 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Calibration of prediction rules for life-time outcomes using prognostic Cox regression survival models and multiple imputations to account for missing predictor data with cross-validatory assessment
May 04, 2021
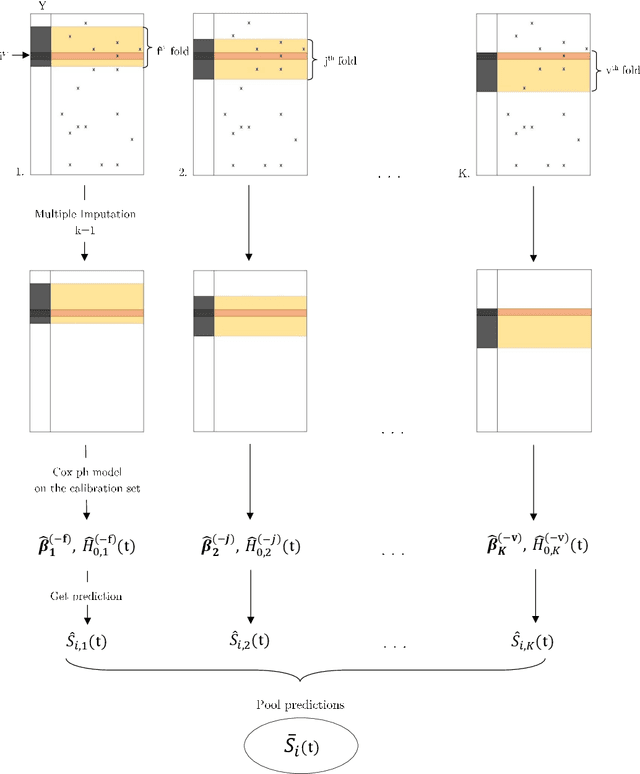
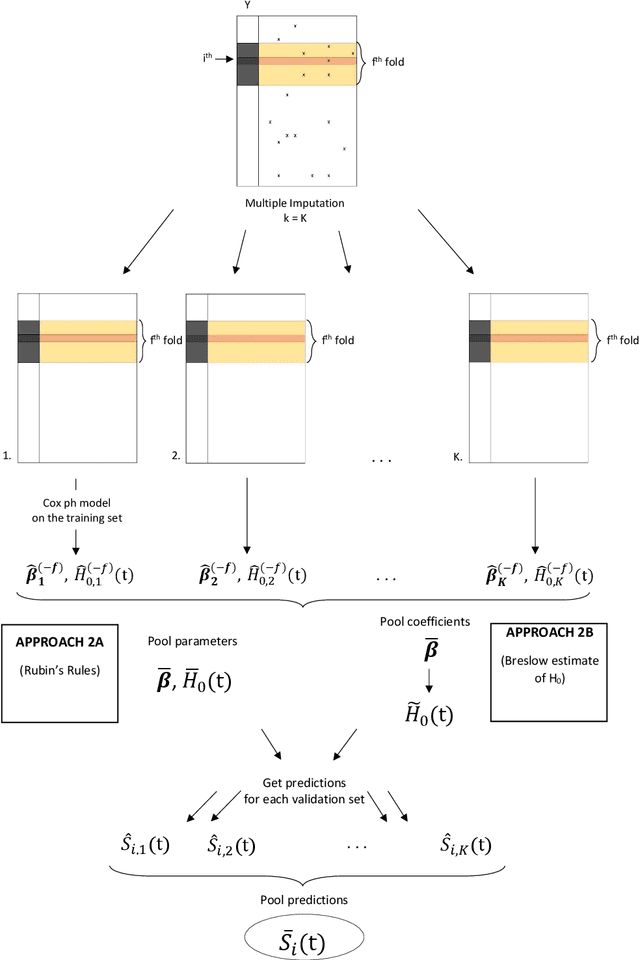
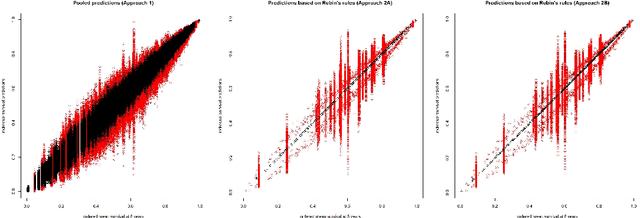
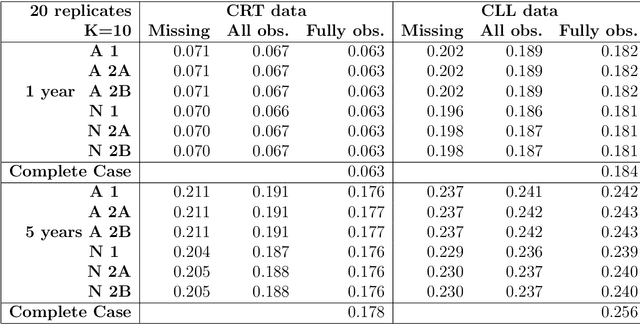
In this paper, we expand the methodology presented in Mertens et. al (2020, Biometrical Journal) to the study of life-time (survival) outcome which is subject to censoring and when imputation is used to account for missing values. We consider the problem where missing values can occur in both the calibration data as well as newly - to-be-predicted - observations (validation). We focus on the Cox model. Methods are described to combine imputation with predictive calibration in survival modeling subject to censoring. Application to cross-validation is discussed. We demonstrate how conclusions broadly confirm the first paper which restricted to the study of binary outcomes only. Specifically prediction-averaging appears to have superior statistical properties, especially smaller predictive variation, as opposed to a direct application of Rubin's rules. Distinct methods for dealing with the baseline hazards are discussed when using Rubin's rules-based approaches.
