 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross-Lingual Citations in English Papers: A Large-Scale Analysis of Prevalence, Usage, and Impact
Nov 10, 2021
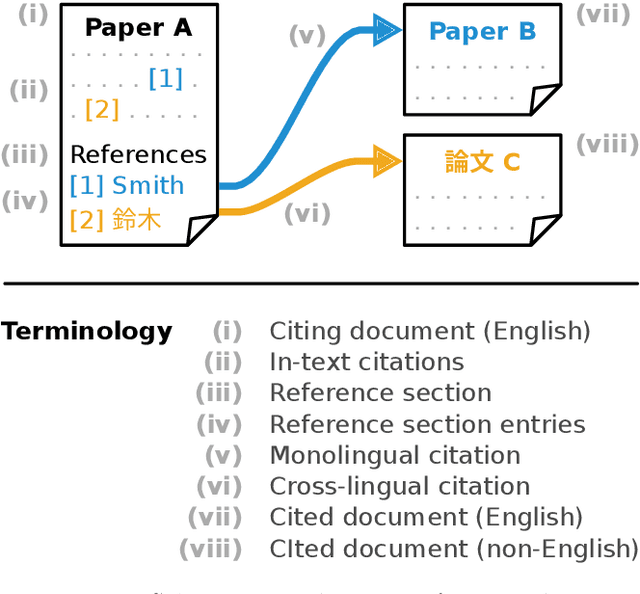

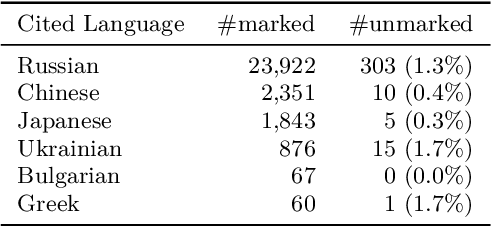
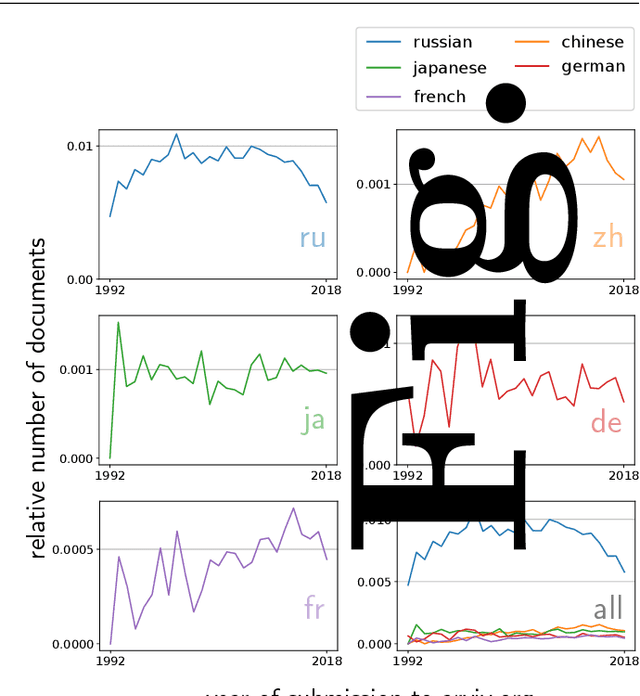
Citation information in scholarly data is an important source of insight into the reception of publications and the scholarly discourse. Outcomes of citation analyses and the applicability of citation based machine learning approaches heavily depend on the completeness of such data. One particular shortcoming of scholarly data nowadays is that non-English publications are often not included in data sets, or that language metadata is not available. Because of this, citations between publications of differing languages (cross-lingual citations) have only been studied to a very limited degree. In this paper, we present an analysis of cross-lingual citations based on over one million English papers, spanning three scientific disciplines and a time span of three decades. Our investigation covers differences between cited languages and disciplines, trends over time, and the usage characteristics as well as impact of cross-lingual citations. Among our findings are an increasing rate of citations to publications written in Chinese, citations being primarily to local non-English languages, and consistency in citation intent between cross- and monolingual citations. To facilitate further research, we make our collected data and source code publicly available.
