 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022

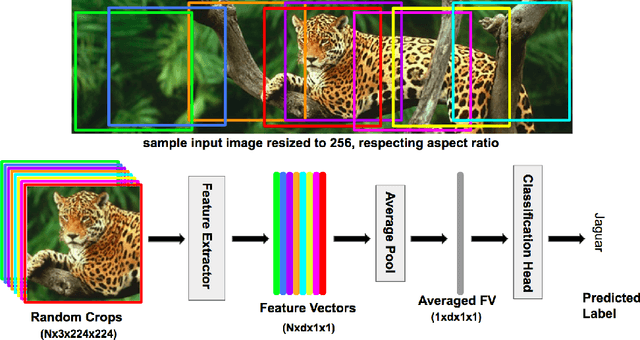
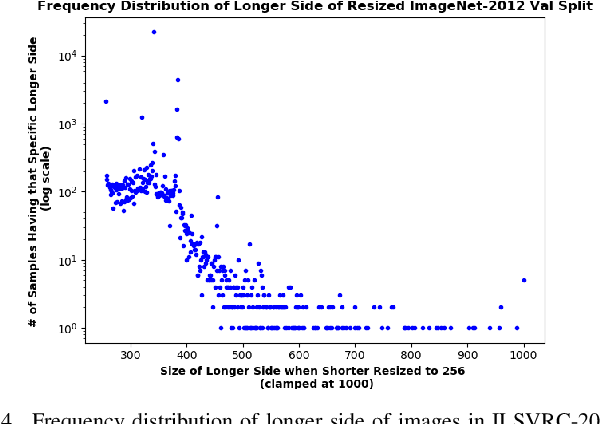
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.
Probabilistic prediction of the heave motions of a semi-submersible by a deep learning problem model
Oct 09, 2021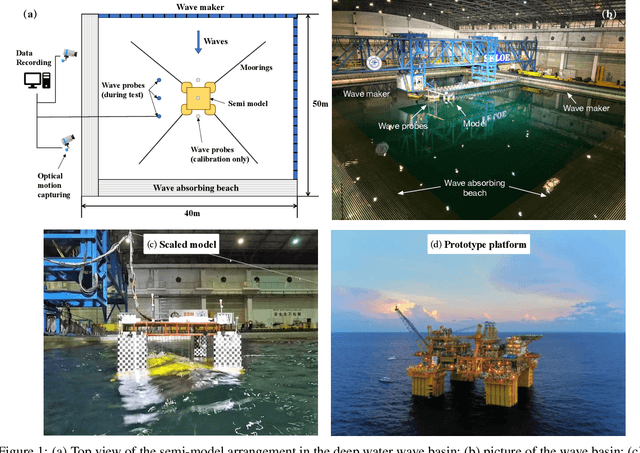
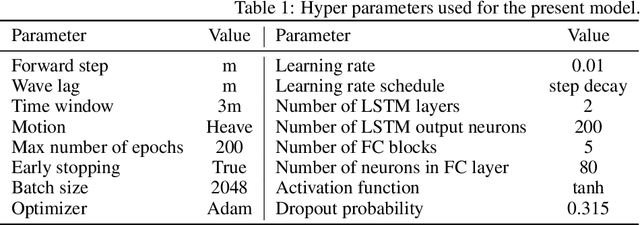
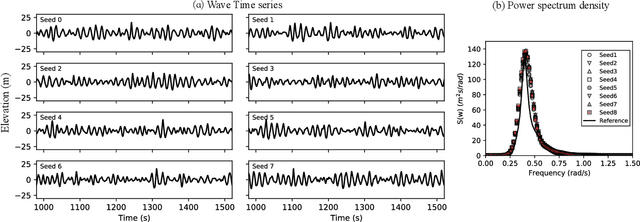
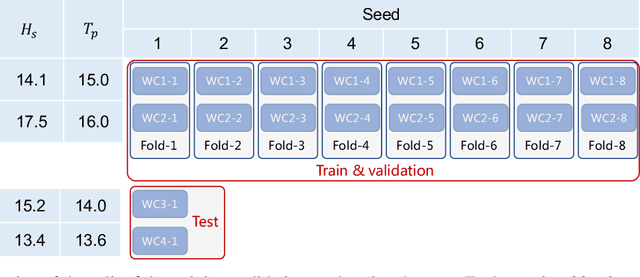
The real-time motion prediction of a floating offshore platform refers to forecasting its motions in the following one- or two-wave cycles, which helps improve the performance of a motion compensation system and provides useful early warning information. In this study, we extend a deep learning (DL) model, which could predict the heave and surge motions of a floating semi-submersible 20 to 50 seconds ahead with good accuracy, to quantify its uncertainty of the predictive time series with the help of the dropout technique. By repeating the inference several times, it is found that the collection of the predictive time series is a Gaussian process (GP). The DL model with dropout learned a kernel inside, and the learning procedure was similar to GP regression. Adding noise into training data could help the model to learn more robust features from the training data, thereby leading to a better performance on test data with a wide noise level range. This study extends the understanding of the DL model to predict the wave excited motions of an offshore platform.
