 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Soundify: Matching Sound Effects to Video
Dec 17, 2021

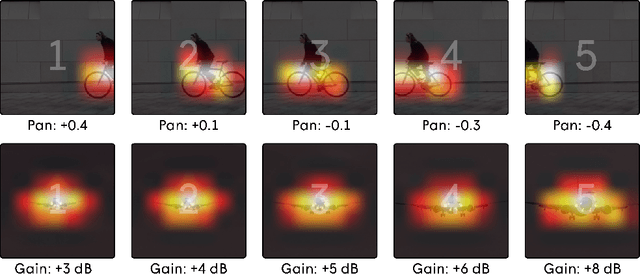
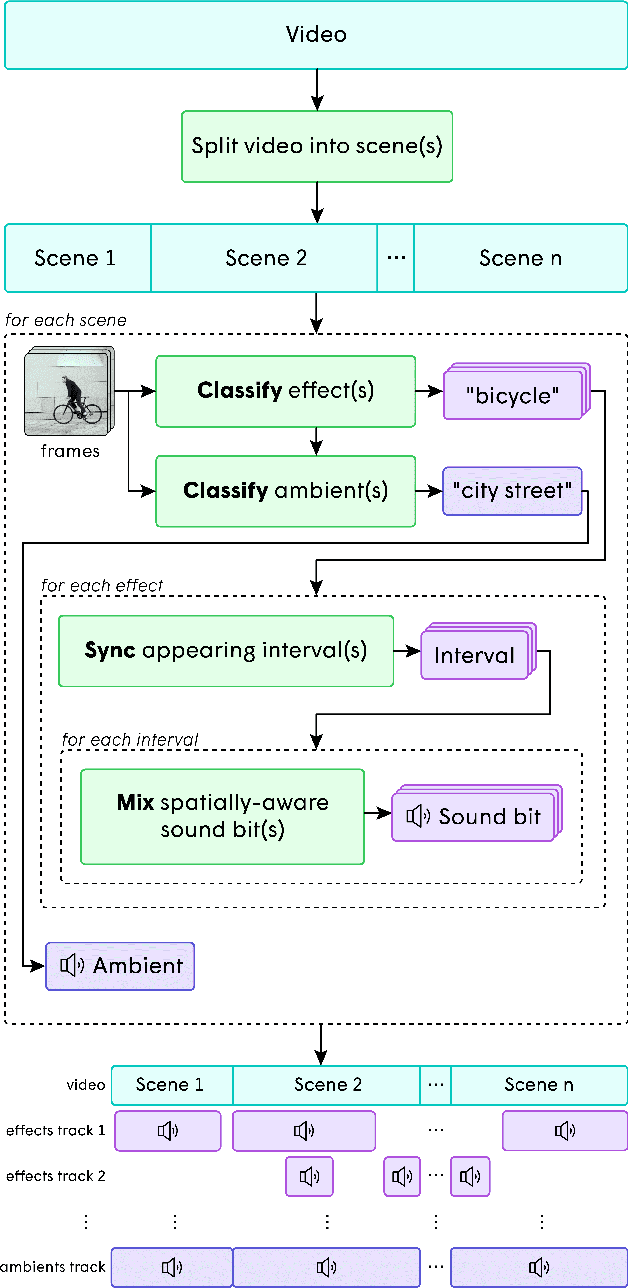
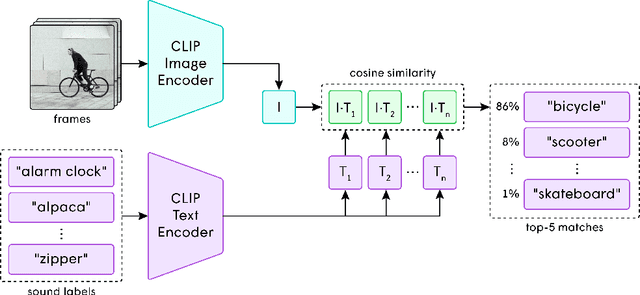
In the art of video editing, sound is really half the story. A skilled video editor overlays sounds, such as effects and ambients, over footage to add character to an object or immerse the viewer within a space. However, through formative interviews with professional video editors, we found that this process can be extremely tedious and time-consuming. We introduce Soundify, a system that matches sound effects to video. By leveraging labeled, studio-quality sound effects libraries and extending CLIP, a neural network with impressive zero-shot image classification capabilities, into a "zero-shot detector", we are able to produce high-quality results without resource-intensive correspondence learning or audio generation. We encourage you to have a look at, or better yet, have a listen to the results at https://chuanenlin.com/soundify.
