 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Federated Reinforcement Learning at the Edge
Dec 11, 2021
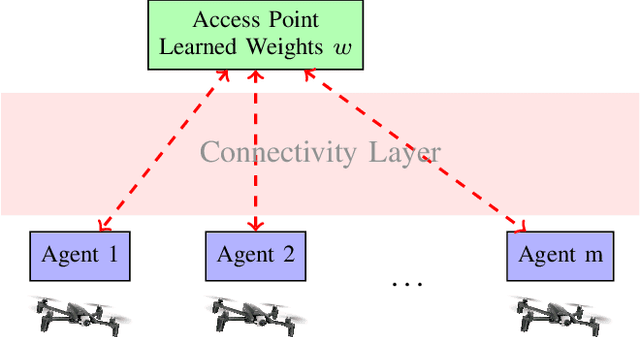
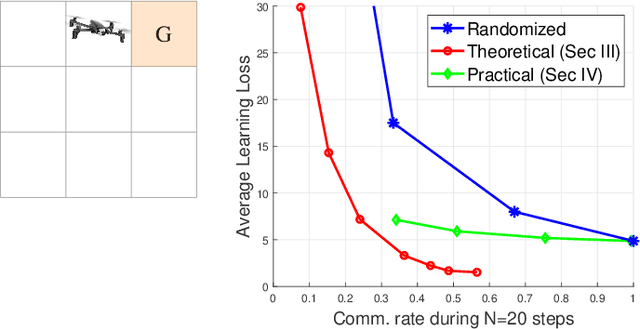
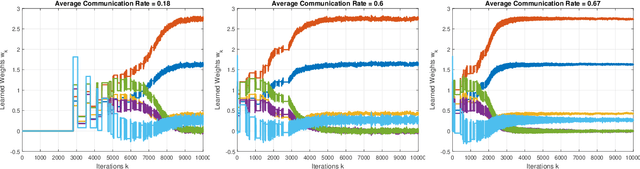
Modern cyber-physical architectures use data collected from systems at different physical locations to learn appropriate behaviors and adapt to uncertain environments. However, an important challenge arises as communication exchanges at the edge of networked systems are costly due to limited resources. This paper considers a setup where multiple agents need to communicate efficiently in order to jointly solve a reinforcement learning problem over time-series data collected in a distributed manner. This is posed as learning an approximate value function over a communication network. An algorithm for achieving communication efficiency is proposed, supported with theoretical guarantees, practical implementations, and numerical evaluations. The approach is based on the idea of communicating only when sufficiently informative data is collected.
Synthetic Velocity Mapping Cardiac MRI Coupled with Automated Left Ventricle Segmentation
Oct 04, 2021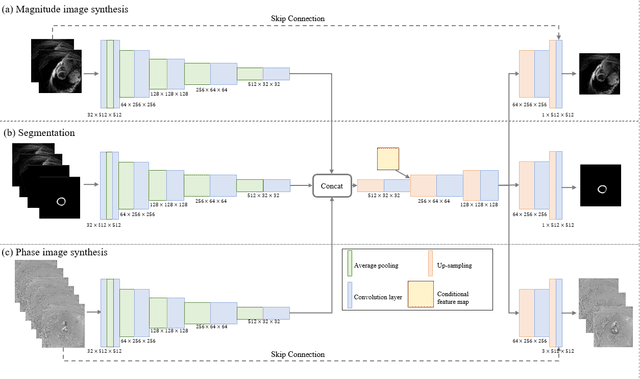
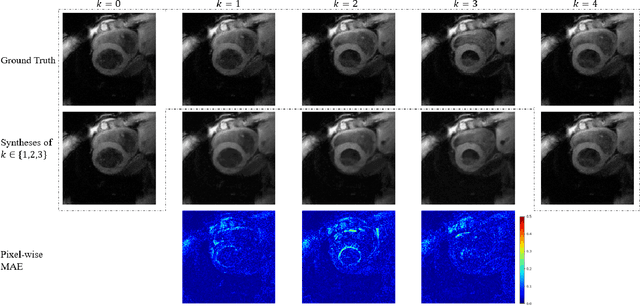
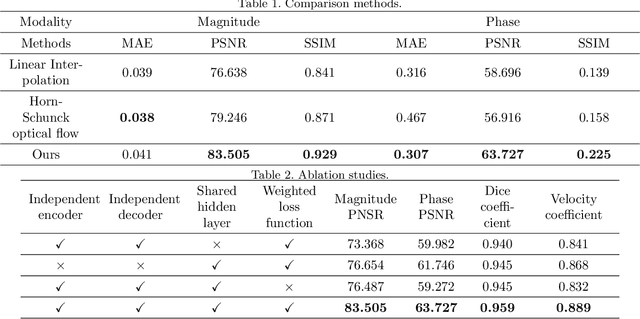
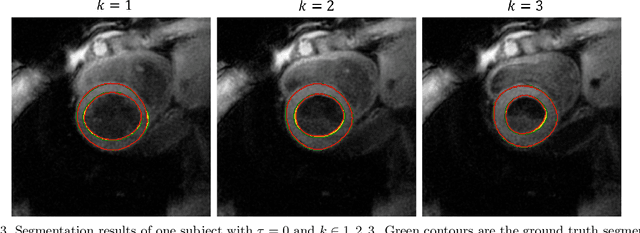
Temporal patterns of cardiac motion provide important information for cardiac disease diagnosis. This pattern could be obtained by three-directional CINE multi-slice left ventricular myocardial velocity mapping (3Dir MVM), which is a cardiac MR technique providing magnitude and phase information of the myocardial motion simultaneously. However, long acquisition time limits the usage of this technique by causing breathing artifacts, while shortening the time causes low temporal resolution and may provide an inaccurate assessment of cardiac