 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
3D-FCT: Simultaneous 3D Object Detection and Tracking Using Feature Correlation
Oct 06, 2021

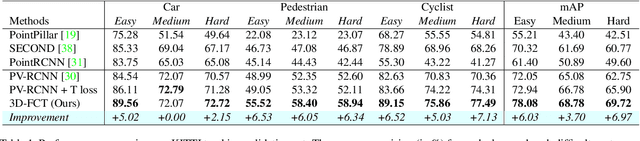
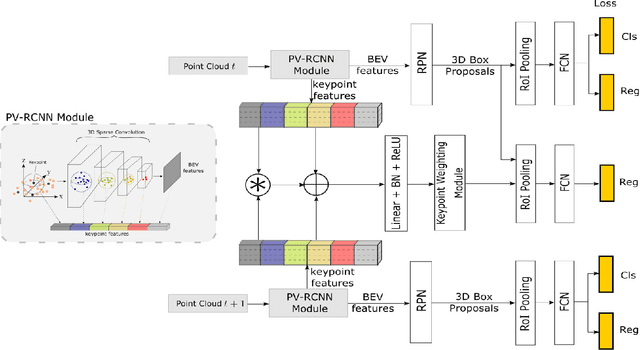
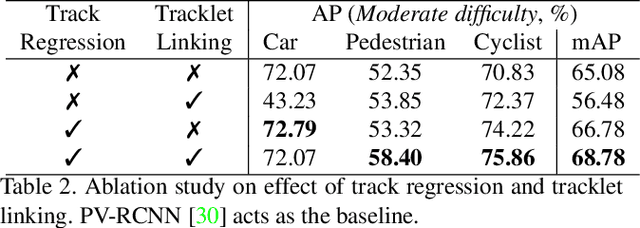
3D object detection using LiDAR data remains a key task for applications like autonomous driving and robotics. Unlike in the case of 2D images, LiDAR data is almost always collected over a period of time. However, most work in this area has focused on performing detection independent of the temporal domain. In this paper we present 3D-FCT, a Siamese network architecture that utilizes temporal information to simultaneously perform the related tasks of 3D object detection and tracking. The network is trained to predict the movement of an object based on the correlation features of extracted keypoints across time. Calculating correlation across keypoints only allows for real-time object detection. We further extend the multi-task objective to include a tracking regression loss. Finally, we produce high accuracy detections by linking short-term object tracklets into long term tracks based on the predicted tracks. Our proposed method is evaluated on the KITTI tracking dataset where it is shown to provide an improvement of 5.57% mAP over a state-of-the-art approach.
Learning Spatio-Temporal Specifications for Dynamical Systems
Dec 20, 2021
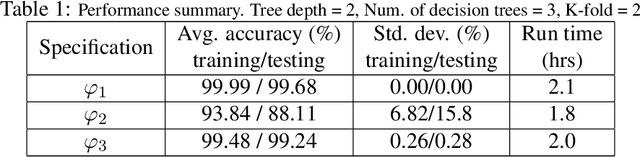

Learning dynamical systems properties from data provides important insights that help us understand such systems and mitigate undesired outcomes. In this work, we propose a framework for learning spatio-temporal (ST) properties as formal logic specifications from data. We introduce SVM-STL, an extension of Signal Signal Temporal Logic (STL), capable of specifying spatial and temporal properties of a wide range of dynamical systems that exhibit time-varying spatial patterns. Our framework utilizes machine learning techniques to learn SVM-STL specifications from system executions given by sequences of spatial patterns. We present methods to deal with both labeled and unlabeled data. In addition, given system requirements in the form of SVM-STL specifications, we provide an approach for parameter synthesis to find parameters that maximize the satisfaction of such specifications. Our learning framework and parameter synthesis approach are showcased in an example of a reaction-diffusion system.
