 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ROS georegistration: Aerial Multi-spectral Image Simulator for the Robot Operating System
Jan 19, 2022




This article describes a software package called ROS georegistration intended for use with the Robot Operating System (ROS) and the Gazebo 3D simulation environment. ROSgeoregistration provides tools for the simulation, test and deployment of aerial georegistration algorithms and is made available with a link provided in the paper. A model creation package is provided which downloads multi-spectral images from the Google Earth Engine database and, if necessary, incorporates these images into a single, possibly very large, reference image. Additionally a Gazebo plugin which uses the real-time sensor pose and image formation model to generate simulated imagery using the specified reference image is provided along with related plugins for UAV relevant data. The novelty of this work is threefold: (1) this is the first system to link the massive multi-spectral imaging database of Google's Earth Engine to the Gazebo simulator, (2) this is the first example of a system that can simulate geospatially and radiometrically accurate imagery from multiple sensor views of the same terrain region, and (3) integration with other UAS tools creates a new holistic UAS simulation environment to support UAS system and subsystem development where real-world testing would generally be prohibitive. Sensed imagery and ground truth registration information is published to client applications which can receive imagery synchronously with telemetry from other payload sensors, e.g., IMU, GPS/GNSS, barometer, and windspeed sensor data. To highlight functionality, we demonstrate ROSgeoregistration for simulating Electro-Optical (EO) and Synthetic Aperture Radar (SAR) image sensors and an example use case for developing and evaluating image-based UAS position feedback, i.e., pose for image-based Guidance Navigation and Control (GNC) applications.
A Survey on Principles, Models and Methods for Learning from Irregularly Sampled Time Series: From Discretization to Attention and Invariance
Nov 30, 2020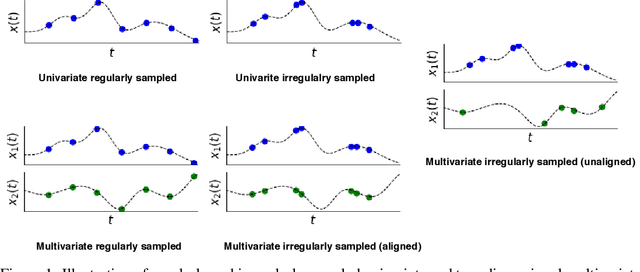
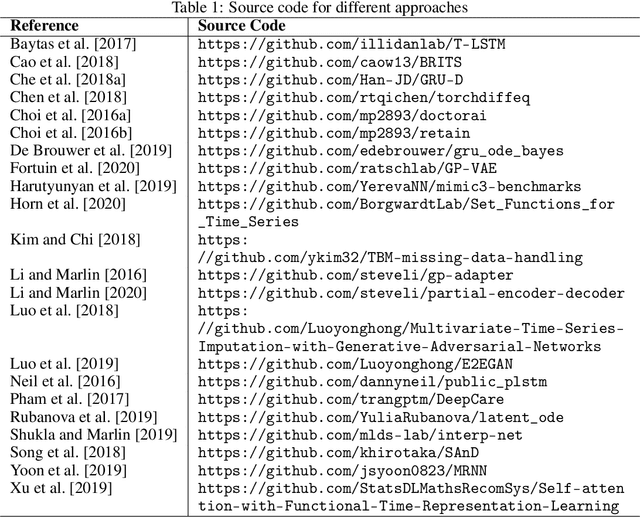
