 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benchmarking Conventional Vision Models on Neuromorphic Fall Detection and Action Recognition Dataset
Jan 28, 2022

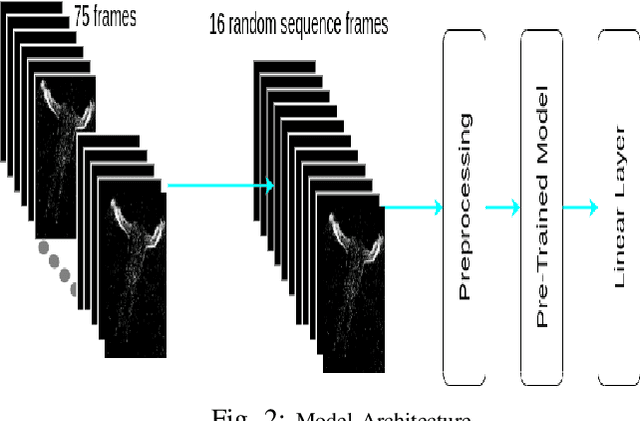
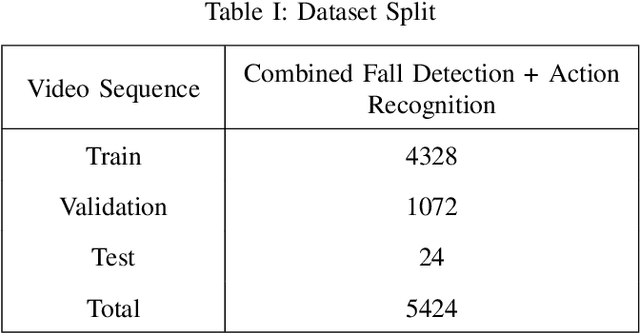
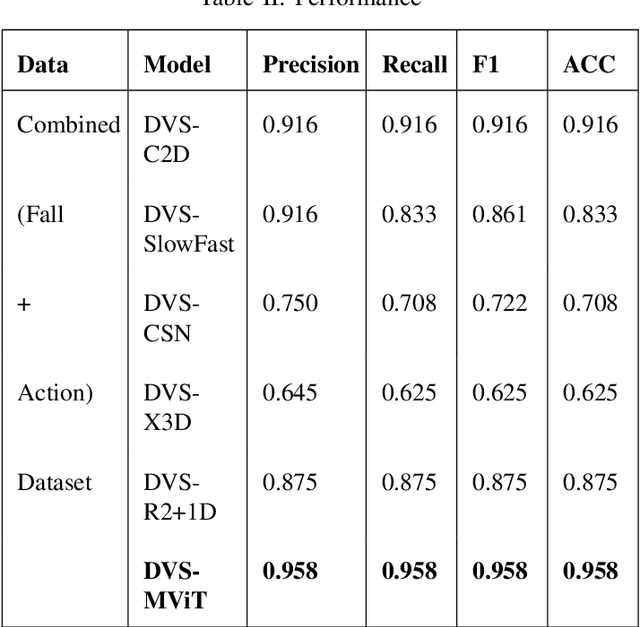
Neuromorphic vision-based sensors are gaining popularity in recent years with their ability to capture Spatio-temporal events with low power sensing. These sensors record events or spikes over traditional cameras which helps in preserving the privacy of the subject being recorded. These events are captured as per-pixel brightness changes and the output data stream is encoded with time, location, and pixel intensity change information. This paper proposes and benchmarks the performance of fine-tuned conventional vision models on neuromorphic human action recognition and fall detection datasets. The Spatio-temporal event streams from the Dynamic Vision Sensing cameras are encoded into a standard sequence image frames. These video frames are used for benchmarking conventional deep learning-based architectures. In this proposed approach, we fine-tuned the state-of-the-art vision models for this Dynamic Vision Sensing (DVS) application and named these models as DVS-R2+1D, DVS-CSN, DVS-C2D, DVS-SlowFast, DVS-X3D, and DVS-MViT. Upon comparing the performance of these models, we see the current state-of-the-art MViT based architecture DVS-MViT outperforms all the other models with an accuracy of 0.958 and an F-1 score of 0.958. The second best is the DVS-C2D with an accuracy of 0.916 and an F-1 score of 0.916. Third and Fourth are DVS-R2+1D and DVS-SlowFast with an accuracy of 0.875 and 0.833 and F-1 score of 0.875 and 0.861 respectively. DVS-CSN and DVS-X3D were the least performing models with an accuracy of 0.708 and 0.625 and an F1 score of 0.722 and 0.625 respectively.
