 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Phoebe: A Learning-based Checkpoint Optimizer
Oct 05, 2021
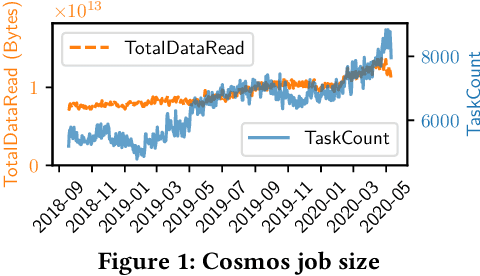
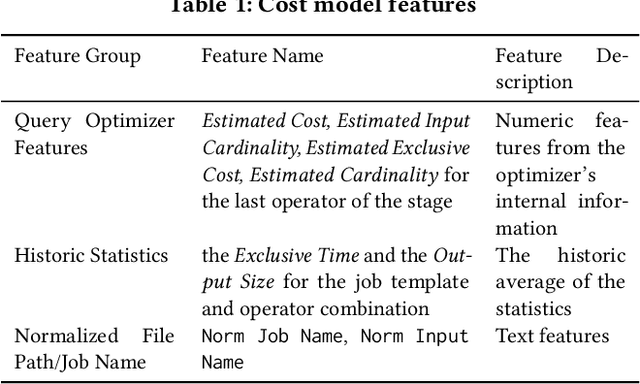

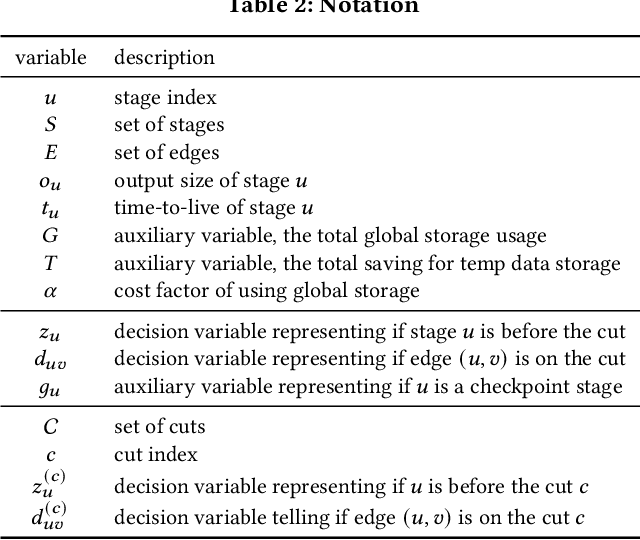
Easy-to-use programming interfaces paired with cloud-scale processing engines have enabled big data system users to author arbitrarily complex analytical jobs over massive volumes of data. However, as the complexity and scale of analytical jobs increase, they encounter a number of unforeseen problems, hotspots with large intermediate data on temporary storage, longer job recovery time after failures, and worse query optimizer estimates being examples of issues that we are facing at Microsoft. To address these issues, we propose Phoebe, an efficient learning-based checkpoint optimizer. Given a set of constraints and an objective function at compile-time, Phoebe is able to determine the decomposition of job plans, and the optimal set of checkpoints to preserve their outputs to durable global storage. Phoebe consists of three machine learning predictors and one optimization module. For each stage of a job, Phoebe makes accurate predictions for: (1) the execution time, (2) the output size, and (3) the start/end time taking into account the inter-stage dependencies. Using these predictions, we formulate checkpoint optimization as an integer programming problem and propose a scalable heuristic algorithm that meets the latency requirement of the production environment. We demonstrate the effectiveness of Phoebe in production workloads, and show that we can free the temporary storage on hotspots by more than 70% and restart failed jobs 68% faster on average with minimum performance impact. Phoebe also illustrates that adding multiple sets of checkpoints is not cost-efficient, which dramatically reduces the complexity of the optimization.
How to train RNNs on chaotic data?
