 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distribution Shift in Airline Customer Behavior during COVID-19
Dec 23, 2021
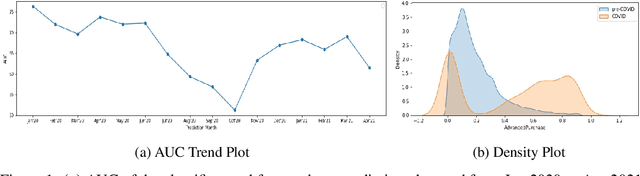

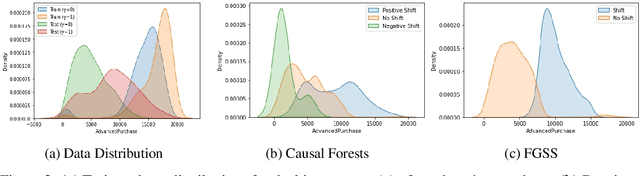
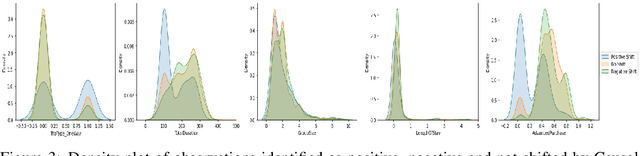
Traditional AI approaches in customized (personalized) contextual pricing applications assume that the data distribution at the time of online pricing is similar to that observed during training. However, this assumption may be violated in practice because of the dynamic nature of customer buying patterns, particularly due to unanticipated system shocks such as COVID-19. We study the changes in customer behavior for a major airline during the COVID-19 pandemic by framing it as a covariate shift and concept drift detection problem. We identify which customers changed their travel and purchase behavior and the attributes affecting that change using (i) Fast Generalized Subset Scanning and (ii) Causal Forests. In our experiments with simulated and real-world data, we present how these two techniques can be used through qualitative analysis.
Using Particle Swarm Optimization as Pathfinding Strategy in a Space with Obstacles
Dec 16, 2021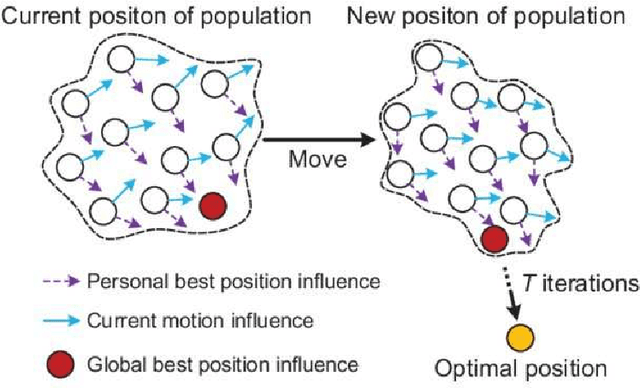
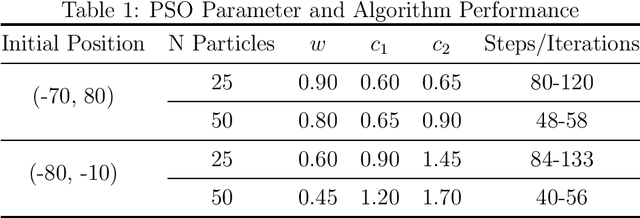
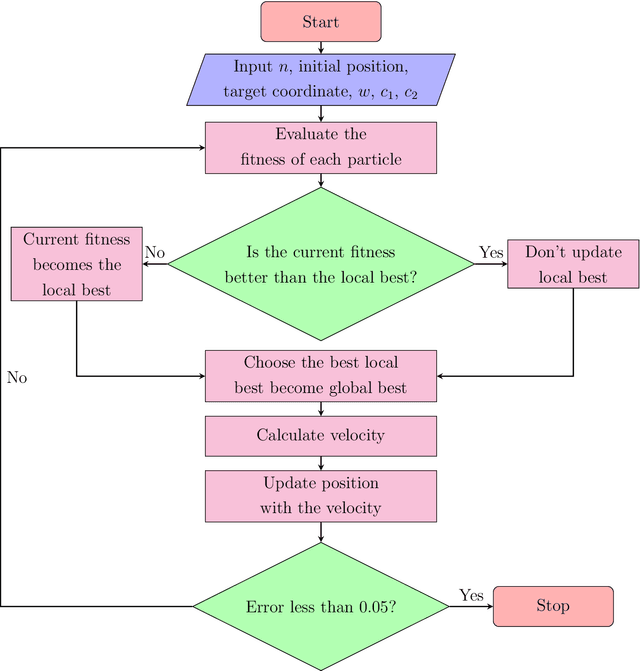
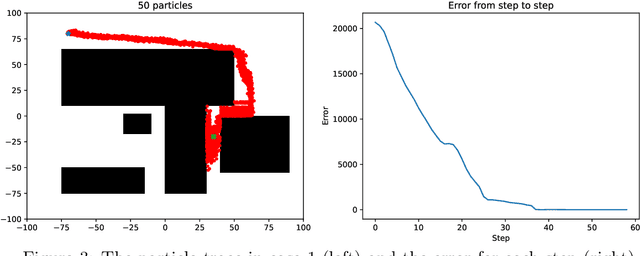
Particle swarm optimization (PSO) is a search algorithm based on stochastic and population-based adaptive optimization. In this paper, a pathfinding strategy is proposed to improve the efficiency of path planning for a broad range of applications. This study aims to investigate the effect of PSO parameters (numbers of particle, weight constant, particle constant, and global constant) on algorithm performance to give solution paths. Increasing the PSO parameters makes the swarm move faster to the target point but takes a long time to converge because of too many random movements, and vice versa. From a variety of simulations with different parameters, the PSO algorithm is proven to be able to provide a solution path in a space with obstacles.
