 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scaling Up Knowledge Graph Creation to Large and Heterogeneous Data Sources
Jan 24, 2022
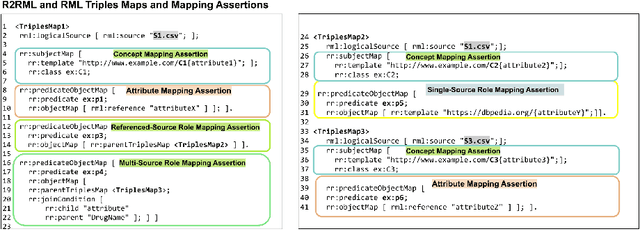
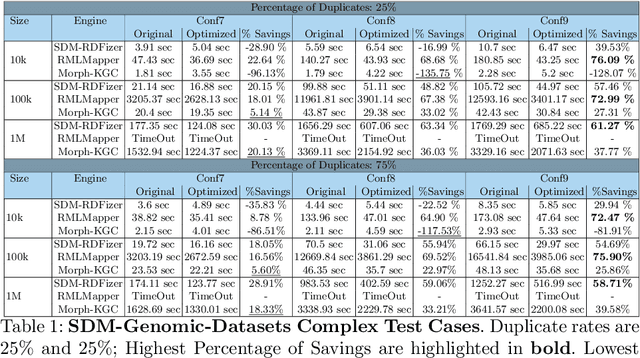
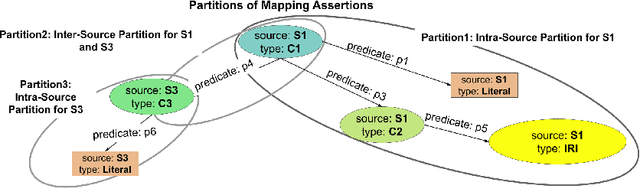
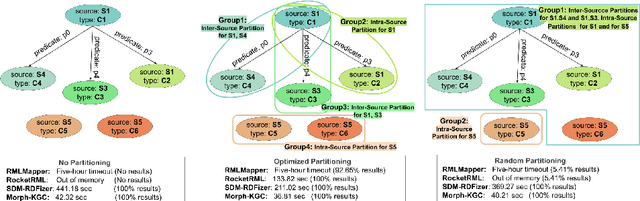
RDF knowledge graphs (KG) are powerful data structures to represent factual statements created from heterogeneous data sources. KG creation is laborious, and demands data management techniques to be executed efficiently. This paper tackles the problem of the automatic generation of KG creation processes declaratively specified; it proposes techniques for planning and transforming heterogeneous data into RDF triples following mapping assertions specified in the RDF Mapping Language (RML). Given a set of mapping assertions, the planner provides an optimized execution plan by partitioning and scheduling the execution of the assertions. First, the planner assesses an optimized number of partitions considering the number of data sources, type of mapping assertions, and the associations between different assertions. After providing a list of partitions and assertions that belong to each partition, the planner determines their execution order. A greedy algorithm is implemented to generate the partitions' bushy tree execution plan. Bushy tree plans are translated into operating system commands that guide the execution of the partitions of the mapping assertions in the order indicated by the bushy tree. The proposed optimization approach is evaluated over state-of-the-art RML-compliant engines and existing benchmarks of data sources and RML triples maps. Our experimental results suggest that the performance of the studied engines can be considerably improved, particularly in a complex setting with numerous triples maps and data sources. As a result, engines that usually time in complex cases out can, if not entirely execute all the assertions, still produce a portion of the KG.
