 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Solving Inverse Problems in Medical Imaging with Score-Based Generative Models
Nov 15, 2021

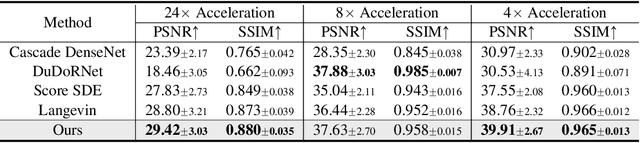

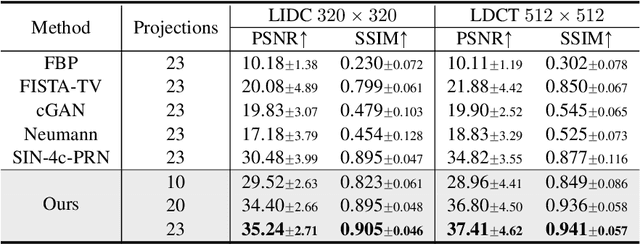
Reconstructing medical images from partial measurements is an important inverse problem in Computed Tomography (CT) and Magnetic Resonance Imaging (MRI). Existing solutions based on machine learning typically train a model to directly map measurements to medical images, leveraging a training dataset of paired images and measurements. These measurements are typically synthesized from images using a fixed physical model of the measurement process, which hinders the generalization capability of models to unknown measurement processes. To address this issue, we propose a fully unsupervised technique for inverse problem solving, leveraging the recently introduced score-based generative models. Specifically, we first train a score-based generative model on medical images to capture their prior distribution. Given measurements and a physical model of the measurement process at test time, we introduce a sampling method to reconstruct an image consistent with both the prior and the observed measurements. Our method does not assume a fixed measurement process during training, and can thus be flexibly adapted to different measurement processes at test time. Empirically, we observe comparable or better performance to supervised learning techniques in several medical imaging tasks in CT and MRI, while demonstrating significantly better generalization to unknown measurement processes.
Contextual Outlier Detection in Continuous-Time Event Sequences
Dec 19, 2019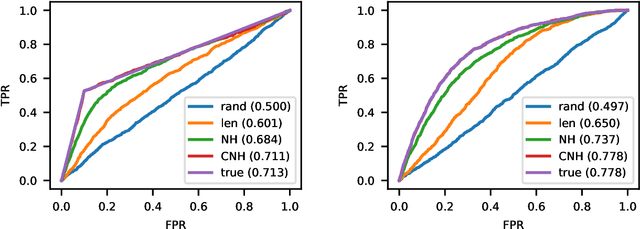
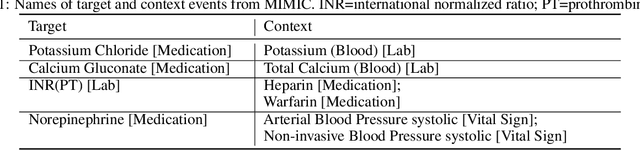
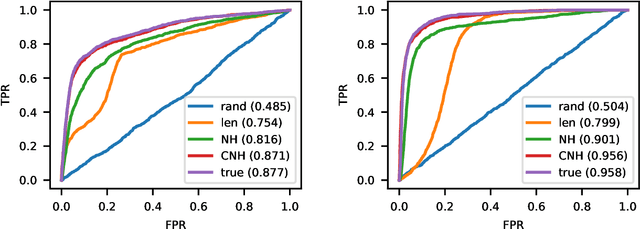
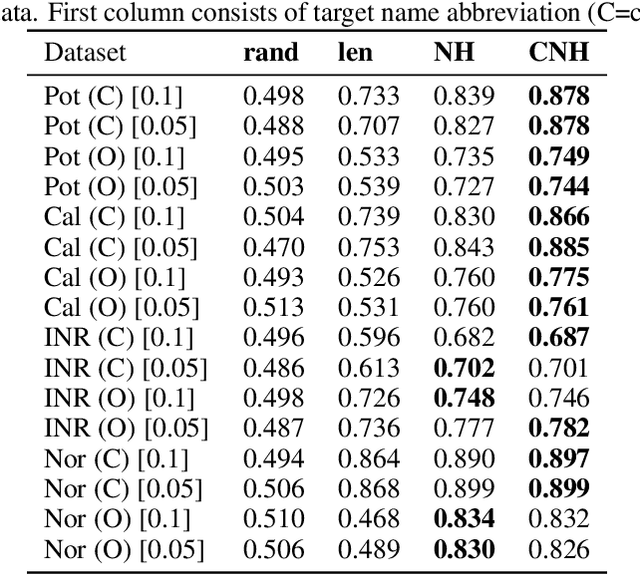
Continuous-time event sequences represent discrete events occurring in continuous time. Such sequences arise frequently in real-life and cover a wide variety of natural events, such as earthquakes, or events corresponding to human actions, such as medical administrations. Usually we expect the event sequences to follow some regular pattern over time. However, sometimes these regular patterns may be interrupted by unexpected absence or unexpected occurrences of events. Identification of these unexpected cases can be very important as they may point to abnormal situations that need human attention. In this work, we study and develop methods for detecting outliers in continuous-time event sequences, including unexpected absence and unexpected occurrences of events. Since the patterns that event sequences tend to follow may change in different contexts, we develop outlier detection methods based on point processes that take into account different contexts. Our outlier scoring methods are based on Bayesian decision theory and hypothesis testing with theoretical guarantees. To test the performance of the methods, we conduct experiments on both synthetic data and real-world clinical data and show the effectiveness of the proposed methods.
