 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accurate Characterization of Non-Uniformly Sampled Time Series using Stochastic Differential Equations
Jul 02, 2020
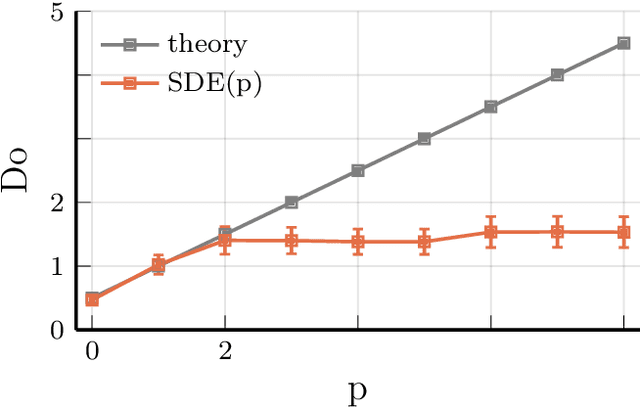
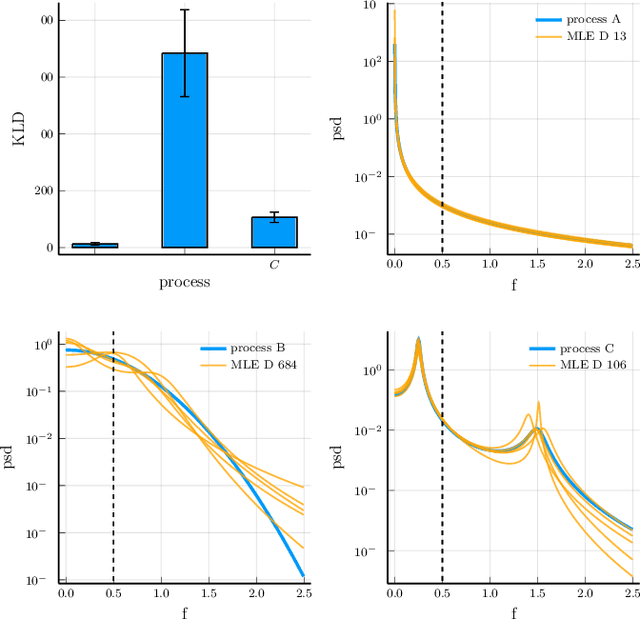
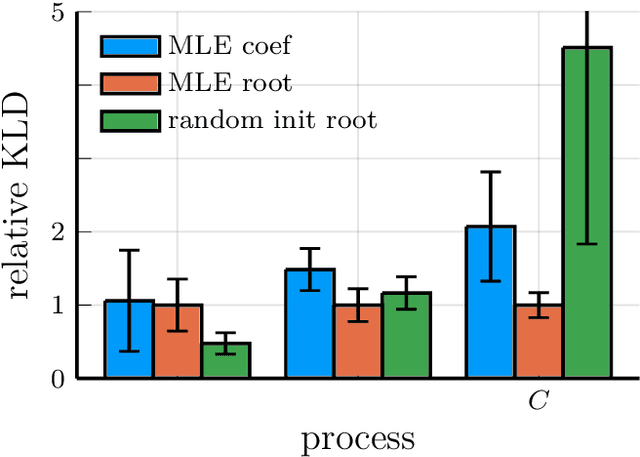
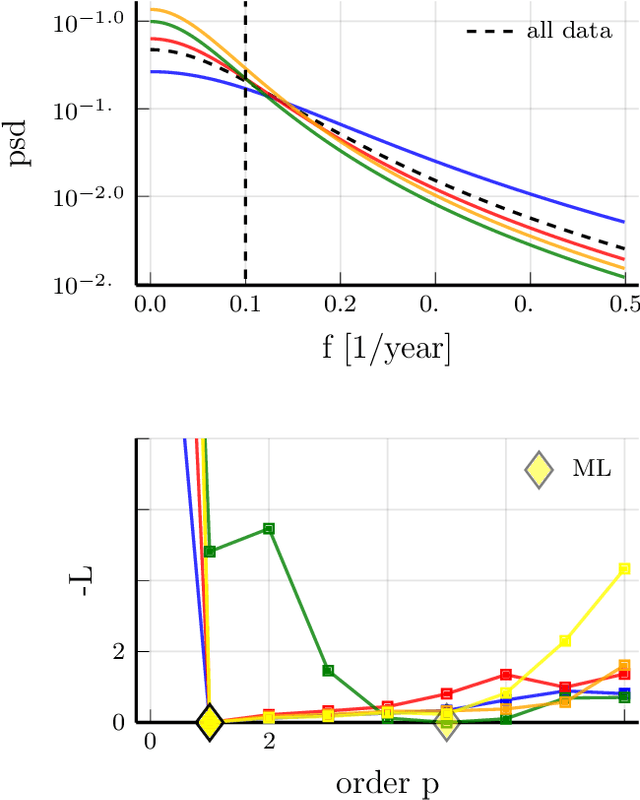
Non-uniform sampling arises when an experimenter does not have full control over the sampling characteristics of the process under investigation. Moreover, it is introduced intentionally in algorithms such as Bayesian optimization and compressive sensing. We argue that Stochastic Differential Equations (SDEs) are especially well-suited for characterizing second order moments of such time series. We introduce new initial estimates for the numerical optimization of the likelihood, based on incremental estimation and initialization from autoregressive models. Furthermore, we introduce model truncation as a purely data-driven method to reduce the order of the estimated model based on the SDE likelihood. We show the increased accuracy achieved with the new estimator in simulation experiments, covering all challenging circumstances that may be encountered in characterizing a non-uniformly sampled time series. Finally, we apply the new estimator to experimental rainfall variability data.
Computational Lens on Cognition: Study Of Autobiographical Versus Imagined Stories With Large-Scale Language Models
