 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhanced Wi-Fi RTT Ranging: A Sensor-Aided Learning Approach
Dec 28, 2021
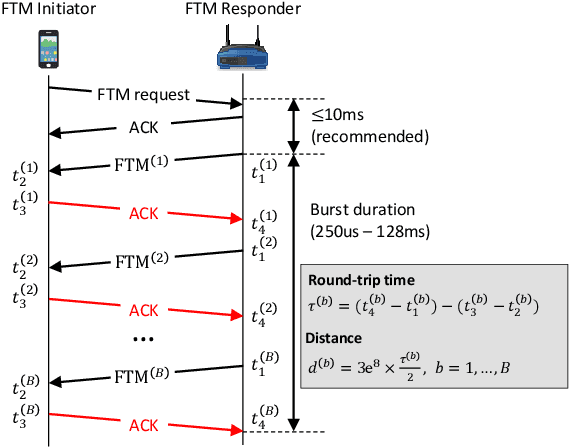
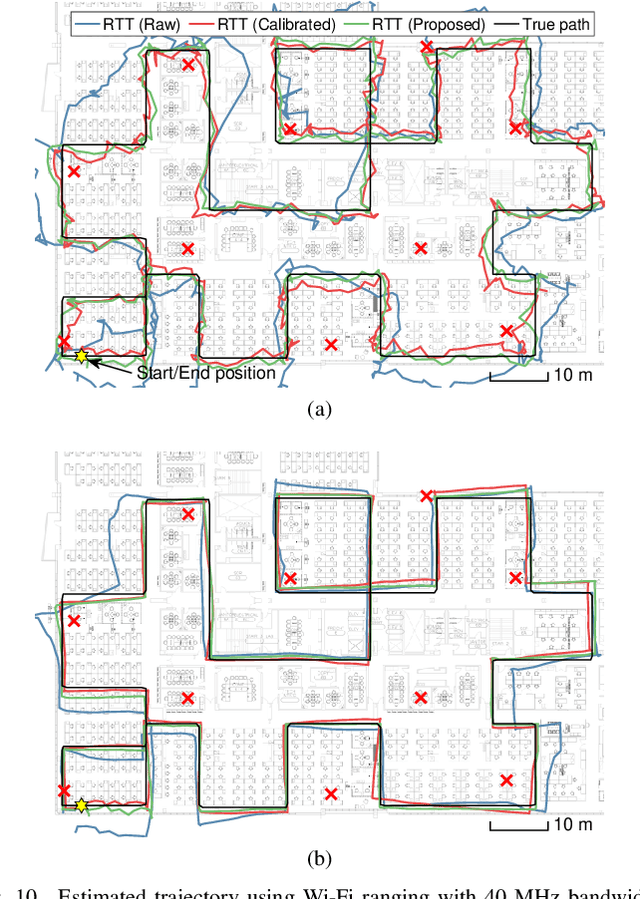
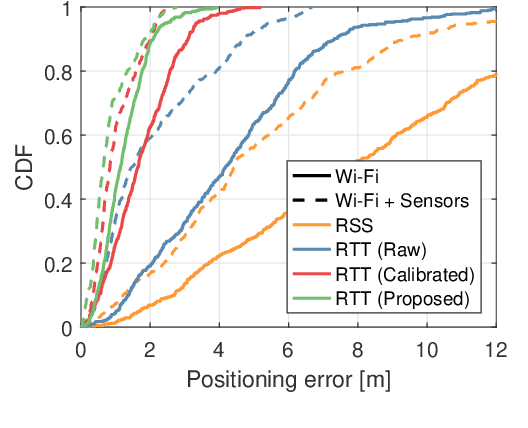
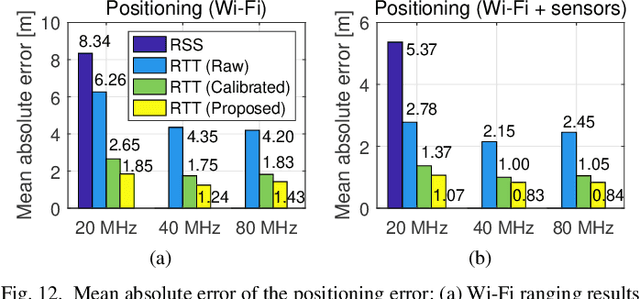
The fine timing measurement (FTM) protocol is designed to determine precise ranging between Wi-Fi devices using round-trip time (RTT) measurements. However, the multipath propagation of radio waves generates inaccurate timing information, degrading the ranging performance. In this study, we use a neural network (NN) to adaptively learn the unique measurement patterns observed at different indoor environments and produce enhanced ranging outputs from raw FTM measurements. Moreover, the NN is trained based on an unsupervised learning framework, using the naturally accumulated sensor data acquired from users accessing location services. Therefore, the effort involved in collecting training data is significantly minimized. The experimental results verified that the collection of unlabeled data for a short duration is sufficient to learn the pattern in raw FTM measurements and produce improved ranging results. The proposed method reduced the ranging errors in raw distance measurements and well-calibrated ranging results requiring the collection of ground truth data by 47-50% and 17-29%, respectively. Consequently, positioning error reduced by 17-30% compared to the result with well-calibrated ranging.