Learning Graphon Mean Field Games and Approximate Nash Equilibria
Nov 29, 2021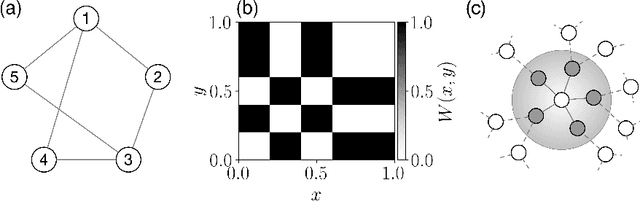
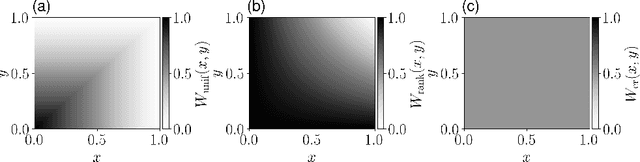
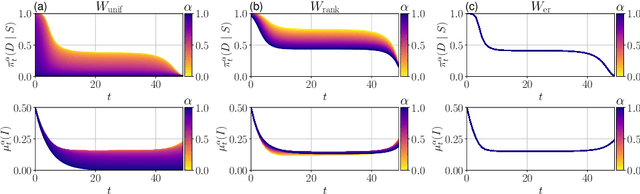
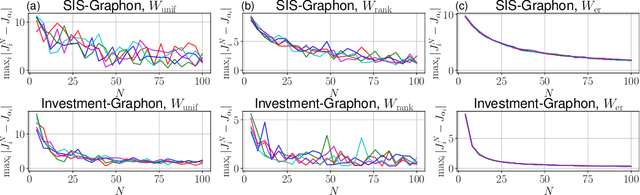
Recent advances at the intersection of dense large graph limits and mean field games have begun to enable the scalable analysis of a broad class of dynamical sequential games with large numbers of agents. So far, results have been largely limited to graphon mean field systems with continuous-time diffusive or jump dynamics, typically without control and with little focus on computational methods. We propose a novel discrete-time formulation for graphon mean field games as the limit of non-linear dense graph Markov games with weak interaction. On the theoretical side, we give extensive and rigorous existence and approximation properties of the graphon mean field solution in sufficiently large systems. On the practical side, we provide general learning schemes for graphon mean field equilibria by either introducing agent equivalence classes or reformulating the graphon mean field system as a classical mean field system. By repeatedly finding a regularized optimal control solution and its generated mean field, we successfully obtain plausible approximate Nash equilibria in otherwise infeasible large dense graph games with many agents. Empirically, we are able to demonstrate on a number of examples that the finite-agent behavior comes increasingly close to the mean field behavior for our computed equilibria as the graph or system size grows, verifying our theory. More generally, we successfully apply policy gradient reinforcement learning in conjunction with sequential Monte Carlo methods.
