 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Theoretical Overview of Neural Contraction Metrics for Learning-based Control with Guaranteed Stability
Oct 02, 2021
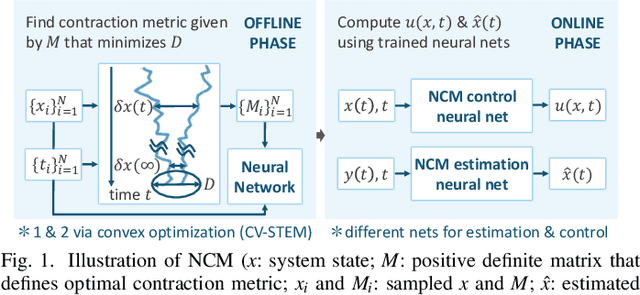
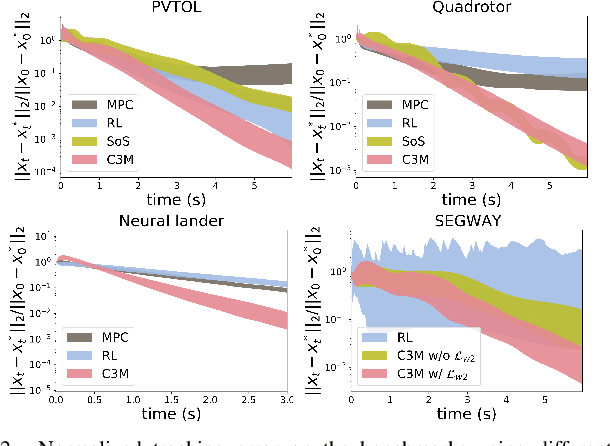
This paper presents a theoretical overview of a Neural Contraction Metric (NCM): a neural network model of an optimal contraction metric and corresponding differential Lyapunov function, the existence of which is a necessary and sufficient condition for incremental exponential stability of non-autonomous nonlinear system trajectories. Its innovation lies in providing formal robustness guarantees for learning-based control frameworks, utilizing contraction theory as an analytical tool to study the nonlinear stability of learned systems via convex optimization. In particular, we rigorously show in this paper that, by regarding modeling errors of the learning schemes as external disturbances, the NCM control is capable of obtaining an explicit bound on the distance between a time-varying target trajectory and perturbed solution trajectories, which exponentially decreases with time even under the presence of deterministic and stochastic perturbation. These useful features permit simultaneous synthesis of a contraction metric and associated control law by a neural network, thereby enabling real-time computable and probably robust learning-based control for general control-affine nonlinear systems.
Stability and Robustness of the Disturbance Observer-based Motion Control Systems in Discrete-Time Domain
Oct 16, 2020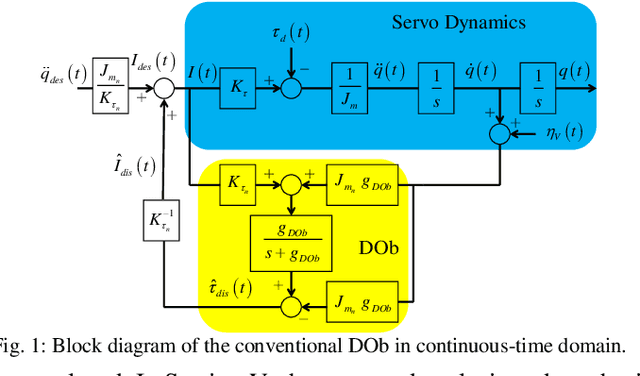
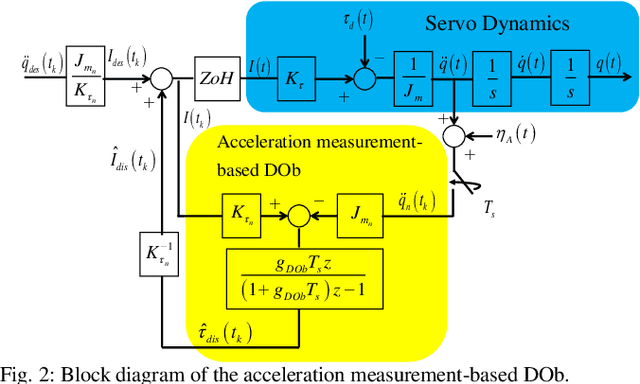
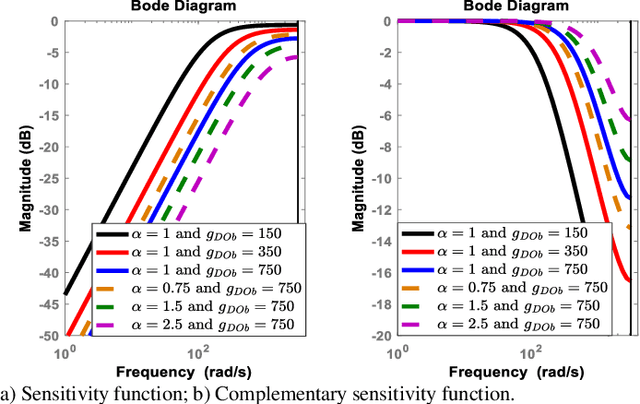
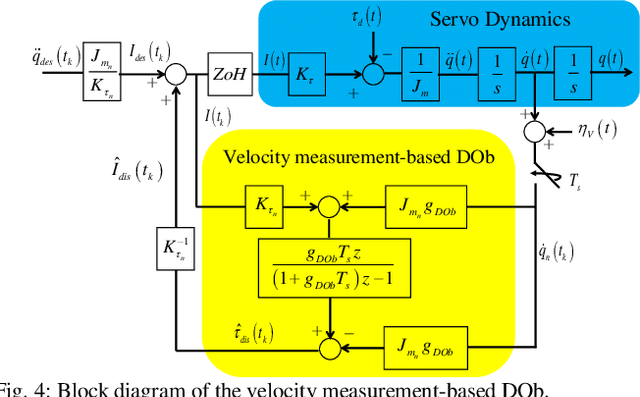