Time-Frequency Scattering Accurately Models Auditory Similarities Between Instrumental Playing Techniques
Jul 21, 2020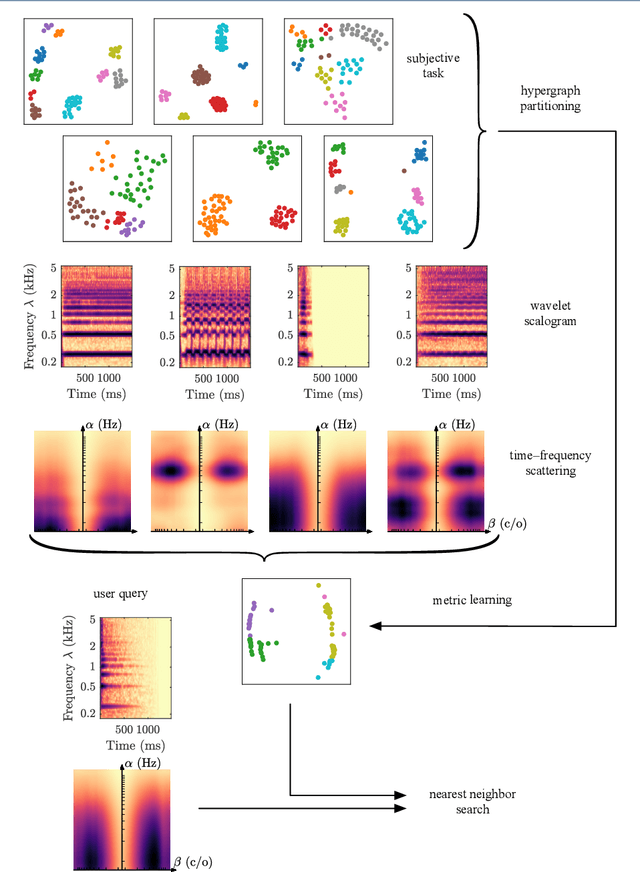
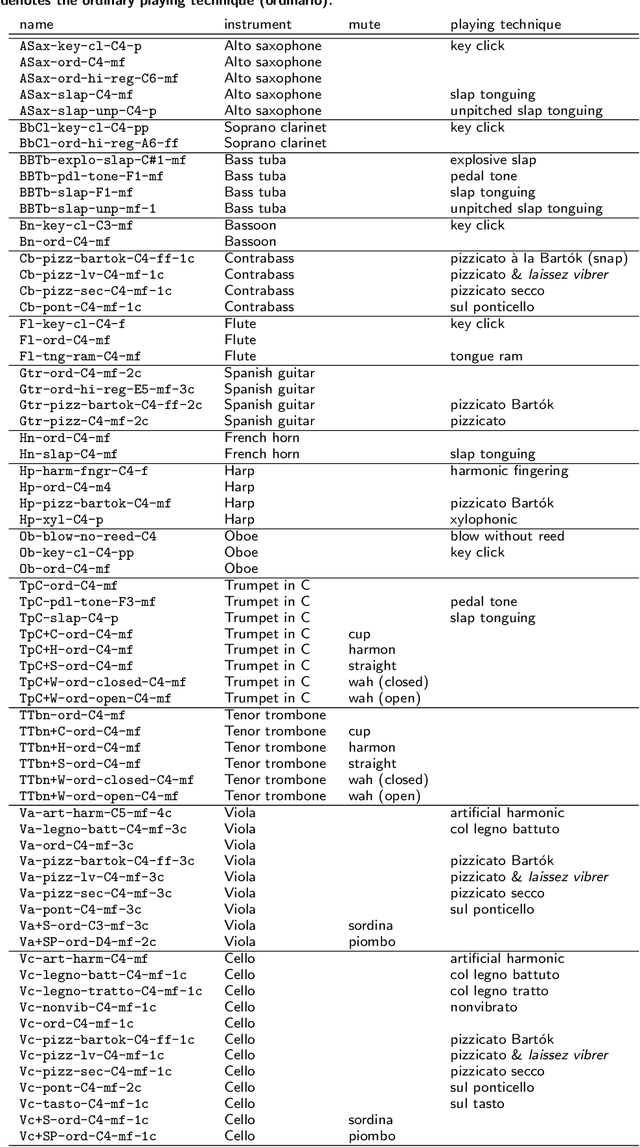

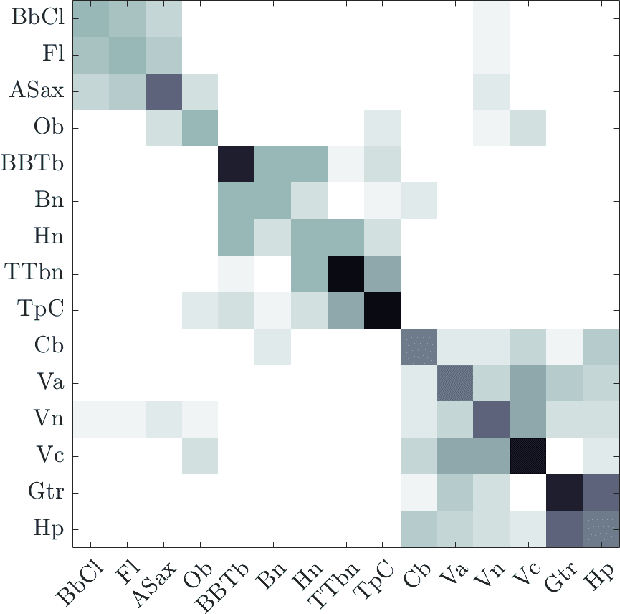
Instrumental playing techniques such as vibratos, glissandos, and trills often denote musical expressivity, both in classical and folk contexts. However, most existing approaches to music similarity retrieval fail to describe timbre beyond the so-called ``ordinary'' technique, use instrument identity as a proxy for timbre quality, and do not allow for customization to the perceptual idiosyncrasies of a new subject. In this article, we ask 31 human subjects to organize 78 isolated notes into a set of timbre clusters. Analyzing their responses suggests that timbre perception operates within a more flexible taxonomy than those provided by instruments or playing techniques alone. In addition, we propose a machine listening model to recover the cluster graph of auditory similarities across instruments, mutes, and techniques. Our model relies on joint time--frequency scattering features to extract spectrotemporal modulations as acoustic features. Furthermore, it minimizes triplet loss in the cluster graph by means of the large-margin nearest neighbor (LMNN) metric learning algorithm. Over a dataset of 9346 isolated notes, we report a state-of-the-art average precision at rank five (AP@5) of $99.0\%\pm1$. An ablation study demonstrates that removing either the joint time--frequency scattering transform or the metric learning algorithm noticeably degrades performance.
