 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Network based on Automatic Differentiation Transformation of Numeric Iterate-to-Fixedpoint
Oct 30, 2021
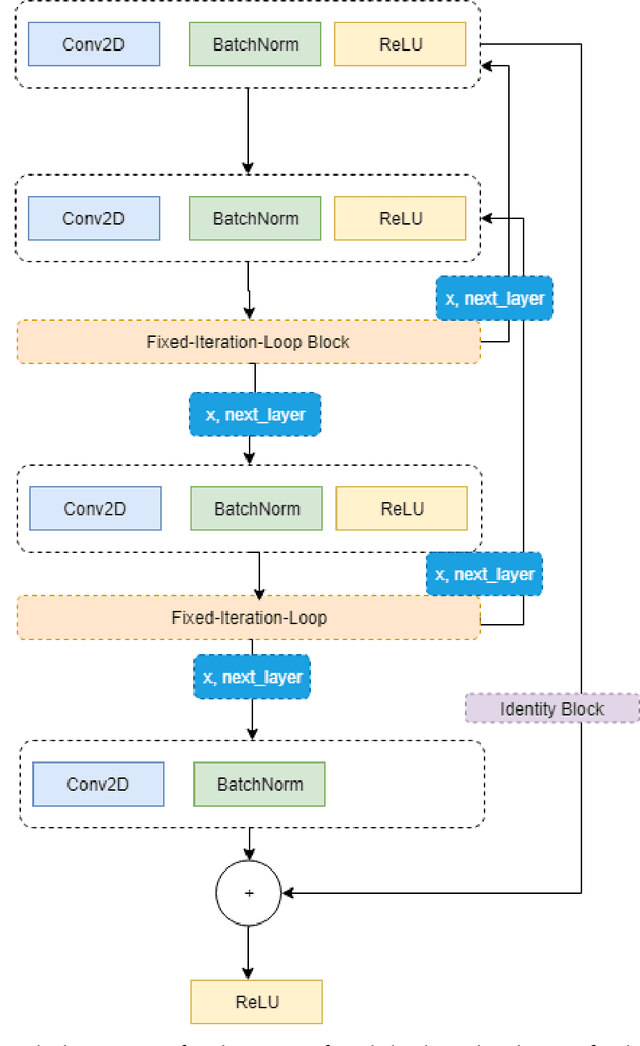

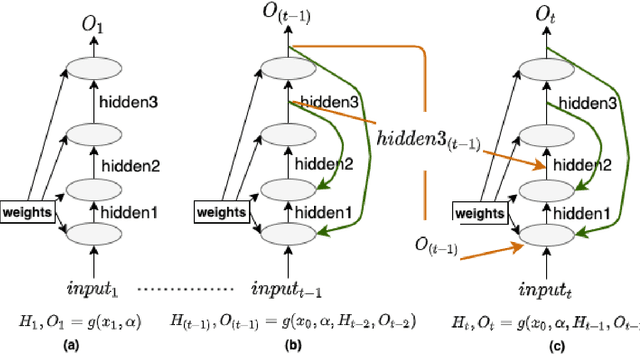

This work proposes a Neural Network model that can control its depth using an iterate-to-fixed-point operator. The architecture starts with a standard layered Network but with added connections from current later to earlier layers, along with a gate to make them inactive under most circumstances. These ``temporal wormhole'' connections create a shortcut that allows the Neural Network to use the information available at deeper layers and re-do earlier computations with modulated inputs. End-to-end training is accomplished by using appropriate calculations for a numeric iterate-to-fixed-point operator. In a typical case, where the ``wormhole'' connections are inactive, this is inexpensive; but when they are active, the network takes a longer time to settle down, and the gradient calculation is also more laborious, with an effect similar to making the network deeper. In contrast to the existing skip-connection concept, this proposed technique enables information to flow up and down in the network. Furthermore, the flow of information follows a fashion that seems analogous to the afferent and efferent flow of information through layers of processing in the brain. We evaluate models that use this novel mechanism on different long-term dependency tasks. The results are competitive with other studies, showing that the proposed model contributes significantly to overcoming traditional deep learning models' vanishing gradient descent problem. At the same time, the training time is significantly reduced, as the ``easy'' input cases are processed more quickly than ``difficult'' ones.