Accelerated Projected Gradient Method for the Optimization of Cell-Free Massive MIMO Downlink
Jan 12, 2022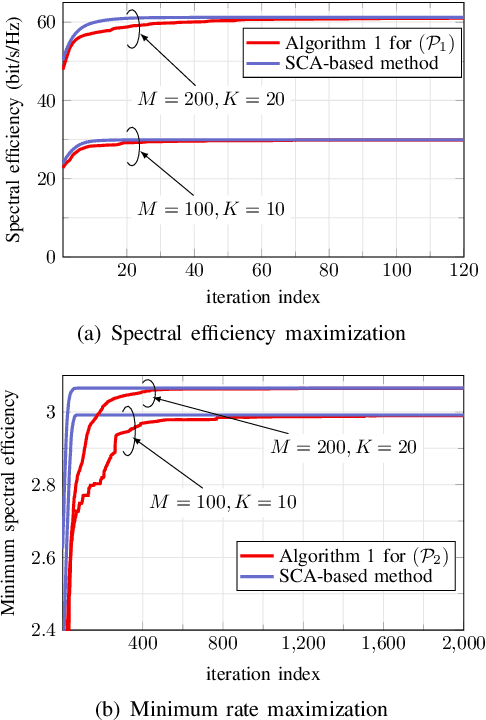
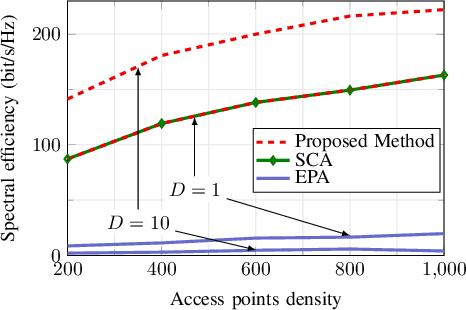
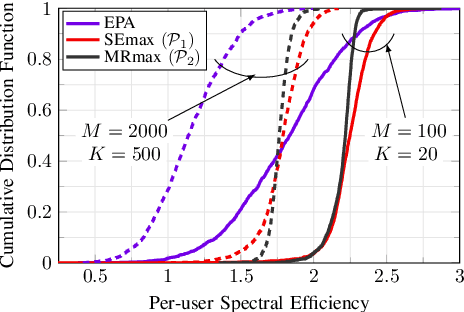
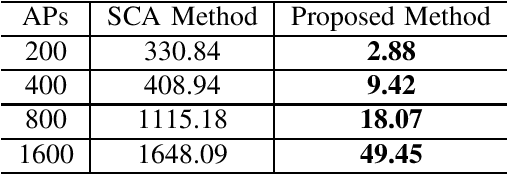
We consider the downlink of a cell-free massive multiple-input multiple-output (MIMO) system where large number of access points (APs) simultaneously serve a group of users. Two fundamental problems are of interest, namely (i) to maximize the total spectral efficiency (SE), and (ii) to maximize the minimum SE of all users. As the considered problems are non-convex, existing solutions rely on successive convex approximation to find a sub-optimal solution. The known methods use off-the-shelf convex solvers, which basically implement an interior-point algorithm, to solve the derived convex problems. The main issue of such methods is that their complexity does not scale favorably with the problem size, limiting previous studies to cell-free massive MIMO of moderate scales. Thus the potential of cell-free massive MIMO has not been fully understood. To address this issue, we propose an accelerated projected gradient method to solve the considered problems. Particularly, the proposed solution is found in closed-form expressions and only requires the first order information of the objective, rather than the Hessian matrix as in known solutions, and thus is much more memory efficient. Numerical results demonstrate that our proposed solution achieves far less run-time, compared to other second-order methods.
Finite-Time Last-Iterate Convergence for Multi-Agent Learning in Games
Feb 23, 2020We consider multi-agent learning via online gradient descent (OGD) in a class of games called $\lambda$-cocoercive games, a broad class of games that admits many Nash equilibria and that properly includes strongly monotone games. We characterize the finite-time last-iterate convergence rate for joint OGD learning on $\lambda$-cocoercive games; further, building on this result, we develop a fully adaptive OGD learning algorithm that does not require any knowledge of the problem parameter (e.g., the cocoercive constant $\lambda$) and show, via a novel double-stopping-time technique, that this adaptive algorithm achieves the same finite-time last-iterate convergence rate as its non-adaptive counterpart. Subsequently, we extend OGD learning to the noisy gradient feedback case and establish last-iterate convergence results---first qualitative almost sure convergence, then quantitative finite-time convergence rates---all under non-decreasing step-sizes. These results fill in several gaps in the existing multi-agent online learning literature, where three aspects---finite-time convergence rates, non-decreasing step-sizes, and fully adaptive algorithms---have not been previously explored.