ZSpeedL -- Evaluating the Performance of Zero-Shot Learning Methods using Low-Power Devices
Oct 09, 2021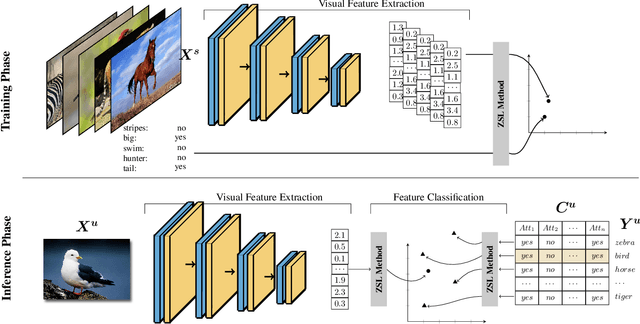
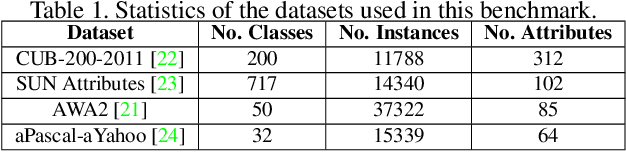

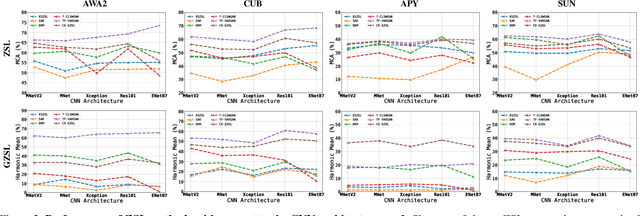
The recognition of unseen objects from a semantic representation or textual description, usually denoted as zero-shot learning, is more prone to be used in real-world scenarios when compared to traditional object recognition. Nevertheless, no work has evaluated the feasibility of deploying zero-shot learning approaches in these scenarios, particularly when using low-power devices. In this paper, we provide the first benchmark on the inference time of zero-shot learning, comprising an evaluation of state-of-the-art approaches regarding their speed/accuracy trade-off. An analysis to the processing time of the different phases of the ZSL inference stage reveals that visual feature extraction is the major bottleneck in this paradigm, but, we show that lightweight networks can dramatically reduce the overall inference time without reducing the accuracy obtained by the de facto ResNet101 architecture. Also, this benchmark evaluates how different ZSL approaches perform in low-power devices, and how the visual feature extraction phase could be optimized in this hardware. To foster the research and deployment of ZSL systems capable of operating in real-world scenarios, we release the evaluation framework used in this benchmark (https://github.com/CristianoPatricio/zsl-methods).
Recognizing Exercises and Counting Repetitions in Real Time
May 07, 2020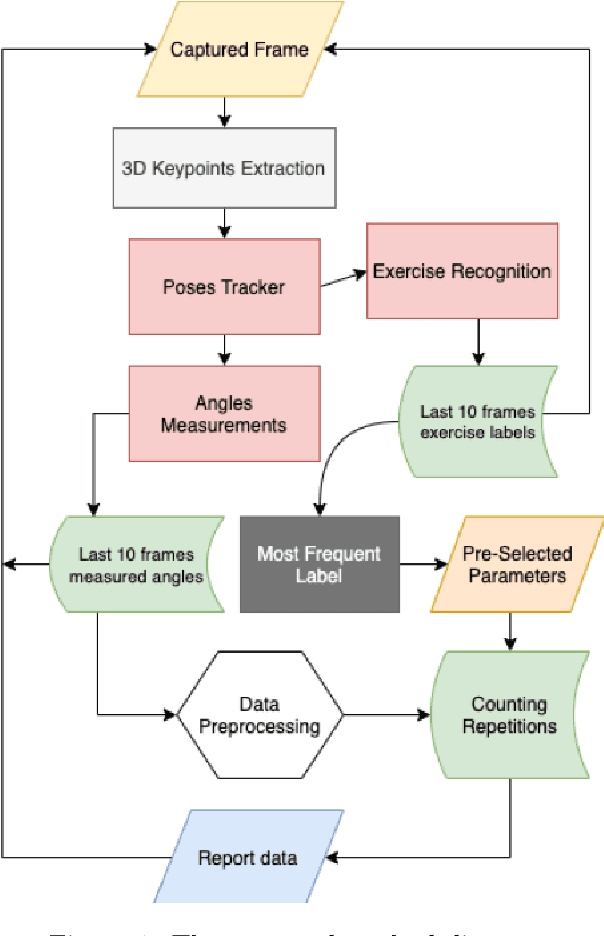
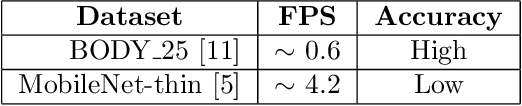

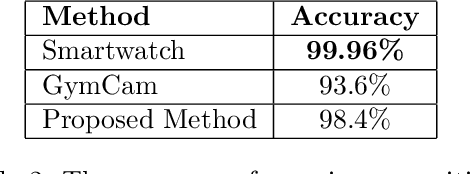
Artificial intelligence technology has made its way absolutely necessary in a variety of industries including the fitness industry. Human pose estimation is one of the important researches in the field of Computer Vision for the last few years. In this project, pose estimation and deep machine learning techniques are combined to analyze the performance and report feedback on the repetitions of performed exercises in real-time. Involving machine learning technology in the fitness industry could help the judges to count repetitions of any exercise during Weightlifting or CrossFit competitions.
