 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vision in adverse weather: Augmentation using CycleGANs with various object detectors for robust perception in autonomous racing
Jan 10, 2022

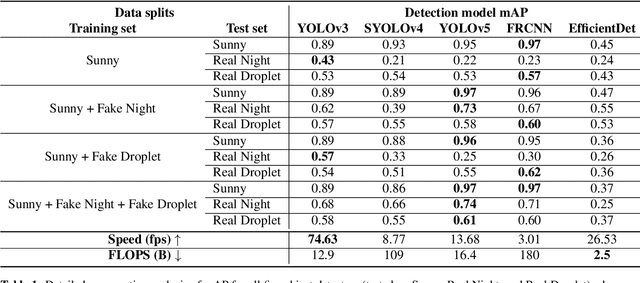
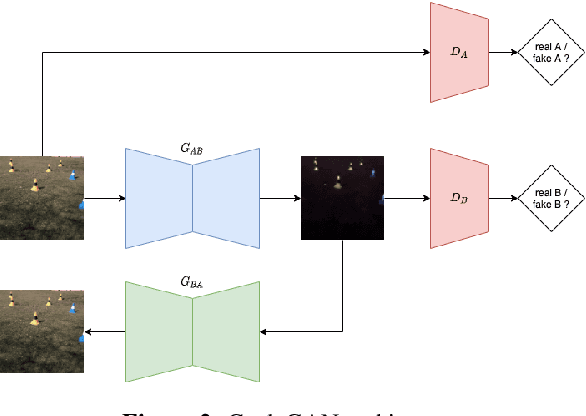

In an autonomous driving system, perception - identification of features and objects from the environment - is crucial. In autonomous racing, high speeds and small margins demand rapid and accurate detection systems. During the race, the weather can change abruptly, causing significant degradation in perception, resulting in ineffective manoeuvres. In order to improve detection in adverse weather, deep-learning-based models typically require extensive datasets captured in such conditions - the collection of which is a tedious, laborious, and costly process. However, recent developments in CycleGAN architectures allow the synthesis of highly realistic scenes in multiple weather conditions. To this end, we introduce an approach of using synthesised adverse condition datasets in autonomous racing (generated using CycleGAN) to improve the performance of four out of five state-of-the-art detectors by an average of 42.7 and 4.4 mAP percentage points in the presence of night-time conditions and droplets, respectively. Furthermore, we present a comparative analysis of five object detectors - identifying the optimal pairing of detector and training data for use during autonomous racing in challenging conditions.
Time-series Change Point Detection with Self-Supervised Contrastive Predictive Coding
Dec 01, 2020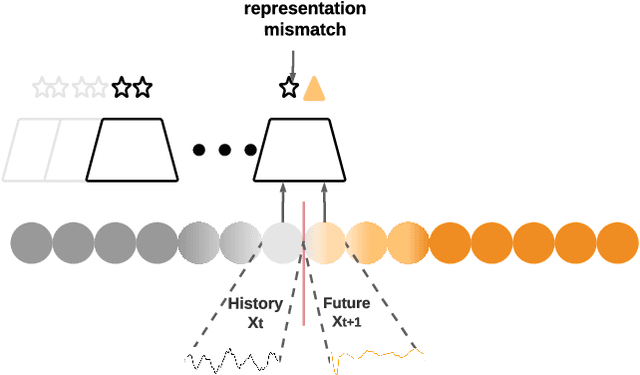
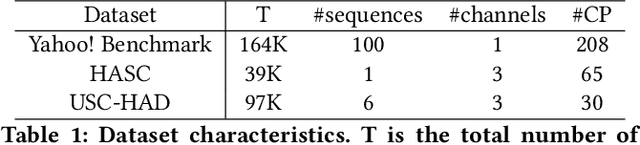
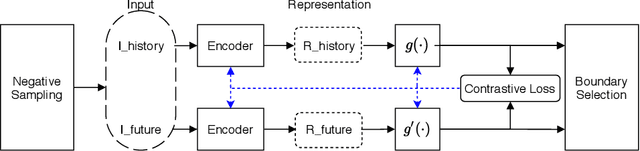
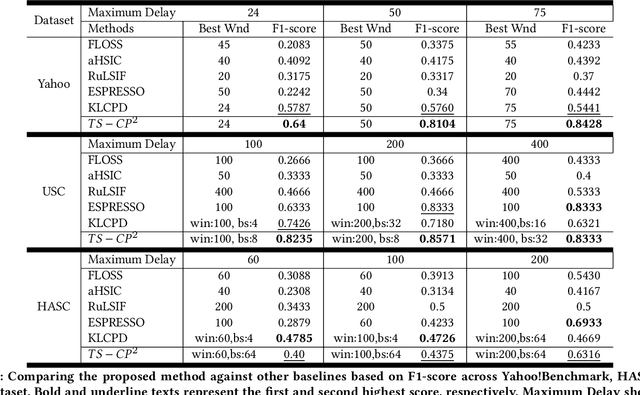
Change Point Detection techniques aim to capture changes in trends and sequences in time-series data to describe the underlying behaviour of the system. Detecting changes and anomalies in the web services, the trend of applications usage can provide valuable insight towards the system, however, many existing approaches are done in a supervised manner, requiring well-labelled data. As the amount of data produced and captured by sensors are growing rapidly, it is getting harder and even impossible to