Control of Walking Assist Exoskeleton with Time-delay Based on the Prediction of Plantar Force
Jul 02, 2020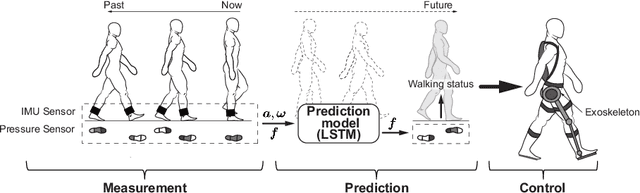
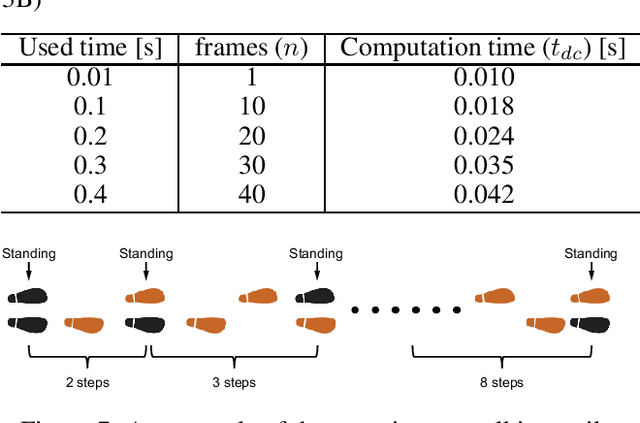
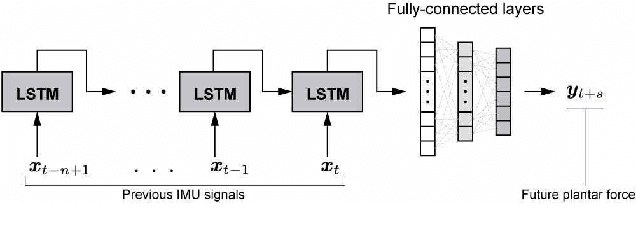
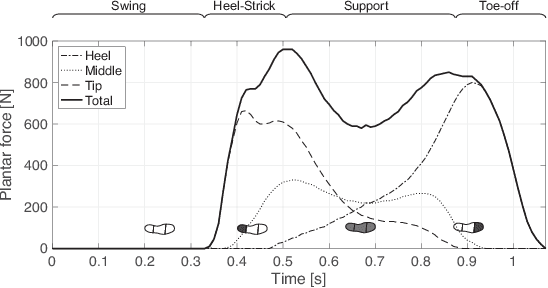
Many kinds of lower-limb exoskeletons were developed for walking assistance. However, time-delay arised from the computation time and the communication delays is still a general problem when controlling these exoskeletons. In this research, we proposed a novel method to prevent the time-delay when controlling a walking assist exoskeleton by predicting future plantar force and walking status. By using Long Short-term Memory (LSTM) and fully-connected network, the plantar force can be predicted only from the data measured from inertial measurement unit (IMU) sensors, not only during the periodic walking but also when the start and end of walking. The walking status and the desired assisting timing can also be detected from the predicted plantar force. By sending the control command beforehand with considering the time-delay, the exoskeleton can be moved right on the desired assisting timing. In the experiments, the prediction errors of the plantar force and the assisting timing are confirmed. The performance of the proposed method is also evaluated by controlling the exoskeleton using the trained model.