Lightweight Salient Object Detection in Optical Remote Sensing Images via Feature Correlation
Jan 20, 2022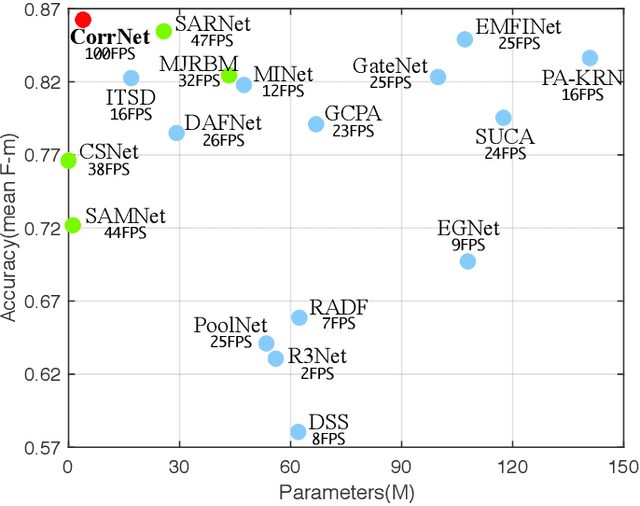
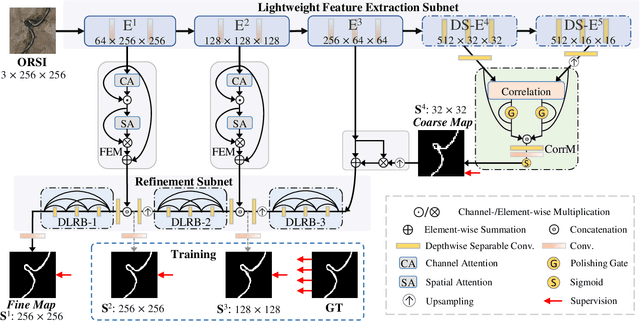
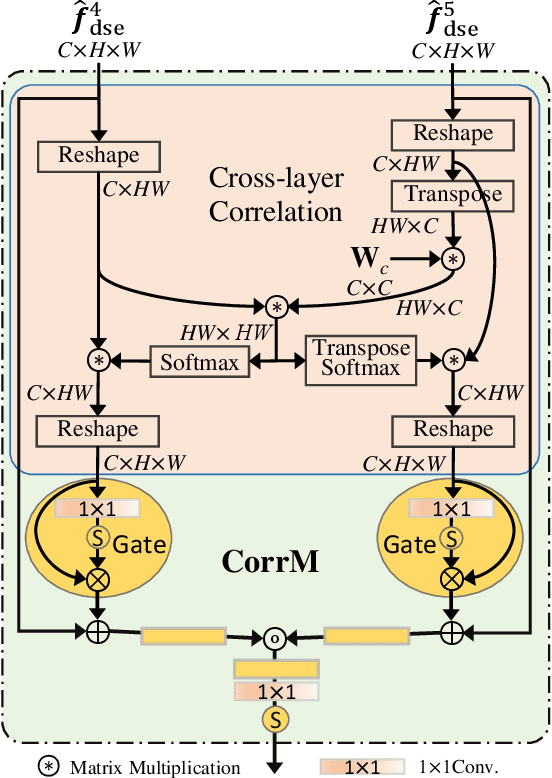
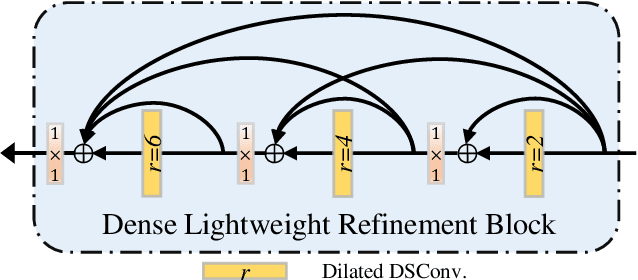
Salient object detection in optical remote sensing images (ORSI-SOD) has been widely explored for understanding ORSIs. However, previous methods focus mainly on improving the detection accuracy while neglecting the cost in memory and computation, which may hinder their real-world applications. In this paper, we propose a novel lightweight ORSI-SOD solution, named CorrNet, to address these issues. In CorrNet, we first lighten the backbone (VGG-16) and build a lightweight subnet for feature extraction. Then, following the coarse-to-fine strategy, we generate an initial coarse saliency map from high-level semantic features in a Correlation Module (CorrM). The coarse saliency map serves as the location guidance for low-level features. In CorrM, we mine the object location information between high-level semantic features through the cross-layer correlation operation. Finally, based on low-level detailed features, we refine the coarse saliency map in the refinement subnet equipped with Dense