Multi-Time-Scale Convolution for Emotion Recognition from Speech Audio Signals
Mar 06, 2020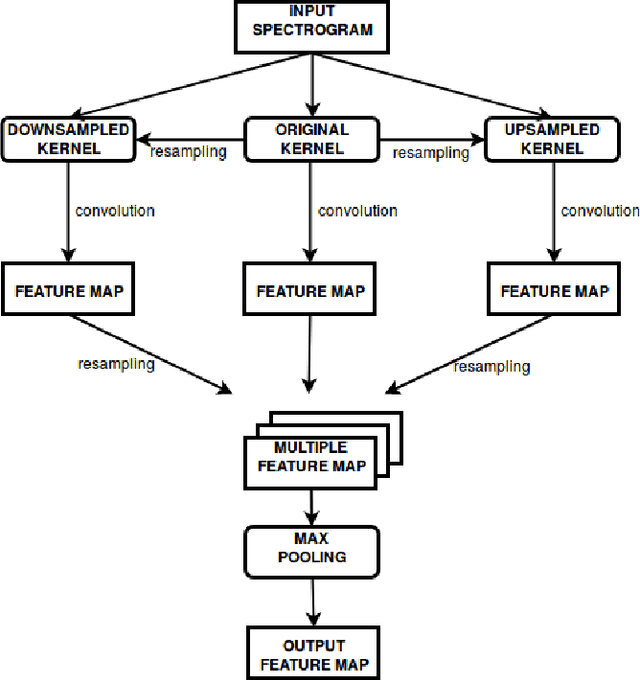
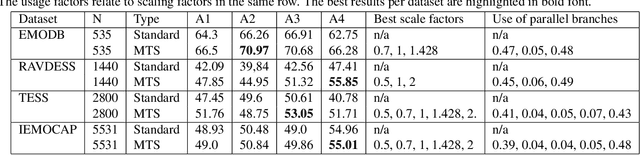
Robustness against temporal variations is important for emotion recognition from speech audio, since emotion is ex-pressed through complex spectral patterns that can exhibit significant local dilation and compression on the time axis depending on speaker and context. To address this and potentially other tasks, we introduce the multi-time-scale (MTS) method to create flexibility towards temporal variations when analyzing time-frequency representations of audio data. MTS extends convolutional neural networks with convolution kernels that are scaled and re-sampled along the time axis, to increase temporal flexibility without increasing the number of trainable parameters compared to standard convolutional layers. We evaluate MTS and standard convolutional layers in different architectures for emotion recognition from speech audio, using 4 datasets of different sizes. The results show that the use of MTS layers consistently improves the generalization of networks of different capacity and depth, compared to standard convolution, especially on smaller datasets