Towards cyber-physical systems robust to communication delays: A differential game approach
Sep 21, 2021
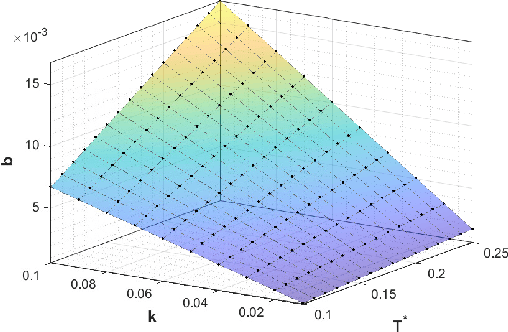
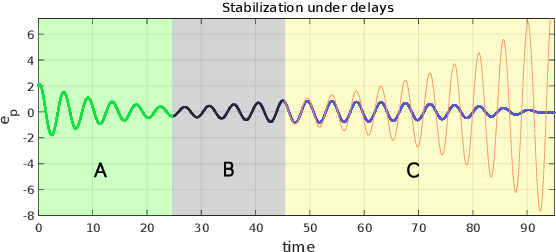
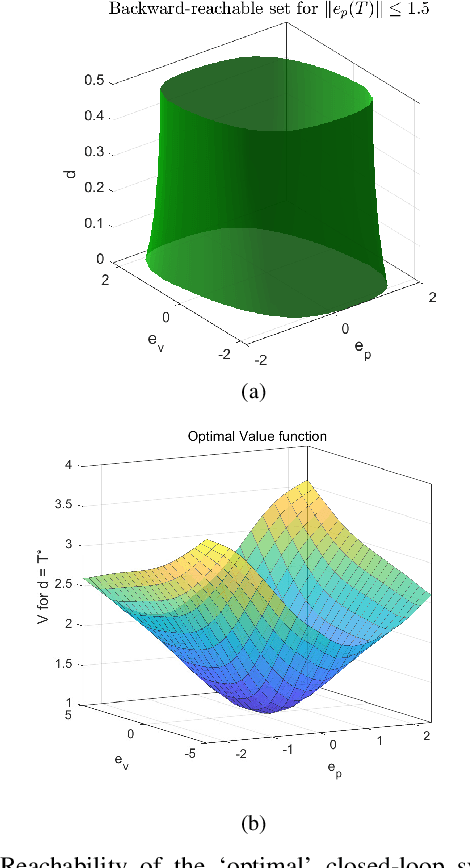
Collaboration between interconnected cyber-physical systems is becoming increasingly pervasive. Time-delays in communication channels between such systems are known to induce catastrophic failure modes, like high frequency oscillations in robotic manipulators in bilateral teleoperation or string instability in platoons of autonomous vehicles. This paper considers nonlinear time-delay systems representing coupled robotic agents, and proposes controllers that are robust to time-varying communication delays. We introduce approximations that allow the delays to be considered as implicit control inputs themselves, and formulate the problem as a zero-sum differential game between the stabilizing controllers and the delays acting adversarially. The ensuing optimal control law is finally compared to known results from Lyapunov-Krasovskii based approaches via numerical experiments.