This paper analyses the robust stability and performance of the Disturbance Observer- (DOb-) based digital motion control systems in discrete-time domain. It is shown that the phase margin and the robustness of the digital motion controller can be directly adjusted by tuning the nominal plant model and the bandwidth of the observer. However, they have upper and lower bounds due to robust stability and performance constraints as well as noise-sensitivity. The constraints on the design parameters of the DOb change when the digital motion controller is synthesised by measuring different states of a servo system. For example, the bandwidth of the DOb is limited by noise-sensitivity and waterbed effect when velocity and position measurements are employed in the digital robust motion controller synthesis. The robustness constraint due to the waterbed effect is removed when the DOb is implemented by acceleration measurement. The design constraints on the nominal plant model and the bandwidth of the observer are analytically derived by employing the generalised Bode Integral Theorem in discrete-time. The proposed design constraints allow one to systematically synthesise a high-performance DOb-based digital robust motion controller. Experimental results are given to verify the proposed analysis and synthesis methods.
* 11 pages, 17 figures
Visual Microfossil Identification via Deep Metric Learning
Jan 04, 2022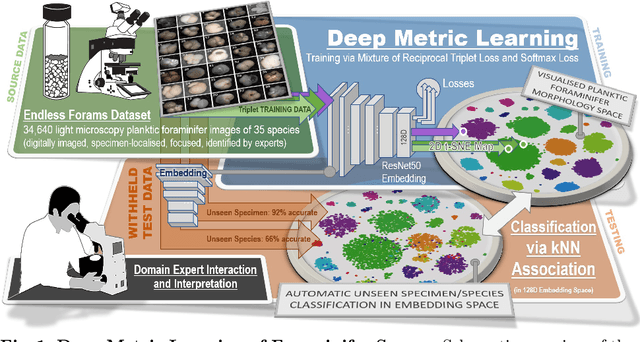
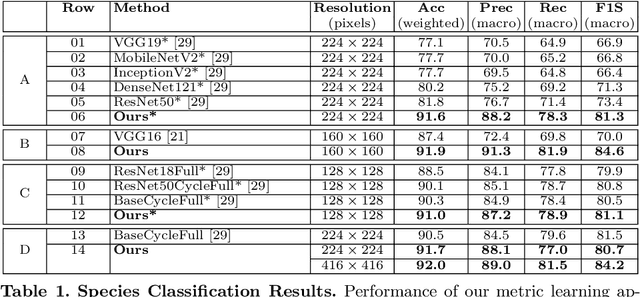
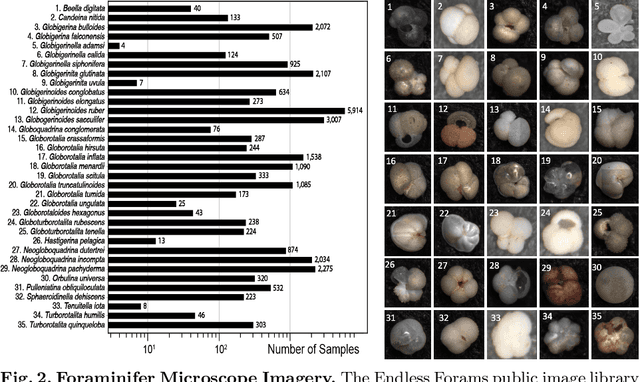
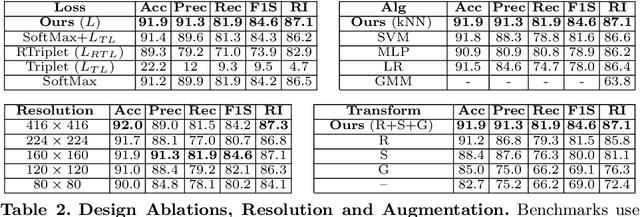
We apply deep metric learning for the first time to the prob-lem of classifying planktic foraminifer shells on microscopic images. This species recognition task is an important information source and scientific pillar for reconstructing past climates. All foraminifer CNN recognition pipelines in the literature produce black-box classifiers that lack visualisation options for human experts and cannot be applied to open set