Unsupervised Domain Adaptation for Constraining Star Formation Histories
Dec 28, 2021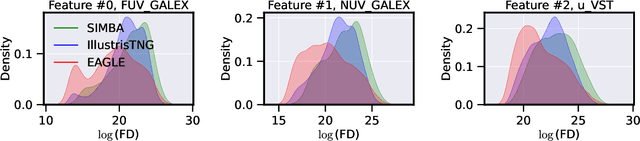
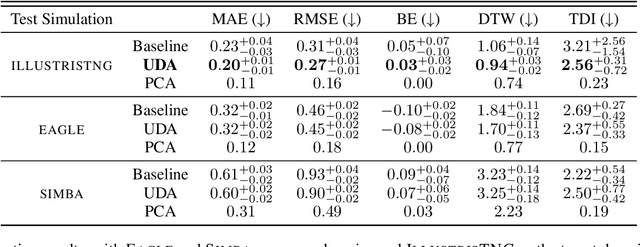
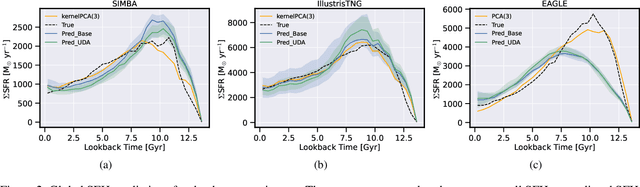
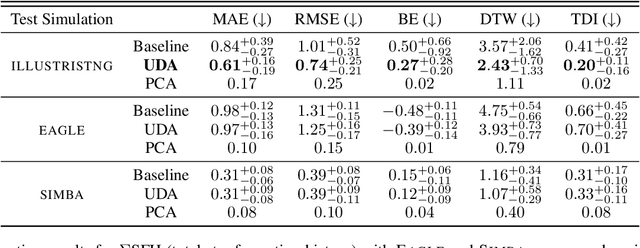
The prevalent paradigm of machine learning today is to use past observations to predict future ones. What if, however, we are interested in knowing the past given the present? This situation is indeed one that astronomers must contend with often. To understand the formation of our universe, we must derive the time evolution of the visible mass content of galaxies. However, to observe a complete star life, one would need to wait for one billion years! To overcome this difficulty, astrophysicists leverage supercomputers and evolve simulated models of galaxies till the current age of the universe, thus establishing a mapping between observed radiation and star formation histories (SFHs). Such ground-truth SFHs are lacking for actual galaxy observations, where they are usually inferred -- with often poor confidence -- from spectral energy distributions (SEDs) using Bayesian fitting methods. In this investigation, we discuss the ability of unsupervised domain adaptation to derive accurate SFHs for galaxies with simulated data as a necessary first step in developing a technique that can ultimately be applied to observational data.