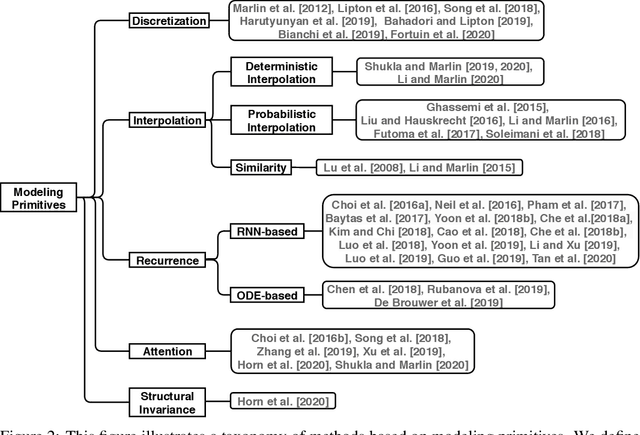
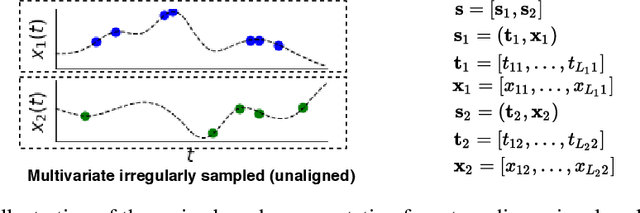
Irregularly sampled time series data arise naturally in many application domains including biology, ecology, climate science, astronomy, and health. Such data represent fundamental challenges to many classical models from machine learning and statistics due to the presence of non-uniform intervals between observations. However, there has been significant progress within the machine learning community over the last decade on developing specialized models and architectures for learning from irregularly sampled univariate and multivariate time series data. In this survey, we first describe several axes along which approaches differ including what data representations they are based on, what modeling primitives they leverage to deal with the fundamental problem of irregular sampling, and what inference tasks they are designed to perform. We then survey the recent literature organized primarily along the axis of modeling primitives. We describe approaches based on temporal discretization, interpolation, recurrence, attention, and structural invariance. We discuss similarities and differences between approaches and highlight primary strengths and weaknesses.
GraphPAS: Parallel Architecture Search for Graph Neural Networks
Dec 07, 2021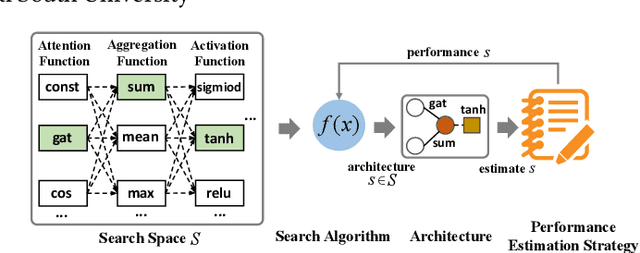

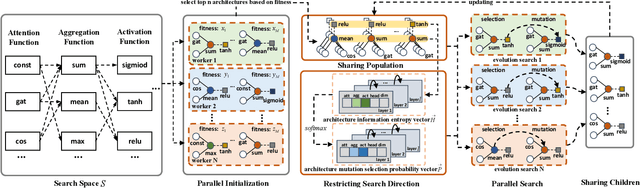
Graph neural architecture search has received a lot of attention as Graph Neural Networks (GNNs) has been successfully applied on the non-Euclidean data recently. However, exploring all possible GNNs architectures in the huge search space is too time-consuming or impossible for big graph data. In this paper, we propose a parallel graph architecture search (GraphPAS) framework for graph neural networks. In GraphPAS, we explore the search space in parallel by designing a sharing-based evolution learning, which can improve the search efficiency without losing the accuracy. Additionally, architecture information entropy is adopted dynamically for mutation selection probability, which can reduce space exploration. The experimental result shows that GraphPAS outperforms state-of-art models with efficiency and accuracy simultaneously.