Oct 14, 2021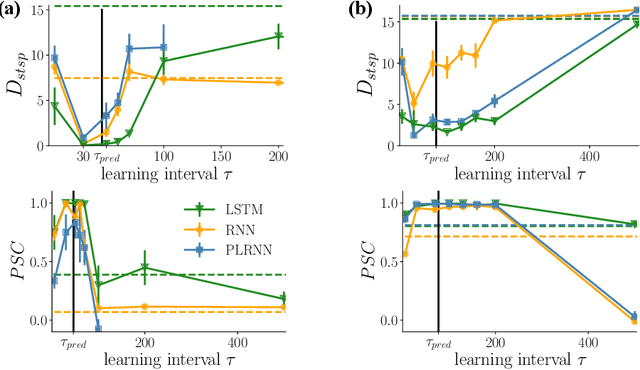
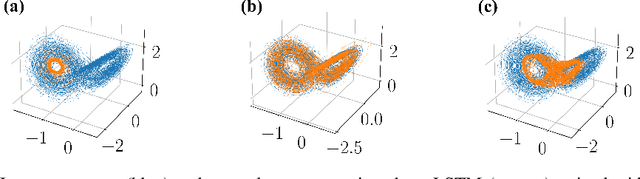
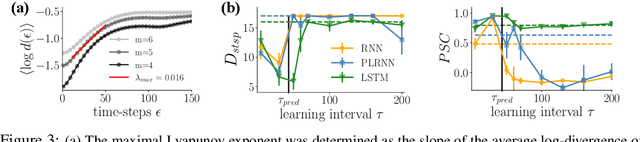
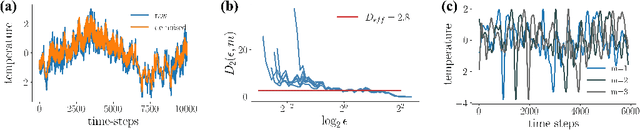
Recurrent neural networks (RNNs) are wide-spread machine learning tools for modeling sequential and time series data. They are notoriously hard to train because their loss gradients backpropagated in time tend to saturate or diverge during training. This is known as the exploding and vanishing gradient problem. Previous solutions to this issue either built on rather complicated, purpose-engineered architectures with gated memory buffers, or - more recently - imposed constraints that ensure convergence to a fixed point or restrict (the eigenspectrum of) the recurrence matrix. Such constraints, however, convey severe limitations on the expressivity of the RNN. Essential intrinsic dynamics such as multistability or chaos are disabled. This is inherently at disaccord with the chaotic nature of many, if not most, time series encountered in nature and society. Here we offer a comprehensive theoretical treatment of this problem by relating the loss gradients during RNN training to the Lyapunov spectrum of RNN-generated orbits. We mathematically prove that RNNs producing stable equilibrium or cyclic behavior have bounded gradients, whereas the gradients of RNNs with chaotic dynamics always diverge. Based on these analyses and insights, we offer an effective yet simple training technique for chaotic data and guidance on how to choose relevant hyperparameters according to the Lyapunov spectrum.
A Survey of NLP-Related Crowdsourcing HITs: what works and what does not
Nov 09, 2021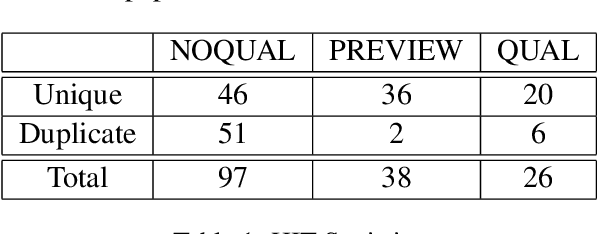
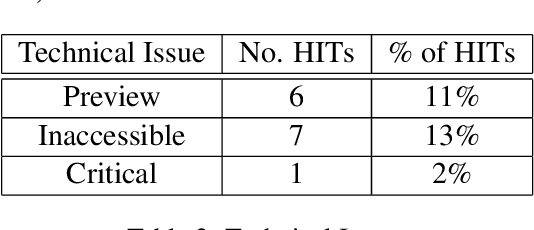

Crowdsourcing requesters on Amazon Mechanical Turk (AMT) have raised questions about the reliability of the workers. The AMT workforce is very diverse and it is not possible to make blanket assumptions about them as a group. Some requesters now reject work en mass when they do not get the results they expect. This has the effect of giving each worker (good or bad) a lower Human Intelligence Task (HIT) approval score, which is unfair to the good workers. It also has the effect of giving the requester a bad reputation on the workers' forums. Some of the issues causing the mass rejections stem from the requesters not taking the time to create a well-formed task with complete instructions and/or not paying a fair wage. To explore this assumption, this paper describes a study that looks at the crowdsourcing HITs on AMT that were available over a given span of time and records information about those HITs. This study also records information from a crowdsourcing forum on the worker perspective on both those HITs and on their corresponding requesters. Results reveal issues in worker payment and presentation issues such as missing instructions or HITs that are not doable.
