 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
InceptionTime: Finding AlexNet for Time Series Classification
Sep 13, 2019
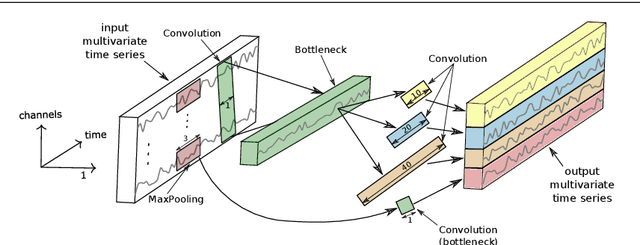
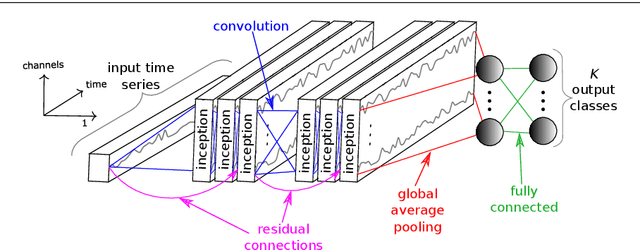
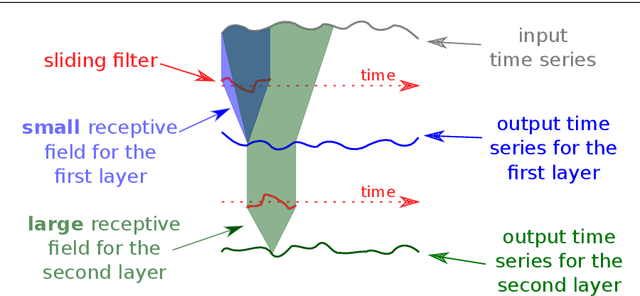
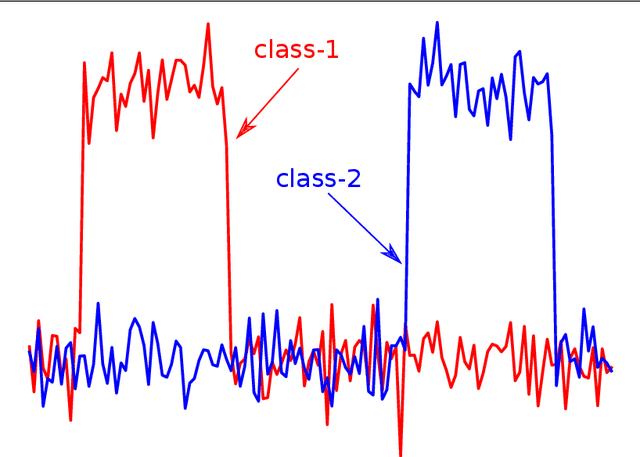
Time series classification (TSC) is the area of machine learning interested in learning how to assign labels to time series. The last few decades of work in this area have led to significant progress in the accuracy of classifiers, with the state of the art now represented by the HIVE-COTE algorithm. While extremely accurate, HIVE-COTE is infeasible to use in many applications because of its very high training time complexity in O(N^2*T^4) for a dataset with N time series of length T. For example, it takes HIVE-COTE more than 72,000s to learn from a small dataset with N=700 time series of short length T=46. Deep learning, on the other hand, has now received enormous attention because of its high scalability and state-of-the-art accuracy in computer vision and natural language processing tasks. Deep learning for TSC has only very recently started to be explored, with the first few architectures developed over the last 3 years only. The accuracy of deep learning for TSC has been raised to a competitive level, but has not quite reached the level of HIVE-COTE. This is what this paper achieves: outperforming HIVE-COTE's accuracy together with scalability. We take an important step towards finding the AlexNet network for TSC by presenting InceptionTime---an ensemble of deep Convolutional Neural Network (CNN) models, inspired by the Inception-v4 architecture. Our experiments show that InceptionTime slightly outperforms HIVE-COTE with a win/draw/loss on the UCR archive of 40/6/39. Not only is InceptionTime more accurate, but it is much faster: InceptionTime learns from that same dataset with 700 time series in 2,300s but can also learn from a dataset with 8M time series in 13 hours, a quantity of data that is fully out of reach of HIVE-COTE.