problems. Here, we benchmark metric learning against these pipelines, produce the first scientific visualisation of the phenotypic planktic foraminifer morphology space, and demonstrate that metric learning can be used to cluster species unseen during training. We show that metric learning out-performs all published CNN-based state-of-the-art benchmarks in this domain. We evaluate our approach on the 34,640 expert-annotated images of the Endless Forams public library of 35 modern planktic foraminifera species. Our results on this data show leading 92% accuracy (at 0.84 F1-score) in reproducing expert labels on withheld test data, and 66.5% accuracy (at 0.70 F1-score) when clustering species never encountered in training. We conclude that metric learning is highly effective for this domain and serves as an important tool towards expert-in-the-loop automation of microfossil identification. Key code, network weights, and data splits are published with this paper for full reproducibility.
An Analytical Update Rule for General Policy Optimization
Dec 03, 2021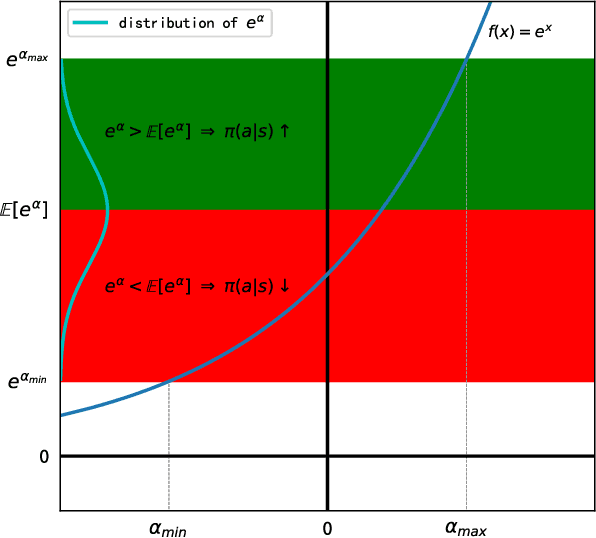
We present an analytical policy update rule that is independent of parameterized function approximators. The update rule is suitable for general stochastic policies with monotonic improvement guarantee. The update rule is derived from a closed-form trust-region solution using calculus of variation, following a new theoretical result that tightens existing bounds for policy search using trust-region methods. An explanation building a connection between the policy update rule and value-function methods is provided. Based on a recursive form of the update rule, an off-policy algorithm is derived naturally, and the monotonic improvement guarantee remains. Furthermore, the update rule extends immediately to multi-agent systems when updates are performed by one agent at a time.
