 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Memory Networks with Self-supervised Learning for Unsupervised Anomaly Detection
Jan 03, 2022
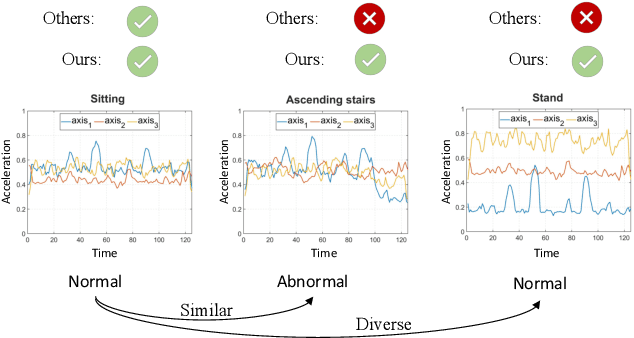

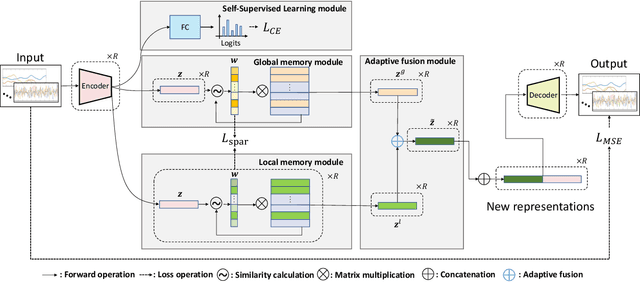
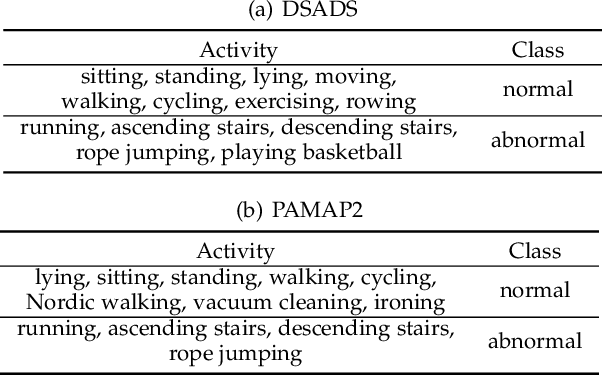
Unsupervised anomaly detection aims to build models to effectively detect unseen anomalies by only training on the normal data. Although previous reconstruction-based methods have made fruitful progress, their generalization ability is limited due to two critical challenges. First, the training dataset only contains normal patterns, which limits the model generalization ability. Second, the feature representations learned by existing models often lack representativeness which hampers the ability to preserve the diversity of normal patterns. In this paper, we propose a novel approach called Adaptive Memory Network with Self-supervised Learning (AMSL) to address these challenges and enhance the generalization ability in unsupervised anomaly detection. Based on the convolutional autoencoder structure, AMSL incorporates a self-supervised learning module to learn general normal patterns and an adaptive memory fusion module to learn rich feature representations. Experiments on four public multivariate time series datasets demonstrate that AMSL significantly improves the performance compared to other state-of-the-art methods. Specifically, on the largest CAP sleep stage detection dataset with 900 million samples, AMSL outperforms the second-best baseline by \textbf{4}\%+ in both accuracy and F1 score. Apart from the enhanced generalization ability, AMSL is also more robust against input noise.