Integrated Sensing and Communication with mmWave Massive MIMO: A Compressed Sampling Perspective
Jan 15, 2022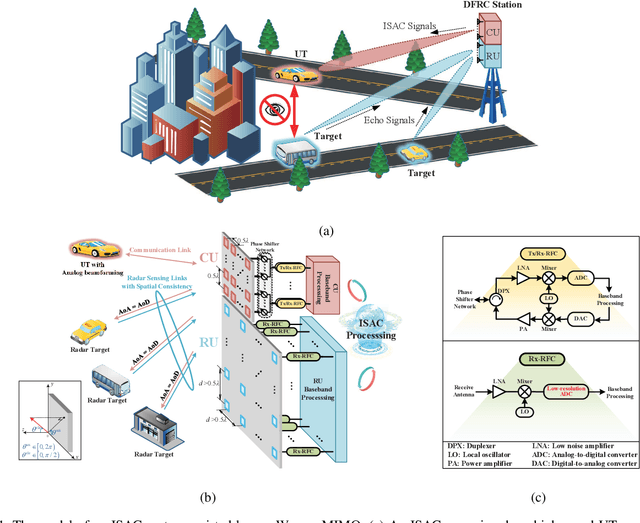
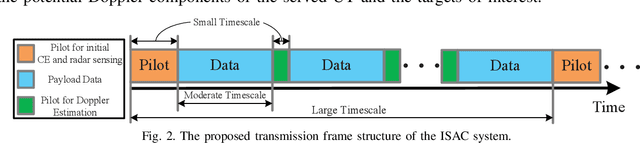
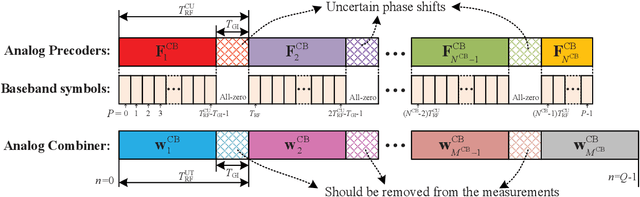
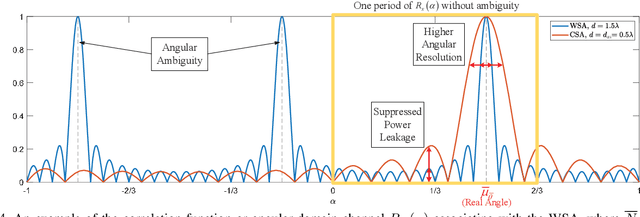
Integrated sensing and communication (ISAC) has opened up numerous game-changing opportunities for realizing future wireless systems. In this paper, we propose an ISAC processing framework relying on millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) systems. Specifically, we provide a compressed sampling (CS) perspective to facilitate ISAC processing, which can not only recover the large-scale channel state information or/and radar imaging information, but also significantly reduce pilot overhead. First, an energy-efficient widely spaced array (WSA) architecture is tailored for the radar receiver, which enhances the angular resolution of radar sensing at the cost of angular ambiguity. Then, we propose an ISAC frame structure for time-variant ISAC systems considering different timescales. The pilot waveforms are judiciously designed by taking into account both CS theories and hardware constraints. Next, we design the dedicated dictionary for WSA that serves as a building block for formulating the ISAC processing as sparse signal recovery problems. The orthogonal matching pursuit with support refinement (OMP-SR) algorithm is proposed to effectively solve the problems in the existence of the angular ambiguity. We also provide a framework for estimating and compensating the Doppler frequencies during payload data transmission to guarantee communication performances. Simulation results demonstrate the good performances of both communications and radar sensing under the proposed ISAC framework.