Jan 07, 2022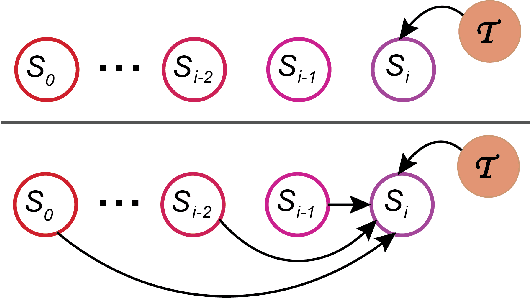
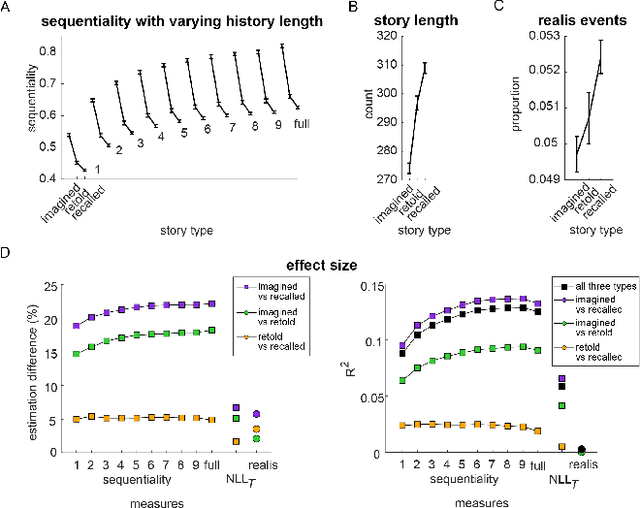
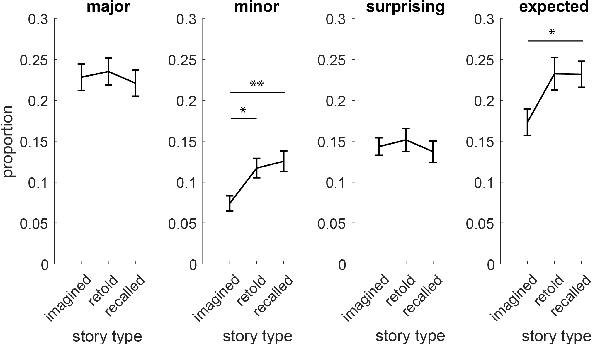
Lifelong experiences and learned knowledge lead to shared expectations about how common situations tend to unfold. Such knowledge enables people to interpret story narratives and identify salient events effortlessly. We study differences in the narrative flow of events in autobiographical versus imagined stories using GPT-3, one of the largest neural language models created to date. The diary-like stories were written by crowdworkers about either a recently experienced event or an imagined event on the same topic. To analyze the narrative flow of events of these stories, we measured sentence *sequentiality*, which compares the probability of a sentence with and without its preceding story context. We found that imagined stories have higher sequentiality than autobiographical stories, and that the sequentiality of autobiographical stories is higher when they are retold than when freshly recalled. Through an annotation of events in story sentences, we found that the story types contain similar proportions of major salient events, but that the autobiographical stories are denser in factual minor events. Furthermore, in comparison to imagined stories, autobiographical stories contain more