 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Universal Link Predictor By In-Context Learning on Graphs
Feb 15, 2024
Link prediction is a crucial task in graph machine learning, where the goal is to infer missing or future links within a graph. Traditional approaches leverage heuristic methods based on widely observed connectivity patterns, offering broad applicability and generalizability without the need for model training. Despite their utility, these methods are limited by their reliance on human-derived heuristics and lack the adaptability of data-driven approaches. Conversely, parametric link predictors excel in automatically learning the connectivity patterns from data and achieving state-of-the-art but fail short to directly transfer across different graphs. Instead, it requires the cost of extensive training and hyperparameter optimization to adapt to the target graph. In this work, we introduce the Universal Link Predictor (UniLP), a novel model that combines the generalizability of heuristic approaches with the pattern learning capabilities of parametric models. UniLP is designed to autonomously identify connectivity patterns across diverse graphs, ready for immediate application to any unseen graph dataset without targeted training. We address the challenge of conflicting connectivity patterns-arising from the unique distributions of different graphs-through the implementation of In-context Learning (ICL). This approach allows UniLP to dynamically adjust to various target graphs based on contextual demonstrations, thereby avoiding negative transfer. Through rigorous experimentation, we demonstrate UniLP's effectiveness in adapting to new, unseen graphs at test time, showcasing its ability to perform comparably or even outperform parametric models that have been finetuned for specific datasets. Our findings highlight UniLP's potential to set a new standard in link prediction, combining the strengths of heuristic and parametric methods in a single, versatile framework.
Particle Denoising Diffusion Sampler
Feb 09, 2024Denoising diffusion models have become ubiquitous for generative modeling. The core idea is to transport the data distribution to a Gaussian by using a diffusion. Approximate samples from the data distribution are then obtained by estimating the time-reversal of this diffusion using score matching ideas. We follow here a similar strategy to sample from unnormalized probability densities and compute their normalizing constants. However, the time-reversed diffusion is here simulated by using an original iterative particle scheme relying on a novel score matching loss. Contrary to standard denoising diffusion models, the resulting Particle Denoising Diffusion Sampler (PDDS) provides asymptotically consistent estimates under mild assumptions. We demonstrate PDDS on multimodal and high dimensional sampling tasks.
Detection Latencies of Anomaly Detectors: An Overlooked Perspective ?
Feb 14, 2024The ever-evolving landscape of attacks, coupled with the growing complexity of ICT systems, makes crafting anomaly-based intrusion detectors (ID) and error detectors (ED) a difficult task: they must accurately detect attacks, and they should promptly perform detections. Although improving and comparing the detection capability is the focus of most research works, the timeliness of the detection is less considered and often insufficiently evaluated or discussed. In this paper, we argue the relevance of measuring the temporal latency of attacks and errors, and we propose an evaluation approach for detectors to ensure a pragmatic trade-off between correct and in-time detection. Briefly, the approach relates the false positive rate with the temporal latency of attacks and errors, and this ultimately leads to guidelines for configuring a detector. We apply our approach by evaluating different ED and ID solutions in two industrial cases: i) an embedded railway on-board system that optimizes public mobility, and ii) an edge device for the Industrial Internet of Things. Our results show that considering latency in addition to traditional metrics like the false positive rate, precision, and coverage gives an additional fundamental perspective on the actual performance of the detector and should be considered when assessing and configuring anomaly detectors.
L3GO: Language Agents with Chain-of-3D-Thoughts for Generating Unconventional Objects
Feb 14, 2024Diffusion-based image generation models such as DALL-E 3 and Stable Diffusion-XL demonstrate remarkable capabilities in generating images with realistic and unique compositions. Yet, these models are not robust in precisely reasoning about physical and spatial configurations of objects, especially when instructed with unconventional, thereby out-of-distribution descriptions, such as "a chair with five legs". In this paper, we propose a language agent with chain-of-3D-thoughts (L3GO), an inference-time approach that can reason about part-based 3D mesh generation of unconventional objects that current data-driven diffusion models struggle with. More concretely, we use large language models as agents to compose a desired object via trial-and-error within the 3D simulation environment. To facilitate our investigation, we develop a new benchmark, Unconventionally Feasible Objects (UFO), as well as SimpleBlenv, a wrapper environment built on top of Blender where language agents can build and compose atomic building blocks via API calls. Human and automatic GPT-4V evaluations show that our approach surpasses the standard GPT-4 and other language agents (e.g., ReAct and Reflexion) for 3D mesh generation on ShapeNet. Moreover, when tested on our UFO benchmark, our approach outperforms other state-of-the-art text-to-2D image and text-to-3D models based on human evaluation.