annotate the data. Therefore, coming up with a self-supervised solution is a necessity these days. In this work, we propose TSCP2 a novel self-supervised technique for temporal change point detection, based on representation learning with Temporal Convolutional Network (TCN). To the best of our knowledge, our proposed method is the first method which employs Contrastive Learning for prediction with the aim change point detection. Through extensive evaluations, we demonstrate that our method outperforms multiple state-of-the-art change point detection and anomaly detection baselines, including those adopting either unsupervised or semi-supervised approach. TSCP2 is shown to improve both non-Deep learning- and Deep learning-based methods by 0.28 and 0.12 in terms of average F1-score across three datasets.
Selective Sampling for Online Best-arm Identification
Nov 02, 2021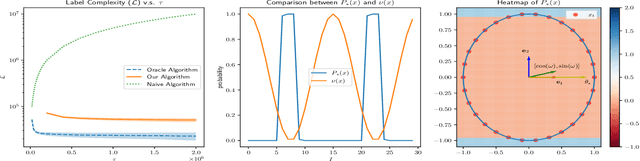
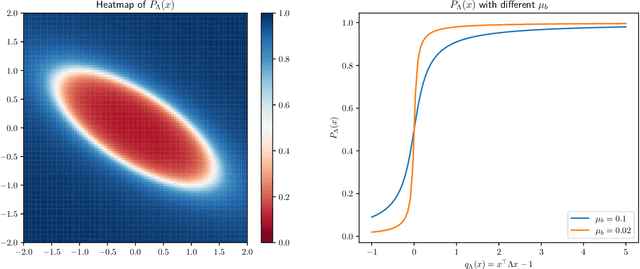
This work considers the problem of selective-sampling for best-arm identification. Given a set of potential options $\mathcal{Z}\subset\mathbb{R}^d$, a learner aims to compute with probability greater than $1-\delta$, $\arg\max_{z\in \mathcal{Z}} z^{\top}\theta_{\ast}$ where $\theta_{\ast}$ is unknown. At each time step, a potential measurement $x_t\in \mathcal{X}\subset\mathbb{R}^d$ is drawn IID and the learner can either choose to take the measurement, in which case they observe a noisy measurement of $x^{\top}\theta_{\ast}$, or to abstain from taking the measurement and wait for a potentially more informative point to arrive in the stream. Hence the learner faces a fundamental trade-off between the number of labeled samples they take and when they have collected enough evidence to declare the best arm and stop sampling. The main results of this work precisely characterize this trade-off between labeled samples and stopping time and provide an algorithm that nearly-optimally achieves the minimal label complexity given a desired stopping time. In addition, we show that the optimal decision rule has a simple geometric form based on deciding whether a point is in an ellipse or not. Finally, our framework is general enough to capture binary classification improving upon previous works.