Multi-Representation Adaptation Network for Cross-domain Image Classification
Jan 04, 2022
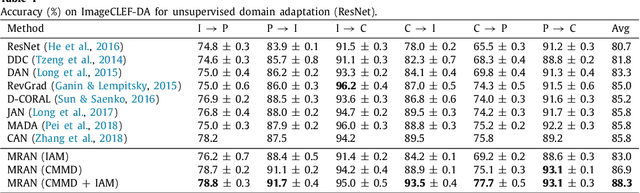
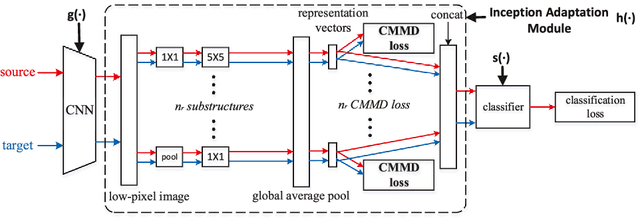
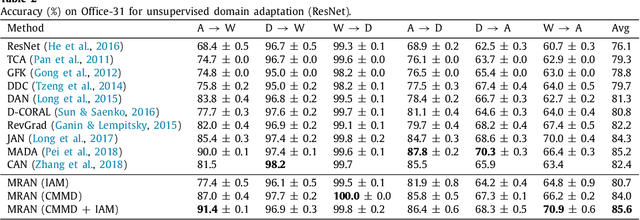
In image classification, it is often expensive and time-consuming to acquire sufficient labels. To solve this problem, domain adaptation often provides an attractive option given a large amount of labeled data from a similar nature but different domain. Existing approaches mainly align the distributions of representations extracted by a single structure and the representations may only contain partial information, e.g., only contain part of the saturation, brightness, and hue information. Along this line, we propose Multi-Representation Adaptation which can dramatically improve the classification accuracy for cross-domain image classification and specially aims to align the distributions of multiple representations extracted by a hybrid structure named Inception Adaptation Module (IAM). Based on this, we present Multi-Representation Adaptation Network (MRAN) to accomplish the cross-domain image classification task via multi-representation alignment which can capture the information from different aspects. In addition, we extend Maximum Mean Discrepancy (MMD) to compute the adaptation loss. Our approach can be easily implemented by extending most feed-forward models with IAM, and the network can be trained efficiently via back-propagation. Experiments conducted on three benchmark image datasets demonstrate the effectiveness of MRAN. The code has been available at https://github.com/easezyc/deep-transfer-learning.