Tight FPT Approximation for Constrained k-Center and k-Supplier
Oct 27, 2021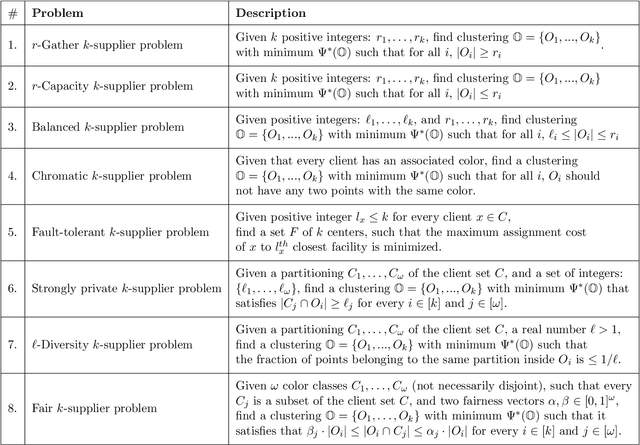
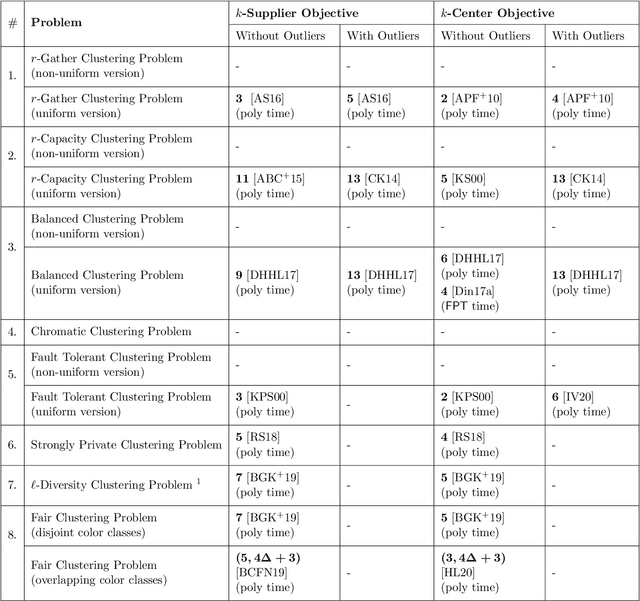
In this work, we study a range of constrained versions of the $k$-supplier and $k$-center problems such as: capacitated, fault-tolerant, fair, etc. These problems fall under a broad framework of constrained clustering. A unified framework for constrained clustering was proposed by Ding and Xu [SODA 2015] in context of the $k$-median and $k$-means objectives. In this work, we extend this framework to the $k$-supplier and $k$-center objectives. This unified framework allows us to obtain results simultaneously for the following constrained versions of the $k$-supplier problem: $r$-gather, $r$-capacity, balanced, chromatic, fault-tolerant, strongly private, $\ell$-diversity, and fair $k$-supplier problems, with and without outliers. We obtain the following results: We give $3$ and $2$ approximation algorithms for the constrained $k$-supplier and $k$-center problems, respectively, with $\mathsf{FPT}$ running time $k^{O(k)} \cdot n^{O(1)}$, where $n = |C \cup L|$. Moreover, these approximation guarantees are tight; that is, for any constant $\epsilon>0$, no algorithm can achieve $(3-\epsilon)$ and $(2-\epsilon)$ approximation guarantees for the constrained $k$-supplier and $k$-center problems in $\mathsf{FPT}$ time, assuming $\mathsf{FPT} \neq \mathsf{W}[2]$. Furthermore, we study these constrained problems in outlier setting. Our algorithm gives $3$ and $2$ approximation guarantees for the constrained outlier $k$-supplier and $k$-center problems, respectively, with $\mathsf{FPT}$ running time $(k+m)^{O(k)} \cdot n^{O(1)}$, where $n = |C \cup L|$ and $m$ is the number of outliers.
Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation
Feb 21, 2020
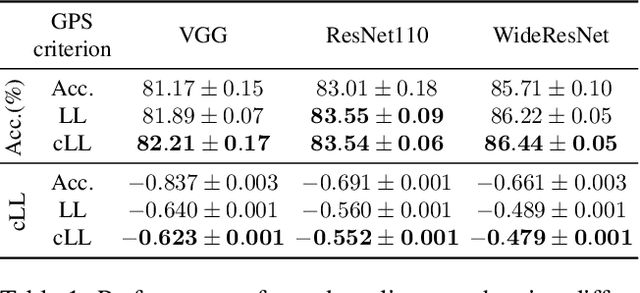
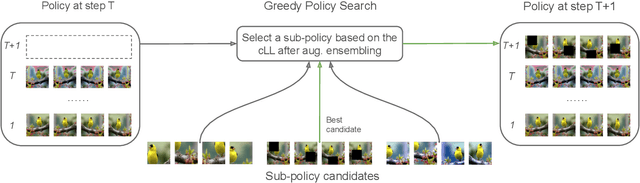

Test-time data augmentation---averaging the predictions of a machine learning model across multiple augmented samples of data---is a widely used technique that improves the predictive performance. While many advanced learnable data augmentation techniques have emerged in recent years, they are focused on the training phase. Such techniques are not necessarily optimal for test-time augmentation and can be outperformed by a policy consisting of simple crops and flips. The primary goal of this paper is to demonstrate that test-time augmentation policies can be successfully learned too. We~introduce \emph{greedy policy search} (GPS), a simple but high-performing method for learning a policy of test-time augmentation. We demonstrate that augmentation policies learned with GPS achieve superior predictive performance on image classification problems, provide better in-domain uncertainty estimation, and improve the robustness to domain shift.
FAT: An In-Memory Accelerator with Fast Addition for Ternary Weight Neural Networks
Jan 19, 2022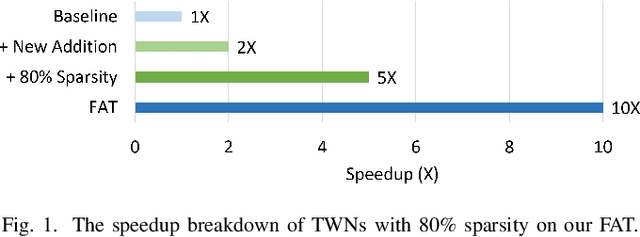
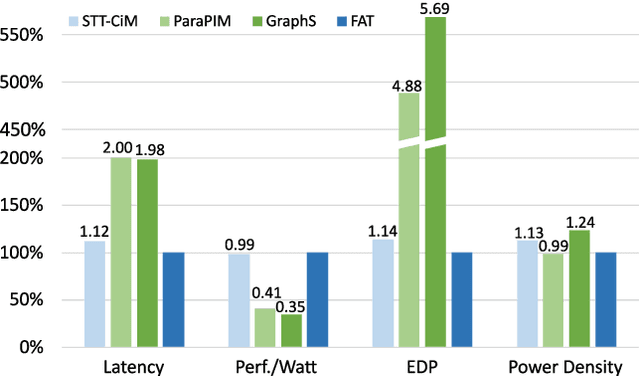

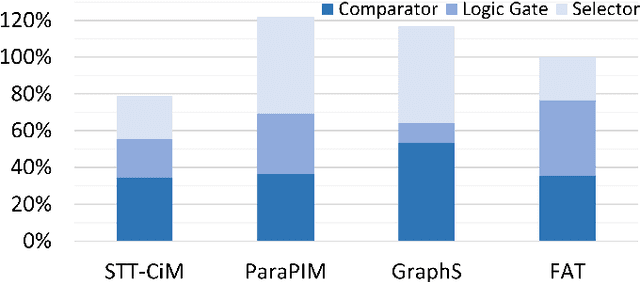
Convolutional Neural Networks (CNNs) demonstrate great performance in various applications but have high computational complexity. Quantization is applied to reduce the latency and storage cost of CNNs. Among the quantization methods, Binary and Ternary Weight Networks (BWNs and TWNs) have a unique advantage over 8-bit and 4-bit quantization. They replace the multiplication operations in CNNs with additions, which are favoured on In-Memory-Computing (IMC) devices. IMC acceleration for BWNs has been widely studied. However, though TWNs have higher accuracy and better sparsity, IMC acceleration for TWNs has limited research. TWNs on existing IMC devices are inefficient because