Arrhythmia Classification using CGAN-augmented ECG Signals
Jan 26, 2022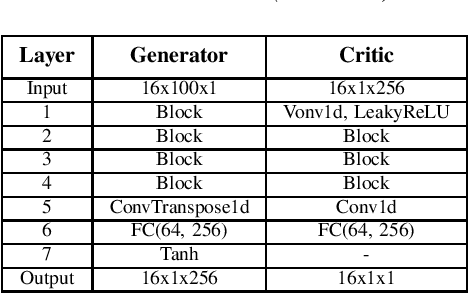
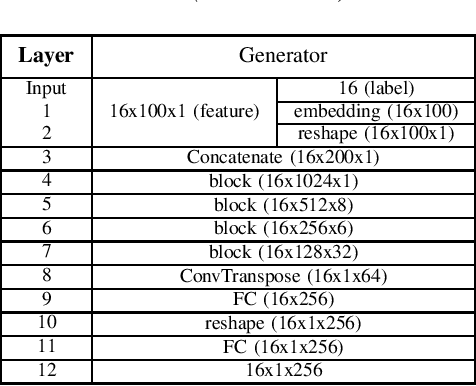
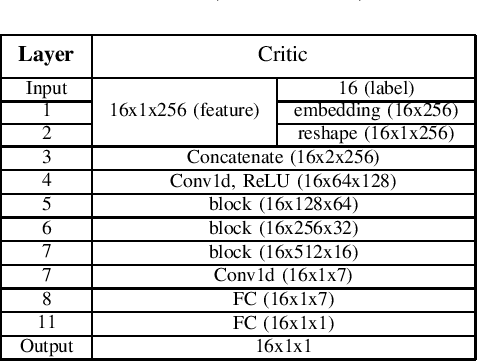
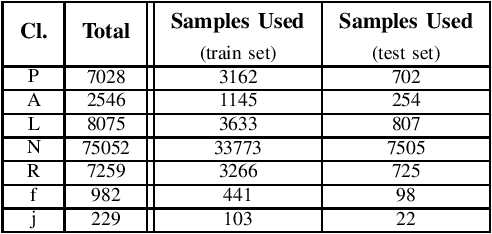
One of the easiest ways to diagnose cardiovascular conditions is Electrocardiogram (ECG) analysis. ECG databases usually have highly imbalanced distributions due to the abundance of Normal ECG and scarcity of abnormal cases which are equally, if not more, important for arrhythmia detection. As such, DL classifiers trained on these datasets usually perform poorly, especially on minor classes. One solution to address the imbalance is to generate realistic synthetic ECG signals mostly using Generative Adversarial Networks (GAN) to augment and the datasets. In this study, we designed an experiment to investigate the impact of data augmentation on arrhythmia classification. Using the MIT-BIH Arrhythmia dataset, we employed two ways for ECG beats generation: (i) an unconditional GAN, i.e., Wasserstein GAN with gradient penalty (WGAN-GP) is trained on each class individually; (ii) a conditional GAN model, i.e., Auxiliary Classifier Wasserstein GAN with gradient penalty (AC-WGAN-GP) is trained on all the available classes to train one single generator. Two scenarios are defined for each case: i) unscreened where all the generated synthetic beats were used directly without any post-processing, and ii) screened where a portion of generated beats are selected based on their Dynamic Time Warping (DTW) distance with a designated template. A ResNet classifier is trained on each of the four augmented datasets and the performance metrics of precision, recall and F1-Score as well as the confusion matrices were compared with the reference case, i.e., when the classifier is trained on the imbalanced original dataset. The results show that in all four cases augmentation achieves impressive improvements in metrics particularly on minor classes (typically from 0 or 0.27 to 0.99). The quality of the generated beats is also evaluated using DTW distance function compared with real data.