Detecting Anomalies using Overlapping Electrical Measurements in Smart Power Grids
Jan 06, 2022
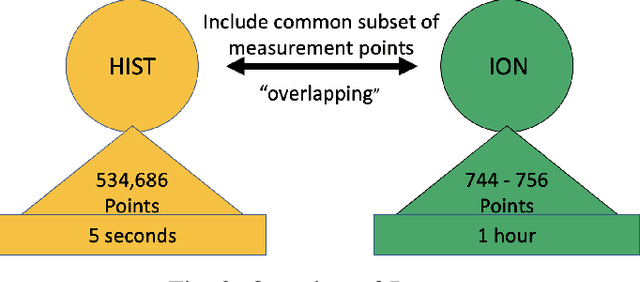
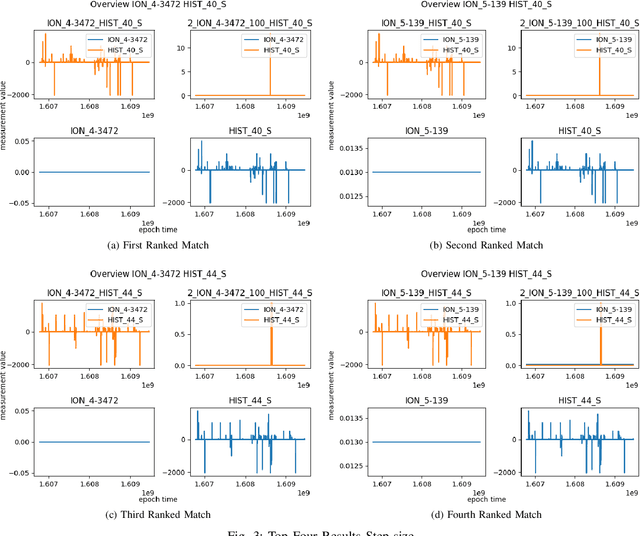
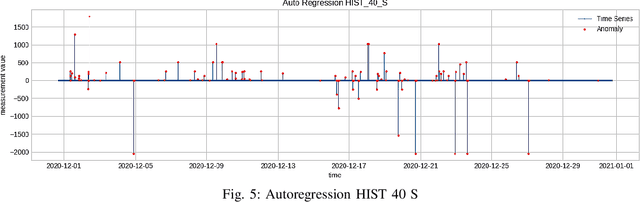
As cyber-attacks against critical infrastructure become more frequent, it is increasingly important to be able to rapidly identify and respond to these threats. This work investigates two independent systems with overlapping electrical measurements with the goal to more rapidly identify anomalies. The independent systems include HIST, a SCADA historian, and ION, an automatic meter reading system (AMR). While prior research has explored the benefits of fusing measurements, the possibility of overlapping measurements from an existing electrical system has not been investigated. To that end, we explore the potential benefits of combining overlapping measurements both to improve the speed/accuracy of anomaly detection and to provide additional validation of the collected measurements. In this paper, we show that merging overlapping measurements provide a more holistic picture of the observed systems. By applying Dynamic Time Warping more anomalies were found -- specifically, an average of 349 times more anomalies, when considering