Egocentric Deep Multi-Channel Audio-Visual Active Speaker Localization
Jan 06, 2022
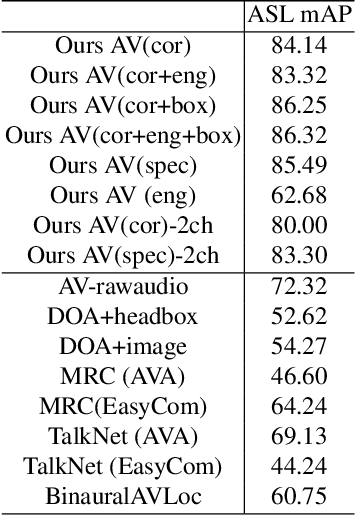
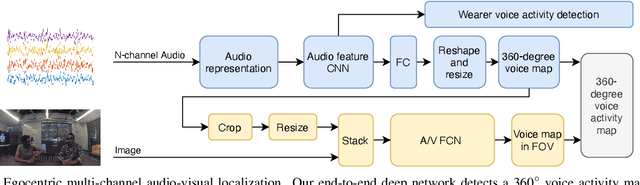
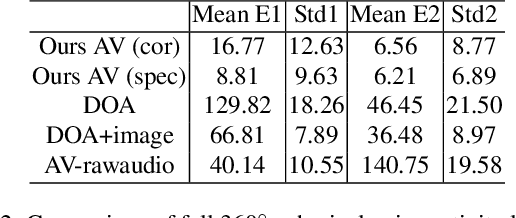
Augmented reality devices have the potential to enhance human perception and enable other assistive functionalities in complex conversational environments. Effectively capturing the audio-visual context necessary for understanding these social interactions first requires detecting and localizing the voice activities of the device wearer and the surrounding people. These tasks are challenging due to their egocentric nature: the wearer's head motion may cause motion blur, surrounding people may appear in difficult viewing angles, and there may be occlusions, visual clutter, audio noise, and bad lighting. Under these conditions, previous state-of-the-art active speaker detection methods do not give satisfactory results. Instead, we tackle the problem from a new setting using both video and multi-channel microphone array audio. We propose a novel end-to-end deep learning approach that is able to give robust voice activity detection and localization results. In contrast to previous methods, our method localizes active speakers from all possible directions on the sphere, even outside the camera's field of view, while simultaneously detecting the device wearer's own voice activity. Our experiments show that the proposed method gives superior results, can run in real time, and is robust against noise and clutter.
A Deep Structural Model for Analyzing Correlated Multivariate Time Series
Jan 02, 2020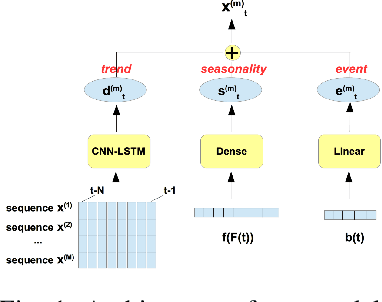
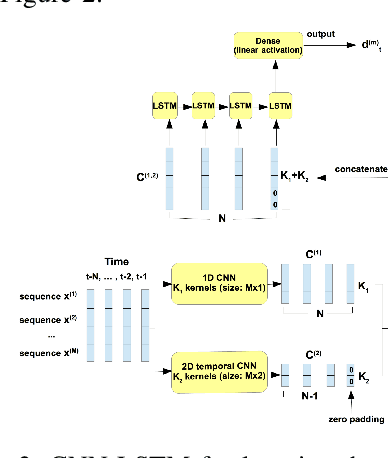
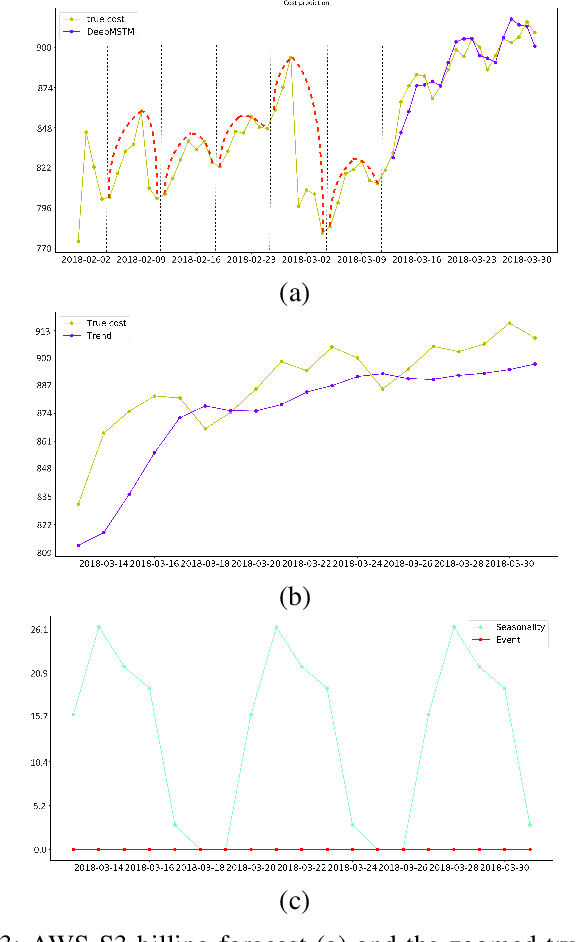
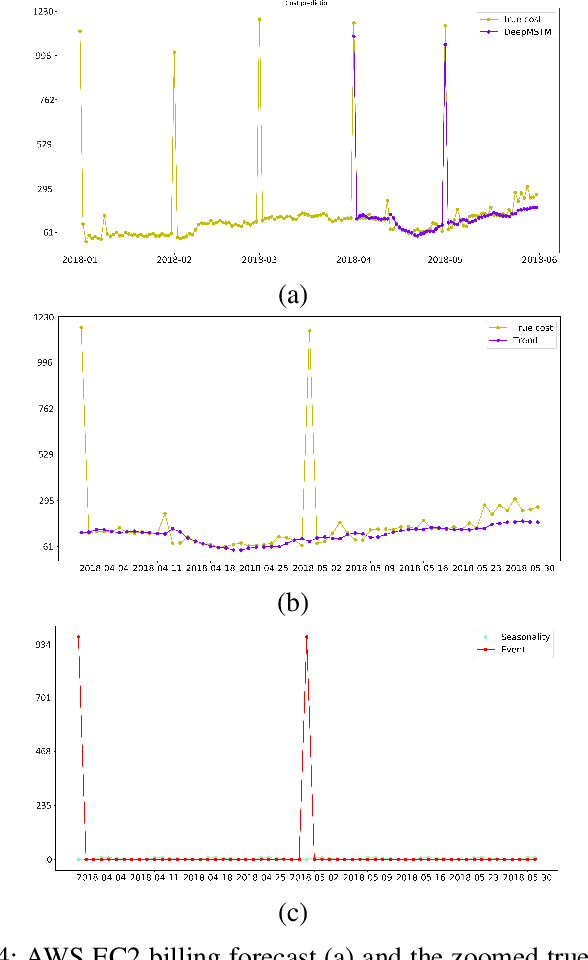