TransVPR: Transformer-based place recognition with multi-level attention aggregation
Jan 06, 2022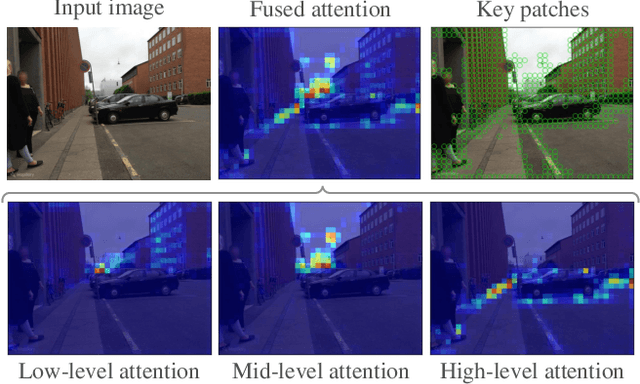

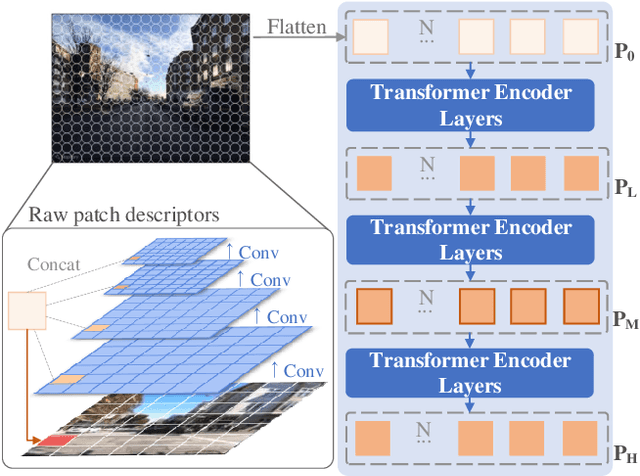
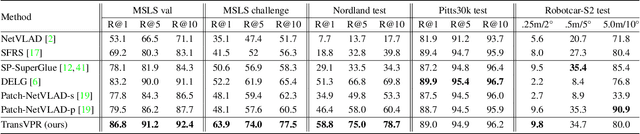
Visual place recognition is a challenging task for applications such as autonomous driving navigation and mobile robot localization. Distracting elements presenting in complex scenes often lead to deviations in the perception of visual place. To address this problem, it is crucial to integrate information from only task-relevant regions into image representations. In this paper, we introduce a novel holistic place recognition model, TransVPR, based on vision Transformers. It benefits from the desirable property of the self-attention operation in Transformers which can naturally aggregate task-relevant features. Attentions from multiple levels of the Transformer, which focus on different regions of interest, are further combined to generate a global image representation. In addition, the output tokens from Transformer layers filtered by the fused attention mask are considered as key-patch descriptors, which are used to perform spatial matching to re-rank the candidates retrieved by the global image features. The whole model allows end-to-end training with a single objective and image-level supervision. TransVPR achieves state-of-the-art performance on several real-world benchmarks while maintaining low computational time and storage requirements.