A review on outlier/anomaly detection in time series data
Feb 11, 2020

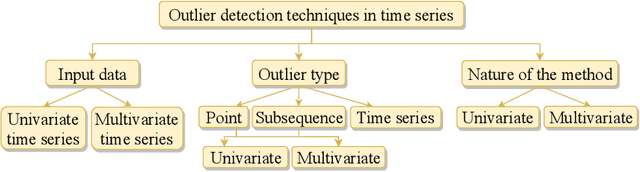
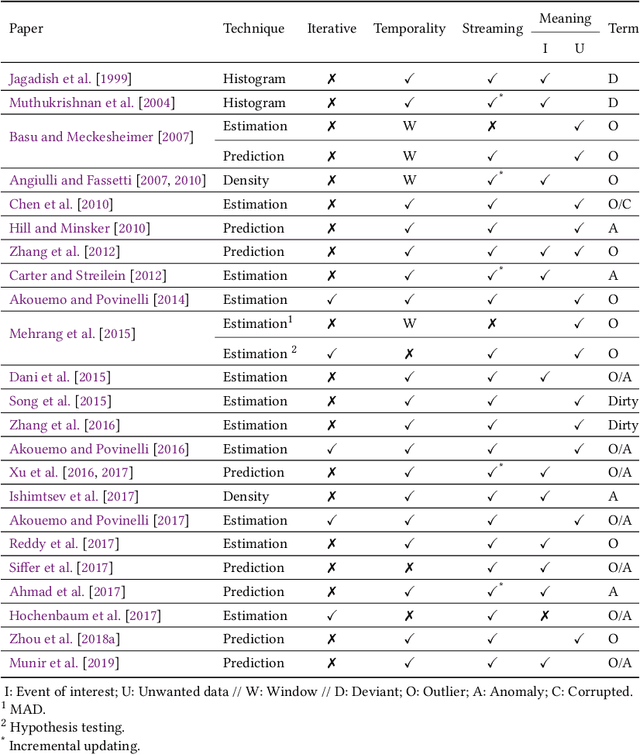
Recent advances in technology have brought major breakthroughs in data collection, enabling a large amount of data to be gathered over time and thus generating time series. Mining this data has become an important task for researchers and practitioners in the past few years, including the detection of outliers or anomalies that may represent errors or events of interest. This review aims to provide a structured and comprehensive state-of-the-art on outlier detection techniques in the context of time series. To this end, a taxonomy is presented based on the main aspects that characterize an outlier detection technique.
The Seven-League Scheme: Deep learning for large time step Monte Carlo simulations of stochastic differential equations
Sep 11, 2020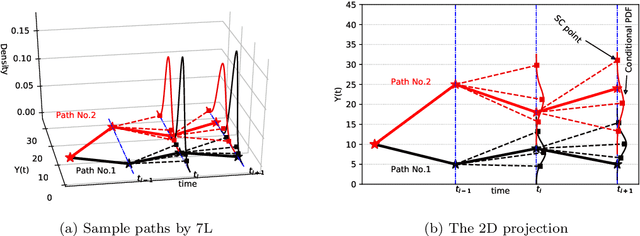
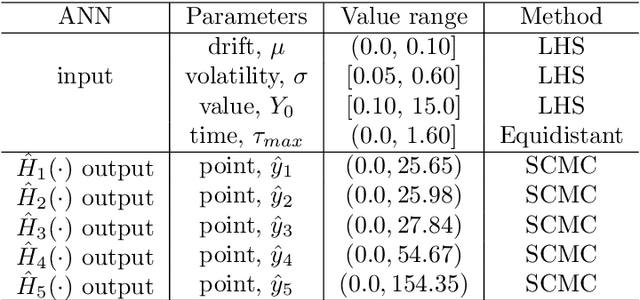
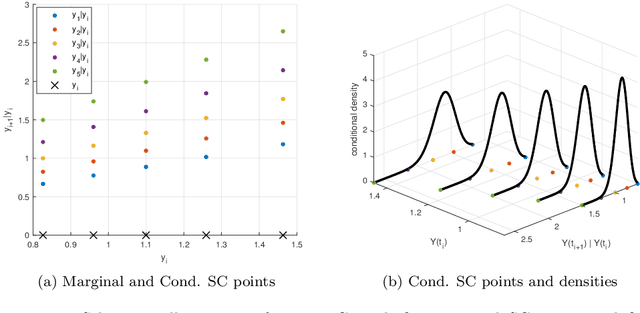

We propose an accurate data-driven numerical scheme to solve Stochastic Differential Equations (SDEs), by taking large time steps. The SDE discretization is built up by means of a polynomial chaos expansion method, on the basis of accurately determined stochastic collocation (SC) points. By employing an artificial neural network to learn these SC points, we can perform Monte Carlo simulations with large time steps. Error analysis confirms that this data-driven scheme results in accurate SDE solutions in the sense of strong convergence, provided the learning methodology is robust and accurate. With a variant method called the compression-decompression collocation and interpolation technique, we can drastically reduce the number of neural network functions that have to be learned, so that computational speed is enhanced. Numerical results show the high quality strong convergence error results, when using large time steps, and the novel scheme outperforms some classical numerical SDE discretizations. Some applications, here in financial option valuation, are also presented.
