 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Human-Level Control without Server-Grade Hardware
Nov 01, 2021
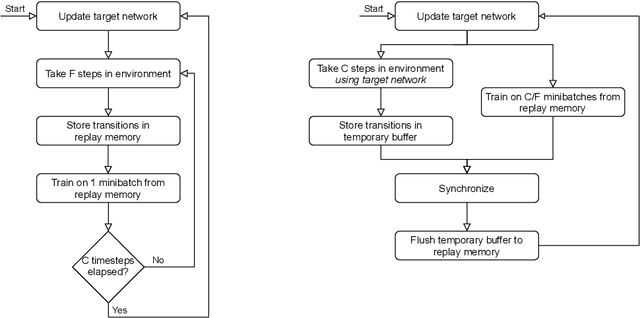

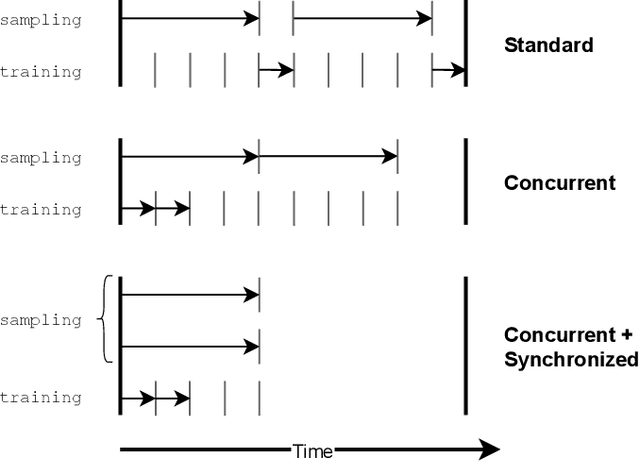

Deep Q-Network (DQN) marked a major milestone for reinforcement learning, demonstrating for the first time that human-level control policies could be learned directly from raw visual inputs via reward maximization. Even years after its introduction, DQN remains highly relevant to the research community since many of its innovations have been adopted by successor methods. Nevertheless, despite significant hardware advances in the interim, DQN's original Atari 2600 experiments remain costly to replicate in full. This poses an immense barrier to researchers who cannot afford state-of-the-art hardware or lack access to large-scale cloud computing resources. To facilitate improved access to deep reinforcement learning research, we introduce a DQN implementation that leverages a novel concurrent and synchronized execution framework designed to maximally utilize a heterogeneous CPU-GPU desktop system. With just one NVIDIA GeForce GTX 1080 GPU, our implementation reduces the training time of a 200-million-frame Atari experiment from 25 hours to just 9 hours. The ideas introduced in our paper should be generalizable to a large number of off-policy deep reinforcement learning methods.
Time-Frequency Scattering Accurately Models Auditory Similarities Between Instrumental Playing Techniques