Lightweight Object-level Topological Semantic Mapping and Long-term Global Localization based on Graph Matching
Jan 16, 2022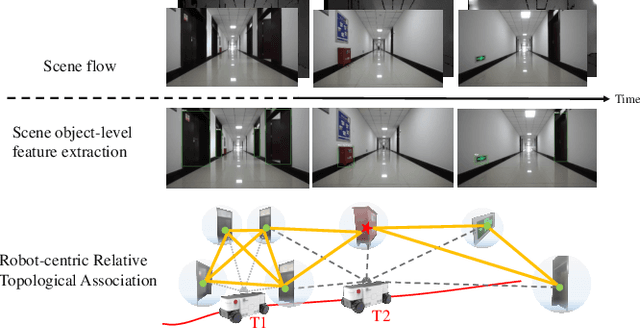

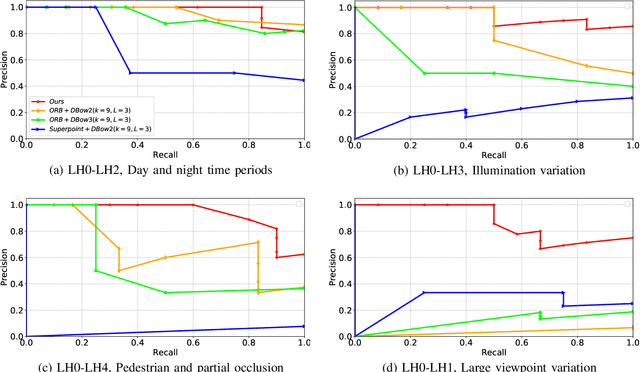
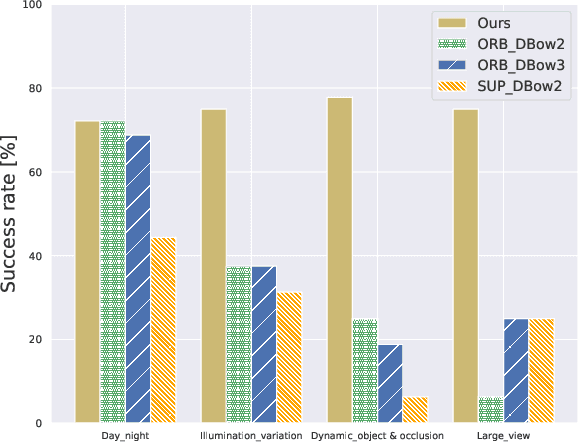
Mapping and localization are two essential tasks for mobile robots in real-world applications. However, largescale and dynamic scenes challenge the accuracy and robustness of most current mature solutions. This situation becomes even worse when computational resources are limited. In this paper, we present a novel lightweight object-level mapping and localization method with high accuracy and robustness. Different from previous methods, our method does not need a prior constructed precise geometric map, which greatly releases the storage burden, especially for large-scale navigation. We use object-level features with both semantic and geometric information to model landmarks in the environment. Particularly, a learning topological primitive is first proposed to efficiently obtain and organize the object-level landmarks. On the basis of this, we use a robot-centric mapping framework to represent the environment as a semantic topology graph and relax the burden of maintaining global consistency at the same time. Besides, a hierarchical memory management mechanism is introduced to improve the efficiency of online mapping with limited computational resources. Based on the proposed map, the robust localization is achieved by constructing a novel local semantic scene graph descriptor, and performing multi-constraint graph matching to compare scene similarity. Finally, we test our method on a low-cost embedded platform to demonstrate its advantages. Experimental results on a large scale and multi-session real-world environment show that the proposed method outperforms the state of arts in terms of lightweight and robustness.
