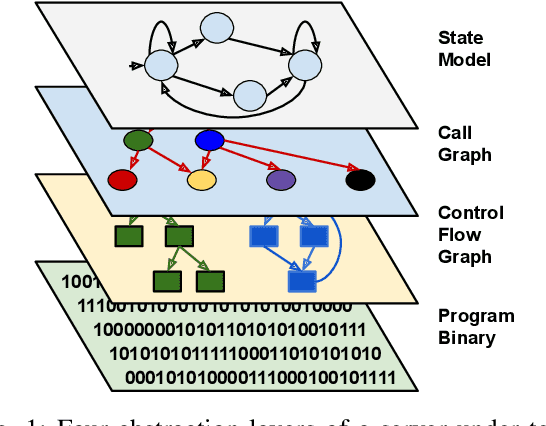
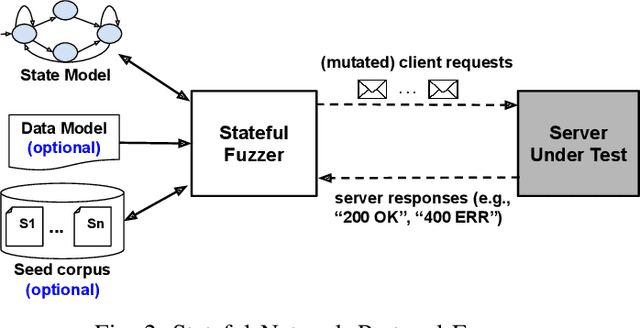
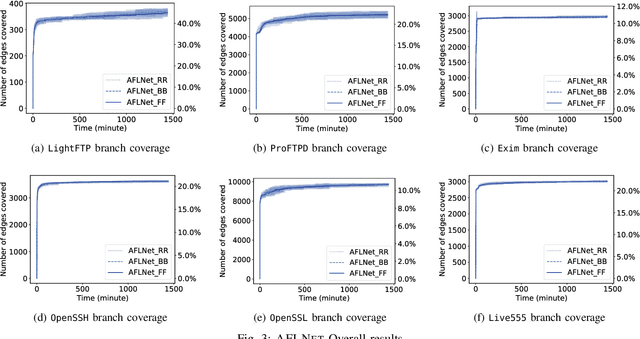

The statefulness property of network protocol implementations poses a unique challenge for testing and verification techniques, including Fuzzing. Stateful fuzzers tackle this challenge by leveraging state models to partition the state space and assist the test generation process. Since not all states are equally important and fuzzing campaigns have time limits, fuzzers need effective state selection algorithms to prioritize progressive states over others. Several state selection algorithms have been proposed but they were implemented and evaluated separately on different platforms, making it hard to achieve conclusive findings. In this work, we evaluate an extensive set of state selection algorithms on the same fuzzing platform that is AFLNet, a state-of-the-art fuzzer for network servers. The algorithm set includes existing ones supported by AFLNet and our novel and principled algorithm called AFLNetLegion. The experimental results on the ProFuzzBench benchmark show that (i) the existing state selection algorithms of AFLNet achieve very similar code coverage, (ii) AFLNetLegion clearly outperforms these algorithms in selected case studies, but (iii) the overall improvement appears insignificant. These are unexpected yet interesting findings. We identify problems and share insights that could open opportunities for future research on this topic.
