 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Block Hankel Tensor ARIMA for Multiple Short Time Series Forecasting
Feb 25, 2020
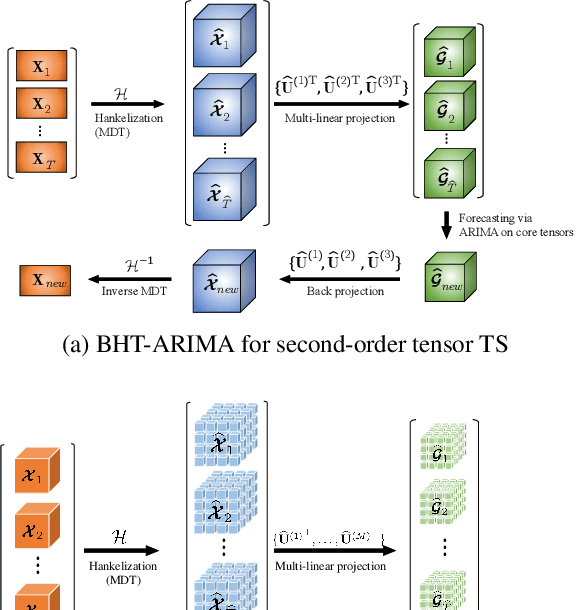
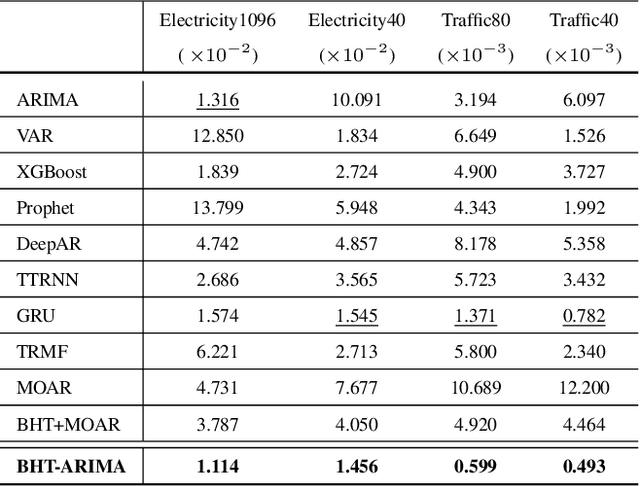
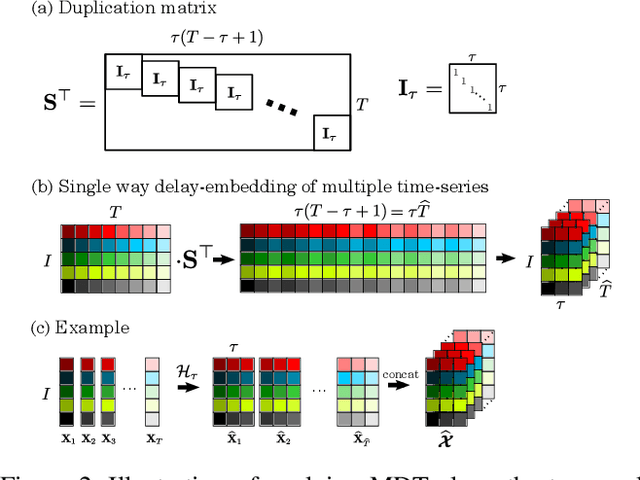
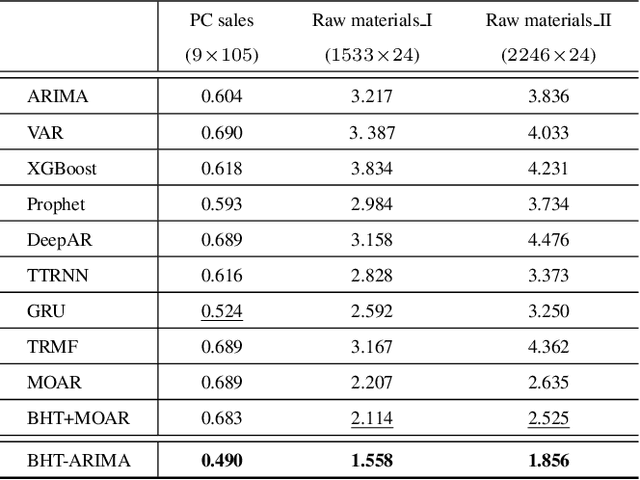
This work proposes a novel approach for multiple time series forecasting. At first, multi-way delay embedding transform (MDT) is employed to represent time series as low-rank block Hankel tensors (BHT). Then, the higher-order tensors are projected to compressed core tensors by applying Tucker decomposition. At the same time, the generalized tensor Autoregressive Integrated Moving Average (ARIMA) is explicitly used on consecutive core tensors to predict future samples. In this manner, the proposed approach tactically incorporates the unique advantages of MDT tensorization (to exploit mutual correlations) and tensor ARIMA coupled with low-rank Tucker decomposition into a unified framework. This framework exploits the low-rank structure of block Hankel tensors in the embedded space and captures the intrinsic correlations among multiple TS, which thus can improve the forecasting results, especially for multiple short time series. Experiments conducted on three public datasets and two industrial datasets verify that the proposed BHT-ARIMA effectively improves forecasting accuracy and reduces computational cost compared with the state-of-the-art methods.