Lightweight Object-level Topological Semantic Mapping and Long-term Global Localization based on Graph Matching
Jan 16, 2022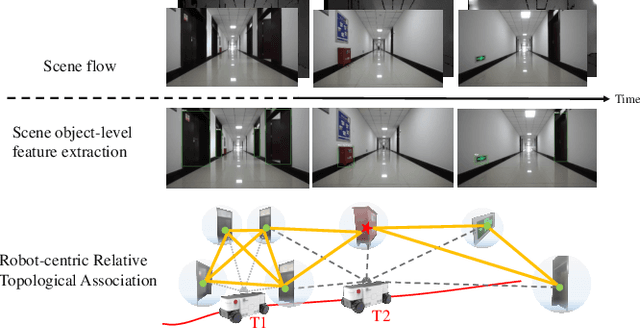

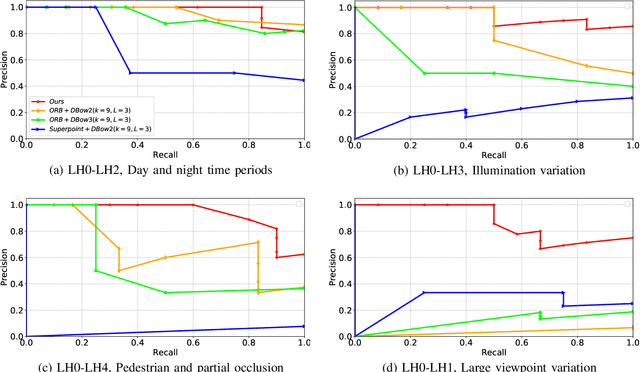
Mapping and localization are two essential tasks for mobile robots in real-world applications. However, largescale and dynamic scenes challenge the accuracy and robustness of most current mature solutions. This situation becomes even worse when computational resources are limited. In this paper, we present a novel lightweight object-level mapping and localization method with high accuracy and robustness. Different from previous methods, our method does not need a prior constructed precise geometric map, which greatly releases the storage burden, especially for large-scale navigation. We use object-level features with both semantic and geometric information to model landmarks in the environment. Particularly, a learning topological primitive is first proposed to efficiently obtain and organize the object-level landmarks. On the basis of this, we use a robot-centric mapping framework to represent the environment as a semantic topology graph and relax the burden of maintaining global consistency at the same time. Besides, a hierarchical memory management mechanism is introduced to improve the efficiency of online mapping with limited computational resources. Based on the proposed map, the robust localization is achieved by constructing a novel local semantic scene graph descriptor, and performing multi-constraint graph matching to compare scene similarity. Finally, we test our method on a low-cost embedded platform to demonstrate its advantages. Experimental results on a large scale and multi-session real-world environment show that the proposed method outperforms the state of arts in terms of lightweight and robustness.
Computational Lens on Cognition: Study Of Autobiographical Versus Imagined Stories With Large-Scale Language Models
Jan 07, 2022
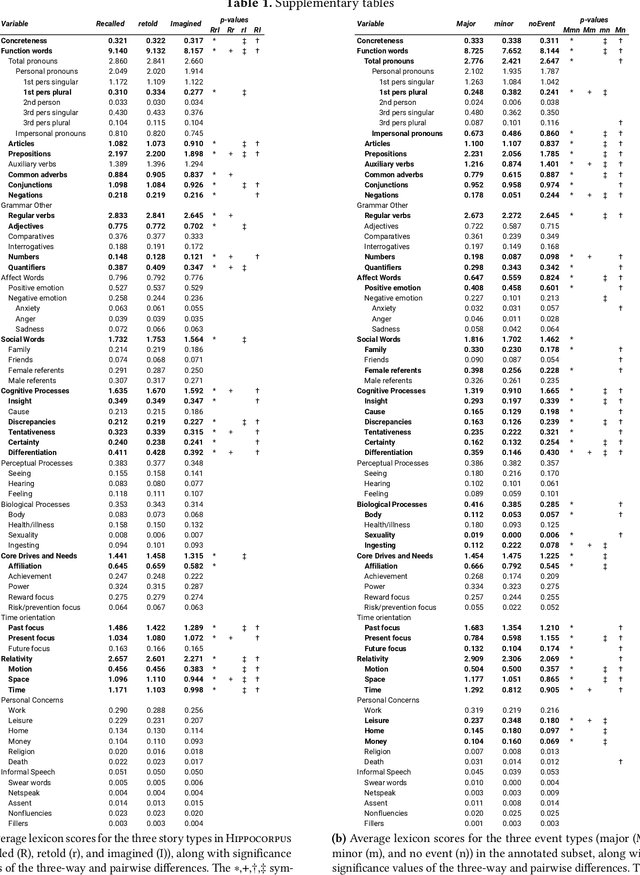
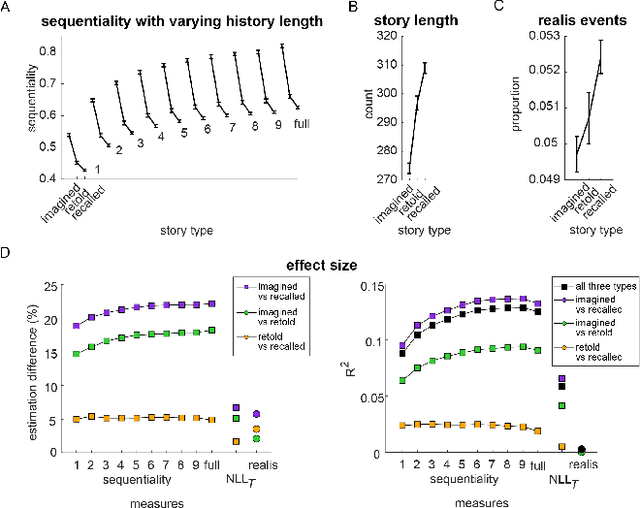
Lifelong experiences and learned knowledge lead to shared expectations about how common situations tend to unfold. Such knowledge enables people to interpret story narratives and identify salient events effortlessly. We study differences in the narrative flow of events in autobiographical versus imagined stories using GPT-3, one of the largest neural language models created to date. The diary-like stories were written by crowdworkers about either a recently experienced event or an imagined event