Adversarial Attacks on Time Series
Mar 01, 2019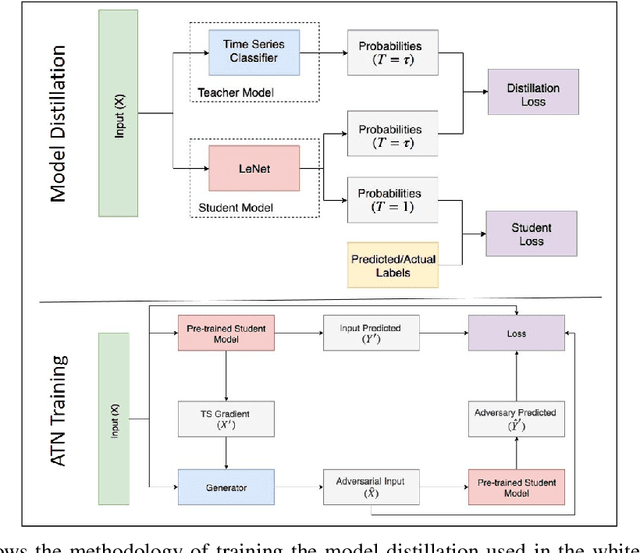
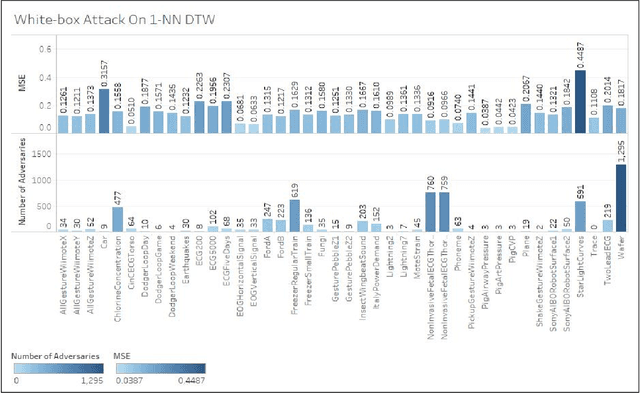
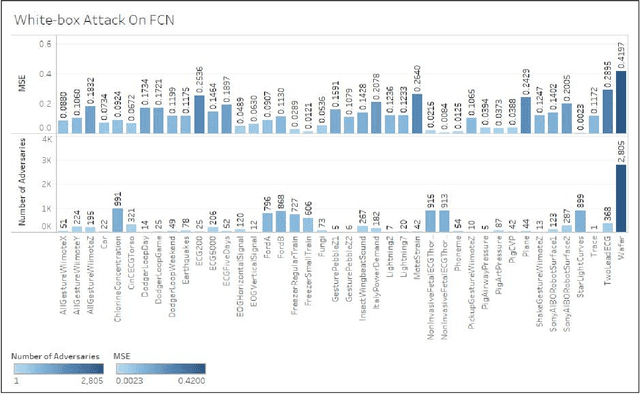
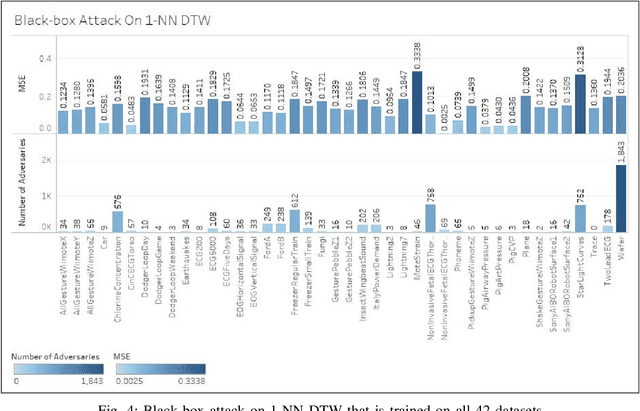
Time series classification models have been garnering significant importance in the research community. However, not much research has been done on generating adversarial samples for these models. These adversarial samples can become a security concern. In this paper, we propose utilizing an adversarial transformation network (ATN) on a distilled model to attack various time series classification models. The proposed attack on the classification model utilizes a distilled model as a surrogate that mimics the behavior of the attacked classical time series classification models. Our proposed methodology is applied onto 1-Nearest Neighbor Dynamic Time Warping (1-NN ) DTW, a Fully Connected Network and a Fully Convolutional Network (FCN), all of which are trained on 42 University of California Riverside (UCR) datasets. In this paper, we show both models were susceptible to attacks on all 42 datasets. To the best of our knowledge, such an attack on time series classification models has never been done before. Finally, we recommend future researchers that develop time series classification models to incorporating adversarial data samples into their training data sets to improve resilience on adversarial samples and to consider model robustness as an evaluative metric.