concrete words and words related to the first person, cognitive processes, time, space, numbers, social words, and core drives and needs. Our findings highlight the opportunity to investigate memory and cognition with large-scale statistical language models.
EuroCrops: A Pan-European Dataset for Time Series Crop Type Classification
Jun 14, 2021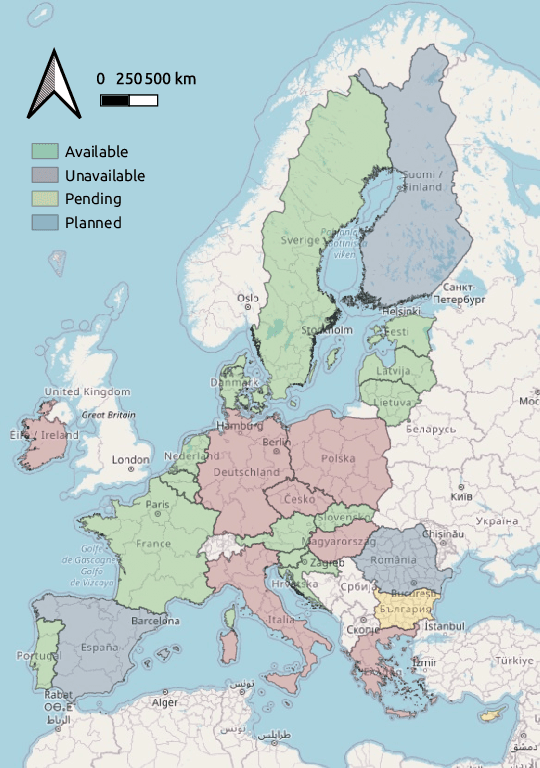
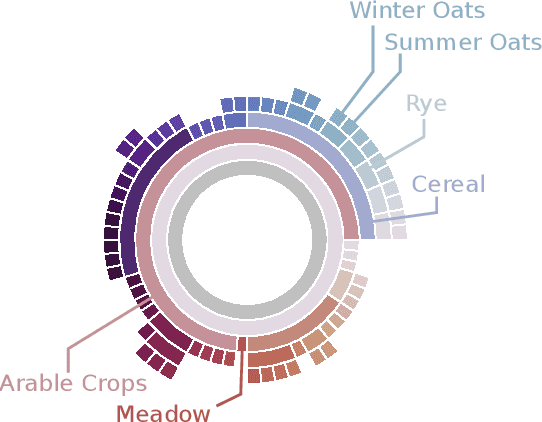

We present EuroCrops, a dataset based on self-declared field annotations for training and evaluating methods for crop type classification and mapping, together with its process of acquisition and harmonisation. By this, we aim to enrich the research efforts and discussion for data-driven land cover classification via Earth observation and remote sensing. Additionally, through inclusion of self-declarations gathered in the scope of subsidy control from all countries of the European Union (EU), this dataset highlights the difficulties and pitfalls one comes across when operating on a transnational level. We, therefore, also introduce a new taxonomy scheme, HCAT-ID, that aspires to capture all the aspects of reference data originating from administrative and agency databases. To address researchers from both the remote sensing and the computer vision and machine learning communities, we publish the dataset in different formats and processing levels.