Self-directed Machine Learning
Jan 08, 2022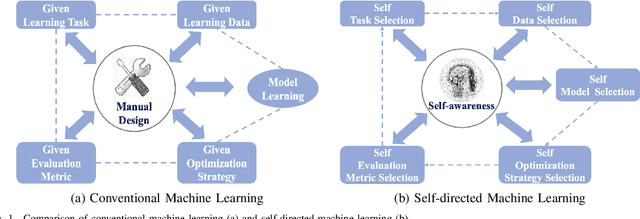
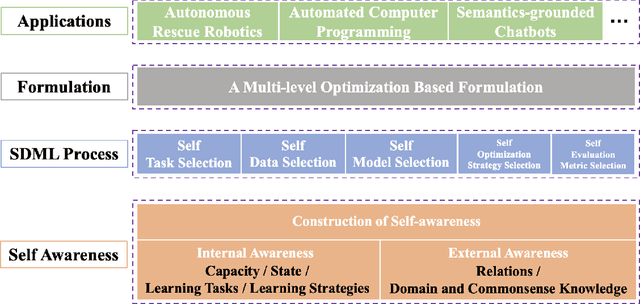
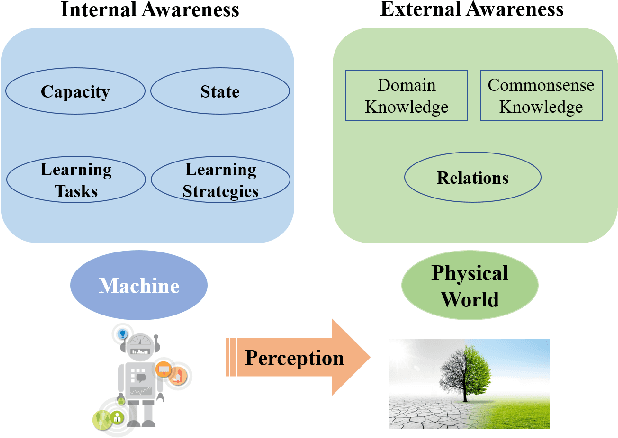
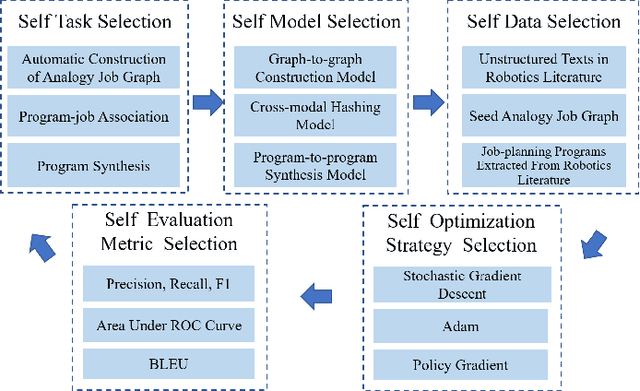
Conventional machine learning (ML) relies heavily on manual design from machine learning experts to decide learning tasks, data, models, optimization algorithms, and evaluation metrics, which is labor-intensive, time-consuming, and cannot learn autonomously like humans. In education science, self-directed learning, where human learners select learning tasks and materials on their own without requiring hands-on guidance, has been shown to be more effective than passive teacher-guided learning. Inspired by the concept of self-directed human learning, we introduce the principal concept of Self-directed Machine Learning (SDML) and propose a framework for SDML. Specifically, we design SDML as a self-directed learning process guided by self-awareness, including internal awareness and external awareness. Our proposed SDML process benefits from self task selection, self data selection, self model selection, self optimization strategy selection and self evaluation metric selection through self-awareness without human guidance. Meanwhile, the learning performance of the SDML process serves as feedback to further improve self-awareness. We propose a mathematical formulation for SDML based on multi-level optimization. Furthermore, we present case studies together with potential applications of SDML, followed by discussing future research directions. We expect that SDML could enable machines to conduct human-like self-directed learning and provide a new perspective towards artificial general intelligence.