CNN-based Temporal Super Resolution of Radar Rainfall Products
Sep 20, 2021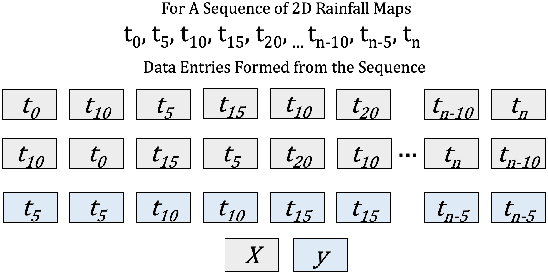
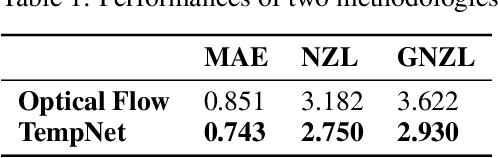
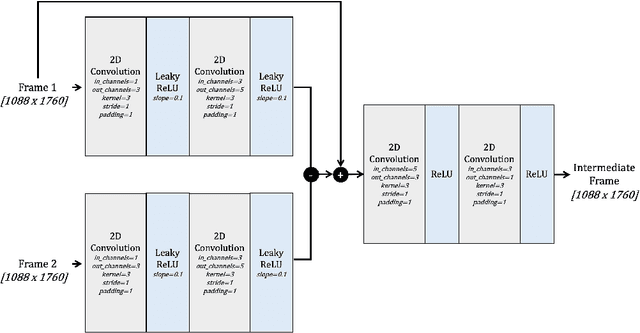
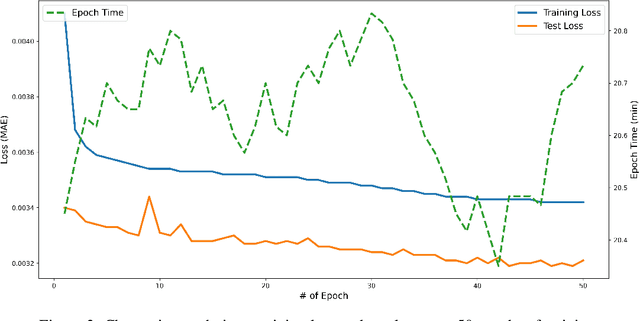
The temporal and spatial resolution of rainfall data is crucial for climate change modeling studies in which its variability in space and time is considered as a primary factor. Rainfall products from different remote sensing instruments (e.g., radar or satellite) provide different space-time resolutions because of the differences in their sensing capabilities. We developed an approach that augments rainfall data with increased time resolutions to complement relatively lower resolution products. This study proposes a neural network architecture based on Convolutional Neural Networks (CNNs) to improve temporal resolution of radar-based rainfall products and compares the proposed model with an optical flow-based interpolation method.