Multivariate time series are routinely encountered in real-world applications, and in many cases, these time series are strongly correlated. In this paper, we present a deep learning structural time series model which can (i) handle correlated multivariate time series input, and (ii) forecast the targeted temporal sequence by explicitly learning/extracting the trend, seasonality, and event components. The trend is learned via a 1D and 2D temporal CNN and LSTM hierarchical neural net. The CNN-LSTM architecture can (i) seamlessly leverage the dependency among multiple correlated time series in a natural way, (ii) extract the weighted differencing feature for better trend learning, and (iii) memorize the long-term sequential pattern. The seasonality component is approximated via a non-liner function of a set of Fourier terms, and the event components are learned by a simple linear function of regressor encoding the event dates. We compare our model with several state-of-the-art methods through a comprehensive set of experiments on a variety of time series data sets, such as forecasts of Amazon AWS Simple Storage Service (S3) and Elastic Compute Cloud (EC2) billings, and the closing prices for corporate stocks in the same category.
Multi-query Video Retrieval
Jan 10, 2022
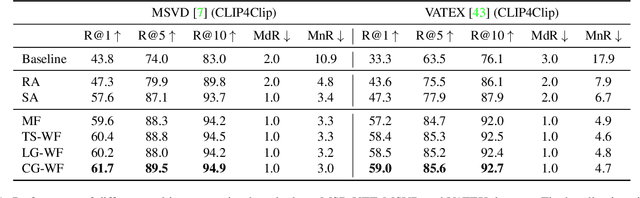
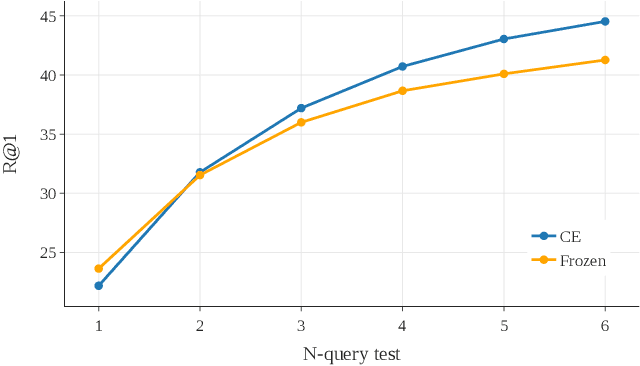
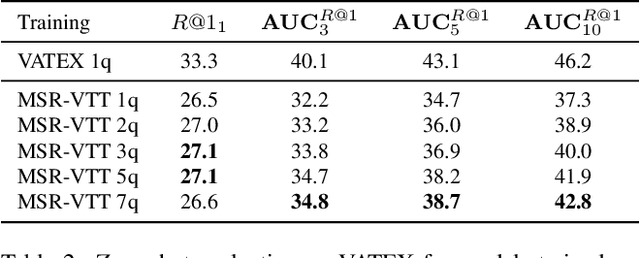
Retrieving target videos based on text descriptions is a task of great practical value and has received increasing attention over the past few years. In this paper, we focus on the less-studied setting of multi-query video retrieval, where multiple queries are provided to the model for searching over the video archive. We first show that the multi-query retrieval task is more pragmatic and representative of real-world use cases and better evaluates retrieval capabilities of current models, thereby deserving of further investigation alongside the more prevalent single-query retrieval setup. We then propose several new methods for leveraging multiple queries at training time to improve over simply combining similarity outputs of multiple queries from regular single-query trained models. Our models consistently outperform several competitive baselines over three different datasets. For instance, Recall@1 can be improved by 4.7 