anomalies from both overlapping measurements. When merging the overlapping measurements, a percent change of anomalies of up to 785\% can be achieved compared to a non-merge of the data as reflected by experimental results.
Soundify: Matching Sound Effects to Video
Dec 17, 2021
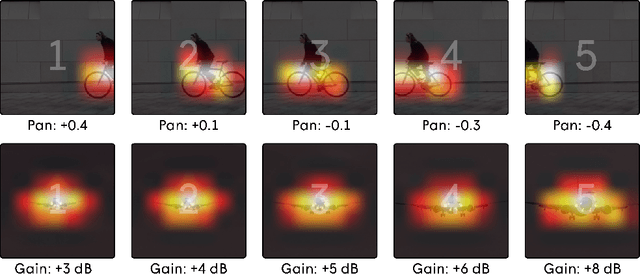
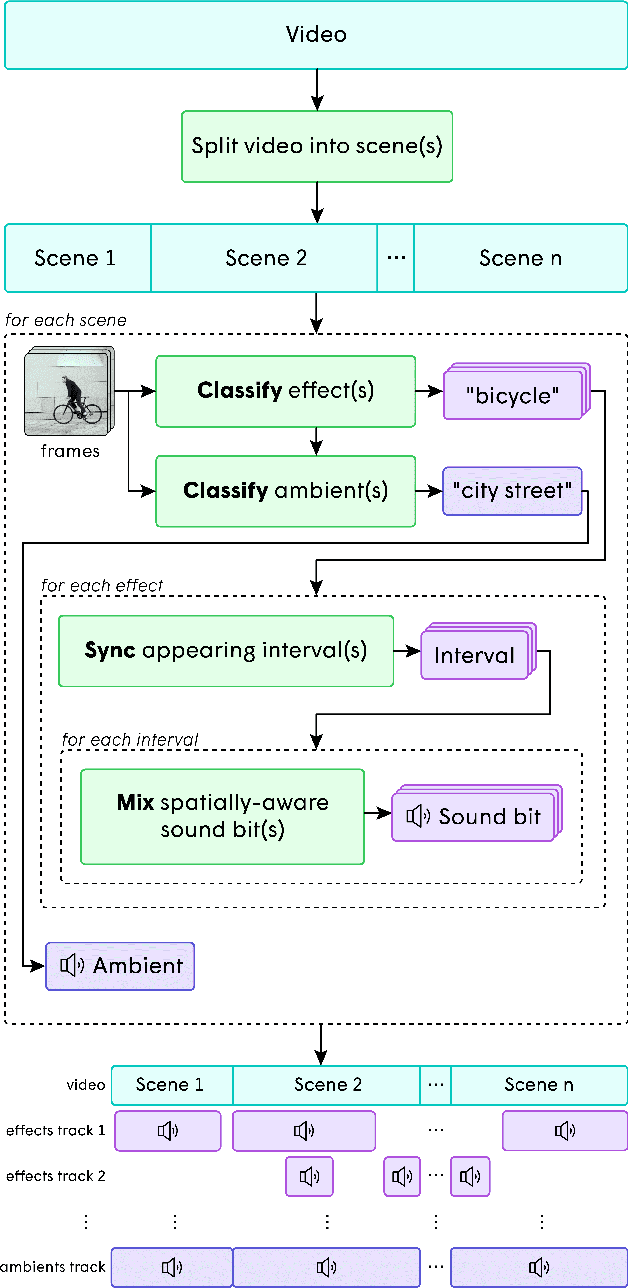
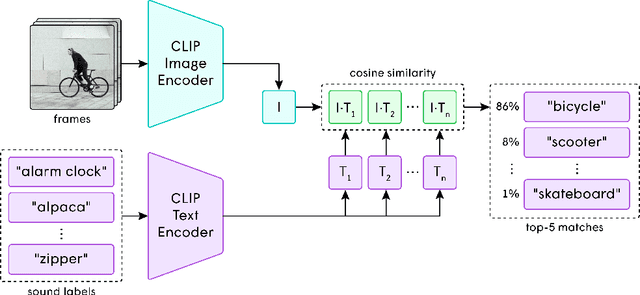
In the art of video editing, sound is really half the story. A skilled video editor overlays sounds, such as effects and ambients, over footage to add character to an object or immerse the viewer within a space. However, through formative interviews with professional video editors, we found that this process can be extremely tedious and time-consuming. We introduce Soundify, a system that matches sound effects to video. By leveraging labeled, studio-quality sound effects libraries and extending CLIP, a neural network with impressive zero-shot image classification capabilities, into a "zero-shot detector", we are able to produce high-quality results without resource-intensive correspondence learning or audio generation. We encourage you to have a look at, or better yet, have a listen to the results at https://chuanenlin.com/soundify.