Object-Independent Human-to-Robot Handovers using Real Time Robotic Vision
Jun 02, 2020
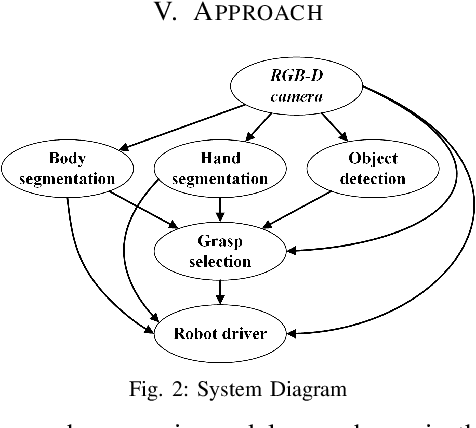
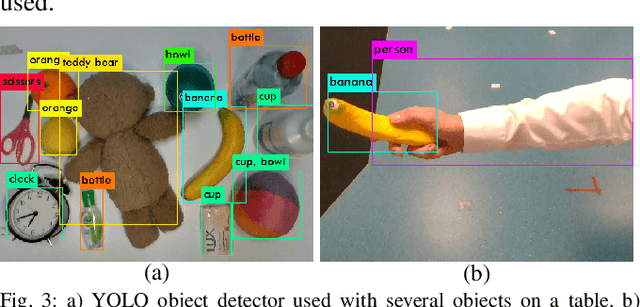

We present an approach for safe and object-independent human-to-robot handovers using real time robotic vision and manipulation. We aim for general applicability with a generic object detector, a fast grasp selection algorithm and by using a single gripper-mounted RGB-D camera, hence not relying on external sensors. The robot is controlled via visual servoing towards the object of interest. Putting a high emphasis on safety, we use two perception modules: human body part segmentation and hand/finger segmentation. Pixels that are deemed to belong to the human are filtered out from candidate grasp poses, hence ensuring that the robot safely picks the object without colliding with the human partner. The grasp selection and perception modules run concurrently in real-time, which allows monitoring of the progress. In experiments with 13 objects, the robot was able to successfully take the object from the human in 81.9% of the trials.
Lightweight Speech Enhancement in Unseen Noisy and Reverberant Conditions using KISS-GEV Beamforming
Oct 10, 2021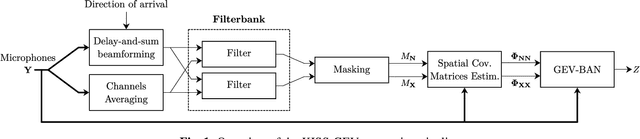
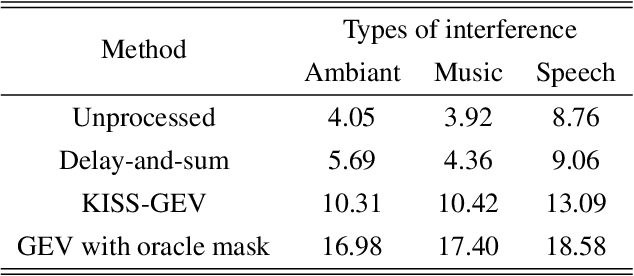
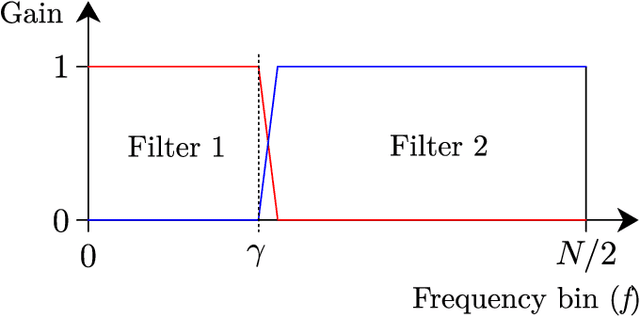
This paper introduces a new method referred to as KISS-GEV (for Keep It Super Simple Generalized eigenvalue) beamforming. While GEV beamforming usually relies on deep neural network for estimating target and noise time-frequency masks, this method uses a signal processing approach based on the direction of arrival (DoA) of the target. This considerably reduces the amount of computations involved at test time, and works for speech enhancement in unseen conditions as there is no need to train a neural network with noisy speech. The proposed method can also be used to separate speech from a mixture, provided the speech sources come from different directions. Results also show that the proposed method uses the same minimal DoA assumption as Delay-and-Sum beamforming, yet outperforms this traditional approach.