A polynomial-time algorithm for learning nonparametric causal graphs
Jun 22, 2020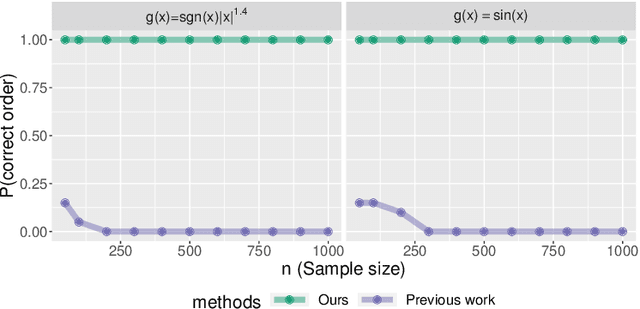
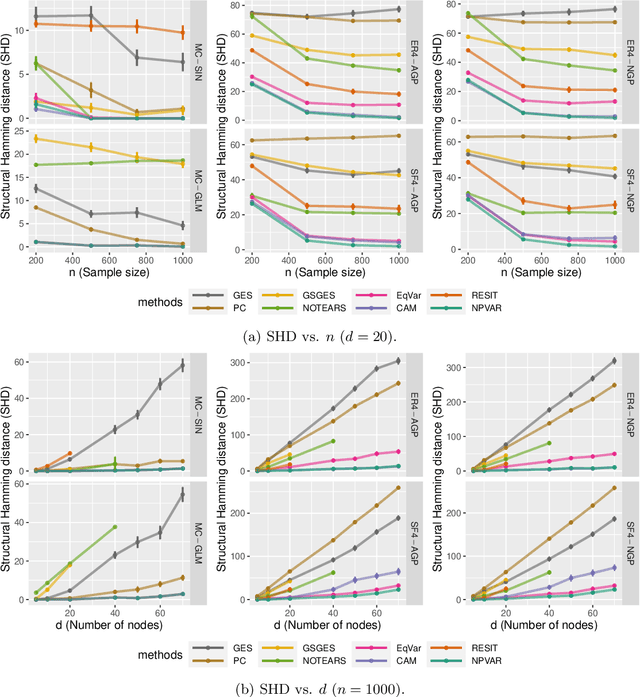
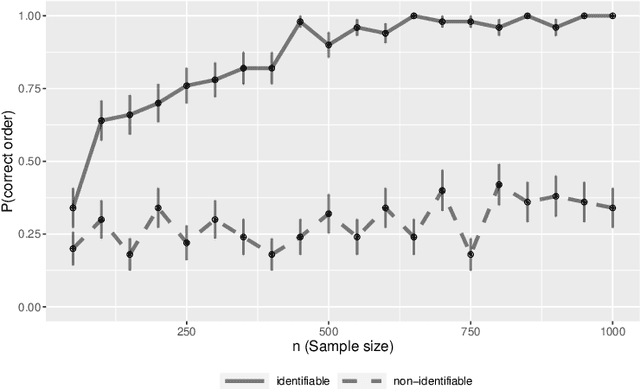
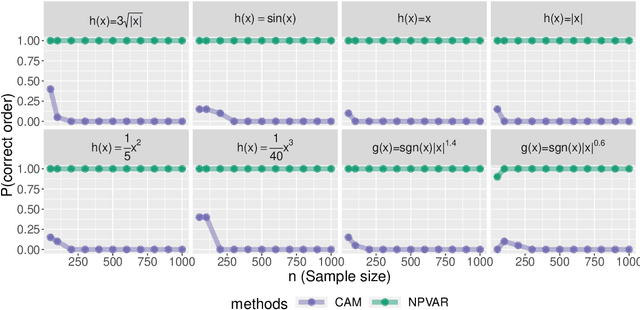
We establish finite-sample guarantees for a polynomial-time algorithm for learning a nonlinear, nonparametric directed acyclic graphical (DAG) model from data. The analysis is model-free and does not assume linearity, additivity, independent noise, or faithfulness. Instead, we impose a condition on the residual variances that is closely related to previous work on linear models with equal variances. Compared to an optimal algorithm with oracle knowledge of the variable ordering, the additional cost of the algorithm is linear in the dimension $d$ and the number of samples $n$. Finally, we compare the proposed algorithm to existing approaches in a simulation study.
Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation
Feb 21, 2020
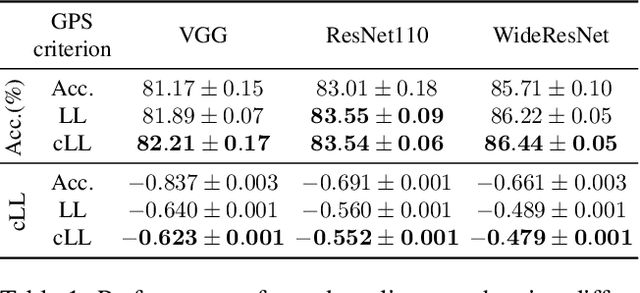
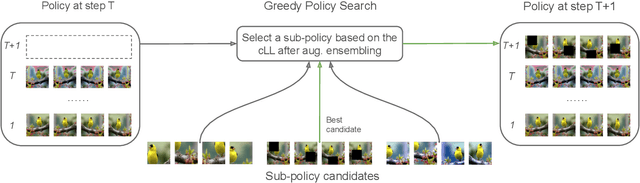

Test-time data augmentation---averaging the predictions of a machine learning model across multiple augmented samples of data---is a widely used technique that improves the predictive performance. While many advanced learnable data augmentation techniques have emerged in recent years, they are focused on the training phase. Such techniques are not necessarily optimal for test-time augmentation and can be outperformed by a policy consisting of simple crops and flips. The primary goal of this paper is to demonstrate that test-time augmentation policies can be successfully learned too. We~introduce \emph{greedy policy search} (GPS), a simple but high-performing method for learning a policy of test-time augmentation. We demonstrate that augmentation policies learned with GPS achieve superior predictive performance on image classification problems, provide better in-domain uncertainty estimation, and improve the robustness to domain shift.
Learning Spatio-Temporal Specifications for Dynamical Systems
Dec 20, 2021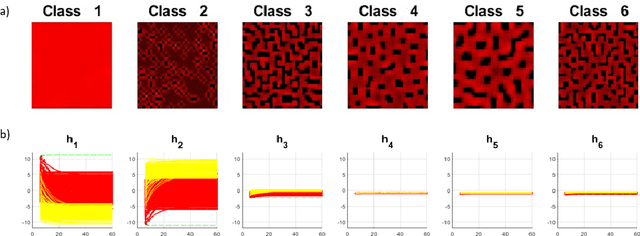
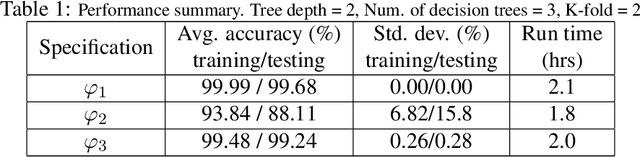

Learning dynamical systems properties from data provides important insights that help us understand such systems and mitigate undesired outcomes. In this work, we propose a framework for learning spatio-temporal (ST) properties as formal logic specifications from data. We introduce SVM-STL, an extension of Signal Signal Temporal Logic (STL), capable of specifying spatial and temporal properties of a wide range of dynamical systems that exhibit time-varying spatial patterns. Our framework utilizes machine learning techniques to learn SVM-STL specifications from system executions given by sequences of spatial patterns. We present methods to deal with both labeled and unlabeled data. In addition, given system requirements in the form of SVM-STL specifications, we provide an approach for parameter synthesis to find parameters that maximize the satisfaction of such specifications. Our learning framework and parameter synthesis approach are showcased in an example of a reaction-diffusion system.
