 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Chronological Causal Bandits
Dec 03, 2021
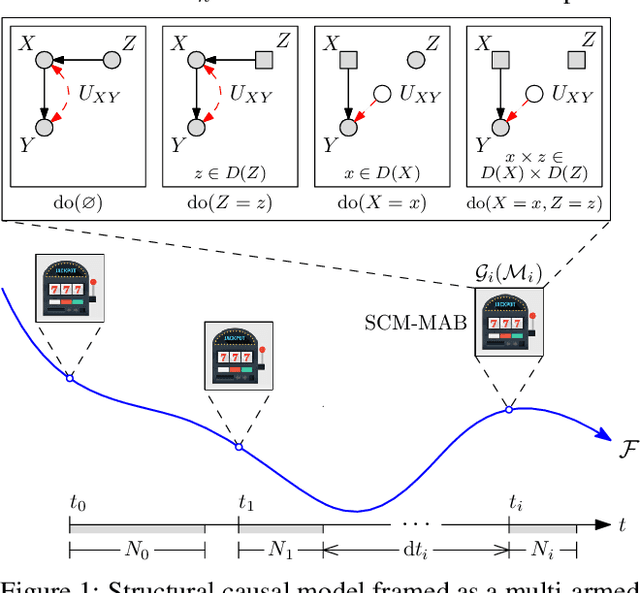
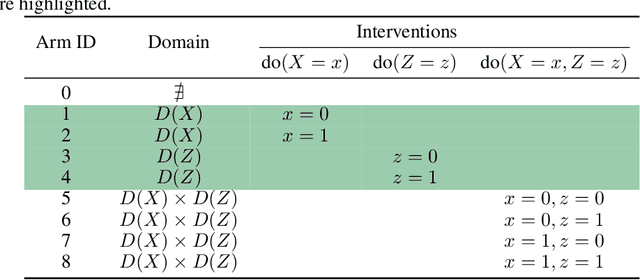
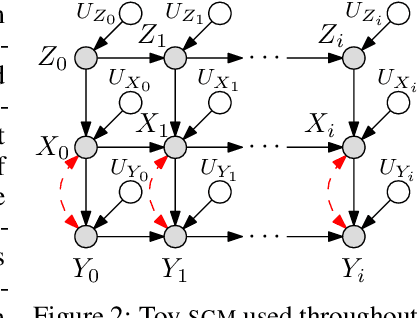

This paper studies an instance of the multi-armed bandit (MAB) problem, specifically where several causal MABs operate chronologically in the same dynamical system. Practically the reward distribution of each bandit is governed by the same non-trivial dependence structure, which is a dynamic causal model. Dynamic because we allow for each causal MAB to depend on the preceding MAB and in doing so are able to transfer information between agents. Our contribution, the Chronological Causal Bandit (CCB), is useful in discrete decision-making settings where the causal effects are changing across time and can be informed by earlier interventions in the same system. In this paper, we present some early findings of the CCB as demonstrated on a toy problem.
Hyperparameter-free Continuous Learning for Domain Classification in Natural Language Understanding
Jan 05, 2022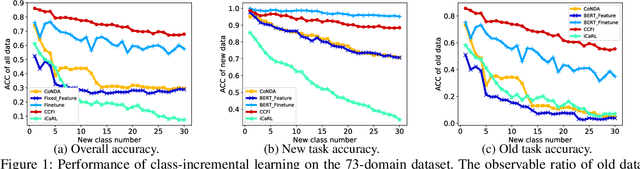

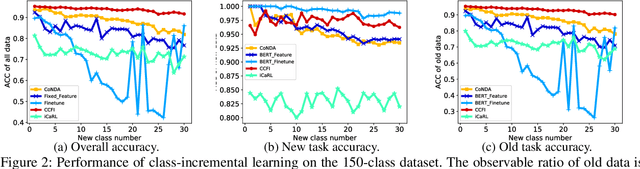

Domain classification is the fundamental task in natural language understanding (NLU), which often requires fast accommodation to new emerging domains. This constraint makes it impossible to retrain all previous domains, even if they are accessible to the new model. Most existing continual learning approaches suffer from low accuracy and performance fluctuation, especially when the distributions of old and new data are significantly different. In fact, the key real-world problem is not the absence of old data, but the inefficiency to retrain the model with the whole old dataset. Is it potential to utilize some old data to yield high accuracy and maintain stable performance, while at the same time, without introducing extra hyperparameters? In this paper, we proposed a hyperparameter-free continual learning model for text data that can stably produce high performance under various environments. Specifically, we utilize Fisher information to select exemplars that can "record" key information of the original model. Also, a novel scheme called dynamical weight consolidation is proposed to enable hyperparameter-free learning during the retrain process. Extensive experiments demonstrate that baselines suffer from fluctuated performance and therefore useless in practice. On the contrary, our proposed model CCFI significantly and consistently outperforms the best state-of-the-art method by up to 20% in average accuracy, and each component of CCFI contributes effectively to overall performance.