Real-time and Autonomous Detection of Helipad for Landing Quad-Rotors by Visual Servoing
Aug 05, 2020

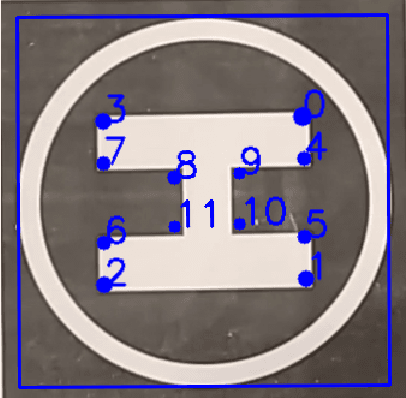
In this paper, we first present a method to autonomously detect helipads in real time. Our method does not rely on any machine-learning methods and as such is applicable in real-time on the computational capabilities of an average quad-rotor. After initial detection, we use image tracking methods to reduce the computational resource requirement further. Once the tracking starts our modified IBVS(Image-Based Visual Servoing) method starts publishing velocity to guide the quad-rotor onto the helipad. The modified IBVS scheme is designed for the four degrees-of-freedom of a quad-rotor and can land the quad-rotor in a specific orientation.
Shallow decision trees for explainable $k$-means clustering
Dec 29, 2021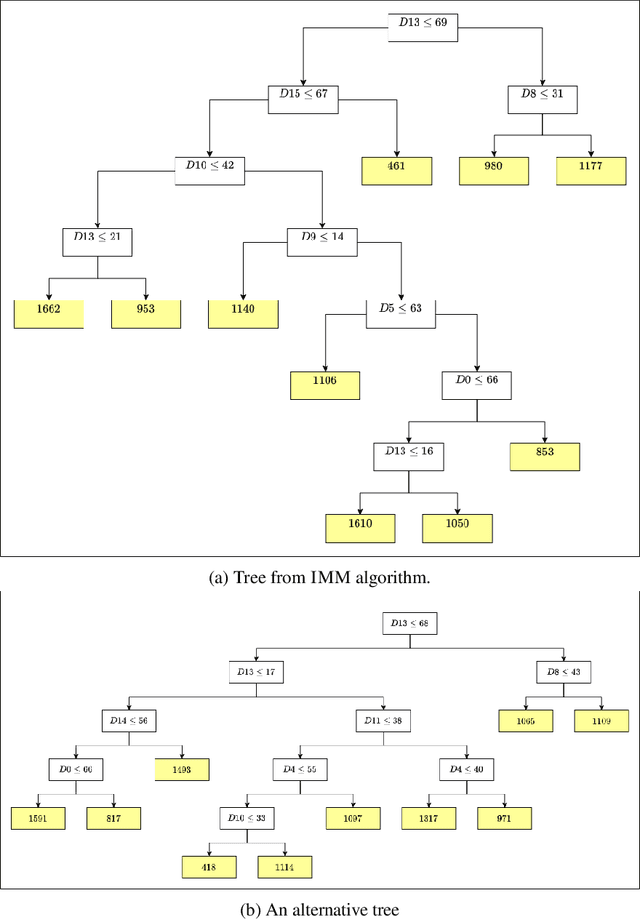
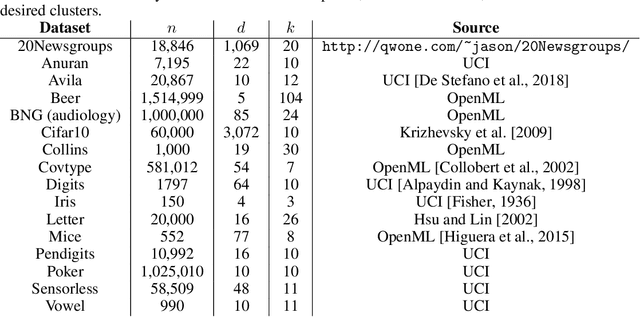
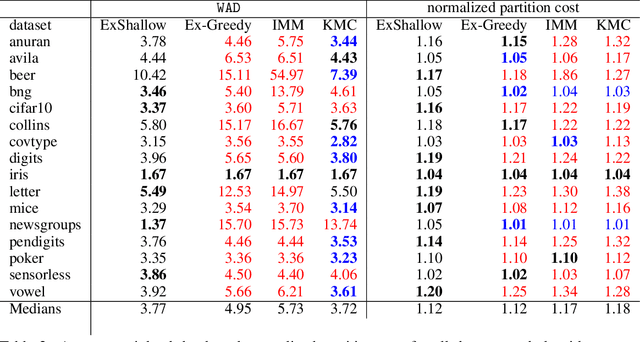
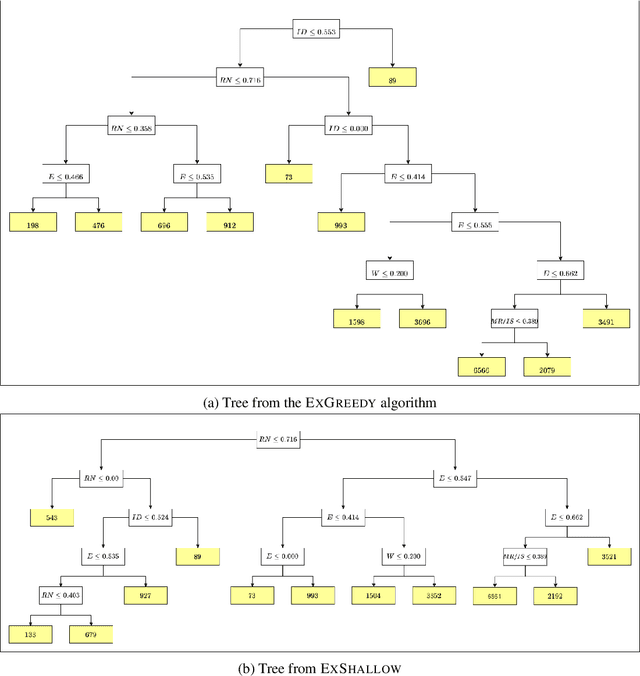
A number of recent works have employed decision trees for the construction of explainable partitions that aim to minimize the $k$-means cost function. These works, however, largely ignore metrics related to the depths of the leaves in the resulting tree, which is perhaps surprising considering how the explainability of a decision tree depends on these depths. To fill this gap in the literature, we propose an efficient algorithm that takes into account these metrics. In experiments on 16 datasets, our algorithm yields better results than decision-tree clustering algorithms such as the ones presented in \cite{dasgupta2020explainable}, \cite{frost2020exkmc}, \cite{laber2021price} and \cite{DBLP:conf/icml/MakarychevS21}, typically achieving lower or equivalent costs with considerably shallower trees. We also show, through a simple adaptation of existing techniques, that the problem of building explainable partitions induced by binary trees for the $k$-means cost function does not admit an $(1+\epsilon)$-approximation in polynomial time unless $P=NP$, which justifies the quest for approximation algorithms and/or heuristics.