Soft Robotic Finger with Variable Effective Length enabled by an Antagonistic Constraint Mechanism
Dec 28, 2021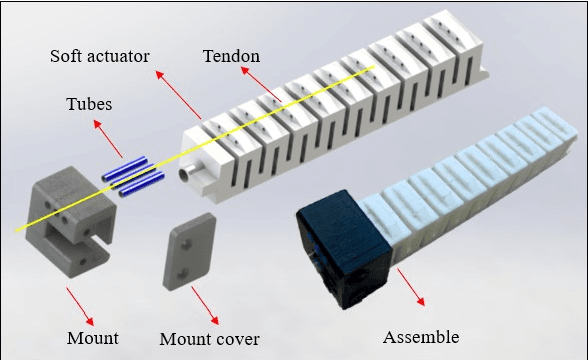
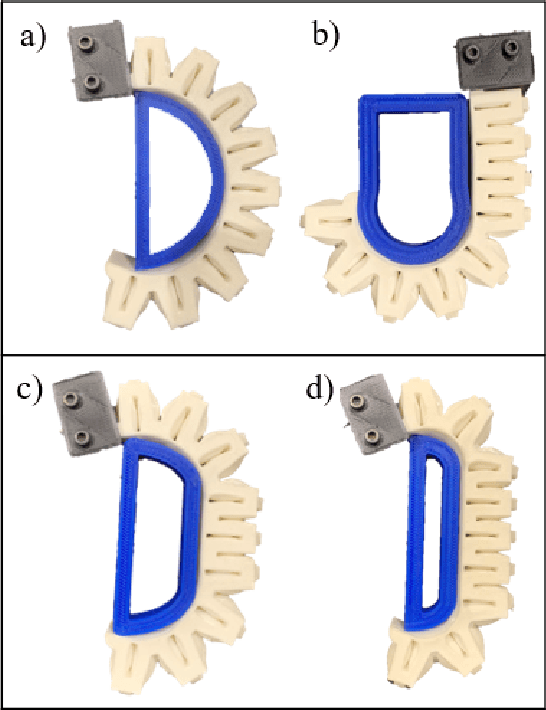


Compared to traditional rigid robotics, soft robotics has attracted increasing attention due to its advantages as compliance, safety, and low cost. As an essential part of soft robotics, the soft robotic gripper also shows its superior while grasping the objects with irregular shapes. Recent research has been conducted to improve its grasping performance by adjusting the variable effective length (VEL). However, the VEL achieved by multi-chamber design or tunable stiffness shape memory material requires complex pneumatic circuit design or a time-consuming phase-changing process. This work proposes a fold-based soft robotic actuator made from 3D printed filament, NinjaFlex. It is experimentally tested and represented by the hyperelastic model. Mathematic and finite element modelling is conducted to study the bending behaviour of the proposed soft actuator. Besides, an antagonistic constraint mechanism is proposed to achieve the VEL, and the experiments demonstrate that better conformity is achieved. Finally, a two-mode gripper is designed and evaluated to demonstrate the advances of VEL on grasping performance.