Intelligent Trading Systems: A Sentiment-Aware Reinforcement Learning Approach
Nov 14, 2021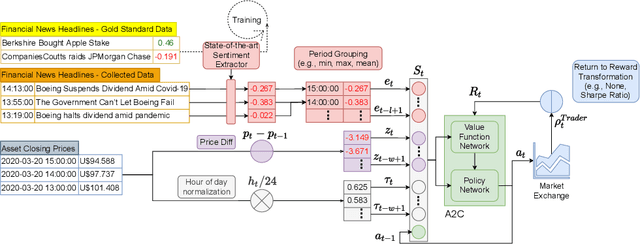
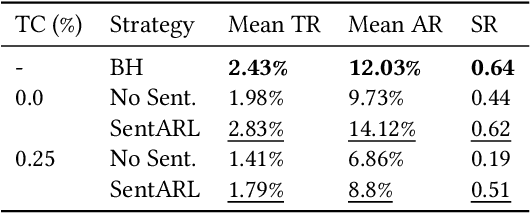
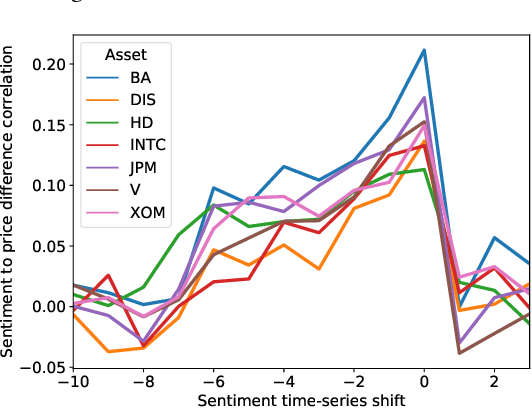
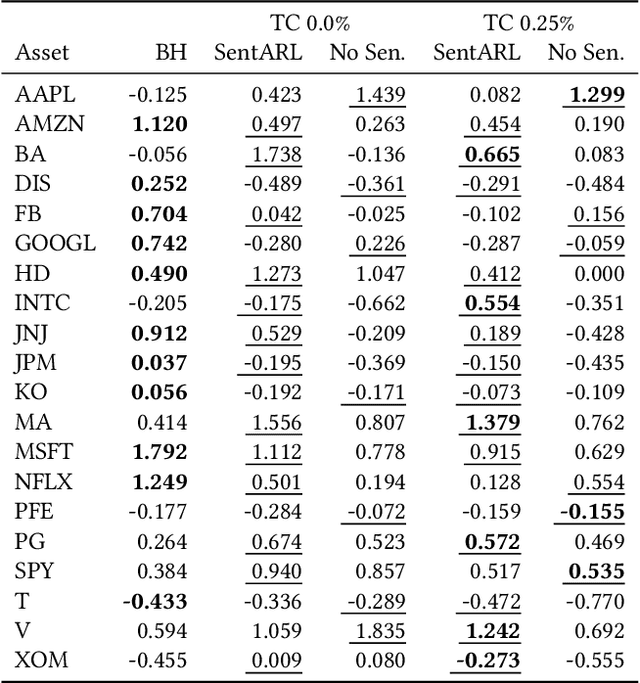
The feasibility of making profitable trades on a single asset on stock exchanges based on patterns identification has long attracted researchers. Reinforcement Learning (RL) and Natural Language Processing have gained notoriety in these single-asset trading tasks, but only a few works have explored their combination. Moreover, some issues are still not addressed, such as extracting market sentiment momentum through the explicit capture of sentiment features that reflect the market condition over time and assessing the consistency and stability of RL results in different situations. Filling this gap, we propose the Sentiment-Aware RL (SentARL) intelligent trading system that improves profit stability by leveraging market mood through an adaptive amount of past sentiment features drawn from textual news. We evaluated SentARL across twenty assets, two transaction costs, and five different periods and initializations to show its consistent effectiveness against baselines. Subsequently, this thorough assessment allowed us to identify the boundary between news coverage and market sentiment regarding the correlation of price-time series above which SentARL's effectiveness is outstanding.