AIDA: An Active Inference-based Design Agent for Audio Processing Algorithms
Jan 10, 2022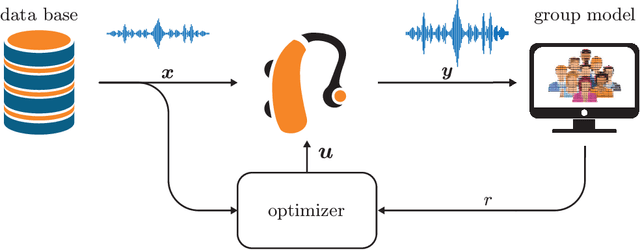
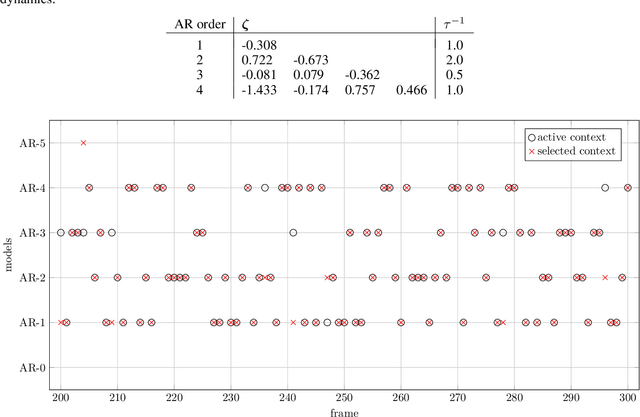
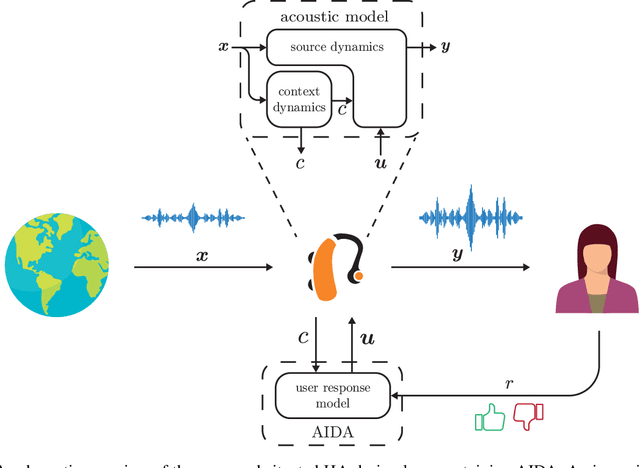
In this paper we present AIDA, which is an active inference-based agent that iteratively designs a personalized audio processing algorithm through situated interactions with a human client. The target application of AIDA is to propose on-the-spot the most interesting alternative values for the tuning parameters of a hearing aid (HA) algorithm, whenever a HA client is not satisfied with their HA performance. AIDA interprets searching for the "most interesting alternative" as an issue of optimal (acoustic) context-aware Bayesian trial design. In computational terms, AIDA is realized as an active inference-based agent with an Expected Free Energy criterion for trial design. This type of architecture is inspired by neuro-economic models on efficient (Bayesian) trial design in brains and implies that AIDA comprises generative probabilistic models for acoustic signals and user responses. We propose a novel generative model for acoustic signals as a sum of time-varying auto-regressive filters and a user response model based on a Gaussian Process Classifier. The full AIDA agent has been implemented in a factor graph for the generative model and all tasks (parameter learning, acoustic context classification, trial design, etc.) are realized by variational message passing on the factor graph. All verification and validation experiments and demonstrations are freely accessible at our GitHub repository.
Soft Sensing Model Visualization: Fine-tuning Neural Network from What Model Learned
Nov 12, 2021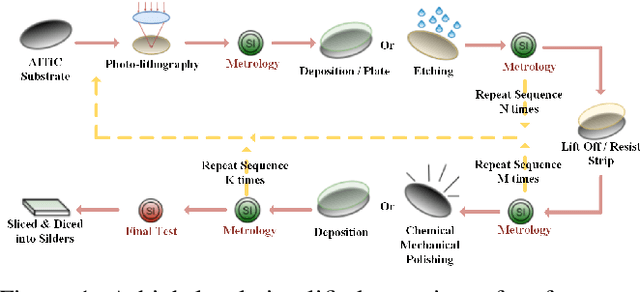
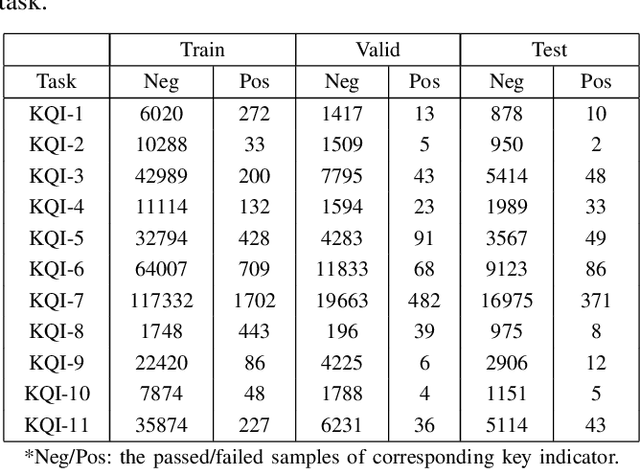
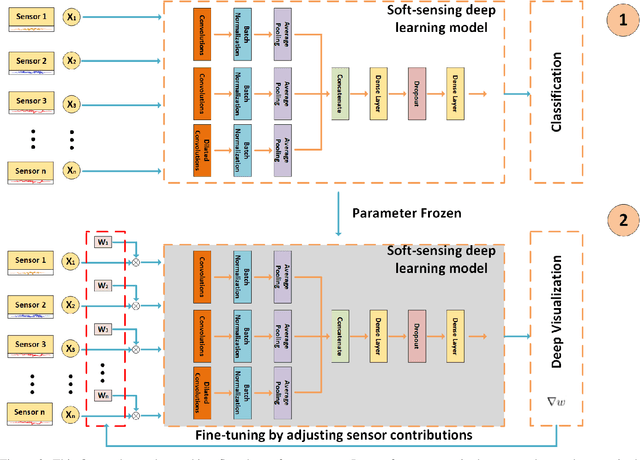
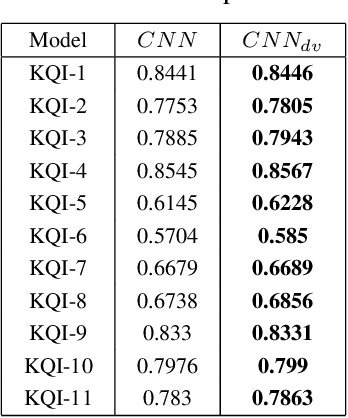
The growing availability of the data collected from smart manufacturing is changing the paradigms of production monitoring and control. The increasing complexity and content of the wafer manufacturing process in addition to the time-varying unexpected disturbances and uncertainties, make it infeasible to do the control process with model-based approaches. As a result, data-driven soft-sensing modeling has become more prevalent in wafer process diagnostics. Recently, deep