Understanding COVID-19 Vaccine Reaction through Comparative Analysis on Twitter
Nov 10, 2021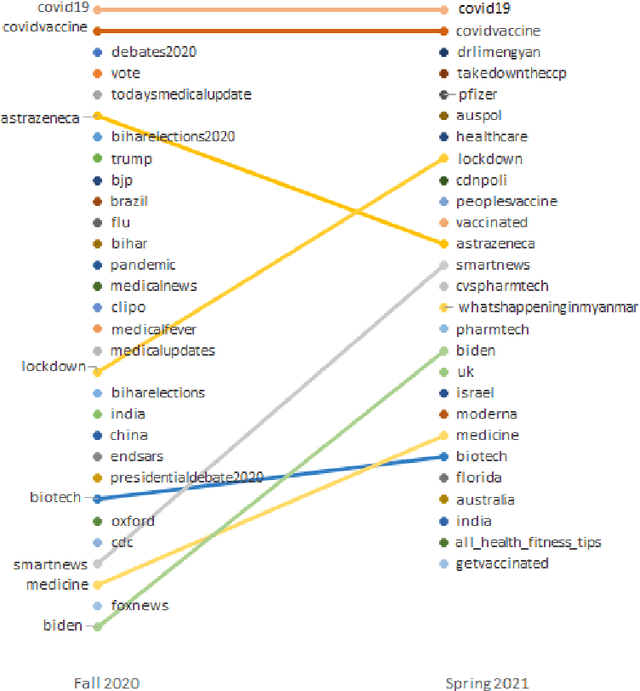
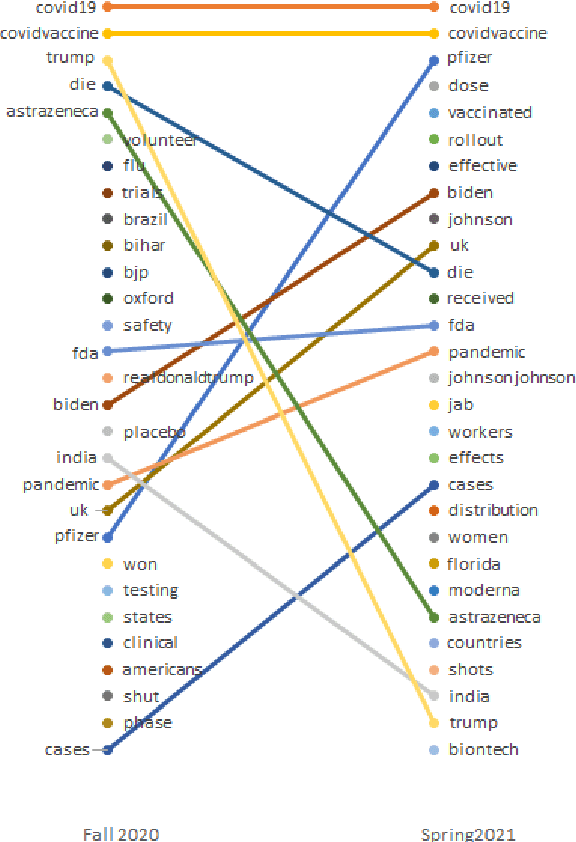
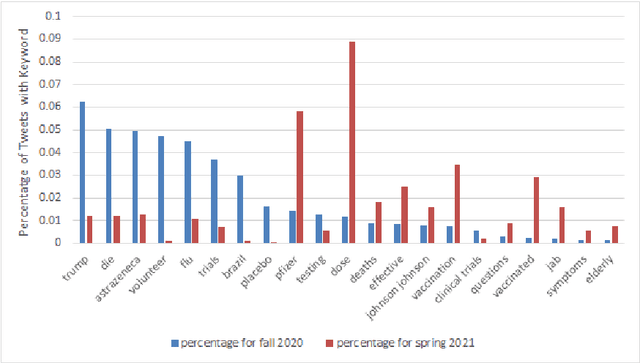
Although multiple COVID-19 vaccines have been available for several months now, vaccine hesitancy continues to be at high levels in the United States. In part, the issue has also become politicized, especially since the presidential election in November. Understanding vaccine hesitancy during this period in the context of social media, including Twitter, can provide valuable guidance both to computational social scientists and policy makers. Rather than studying a single Twitter corpus, this paper takes a novel view of the problem by comparatively studying two Twitter datasets collected between two different time periods (one before the election, and the other, a few months after) using the same, carefully controlled data collection and filtering methodology. Our results show that there was a significant shift in discussion from politics to COVID-19 vaccines from fall of 2020 to spring of 2021. By using clustering and machine learning-based methods in conjunction with sampling and qualitative analysis, we uncover several fine-grained reasons for vaccine hesitancy, some of which have become more (or less) important over time. Our results also underscore the intense polarization and politicization of this issue over the last year.