Towards Return Parity in Markov Decision Processes
Nov 19, 2021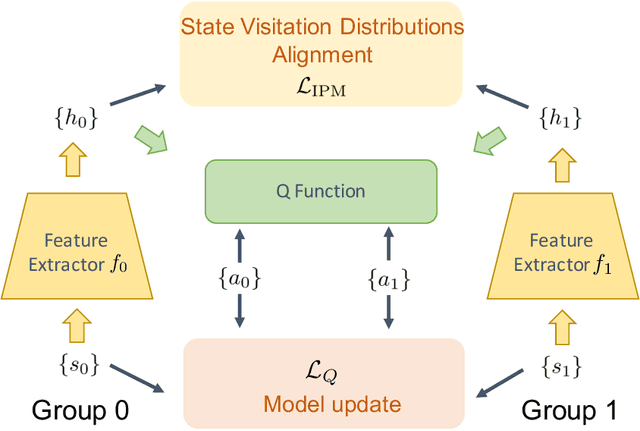

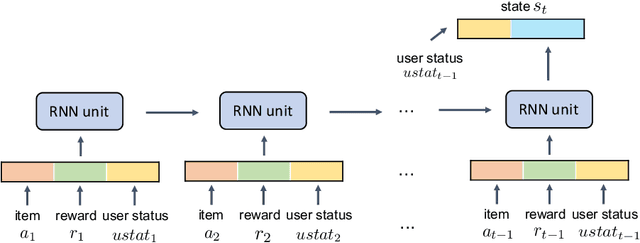
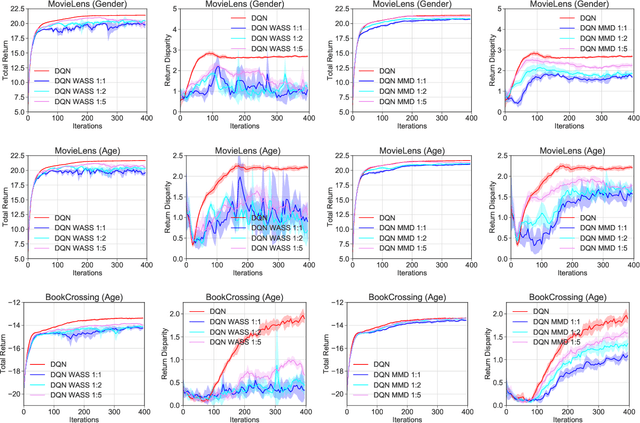
Algorithmic decisions made by machine learning models in high-stakes domains may have lasting impacts over time. Unfortunately, naive applications of standard fairness criterion in static settings over temporal domains may lead to delayed and adverse effects. To understand the dynamics of performance disparity, we study a fairness problem in Markov decision processes (MDPs). Specifically, we propose return parity, a fairness notion that requires MDPs from different demographic groups that share the same state and action spaces to achieve approximately the same expected time-discounted rewards. We first provide a decomposition theorem for return disparity, which decomposes the return disparity of any two MDPs into the distance between group-wise reward functions, the discrepancy of group policies, and the discrepancy between state visitation distributions induced by the group policies. Motivated by our decomposition theorem, we propose algorithms to mitigate return disparity via learning a shared group policy with state visitation distributional alignment using integral probability metrics. We conduct experiments to corroborate our results, showing that the proposed algorithm can successfully close the disparity gap while maintaining the performance of policies on two real-world recommender system benchmark datasets.