the sparsity is not well utilized, and the addition operation is not efficient. In this paper, we propose FAT as a novel IMC accelerator for TWNs. First, we propose a Sparse Addition Control Unit, which utilizes the sparsity of TWNs to skip the null operations on zero weights. Second, we propose a fast addition scheme based on the memory Sense Amplifier to avoid the time overhead of both carry propagation and writing back the carry to the memory cells. Third, we further propose a Combined-Stationary data mapping to reduce the data movement of both activations and weights and increase the parallelism of memory columns. Simulation results show that for addition operations at the Sense Amplifier level, FAT achieves 2.00X speedup, 1.22X power efficiency and 1.22X area efficiency compared with State-Of-The-Art IMC accelerator ParaPIM. FAT achieves 10.02X speedup and 12.19X energy efficiency compared with ParaPIM on networks with 80% sparsity
Digital Twinning Remote Laboratories for Online Practical Learning
Dec 13, 2021
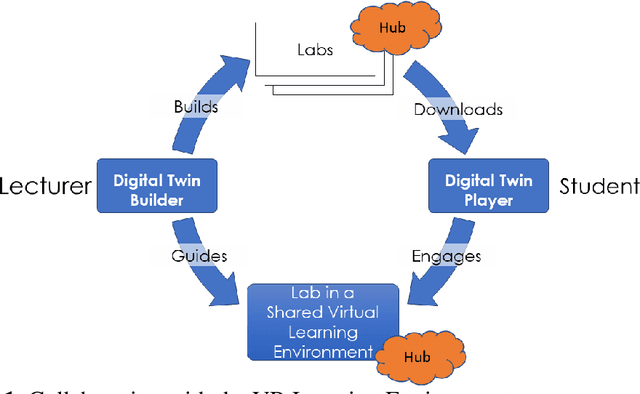
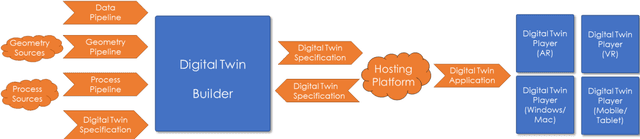
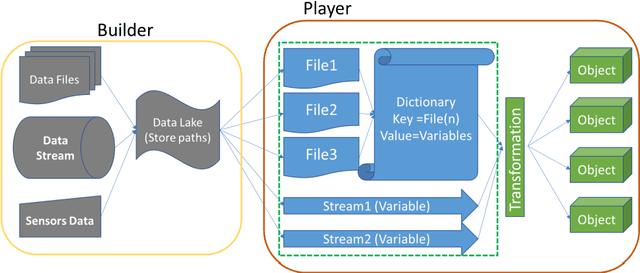
The COVID19 pandemic has demonstrated a need for remote learning and virtual learning applications such as virtual reality (VR) and tablet-based solutions. Creating complex learning scenarios by developers is highly time-consuming and can take over a year. It is also costly to employ teams of system analysts, developers and 3D artists. There is a requirement to provide a simple method to enable lecturers to create their own content for their laboratory tutorials. Research has been undertaken into developing generic models to enable the semi-automatic creation of a virtual learning tools for subjects that require practical interactions with the lab resources. In addition to the system for creating digital twins, a case study describing the creation of a virtual learning application for an electrical laboratory tutorial has been presented.