A Multi-Resolution Front-End for End-to-End Speech Anti-Spoofing
Oct 11, 2021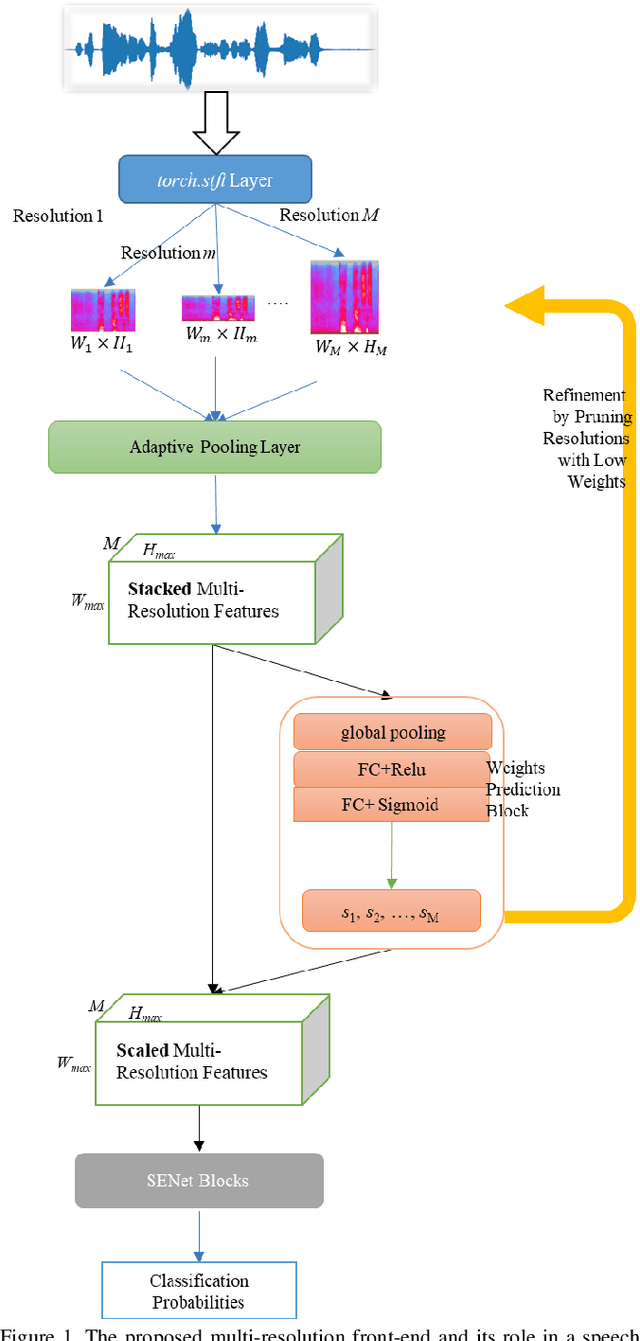
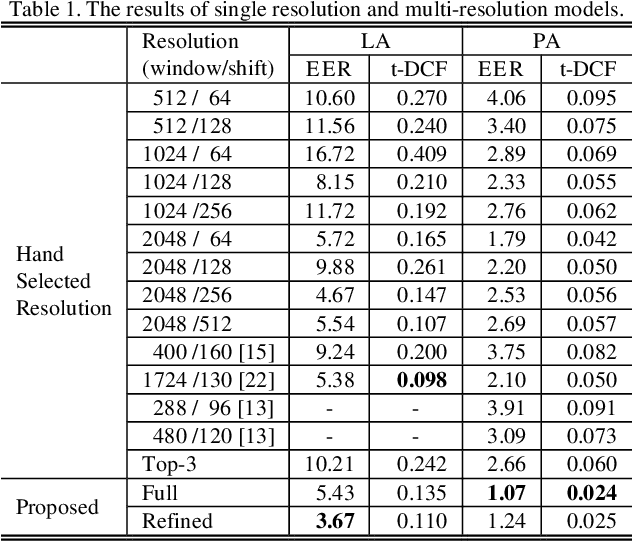
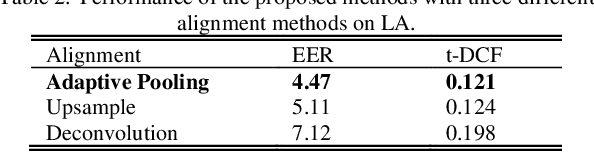
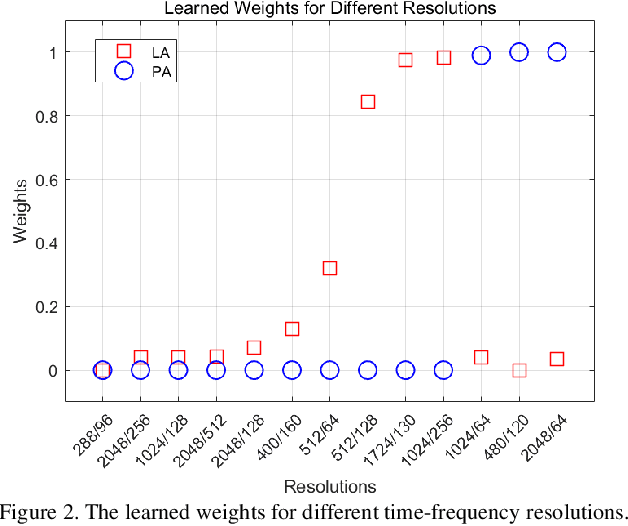
The choice of an optimal time-frequency resolution is usually a difficult but important step in tasks involving speech signal classification, e.g., speech anti-spoofing. The variations of the performance with different choices of timefrequency resolutions can be as large as those with different model architectures, which makes it difficult to judge what the improvement actually comes from when a new network architecture is invented and introduced as the classifier. In this paper, we propose a multi-resolution front-end for feature extraction in an end-to-end classification framework. Optimal weighted combinations of multiple time-frequency resolutions will be learned automatically given the objective of a classification task. Features extracted with different time-frequency resolutions are weighted and concatenated as inputs to the successive networks, where the weights are predicted by a learnable neural network inspired by the weighting block in squeeze-and-excitation networks (SENet). Furthermore, the refinement of the chosen timefrequency resolutions is investigated by pruning the ones with relatively low importance, which reduces the complexity and size of the model. The proposed method is evaluated on the tasks of speech anti-spoofing in ASVSpoof 2019 and its superiority has been justified by comparing with similar baselines.