DeDUCE: Generating Counterfactual Explanations Efficiently
Nov 29, 2021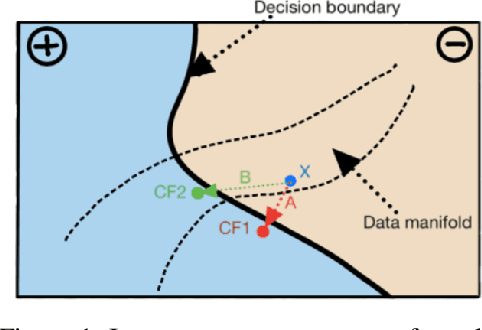

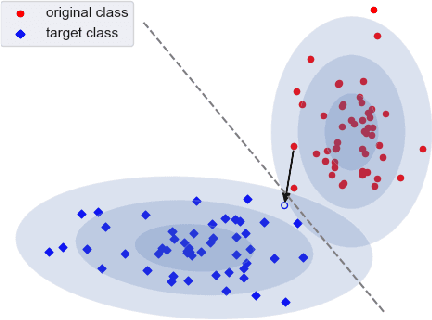

When an image classifier outputs a wrong class label, it can be helpful to see what changes in the image would lead to a correct classification. This is the aim of algorithms generating counterfactual explanations. However, there is no easily scalable method to generate such counterfactuals. We develop a new algorithm providing counterfactual explanations for large image classifiers trained with spectral normalisation at low computational cost. We empirically compare this algorithm against baselines from the literature; our novel algorithm consistently finds counterfactuals that are much closer to the original inputs. At the same time, the realism of these counterfactuals is comparable to the baselines. The code for all experiments is available at https://github.com/benedikthoeltgen/DeDUCE.
Learning To Retrieve Prompts for In-Context Learning
Dec 16, 2021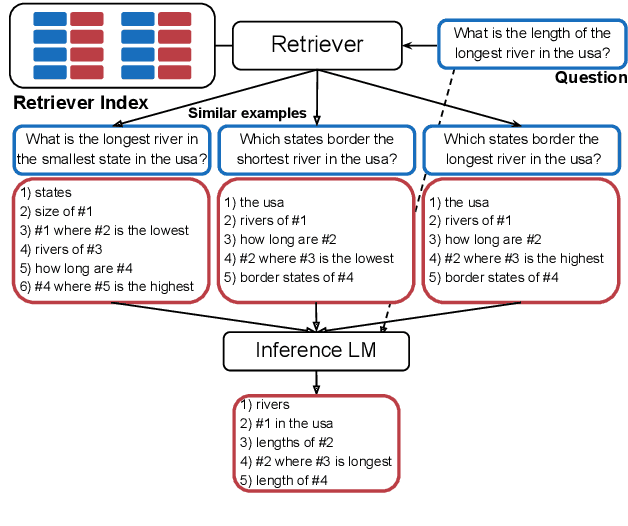

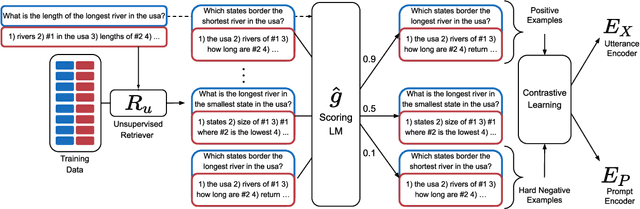
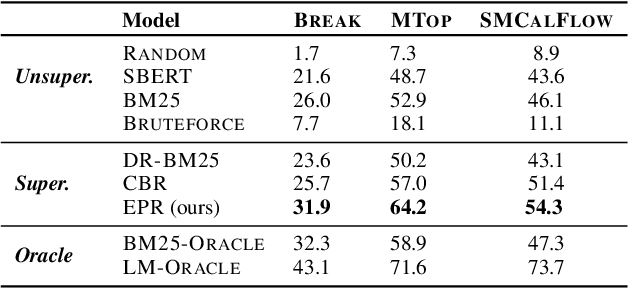
In-context learning is a recent paradigm in natural language understanding, where a large pre-trained language model (LM) observes a test instance and a few training examples as its input, and directly decodes the output without any update to its parameters. However, performance has been shown to strongly depend on the selected training examples (termed prompt). In this work, we propose an efficient method for retrieving prompts for in-context learning using annotated data and a LM. Given an input-output pair, we estimate the probability of the output