Hyperdimensional Feature Fusion for Out-Of-Distribution Detection
Dec 10, 2021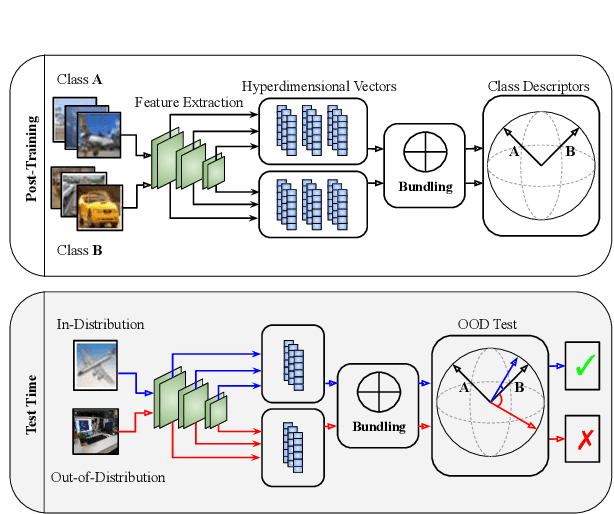
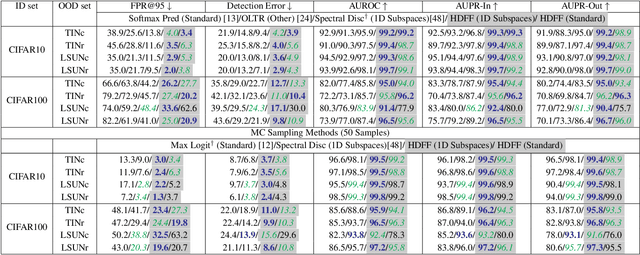
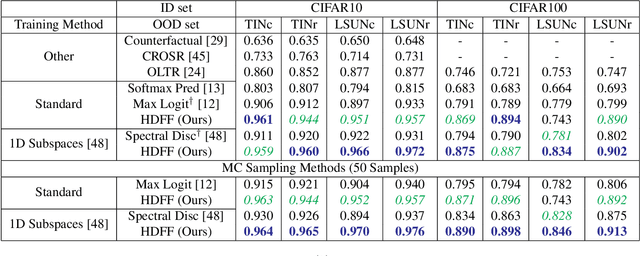
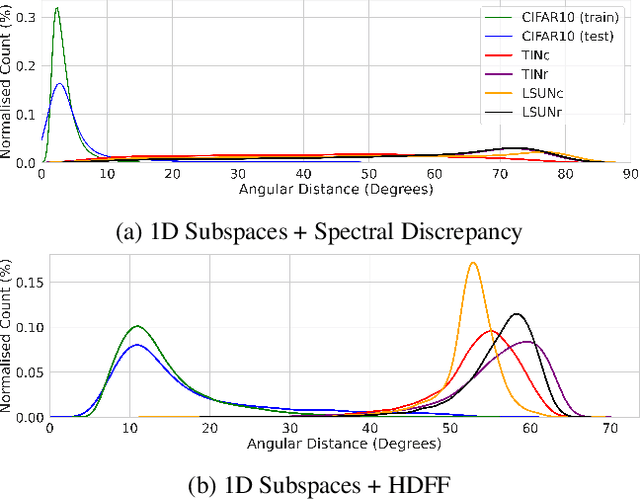
We introduce powerful ideas from Hyperdimensional Computing into the challenging field of Out-of-Distribution (OOD) detection. In contrast to most existing work that performs OOD detection based on only a single layer of a neural network, we use similarity-preserving semi-orthogonal projection matrices to project the feature maps from multiple layers into a common vector space. By repeatedly applying the bundling operation $\oplus$, we create expressive class-specific descriptor vectors for all in-distribution classes. At test time, a simple and efficient cosine similarity calculation between descriptor vectors consistently identifies OOD samples with better performance than the current state-of-the-art. We show that the hyperdimensional fusion of multiple network layers is critical to achieve best general performance.