* 4 pages, website: https://www.eurocrops.tum.de/
End-to-End Real-time Catheter Segmentation with Optical Flow-Guided Warping during Endovascular Intervention
Jun 16, 2020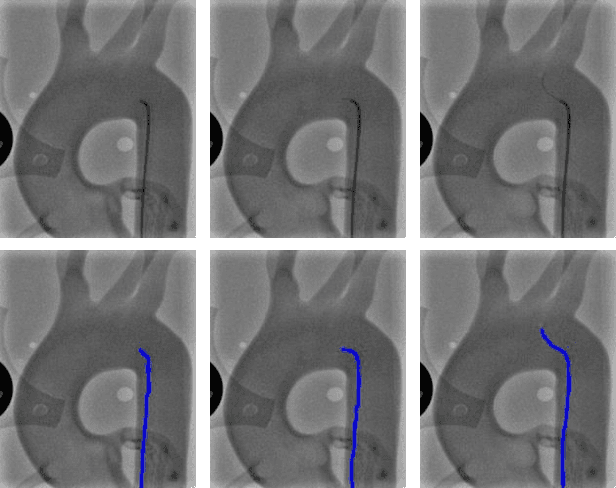

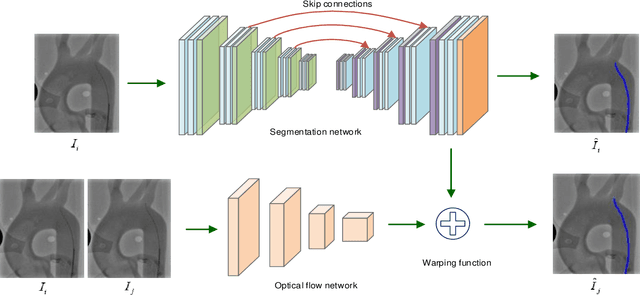
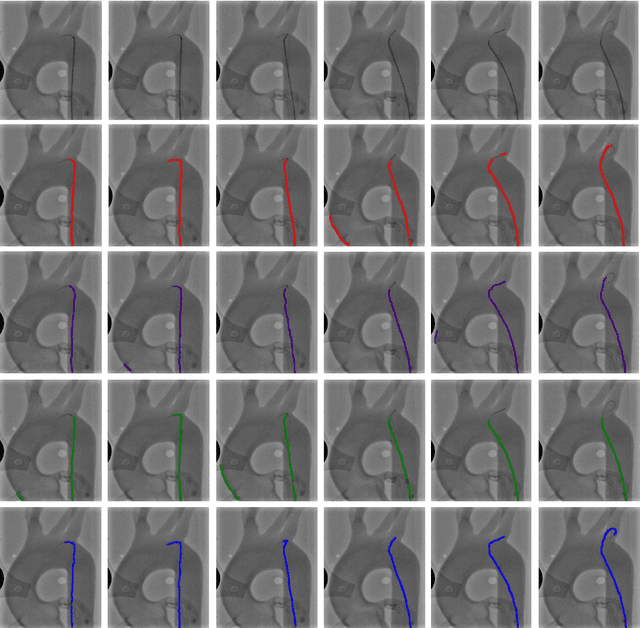
Accurate real-time catheter segmentation is an important pre-requisite for robot-assisted endovascular intervention. Most of the existing learning-based methods for catheter segmentation and tracking are only trained on small-scale datasets or synthetic data due to the difficulties of ground-truth annotation. Furthermore, the temporal continuity in intraoperative imaging sequences is not fully utilised. In this paper, we present FW-Net, an end-to-end and real-time deep learning framework for endovascular intervention. The proposed FW-Net has three modules: a segmentation network with encoder-decoder architecture, a flow network to extract optical flow information, and a novel flow-guided warping function to learn the frame-to-frame temporal continuity. We show that by effectively learning temporal continuity, the network can successfully segment and track the catheters in real-time sequences using only raw ground-truth for training. Detailed validation results confirm that our FW-Net outperforms state-of-the-art techniques while achieving real-time performance.
MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound
Jan 07, 2022
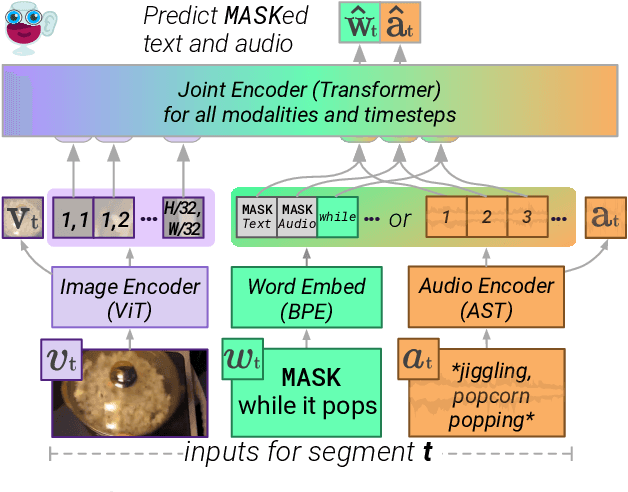

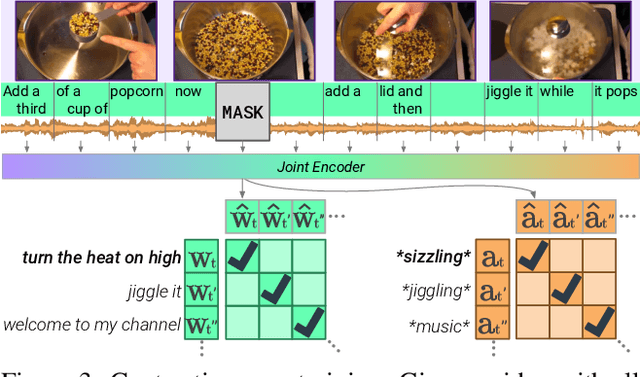
As humans, we navigate the world through all our senses, using perceptual input from each one to correct the others. We introduce MERLOT Reserve, a model that represents videos jointly over time -- through a new training objective that learns from audio, subtitles, and video frames. Given a video, we replace snippets of text and audio with a MASK token; the model learns by choosing the correct masked-out snippet. Our objective learns faster than alternatives, and performs well at scale: we pretrain on 20 million YouTube videos. Empirical results show that MERLOT Reserve learns strong representations about videos through all constituent modalities. When finetuned, it sets a new state-of-the-art on both VCR and TVQA, outperforming prior work by 5% and 7% respectively. Ablations show that both tasks benefit from audio pretraining -- even VCR, a QA task centered around images (without sound). Moreover, our objective enables out-of-the-box prediction, revealing strong multimodal commonsense understanding. In a fully zero-shot setting, our model obtains competitive results on four video understanding tasks, even outperforming supervised approaches on the recently proposed Situated Reasoning (STAR) benchmark. We analyze why incorporating audio leads to better vision-language representations, suggesting significant opportunities for future research. We conclude by discussing ethical and societal implications of multimodal pretraining.
Enhancement of Healthcare Data Performance Metrics using Neural Network Machine Learning Algorithms
Jan 16, 2022Patients are often encouraged to make use of wearable devices for remote collection and monitoring of health data. This adoption of wearables results in a significant increase in the volume of data collected and transmitted. The battery life of the devices is then quickly diminished due to the high processing requirements of the devices. Given the importance attached to medical data, it is imperative that all transmitted data adhere to strict integrity and availability requirements. Reducing the volume of healthcare data for network transmission may improve sensor battery life without compromising accuracy. There is a trade-off between efficiency and accuracy which can be controlled by adjusting the sampling and transmission rates. This paper demonstrates that machine learning can be used to analyse complex health data metrics such as the accuracy and efficiency of data transmission to overcome the trade-off problem. The study uses time series nonlinear autoregressive neural network algorithms to enhance both data metrics by taking fewer samples to transmit. The algorithms were tested with a standard heart rate dataset to compare their accuracy and efficiency. The result showed that the Levenbery-Marquardt algorithm was the best performer with an efficiency of 3.33 and accuracy of 79.17%, which is similar to other algorithms accuracy but demonstrates improved efficiency. This proves that machine learning can improve without sacrificing a metric over the other compared to the existing methods with high efficiency.