learning has been utilized in soft sensing system with promising performance on highly nonlinear and dynamic time-series data. Despite its successes in soft-sensing systems, however, the underlying logic of the deep learning framework is hard to understand. In this paper, we propose a deep learning-based model for defective wafer detection using a highly imbalanced dataset. To understand how the proposed model works, the deep visualization approach is applied. Additionally, the model is then fine-tuned guided by the deep visualization. Extensive experiments are performed to validate the effectiveness of the proposed system. The results provide an interpretation of how the model works and an instructive fine-tuning method based on the interpretation.
GraSSNet: Graph Soft Sensing Neural Networks
Nov 12, 2021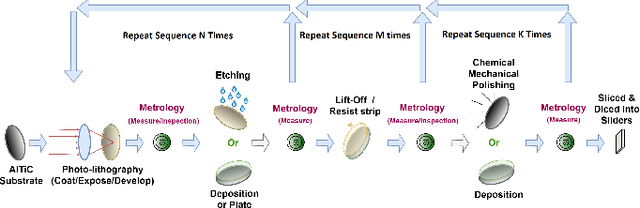
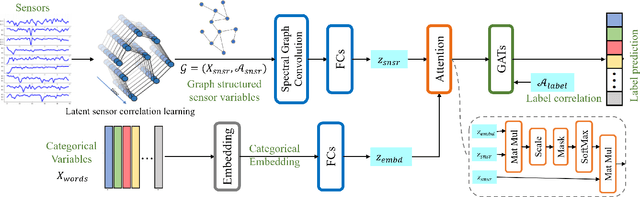
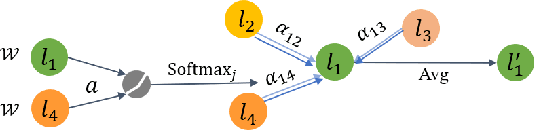
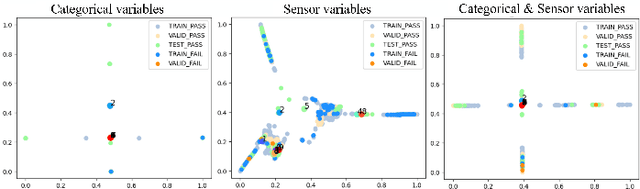
In the era of big data, data-driven based classification has become an essential method in smart manufacturing to guide production and optimize inspection. The industrial data obtained in practice is usually time-series data collected by soft sensors, which are highly nonlinear, nonstationary, imbalanced, and noisy. Most existing soft-sensing machine learning models focus on capturing either intra-series temporal dependencies or pre-defined inter-series correlations, while ignoring the correlation between labels as each instance is associated with multiple labels simultaneously. In this paper, we propose a novel graph based soft-sensing neural network (GraSSNet) for multivariate time-series classification of noisy and highly-imbalanced soft-sensing data. The proposed GraSSNet is able to 1) capture the inter-series and intra-series dependencies jointly in the spectral domain; 2) exploit the label correlations by superimposing label graph that built from statistical co-occurrence information; 3) learn features with attention mechanism from both textual and numerical domain; and 4) leverage unlabeled data and mitigate data imbalance by semi-supervised learning. Comparative studies with other commonly used classifiers are carried out on Seagate soft sensing data, and the experimental results validate the competitive performance of our proposed method.