On the Resurgence of Recurrent Models for Long Sequences -- Survey and Research Opportunities in the Transformer Era
Feb 14, 2024A longstanding challenge for the Machine Learning community is the one of developing models that are capable of processing and learning from very long sequences of data. The outstanding results of Transformers-based networks (e.g., Large Language Models) promotes the idea of parallel attention as the key to succeed in such a challenge, obfuscating the role of classic sequential processing of Recurrent Models. However, in the last few years, researchers who were concerned by the quadratic complexity of self-attention have been proposing a novel wave of neural models, which gets the best from the two worlds, i.e., Transformers and Recurrent Nets. Meanwhile, Deep Space-State Models emerged as robust approaches to function approximation over time, thus opening a new perspective in learning from sequential data, followed by many people in the field and exploited to implement a special class of (linear) Recurrent Neural Networks. This survey is aimed at providing an overview of these trends framed under the unifying umbrella of Recurrence. Moreover, it emphasizes novel research opportunities that become prominent when abandoning the idea of processing long sequences whose length is known-in-advance for the more realistic setting of potentially infinite-length sequences, thus intersecting the field of lifelong-online learning from streamed data.
Fine-Tuning Text-To-Image Diffusion Models for Class-Wise Spurious Feature Generation
Feb 13, 2024

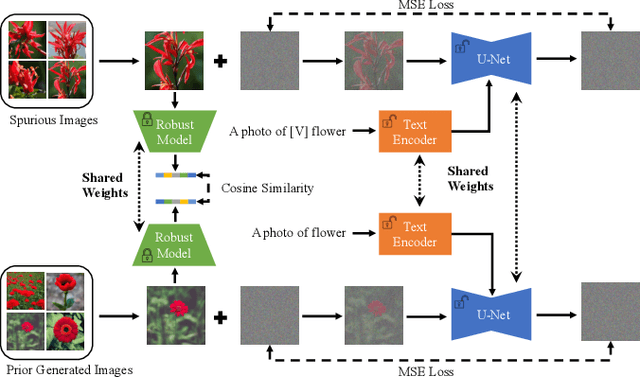
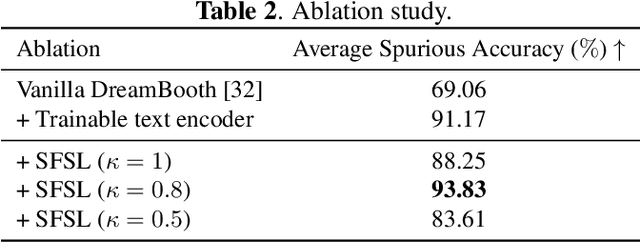
We propose a method for generating spurious features by leveraging large-scale text-to-image diffusion models. Although the previous work detects spurious features in a large-scale dataset like ImageNet and introduces Spurious ImageNet, we found that not all spurious images are spurious across different classifiers. Although spurious images help measure the reliance of a classifier, filtering many images from the Internet to find more spurious features is time-consuming. To this end, we utilize an existing approach of personalizing large-scale text-to-image diffusion models with available discovered spurious images and propose a new spurious feature similarity loss based on neural features of an adversarially robust model. Precisely, we fine-tune Stable Diffusion with several reference images from Spurious ImageNet with a modified objective incorporating the proposed spurious-feature similarity loss. Experiment results show that our method can generate spurious images that are consistently spurious across different classifiers. Moreover, the generated spurious images are visually similar to reference images from Spurious ImageNet.