on the same topic. To analyze the narrative flow of events of these stories, we measured sentence *sequentiality*, which compares the probability of a sentence with and without its preceding story context. We found that imagined stories have higher sequentiality than autobiographical stories, and that the sequentiality of autobiographical stories is higher when they are retold than when freshly recalled. Through an annotation of events in story sentences, we found that the story types contain similar proportions of major salient events, but that the autobiographical stories are denser in factual minor events. Furthermore, in comparison to imagined stories, autobiographical stories contain more concrete words and words related to the first person, cognitive processes, time, space, numbers, social words, and core drives and needs. Our findings highlight the opportunity to investigate memory and cognition with large-scale statistical language models.
MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound
Jan 07, 2022
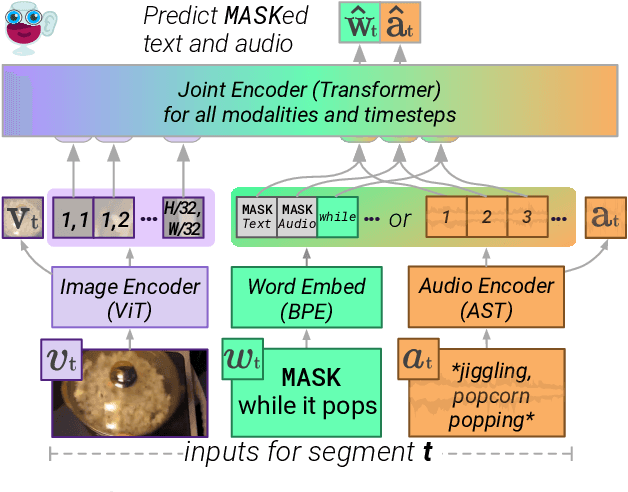

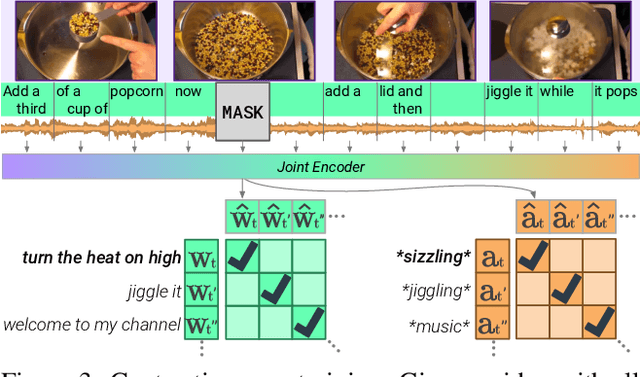
As humans, we navigate the world through all our senses, using perceptual input from each one to correct the others. We introduce MERLOT Reserve, a model that represents videos jointly over time -- through a new training objective that learns from audio, subtitles, and video frames. Given a video, we replace snippets of text and audio with a MASK token; the model learns by choosing the correct masked-out snippet. Our objective learns faster than alternatives, and performs well at scale: we pretrain on 20 million YouTube videos. Empirical results show that MERLOT Reserve learns strong representations about videos through all constituent modalities. When finetuned, it sets a new state-of-the-art on both VCR and TVQA, outperforming prior work by 5% and 7% respectively. Ablations show that both tasks benefit from audio pretraining -- even VCR, a QA task centered around images (without sound). Moreover, our objective enables out-of-the-box prediction, revealing strong multimodal commonsense understanding. In a fully zero-shot setting, our model obtains competitive results on four video understanding tasks, even outperforming supervised approaches on the recently proposed Situated Reasoning (STAR) benchmark. We analyze why incorporating audio leads to better vision-language representations, suggesting significant opportunities for future research. We conclude by discussing ethical and societal implications of multimodal pretraining.