Shimon the Rapper: A Real-Time System for Human-Robot Interactive Rap Battles
Sep 19, 2020
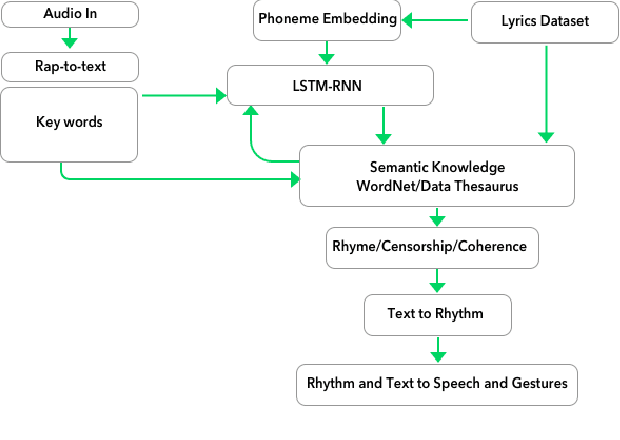
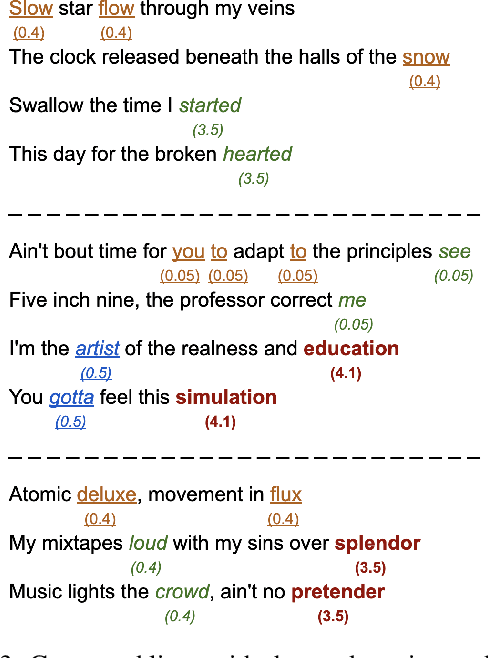

We present a system for real-time lyrical improvisation between a human and a robot in the style of hip hop. Our system takes vocal input from a human rapper, analyzes the semantic meaning, and generates a response that is rapped back by a robot over a musical groove. Previous work with real-time interactive music systems has largely focused on instrumental output, and vocal interactions with robots have been explored, but not in a musical context. Our generative system includes custom methods for censorship, voice, rhythm, rhyming and a novel deep learning pipeline based on phoneme embeddings. The rap performances are accompanied by synchronized robotic gestures and mouth movements. Key technical challenges that were overcome in the system are developing rhymes, performing with low-latency and dataset censorship. We evaluated several aspects of the system through a survey of videos and sample text output. Analysis of comments showed that the overall perception of the system was positive. The model trained on our hip hop dataset was rated significantly higher than our metal dataset in coherence, rhyme quality, and enjoyment. Participants preferred outputs generated by a given input phrase over outputs generated from unknown keywords, indicating that the system successfully relates its output to its input.