motion. In this study, we proposed a frame synthesis algorithm to increase the temporal resolution of 3Dir MVM data. Our algorithm is featured by 1) three attention-based encoders which accept magnitude images, phase images, and myocardium segmentation masks respectively as inputs; 2) three decoders that output the interpolated frames and corresponding myocardium segmentation results; and 3) loss functions highlighting myocardium pixels. Our algorithm can not only increase the temporal resolution 3Dir MVMs, but can also generates the myocardium segmentation results at the same time.
InceptionTime: Finding AlexNet for Time Series Classification
Sep 13, 2019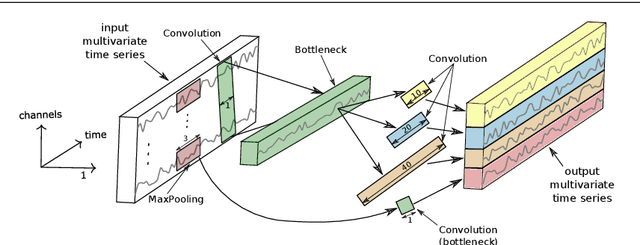
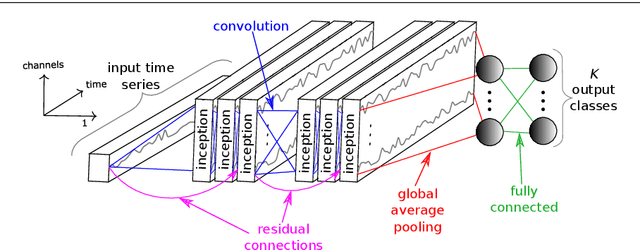
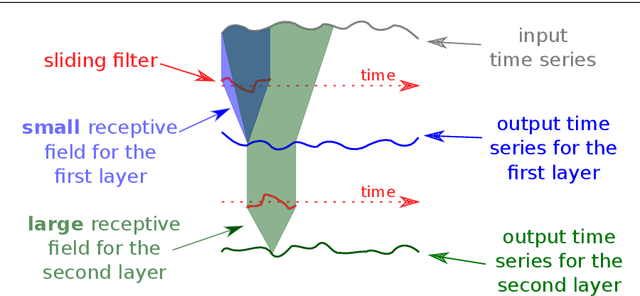
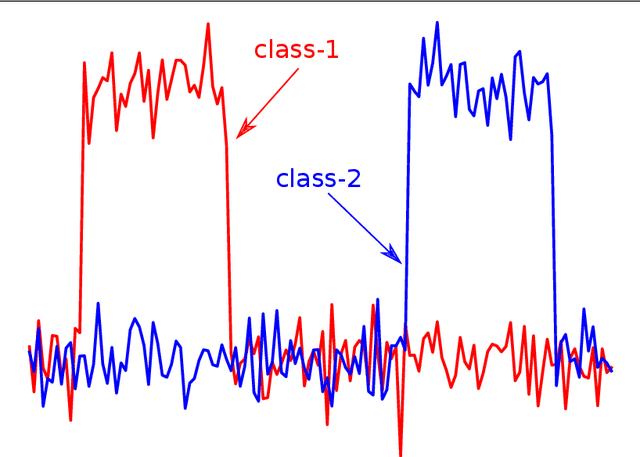
Time series classification (TSC) is the area of machine learning interested in learning how to assign labels to time series. The last few decades of work in this area have led to significant progress in the accuracy of classifiers, with the state of the art now represented by the HIVE-COTE algorithm. While extremely accurate, HIVE-COTE is infeasible to use in many applications because of its very high training time complexity in O(N^2*T^4) for a dataset with N time series of length T. For example, it takes HIVE-COTE more than 72,000s to learn from a small dataset with N=700 time series of short length T=46. Deep learning, on the other hand, has now received enormous attention because of its high scalability and state-of-the-art accuracy in computer vision and natural language processing tasks. Deep learning for TSC has only very recently started to be explored, with the first few architectures developed over the last 3 years only. The accuracy of deep learning for TSC has been raised to a competitive level, but has not quite reached the level of