Managing dataset shift by adversarial validation for credit scoring
Dec 19, 2021

Dataset shift is common in credit scoring scenarios, and the inconsistency between the distribution of training data and the data that actually needs to be predicted is likely to cause poor model performance. However, most of the current studies do not take this into account, and they directly mix data from different time periods when training the models. This brings about two problems. Firstly, there is a risk of data leakage, i.e., using future data to predict the past. This can result in inflated results in offline validation, but unsatisfactory results in practical applications. Secondly, the macroeconomic environment and risk control strategies are likely to be different in different time periods, and the behavior patterns of borrowers may also change. The model trained with past data may not be applicable to the recent stage. Therefore, we propose a method based on adversarial validation to alleviate the dataset shift problem in credit scoring scenarios. In this method, partial training set samples with the closest distribution to the predicted data are selected for cross-validation by adversarial validation to ensure the generalization performance of the trained model on the predicted samples. In addition, through a simple splicing method, samples in the training data that are inconsistent with the test data distribution are also involved in the training process of cross-validation, which makes full use of all the data and further improves the model performance. To verify the effectiveness of the proposed method, comparative experiments with several other data split methods are conducted with the data provided by Lending Club. The experimental results demonstrate the importance of dataset shift in the field of credit scoring and the superiority of the proposed method.