Detecting Twenty-thousand Classes using Image-level Supervision
Jan 07, 2022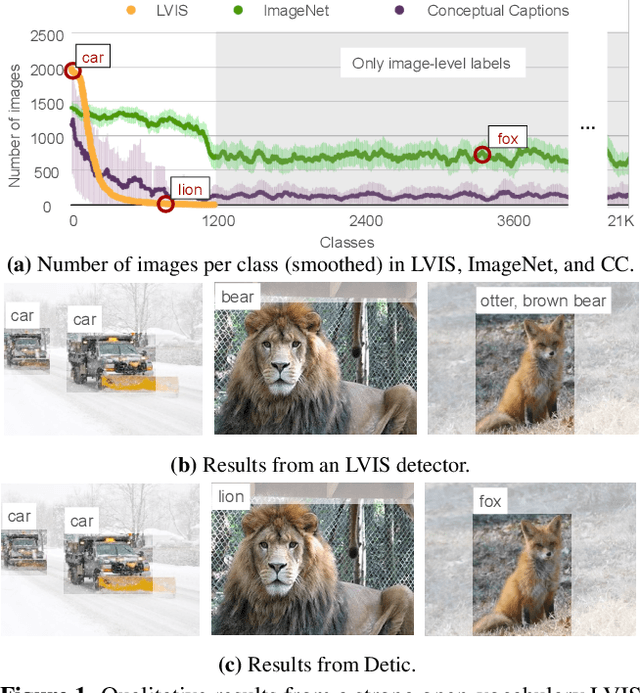
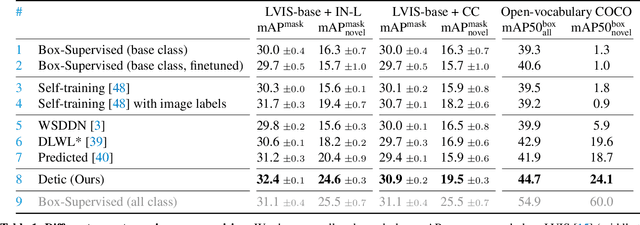


Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets are larger and easier to collect. We propose Detic, which simply trains the classifiers of a detector on image classification data and thus expands the vocabulary of detectors to tens of thousands of concepts. Unlike prior work, Detic does not assign image labels to boxes based on model predictions, making it much easier to implement and compatible with a range of detection architectures and backbones. Our results show that Detic yields excellent detectors even for classes without box annotations. It outperforms prior work on both open-vocabulary and long-tail detection benchmarks. Detic provides a gain of 2.4 mAP for all classes and 8.3 mAP for novel classes on the open-vocabulary LVIS benchmark. On the standard LVIS benchmark, Detic reaches 41.7 mAP for all classes and 41.7 mAP for rare classes. For the first time, we train a detector with all the twenty-one-thousand classes of the ImageNet dataset and show that it generalizes to new datasets without fine-tuning. Code is available at https://github.com/facebookresearch/Detic.