Online MAP Inference and Learning for Nonsymmetric Determinantal Point Processes
Nov 29, 2021



In this paper, we introduce the online and streaming MAP inference and learning problems for Non-symmetric Determinantal Point Processes (NDPPs) where data points arrive in an arbitrary order and the algorithms are constrained to use a single-pass over the data as well as sub-linear memory. The online setting has an additional requirement of maintaining a valid solution at any point in time. For solving these new problems, we propose algorithms with theoretical guarantees, evaluate them on several real-world datasets, and show that they give comparable performance to state-of-the-art offline algorithms that store the entire data in memory and take multiple passes over it.
Weighted Encoding Optimization for Dynamic Single-pixel Imaging and Sensing
Jan 08, 2022



Using single-pixel detection, the end-to-end neural network that jointly optimizes both encoding and decoding enables high-precision imaging and high-level semantic sensing. However, for varied sampling rates, the large-scale network requires retraining that is laboursome and computation-consuming. In this letter, we report a weighted optimization technique for dynamic rate-adaptive single-pixel imaging and sensing, which only needs to train the network for one time that is available for any sampling rates. Specifically, we introduce a novel weighting scheme in the encoding process to characterize different patterns' modulation efficiency. While the network is training at a high sampling rate, the modulation patterns and corresponding weights are updated iteratively, which produces optimal ranked encoding series when converged. In the experimental implementation, the optimal pattern series with the highest weights are employed for light modulation, thus achieving highly-efficient imaging and sensing. The reported strategy saves the additional training of another low-rate network required by the existing dynamic single-pixel networks, which further doubles training efficiency. Experiments on the MNIST dataset validated that once the network is trained with a sampling rate of 1, the average imaging PSNR reaches 23.50 dB at 0.1 sampling rate, and the image-free classification accuracy reaches up to 95.00\% at a sampling rate of 0.03 and 97.91\% at a sampling rate of 0.1.