Avoiding Overfitting: A Survey on Regularization Methods for Convolutional Neural Networks
Jan 10, 2022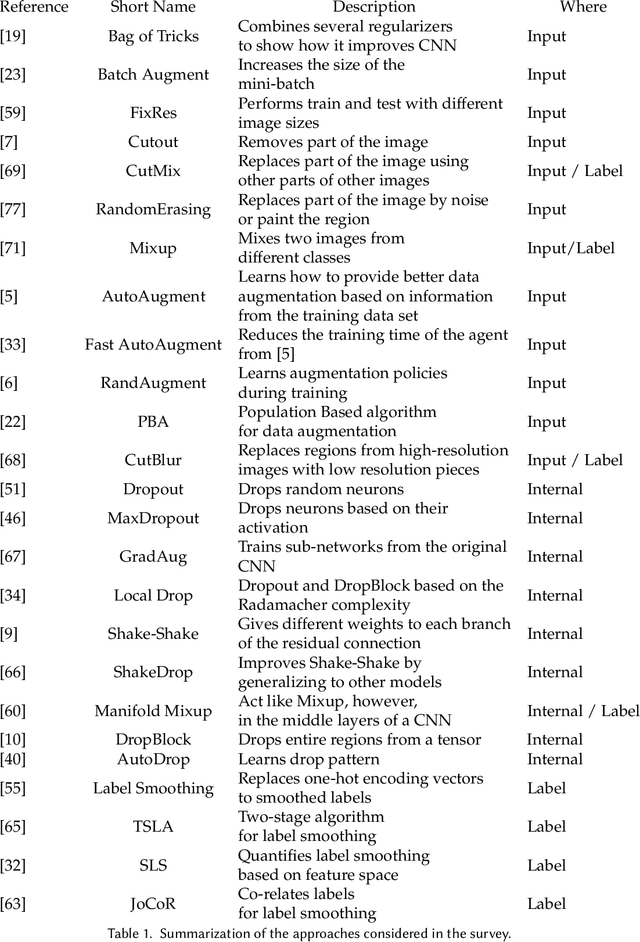
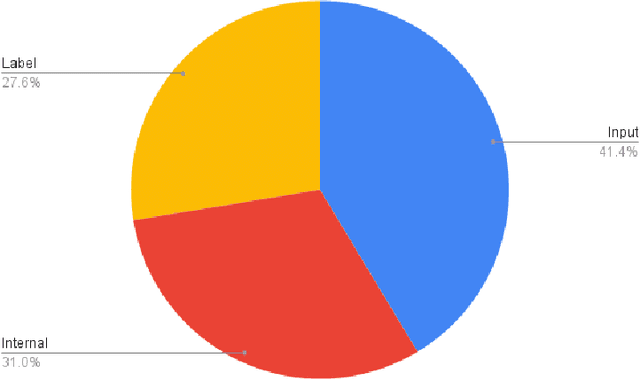
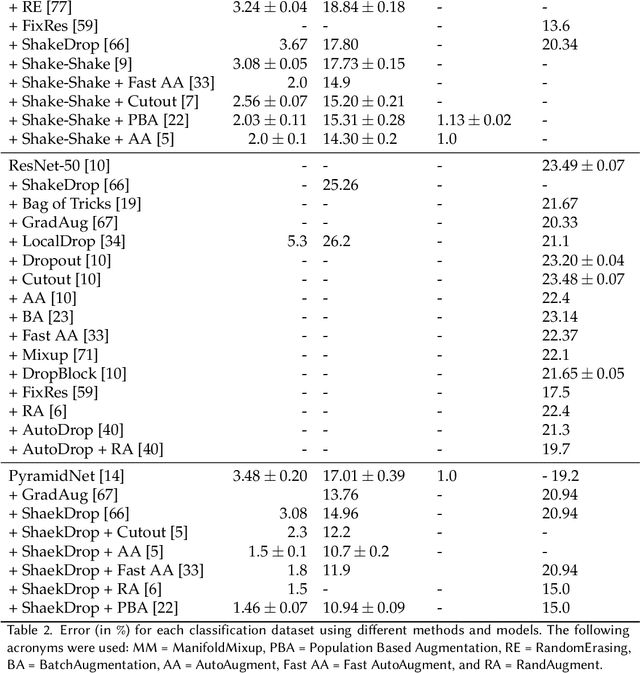
Several image processing tasks, such as image classification and object detection, have been significantly improved using Convolutional Neural Networks (CNN). Like ResNet and EfficientNet, many architectures have achieved outstanding results in at least one dataset by the time of their creation. A critical factor in training concerns the network's regularization, which prevents the structure from overfitting. This work analyzes several regularization methods developed in the last few years, showing significant improvements for different CNN models. The works are classified into three main areas: the first one is called "data augmentation", where all the techniques focus on performing changes in the input data. The second, named "internal changes", which aims to describe procedures to modify the feature maps generated by the neural network or the kernels. The last one, called "label", concerns transforming the labels of a given input. This work presents two main differences comparing to other available surveys about regularization: (i) the first concerns the papers gathered in the manuscript, which are not older than five years, and (ii) the second distinction is about reproducibility, i.e., all works refered here have their code available in public repositories or they have been directly implemented in some framework, such as TensorFlow or Torch.