Cardiac and respiratory motion extraction for MRI using Pilot Tone-a patient study
Jan 31, 2022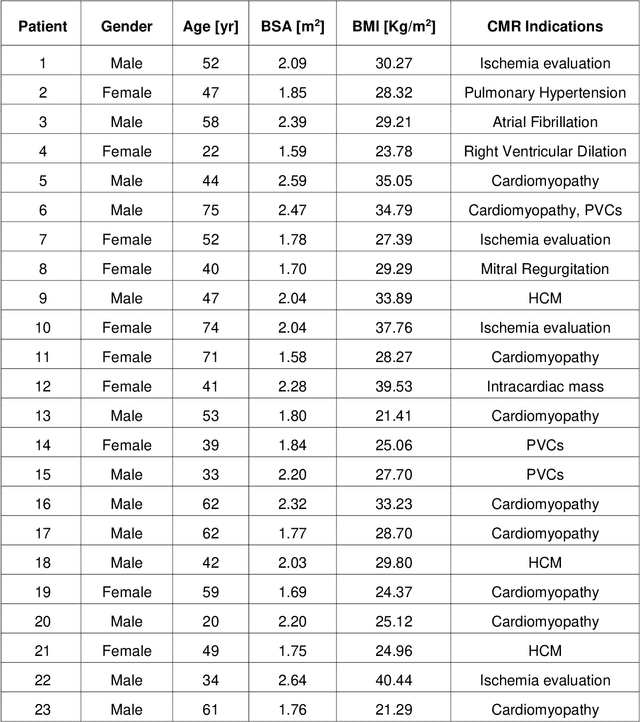
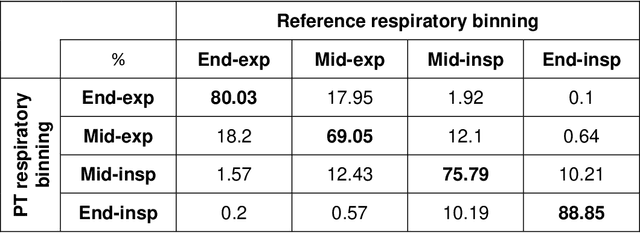
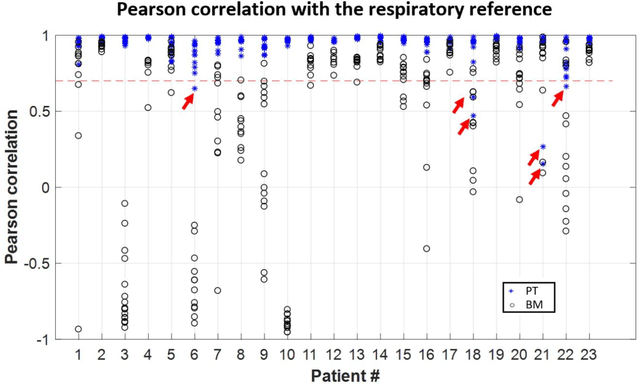
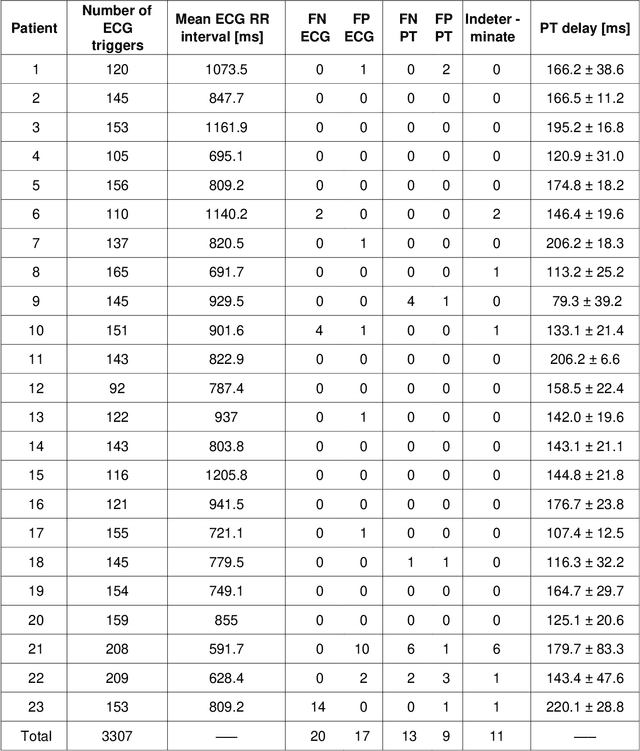
Background:The Pilot Tone (PT) technology allows contactless monitoring of physiological motion during the MRI scan. Several studies have shown that both respiratory and cardiac motion can be extracted from the PT signal successfully. However, most of these studies were performed in healthy volunteers. In this study, we seek to evaluate the accuracy and reliability of the cardiac and respiratory signals extracted from PT in patients clinically referred for cardiovascular MRI (CMR). Methods: Twenty-three patients were included in this study, each scanned under free-breathing conditions using a balanced steady-state free-precession real-time (RT) cine sequence on a 1.5T scanner. The PT signal was generated by a built-in PT transmitter integrated within the body array coil. For comparison, ECG and BioMatrix (BM) respiratory sensor signals were also synchronously recorded. To assess the performances of PT, ECG, and BM, cardiac and respiratory signals extracted from the RT cine images were used as the ground truth. Results: The respiratory motion extracted from PT correlated positively with the image-derived respiratory signal in all cases and showed a stronger correlation (absolute coefficient: 0.95-0.09) than BM (0.72-0.24). For the cardiac signal, the precision of PT-based triggers (standard deviation of PT trigger locations relative to ECG triggers) ranged from 6.6 to 81.2 ms (median 19.5 ms). Overall, the performance of PT-based trigger extraction was comparable to that of ECG. Conclusions: This study demonstrates the potential of PT to monitor both respiratory and cardiac motion in patients clinically referred for CMR.