points on MSR-VTT, 4.1 points on MSVD and 11.7 points on VATEX over a strong baseline built on the state-of-the-art CLIP4Clip model. We believe further modeling efforts will bring new insights to this direction and spark new systems that perform better in real-world video retrieval applications. Code is available at https://github.com/princetonvisualai/MQVR.
Towards Trustworthy Cross-patient Model Development
Dec 20, 2021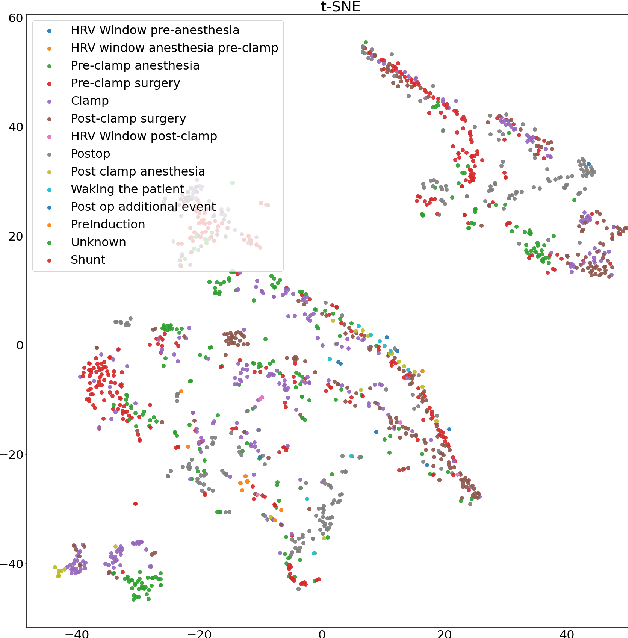
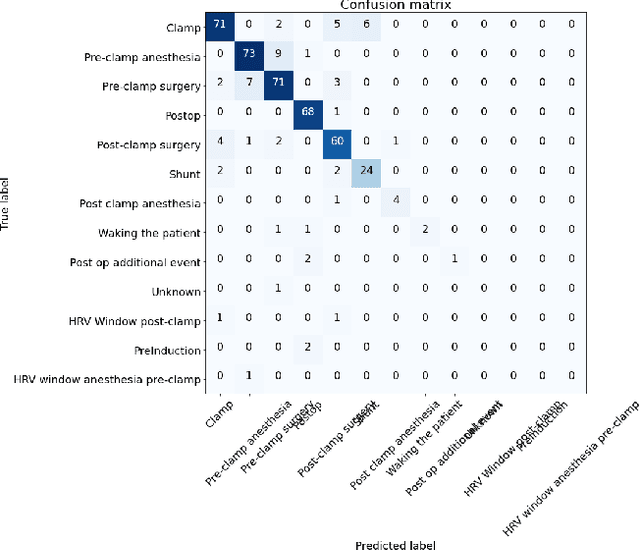
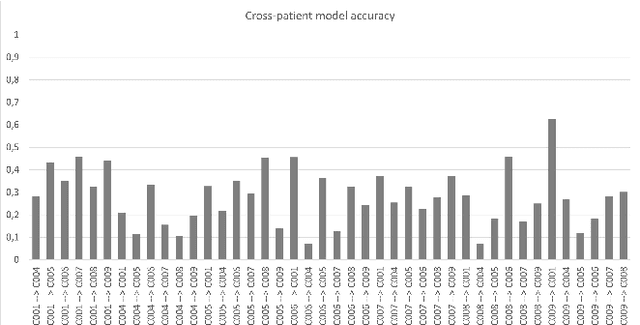
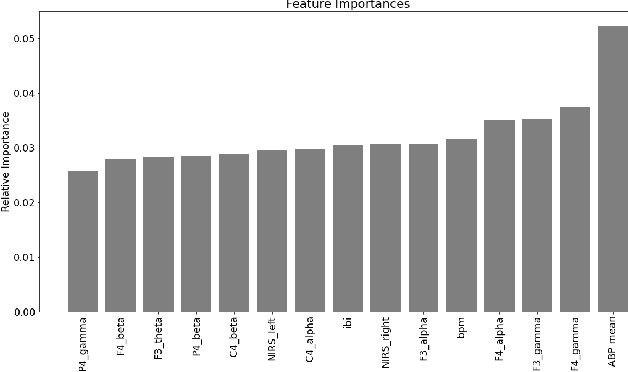
Machine learning is used in medicine to support physicians in examination, diagnosis, and predicting outcomes. One of the most dynamic area is the usage of patient generated health data from intensive care units. The goal of this paper is to demonstrate how we advance cross-patient ML model development by combining the patient's demographics data with their physiological data. We used a population of patients undergoing Carotid Enderarterectomy (CEA), where we studied differences in model performance and explainability when trained for all patients and one patient at a time. The results show that patients' demographics has a large impact on the performance and explainability and thus trustworthiness. We conclude that we can increase trust in ML models in a cross-patient context, by careful selection of models and patients based on their demographics and the surgical procedure.
Unadjusted Langevin algorithm for sampling a mixture of weakly smooth potentials
Dec 17, 2021Discretization of continuous-time diffusion processes is a widely recognized method for sampling. However, it seems to be a considerable restriction when the potentials are often required to be smooth (gradient Lipschitz). This paper studies the problem of sampling through Euler discretization, where the potential function is assumed to be a mixture of weakly smooth distributions and satisfies weakly dissipative. We establish the convergence in Kullback-Leibler (KL) divergence with the number