Detecting Twenty-thousand Classes using Image-level Supervision
Jan 07, 2022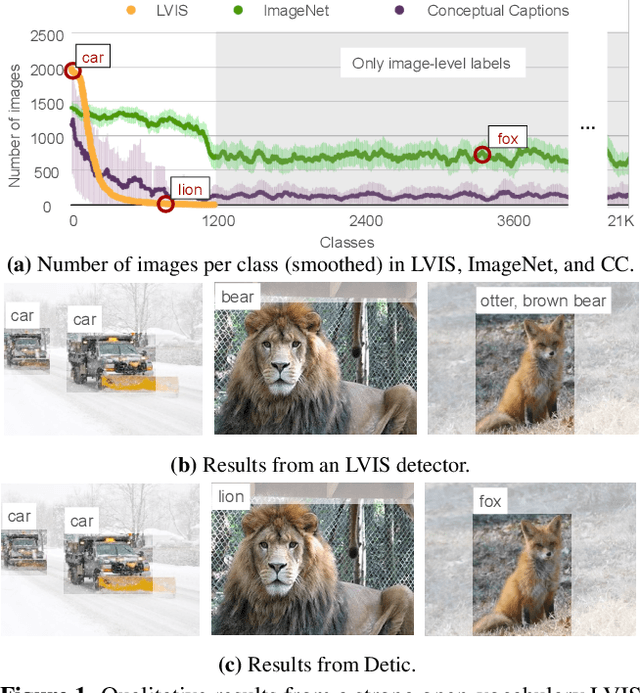
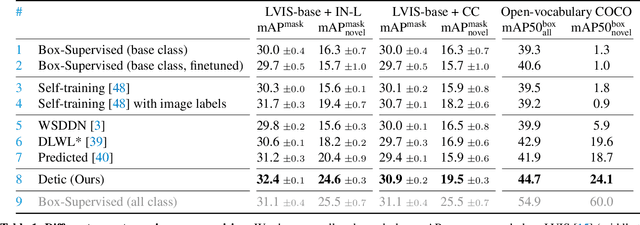


Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets are larger and easier to collect. We propose Detic, which simply trains the classifiers of a detector on image classification data and thus expands the vocabulary of detectors to tens of thousands of concepts. Unlike prior work, Detic does not assign image labels to boxes based on model predictions, making it much easier to implement and compatible with a range of detection architectures and backbones. Our results show that Detic yields excellent detectors even for classes without box annotations. It outperforms prior work on both open-vocabulary and long-tail detection benchmarks. Detic provides a gain of 2.4 mAP for all classes and 8.3 mAP for novel classes on the open-vocabulary LVIS benchmark. On the standard LVIS benchmark, Detic reaches 41.7 mAP for all classes and 41.7 mAP for rare classes. For the first time, we train a detector with all the twenty-one-thousand classes of the ImageNet dataset and show that it generalizes to new datasets without fine-tuning. Code is available at https://github.com/facebookresearch/Detic.