HIVE-COTE. This is what this paper achieves: outperforming HIVE-COTE's accuracy together with scalability. We take an important step towards finding the AlexNet network for TSC by presenting InceptionTime---an ensemble of deep Convolutional Neural Network (CNN) models, inspired by the Inception-v4 architecture. Our experiments show that InceptionTime slightly outperforms HIVE-COTE with a win/draw/loss on the UCR archive of 40/6/39. Not only is InceptionTime more accurate, but it is much faster: InceptionTime learns from that same dataset with 700 time series in 2,300s but can also learn from a dataset with 8M time series in 13 hours, a quantity of data that is fully out of reach of HIVE-COTE.
Scoring and Assessment in Medical VR Training Simulators with Dynamic Time Series Classification
Jun 11, 2020
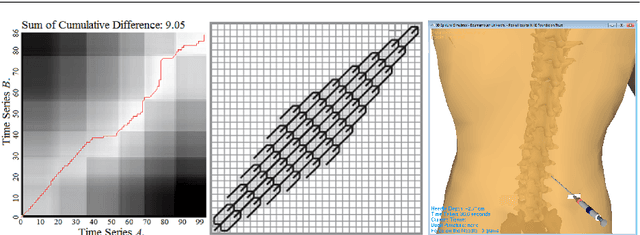

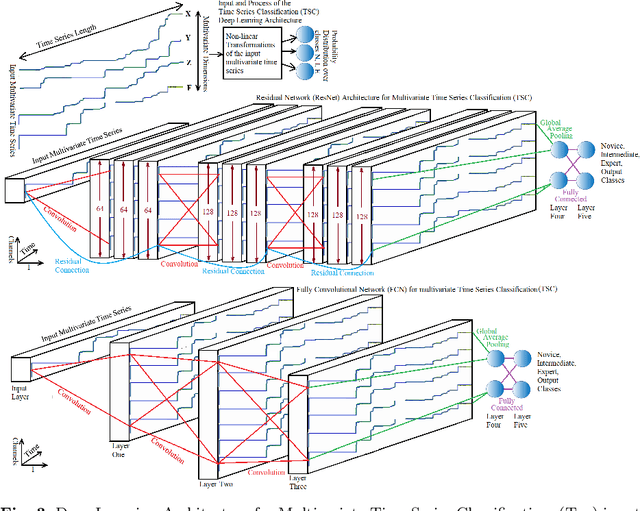
This research proposes and evaluates scoring and assessment methods for Virtual Reality (VR) training simulators. VR simulators capture detailed n-dimensional human motion data which is useful for performance analysis. Custom made medical haptic VR training simulators were developed and used to record data from 271 trainees of multiple clinical experience levels. DTW Multivariate Prototyping (DTW-MP) is proposed. VR data was classified as Novice, Intermediate or Expert. Accuracy of algorithms applied for time-series classification were: dynamic time warping 1-nearest neighbor (DTW-1NN) 60%, nearest centroid SoftDTW classification 77.5%, Deep Learning: ResNet 85%, FCN 75%, CNN 72.5% and MCDCNN 28.5%. Expert VR data recordings can be used for guidance of novices. Assessment feedback can help trainees to improve skills and consistency. Motion analysis can identify different techniques used by individuals. Mistakes can be detected dynamically in real-time, raising alarms to prevent injuries.