FRIDA -- Generative Feature Replay for Incremental Domain Adaptation
Dec 28, 2021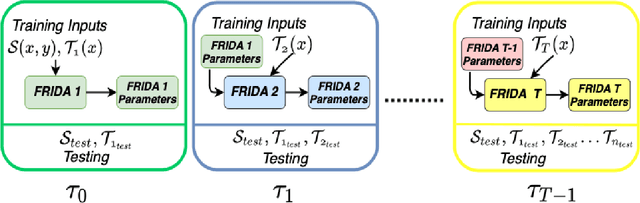

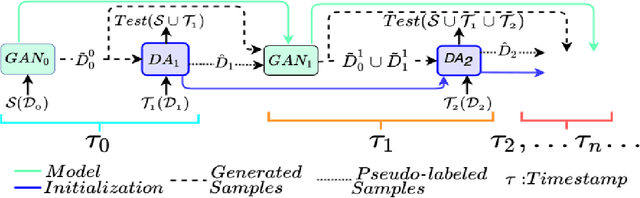
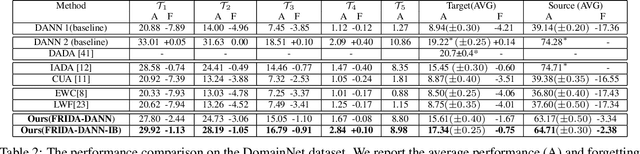
We tackle the novel problem of incremental unsupervised domain adaptation (IDA) in this paper. We assume that a labeled source domain and different unlabeled target domains are incrementally observed with the constraint that data corresponding to the current domain is only available at a time. The goal is to preserve the accuracies for all the past domains while generalizing well for the current domain. The IDA setup suffers due to the abrupt differences among the domains and the unavailability of past data including the source domain. Inspired by the notion of generative feature replay, we propose a novel framework called Feature Replay based Incremental Domain Adaptation (FRIDA) which leverages a new incremental generative adversarial network (GAN) called domain-generic auxiliary classification GAN (DGAC-GAN) for producing domain-specific feature representations seamlessly. For domain alignment, we propose a simple extension of the popular domain adversarial neural network (DANN) called DANN-IB which encourages discriminative domain-invariant and task-relevant feature learning. Experimental results on Office-Home, Office-CalTech, and DomainNet datasets confirm that FRIDA maintains superior stability-plasticity trade-off than the literature.
A polynomial-time algorithm for learning nonparametric causal graphs
Jun 22, 2020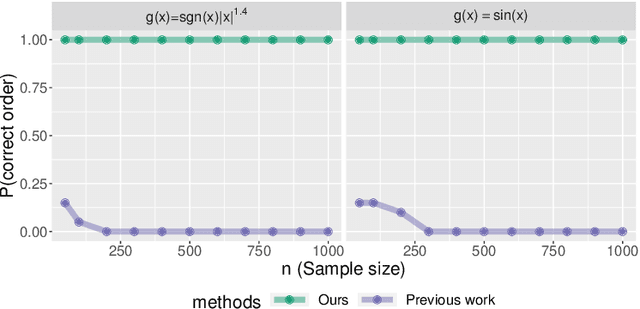
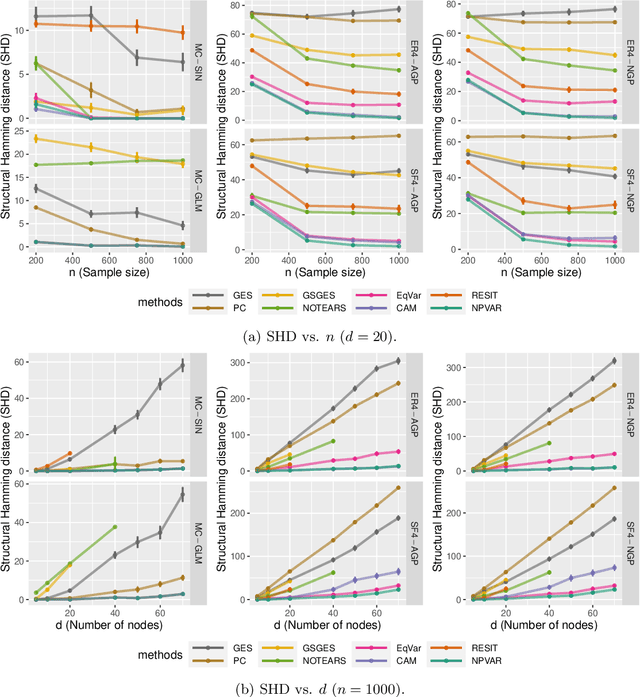
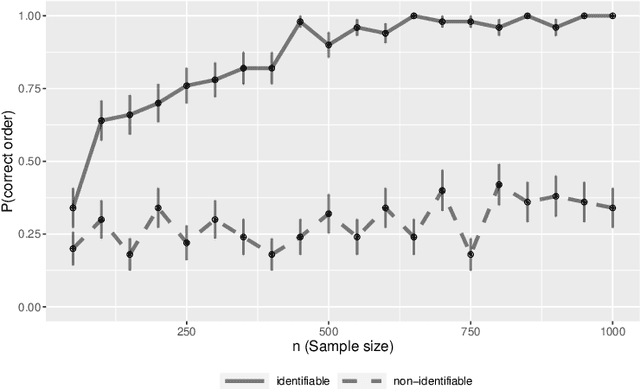
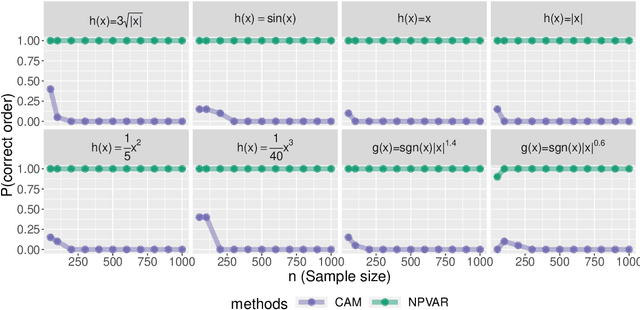