Spatiogram: A phase based directional angular measure and perceptual weighting for ensemble source width
Dec 14, 2021
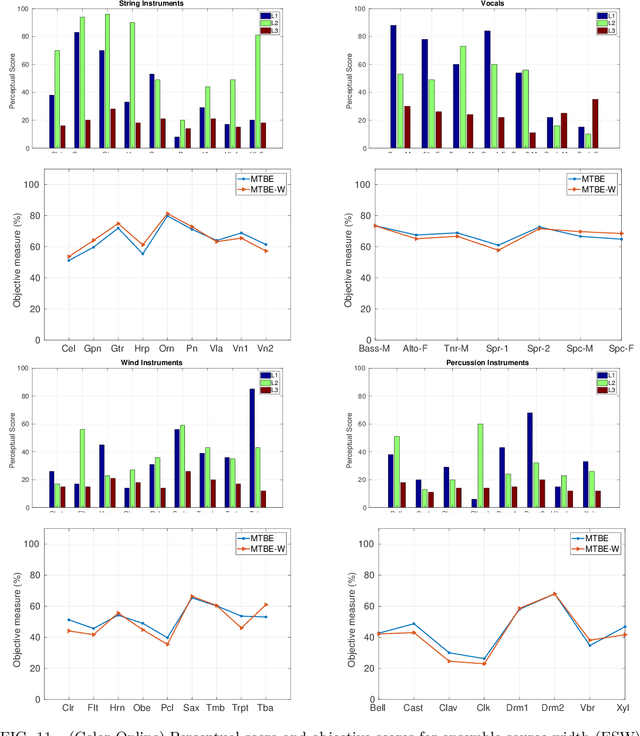
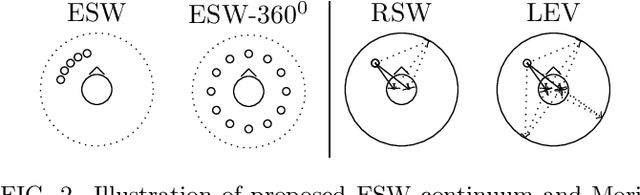
In concert hall studies, inter-aural cross-correlation (IACC), which is signal dependent, is used as a measure of perceptual source width. The same measure is used for perceptual source width in the case of distributed sources also. In this work, we examine the validity of IACC for both the cases and develop an improved measure for ensemble-like distributed sources. We decompose the new objective measure for perceptual ensemble source width (ESW) into two components (i) phase based directional angular measure, which is timbre independent (spatial measure) and (ii) mean time-bandwidth energy (MTBE), a perceptual weight, (timbre measure). This combination of spatial and timbral measures can be extended as an alternate measure for determining auditory source width (ASW) and listener envelopment (LEV) of arbitrary signals in concert-hall and room acoustics.