Jul 21, 2020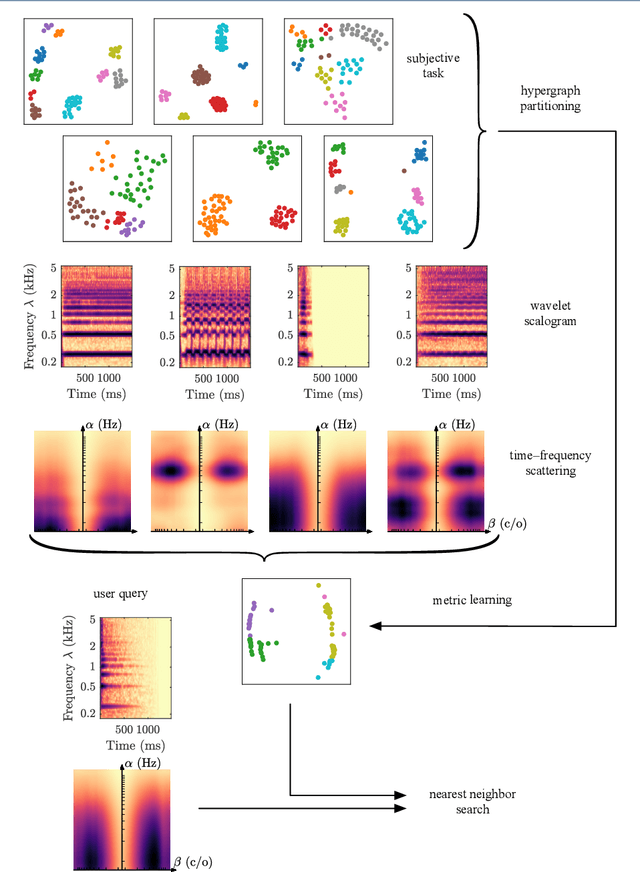
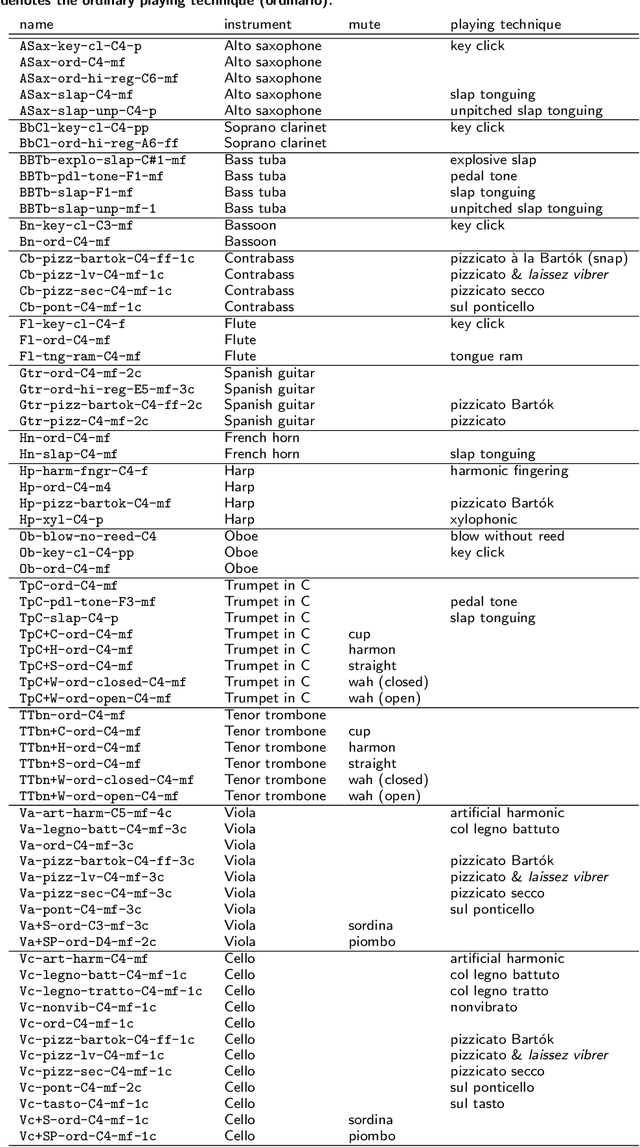

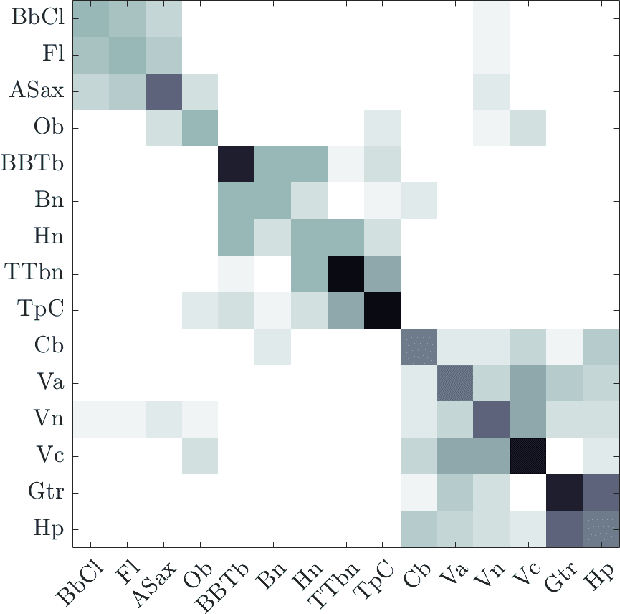
Instrumental playing techniques such as vibratos, glissandos, and trills often denote musical expressivity, both in classical and folk contexts. However, most existing approaches to music similarity retrieval fail to describe timbre beyond the so-called ``ordinary'' technique, use instrument identity as a proxy for timbre quality, and do not allow for customization to the perceptual idiosyncrasies of a new subject. In this article, we ask 31 human subjects to organize 78 isolated notes into a set of timbre clusters. Analyzing their responses suggests that timbre perception operates within a more flexible taxonomy than those provided by instruments or playing techniques alone. In addition, we propose a machine listening model to recover the cluster graph of auditory similarities across instruments, mutes, and techniques. Our model relies on joint time--frequency scattering features to extract spectrotemporal modulations as acoustic features. Furthermore, it minimizes triplet loss in the cluster graph by means of the large-margin nearest neighbor (LMNN) metric learning algorithm. Over a dataset of 9346 isolated notes, we report a state-of-the-art average precision at rank five (AP@5) of $99.0\%\pm1$. An ablation study demonstrates that removing either the joint time--frequency scattering transform or the metric learning algorithm noticeably degrades performance.