Reactive Message Passing for Scalable Bayesian Inference
Dec 25, 2021
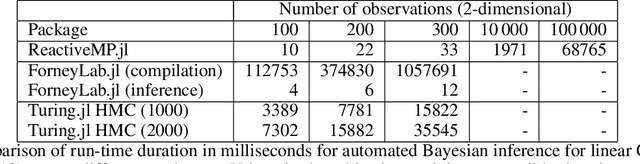
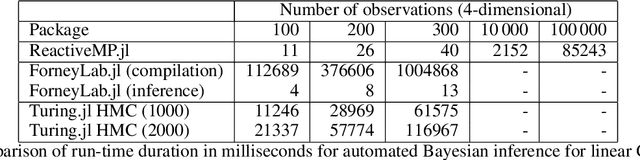
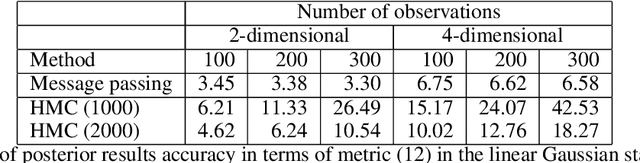
We introduce Reactive Message Passing (RMP) as a framework for executing schedule-free, robust and scalable message passing-based inference in a factor graph representation of a probabilistic model. RMP is based on the reactive programming style that only describes how nodes in a factor graph react to changes in connected nodes. The absence of a fixed message passing schedule improves robustness, scalability and execution time of the inference procedure. We also present ReactiveMP.jl, which is a Julia package for realizing RMP through minimization of a constrained Bethe free energy. By user-defined specification of local form and factorization constraints on the variational posterior distribution, ReactiveMP.jl executes hybrid message passing algorithms including belief propagation, variational message passing, expectation propagation, and expectation maximisation update rules. Experimental results demonstrate the improved performance of ReactiveMP-based RMP in comparison to other Julia packages for Bayesian inference across a range of probabilistic models. In particular, we show that the RMP framework is able to run Bayesian inference for large-scale probabilistic state space models with hundreds of thousands of random variables on a standard laptop computer.