LSTM Architecture for Oil Stocks Prices Prediction
Jan 02, 2022
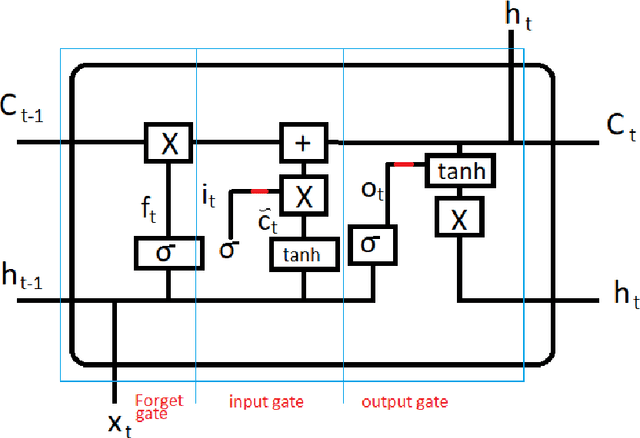
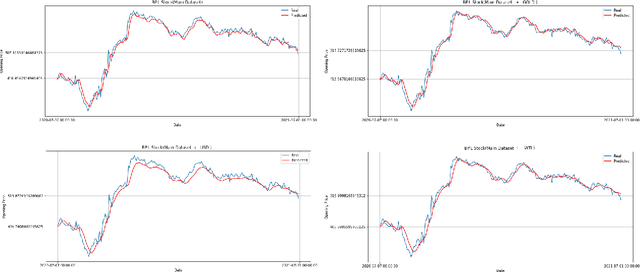
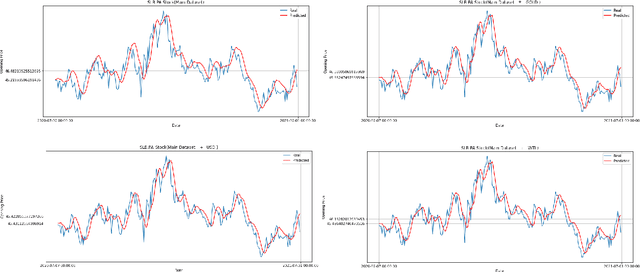
Oil companies are among the largest companies in the world whose economic indicators in the global stock market have a great impact on the world economy and market due to their relation to gold, crude oil, and the dollar. To quantify these relations we use the correlation feature and the relationships between stocks with the dollar, crude oil, gold, and major oil company stock indices, we create datasets and compare the results of forecasts with real data. To predict the stocks of different companies, we use Recurrent Neural Networks (RNNs) and LSTM, because these stocks change in time series. We carry on empirical experiments and perform on the stock indices dataset to evaluate the prediction performance in terms of several common error metrics such as Mean Square Error (MSE), Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and Mean Absolute Percentage Error (MAPE). The received results are promising and present a reasonably accurate prediction for the price of oil companies' stocks in the near future. The results show that RNNs do not have the interpretability, and we cannot improve the model by adding any correlated data.
Almost Optimal Batch-Regret Tradeoff for Batch Linear Contextual Bandits
Nov 09, 2021We study the optimal batch-regret tradeoff for batch linear contextual bandits. For any batch number $M$, number of actions $K$, time horizon $T$, and dimension $d$, we provide an algorithm and prove its regret guarantee, which, due to technical reasons, features a two-phase expression as the time horizon $T$ grows. We also prove a lower bound theorem that surprisingly shows the optimality of our two-phase regret upper bound (up to logarithmic factors) in the \emph{full range} of the problem parameters, therefore establishing the exact batch-regret tradeoff. Compared to the recent work \citep{ruan2020linear} which showed that $M = O(\log \log T)$ batches suffice to achieve the asymptotically minimax-optimal regret without the batch constraints, our algorithm is simpler and easier for practical implementation. Furthermore, our algorithm achieves the optimal regret for all $T \geq d$, while \citep{ruan2020linear} requires that $T$ greater than an unrealistically large polynomial of $d$. Along our analysis, we also prove a new matrix concentration inequality with dependence on their dynamic upper bounds, which, to the best of our knowledge, is the first of its kind in literature and maybe of independent interest.