Human and Machine Type Communications can Coexist in Uplink Massive MIMO Systems
Dec 31, 2021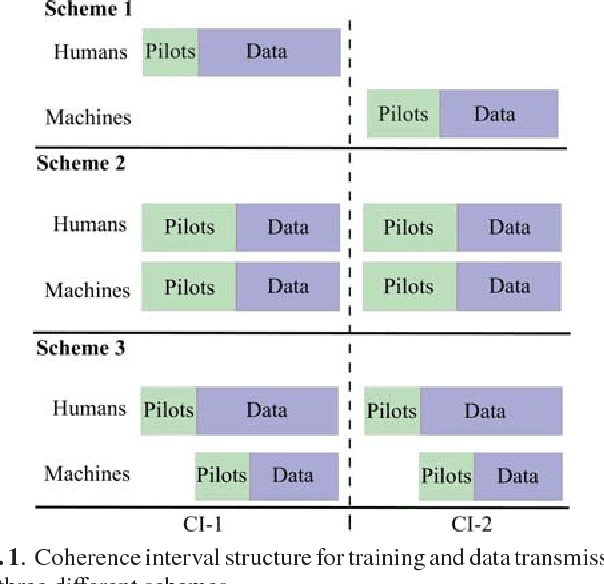
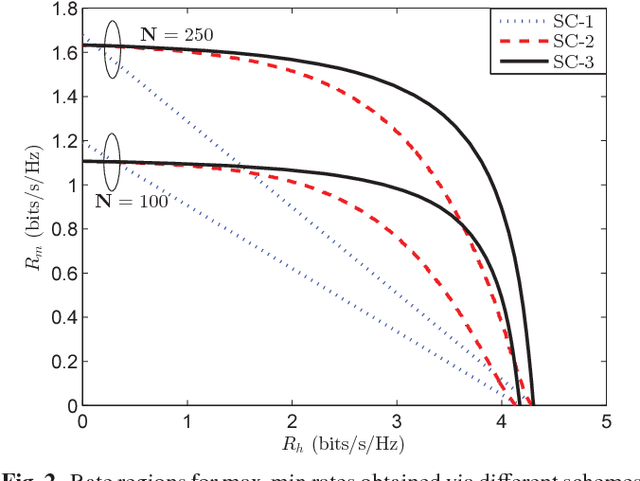
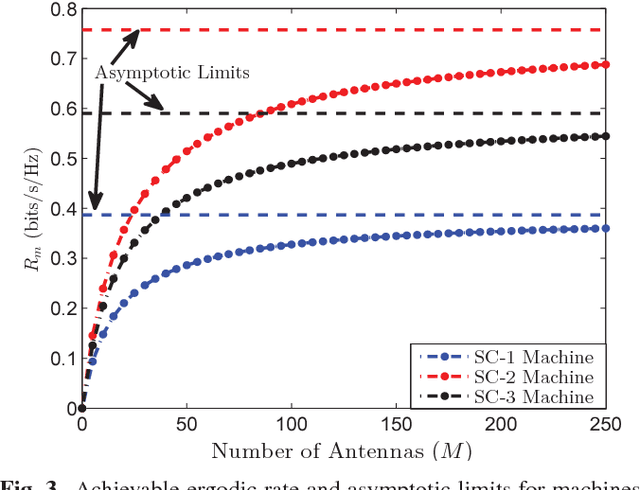
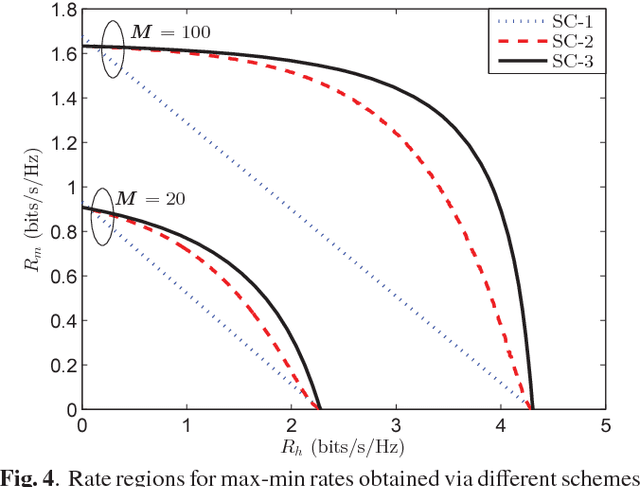
Future cellular networks are expected to support new communication paradigms such as machine-type communication (MTC) services along with human-type communication (HTC) services. This requires base stations to serve a large number of devices in relatively short channel coherence intervals which renders allocation of orthogonal pilot sequence per-device approaches impractical. Furthermore, the stringent power constraints, place-and-play type connectivity and various data rate requirements of MTC devices make it impossible for the traditional cellular architecture to accommodate MTC and HTC services together. Massive multiple-input-multiple-output (MaMIMO) technology has the potential to allow the coexistence of HTC and MTC services, thanks to its inherent spatial multiplexing properties and low transmission power requirements. In this work, we investigate the performance of a single cell under a shared physical channel assumption for MTC and HTC services and propose a novel scheme for sharing the time-frequency resources. The analysis reveals that MaMIMO can significantly enhance the performance of such a setup and allow the inclusion of MTC services into the cellular networks without requiring additional resources.
Precise Stock Price Prediction for Robust Portfolio Design from Selected Sectors of the Indian Stock Market