Unsupervised Temporal Video Grounding with Deep Semantic Clustering
Jan 14, 2022
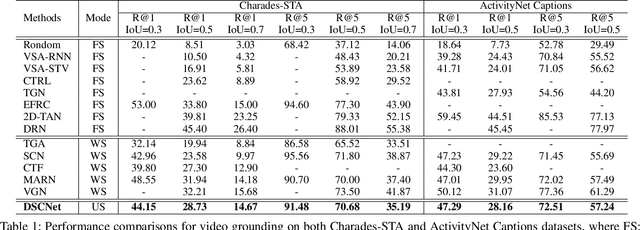
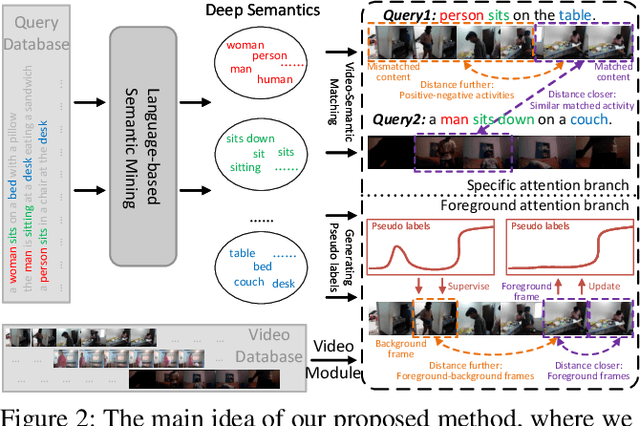

Temporal video grounding (TVG) aims to localize a target segment in a video according to a given sentence query. Though respectable works have made decent achievements in this task, they severely rely on abundant video-query paired data, which is expensive and time-consuming to collect in real-world scenarios. In this paper, we explore whether a video grounding model can be learned without any paired annotations. To the best of our knowledge, this paper is the first work trying to address TVG in an unsupervised setting. Considering there is no paired supervision, we propose a novel Deep Semantic Clustering Network (DSCNet) to leverage all semantic information from the whole query set to compose the possible activity in each video for grounding. Specifically, we first develop a language semantic mining module, which extracts implicit semantic features from the whole query set. Then, these language semantic features serve as the guidance to compose the activity in video via a video-based semantic aggregation module. Finally, we utilize a foreground attention branch to filter out the redundant background activities and refine the grounding results. To validate the effectiveness of our DSCNet, we conduct experiments on both ActivityNet Captions and Charades-STA datasets. The results demonstrate that DSCNet achieves competitive performance, and even outperforms most weakly-supervised approaches.