3D Skeleton-based Few-shot Action Recognition with JEANIE is not so Naïve
Dec 23, 2021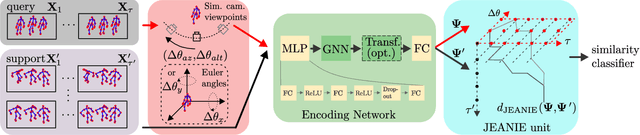
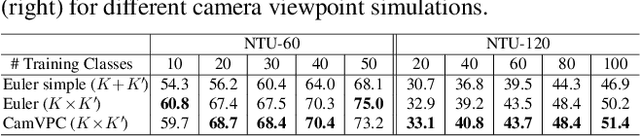
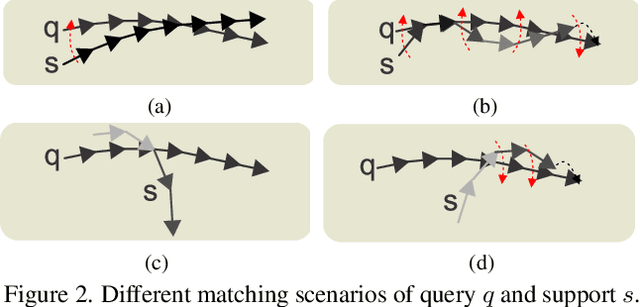
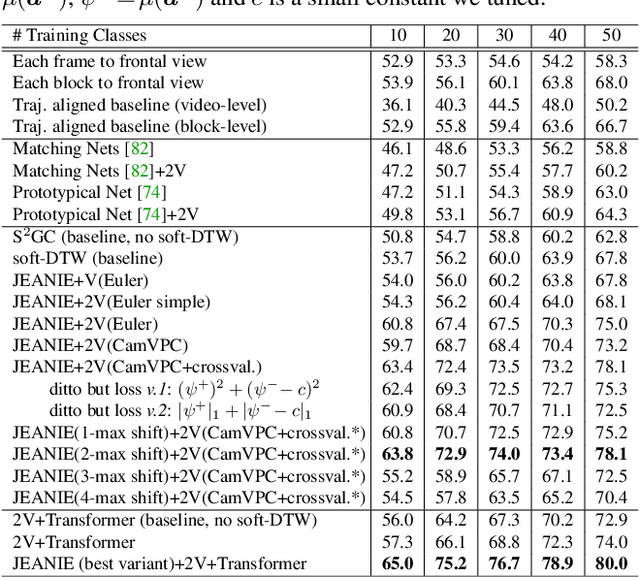
In this paper, we propose a Few-shot Learning pipeline for 3D skeleton-based action recognition by Joint tEmporal and cAmera viewpoiNt alIgnmEnt (JEANIE). To factor out misalignment between query and support sequences of 3D body joints, we propose an advanced variant of Dynamic Time Warping which jointly models each smooth path between the query and support frames to achieve simultaneously the best alignment in the temporal and simulated camera viewpoint spaces for end-to-end learning under the limited few-shot training data. Sequences are encoded with a temporal block encoder based on Simple Spectral Graph Convolution, a lightweight linear Graph Neural Network backbone (we also include a setting with a transformer). Finally, we propose a similarity-based loss which encourages the alignment of sequences of the same class while preventing the alignment of unrelated sequences. We demonstrate state-of-the-art results on NTU-60, NTU-120, Kinetics-skeleton and UWA3D Multiview Activity II.