given the input and a candidate training example as the prompt, and label training examples as positive or negative based on this probability. We then train an efficient dense retriever from this data, which is used to retrieve training examples as prompts at test time. We evaluate our approach on three sequence-to-sequence tasks where language utterances are mapped to meaning representations, and find that it substantially outperforms prior work and multiple baselines across the board.
State-based Episodic Memory for Multi-Agent Reinforcement Learning
Oct 19, 2021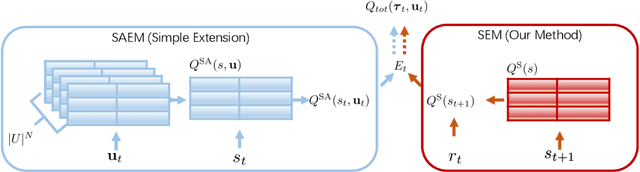

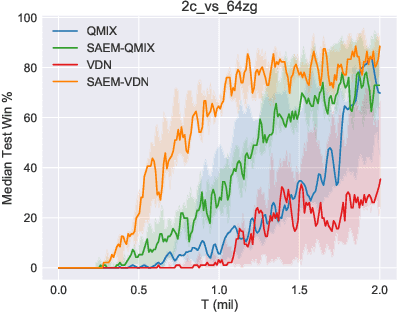
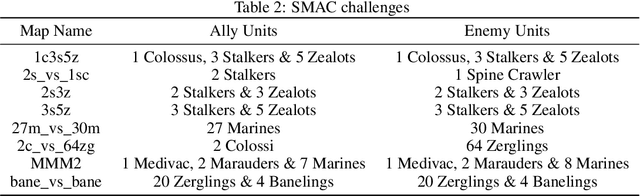
Multi-agent reinforcement learning (MARL) algorithms have made promising progress in recent years by leveraging the centralized training and decentralized execution (CTDE) paradigm. However, existing MARL algorithms still suffer from the sample inefficiency problem. In this paper, we propose a simple yet effective approach, called state-based episodic memory (SEM), to improve sample efficiency in MARL. SEM adopts episodic memory (EM) to supervise the centralized training procedure of CTDE in MARL. To the best of our knowledge, SEM is the first work to introduce EM into MARL. We can theoretically prove that, when using for MARL, SEM has lower space complexity and time complexity than state and action based EM (SAEM), which is originally proposed for single-agent reinforcement learning. Experimental results on StarCraft multi-agent challenge (SMAC) show that introducing episodic memory into MARL can improve sample efficiency and SEM can reduce storage cost and time cost compared with SAEM.