of iterations to reach $\epsilon$-neighborhood of a target distribution in only polynomial dependence on the dimension. We relax the degenerated convex at infinity conditions of \citet{erdogdu2020convergence} and prove convergence guarantees under Poincar\'{e} inequality or non-strongly convex outside the ball. In addition, we also provide convergence in $L_{\beta}$-Wasserstein metric for the smoothing potential.
Investigating internal migration with network analysis and latent space representations: An application to Turkey
Jan 10, 2022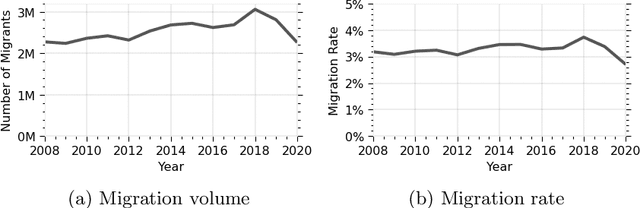
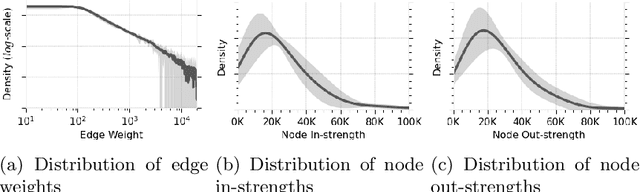
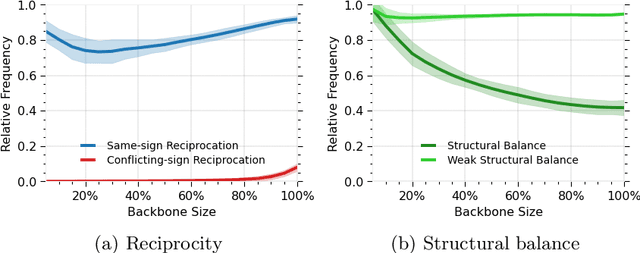

Human migration patterns influence the redistribution of population characteristics over the geography and since such distributions are closely related to social and economic outcomes, investigating the structure and dynamics of internal migration plays a crucial role in understanding and designing policies for such systems. We provide an in-depth investigation into the structure and dynamics of the internal migration in Turkey from 2008 to 2020. We identify a set of classical migration laws and examine them via various methods for signed network analysis, ego network analysis, representation learning, temporal stability analysis, community detection, and network visualization. The findings show that, in line with the classical migration laws, most migration links are geographically bounded with several exceptions involving cities with large economic activity, major migration flows are countered with migration flows in the opposite direction, there are well-defined migration routes, and the migration system is generally stable over the investigated period. Apart from these general results, we also provide unique and specific insights into Turkey. Overall, the novel toolset we employ for the first time in the literature allows the investigation of selected migration laws from a complex networks perspective and sheds light on future migration research on different geographies.