Evolutionary Optimization of High-Coverage Budgeted Classifiers
Nov 01, 2021
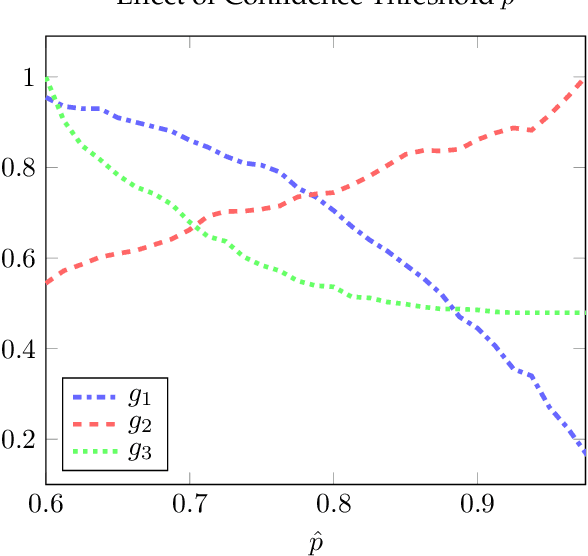
Classifiers are often utilized in time-constrained settings where labels must be assigned to inputs quickly. To address these scenarios, budgeted multi-stage classifiers (MSC) process inputs through a sequence of partial feature acquisition and evaluation steps with early-exit options until a confident prediction can be made. This allows for fast evaluation that can prevent expensive, unnecessary feature acquisition in time-critical instances. However, performance of MSCs is highly sensitive to several design aspects -- making optimization of these systems an important but difficult problem. To approximate an initially intractable combinatorial problem, current approaches to MSC configuration rely on well-behaved surrogate loss functions accounting for two primary objectives (processing cost, error). These approaches have proven useful in many scenarios but are limited by analytic constraints (convexity, smoothness, etc.) and do not manage additional performance objectives. Notably, such methods do not explicitly account for an important aspect of real-time detection systems -- the ratio of "accepted" predictions satisfying some confidence criterion imposed by a risk-averse monitor. This paper proposes a problem-specific genetic algorithm, EMSCO, that incorporates a terminal reject option for indecisive predictions and treats MSC design as an evolutionary optimization problem with distinct objectives (accuracy, cost, coverage). The algorithm's design emphasizes Pareto efficiency while respecting a notion of aggregated performance via a unique scalarization. Experiments are conducted to demonstrate EMSCO's ability to find global optima in a variety of Theta(k^n) solution spaces, and multiple experiments show EMSCO is competitive with alternative budgeted approaches.
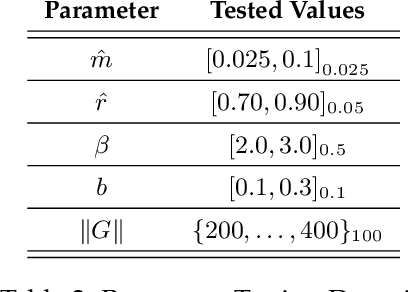
Digital RIS (DRIS): The Future of Digital Beam Management in RIS-Assisted OWC Systems
Dec 18, 2021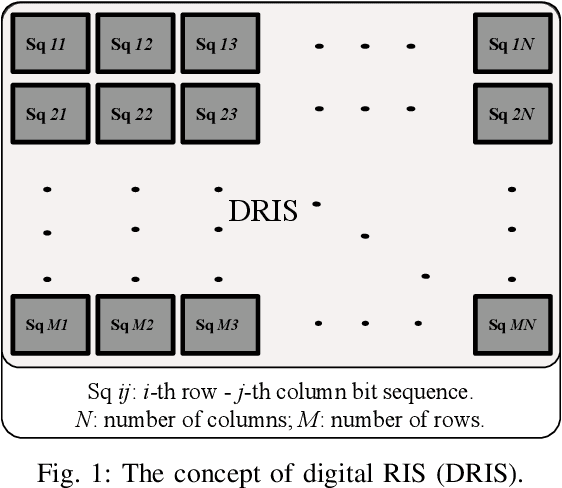
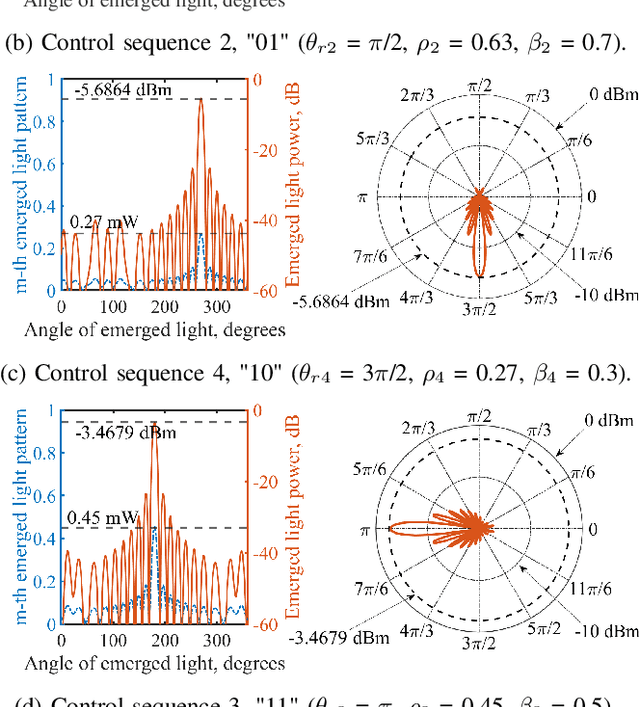
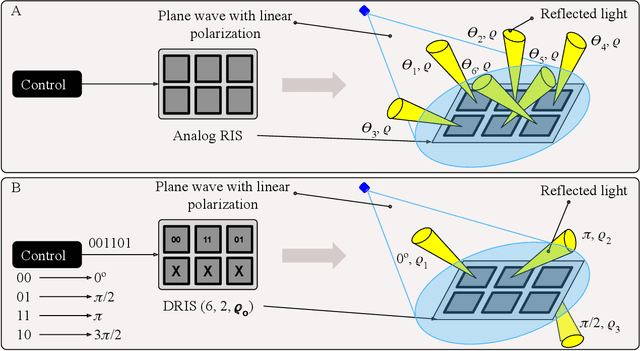
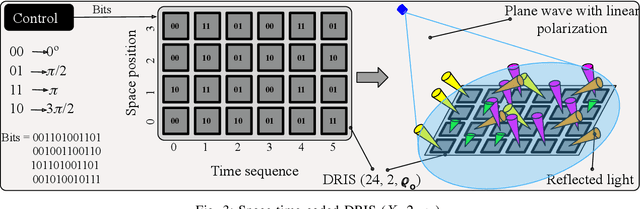