Multi-variate Probabilistic Time Series Forecasting via Conditioned Normalizing Flows
Feb 14, 2020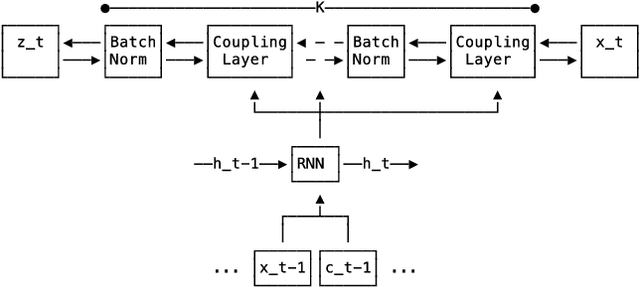

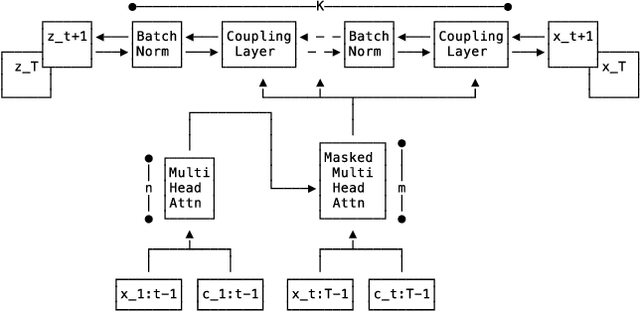
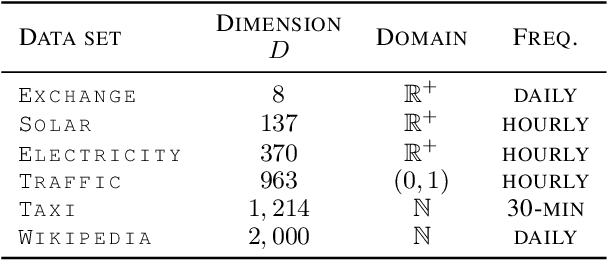
Time series forecasting is often fundamental to scientific and engineering problems and enables decision making. With ever increasing data set sizes, a trivial solution to scale up predictions is to assume independence between interacting time series. However, modeling statistical dependencies can improve accuracy and enable analysis of interaction effects. Deep learning methods are well suited for this problem, but multi-variate models often assume a simple parametric distribution and do not scale to high dimensions. In this work we model the multi-variate temporal dynamics of time series via an autoregressive deep learning model, where the data distribution is represented by a conditioned normalizing flow. This combination retains the power of autoregressive models, such as good performance in extrapolation into the future, with the flexibility of flows as a general purpose high-dimensional distribution model, while remaining computationally tractable. We show that it improves over the state-of-the-art for standard metrics on many real-world data sets with several thousand interacting time-series.
The Seven-League Scheme: Deep learning for large time step Monte Carlo simulations of stochastic differential equations
Sep 11, 2020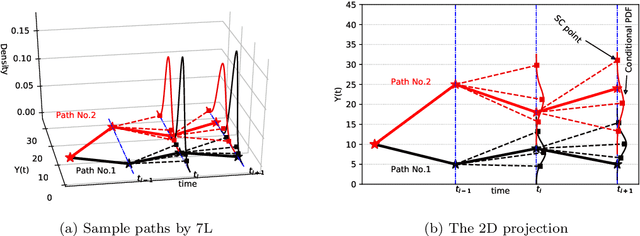
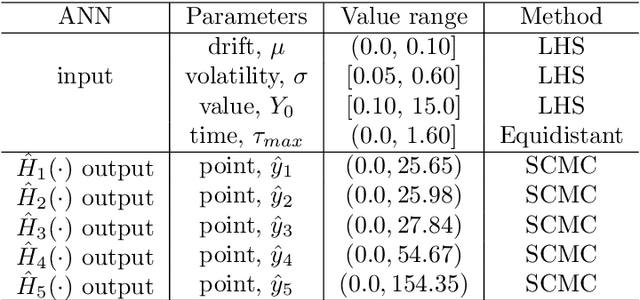
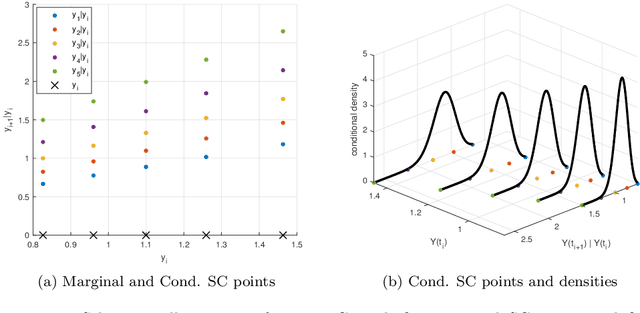

We propose an accurate data-driven numerical scheme to solve Stochastic Differential Equations (SDEs), by taking large time steps. The SDE discretization is built up by means of a polynomial chaos expansion method, on the basis of accurately determined stochastic collocation (SC) points. By employing an artificial neural network to learn these SC points, we can perform Monte Carlo simulations with large time steps. Error analysis confirms that this data-driven scheme results in accurate SDE solutions in the sense of strong convergence, provided the learning methodology is robust and accurate. With a variant method called the compression-decompression collocation and interpolation technique, we can drastically reduce the number of neural network functions that have to be learned, so that computational speed is enhanced. Numerical results show the high quality strong convergence error results, when using large time steps, and the novel scheme outperforms some classical numerical SDE discretizations. Some applications, here in financial option valuation, are also presented.