Depth Uncertainty Networks for Active Learning
Dec 13, 2021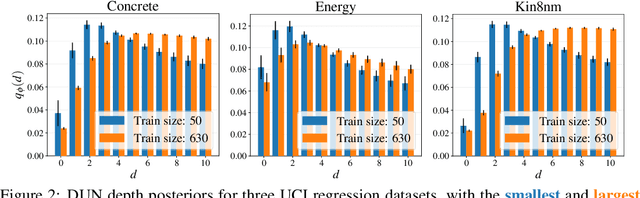
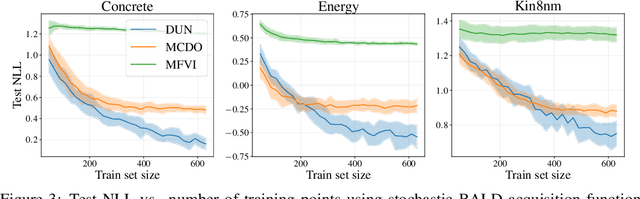
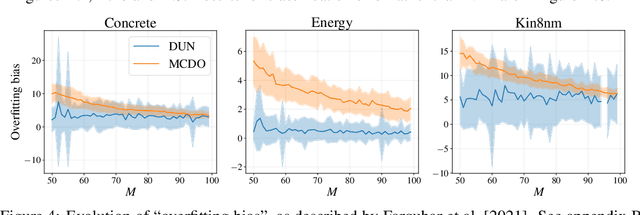
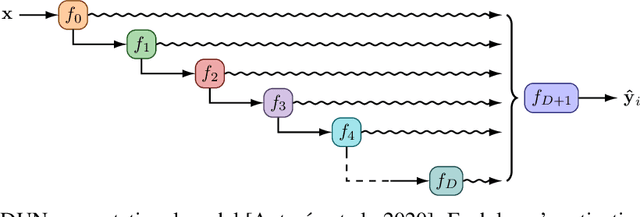
In active learning, the size and complexity of the training dataset changes over time. Simple models that are well specified by the amount of data available at the start of active learning might suffer from bias as more points are actively sampled. Flexible models that might be well suited to the full dataset can suffer from overfitting towards the start of active learning. We tackle this problem using Depth Uncertainty Networks (DUNs), a BNN variant in which the depth of the network, and thus its complexity, is inferred. We find that DUNs outperform other BNN variants on several active learning tasks. Importantly, we show that on the tasks in which DUNs perform best they present notably less overfitting than baselines.
A unified algorithm framework for mean-variance optimization in discounted Markov decision processes
Jan 15, 2022This paper studies the risk-averse mean-variance optimization in infinite-horizon discounted Markov decision processes (MDPs). The involved variance metric concerns reward variability during the whole process, and future deviations are discounted to their present values. This discounted mean-variance optimization yields a reward function dependent on a discounted mean, and this dependency renders traditional dynamic programming methods inapplicable since it suppresses a crucial property -- time consistency. To deal with this unorthodox problem, we introduce a pseudo mean to transform the untreatable MDP to a standard one with a redefined reward function in standard form and derive a discounted mean-variance performance difference formula. With the pseudo mean, we propose a unified algorithm framework with a bilevel optimization structure for the discounted mean-variance optimization. The framework unifies a variety of algorithms for several variance-related problems including, but not limited to, risk-averse variance and mean-variance optimizations in discounted and average MDPs. Furthermore, the convergence analyses missing from the literature can be complemented with the proposed framework as well. Taking the value iteration as an example, we develop a discounted mean-variance value iteration algorithm and prove its convergence to a local optimum with the aid of a Bellman local-optimality equation. Finally, we conduct a numerical experiment on portfolio management to validate the proposed algorithm.