Visual Identification of Problematic Bias in Large Label Spaces
Jan 17, 2022

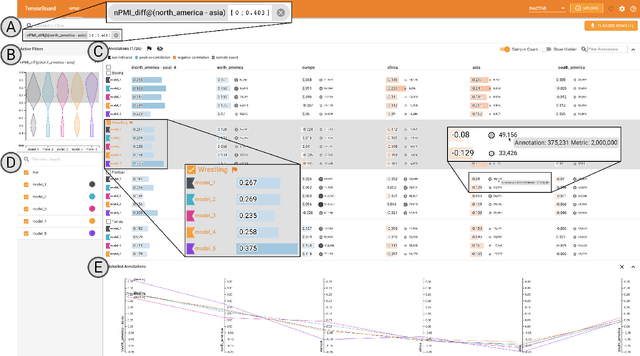
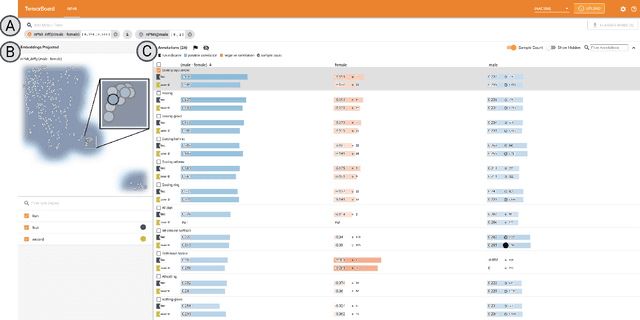
While the need for well-trained, fair ML systems is increasing ever more, measuring fairness for modern models and datasets is becoming increasingly difficult as they grow at an unprecedented pace. One key challenge in scaling common fairness metrics to such models and datasets is the requirement of exhaustive ground truth labeling, which cannot always be done. Indeed, this often rules out the application of traditional analysis metrics and systems. At the same time, ML-fairness assessments cannot be made algorithmically, as fairness is a highly subjective matter. Thus, domain experts need to be able to extract and reason about bias throughout models and datasets to make informed decisions. While visual analysis tools are of great help when investigating potential bias in DL models, none of the existing approaches have been designed for the specific tasks and challenges that arise in large label spaces. Addressing the lack of visualization work in this area, we propose guidelines for designing visualizations for such large label spaces, considering both technical and ethical issues. Our proposed visualization approach can be integrated into classical model and data pipelines, and we provide an implementation of our techniques open-sourced as a TensorBoard plug-in. With our approach, different models and datasets for large label spaces can be systematically and visually analyzed and compared to make informed fairness assessments tackling problematic bias.
Convolutional Neural Networks for Real-Time Localization and Classification in Feedback Digital Microscopy
Apr 10, 2020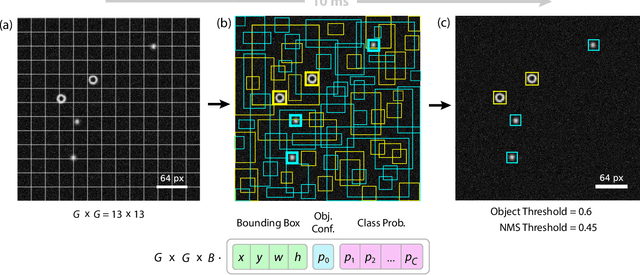
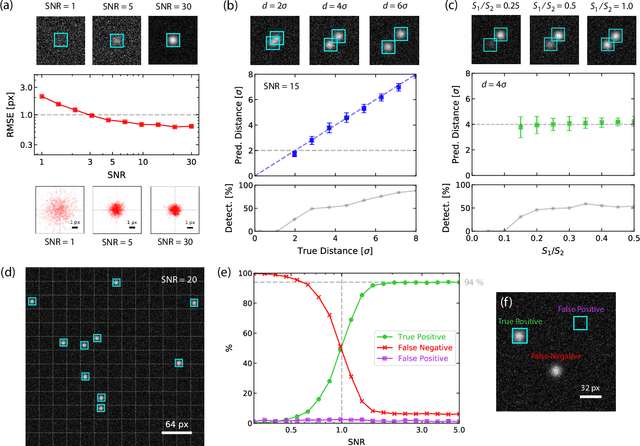
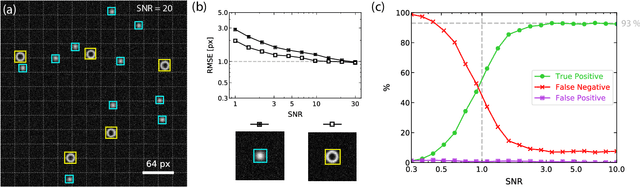

We present an adapted single-shot convolutional neural network (YOLOv2) for the real-time localization and classification of particles in optical microscopy. As compared to previous works, we focus on the real-time detection capabilities of the system to allow for manipulation of microscopic objects in large heterogeneous ensembles with the help of feedback control. The network is capable of localizing and classifying several hundreds of microscopic objects even at very low signal-to-noise ratios for images as large as 416x416 pixels with an inference time of about 10 ms. We demonstrate the real-time detection performance by manipulating active particles propelled by laser-induced self-thermophoresis. In order to make our framework readily available for others, we provide all scripts and source code. The network is implemented in Python/Keras using the TensorFlow backend. A C library supporting GPUs is provided for the real-time inference.