Swift and Sure: Hardness-aware Contrastive Learning for Low-dimensional Knowledge Graph Embeddings
Jan 03, 2022
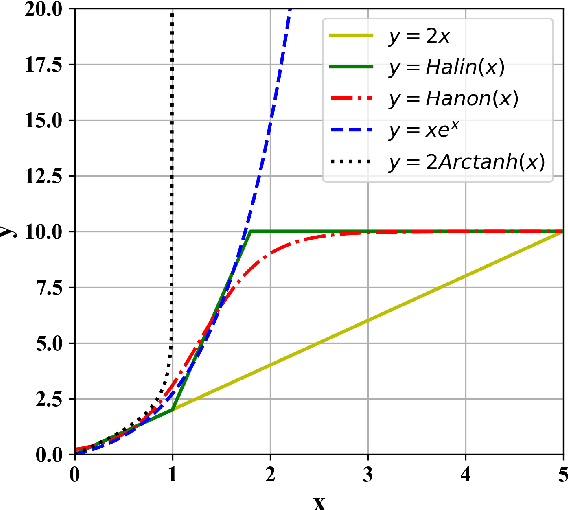
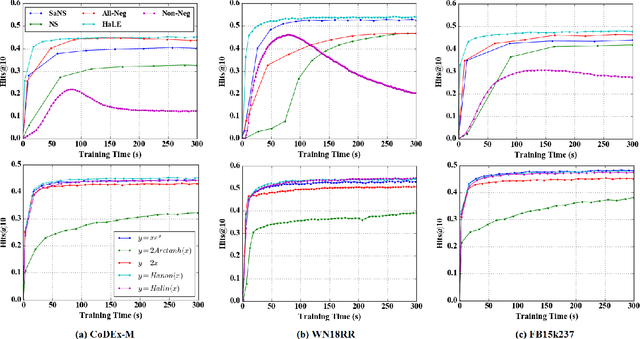
Knowledge graph embedding (KGE) has drawn great attention due to its potential in automatic knowledge graph (KG) completion and knowledge-driven tasks. However, recent KGE models suffer from high training cost and large storage space, thus limiting their practicality in real-world applications. To address this challenge, based on the latest findings in the field of Contrastive Learning, we propose a novel KGE training framework called Hardness-aware Low-dimensional Embedding (HaLE). Instead of the traditional Negative Sampling, we design a new loss function based on query sampling that can balance two important training targets, Alignment and Uniformity. Furthermore, we analyze the hardness-aware ability of recent low-dimensional hyperbolic models and propose a lightweight hardness-aware activation mechanism, which can help the KGE models focus on hard instances and speed up convergence. The experimental results show that in the limited training time, HaLE can effectively improve the performance and training speed of KGE models on five commonly-used datasets. The HaLE-trained models can obtain a high prediction accuracy after training few minutes and are competitive compared to the state-of-the-art models in both low- and high-dimensional conditions.
On the Limits of Minimal Pairs in Contrastive Evaluation
Sep 15, 2021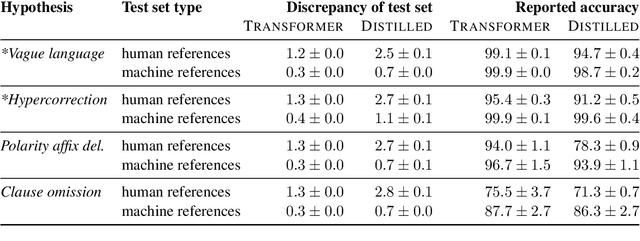
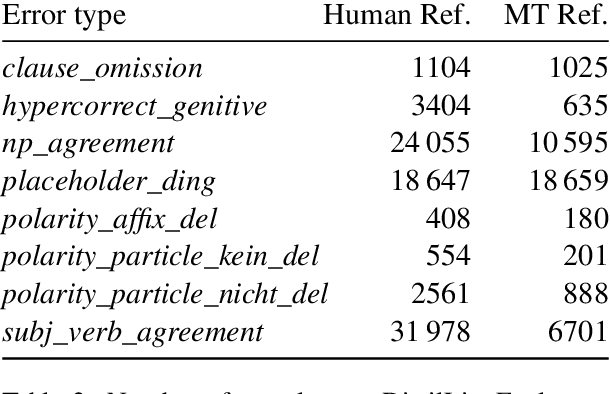
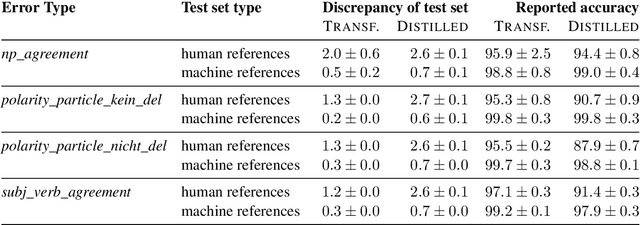

Minimal sentence pairs are frequently used to analyze the behavior of language models. It is often assumed that model behavior on contrastive pairs is predictive of model behavior at large. We argue that two conditions are necessary for this assumption to hold: First, a tested hypothesis should be well-motivated, since experiments show that contrastive evaluation can lead to false positives. Secondly, test data should be chosen such as to minimize distributional discrepancy between evaluation time and deployment time. For a good approximation of deployment-time decoding, we recommend that minimal pairs are created based on machine-generated text, as opposed to human-written references. We present a contrastive evaluation suite for English-German MT that implements this recommendation.