Vibration Fault Diagnosis in Wind Turbines based on Automated Feature Learning
Jan 31, 2022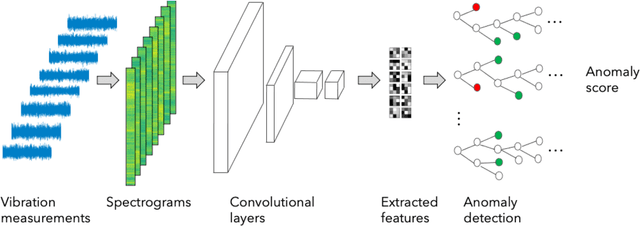

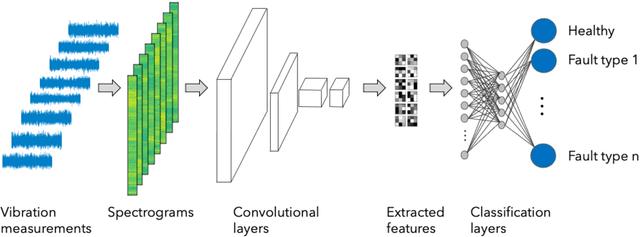
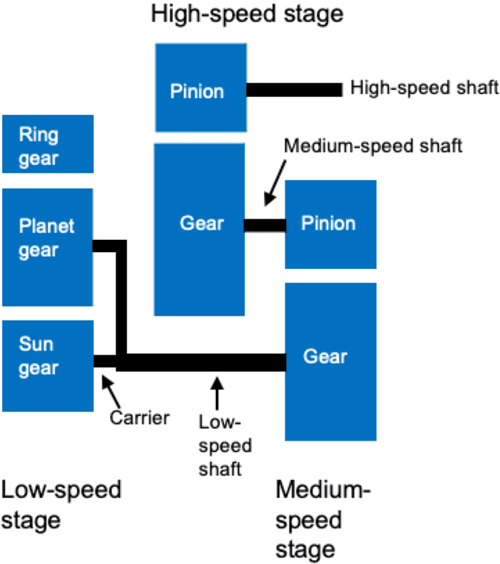
A growing number of wind turbines are equipped with vibration measurement systems to enable a close monitoring and early detection of developing fault conditions. The vibration measurements are analyzed to continuously assess the component health and prevent failures that can result in downtimes. This study focuses on gearbox monitoring but is applicable also to other subsystems. The current state-of-the-art gearbox fault diagnosis algorithms rely on statistical or machine learning methods based on fault signatures that have been defined by human analysts. This has multiple disadvantages. Defining the fault signatures by human analysts is a time-intensive process that requires highly detailed knowledge of the gearbox composition. This effort needs to be repeated for every new turbine, so it does not scale well with the increasing number of monitored turbines, especially in fast growing portfolios. Moreover, fault signatures defined by human analysts can result in biased and imprecise decision boundaries that lead to imprecise and uncertain fault diagnosis decisions. We present a novel accurate fault diagnosis method for vibration-monitored wind turbine components that overcomes these disadvantages. Our approach combines autonomous data-driven learning of fault signatures and health state classification based on convolutional neural networks and isolation forests. We demonstrate its performance with vibration measurements from two wind turbine gearboxes. Unlike the state-of-the-art methods, our approach does not require gearbox-type specific diagnosis expertise and is not restricted to predefined frequencies or spectral ranges but can monitor the full spectrum at once.