Reconfigurable intelligent surfaces (RIS) have been recently introduced to optical wireless communication (OWC) networks to resolve skip areas and improve the signal-to-noise ratio at the user's end. In OWC networks, RIS are based on mirrors or metasurfaces. Metasurfaces have evolved significantly over the last few years. As a result, coding, digital, programmable, and information metamaterials have been developed. The advantage of these materials is that they can enable digital signal processing (DSP) techniques. For the first time, this paper proposes the use of digital RIS (DRIS) in OWC systems. We discuss the concept of DRIS and the application of DSP methods to the physical material. In addition, we examine metamaterials for optical DRIS with liquid crystals serving as the front row material. Finally, we present a design example and discuss future research directions.
Learning with latent group sparsity via heat flow dynamics on networks
Jan 20, 2022
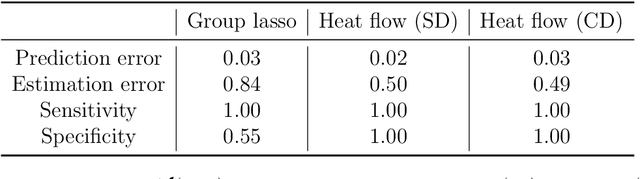
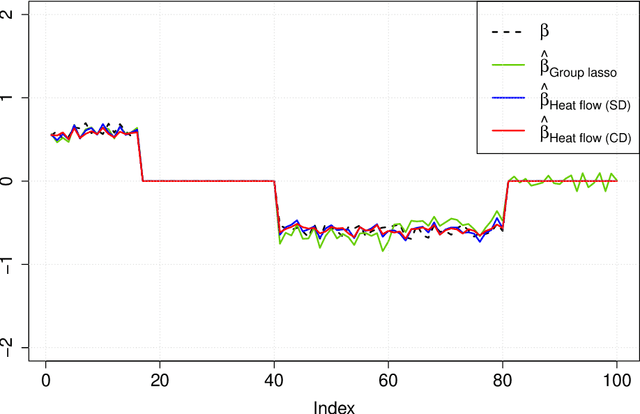
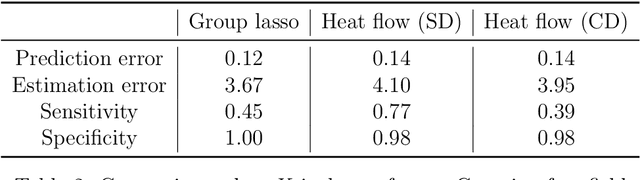
Group or cluster structure on explanatory variables in machine learning problems is a very general phenomenon, which has attracted broad interest from practitioners and theoreticians alike. In this work we contribute an approach to learning under such group structure, that does not require prior information on the group identities. Our paradigm is motivated by the Laplacian geometry of an underlying network with a related community structure, and proceeds by directly incorporating this into a penalty that is effectively computed via a heat flow-based local network dynamics. In fact, we demonstrate a procedure to construct such a network based on the available data. Notably, we dispense with computationally intensive pre-processing involving clustering of variables, spectral or otherwise. Our technique is underpinned by rigorous theorems that guarantee its effective performance and provide bounds on its sample complexity. In particular, in a wide range of settings, it provably suffices to run the heat flow dynamics for time that is only logarithmic in the problem dimensions. We explore in detail the interfaces of our approach with key statistical physics models in network science, such as the Gaussian Free Field and the Stochastic Block Model. We validate our approach by successful applications to real-world data from a wide array of application domains, including computer science, genetics, climatology and economics. Our work raises the possibility of applying similar diffusion-based techniques to classical learning tasks, exploiting the interplay between geometric, dynamical and stochastic structures underlying the data.