3D Skeleton-based Few-shot Action Recognition with JEANIE is not so Naïve
Dec 23, 2021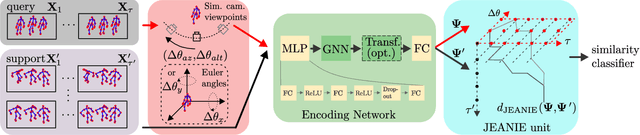
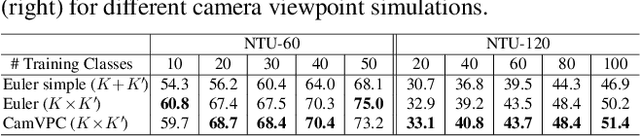
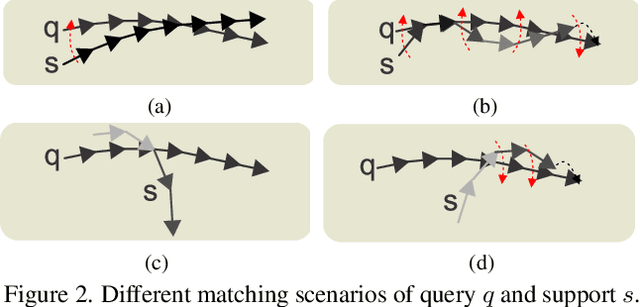
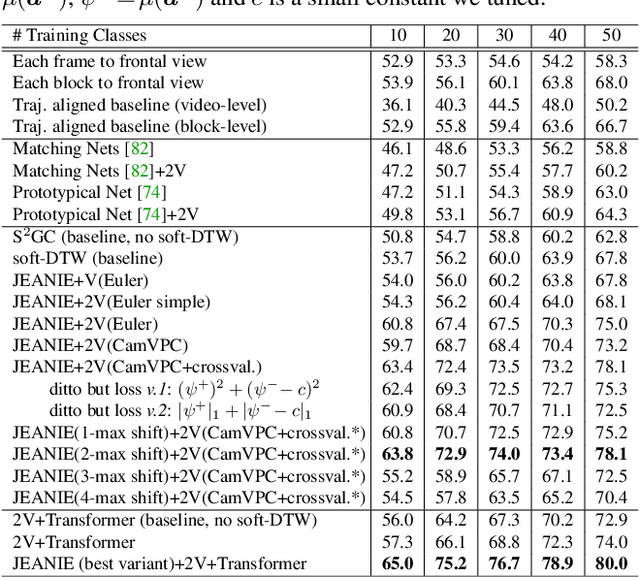
In this paper, we propose a Few-shot Learning pipeline for 3D skeleton-based action recognition by Joint tEmporal and cAmera viewpoiNt alIgnmEnt (JEANIE). To factor out misalignment between query and support sequences of 3D body joints, we propose an advanced variant of Dynamic Time Warping which jointly models each smooth path between the query and support frames to achieve simultaneously the best alignment in the temporal and simulated camera viewpoint spaces for end-to-end learning under the limited few-shot training data. Sequences are encoded with a temporal block encoder based on Simple Spectral Graph Convolution, a lightweight linear Graph Neural Network backbone (we also include a setting with a transformer). Finally, we propose a similarity-based loss which encourages the alignment of sequences of the same class while preventing the alignment of unrelated sequences. We demonstrate state-of-the-art results on NTU-60, NTU-120, Kinetics-skeleton and UWA3D Multiview Activity II.