Algorithm and Hardware Co-design for Reconfigurable CNN Accelerator
Nov 24, 2021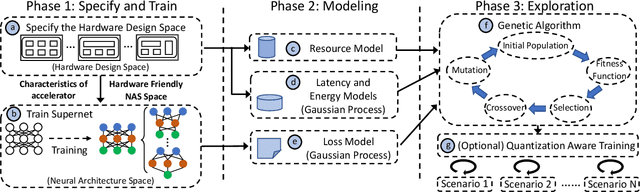
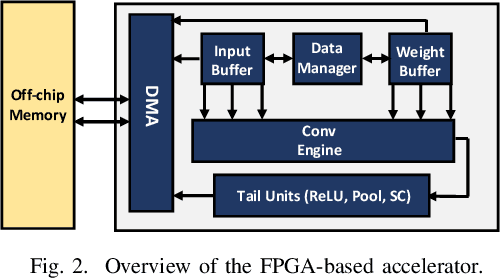
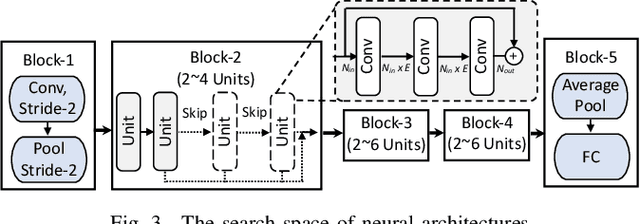
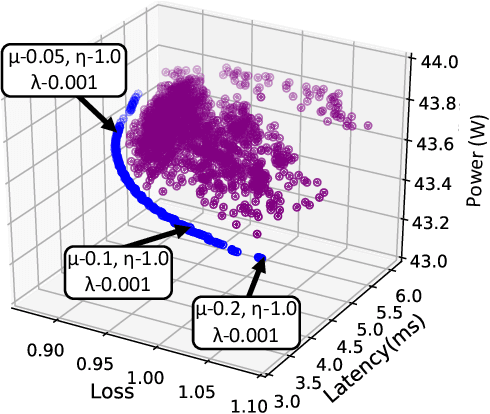
Recent advances in algorithm-hardware co-design for deep neural networks (DNNs) have demonstrated their potential in automatically designing neural architectures and hardware designs. Nevertheless, it is still a challenging optimization problem due to the expensive training cost and the time-consuming hardware implementation, which makes the exploration on the vast design space of neural architecture and hardware design intractable. In this paper, we demonstrate that our proposed approach is capable of locating designs on the Pareto frontier. This capability is enabled by a novel three-phase co-design framework, with the following new features: (a) decoupling DNN training from the design space exploration of hardware architecture and neural architecture, (b) providing a hardware-friendly neural architecture space by considering hardware characteristics in constructing the search cells, (c) adopting Gaussian process to predict accuracy, latency and power consumption to avoid time-consuming synthesis and place-and-route processes. In comparison with the manually-designed ResNet101, InceptionV2 and MobileNetV2, we can achieve up to 5% higher accuracy with up to 3x speed up on the ImageNet dataset. Compared with other state-of-the-art co-design frameworks, our found network and hardware configuration can achieve 2% ~ 6% higher accuracy, 2x ~ 26x smaller latency and 8.5x higher energy efficiency.