Deep Spiking Neural Networks with Resonate-and-Fire Neurons
Sep 16, 2021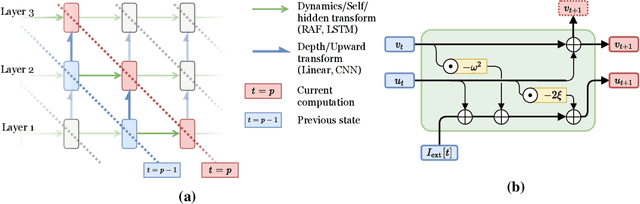
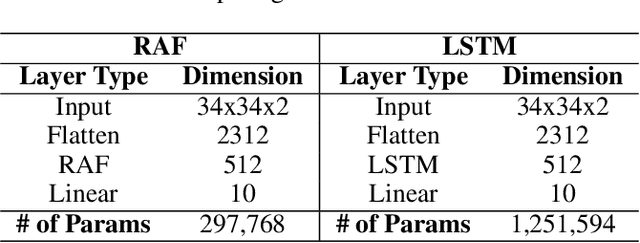
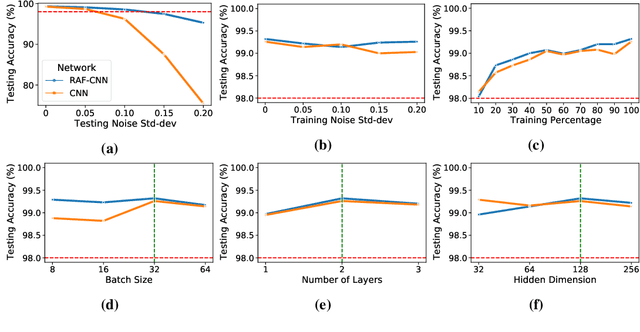
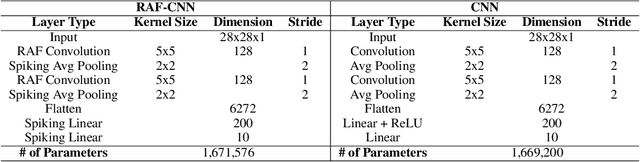
In this work, we explore a new Spiking Neural Network (SNN) formulation with Resonate-and-Fire (RAF) neurons (Izhikevich, 2001) trained with gradient descent via back-propagation. The RAF-SNN, while more biologically plausible, achieves performance comparable to or higher than conventional models in the Machine Learning literature across different network configurations, using similar or fewer parameters. Strikingly, the RAF-SNN proves robust against noise induced at testing/training time, under both static and dynamic conditions. Against CNN on MNIST, we show 25% higher absolute accuracy with N(0, 0.2) induced noise at testing time. Against LSTM on N-MNIST, we show 70% higher absolute accuracy with 20% induced noise at training time.
Enhancement of Healthcare Data Performance Metrics using Neural Network Machine Learning Algorithms
Jan 16, 2022Patients are often encouraged to make use of wearable devices for remote collection and monitoring of health data. This adoption of wearables results in a significant increase in the volume of data collected and transmitted. The battery life of the devices is then quickly diminished due to the high processing requirements of the devices. Given the importance attached to medical data, it is imperative that all transmitted data adhere to strict integrity and availability requirements. Reducing the volume of healthcare data for network transmission may improve sensor battery life without compromising accuracy. There is a trade-off between efficiency and accuracy which can be controlled by adjusting the sampling and transmission rates. This paper demonstrates that machine learning can be used to analyse complex health data metrics such as the accuracy and efficiency of data transmission to overcome the trade-off problem. The study uses time series nonlinear autoregressive neural network algorithms to enhance both data metrics by taking fewer samples to transmit. The algorithms were tested with a standard heart rate dataset to compare their accuracy and efficiency. The result showed that the Levenbery-Marquardt algorithm was the best performer with an efficiency of 3.33 and accuracy of 79.17%, which is similar to other algorithms accuracy but demonstrates improved efficiency. This proves that machine learning can improve without sacrificing a metric over the other compared to the existing methods with high efficiency.