Joint Detection of Motion Boundaries and Occlusions
Nov 01, 2021



We propose MONet, a convolutional neural network that jointly detects motion boundaries (MBs) and occlusion regions (Occs) in video both forward and backward in time. Detection is difficult because optical flow is discontinuous along MBs and undefined in Occs, while many flow estimators assume smoothness and a flow defined everywhere. To reason in the two time directions simultaneously, we direct-warp the estimated maps between the two frames. Since appearance mismatches between frames often signal vicinity to MBs or Occs, we construct a cost block that for each feature in one frame records the lowest discrepancy with matching features in a search range. This cost block is two-dimensional, and much less expensive than the four-dimensional cost volumes used in flow analysis. Cost-block features are computed by an encoder, and MB and Occ estimates are computed by a decoder. We found that arranging decoder layers fine-to-coarse, rather than coarse-to-fine, improves performance. MONet outperforms the prior state of the art for both tasks on the Sintel and FlyingChairsOcc benchmarks without any fine-tuning on them.
Self-directed Machine Learning
Jan 04, 2022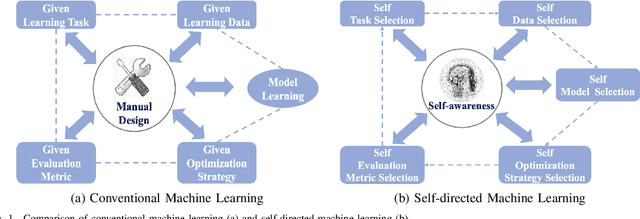
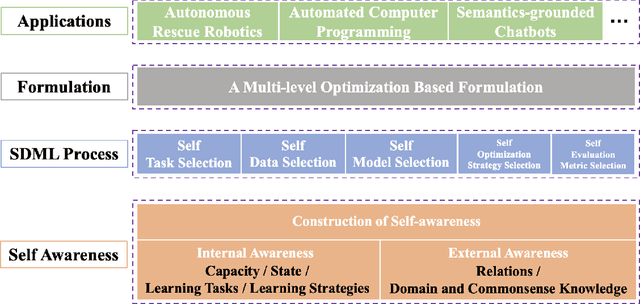
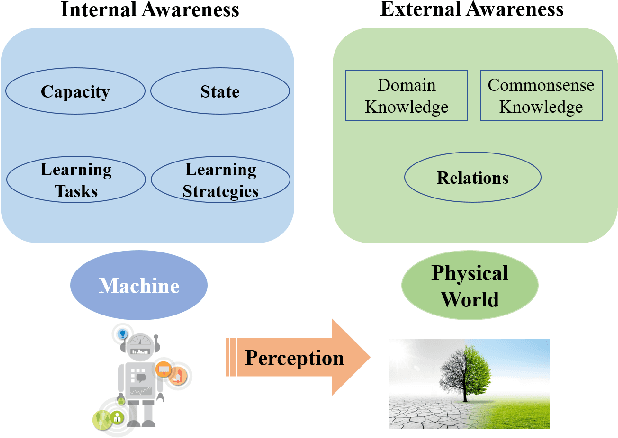
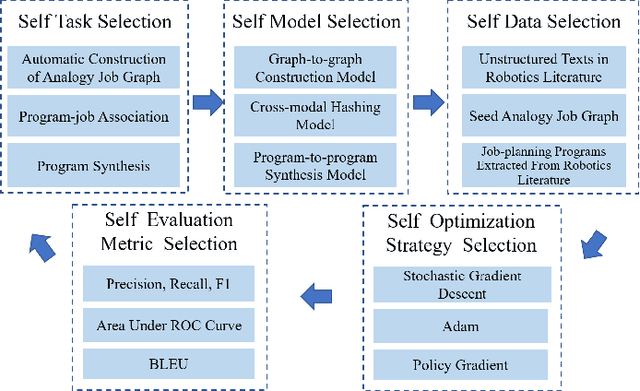
Conventional machine learning (ML) relies heavily on manual design from machine learning experts to decide learning tasks, data, models, optimization algorithms, and evaluation metrics, which is labor-intensive, time-consuming, and cannot learn autonomously like humans. In education science, self-directed learning, where human learners select learning tasks and materials on their own without requiring hands-on guidance, has been shown to be more