Traffic event description based on Twitter data using Unsupervised Learning Methods for Indian road conditions
Dec 23, 2021Non-recurrent and unpredictable traffic events directly influence road traffic conditions. There is a need for dynamic monitoring and prediction of these unpredictable events to improve road network management. The problem with the existing traditional methods (flow or speed studies) is that the coverage of many Indian roads is very sparse and reproducible methods to identify and describe the events are not available. Addition of some other form of data is essential to help with this problem. This could be real-time speed monitoring data like Google Maps, Waze, etc. or social data like Twitter, Facebook, etc. In this paper, an unsupervised learning model is used to perform effective tweet classification for enhancing Indian traffic data. The model uses word-embeddings to calculate semantic similarity and achieves a test score of 94.7%.
Spatio-Temporal Variational Gaussian Processes
Nov 02, 2021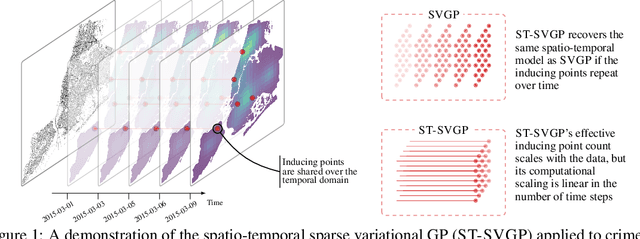

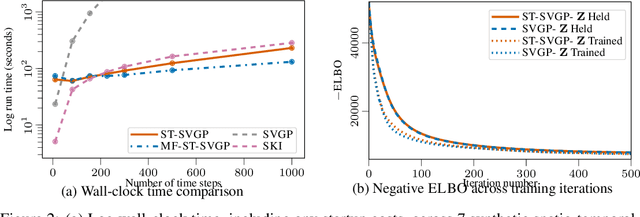
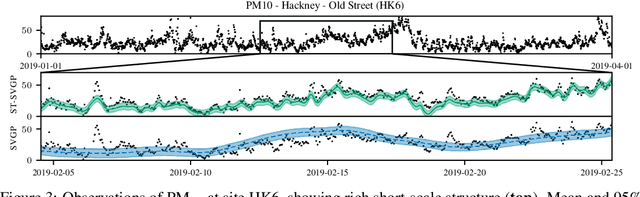
We introduce a scalable approach to Gaussian process inference that combines spatio-temporal filtering with natural gradient variational inference, resulting in a non-conjugate GP method for multivariate data that scales linearly with respect to time. Our natural gradient approach enables application of parallel filtering and smoothing, further reducing the temporal span complexity to be logarithmic in the number of time steps. We derive a sparse approximation that constructs a state-space model over a reduced set of spatial inducing points, and show that for separable Markov kernels the full and sparse cases exactly recover the standard variational GP, whilst exhibiting favourable computational properties. To further improve the spatial scaling we propose a mean-field assumption of independence between spatial locations which, when coupled with sparsity and parallelisation, leads to an efficient and accurate method for large spatio-temporal problems.
ABBA: Adaptive Brownian bridge-based symbolic aggregation of time series
Mar 27, 2020

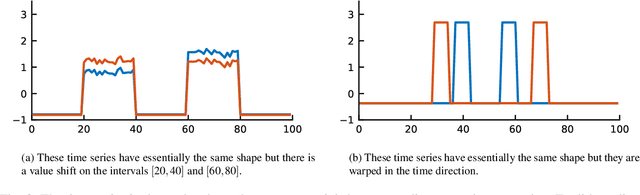

A new symbolic representation of time series, called ABBA, is introduced. It is based on an adaptive polygonal chain approximation of the time series into a sequence of tuples, followed by a mean-based clustering to obtain the symbolic representation. We show that the reconstruction error of this representation can be modelled as a random walk with pinned start and end points, a so-called Brownian bridge. This insight allows us to make ABBA essentially parameter-free, except for the approximation tolerance which must be chosen. Extensive comparisons with the SAX and 1d-SAX representations are included in the form of performance profiles, showing that ABBA is able to better preserve the essential shape information of time series compared to other approaches. Advantages and applications of ABBA are discussed, including its in-built differencing property and use for anomaly detection, and Python implementations provided.