Fast TreeSHAP: Accelerating SHAP Value Computation for Trees
Sep 20, 2021
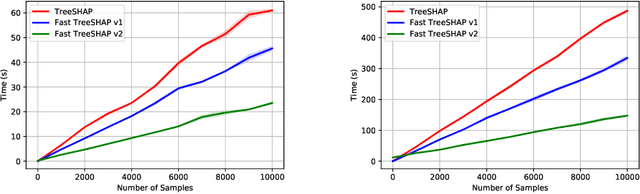
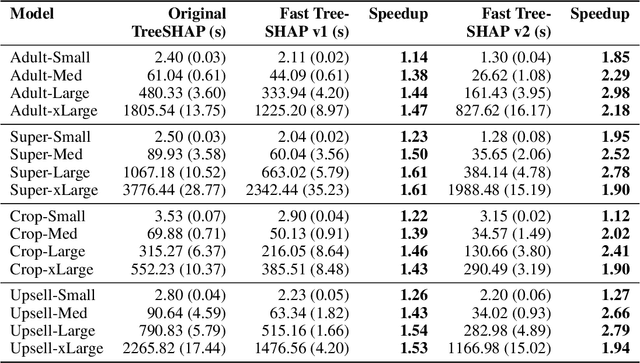
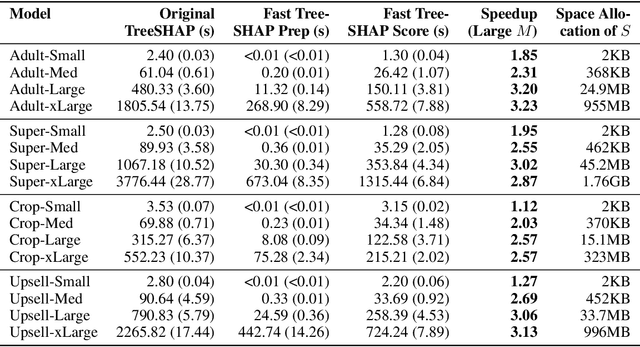
SHAP (SHapley Additive exPlanation) values are one of the leading tools for interpreting machine learning models, with strong theoretical guarantees (consistency, local accuracy) and a wide availability of implementations and use cases. Even though computing SHAP values takes exponential time in general, TreeSHAP takes polynomial time on tree-based models. While the speedup is significant, TreeSHAP can still dominate the computation time of industry-level machine learning solutions on datasets with millions or more entries, causing delays in post-hoc model diagnosis and interpretation service. In this paper we present two new algorithms, Fast TreeSHAP v1 and v2, designed to improve the computational efficiency of TreeSHAP for large datasets. We empirically find that Fast TreeSHAP v1 is 1.5x faster than TreeSHAP while keeping the memory cost unchanged. Similarly, Fast TreeSHAP v2 is 2.5x faster than TreeSHAP, at the cost of a slightly higher memory usage, thanks to the pre-computation of expensive TreeSHAP steps. We also show that Fast TreeSHAP v2 is well-suited for multi-time model interpretations, resulting in as high as 3x faster explanation of newly incoming samples.
Targetless Calibration of LiDAR-IMU System Based on Continuous-time Batch Estimation
Jul 29, 2020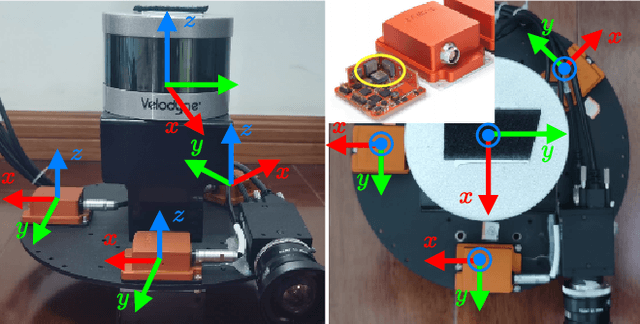
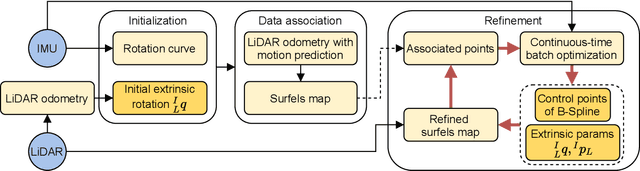

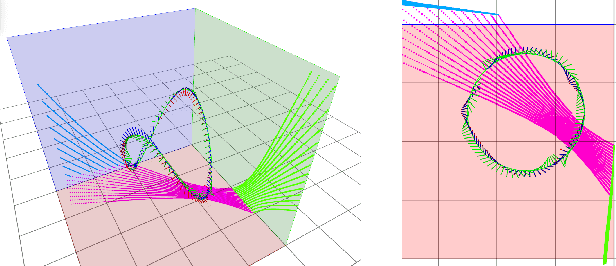
Sensor calibration is the fundamental block for a multi-sensor fusion system. This paper presents an accurate and repeatable LiDAR-IMU calibration method (termed LI-Calib), to calibrate the 6-DOF extrinsic transformation between the 3D LiDAR and the Inertial Measurement Unit (IMU). % Regarding the high data capture rate for LiDAR and IMU sensors, LI-Calib adopts a continuous-time trajectory formulation based on B-Spline, which is more suitable for fusing high-rate or asynchronous measurements than discrete-time based approaches. % Additionally, LI-Calib decomposes the space into cells and identifies the planar segments for data