Bandlimited signal reconstruction from leaky integrate-and-fire encoding using POCS
Jan 09, 2022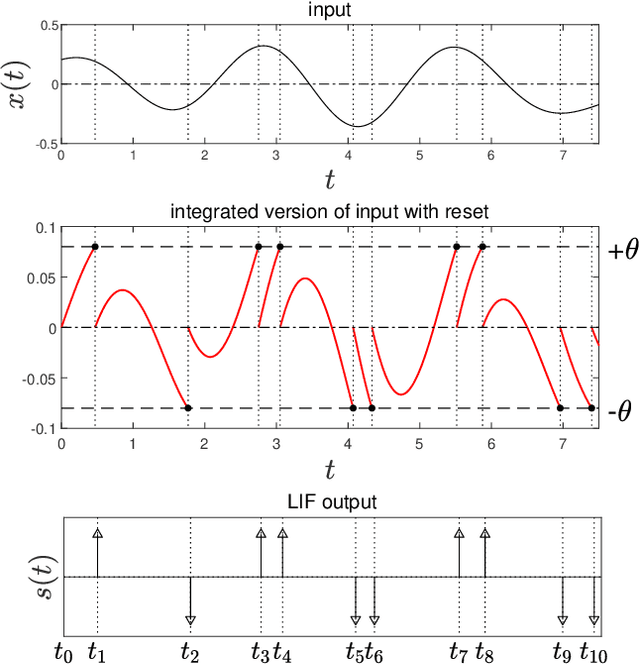
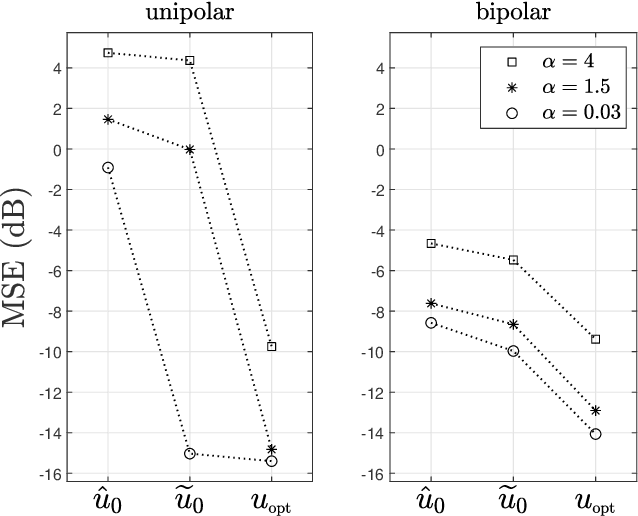
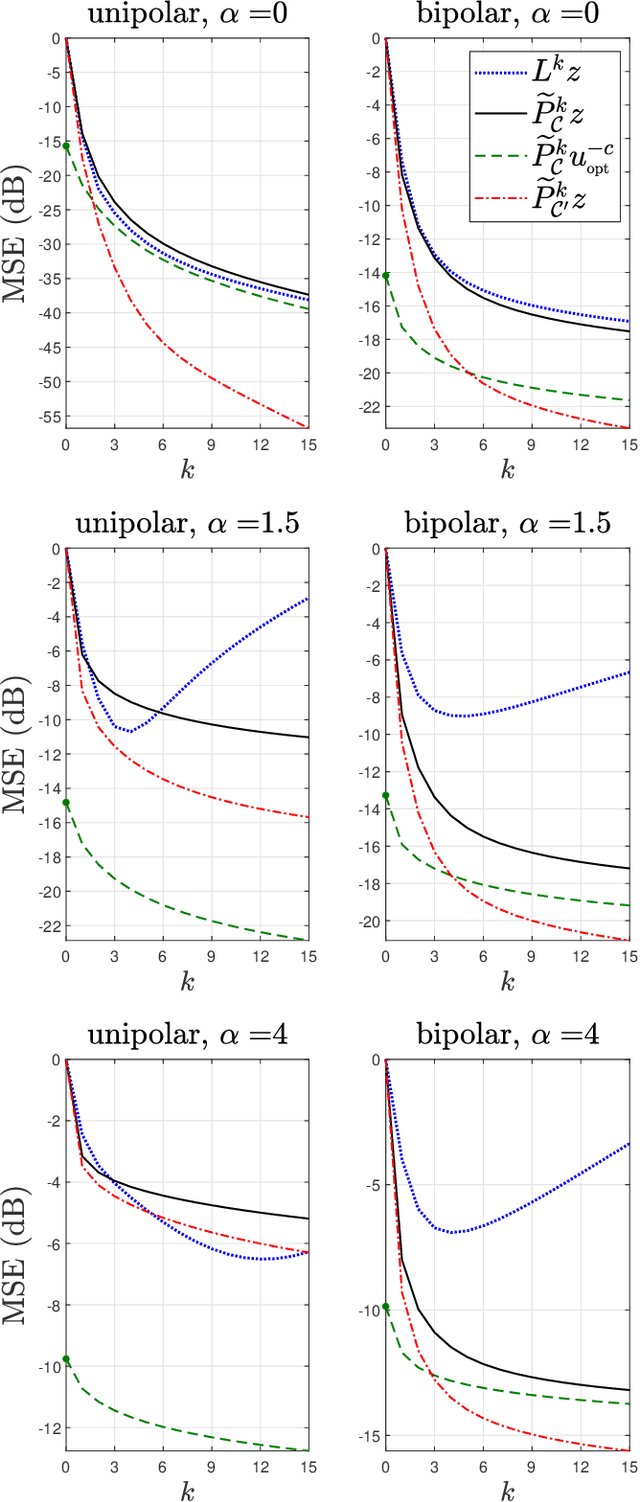
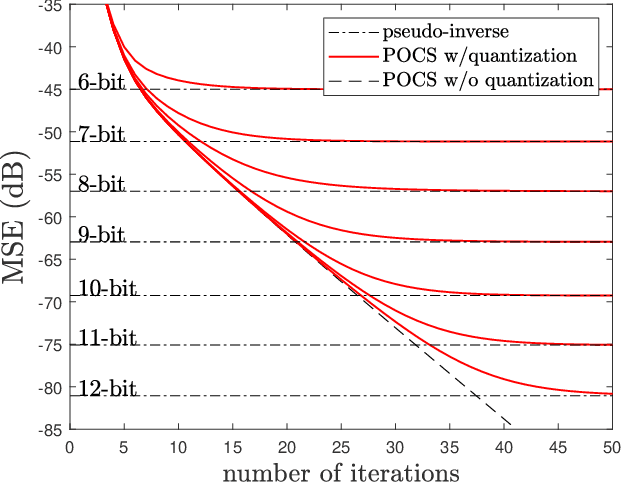
Leaky integrate-and-fire (LIF) encoding is a model of neuron transfer function in biology that has recently attracted the attention of the signal processing and neuromorphic computing communities as a technique of event-based sampling for data acquisition. While LIF enables the implementation of analog-circuit signal samplers of lower complexity and higher accuracy simultaneously, the core difficulty of this technique is the retrieval of an input from its LIF-encoded output. This theoretically requires to perform the pseudo-inversion of a linear but time-varying operator of virtually infinite size. In the context of bandlimited inputs to allow finite-rate sampling, we show two fundamental contributions of the method of projection onto convex sets (POCS) to this problem: (i) single iterations of the POCS method can be used to deterministically improve input estimates from any other reconstruction method; (ii) the iteration limit of the POCS method is the pseudo-inverse of the above mentioned operator in all conditions, whether reconstruction is unique or not and whether the encoding is corrupted by noise or not. The algorithms available until now converge only under particular situations of unique of reconstruction.