FRIDA -- Generative Feature Replay for Incremental Domain Adaptation
Dec 28, 2021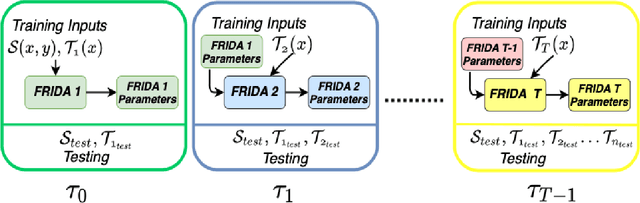

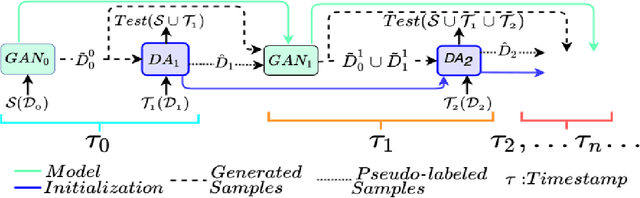
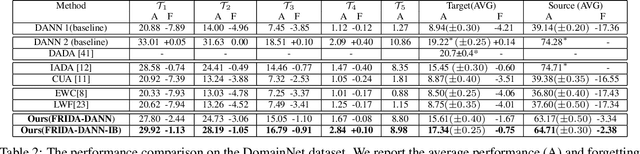
We tackle the novel problem of incremental unsupervised domain adaptation (IDA) in this paper. We assume that a labeled source domain and different unlabeled target domains are incrementally observed with the constraint that data corresponding to the current domain is only available at a time. The goal is to preserve the accuracies for all the past domains while generalizing well for the current domain. The IDA setup suffers due to the abrupt differences among the domains and the unavailability of past data including the source domain. Inspired by the notion of generative feature replay, we propose a novel framework called Feature Replay based Incremental Domain Adaptation (FRIDA) which leverages a new incremental generative adversarial network (GAN) called domain-generic auxiliary classification GAN (DGAC-GAN) for producing domain-specific feature representations seamlessly. For domain alignment, we propose a simple extension of the popular domain adversarial neural network (DANN) called DANN-IB which encourages discriminative domain-invariant and task-relevant feature learning. Experimental results on Office-Home, Office-CalTech, and DomainNet datasets confirm that FRIDA maintains superior stability-plasticity trade-off than the literature.
Enhancement of Healthcare Data Performance Metrics using Neural Network Machine Learning Algorithms
Jan 16, 2022Patients are often encouraged to make use of wearable devices for remote collection and monitoring of health data. This adoption of wearables results in a significant increase in the volume of data collected and transmitted. The battery life of the devices is then quickly diminished due to the high processing requirements of the devices. Given the importance attached to medical data, it is imperative that all transmitted data adhere to strict integrity and availability requirements. Reducing the volume of healthcare data for network transmission may improve sensor battery life without compromising accuracy. There is a trade-off between efficiency and accuracy which can be controlled by adjusting the sampling and transmission rates. This paper demonstrates that machine learning can be used to analyse complex health data metrics such as the accuracy and efficiency of data transmission to overcome the trade-off problem. The study uses time series nonlinear autoregressive neural network algorithms to enhance both data metrics by taking fewer samples to transmit. The algorithms were tested with a standard heart rate dataset to compare their accuracy and efficiency. The result showed that the Levenbery-Marquardt algorithm was the best performer with an efficiency of 3.33 and accuracy of 79.17%, which is similar to other algorithms accuracy but demonstrates improved efficiency. This proves that machine learning can improve without sacrificing a metric over the other compared to the existing methods with high efficiency.