Addressing Deep Learning Model Uncertainty in Long-Range Climate Forecasting with Late Fusion
Dec 10, 2021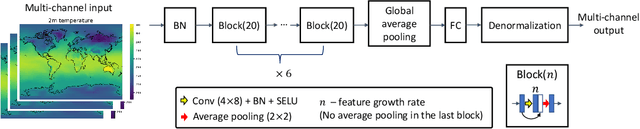
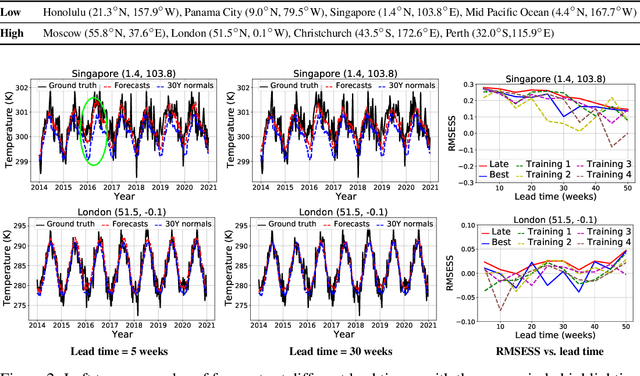
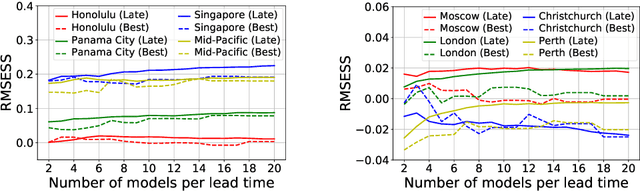
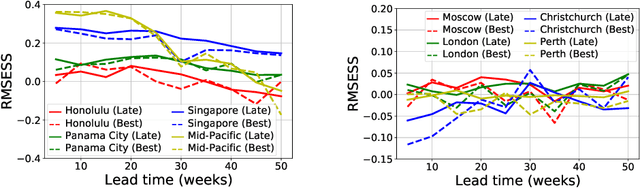
Global warming leads to the increase in frequency and intensity of climate extremes that cause tremendous loss of lives and property. Accurate long-range climate prediction allows more time for preparation and disaster risk management for such extreme events. Although machine learning approaches have shown promising results in long-range climate forecasting, the associated model uncertainties may reduce their reliability. To address this issue, we propose a late fusion approach that systematically combines the predictions from multiple models to reduce the expected errors of the fused results. We also propose a network architecture with the novel denormalization layer to gain the benefits of data normalization without actually normalizing the data. The experimental results on long-range 2m temperature forecasting show that the framework outperforms the 30-year climate normals, and the accuracy can be improved by increasing the number of models.
A Neural Network Ensemble Approach to System Identification
Oct 15, 2021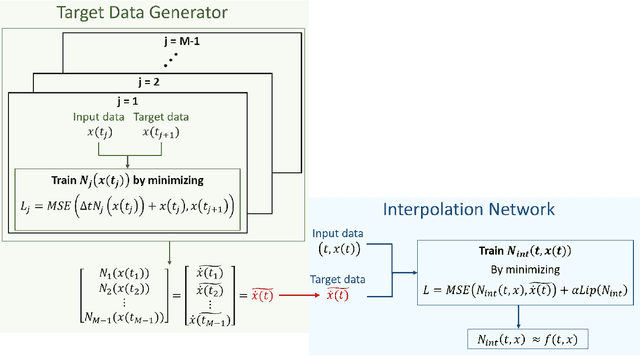
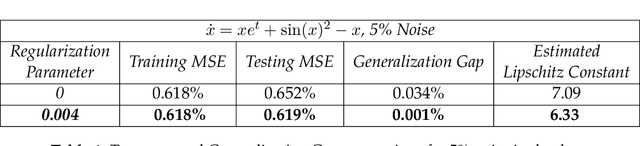
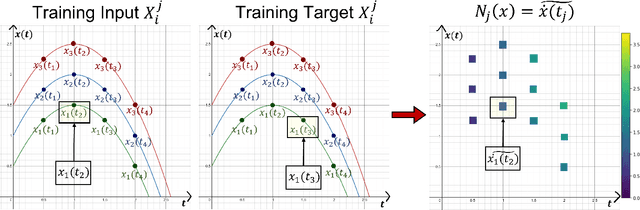

We present a new algorithm for learning unknown governing equations from trajectory data, using and ensemble of neural networks. Given samples of solutions $x(t)$ to an unknown dynamical system $\dot{x}(t)=f(t,x(t))$, we approximate the function $f$ using an ensemble of neural networks. We express the equation in integral form and use Euler method to predict the solution at every successive time step using at each iteration a different neural network as a prior for $f$. This procedure yields M-1 time-independent networks, where M is the number of time steps at which $x(t)$ is observed. Finally, we obtain a single function $f(t,x(t))$ by neural network interpolation. Unlike our earlier work, where we numerically computed the derivatives of data, and used them as target in a Lipschitz regularized neural network to approximate $f$, our new method avoids numerical differentiations, which are unstable in presence of noise. We test the new algorithm on multiple examples both with and without noise in the data. We empirically show that generalization and recovery of the governing equation improve by adding a Lipschitz regularization term in our loss function and that this method improves our previous one especially in presence of noise, when numerical differentiation provides low quality target data. Finally, we compare our results with the method proposed by Raissi, et al. arXiv:1801.01236 (2018) and with SINDy.