Hybrid Reinforcement Learning-Based Eco-Driving Strategy for Connected and Automated Vehicles at Signalized Intersections
Jan 19, 2022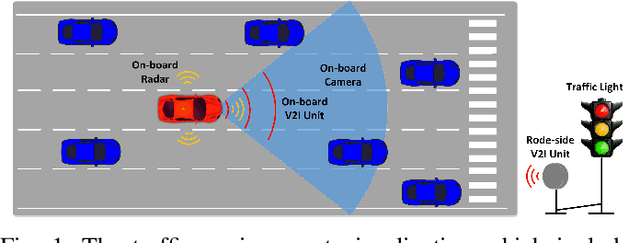
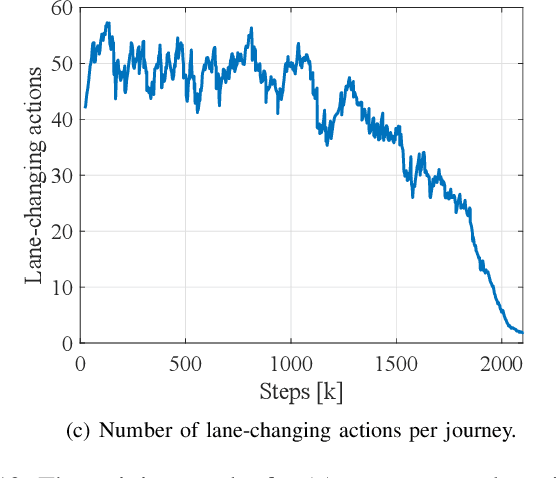
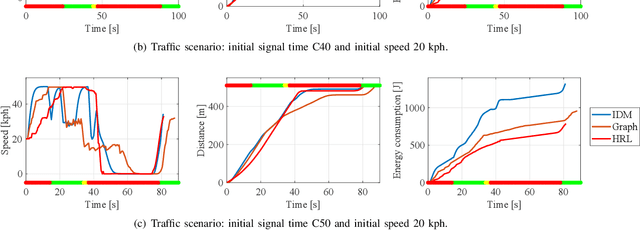
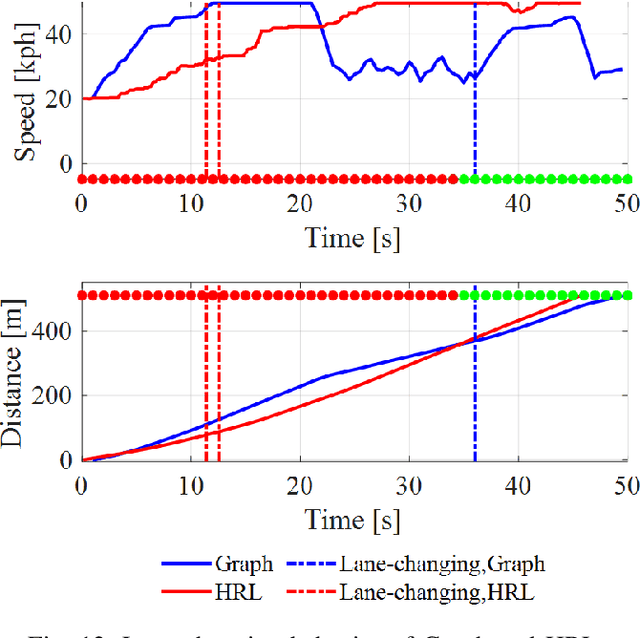
Taking advantage of both vehicle-to-everything (V2X) communication and automated driving technology, connected and automated vehicles are quickly becoming one of the transformative solutions to many transportation problems. However, in a mixed traffic environment at signalized intersections, it is still a challenging task to improve overall throughput and energy efficiency considering the complexity and uncertainty in the traffic system. In this study, we proposed a hybrid reinforcement learning (HRL) framework which combines the rule-based strategy and the deep reinforcement learning (deep RL) to support connected eco-driving at signalized intersections in mixed traffic. Vision-perceptive methods are integrated with vehicle-to-infrastructure (V2I) communications to achieve higher mobility and energy efficiency in mixed connected traffic. The HRL framework has three components: a rule-based driving manager that operates the collaboration between the rule-based policies and the RL policy; a multi-stream neural network that extracts the hidden features of vision and V2I information; and a deep RL-based policy network that generate both longitudinal and lateral eco-driving actions. In order to evaluate our approach, we developed a Unity-based simulator and designed a mixed-traffic intersection scenario. Moreover, several baselines were implemented to compare with our new design, and numerical experiments were conducted to test the performance of the HRL model. The experiments show that our HRL method can reduce energy consumption by 12.70% and save 11.75% travel time when compared with a state-of-the-art model-based Eco-Driving approach.