Phoebe: A Learning-based Checkpoint Optimizer
Oct 05, 2021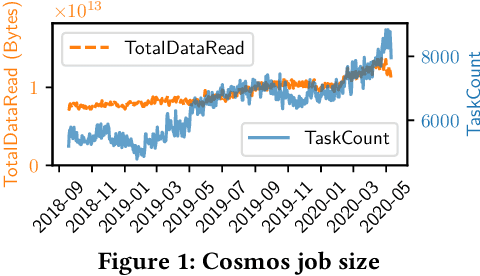
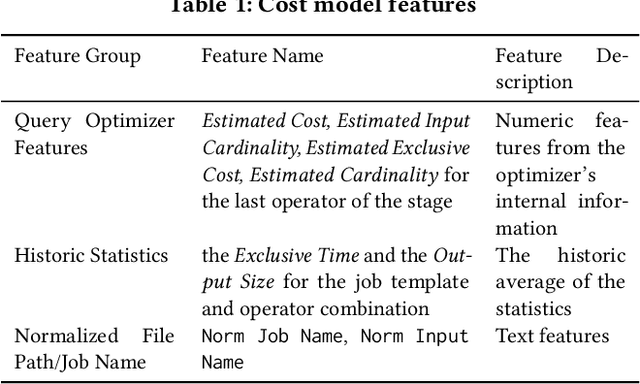

Easy-to-use programming interfaces paired with cloud-scale processing engines have enabled big data system users to author arbitrarily complex analytical jobs over massive volumes of data. However, as the complexity and scale of analytical jobs increase, they encounter a number of unforeseen problems, hotspots with large intermediate data on temporary storage, longer job recovery time after failures, and worse query optimizer estimates being examples of issues that we are facing at Microsoft. To address these issues, we propose Phoebe, an efficient learning-based checkpoint optimizer. Given a set of constraints and an objective function at compile-time, Phoebe is able to determine the decomposition of job plans, and the optimal set of checkpoints to preserve their outputs to durable global storage. Phoebe consists of three machine learning predictors and one optimization module. For each stage of a job, Phoebe makes accurate predictions for: (1) the execution time, (2) the output size, and (3) the start/end time taking into account the inter-stage dependencies. Using these predictions, we formulate checkpoint optimization as an integer programming problem and propose a scalable heuristic algorithm that meets the latency requirement of the production environment. We demonstrate the effectiveness of Phoebe in production workloads, and show that we can free the temporary storage on hotspots by more than 70% and restart failed jobs 68% faster on average with minimum performance impact. Phoebe also illustrates that adding multiple sets of checkpoints is not cost-efficient, which dramatically reduces the complexity of the optimization.
Time Series to Images: Monitoring the Condition of Industrial Assets with Deep Learning Image Processing Algorithms