Towards more patient friendly clinical notes through language models and ontologies
Dec 23, 2021

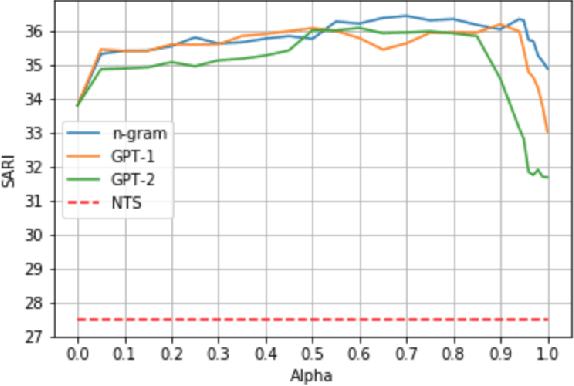
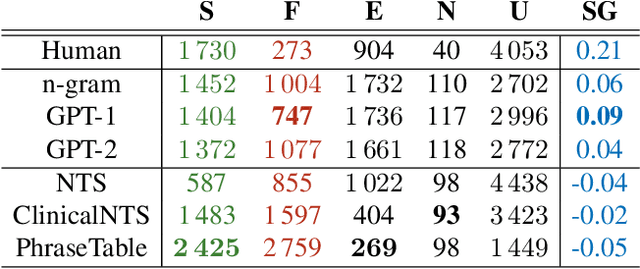
Clinical notes are an efficient way to record patient information but are notoriously hard to decipher for non-experts. Automatically simplifying medical text can empower patients with valuable information about their health, while saving clinicians time. We present a novel approach to automated simplification of medical text based on word frequencies and language modelling, grounded on medical ontologies enriched with layman terms. We release a new dataset of pairs of publicly available medical sentences and a version of them simplified by clinicians. Also, we define a novel text simplification metric and evaluation framework, which we use to conduct a large-scale human evaluation of our method against the state of the art. Our method based on a language model trained on medical forum data generates simpler sentences while preserving both grammar and the original meaning, surpassing the current state of the art.