AI-based Carcinoma Detection and Classification Using Histopathological Images: A Systematic Review
Jan 18, 2022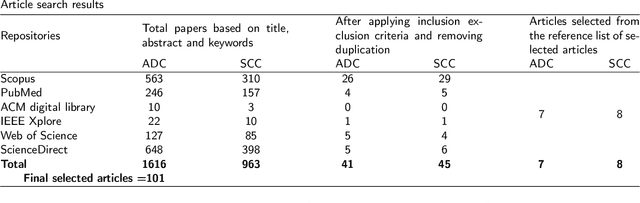
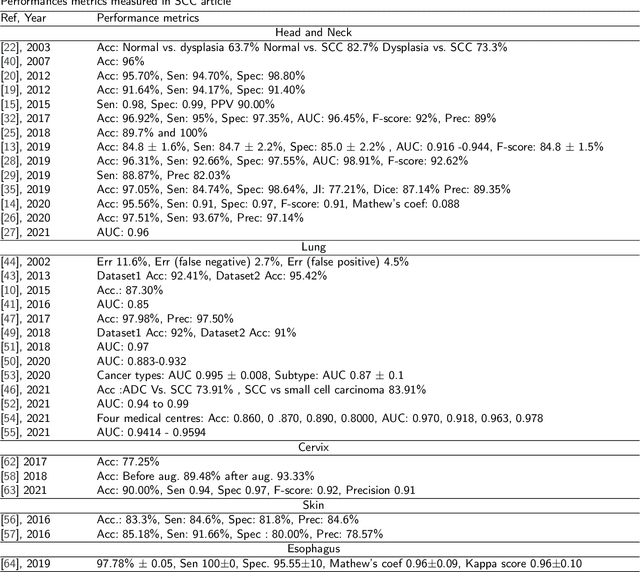

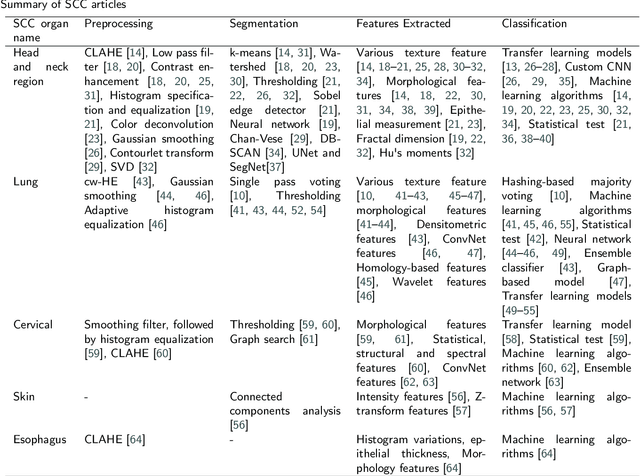
Histopathological image analysis is the gold standard to diagnose cancer. Carcinoma is a subtype of cancer that constitutes more than 80% of all cancer cases. Squamous cell carcinoma and adenocarcinoma are two major subtypes of carcinoma, diagnosed by microscopic study of biopsy slides. However, manual microscopic evaluation is a subjective and time-consuming process. Many researchers have reported methods to automate carcinoma detection and classification. The increasing use of artificial intelligence (AI) in the automation of carcinoma diagnosis also reveals a significant rise in the use of deep network models. In this systematic literature review, we present a comprehensive review of the state-of-the-art approaches reported in carcinoma diagnosis using histopathological images. Studies are selected from well-known databases with strict inclusion/exclusion criteria. We have categorized the articles and recapitulated their methods based on specific organs of carcinoma origin. Further, we have summarized pertinent literature on AI methods, highlighted critical challenges and limitations, and provided insights on future research direction in automated carcinoma diagnosis. Out of 101 articles selected, most of the studies experimented on private datasets with varied image sizes, obtaining accuracy between 63% and 100%. Overall, this review highlights the need for a generalized AI-based carcinoma diagnostic system. Additionally, it is desirable to have accountable approaches to extract microscopic features from images of multiple magnifications that should mimic pathologists' evaluations.