AGMI: Attention-Guided Multi-omics Integration for Drug Response Prediction with Graph Neural Networks
Dec 15, 2021



Accurate drug response prediction (DRP) is a crucial yet challenging task in precision medicine. This paper presents a novel Attention-Guided Multi-omics Integration (AGMI) approach for DRP, which first constructs a Multi-edge Graph (MeG) for each cell line, and then aggregates multi-omics features to predict drug response using a novel structure, called Graph edge-aware Network (GeNet). For the first time, our AGMI approach explores gene constraint based multi-omics integration for DRP with the whole-genome using GNNs. Empirical experiments on the CCLE and GDSC datasets show that our AGMI largely outperforms state-of-the-art DRP methods by 8.3%--34.2% on four metrics. Our data and code are available at https://github.com/yivan-WYYGDSG/AGMI.
Audio representations for deep learning in sound synthesis: A review
Jan 07, 2022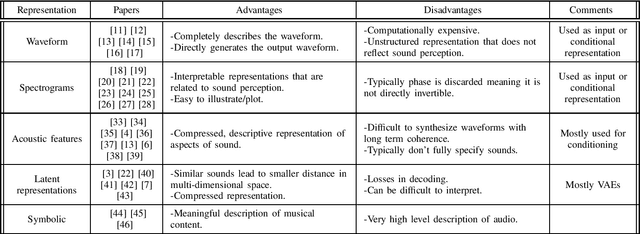
The rise of deep learning algorithms has led many researchers to withdraw from using classic signal processing methods for sound generation. Deep learning models have achieved expressive voice synthesis, realistic sound textures, and musical notes from virtual instruments. However, the most suitable deep learning architecture is still under investigation. The choice of architecture is tightly coupled to the audio representations. A sound's original waveform can be too dense and rich for deep learning models to deal with efficiently - and complexity increases training time and computational cost. Also, it does not represent sound in the manner in which it is perceived. Therefore, in many cases, the raw audio has been transformed into a compressed and more meaningful form using upsampling, feature-extraction, or even by adopting a higher level illustration of the waveform. Furthermore, conditional on the form chosen, additional conditioning representations, different model architectures, and numerous metrics for evaluating the reconstructed sound have been investigated. This paper provides an overview of audio representations applied to sound synthesis using deep learning. Additionally, it presents the most significant methods for developing and evaluating a sound synthesis architecture using deep learning models, always depending on the audio representation.