'Moving On' -- Investigating Inventors' Ethnic Origins Using Supervised Learning
Jan 03, 2022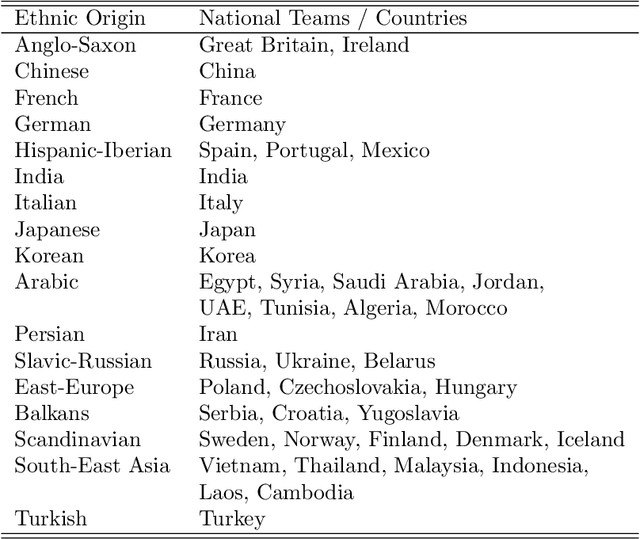
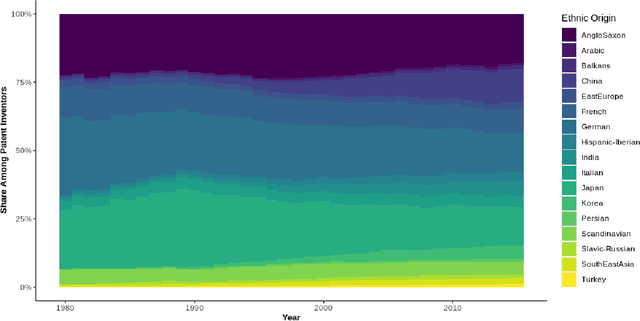
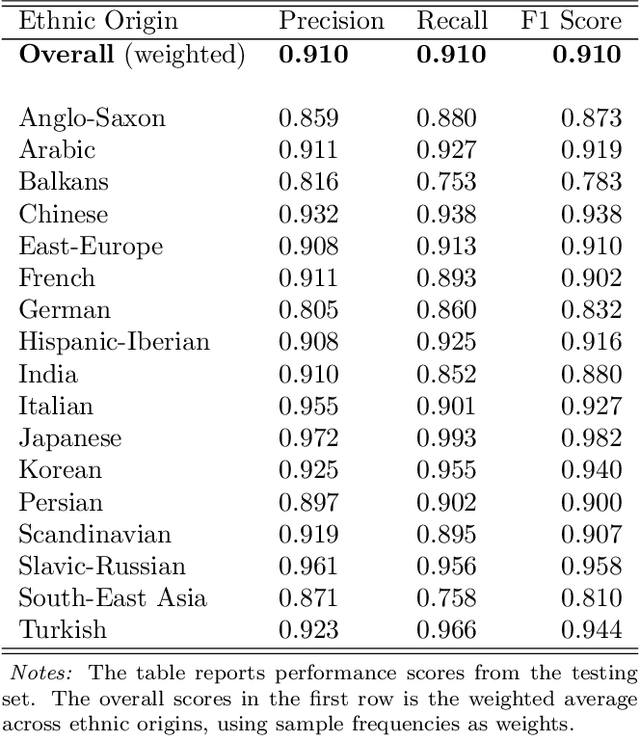
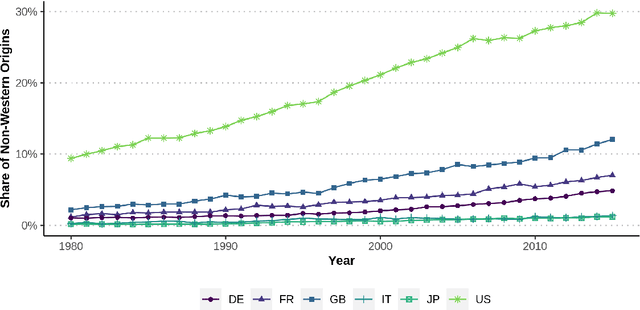
Patent data provides rich information about technical inventions, but does not disclose the ethnic origin of inventors. In this paper, I use supervised learning techniques to infer this information. To do so, I construct a dataset of 95'202 labeled names and train an artificial recurrent neural network with long-short-term memory (LSTM) to predict ethnic origins based on names. The trained network achieves an overall performance of 91% across 17 ethnic origins. I use this model to classify and investigate the ethnic origins of 2.68 million inventors and provide novel descriptive evidence regarding their ethnic origin composition over time and across countries and technological fields. The global ethnic origin composition has become more diverse over the last decades, which was mostly due to a relative increase of Asian origin inventors. Furthermore, the prevalence of foreign-origin inventors is especially high in the USA, but has also increased