Kinit Classification in Ethiopian Chants, Azmaris and Modern Music: A New Dataset and CNN Benchmark
Jan 20, 2022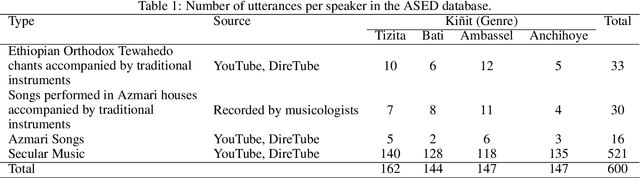
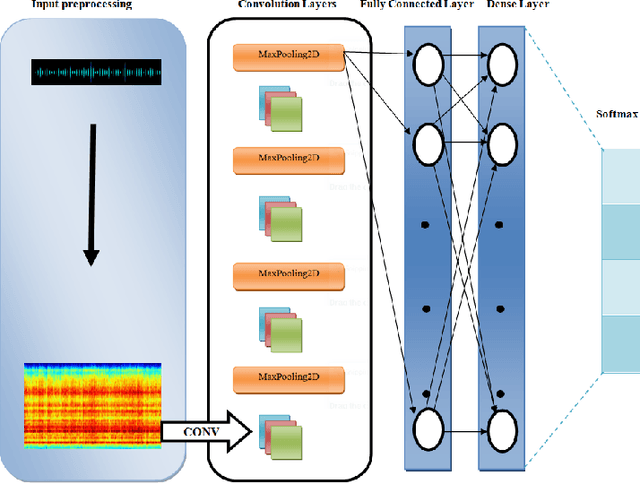
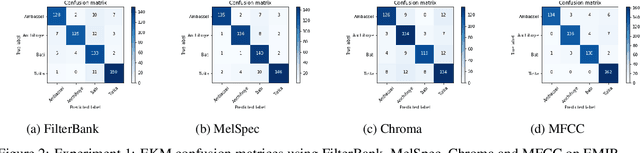
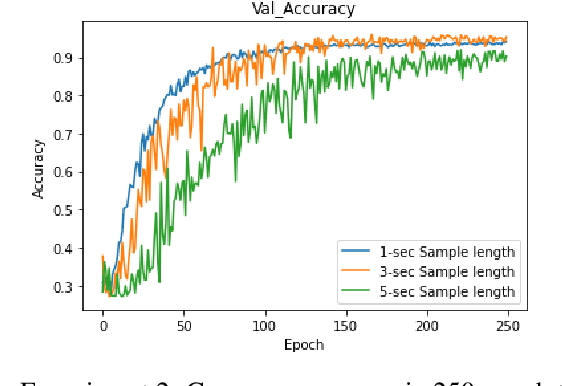
In this paper, we create EMIR, the first-ever Music Information Retrieval dataset for Ethiopian music. EMIR is freely available for research purposes and contains 600 sample recordings of Orthodox Tewahedo chants, traditional Azmari songs and contemporary Ethiopian secular music. Each sample is classified by five expert judges into one of four well-known Ethiopian Kinits, Tizita, Bati, Ambassel and Anchihoye. Each Kinit uses its own pentatonic scale and also has its own stylistic characteristics. Thus, Kinit classification needs to combine scale identification with genre recognition. After describing the dataset, we present the Ethio Kinits Model (EKM), based on VGG, for classifying the EMIR clips. In Experiment 1, we investigated whether Filterbank, Mel-spectrogram, Chroma, or Mel-frequency Cepstral coefficient (MFCC) features work best for Kinit classification using EKM. MFCC was found to be superior and was therefore adopted for Experiment 2, where the performance of EKM models using MFCC was compared using three different audio sample lengths. 3s length gave the best results. In Experiment 3, EKM and four existing models were compared on the EMIR dataset: AlexNet, ResNet50, VGG16 and LSTM. EKM was found to have the best accuracy (95.00%) as well as the fastest training time. We hope this work will encourage others to explore Ethiopian music and to experiment with other models for Kinit classification.