* Copyright 2020. This manuscript version is made available under CC-BY-NC-ND 4.0 license http://creativecommons.org/licenses/by-nc-nd/4.0/
A Device and Method to Identify Hip, Knee and Ankle Joint Impedance During Walking
Dec 10, 2021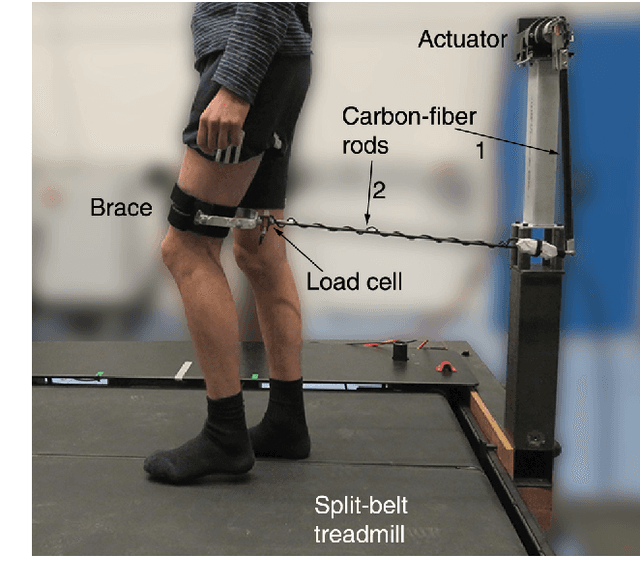
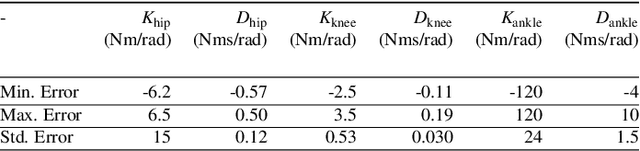
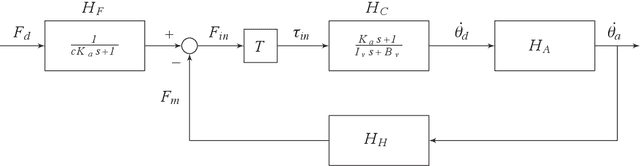
Knowledge on joint impedance during walking in various conditions is relevant for clinical decision making and the development of robotic gait trainers, leg prostheses, leg orthotics, and wearable exoskeletons. Whereas ankle impedance during walking has been experimentally assessed, knee and hip joint impedance during walking have not been identified yet. Here we developed and evaluated a lower limb perturbator to identify hip, knee and ankle joint impedance during treadmill walking. The lower limb perturbator (LOPER) consists of an actuator connected to the thigh via rods. The LOPER allows to apply force perturbations to a free-hanging leg, while standing on the contralateral leg, with a bandwidth of up to 39Hz. While walking in minimal impedance mode, the interaction forces between LOPER and the thigh were low (<5N) and the effect on the walking pattern was smaller than the within-subject variability during normal walking. Using a non-linear multibody dynamical model of swing leg dynamics, the hip, knee and ankle joint impedance were estimated at three time points during the swing phase for nine subjects walking at a speed of 0.5 m/s. The identified model was well able to predict the experimental responses, since the mean variance accounted for was 99%, 96%, and 77%, for the hip, knee and ankle respectively. The averaged across subjects stiffness varied between the three time point within 34-66 Nm/rad, 0-3.5 Nm/rad, and 2.5-24 Nm/rad for the hip, knee and ankle joint respectively. The damping varied between 1.9-4.6 Nms/rad, 0.02-0.14 Nms/rad, and 0.2-2.4 Nms/rad for hip, knee, and ankle respectively. The developed LOPER has a negligible effect on the unperturbed walking pattern and allows to identify hip, knee and ankle joint impedance during the swing phase.