association, which renders the calibration problem well-constrained in usual scenarios without any artificial targets. We validate the proposed calibration approach on both simulated and real-world experiments. The results demonstrate the high accuracy and good repeatability of the proposed method in common human-made scenarios. To benefit the research community, we open-source our code at \url{https://github.com/APRIL-ZJU/lidar_IMU_calib}
Integrated Sensing and Communication with mmWave Massive MIMO: A Compressed Sampling Perspective
Jan 15, 2022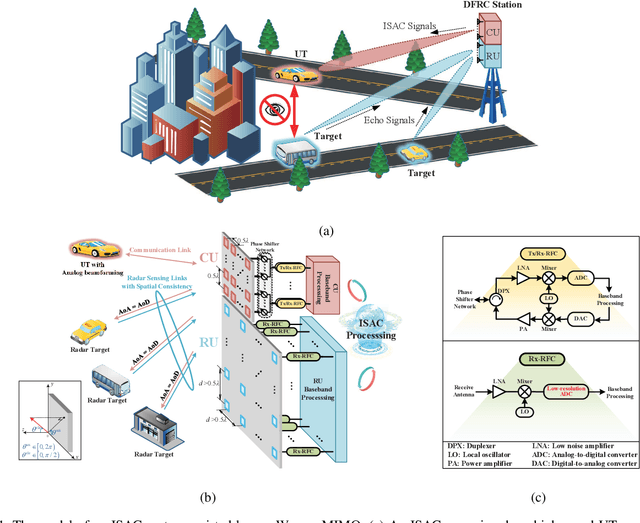
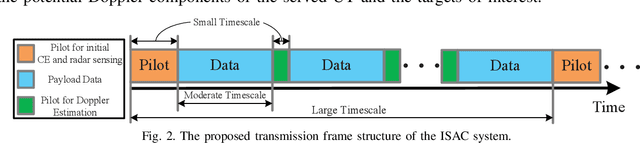
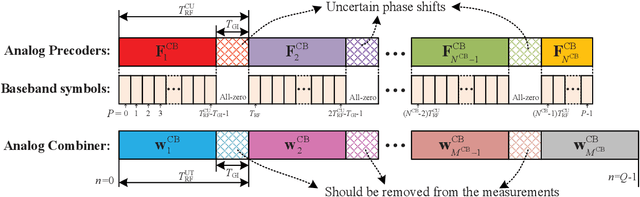
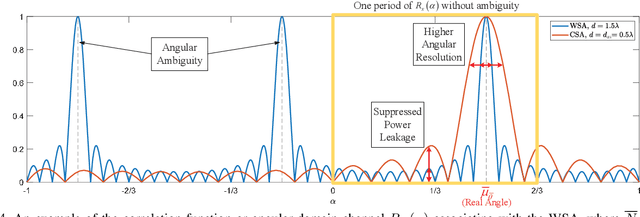
Integrated sensing and communication (ISAC) has opened up numerous game-changing opportunities for realizing future wireless systems. In this paper, we propose an ISAC processing framework relying on millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) systems. Specifically, we provide a compressed sampling (CS) perspective to facilitate ISAC processing, which can not only recover the large-scale channel state information or/and radar imaging information, but also significantly reduce pilot overhead. First, an energy-efficient widely spaced array (WSA) architecture is tailored for the radar receiver, which enhances the angular resolution of radar sensing at the cost of angular ambiguity. Then, we propose an ISAC frame structure for time-variant ISAC systems considering different timescales. The pilot waveforms are judiciously designed by taking into account both CS theories and hardware constraints. Next, we design the dedicated dictionary for WSA that serves as a building block for formulating the ISAC processing as sparse signal recovery problems. The orthogonal matching pursuit with support refinement (OMP-SR) algorithm is proposed to effectively solve the problems in the existence of the angular ambiguity. We also provide a framework for estimating and compensating the Doppler frequencies during payload data transmission to guarantee communication performances. Simulation results demonstrate the good performances of both communications and radar sensing under the proposed ISAC framework.