in other high-income economies. This increase was mainly driven by an inflow of non-western inventors into emerging high-technology fields for the USA, but not for other high-income countries.
Attention based Broadly Self-guided Network for Low light Image Enhancement
Dec 12, 2021
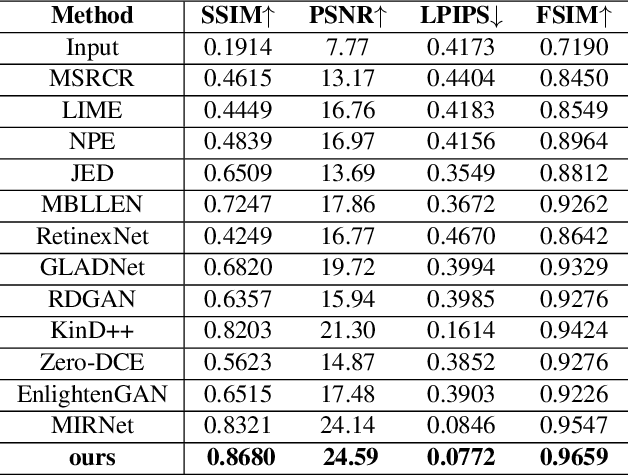
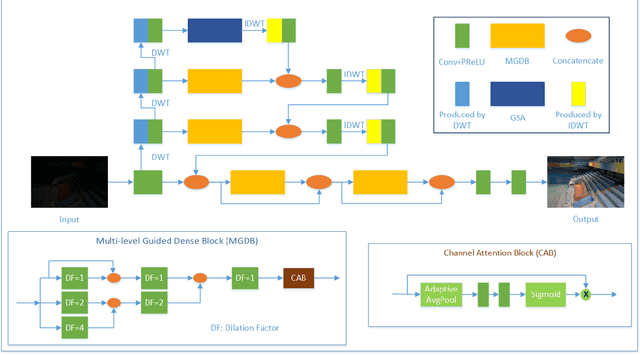
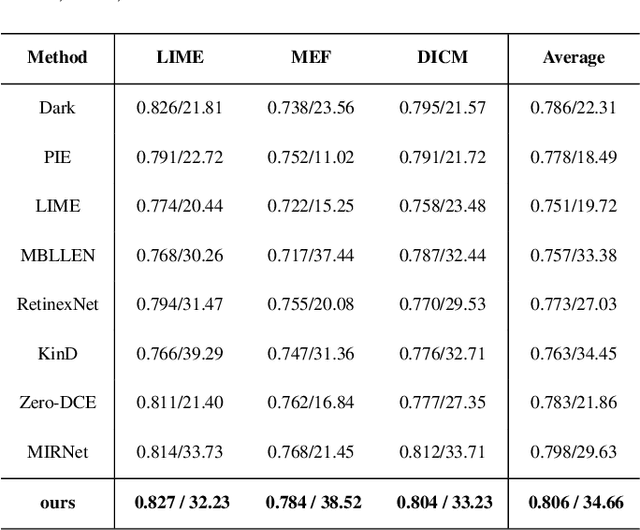
During the past years,deep convolutional neural networks have achieved impressive success in low-light Image Enhancement.Existing deep learning methods mostly enhance the ability of feature extraction by stacking network structures and deepening the depth of the network.which causes more runtime cost on single image.In order to reduce inference time while fully extracting local features and global features.Inspired by SGN,we propose a Attention based Broadly self-guided network (ABSGN) for real world low-light image Enhancement.such a broadly strategy is able to handle the noise at different exposures.The proposed network is validated by many mainstream benchmark.Additional experimental results show that the proposed network outperforms most of state-of-the-art low-light image Enhancement solutions.