Jan 14, 2022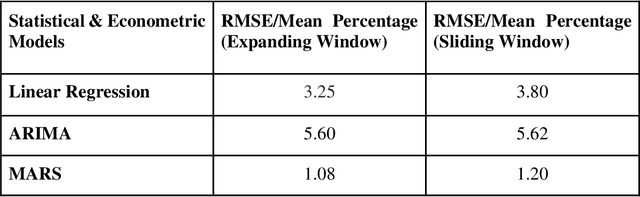
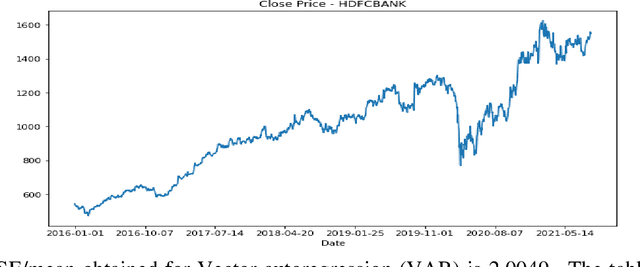
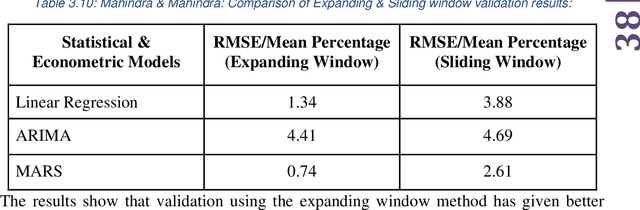
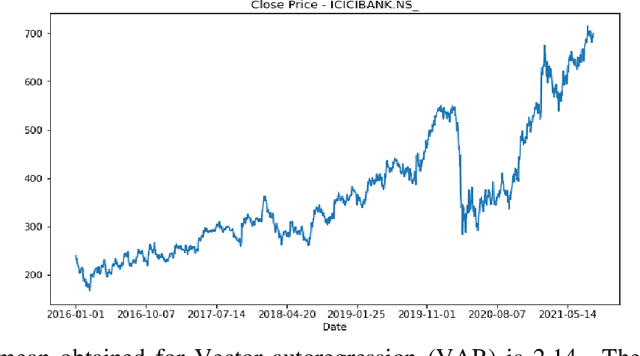
Stock price prediction is a challenging task and a lot of propositions exist in the literature in this area. Portfolio construction is a process of choosing a group of stocks and investing in them optimally to maximize the return while minimizing the risk. Since the time when Markowitz proposed the Modern Portfolio Theory, several advancements have happened in the area of building efficient portfolios. An investor can get the best benefit out of the stock market if the investor invests in an efficient portfolio and could take the buy or sell decision in advance, by estimating the future asset value of the portfolio with a high level of precision. In this project, we have built an efficient portfolio and to predict the future asset value by means of individual stock price prediction of the stocks in the portfolio. As part of building an efficient portfolio we have studied multiple portfolio optimization methods beginning with the Modern Portfolio theory. We have built the minimum variance portfolio and optimal risk portfolio for all the five chosen sectors by using past daily stock prices over the past five years as the training data, and have also conducted back testing to check the performance of the portfolio. A comparative study of minimum variance portfolio and optimal risk portfolio with equal weight portfolio is done by backtesting.