Hybrid Reinforcement Learning-Based Eco-Driving Strategy for Connected and Automated Vehicles at Signalized Intersections
Jan 28, 2022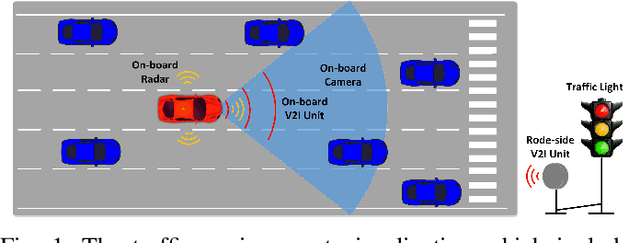
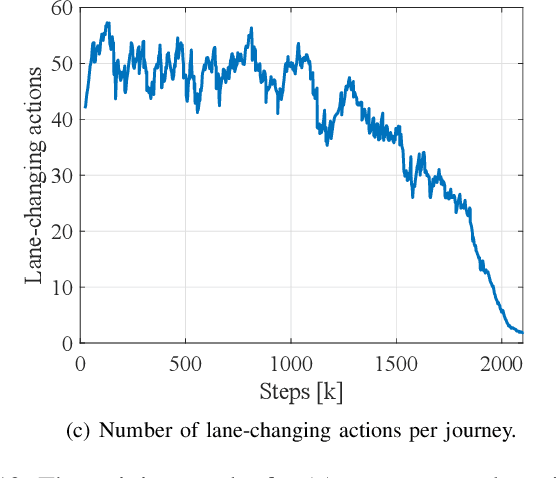
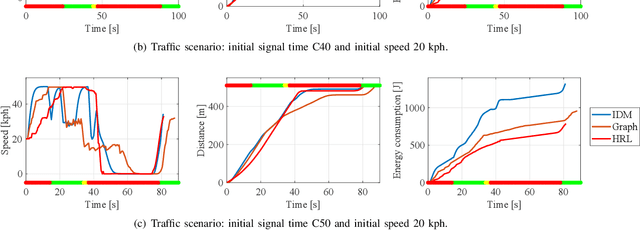
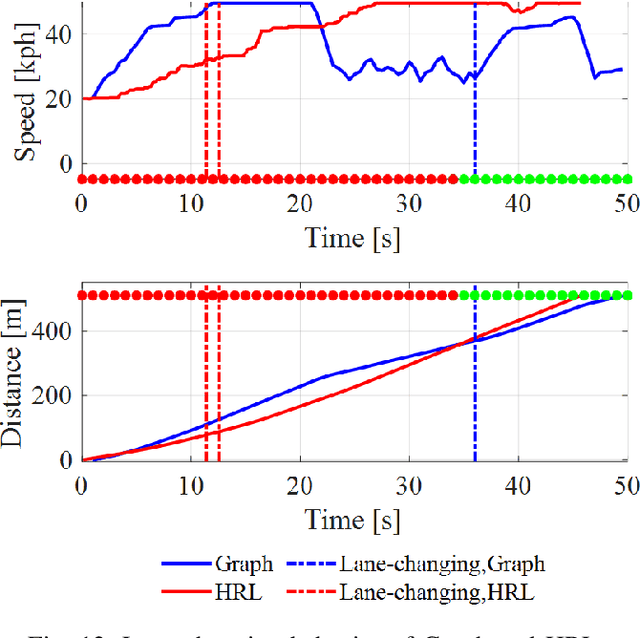
Taking advantage of both vehicle-to-everything (V2X) communication and automated driving technology, connected and automated vehicles are quickly becoming one of the transformative solutions to many transportation problems. However, in a mixed traffic environment at signalized intersections, it is still a challenging task to improve overall throughput and energy efficiency considering the complexity and uncertainty in the traffic system. In this study, we proposed a hybrid reinforcement learning (HRL) framework which combines the rule-based strategy and the deep reinforcement learning (deep RL) to support connected eco-driving at signalized intersections in mixed traffic. Vision-perceptive methods are integrated with vehicle-to-infrastructure (V2I) communications to achieve higher mobility and energy efficiency in mixed connected traffic. The HRL framework has three components: a rule-based driving manager that operates the collaboration between the rule-based policies and the RL policy; a multi-stream neural network that extracts the hidden features of vision and V2I information; and a deep RL-based policy network that generate both longitudinal and lateral eco-driving actions. In order to evaluate our approach, we developed a Unity-based simulator and designed a mixed-traffic intersection scenario. Moreover, several baselines were implemented to compare with our new design, and numerical experiments were conducted to test the performance of the HRL model. The experiments show that our HRL method can reduce energy consumption by 12.70% and save 11.75% travel time when compared with a state-of-the-art model-based Eco-Driving approach.