Memetic Search for Vehicle Routing with Simultaneous Pickup-Delivery and Time Windows
Nov 19, 2020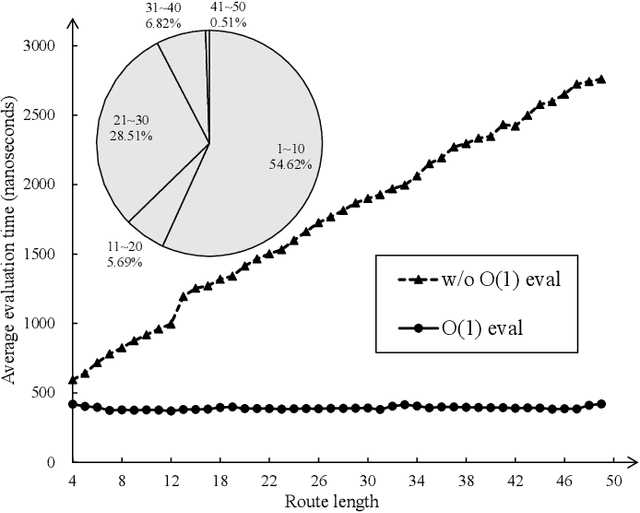
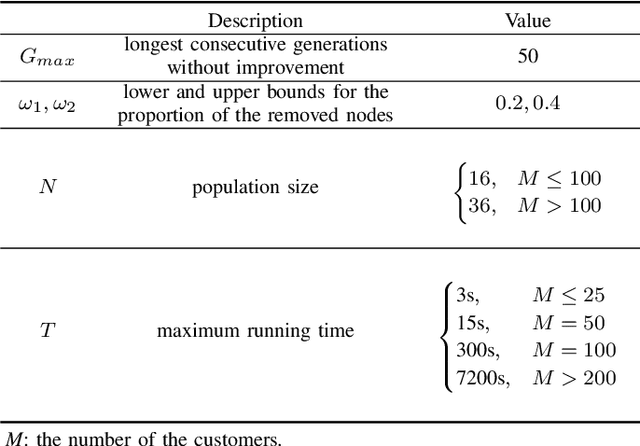
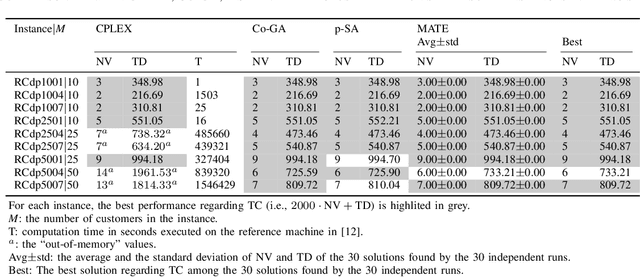
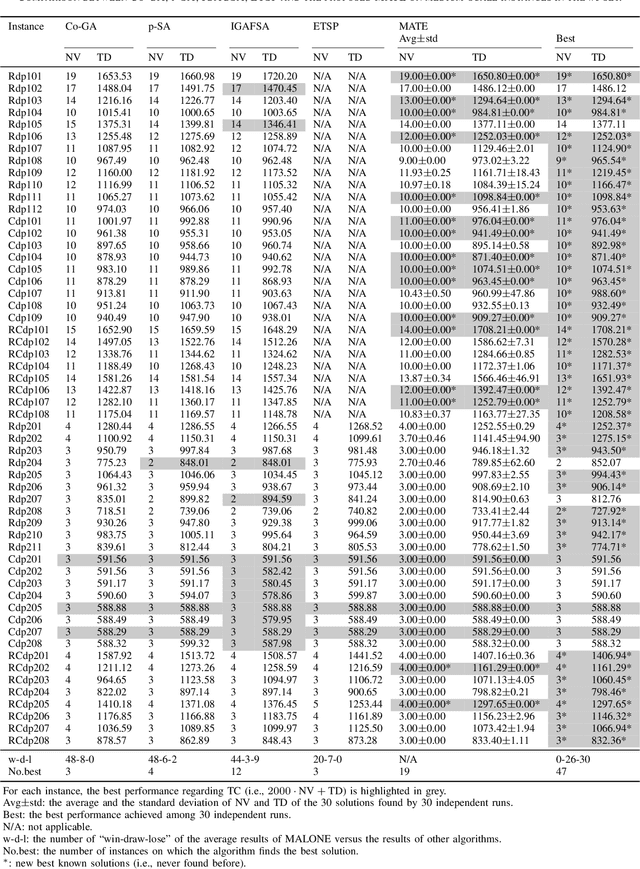
The vehicle routing problem with simultaneous pickup-delivery and time windows (VRPSPDTW) has attracted much attention in the last decade, due to its wide application in modern logistics involving bi-directional flow of goods. In this paper, we propose a memetic algorithm with efficient local search and extended neighborhood, dubbed MATE, for solving this problem. The novelty of MATE lies in three aspects: 1) an initialization procedure which integrates an existing heuristic into the population-based search framework, in an intelligent way; 2) a new crossover involving route inheritance and regret-based node reinsertion; 3) a highly-effective local search procedure which could flexibly search in a large neighborhood by switching between move operators with different step sizes, while keeping low computational complexity. Experimental results on public benchmark show that MATE consistently outperforms all the state-of-the-art algorithms, and notably, finds new best-known solutions on 44 instances (65 instances in total). A new benchmark of large-scale instances, derived from a real-world application of the JD logistics, is also introduced, which could serve as a new and more practical test set for future research.