Joint Radar-Communications Processing from a Dual-Blind Deconvolution Perspective
Nov 11, 2021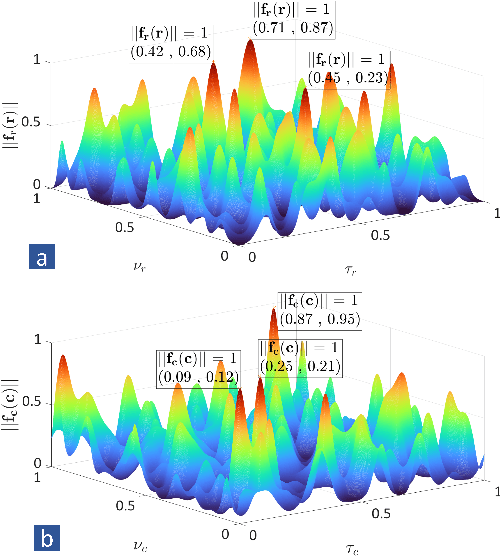

We consider a general spectral coexistence scenario, wherein the channels and transmit signals of both radar and communications systems are unknown at the receiver. In this \textit{dual-blind deconvolution} (DBD) problem, a common receiver admits the multi-carrier wireless communications signal that is overlaid with the radar signal reflected-off multiple targets. When the radar receiver is not collocated with the transmitter, such as in passive or multistatic radars, the transmitted signal is also unknown apart from the target parameters. Similarly, apart from the transmitted messages, the communications channel may also be unknown in dynamic environments such as vehicular networks. As a result, the estimation of unknown target and communications parameters in a DBD scenario is highly challenging. In this work, we exploit the sparsity of the channel to solve DBD by casting it as an atomic norm minimization problem. Our theoretical analyses and numerical experiments demonstrate perfect recovery of continuous-valued range-time and Doppler velocities of multiple targets as well as delay-Doppler communications channel parameters using uniformly-spaced time samples in the dual-blind receiver.
Online Advertising Revenue Forecasting: An Interpretable Deep Learning Approach
Nov 16, 2021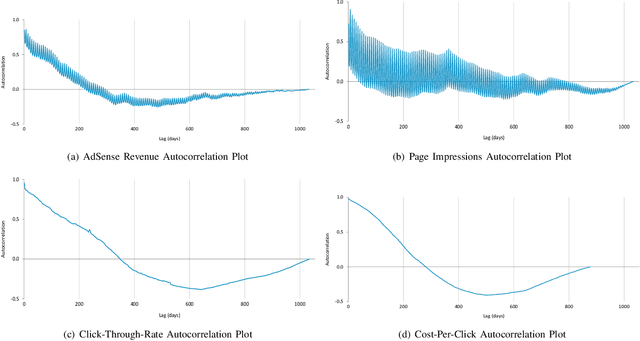
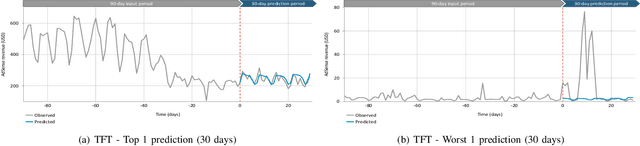
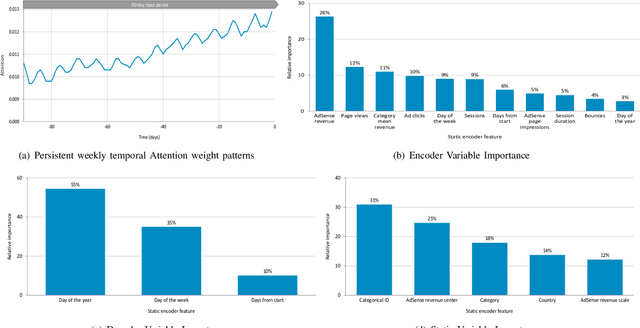

Online advertising revenues account for an increasing share of publishers' revenue streams, especially for small and medium-sized publishers who depend on the advertisement networks of tech companies such as Google and Facebook. Thus publishers may benefit significantly from accurate online advertising revenue forecasts to better manage their website monetization strategies. However, publishers who only have access to their own revenue data lack a holistic view of the total ad market of publishers, which in turn limits their ability to generate insights into their own future online advertising revenues. To address this business issue, we leverage