KryptoOracle: A Real-Time Cryptocurrency Price Prediction Platform Using Twitter Sentiments
Feb 21, 2020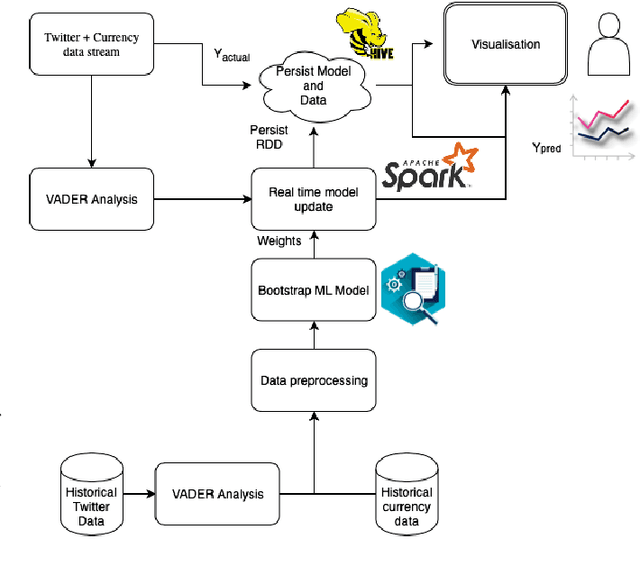
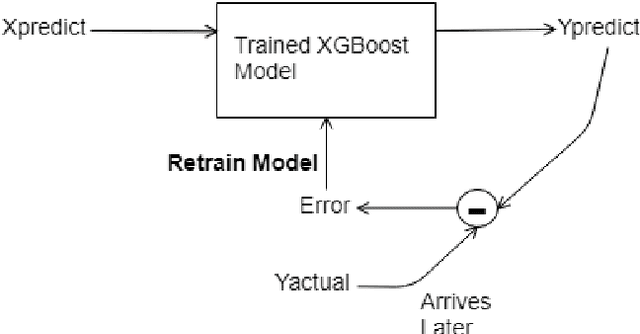
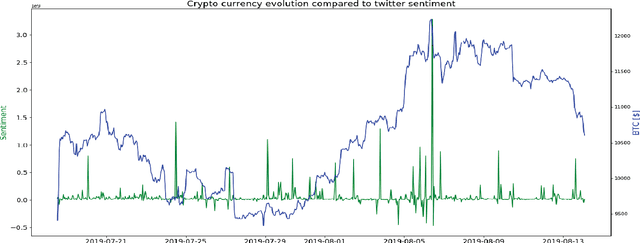
Cryptocurrencies, such as Bitcoin, are becoming increasingly popular, having been widely used as an exchange medium in areas such as financial transaction and asset transfer verification. However, there has been a lack of solutions that can support real-time price prediction to cope with high currency volatility, handle massive heterogeneous data volumes, including social media sentiments, while supporting fault tolerance and persistence in real time, and provide real-time adaptation of learning algorithms to cope with new price and sentiment data. In this paper we introduce KryptoOracle, a novel real-time and adaptive cryptocurrency price prediction platform based on Twitter sentiments. The integrative and modular platform is based on (i) a Spark-based architecture which handles the large volume of incoming data in a persistent and fault tolerant way; (ii) an approach that supports sentiment analysis which can respond to large amounts of natural language processing queries in real time; and (iii) a predictive method grounded on online learning in which a model adapts its weights to cope with new prices and sentiments. Besides providing an architectural design, the paper also describes the KryptoOracle platform implementation and experimental evaluation. Overall, the proposed platform can help accelerate decision-making, uncover new opportunities and provide more timely insights based on the available and ever-larger financial data volume and variety.