Model-Size Reduction for Reservoir Computing by Concatenating Internal States Through Time
Jun 11, 2020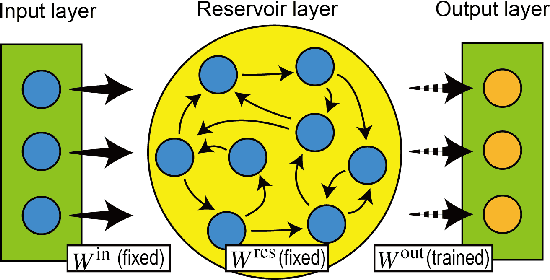
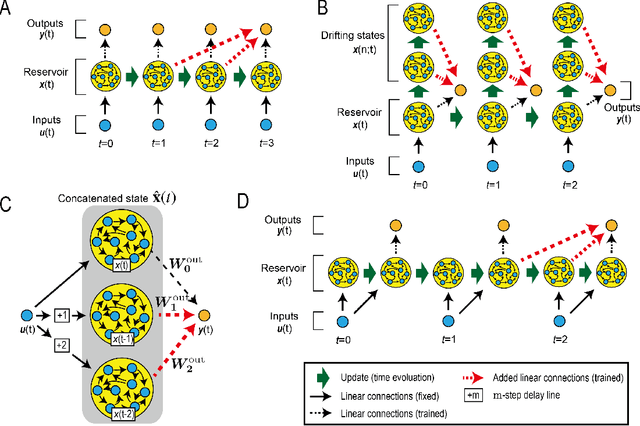
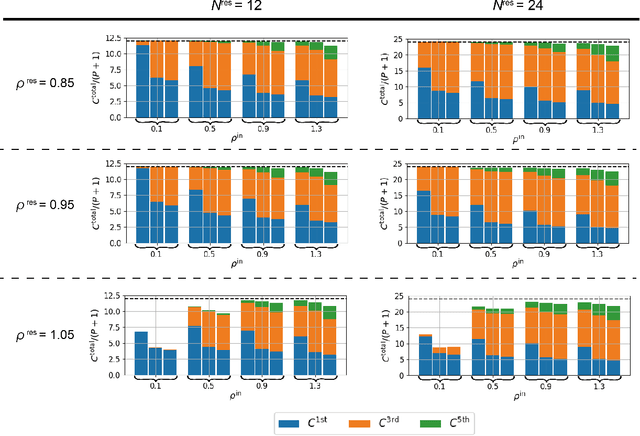
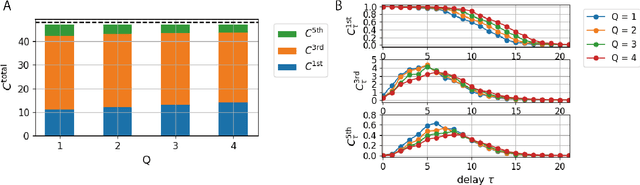
Reservoir computing (RC) is a machine learning algorithm that can learn complex time series from data very rapidly based on the use of high-dimensional dynamical systems, such as random networks of neurons, called "reservoirs." To implement RC in edge computing, it is highly important to reduce the amount of computational resources that RC requires. In this study, we propose methods that reduce the size of the reservoir by inputting the past or drifting states of the reservoir to the output layer at the current time step. These proposed methods are analyzed based on information processing capacity, which is a performance measure of RC proposed by Dambre et al. (2012). In addition, we evaluate the effectiveness of the proposed methods on time-series prediction tasks: the generalized Henon-map and NARMA. On these tasks, we found that the proposed methods were able to reduce the size of the reservoir up to one tenth without a substantial increase in regression error. Because the applications of the proposed methods are not limited to a specific network structure of the reservoir, the proposed methods could further improve the energy efficiency of RC-based systems, such as FPGAs and photonic systems.