A Binded VAE for Inorganic Material Generation
Dec 17, 2021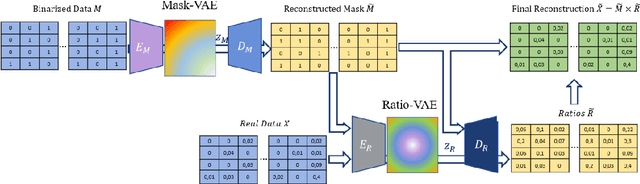

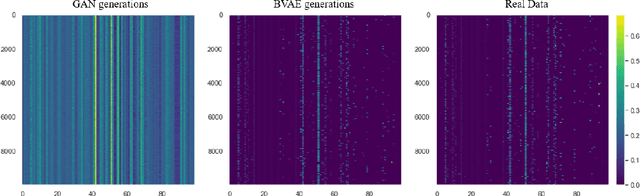

Designing new industrial materials with desired properties can be very expensive and time consuming. The main difficulty is to generate compounds that correspond to realistic materials. Indeed, the description of compounds as vectors of components' proportions is characterized by discrete features and a severe sparsity. Furthermore, traditional generative model validation processes as visual verification, FID and Inception scores are tailored for images and cannot then be used as such in this context. To tackle these issues, we develop an original Binded-VAE model dedicated to the generation of discrete datasets with high sparsity. We validate the model with novel metrics adapted to the problem of compounds generation. We show on a real issue of rubber compound design that the proposed approach outperforms the standard generative models which opens new perspectives for material design optimization.
Multi-query Video Retrieval
Jan 10, 2022
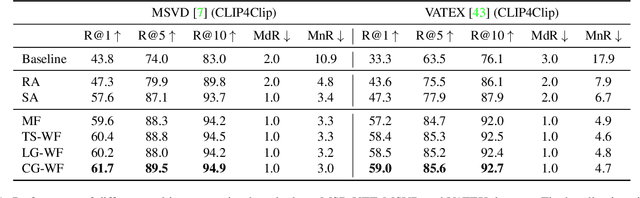
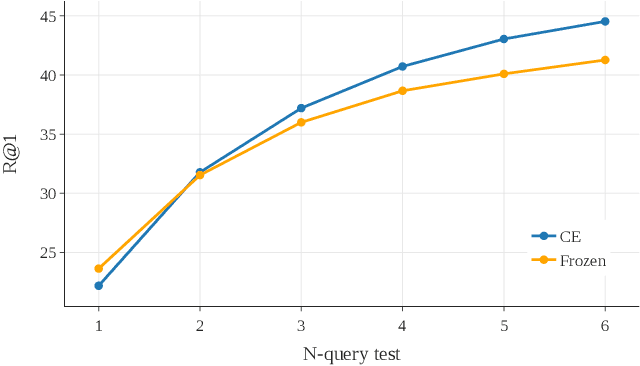
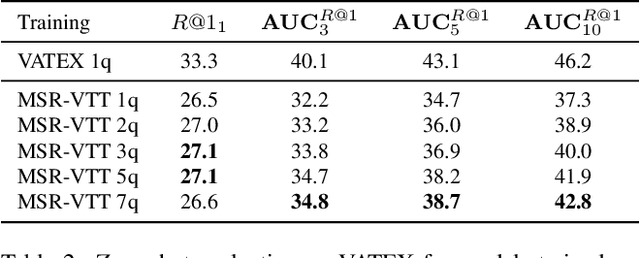
Retrieving target videos based on text descriptions is a task of great practical value and has received increasing attention over the past few years. In this paper, we focus on the less-studied setting of multi-query video retrieval, where multiple queries are provided to the model for searching over the video archive. We first show that the multi-query retrieval task is more pragmatic and representative of real-world use cases and better evaluates retrieval capabilities of current models, thereby deserving of further investigation alongside the more prevalent single-query retrieval setup. We then propose several new methods for leveraging multiple queries at training time to improve over simply combining similarity outputs of multiple queries from regular single-query trained models. Our models