Bayesian Learning via Neural Schrödinger-Föllmer Flows
Nov 23, 2021
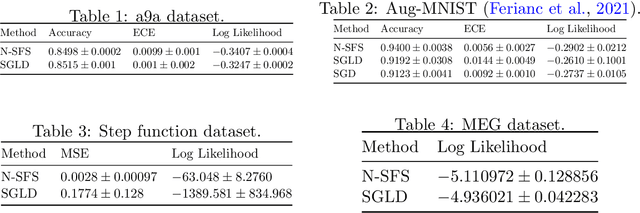
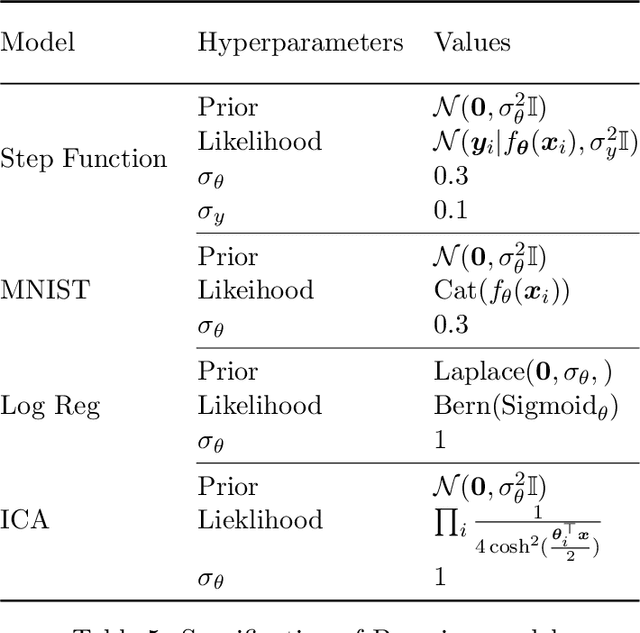
In this work we explore a new framework for approximate Bayesian inference in large datasets based on stochastic control. We advocate stochastic control as a finite time alternative to popular steady-state methods such as stochastic gradient Langevin dynamics (SGLD). Furthermore, we discuss and adapt the existing theoretical guarantees of this framework and establish connections to already existing VI routines in SDE-based models.
A Machine Learning Approach for Material Type Logging and Chemical Assaying from Autonomous Measure-While-Drilling (MWD) Data
Feb 07, 2022

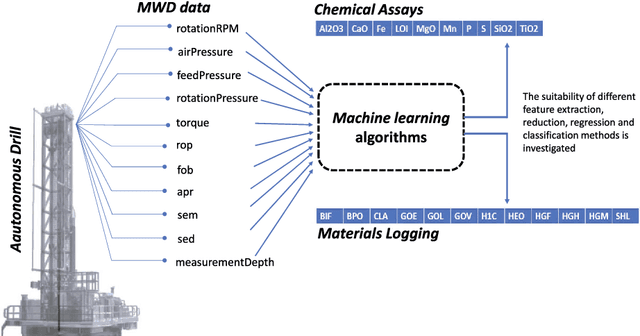
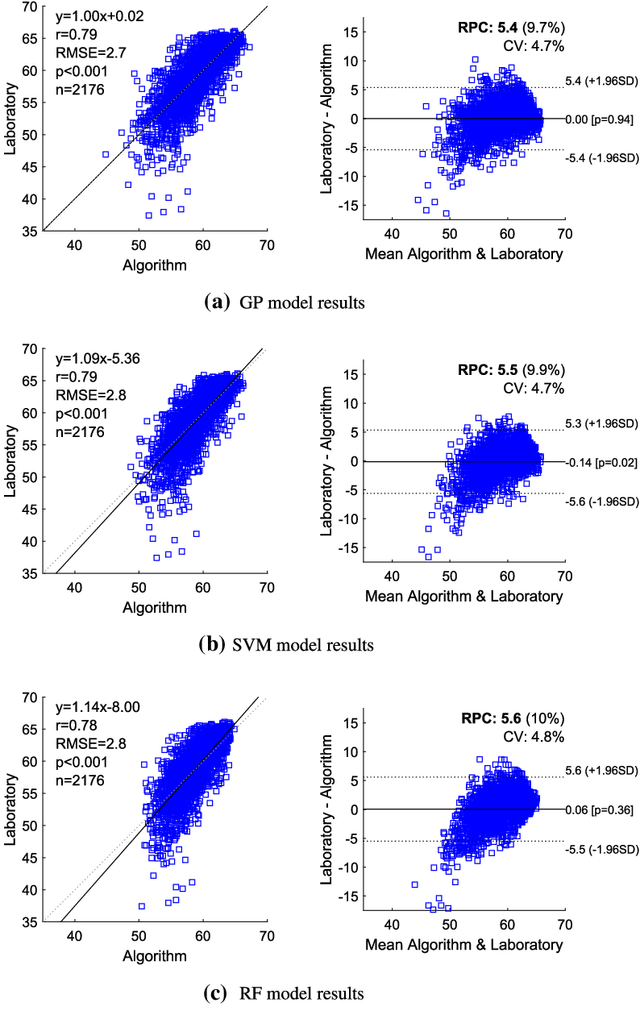
Understanding the structure and mineralogical composition of a region is an essential step in mining, both during exploration (before mining) and in the mining process. During exploration, sparse but high-quality data are gathered to assess the overall orebody. During the mining process, boundary positions and material properties are refined as the mine progresses. This refinement is facilitated through drilling, material logging, and chemical assaying. Material type logging suffers from a high degree of variability due to factors such as the diversity in mineralization and geology, the subjective nature of human measurement even by experts, and human error in manually recording results. While laboratory-based chemical assaying is much more precise, it is time-consuming and costly and does not always capture or correlate boundary positions between all material types. This leads to significant challenges and financial implications for the industry, as the accuracy of production blasthole logging and assaying processes is essential for resource evaluation, planning, and execution of mine plans. To overcome these challenges, this work reports on a pilot study to automate the process of material logging and chemical assaying. A machine learning approach has been trained on features extracted from measurement-while-drilling (MWD) data, logged from