On Complexity of 1-Center in Various Metrics
Dec 06, 2021We consider the classic 1-center problem: Given a set P of n points in a metric space find the point in P that minimizes the maximum distance to the other points of P. We study the complexity of this problem in d-dimensional $\ell_p$-metrics and in edit and Ulam metrics over strings of length d. Our results for the 1-center problem may be classified based on d as follows. $\bullet$ Small d: We provide the first linear-time algorithm for 1-center problem in fixed-dimensional $\ell_1$ metrics. On the other hand, assuming the hitting set conjecture (HSC), we show that when $d=\omega(\log n)$, no subquadratic algorithm can solve 1-center problem in any of the $\ell_p$-metrics, or in edit or Ulam metrics. $\bullet$ Large d. When $d=\Omega(n)$, we extend our conditional lower bound to rule out sub quartic algorithms for 1-center problem in edit metric (assuming Quantified SETH). On the other hand, we give a $(1+\epsilon)$-approximation for 1-center in Ulam metric with running time $\tilde{O_{\epsilon}}(nd+n^2\sqrt{d})$. We also strengthen some of the above lower bounds by allowing approximations or by reducing the dimension d, but only against a weaker class of algorithms which list all requisite solutions. Moreover, we extend one of our hardness results to rule out subquartic algorithms for the well-studied 1-median problem in the edit metric, where given a set of n strings each of length n, the goal is to find a string in the set that minimizes the sum of the edit distances to the rest of the strings in the set.
DeepSampling: Selectivity Estimation with Predicted Error and Response Time
Aug 16, 2020
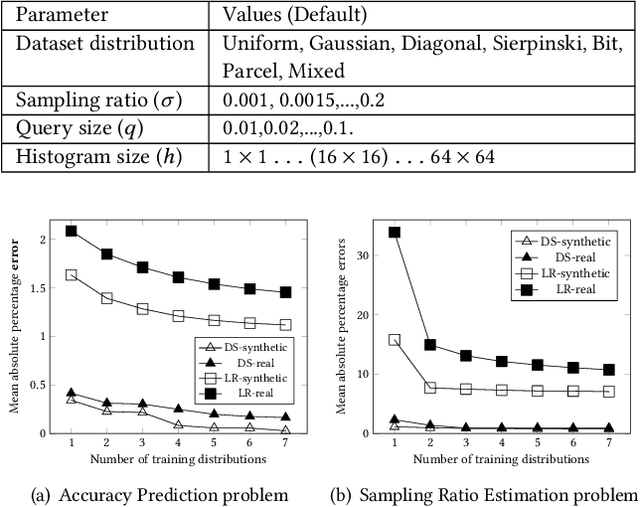
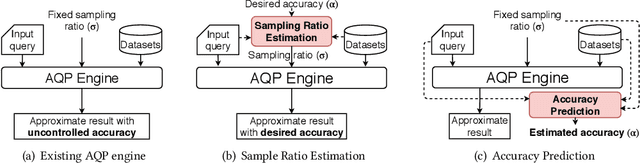
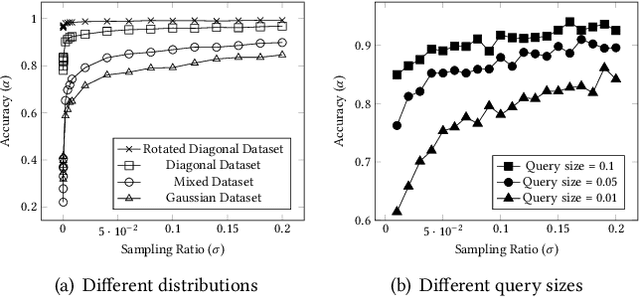
The rapid growth of spatial data urges the research community to find efficient processing techniques for interactive queries on large volumes of data. Approximate Query Processing (AQP) is the most prominent technique that can provide real-time answer for ad-hoc queries based on a random sample. Unfortunately, existing AQP methods provide an answer without providing any accuracy metrics due to the complex relationship between the sample size, the query parameters, the data distribution, and the result accuracy. This paper proposes DeepSampling, a deep-learning-based model that predicts the accuracy of a sample-based AQP algorithm, specially selectivity estimation, given the sample size, the input distribution, and query parameters. The model can also be reversed to measure the sample size that would produce a desired accuracy. DeepSampling is the first system that provides a reliable tool for existing spatial databases to control the accuracy of AQP.