EuroCrops: A Pan-European Dataset for Time Series Crop Type Classification
Jun 14, 2021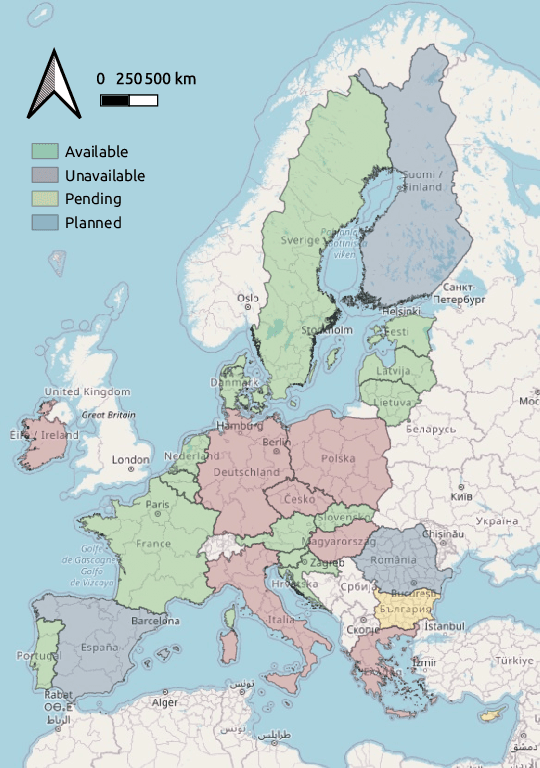
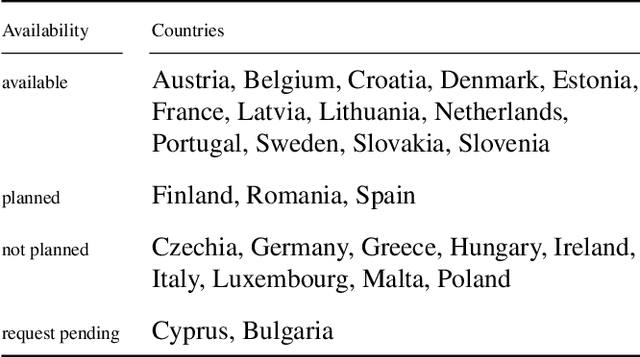
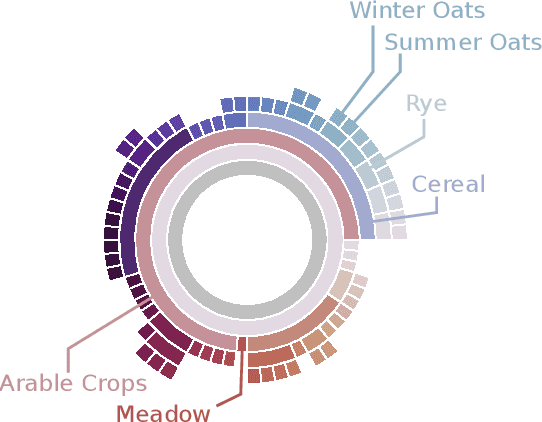

We present EuroCrops, a dataset based on self-declared field annotations for training and evaluating methods for crop type classification and mapping, together with its process of acquisition and harmonisation. By this, we aim to enrich the research efforts and discussion for data-driven land cover classification via Earth observation and remote sensing. Additionally, through inclusion of self-declarations gathered in the scope of subsidy control from all countries of the European Union (EU), this dataset highlights the difficulties and pitfalls one comes across when operating on a transnational level. We, therefore, also introduce a new taxonomy scheme, HCAT-ID, that aspires to capture all the aspects of reference data originating from administrative and agency databases. To address researchers from both the remote sensing and the computer vision and machine learning communities, we publish the dataset in different formats and processing levels.
* 4 pages, website: https://www.eurocrops.tum.de/