Real-Time Regression with Dividing Local Gaussian Processes
Jun 16, 2020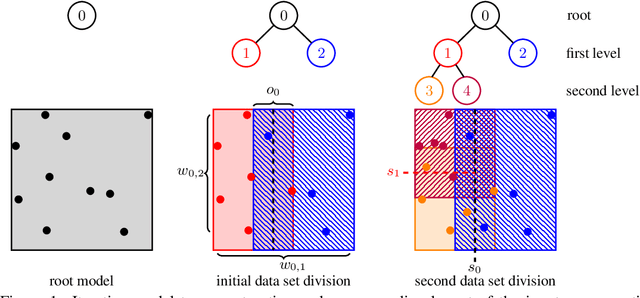
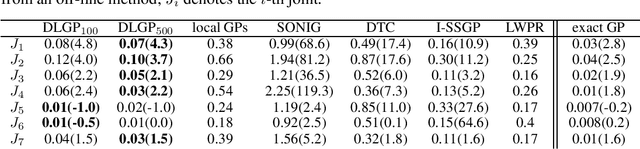
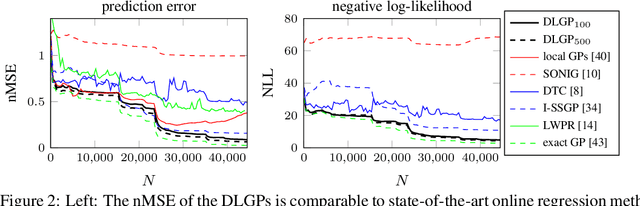
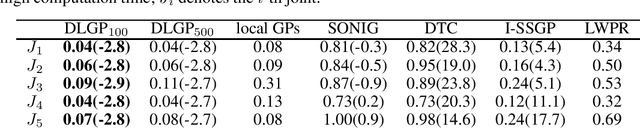
The increased demand for online prediction and the growing availability of large data sets drives the need for computationally efficient models. While exact Gaussian process regression shows various favorable theoretical properties (uncertainty estimate, unlimited expressive power), the poor scaling with respect to the training set size prohibits its application in big data regimes in real-time. Therefore, this paper proposes dividing local Gaussian processes, which are a novel, computationally efficient modeling approach based on Gaussian process regression. Due to an iterative, data-driven division of the input space, they achieve a sublinear computational complexity in the total number of training points in practice, while providing excellent predictive distributions. A numerical evaluation on real-world data sets shows their advantages over other state-of-the-art methods in terms of accuracy as well as prediction and update speed.