Suppressing Pink Elephants with Direct Principle Feedback
Feb 13, 2024Existing methods for controlling language models, such as RLHF and Constitutional AI, involve determining which LLM behaviors are desirable and training them into a language model. However, in many cases, it is desirable for LLMs to be controllable at inference time, so that they can be used in multiple contexts with diverse needs. We illustrate this with the Pink Elephant Problem: instructing an LLM to avoid discussing a certain entity (a ``Pink Elephant''), and instead discuss a preferred entity (``Grey Elephant''). We apply a novel simplification of Constitutional AI, Direct Principle Feedback, which skips the ranking of responses and uses DPO directly on critiques and revisions. Our results show that after DPF fine-tuning on our synthetic Pink Elephants dataset, our 13B fine-tuned LLaMA 2 model significantly outperforms Llama-2-13B-Chat and a prompted baseline, and performs as well as GPT-4 in on our curated test set assessing the Pink Elephant Problem.
Knowledge Editing on Black-box Large Language Models
Feb 13, 2024Knowledge editing (KE) aims to efficiently and precisely modify the behavior of large language models (LLMs) to update specific knowledge without negatively influencing other knowledge. Current research primarily focuses on white-box LLMs editing, overlooking an important scenario: black-box LLMs editing, where LLMs are accessed through interfaces and only textual output is available. To address the limitations of existing evaluations that are not inapplicable to black-box LLM editing and lack comprehensiveness, we propose a multi-perspective evaluation framework, incorporating the assessment of style retention for the first time. To tackle privacy leaks of editing data and style over-editing in current methods, we introduce a novel postEdit framework, resolving privacy concerns through downstream post-processing and maintaining textual style consistency via fine-grained editing to original responses. Experiments and analysis on two benchmarks demonstrate that postEdit outperforms all baselines and achieves strong generalization, especially with huge improvements on style retention (average $+20.82\%\uparrow$).
A Novel Approach to Regularising 1NN classifier for Improved Generalization
Feb 13, 2024In this paper, we propose a class of non-parametric classifiers, that learn arbitrary boundaries and generalize well. Our approach is based on a novel way to regularize 1NN classifiers using a greedy approach. We refer to this class of classifiers as Watershed Classifiers. 1NN classifiers are known to trivially over-fit but have very large VC dimension, hence do not generalize well. We show that watershed classifiers can find arbitrary boundaries on any dense enough dataset, and, at the same time, have very small VC dimension; hence a watershed classifier leads to good generalization. Traditional approaches to regularize 1NN classifiers are to consider $K$ nearest neighbours. Neighbourhood component analysis (NCA) proposes a way to learn representations consistent with ($n-1$) nearest neighbour classifier, where $n$ denotes the size of the dataset. In this article, we propose a loss function which can learn representations consistent with watershed classifiers, and show that it outperforms the NCA baseline.
Successive Refinement in Large-Scale Computation: Advancing Model Inference Applications
Feb 11, 2024Modern computationally-intensive applications often operate under time constraints, necessitating acceleration methods and distribution of computational workloads across multiple entities. However, the outcome is either achieved within the desired timeline or not, and in the latter case, valuable resources are wasted. In this paper, we introduce solutions for layered-resolution computation. These solutions allow lower-resolution results to be obtained at an earlier stage than the final result. This innovation notably enhances the deadline-based systems, as if a computational job is terminated due to time constraints, an approximate version of the final result can still be generated. Moreover, in certain operational regimes, a high-resolution result might be unnecessary, because the low-resolution result may already deviate significantly from the decision threshold, for example in AI-based decision-making systems. Therefore, operators can decide whether higher resolution is needed or not based on intermediate results, enabling computations with adaptive resolution. We present our framework for two critical and computationally demanding jobs: distributed matrix multiplication (linear) and model inference in machine learning (nonlinear). Our theoretical and empirical results demonstrate that the execution delay for the first resolution is significantly shorter than that for the final resolution, while maintaining overall complexity comparable to the conventional one-shot approach. Our experiments further illustrate how the layering feature increases the likelihood of meeting deadlines and enables adaptability and transparency in massive, large-scale computations.