Forecasting Crude Oil Price Using Event Extraction
Nov 14, 2021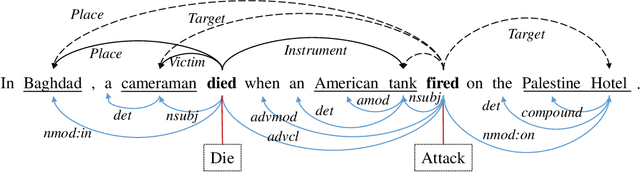
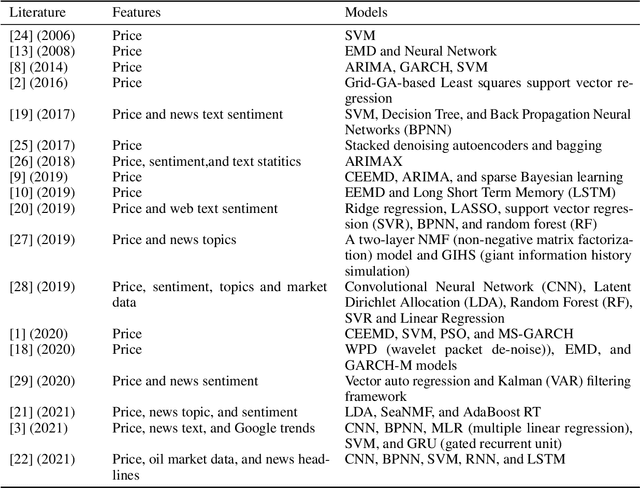

Research on crude oil price forecasting has attracted tremendous attention from scholars and policymakers due to its significant effect on the global economy. Besides supply and demand, crude oil prices are largely influenced by various factors, such as economic development, financial markets, conflicts, wars, and political events. Most previous research treats crude oil price forecasting as a time series or econometric variable prediction problem. Although recently there have been researches considering the effects of real-time news events, most of these works mainly use raw news headlines or topic models to extract text features without profoundly exploring the event information. In this study, a novel crude oil price forecasting framework, AGESL, is proposed to deal with this problem. In our approach, an open domain event extraction algorithm is utilized to extract underlying related events, and a text sentiment analysis algorithm is used to extract sentiment from massive news. Then a deep neural network integrating the news event features, sentimental features, and historical price features is built to predict future crude oil prices. Empirical experiments are performed on West Texas Intermediate (WTI) crude oil price data, and the results show that our approach obtains superior performance compared with several benchmark methods.
* 14 pages, 5 figures, 5 tables
Agricultural Plant Cataloging and Establishment of a Data Framework from UAV-based Crop Images by Computer Vision
Jan 11, 2022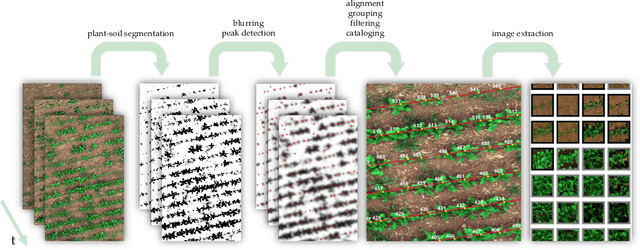


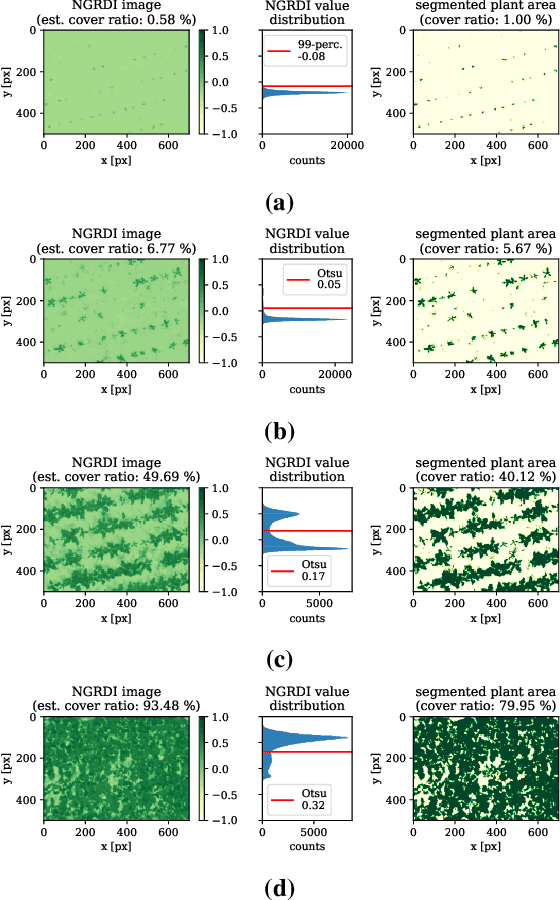
UAV-based image retrieval in modern agriculture enables gathering large amounts of spatially referenced crop image data. In large-scale experiments, however, UAV images suffer from containing a multitudinous amount of crops in a complex canopy architecture. Especially for the observation of temporal effects, this complicates the recognition of individual plants over several images and the extraction of relevant information tremendously. In this work, we present a hands-on workflow for the automatized temporal and spatial identification and individualization of crop images from UAVs abbreviated as "cataloging" based on comprehensible computer vision methods. We evaluate the workflow on two real-world datasets. One dataset is recorded for observation of Cercospora leaf spot - a fungal disease - in sugar beet over an entire growing cycle. The other one deals with harvest prediction of cauliflower plants. The plant catalog is utilized for the extraction of single plant images seen over multiple time points. This gathers large-scale spatio-temporal image dataset that in turn can be applied to train further machine learning models including various data layers. The presented approach improves analysis and interpretation of UAV data in agriculture significantly. By validation with some reference data, our method shows an accuracy that is similar to more complex deep learning-based recognition techniques. Our workflow is able to automatize plant cataloging and training image extraction, especially for large datasets.