On End-to-end Multi-channel Time Domain Speech Separation in Reverberant Environments
Nov 11, 2020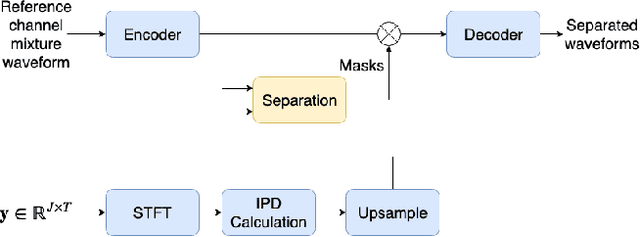

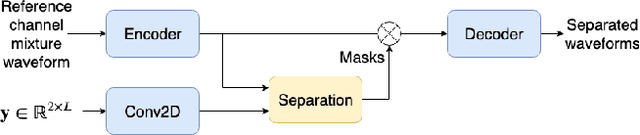
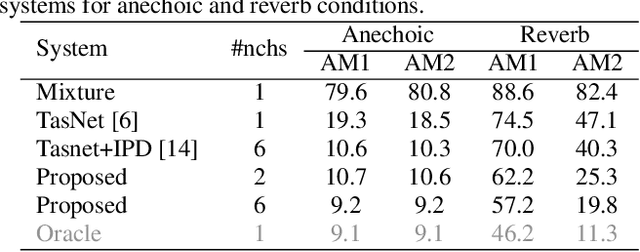
This paper introduces a new method for multi-channel time domain speech separation in reverberant environments. A fully-convolutional neural network structure has been used to directly separate speech from multiple microphone recordings, with no need of conventional spatial feature extraction. To reduce the influence of reverberation on spatial feature extraction, a dereverberation pre-processing method has been applied to further improve the separation performance. A spatialized version of wsj0-2mix dataset has been simulated to evaluate the proposed system. Both source separation and speech recognition performance of the separated signals have been evaluated objectively. Experiments show that the proposed fully-convolutional network improves the source separation metric and the word error rate (WER) by more than 13% and 50% relative, respectively, over a reference system with conventional features. Applying dereverberation as pre-processing to the proposed system can further reduce the WER by 29% relative using an acoustic model trained on clean and reverberated data.
* Presented at IEEE ICASSP 2020
Trajectory Prediction with Linguistic Representations
Oct 19, 2021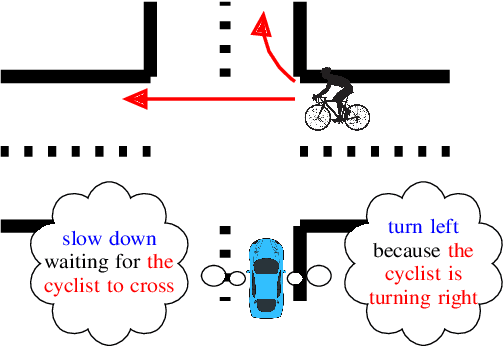
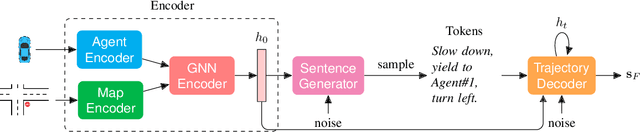
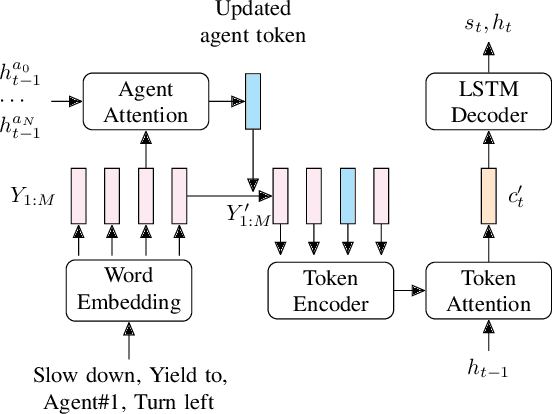

Language allows humans to build mental models that interpret what is happening around them resulting in more accurate long-term predictions. We present a novel trajectory prediction model that uses linguistic intermediate representations to forecast trajectories, and is trained using trajectory samples with partially annotated captions. The model learns the meaning of each of the words without direct per-word supervision. At inference time, it generates a linguistic description of trajectories which captures maneuvers and interactions over an extended time interval. This generated description is used to refine predictions of the trajectories of multiple agents. We train and validate our model on the Argoverse dataset, and demonstrate improved accuracy results in trajectory prediction. In addition, our model is more interpretable: it presents part of its reasoning in plain language as captions, which can aid model development and can aid in building confidence in the model before deploying it.