* 9 pages, published in DeepSpatial 2020
SC-Reg: Training Overparameterized Neural Networks under Self-Concordant Regularization
Dec 14, 2021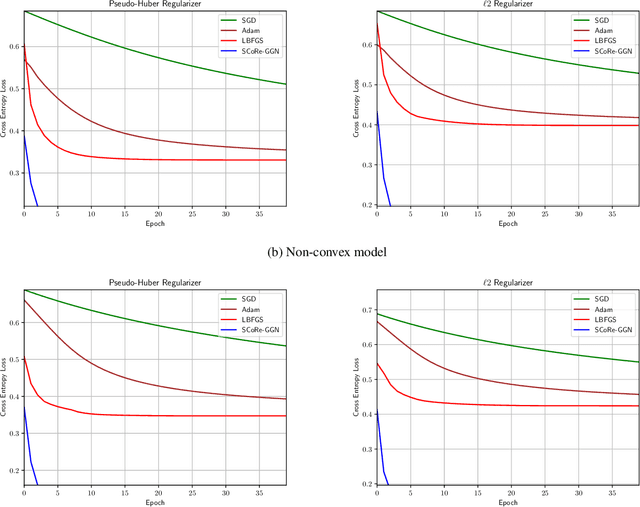

In this paper we propose the SC-Reg (self-concordant regularization) framework for learning overparameterized feedforward neural networks by incorporating second-order information in the \emph{Newton decrement} framework for convex problems. We propose the generalized Gauss-Newton with Self-Concordant Regularization (SCoRe-GGN) algorithm that updates the network parameters each time it receives a new input batch. The proposed algorithm exploits the structure of the second-order information in the Hessian matrix, thereby reducing the training computational overhead. Although our current analysis considers only the convex case, numerical experiments show the efficiency of our method and its fast convergence under both convex and non-convex settings, which compare favorably against baseline first-order methods and a quasi-Newton method.
Responsive Listening Head Generation: A Benchmark Dataset and Baseline
Dec 27, 2021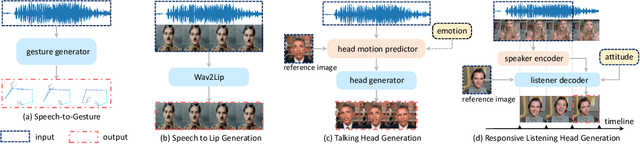

Responsive listening during face-to-face conversations is a critical element of social interaction and is well established in psychological research. Through non-verbal signals response to the speakers' words, intonations, or behaviors in real-time, listeners show how they are engaged in dialogue. In this work, we build the Responsive Listener Dataset (RLD), a conversation video corpus collected from the public resources featuring 67 speakers, 76 listeners with three different attitudes. We define the responsive listening head generation task as the synthesis of a non-verbal head with motions and expressions reacting to the multiple inputs, including the audio and visual signal of the speaker. Unlike speech-driven gesture or talking head generation, we introduce more modals in this task, hoping to benefit several research fields, including human-to-human interaction, video-to-video translation, cross-modal understanding, and generation. Furthermore, we release an attitude conditioned listening head generation baseline. Project page: \url{https://project.mhzhou.com/rld}.
Enhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022
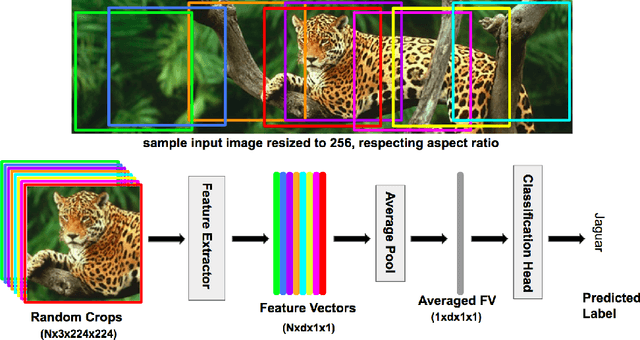
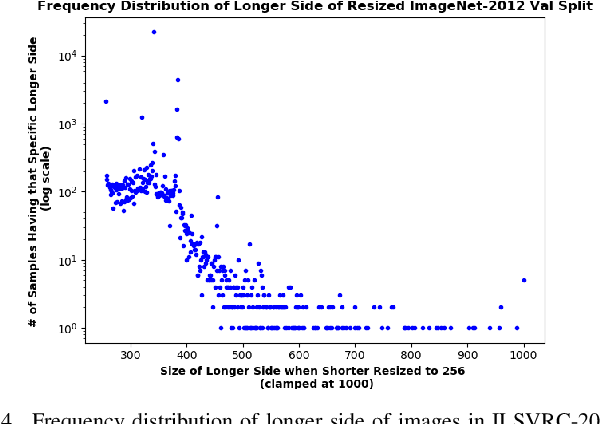
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.