Spike-inspired Rank Coding for Fast and Accurate Recurrent Neural Networks
Oct 06, 2021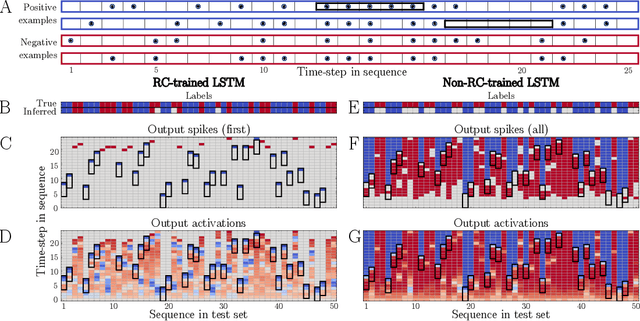
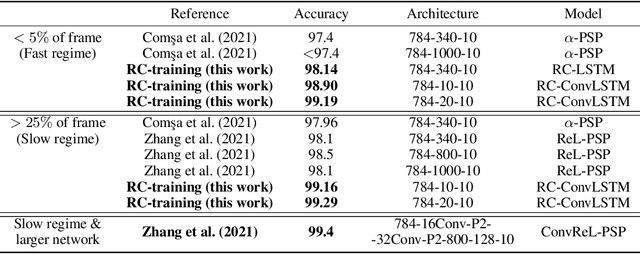

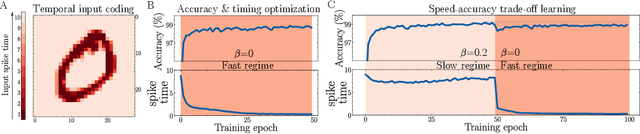
Biological spiking neural networks (SNNs) can temporally encode information in their outputs, e.g. in the rank order in which neurons fire, whereas artificial neural networks (ANNs) conventionally do not. As a result, models of SNNs for neuromorphic computing are regarded as potentially more rapid and efficient than ANNs when dealing with temporal input. On the other hand, ANNs are simpler to train, and usually achieve superior performance. Here we show that temporal coding such as rank coding (RC) inspired by SNNs can also be applied to conventional ANNs such as LSTMs, and leads to computational savings and speedups. In our RC for ANNs, we apply backpropagation through time using the standard real-valued activations, but only from a strategically early time step of each sequential input example, decided by a threshold-crossing event. Learning then incorporates naturally also _when_ to produce an output, without other changes to the model or the algorithm. Both the forward and the backward training pass can be significantly shortened by skipping the remaining input sequence after that first event. RC-training also significantly reduces time-to-insight during inference, with a minimal decrease in accuracy. The desired speed-accuracy trade-off is tunable by varying the threshold or a regularization parameter that rewards output entropy. We demonstrate these in two toy problems of sequence classification, and in a temporally-encoded MNIST dataset where our RC model achieves 99.19% accuracy after the first input time-step, outperforming the state of the art in temporal coding with SNNs, as well as in spoken-word classification of Google Speech Commands, outperforming non-RC-trained early inference with LSTMs.
Driver Drowsiness Detection Using Ensemble Convolutional Neural Networks on YawDD
Dec 20, 2021
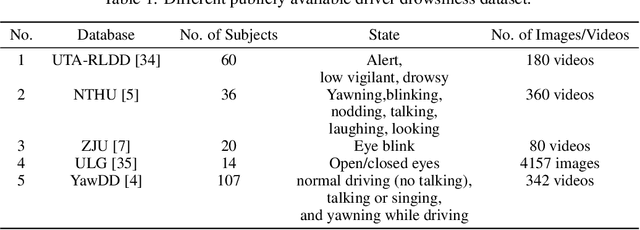
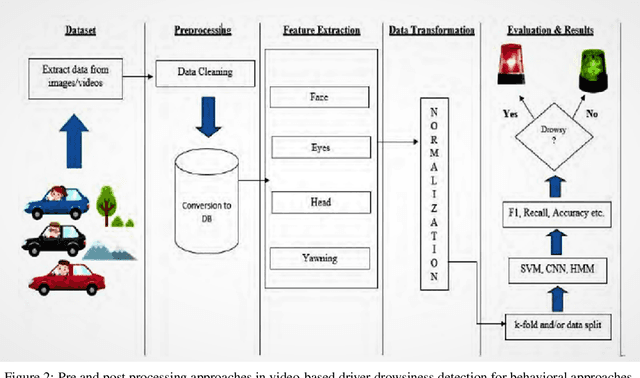
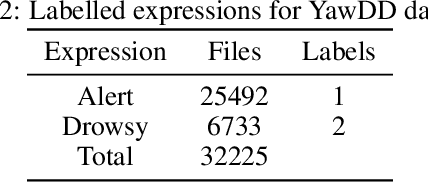
Driver drowsiness detection using videos/images is one of the most essential areas in today's time for driver safety. The development of deep learning techniques, notably Convolutional Neural Networks (CNN), applied in computer vision applications such as drowsiness detection, has shown promising results due to the tremendous increase in technology in the recent few decades. Eyes that are closed or blinking excessively, yawning, nodding, and occlusion are all key aspects of drowsiness. In this work, we have applied four different Convolutional Neural Network (CNN) techniques on the YawDD dataset to detect and examine the extent of drowsiness depending on the yawning frequency with specific pose and occlusion variation. Preliminary computational results show that our proposed Ensemble Convolutional Neural Network (ECNN) outperformed the traditional CNN-based approach by achieving an F1 score of 0.935, whereas the other three CNN, such as CNN1, CNN2, and CNN3 approaches gained 0.92, 0.90, and 0.912 F1 scores, respectively.