Region Invariant Normalizing Flows for Mobility Transfer
Sep 13, 2021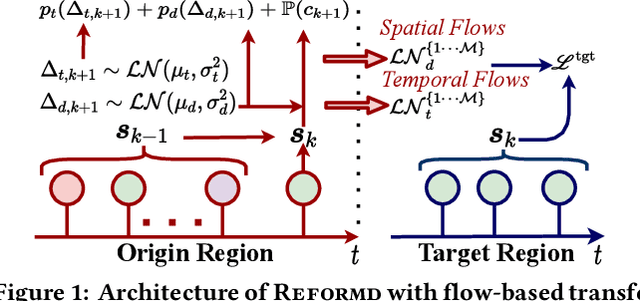
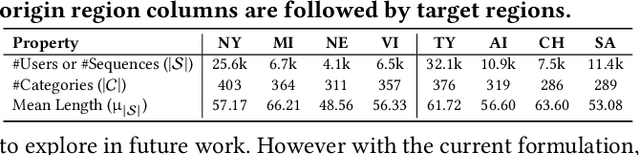
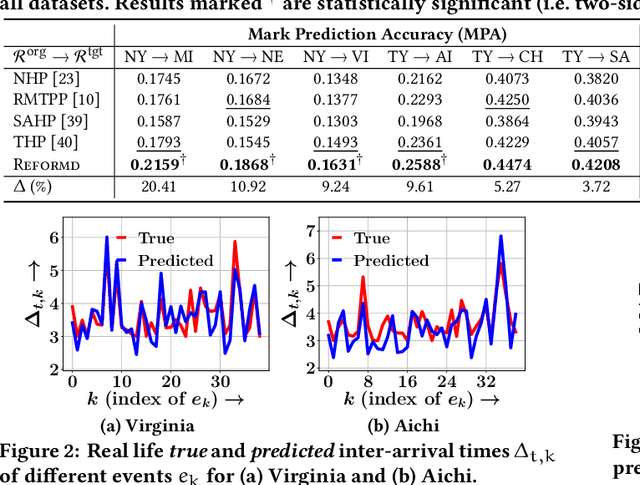
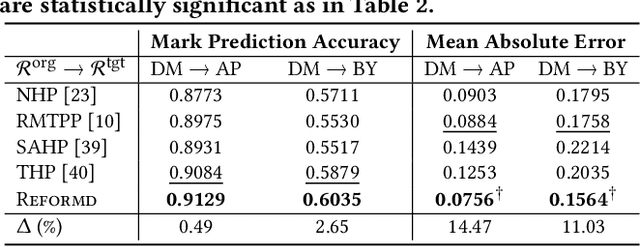
There exists a high variability in mobility data volumes across different regions, which deteriorates the performance of spatial recommender systems that rely on region-specific data. In this paper, we propose a novel transfer learning framework called REFORMD, for continuous-time location prediction for regions with sparse checkin data. Specifically, we model user-specific checkin-sequences in a region using a marked temporal point process (MTPP) with normalizing flows to learn the inter-checkin time and geo-distributions. Later, we transfer the model parameters of spatial and temporal flows trained on a data-rich origin region for the next check-in and time prediction in a target region with scarce checkin data. We capture the evolving region-specific checkin dynamics for MTPP and spatial-temporal flows by maximizing the joint likelihood of next checkin with three channels (1) checkin-category prediction, (2) checkin-time prediction, and (3) travel distance prediction. Extensive experiments on different user mobility datasets across the U.S. and Japan show that our model significantly outperforms state-of-the-art methods for modeling continuous-time sequences. Moreover, we also show that REFORMD can be easily adapted for product recommendations i.e., sequences without any spatial component.
OTFS Without CP in Massive MIMO: Breaking Doppler Limitations with TR-MRC and Windowing