Delay Alignment Modulation: Enabling Equalization-Free Single-Carrier Communication
Jan 07, 2022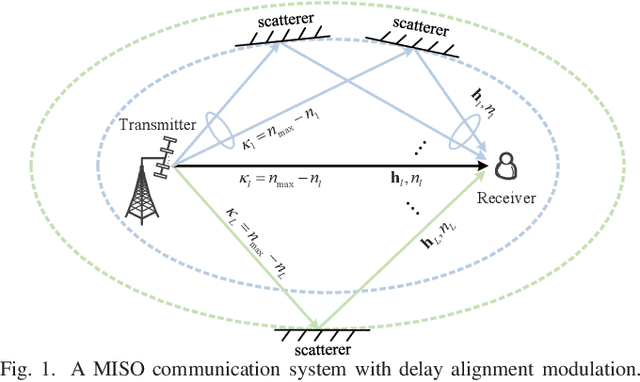
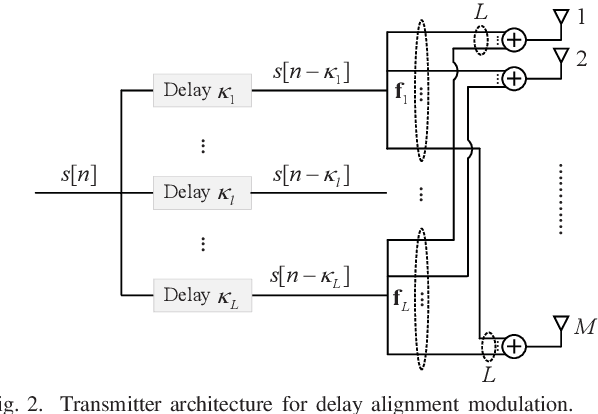
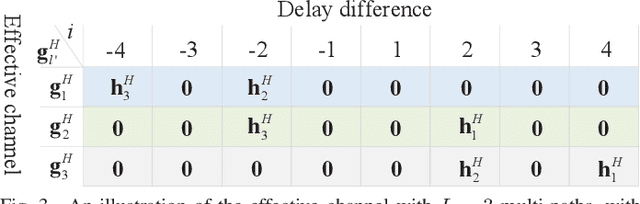

This paper proposes a novel broadband transmission technology, termed delay alignment modulation (DAM), which enables the low-complexity equalization-free single-carrier communication, yet without suffering from inter-symbol interference (ISI). The key idea of DAM is to deliberately introduce appropriate delays for information-bearing symbols at the transmitter side, so that after propagating over the time-dispersive channel, all multi-path signal components will arrive at the receiver simultaneously and constructively. We first show that by applying DAM for the basic multiple-input single-output (MISO) communication system, an ISI-free additive white Gaussian noise (AWGN) system can be obtained with the simple zero-forcing (ZF) beamforming. Furthermore, the more general DAM scheme is studied with the ISI-maximal-ratio transmission (MRT) and the ISI-minimum mean-square error (MMSE) beamforming. Simulation results are provided to show that when the channel is sparse and/or the antenna dimension is large, DAM not only resolves the notorious practical issues suffered by orthogonal frequency-division multiplexing (OFDM) such as high peak-to-average-power ratio (PAPR), severe out-of-band (OOB) emission, and vulnerability to carrier frequency offset (CFO), with low complexity, but also achieves higher spectral efficiency due to the saving of guard interval overhead.