consistently outperform several competitive baselines over three different datasets. For instance, Recall@1 can be improved by 4.7 points on MSR-VTT, 4.1 points on MSVD and 11.7 points on VATEX over a strong baseline built on the state-of-the-art CLIP4Clip model. We believe further modeling efforts will bring new insights to this direction and spark new systems that perform better in real-world video retrieval applications. Code is available at https://github.com/princetonvisualai/MQVR.
Egocentric Deep Multi-Channel Audio-Visual Active Speaker Localization
Jan 06, 2022
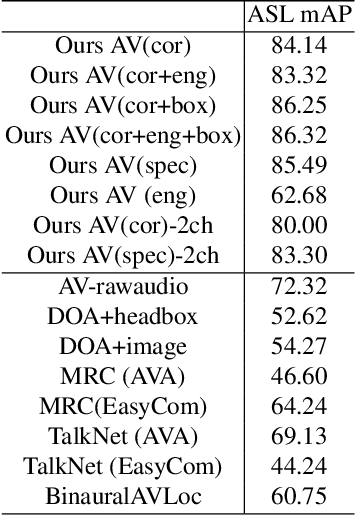
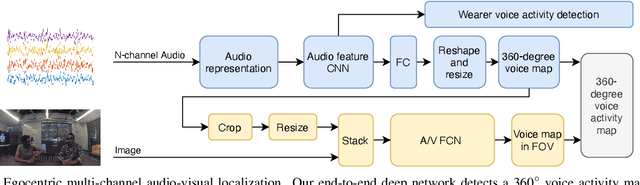
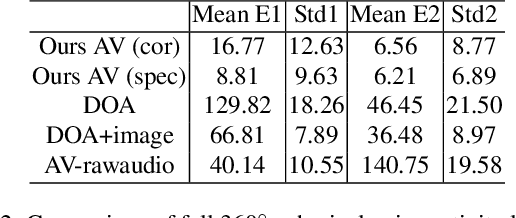
Augmented reality devices have the potential to enhance human perception and enable other assistive functionalities in complex conversational environments. Effectively capturing the audio-visual context necessary for understanding these social interactions first requires detecting and localizing the voice activities of the device wearer and the surrounding people. These tasks are challenging due to their egocentric nature: the wearer's head motion may cause motion blur, surrounding people may appear in difficult viewing angles, and there may be occlusions, visual clutter, audio noise, and bad lighting. Under these conditions, previous state-of-the-art active speaker detection methods do not give satisfactory results. Instead, we tackle the problem from a new setting using both video and multi-channel microphone array audio. We propose a novel end-to-end deep learning approach that is able to give robust voice activity detection and localization results. In contrast to previous methods, our method localizes active speakers from all possible directions on the sphere, even outside the camera's field of view, while simultaneously detecting the device wearer's own voice activity. Our experiments show that the proposed method gives superior results, can run in real time, and is robust against noise and clutter.