Continual Learning for Unsupervised Anomaly Detection in Continuous Auditing of Financial Accounting Data
Dec 25, 2021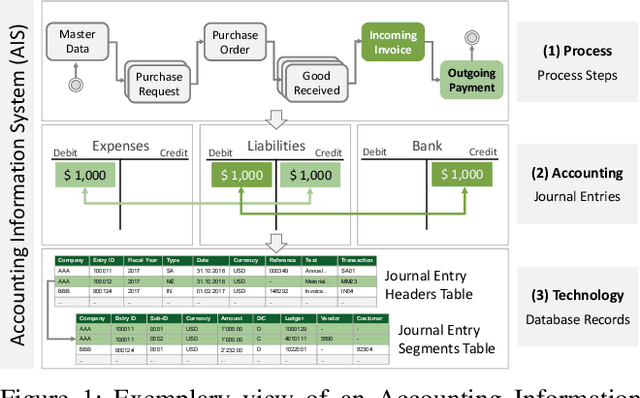

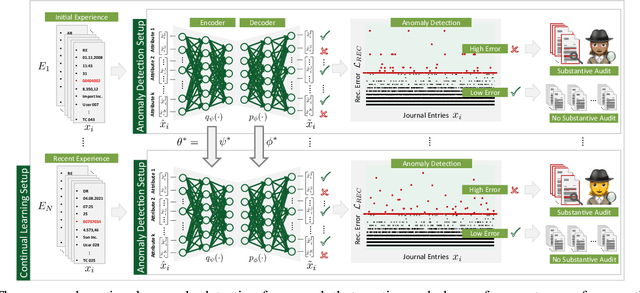
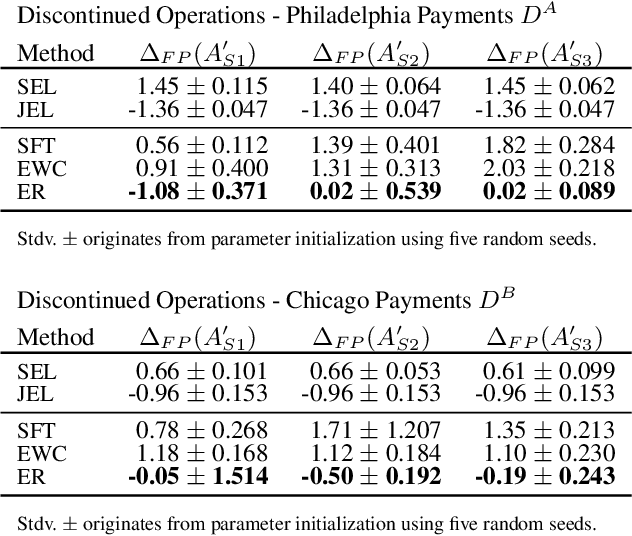
International audit standards require the direct assessment of a financial statement's underlying accounting journal entries. Driven by advances in artificial intelligence, deep-learning inspired audit techniques emerged to examine vast quantities of journal entry data. However, in regular audits, most of the proposed methods are applied to learn from a comparably stationary journal entry population, e.g., of a financial quarter or year. Ignoring situations where audit relevant distribution changes are not evident in the training data or become incrementally available over time. In contrast, in continuous auditing, deep-learning models are continually trained on a stream of recorded journal entries, e.g., of the last hour. Resulting in situations where previous knowledge interferes with new information and will be entirely overwritten. This work proposes a continual anomaly detection framework to overcome both challenges and designed to learn from a stream of journal entry data experiences. The framework is evaluated based on deliberately designed audit scenarios and two real-world datasets. Our experimental results provide initial evidence that such a learning scheme offers the ability to reduce false-positive alerts and false-negative decisions.
A pipeline for automated processing of Corona KH-4 (1962-1972) stereo imagery
Jan 19, 2022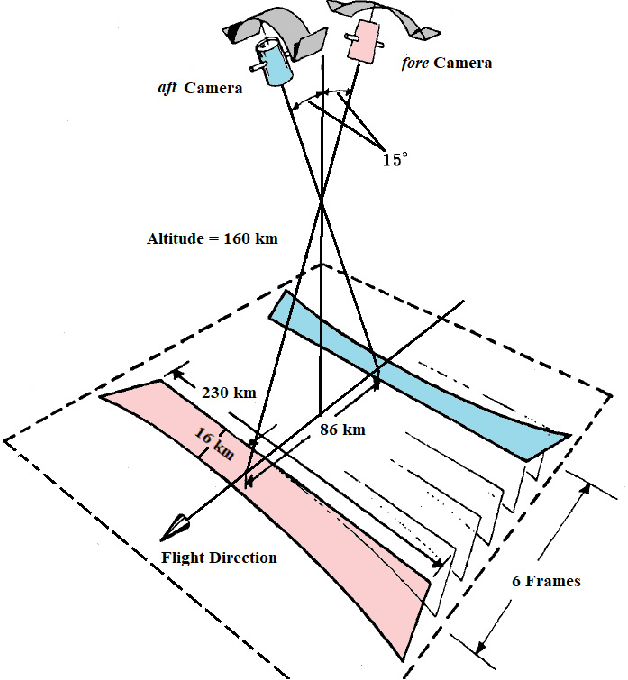
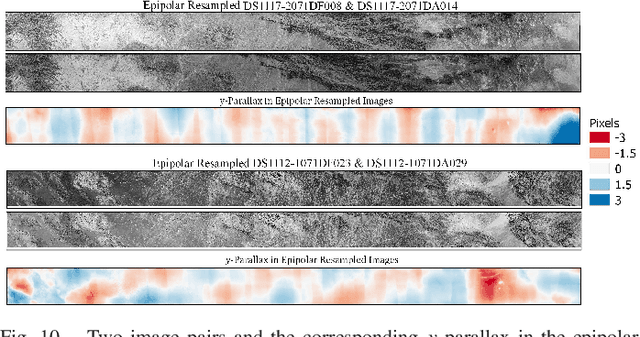
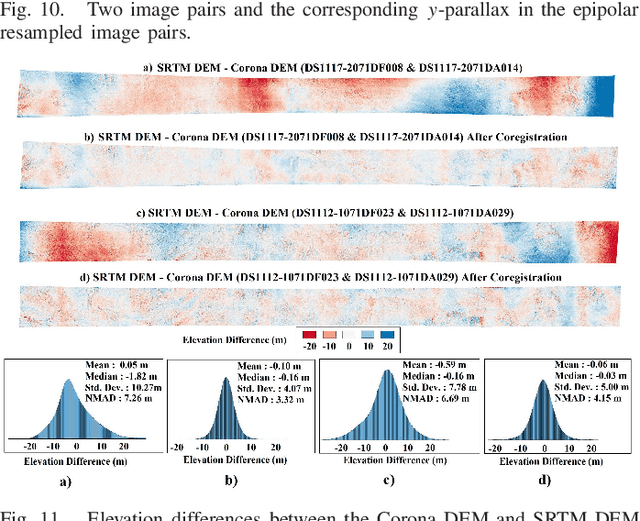

The Corona KH-4 reconnaissance satellite missions from 1962-1972 acquired panoramic stereo imagery with high spatial resolution of 1.8-7.5 m. The potential of 800,000+ declassified Corona images has not been leveraged due to the complexities arising from handling of panoramic imaging geometry, film distortions and limited availability of the metadata required for georeferencing of the Corona imagery. This paper presents Corona Stereo Pipeline (CoSP): A pipeline for