May 14, 2020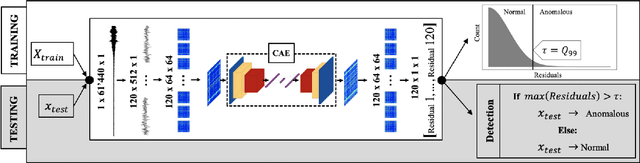
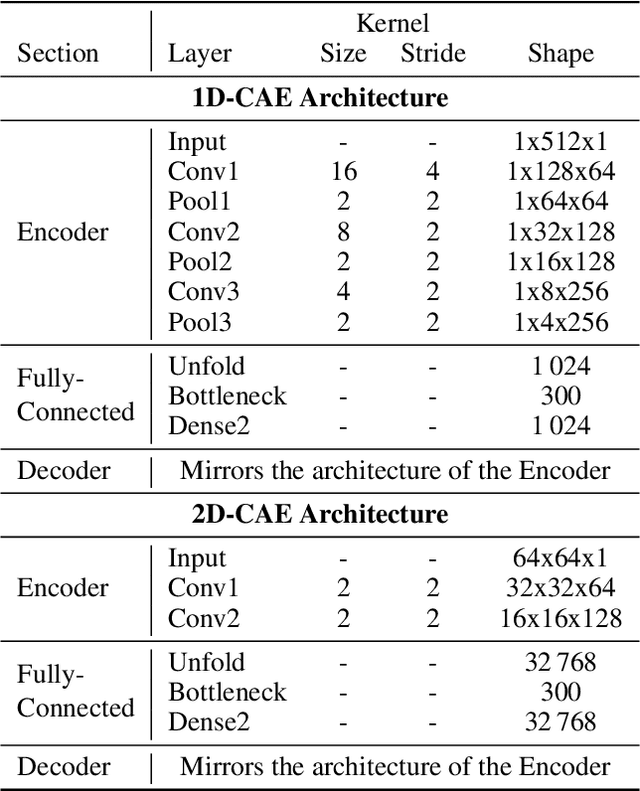
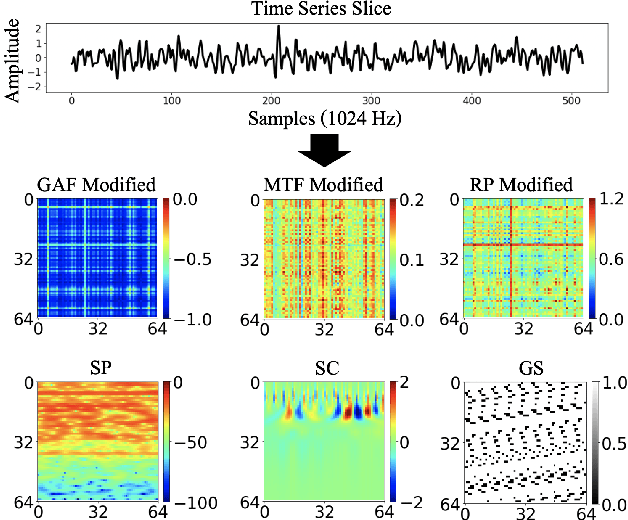
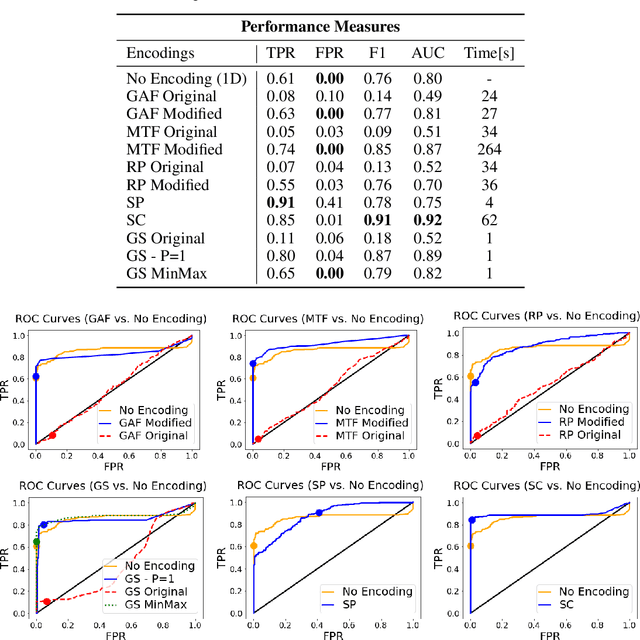
The ability to detect anomalies in time series is considered as highly valuable within plenty of application domains. The sequential nature of time series objects is responsible for an additional feature complexity, ultimately requiring specialized approaches for solving the task. Essential characteristics of time series, laying outside the time domain, are often difficult to capture with state-of-the-art anomaly detection methods, when no transformations on the time series have been applied. Inspired by the success of deep learning methods in computer vision, several studies have proposed to transform time-series into image-like representations, leading to very promising results. However, most of the previous studies implementing time-series to image encodings have focused on the supervised classification. The application to unsupervised anomaly detection tasks has been limited. The paper has the following contributions: First, we evaluate the application of six time-series to image encodings to DL algorithms: Gramian Angular Field, Markov Transition Field, Recurrence Plot, Grey Scale Encoding, Spectrogram and Scalogram. Second, we propose modifications of the original encoding definitions, to make them more robust to the variability in large datasets. And third, we provide a comprehensive comparison between using the raw time series directly and the different encodings, with and without the proposed improvements. The comparison is performed on a dataset collected and released by Airbus, containing highly complex vibration measurements from real helicopters flight tests. The different encodings provide competitive results for anomaly detection.