Online Change Point Detection for Weighted and Directed Random Dot Product Graphs
Jan 26, 2022
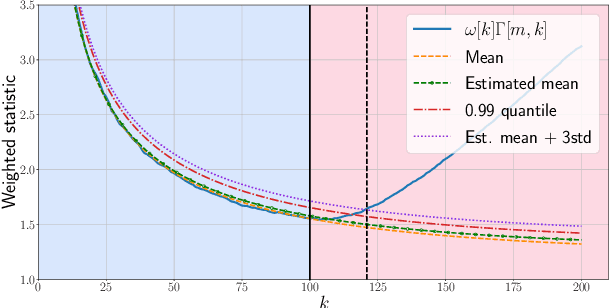
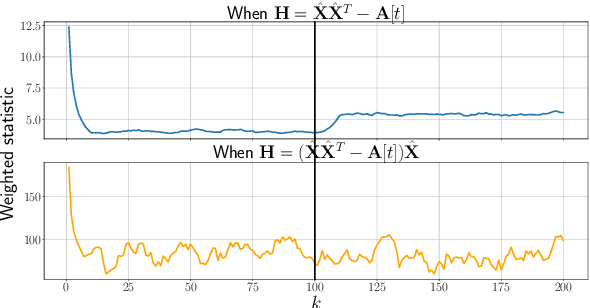
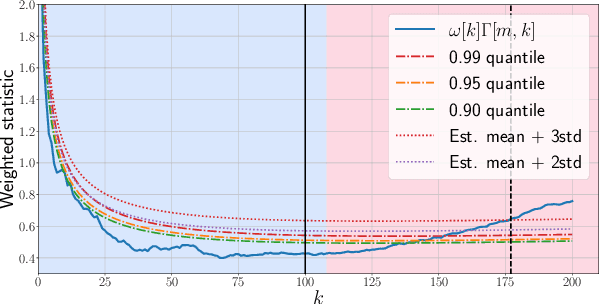
Given a sequence of random (directed and weighted) graphs, we address the problem of online monitoring and detection of changes in the underlying data distribution. Our idea is to endow sequential change-point detection (CPD) techniques with a graph representation learning substrate based on the versatile Random Dot Product Graph (RDPG) model. We consider efficient, online updates of a judicious monitoring function, which quantifies the discrepancy between the streaming graph observations and the nominal RDPG. This reference distribution is inferred via spectral embeddings of the first few graphs in the sequence. We characterize the distribution of this running statistic to select thresholds that guarantee error-rate control, and under simplifying approximations we offer insights on the algorithm's detection resolution and delay. The end result is a lightweight online CPD algorithm, that is also explainable by virtue of the well-appreciated interpretability of RDPG embeddings. This is in stark contrast with most existing graph CPD approaches, which either rely on extensive computation, or they store and process the entire observed time series. An apparent limitation of the RDPG model is its suitability for undirected and unweighted graphs only, a gap we aim to close here to broaden the scope of the CPD framework. Unlike previous proposals, our non-parametric RDPG model for weighted graphs does not require a priori specification of the weights' distribution to perform inference and estimation. This network modeling contribution is of independent interest beyond CPD. We offer an open-source implementation of the novel online CPD algorithm for weighted and direct graphs, whose effectiveness and efficiency are demonstrated via (reproducible) synthetic and real network data experiments.
AutoDES: AutoML Pipeline Generation of Classification with Dynamic Ensemble Strategy Selection
Jan 01, 2022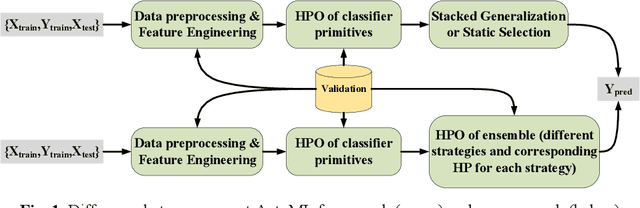

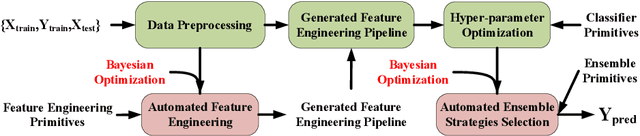

Automating machine learning has achieved remarkable technological developments in recent years, and building an automated machine learning pipeline is now an essential task. The model ensemble is the technique of combining multiple models to get a better and more robust model. However, existing automated machine learning tends to be simplistic in handling the model ensemble, where the ensemble strategy is fixed, such as stacked generalization. There have been many techniques on different ensemble methods, especially ensemble selection, and the fixed ensemble strategy limits the upper limit of the model's performance. In this article, we present a novel framework for automated machine learning. Our framework incorporates advances in dynamic ensemble selection, and to our best knowledge, our approach is the first in the field of AutoML to search and optimize ensemble strategies. In the comparison experiments, our method outperforms the state-of-the-art automated machine learning frameworks with the same CPU time in 42 classification datasets from the OpenML platform. Ablation experiments on our framework validate the effectiveness of our proposed method.