autonomous drilling systems (ADS). MWD data facilitate the construction of profiles of physical drilling parameters as a function of hole depth. A hypothesis is formed to link these drilling parameters to the underlying mineral composition. The results of the pilot study discussed in this paper demonstrate the feasibility of this process, with correlation coefficients of up to 0.92 for chemical assays and 93% accuracy for material detection, depending on the material or assay type and their generalization across the different spatial regions.
* 29 pages, 19 figures, mathematical geosciences, Rio Tinto Centre for Mine Automation
Near-Optimal Algorithms for Linear Algebra in the Current Matrix Multiplication Time
Jul 16, 2021Currently, in the numerical linear algebra community, it is thought that to obtain nearly-optimal bounds for various problems such as rank computation, finding a maximal linearly independent subset of columns, regression, low rank approximation, maximum matching on general graphs and linear matroid union, one would need to resolve the main open question of Nelson and Nguyen (FOCS, 2013) regarding the logarithmic factors in the sketching dimension for existing constant factor approximation oblivious subspace embeddings. We show how to bypass this question using a refined sketching technique, and obtain optimal or nearly optimal bounds for these problems. A key technique we use is an explicit mapping of Indyk based on uncertainty principles and extractors, which after first applying known oblivious subspace embeddings, allows us to quickly spread out the mass of the vector so that sampling is now effective, and we avoid a logarithmic factor that is standard in the sketching dimension resulting from matrix Chernoff bounds. For the fundamental problems of rank computation and finding a linearly independent subset of columns, our algorithms improve Cheung, Kwok, and Lau (JACM, 2013) and are optimal to within a constant factor and a $\log\log(n)$-factor, respectively. Further, for constant factor regression and low rank approximation we give the first optimal algorithms, for the current matrix multiplication exponent.