The Seven-League Scheme: Deep learning for large time step Monte Carlo simulations of stochastic differential equations
Sep 11, 2020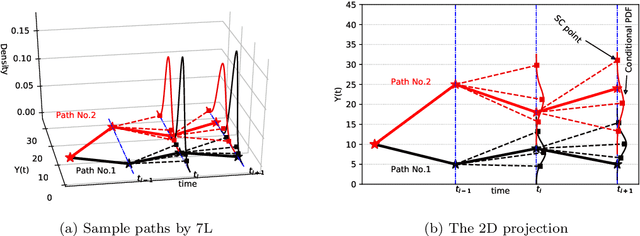
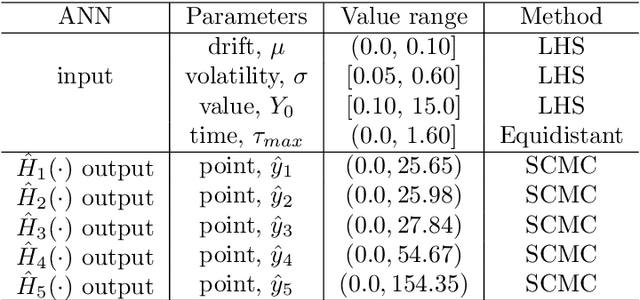
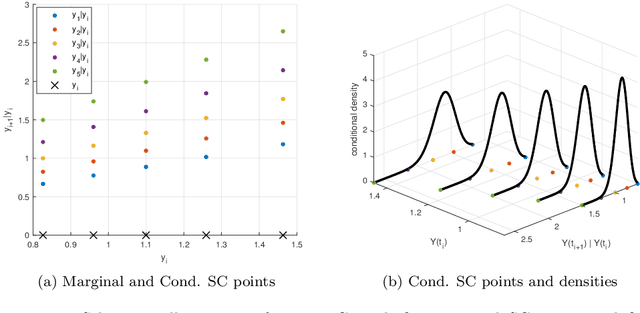

We propose an accurate data-driven numerical scheme to solve Stochastic Differential Equations (SDEs), by taking large time steps. The SDE discretization is built up by means of a polynomial chaos expansion method, on the basis of accurately determined stochastic collocation (SC) points. By employing an artificial neural network to learn these SC points, we can perform Monte Carlo simulations with large time steps. Error analysis confirms that this data-driven scheme results in accurate SDE solutions in the sense of strong convergence, provided the learning methodology is robust and accurate. With a variant method called the compression-decompression collocation and interpolation technique, we can drastically reduce the number of neural network functions that have to be learned, so that computational speed is enhanced. Numerical results show the high quality strong convergence error results, when using large time steps, and the novel scheme outperforms some classical numerical SDE discretizations. Some applications, here in financial option valuation, are also presented.
A unified algorithm framework for mean-variance optimization in discounted Markov decision processes
Jan 15, 2022This paper studies the risk-averse mean-variance optimization in infinite-horizon discounted Markov decision processes (MDPs). The involved variance metric concerns reward variability during the whole process, and future deviations are discounted to their present values. This discounted mean-variance optimization yields a reward function dependent on a discounted mean, and this dependency renders traditional dynamic programming methods inapplicable since it suppresses a crucial property -- time consistency. To deal with this unorthodox problem, we introduce a pseudo mean to transform the untreatable MDP to a standard one with a redefined reward function in standard form and derive a discounted mean-variance performance difference formula. With the pseudo mean, we propose a unified algorithm framework with a bilevel optimization structure for the discounted mean-variance optimization. The framework unifies a variety of algorithms for several variance-related problems including, but not limited to, risk-averse variance and mean-variance optimizations in discounted and average MDPs. Furthermore, the convergence analyses missing from the literature can be complemented with the proposed framework as well. Taking the value iteration as an example, we develop a discounted mean-variance value iteration algorithm and prove its convergence to a local optimum with the aid of a Bellman local-optimality equation. Finally, we conduct a numerical experiment on portfolio management to validate the proposed algorithm.