effective than passive teacher-guided learning. Inspired by the concept of self-directed human learning, we introduce the principal concept of Self-directed Machine Learning (SDML) and propose a framework for SDML. Specifically, we design SDML as a self-directed learning process guided by self-awareness, including internal awareness and external awareness. Our proposed SDML process benefits from self task selection, self data selection, self model selection, self optimization strategy selection and self evaluation metric selection through self-awareness without human guidance. Meanwhile, the learning performance of the SDML process serves as feedback to further improve self-awareness. We propose a mathematical formulation for SDML based on multi-level optimization. Furthermore, we present case studies together with potential applications of SDML, followed by discussing future research directions. We expect that SDML could enable machines to conduct human-like self-directed learning and provide a new perspective towards artificial general intelligence.
Recognizing Exercises and Counting Repetitions in Real Time
May 07, 2020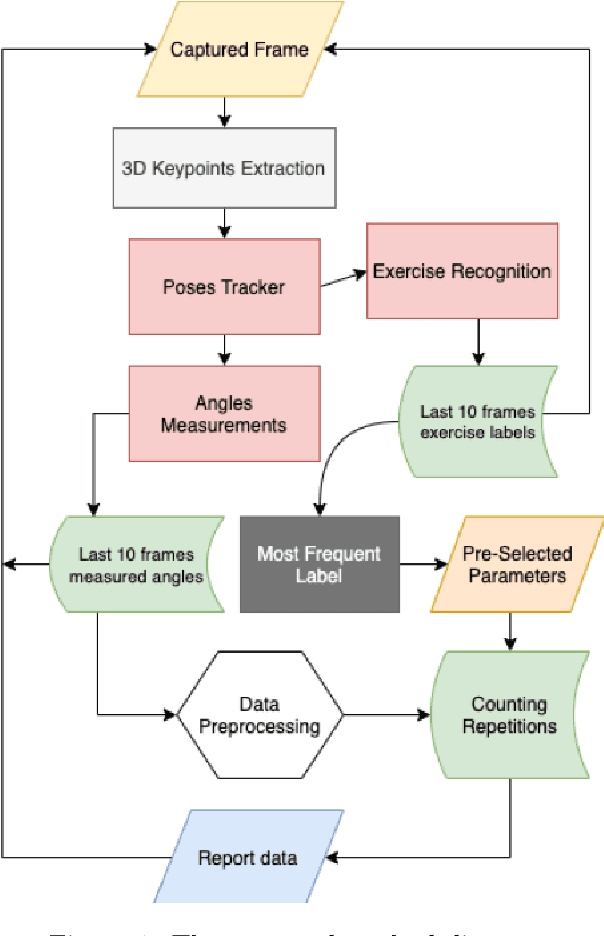
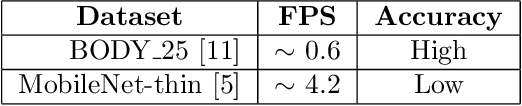

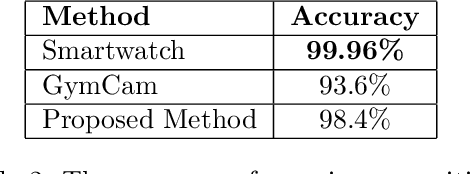
Artificial intelligence technology has made its way absolutely necessary in a variety of industries including the fitness industry. Human pose estimation is one of the important researches in the field of Computer Vision for the last few years. In this project, pose estimation and deep machine learning techniques are combined to analyze the performance and report feedback on the repetitions of performed exercises in real-time. Involving machine learning technology in the fitness industry could help the judges to count repetitions of any exercise during Weightlifting or CrossFit competitions.