We establish finite-sample guarantees for a polynomial-time algorithm for learning a nonlinear, nonparametric directed acyclic graphical (DAG) model from data. The analysis is model-free and does not assume linearity, additivity, independent noise, or faithfulness. Instead, we impose a condition on the residual variances that is closely related to previous work on linear models with equal variances. Compared to an optimal algorithm with oracle knowledge of the variable ordering, the additional cost of the algorithm is linear in the dimension $d$ and the number of samples $n$. Finally, we compare the proposed algorithm to existing approaches in a simulation study.
Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation
Feb 21, 2020
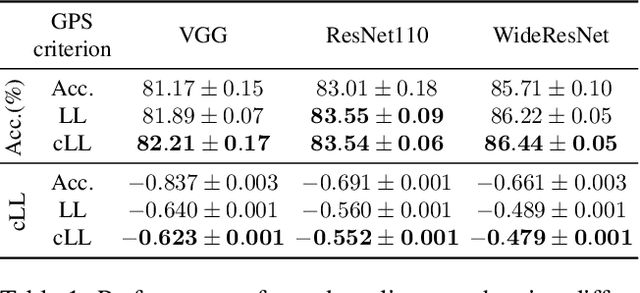
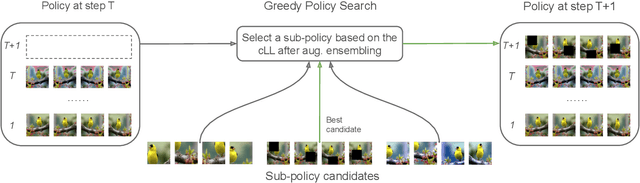

Test-time data augmentation---averaging the predictions of a machine learning model across multiple augmented samples of data---is a widely used technique that improves the predictive performance. While many advanced learnable data augmentation techniques have emerged in recent years, they are focused on the training phase. Such techniques are not necessarily optimal for test-time augmentation and can be outperformed by a policy consisting of simple crops and flips. The primary goal of this paper is to demonstrate that test-time augmentation policies can be successfully learned too. We~introduce \emph{greedy policy search} (GPS), a simple but high-performing method for learning a policy of test-time augmentation. We demonstrate that augmentation policies learned with GPS achieve superior predictive performance on image classification problems, provide better in-domain uncertainty estimation, and improve the robustness to domain shift.