Generative Trees: Adversarial and Copycat
Jan 26, 2022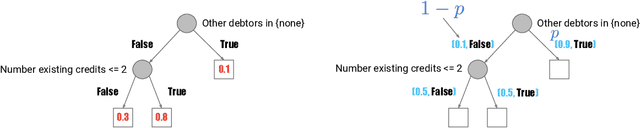

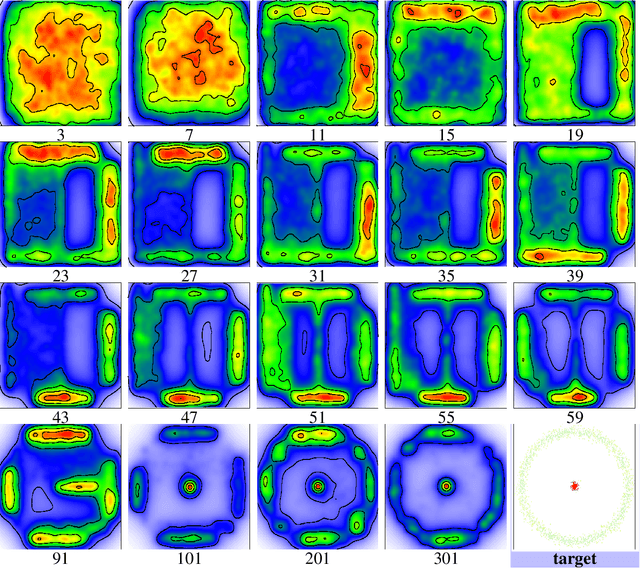
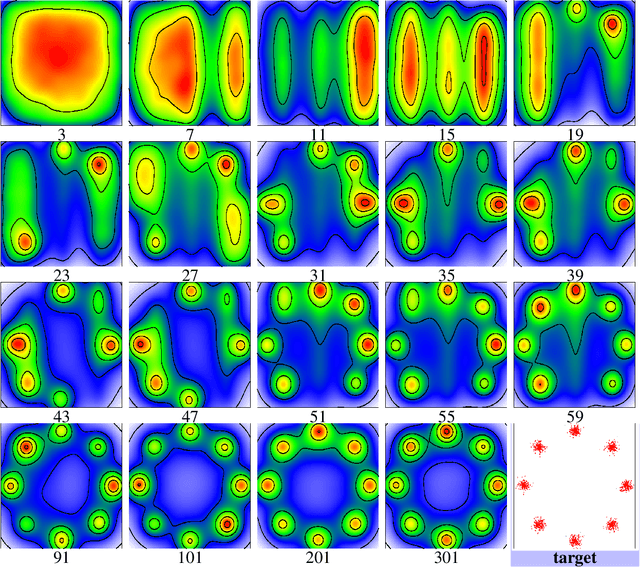
While Generative Adversarial Networks (GANs) achieve spectacular results on unstructured data like images, there is still a gap on tabular data, data for which state of the art supervised learning still favours to a large extent decision tree (DT)-based models. This paper proposes a new path forward for the generation of tabular data, exploiting decades-old understanding of the supervised task's best components for DT induction, from losses (properness), models (tree-based) to algorithms (boosting). The \textit{properness} condition on the supervised loss -- which postulates the optimality of Bayes rule -- leads us to a variational GAN-style loss formulation which is \textit{tight} when discriminators meet a calibration property trivially satisfied by DTs, and, under common assumptions about the supervised loss, yields "one loss to train against them all" for the generator: the $\chi^2$. We then introduce tree-based generative models, \textit{generative trees} (GTs), meant to mirror on the generative side the good properties of DTs for classifying tabular data, with a boosting-compliant \textit{adversarial} training algorithm for GTs. We also introduce \textit{copycat training}, in which the generator copies at run time the underlying tree (graph) of the discriminator DT and completes it for the hardest discriminative task, with boosting compliant convergence. We test our algorithms on tasks including fake/real distinction, training from fake data and missing data imputation. Each one of these tasks displays that GTs can provide comparatively simple -- and interpretable -- contenders to sophisticated state of the art methods for data generation (using neural network models) or missing data imputation (relying on multiple imputation by chained equations with complex tree-based modeling).