Automatic Recognition of Abdominal Organs in Ultrasound Images based on Deep Neural Networks and K-Nearest-Neighbor Classification
Oct 09, 2021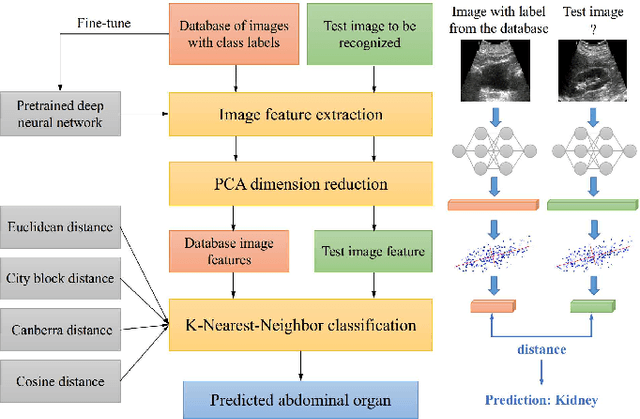
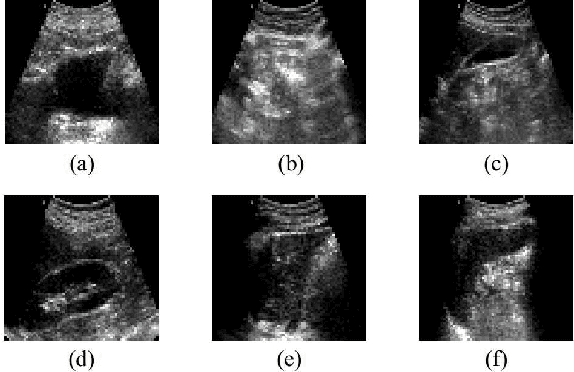
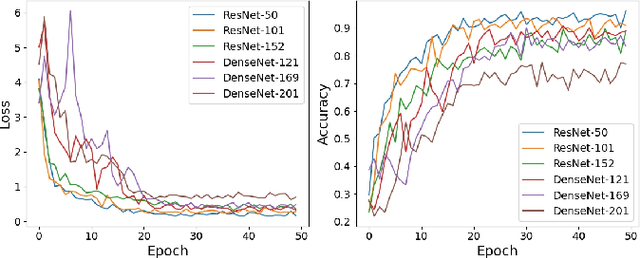
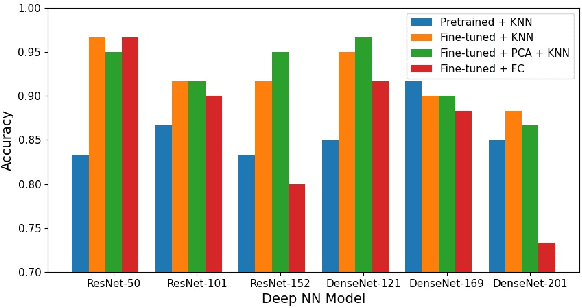
Abdominal ultrasound imaging has been widely used to assist in the diagnosis and treatment of various abdominal organs. In order to shorten the examination time and reduce the cognitive burden on the sonographers, we present a classification method that combines the deep learning techniques and k-Nearest-Neighbor (k-NN) classification to automatically recognize various abdominal organs in the ultrasound images in real time. Fine-tuned deep neural networks are used in combination with PCA dimension reduction to extract high-level features from raw ultrasound images, and a k-NN classifier is employed to predict the abdominal organ in the image. We demonstrate the effectiveness of our method in the task of ultrasound image classification to automatically recognize six abdominal organs. A comprehensive comparison of different configurations is conducted to study the influence of different feature extractors and classifiers on the classification accuracy. Both quantitative and qualitative results show that with minimal training effort, our method can "lazily" recognize the abdominal organs in the ultrasound images in real time with an accuracy of 96.67%. Our implementation code is publicly available at: https://github.com/LeeKeyu/abdominal_ultrasound_classification.
Architecting and Visualizing Deep Reinforcement Learning Models
Dec 02, 2021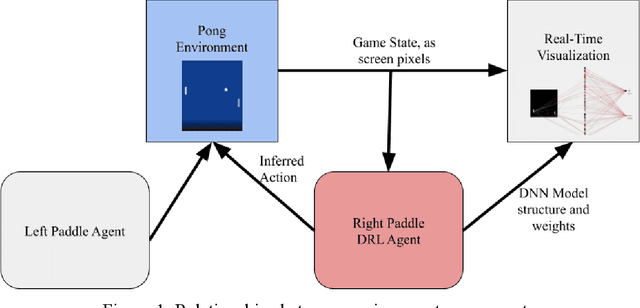



To meet the growing interest in Deep Reinforcement Learning (DRL), we sought to construct a DRL-driven Atari Pong agent and accompanying visualization tool. Existing approaches do not support the flexibility required to create an interactive exhibit with easily-configurable physics and a human-controlled player. Therefore, we constructed a new Pong game environment, discovered and addressed a number of unique data deficiencies that arise when applying DRL to a new environment, architected and tuned a policy gradient based DRL model, developed a real-time network visualization, and combined these elements into an interactive display to help build intuition and awareness of the mechanics of DRL inference.