Spatiogram: A phase based directional angular measure and perceptual weighting for ensemble source width
Dec 14, 2021
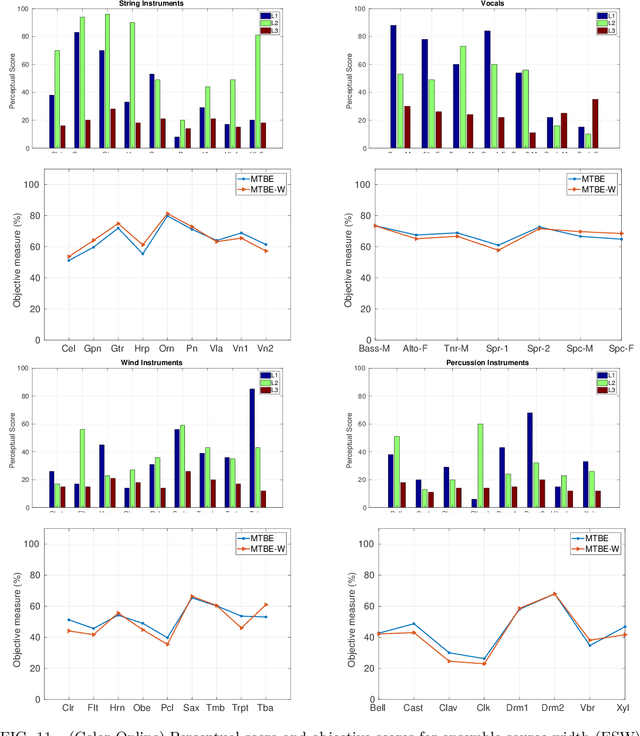
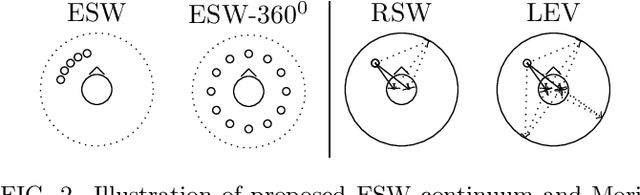
In concert hall studies, inter-aural cross-correlation (IACC), which is signal dependent, is used as a measure of perceptual source width. The same measure is used for perceptual source width in the case of distributed sources also. In this work, we examine the validity of IACC for both the cases and develop an improved measure for ensemble-like distributed sources. We decompose the new objective measure for perceptual ensemble source width (ESW) into two components (i) phase based directional angular measure, which is timbre independent (spatial measure) and (ii) mean time-bandwidth energy (MTBE), a perceptual weight, (timbre measure). This combination of spatial and timbral measures can be extended as an alternate measure for determining auditory source width (ASW) and listener envelopment (LEV) of arbitrary signals in concert-hall and room acoustics.
Computational Lens on Cognition: Study Of Autobiographical Versus Imagined Stories With Large-Scale Language Models
Jan 07, 2022
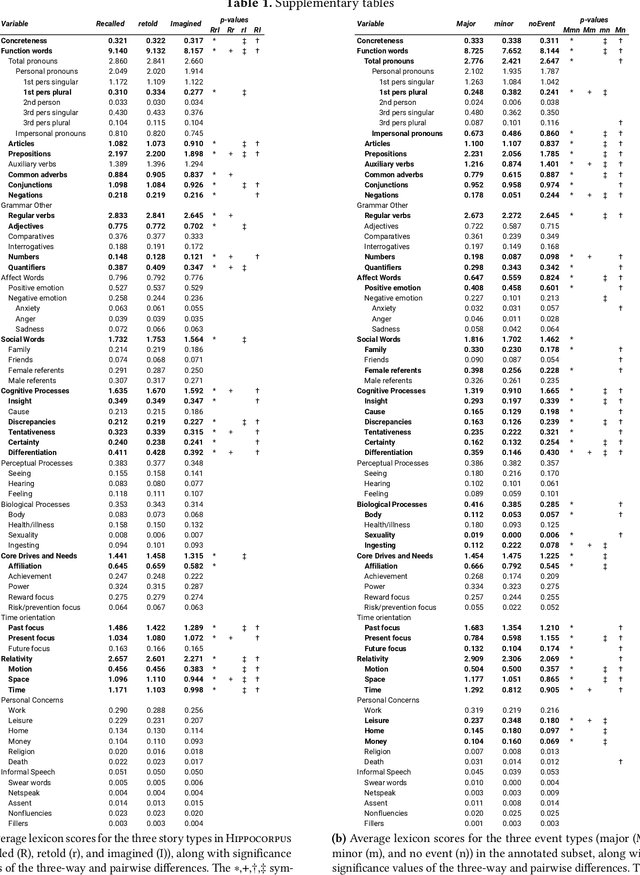
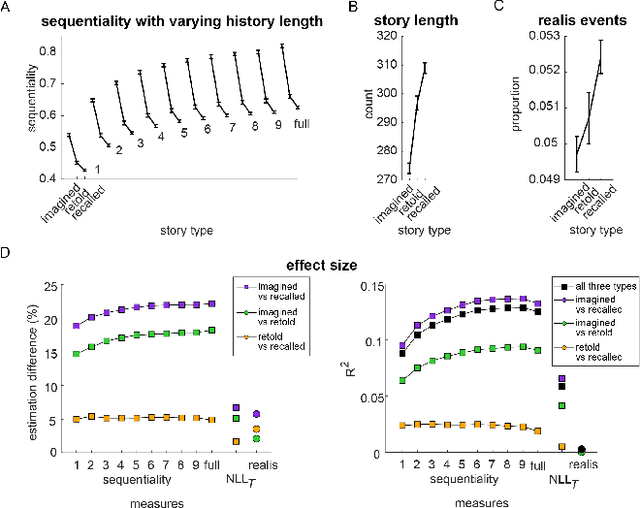
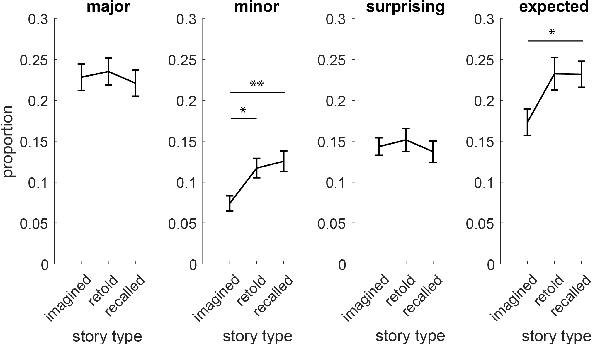
Lifelong experiences and learned knowledge lead to shared expectations about how common situations tend to unfold. Such knowledge enables people to interpret story narratives and identify salient events effortlessly. We study differences in the narrative flow of events in autobiographical versus imagined stories using GPT-3, one of the largest neural language models created to date. The diary-like stories were written by crowdworkers about either a recently experienced event or an imagined event on the same topic. To analyze the narrative flow of events of these stories, we measured sentence *sequentiality*, which compares the probability of a sentence with and without its preceding story context. We found that imagined stories have higher sequentiality than autobiographical stories, and that the sequentiality of autobiographical stories is higher when they are retold than when freshly recalled. Through an annotation of events in story sentences, we found that the story types contain similar proportions of major salient events, but that the autobiographical stories are denser in factual minor events. Furthermore, in comparison to imagined stories, autobiographical stories contain more concrete words and words related to the first person, cognitive processes, time, space, numbers, social words, and core drives and needs. Our findings highlight the opportunity to investigate memory and cognition with large-scale statistical language models.