Attention-based Proposals Refinement for 3D Object Detection
Jan 18, 2022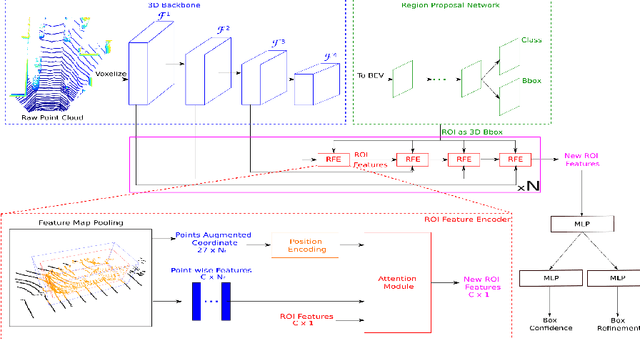
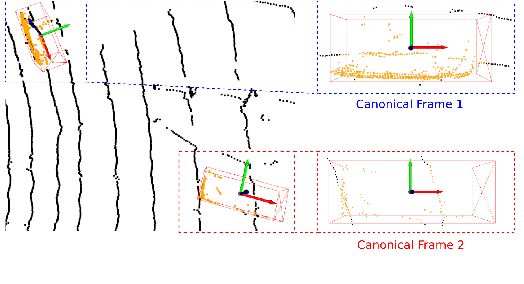
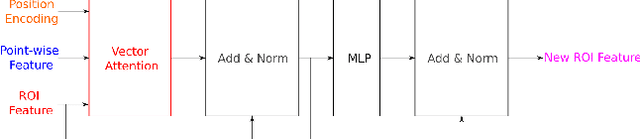
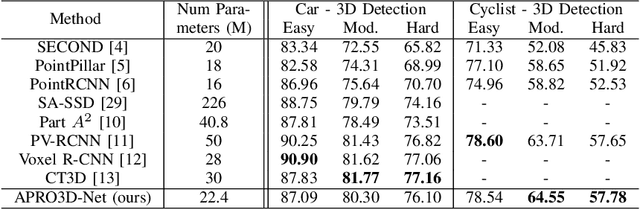
Safe autonomous driving technology heavily depends on accurate 3D object detection since it produces input to safety critical downstream tasks such as prediction and navigation. Recent advances in this field is made by developing the refinement stage for voxel-based region proposal networks to better strike the balance between accuracy and efficiency. A popular approach among state-of-the-art frameworks is to divide proposals, or Region of Interest (ROI), into grids and extract feature for each grid location before synthesizing them to ROI feature. While achieving impressive performances, such an approach involves a number of hand crafted components (e.g. grid sampling, set abstraction) which requires expert knowledge to be tuned correctly. This paper takes a more data-driven approach to ROI feature extraction using the attention mechanism. Specifically, points inside a ROI are positionally encoded to incorporate ROI 's geometry. The resulted position encoding and their features are transformed into ROI feature via vector attention. Unlike the original multi-head attention, vector attention assign different weights to different channels within a point feature, thus being able to capture a more sophisticated relation between pooled points and ROI. Experiments on KITTI \textit{validation} set show that our method achieves competitive performance of 84.84 AP for class Car at Moderate difficulty while having the least parameters compared to closely related methods and attaining a quasi-real time inference speed at 15 FPS on NVIDIA V100 GPU. The code will be released.
Sample Selection with Deadline Control for Efficient Federated Learning on Heterogeneous Clients
Jan 05, 2022



Federated Learning (FL) trains a machine learning model on distributed clients without exposing individual data. Unlike centralized training that is usually based on carefully-organized data, FL deals with on-device data that are often unfiltered and imbalanced. As a result, conventional FL training protocol that treats all data equally leads to a waste of local computational resources and slows down the global learning process. To this end, we propose FedBalancer, a systematic FL framework that actively selects clients' training samples. Our sample selection strategy prioritizes more "informative" data while respecting privacy and computational capabilities of clients. To better utilize the sample selection to speed up global training, we further introduce an adaptive deadline control scheme that predicts the optimal deadline for each round with varying client train data. Compared with existing FL algorithms with deadline configuration methods, our evaluation on five datasets from three different domains shows that FedBalancer improves the time-to-accuracy performance by 1.22~4.62x while improving the model accuracy by 1.0~3.3%. We also show that FedBalancer is readily applicable to other FL approaches by demonstrating that FedBalancer improves the convergence speed and accuracy when operating jointly with three different FL algorithms.