Learning Large Neighborhood Search Policy for Integer Programming
Nov 01, 2021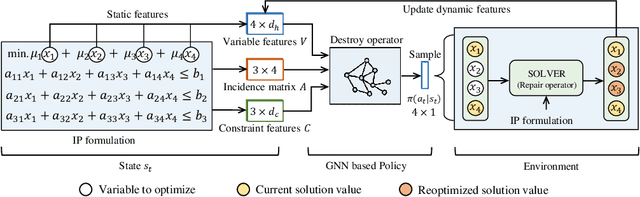

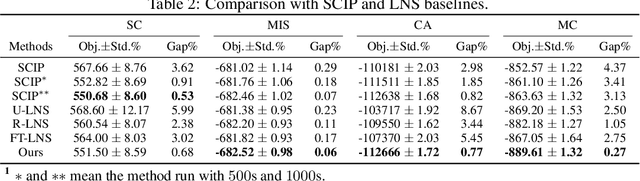
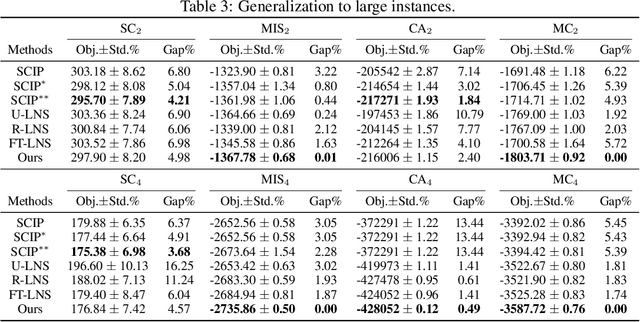
We propose a deep reinforcement learning (RL) method to learn large neighborhood search (LNS) policy for integer programming (IP). The RL policy is trained as the destroy operator to select a subset of variables at each step, which is reoptimized by an IP solver as the repair operator. However, the combinatorial number of variable subsets prevents direct application of typical RL algorithms. To tackle this challenge, we represent all subsets by factorizing them into binary decisions on each variable. We then design a neural network to learn policies for each variable in parallel, trained by a customized actor-critic algorithm. We evaluate the proposed method on four representative IP problems. Results show that it can find better solutions than SCIP in much less time, and significantly outperform other LNS baselines with the same runtime. Moreover, these advantages notably persist when the policies generalize to larger problems. Further experiments with Gurobi also reveal that our method can outperform this state-of-the-art commercial solver within the same time limit.
Neural Predictive Control for the Optimization of Smart Grid Flexibility Schedules