Sep 24, 2021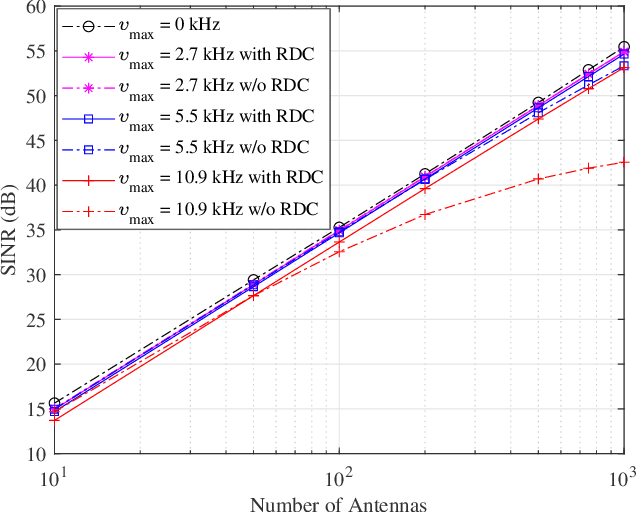
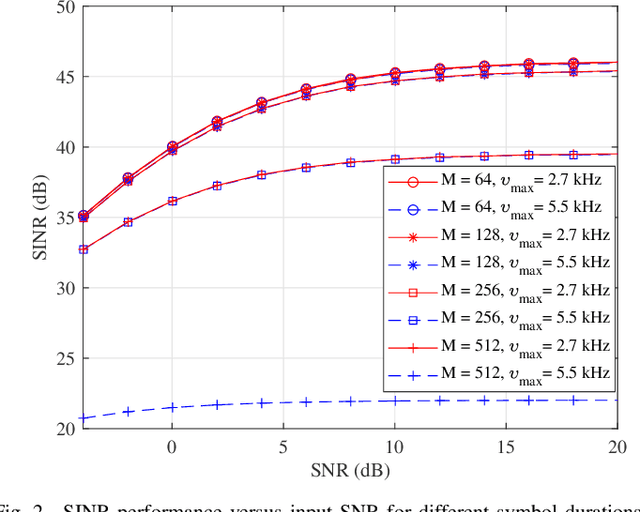
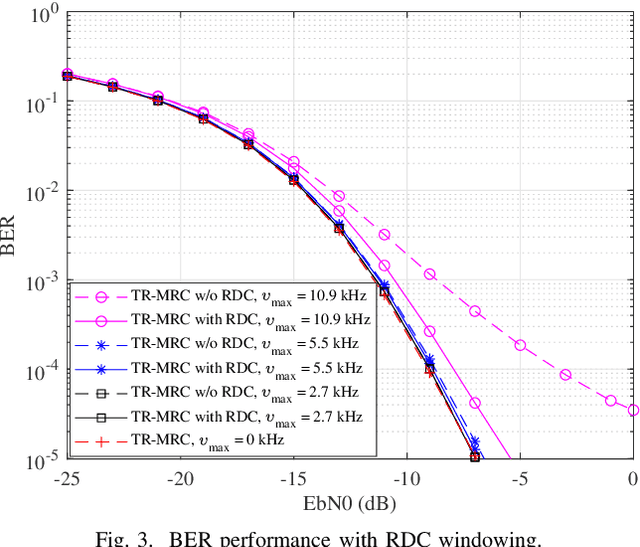
Orthogonal time frequency space (OTFS) modulation has recently emerged as an effective waveform to tackle the linear time-varying channels. In OTFS literature, approximately constant channel gains for every group of samples within each OTFS block are assumed. This leads to limitations for OTFS on the maximum Doppler frequency that it can tolerate. Additionally, presence of cyclic prefix (CP) in OTFS signal limits the flexibility in adjusting its parameters to improve its robustness against channel time variations. Therefore, in this paper, we study the possibility of removing the CP overhead from OTFS and breaking its Doppler limitations through multiple antenna processing in the large antenna regime. We asymptotically analyze the performance of time-reversal maximum ratio combining (TR-MRC) for OTFS without CP. We show that doubly dispersive channel effects average out in the large antenna regime when the maximum Doppler shift is within OTFS limitations. However, for considerably large Doppler shifts exceeding OTFS limitations, a residual Doppler effect remains. Our asymptotic derivations reveal that this effect converges to scaling of the received symbols in delay dimension with the samples of a Bessel function that depends on the maximum Doppler shift. Hence, we propose a novel residual Doppler correction (RDC) windowing technique that can break the Doppler limitations of OTFS and lead to a performance close to that of the linear time-invariant channels. Finally, we confirm the validity of our claims through simulations.