a proprietary database encompassing Google Adsense revenues from a large collection of publishers in diverse areas. We adopt the Temporal Fusion Transformer (TFT) model, a novel attention-based architecture to predict publishers' advertising revenues. We leverage multiple covariates, including not only the publisher's own characteristics but also other publishers' advertising revenues. Our prediction results outperform several benchmark deep-learning time-series forecast models over multiple time horizons. Moreover, we interpret the results by analyzing variable importance weights to identify significant features and self-attention weights to reveal persistent temporal patterns.
SODEN: A Scalable Continuous-Time Survival Model through Ordinary Differential Equation Networks
Aug 19, 2020
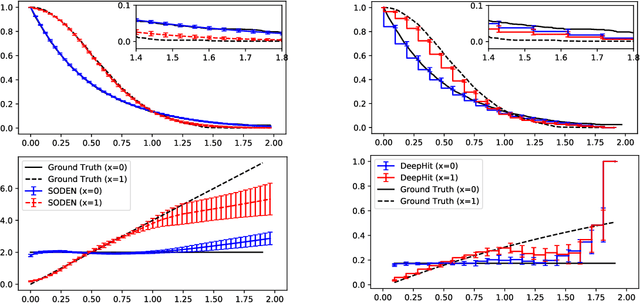
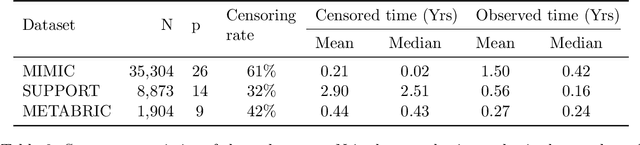
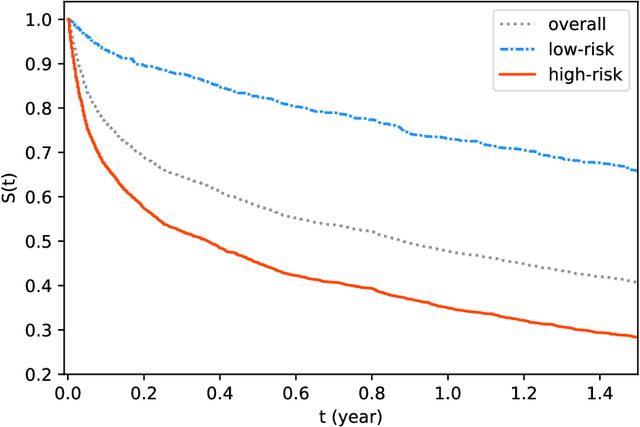
In this paper, we propose a flexible model for survival analysis using neural networks along with scalable optimization algorithms. One key technical challenge for directly applying maximum likelihood estimation (MLE) to censored data is that evaluating the objective function and its gradients with respect to model parameters requires the calculation of integrals. To address this challenge, we recognize that the MLE for censored data can be viewed as a differential-equation constrained optimization problem, a novel perspective. Following this connection, we model the distribution of event time through an ordinary differential equation and utilize efficient ODE solvers and adjoint sensitivity analysis to numerically evaluate the likelihood and the gradients. Using this approach, we are able to 1) provide a broad family of continuous-time survival distributions without strong structural assumptions, 2) obtain powerful feature representations using neural networks, and 3) allow efficient estimation of the model in large-scale applications using stochastic gradient descent. Through both simulation studies and real-world data examples, we demonstrate the effectiveness of the proposed method in comparison to existing state-of-the-art deep learning survival analysis models.