Estimating Counterfactual Treatment Outcomes over Time Through Adversarially Balanced Representations
Feb 10, 2020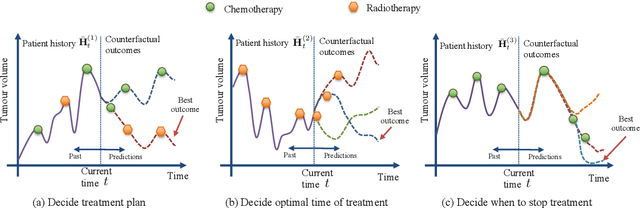
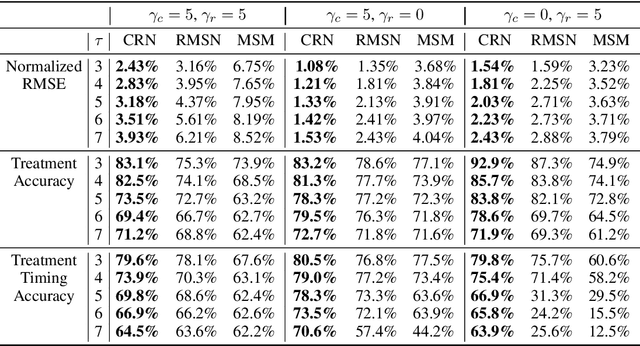
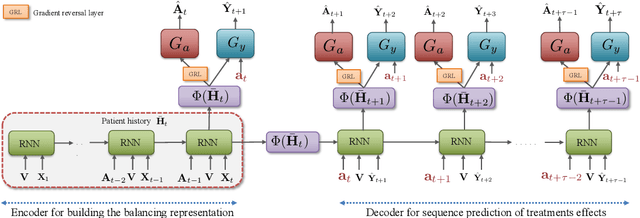

Identifying when to give treatments to patients and how to select among multiple treatments over time are important medical problems with a few existing solutions. In this paper, we introduce the Counterfactual Recurrent Network (CRN), a novel sequence-to-sequence model that leverages the increasingly available patient observational data to estimate treatment effects over time and answer such medical questions. To handle the bias from time-varying confounders, covariates affecting the treatment assignment policy in the observational data, CRN uses domain adversarial training to build balancing representations of the patient history. At each timestep, CRN constructs a treatment invariant representation which removes the association between patient history and treatment assignments and thus can be reliably used for making counterfactual predictions. On a simulated model of tumour growth, with varying degree of time-dependent confounding, we show how our model achieves lower error in estimating counterfactuals and in choosing the correct treatment and timing of treatment than current state-of-the-art methods.