Aug 19, 2021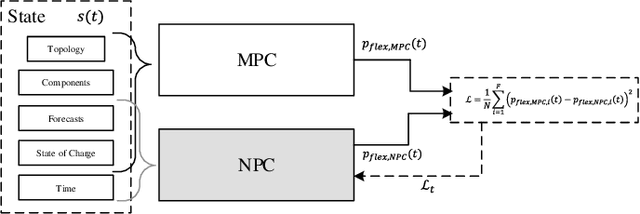
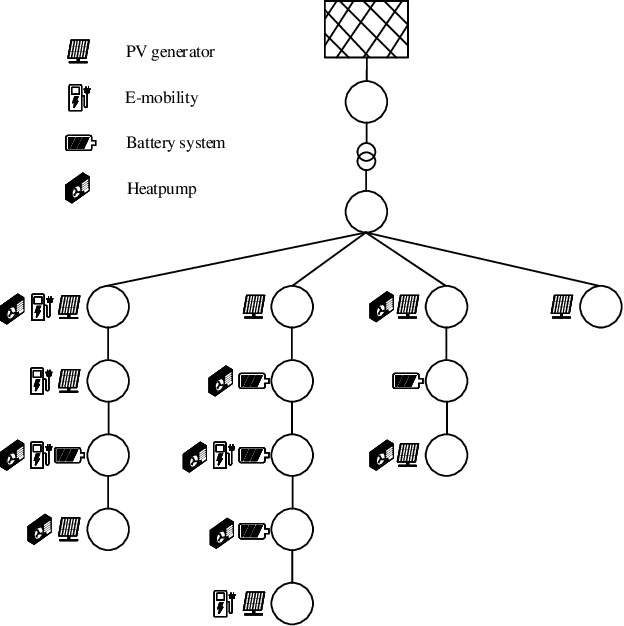
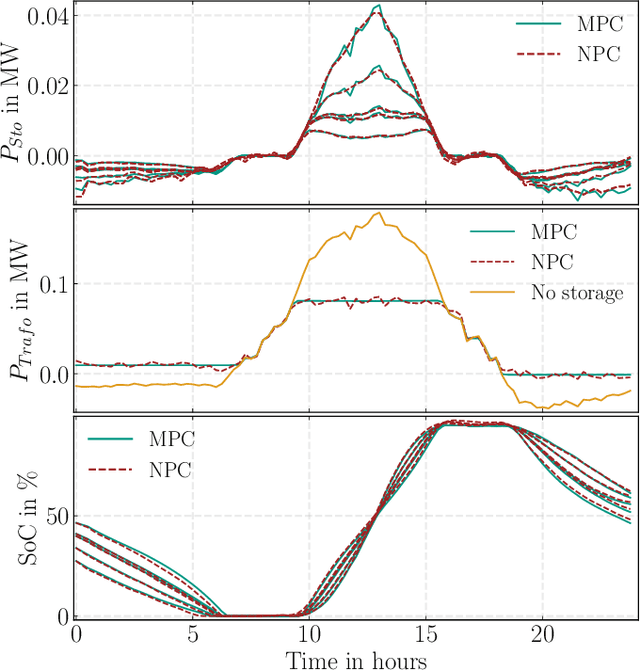
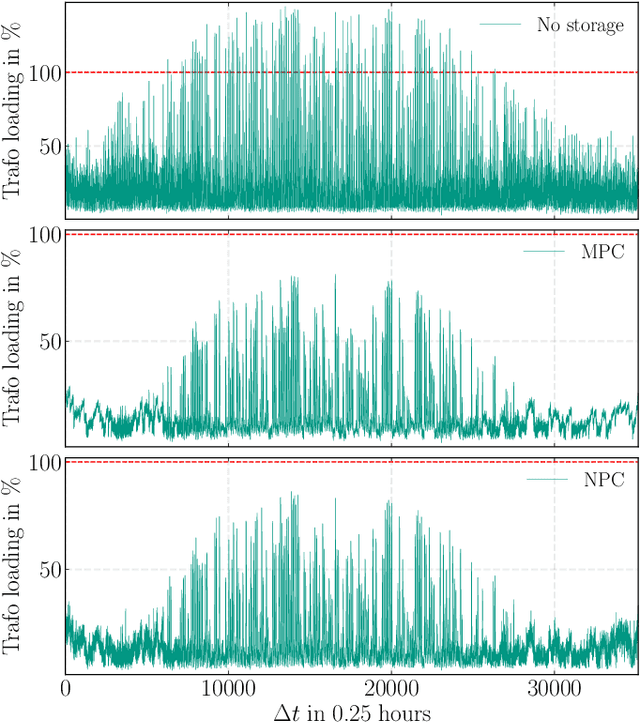
Model predictive control (MPC) is a method to formulate the optimal scheduling problem for grid flexibilities in a mathematical manner. The resulting time-constrained optimization problem can be re-solved in each optimization time step using classical optimization methods such as Second Order Cone Programming (SOCP) or Interior Point Methods (IPOPT). When applying MPC in a rolling horizon scheme, the impact of uncertainty in forecasts on the optimal schedule is reduced. While MPC methods promise accurate results for time-constrained grid optimization they are inherently limited by the calculation time needed for large and complex power system models. Learning the optimal control behaviour using function approximation offers the possibility to determine near-optimal control actions with short calculation time. A Neural Predictive Control (NPC) scheme is proposed to learn optimal control policies for linear and nonlinear power systems through imitation. It is demonstrated that this procedure can find near-optimal solutions, while reducing the calculation time by an order of magnitude. The learned controllers are validated using a benchmark smart grid.