A review on outlier/anomaly detection in time series data
Feb 11, 2020

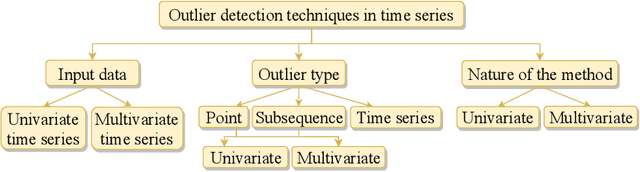
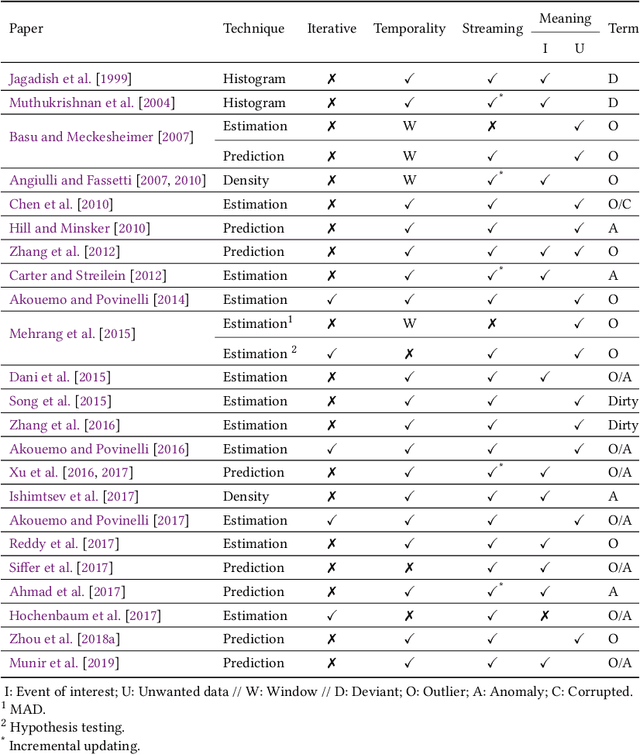
Recent advances in technology have brought major breakthroughs in data collection, enabling a large amount of data to be gathered over time and thus generating time series. Mining this data has become an important task for researchers and practitioners in the past few years, including the detection of outliers or anomalies that may represent errors or events of interest. This review aims to provide a structured and comprehensive state-of-the-art on outlier detection techniques in the context of time series. To this end, a taxonomy is presented based on the main aspects that characterize an outlier detection technique.
Underwater Object Classification and Detection: first results and open challenges
Jan 04, 2022

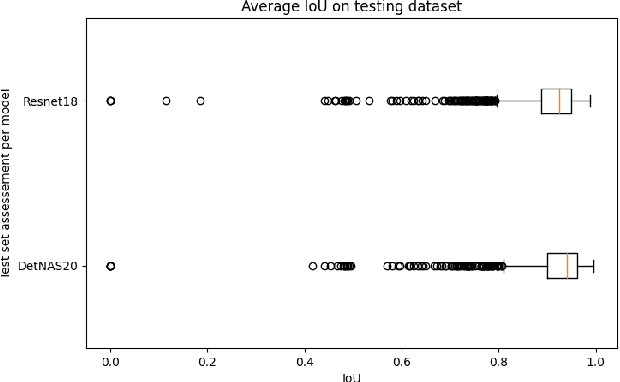
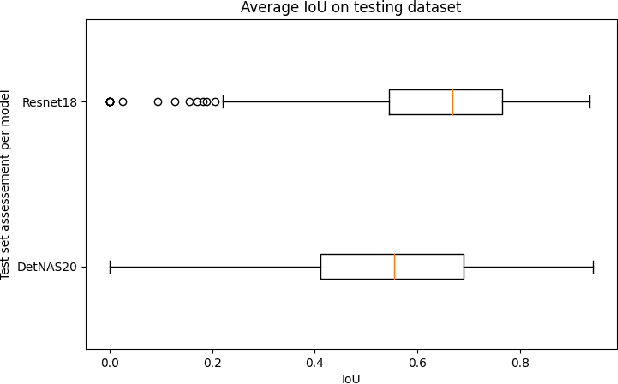
This work reviews the problem of object detection in underwater environments. We analyse and quantify the shortcomings of conventional state-of-the-art (SOTA) algorithms in the computer vision community when applied to this challenging environment, as well as providing insights and general guidelines for future research efforts. First, we assessed if pretraining with the conventional ImageNet is beneficial when the object detector needs to be applied to environments that may be characterised by a different feature distribution. We then investigate whether two-stage detectors yields to better performance with respect to single-stage detectors, in terms of accuracy, intersection of union (IoU), floating operation per second (FLOPS), and inference time. Finally, we assessed the generalisation capability of each model to a lower quality dataset to simulate performance on a real scenario, in which harsher conditions ought to be expected. Our experimental results provide evidence that underwater object detection requires searching for "ad-hoc" architectures than merely training SOTA architectures on new data, and that pretraining is not beneficial.