Multiway Storage Modification Machines
Nov 12, 2021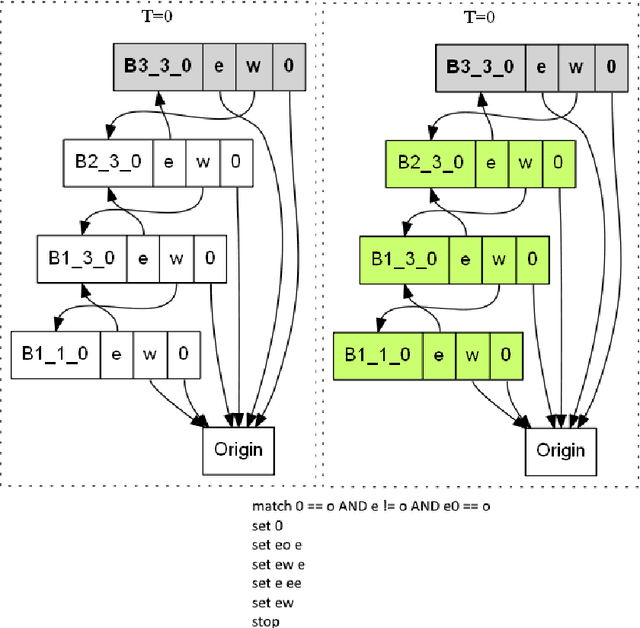

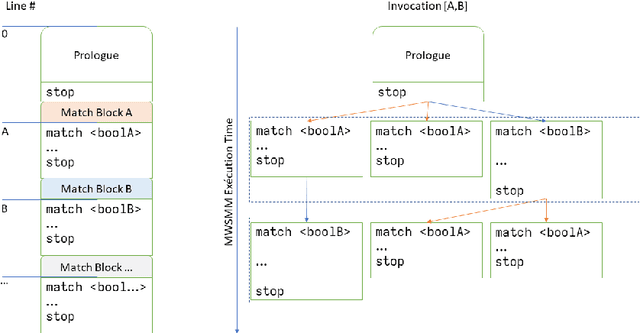

We present a parallel version of Sch\"onhage's Storage Modification Machine, the Multiway Storage Modification Machine (MWSMM). Like the alternative Association Storage Modification Machine of Tromp and van Emde Boas, MWSMMs recognize in polynomial time what Turing Machines recognize in polynomial space. Falling thus into the Second Machine Class, the MWSMM is a parallel machine model conforming to the Parallel Computation Thesis. We illustrate MWSMMs by a simple implementation of Wolfram's String Substitution System.
Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation
Feb 21, 2020
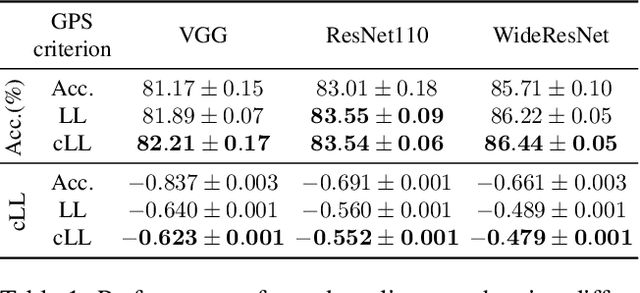
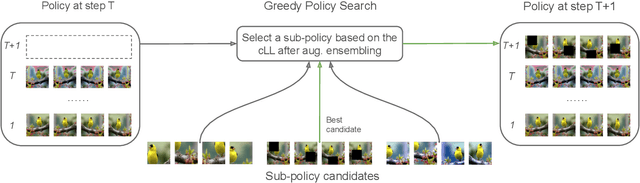

Test-time data augmentation---averaging the predictions of a machine learning model across multiple augmented samples of data---is a widely used technique that improves the predictive performance. While many advanced learnable data augmentation techniques have emerged in recent years, they are focused on the training phase. Such techniques are not necessarily optimal for test-time augmentation and can be outperformed by a policy consisting of simple crops and flips. The primary goal of this paper is to demonstrate that test-time augmentation policies can be successfully learned too. We~introduce \emph{greedy policy search} (GPS), a simple but high-performing method for learning a policy of test-time augmentation. We demonstrate that augmentation policies learned with GPS achieve superior predictive performance on image classification problems, provide better in-domain uncertainty estimation, and improve the robustness to domain shift.
A Theoretical Overview of Neural Contraction Metrics for Learning-based Control with Guaranteed Stability
Oct 02, 2021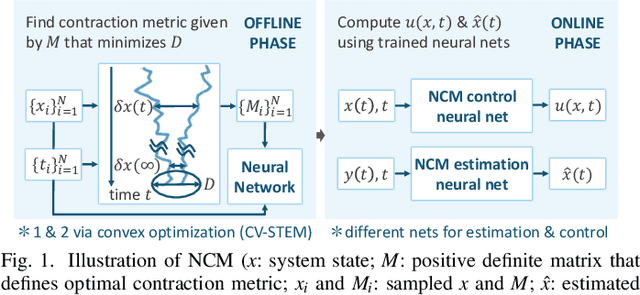
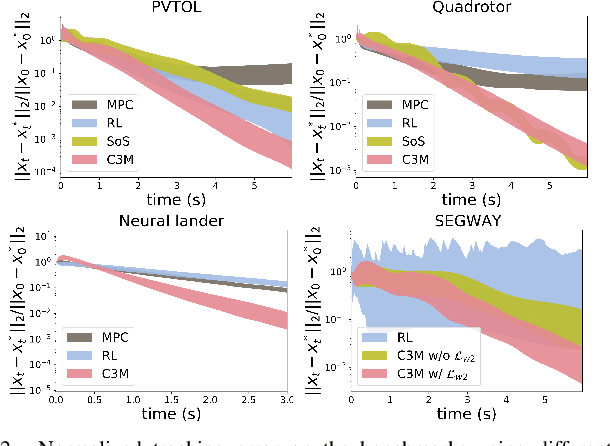
This paper presents a theoretical overview of a Neural Contraction Metric (NCM): a neural network model of an optimal contraction metric and corresponding differential Lyapunov function, the existence of which is a necessary and sufficient condition for incremental exponential stability of non-autonomous nonlinear system trajectories. Its innovation lies in providing formal robustness guarantees for learning-based control frameworks, utilizing contraction theory as an analytical tool to study the nonlinear stability of learned systems via convex optimization. In particular, we rigorously show in this paper that, by regarding modeling errors of the learning schemes as external disturbances, the NCM control is capable of obtaining an explicit bound on the distance between a time-varying target trajectory and perturbed solution trajectories, which exponentially decreases with time even under the presence of deterministic and stochastic perturbation. These useful features permit simultaneous synthesis of a contraction metric and associated control law by a neural network, thereby enabling real-time computable and probably robust learning-based control for general control-affine nonlinear systems.