processing of Corona KH-4 stereo panoramic imagery. CoSP utlizes a deep learning based feature matcher SuperGlue to automatically match features point between Corona KH-4 images and recent satellite imagery to generate Ground Control Points (GCPs). To model the imaging geometry and the scanning motion of the panoramic KH-4 cameras, a rigorous camera model consisting of modified collinearity equations with time dependent exterior orientation parameters is employed. The results show that using the entire frame of the Corona image, bundle adjustment using well-distributed GCPs results in an average standard deviation (SD) of less than 2 pixels. The distortion pattern of image residuals of GCPs and y-parallax in epipolar resampled images suggest that film distortions due to long term storage as likely cause of systematic deviations. Compared to the SRTM DEM, the Corona DEM computed using CoSP achieved a Normalized Median Absolute Deviation (NMAD) of elevation differences of ~4 m over an area of approx. 4000 $km^2$. We show that the proposed pipeline can be applied to sequence of complex scenes involving high relief and glacierized terrain and that the resulting DEMs can be used to compute long term glacier elevation changes over large areas.
Automatic Tuning of Federated Learning Hyper-Parameters from System Perspective
Oct 06, 2021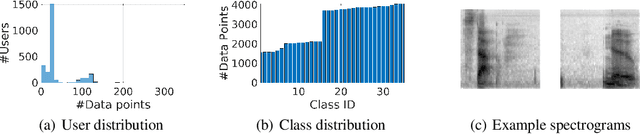

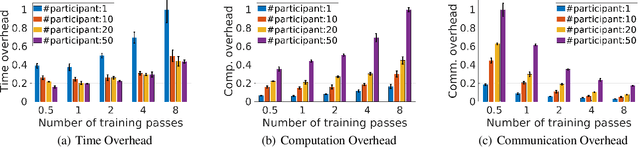
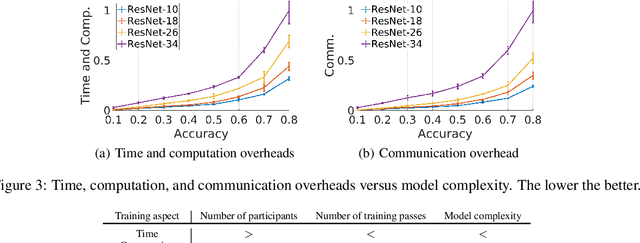
Federated learning (FL) is a distributed model training paradigm that preserves clients' data privacy. FL hyper-parameters significantly affect the training overheads in terms of time, computation, and communication. However, the current practice of manually selecting FL hyper-parameters puts a high burden on FL practitioners since various applications prefer different training preferences. In this paper, we propose FedTuning, an automatic FL hyper-parameter tuning algorithm tailored to applications' diverse system requirements of FL training. FedTuning is lightweight and flexible, achieving an average of 41% improvement for different training preferences on time, computation, and communication compared to fixed FL hyper-parameters. FedTuning is available at https://github.com/dtczhl/FedTuning.