Optimal Trajectory Generation for Autonomous Vehicles Under Centripetal Acceleration Constraints for In-lane Driving Scenarios
Dec 03, 2021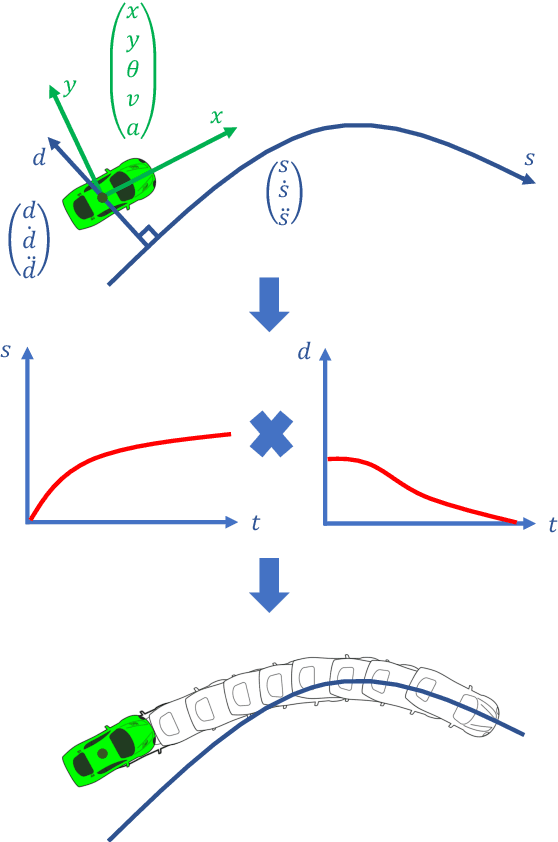
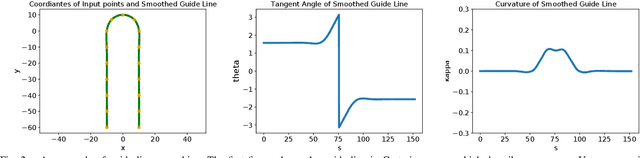
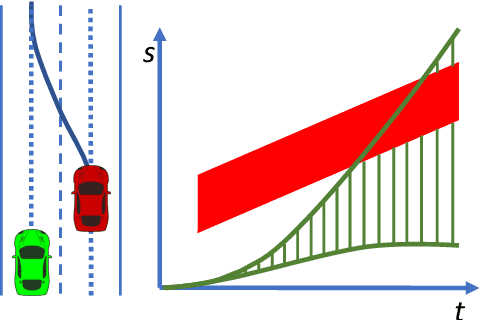
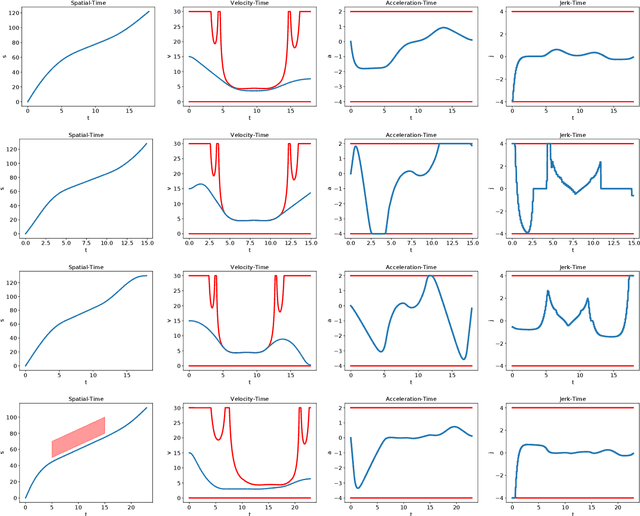
This paper presents a noval method that generates optimal trajectories for autonomous vehicles for in-lane driving scenarios. The method computes a trajectory using a two-phase optimization procedure. In the first phase, the optimization procedure generates a close-form driving guide line with differetiable curvatures. In the second phase, the procedure takes the driving guide line as input, and outputs dynamically feasible, jerk and time optimal trajectories for vehicles driving along the guide line. This method is especially useful for generating trajectories at curvy road where the vehicles need to apply frequent accelerations and decelerations to accommodate centripetal acceleration limits.