Darknet Traffic Big-Data Analysis and Network Management to Real-Time Automating the Malicious Intent Detection Process by a Weight Agnostic Neural Networks Framework
Feb 16, 2021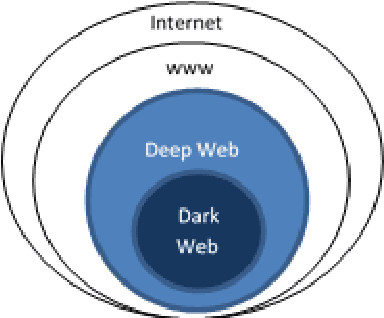
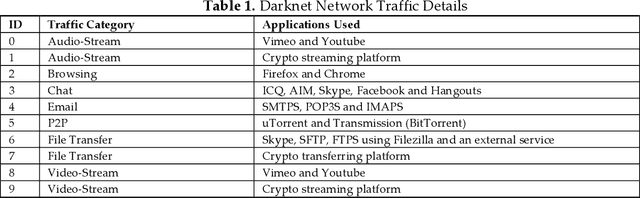

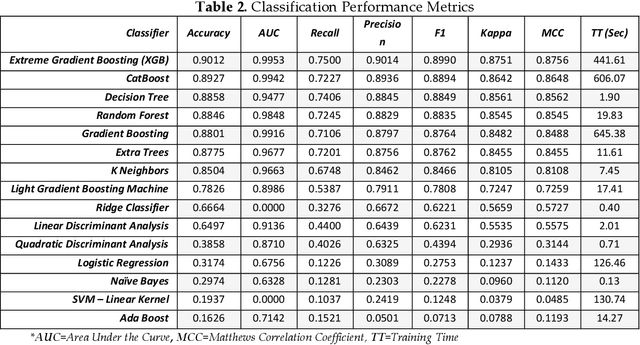
Attackers are perpetually modifying their tactics to avoid detection and frequently leverage legitimate credentials with trusted tools already deployed in a network environment, making it difficult for organizations to proactively identify critical security risks. Network traffic analysis products have emerged in response to attackers relentless innovation, offering organizations a realistic path forward for combatting creative attackers. Additionally, thanks to the widespread adoption of cloud computing, Device Operators processes, and the Internet of Things, maintaining effective network visibility has become a highly complex and overwhelming process. What makes network traffic analysis technology particularly meaningful is its ability to combine its core capabilities to deliver malicious intent detection. In this paper, we propose a novel darknet traffic analysis and network management framework to real-time automating the malicious intent detection process, using a weight agnostic neural networks architecture. It is an effective and accurate computational intelligent forensics tool for network traffic analysis, the demystification of malware traffic, and encrypted traffic identification in real-time. Based on Weight Agnostic Neural Networks methodology, we propose an automated searching neural net architectures strategy that can perform various tasks such as identify zero-day attacks. By automating the malicious intent detection process from the darknet, the advanced proposed solution is reducing the skills and effort barrier that prevents many organizations from effectively protecting their most critical assets.
An Analytical Update Rule for General Policy Optimization
Dec 03, 2021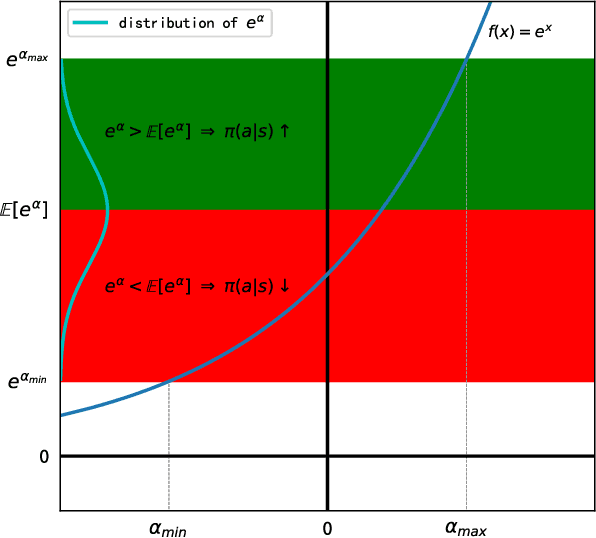
We present an analytical policy update rule that is independent of parameterized function approximators. The update rule is suitable for general stochastic policies with monotonic improvement guarantee. The update rule is derived from a closed-form trust-region solution using calculus of variation, following a new theoretical result that tightens existing bounds for policy search using trust-region methods. An explanation building a connection between the policy update rule and value-function methods is provided. Based on a recursive form of the update rule, an off-policy algorithm is derived naturally, and the monotonic improvement guarantee remains. Furthermore, the update rule extends immediately to multi-agent systems when updates are performed by one agent at a time.