Image-free multi-character recognition
Dec 20, 2021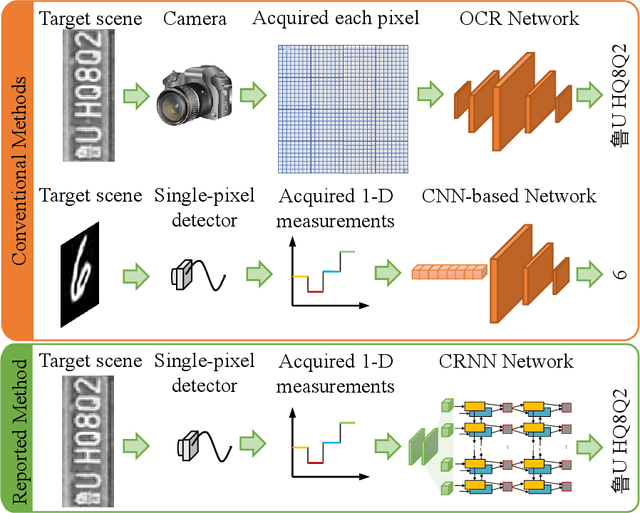
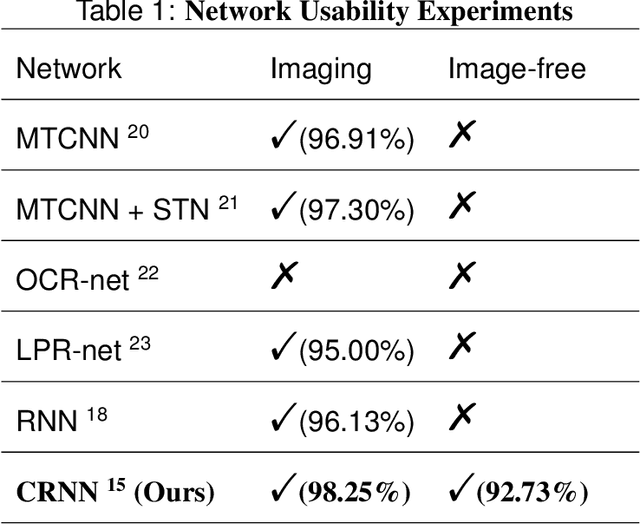
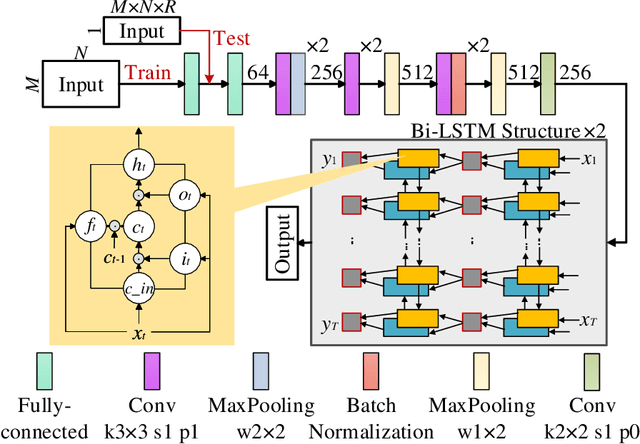
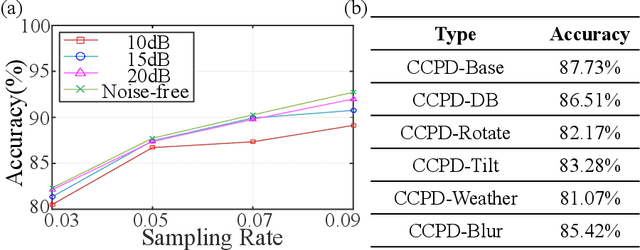
The recently developed image-free sensing technique maintains the advantages of both the light hardware and software, which has been applied in simple target classification and motion tracking. In practical applications, however, there usually exist multiple targets in the field of view, where existing trials fail to produce multi-semantic information. In this letter, we report a novel image-free sensing technique to tackle the multi-target recognition challenge for the first time. Different from the convolutional layer stack of image-free single-pixel networks, the reported CRNN network utilities the bidirectional LSTM architecture to predict the distribution of multiple characters simultaneously. The framework enables to capture the long-range dependencies, providing a high recognition accuracy of multiple characters. We demonstrated the technique's effectiveness in license plate detection, which achieved 87.60% recognition accuracy at a 5% sampling rate with a higher than 100 FPS refresh rate.