A Generalised Signature Method for Time Series
Jun 01, 2020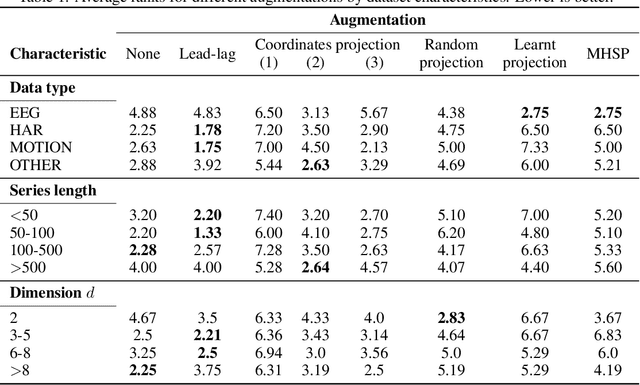

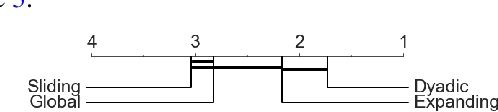
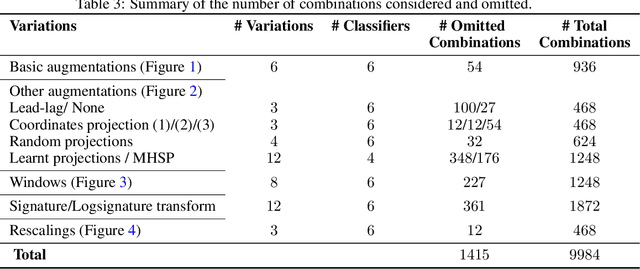
The `signature method' refers to a collection of feature extraction techniques for multimodal sequential data, derived from the theory of controlled differential equations. Variations exist as many authors have proposed modifications to the method, so as to improve some aspect of it. Here, we introduce a \emph{generalised signature method} that contains these variations as special cases, and groups them conceptually into \emph{augmentations}, \emph{windows}, \emph{transforms}, and \emph{rescalings}. Within this framework we are then able to propose novel variations, and demonstrate how previously distinct options may be combined. We go on to perform an extensive empirical study on 26 datasets as to which aspects of this framework typically produce the best results. Combining the top choices produces a canonical pipeline for the generalised signature method, which demonstrates state-of-the-art accuracy on benchmark problems in multivariate time series classification.
MultiQT: Multimodal Learning for Real-Time Question Tracking in Speech
May 02, 2020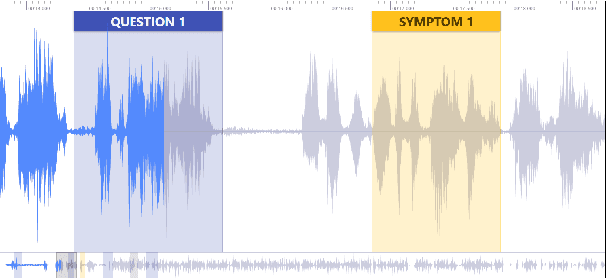

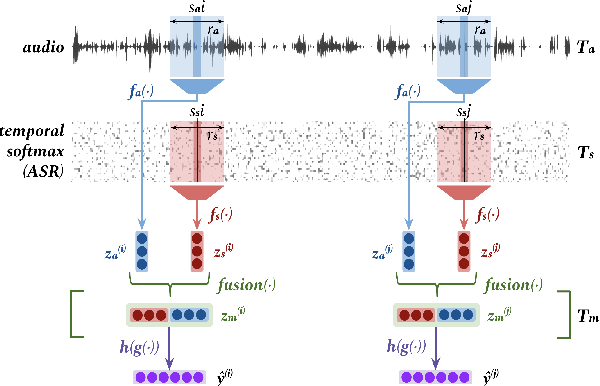

We address a challenging and practical task of labeling questions in speech in real time during telephone calls to emergency medical services in English, which embeds within a broader decision support system for emergency call-takers. We propose a novel multimodal approach to real-time sequence labeling in speech. Our model treats speech and its own textual representation as two separate modalities or views, as it jointly learns from streamed audio and its noisy transcription into text via automatic speech recognition. Our results show significant gains of jointly learning from the two modalities when compared to text or audio only, under adverse noise and limited volume of training data. The results generalize to medical symptoms detection where we observe a similar pattern of improvements with multimodal learning.