Lightweight Refinement Blocks, and produce the final fine saliency map. By reducing the parameters and computations of each component, CorrNet ends up having only 4.09M parameters and running with 21.09G FLOPs. Experimental results on two public datasets demonstrate that our lightweight CorrNet achieves competitive or even better performance compared with 26 state-of-the-art methods (including 16 large CNN-based methods and 2 lightweight methods), and meanwhile enjoys the clear memory and run time efficiency. The code and results of our method are available at https://github.com/MathLee/CorrNet.
Efficient Data Compression for 3D Sparse TPC via Bicephalous Convolutional Autoencoder
Nov 09, 2021
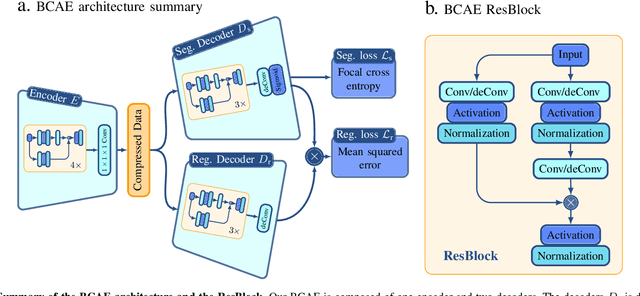
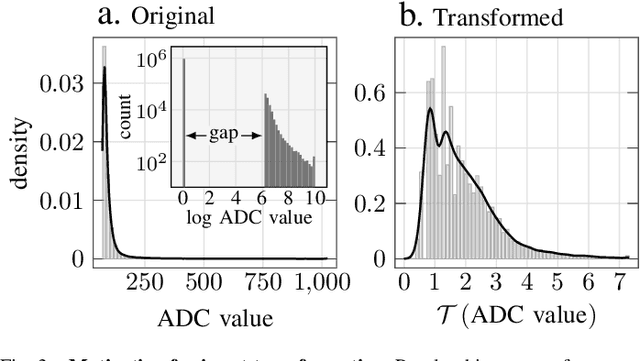
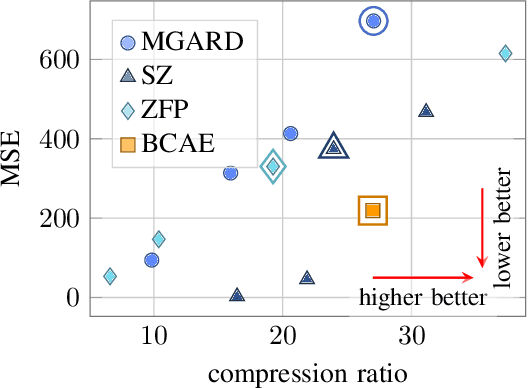
Real-time data collection and analysis in large experimental facilities present a great challenge across multiple domains, including high energy physics, nuclear physics, and cosmology. To address this, machine learning (ML)-based methods for real-time data compression have drawn significant attention. However, unlike natural image data, such as CIFAR and ImageNet that are relatively small-sized and continuous, scientific data often come in as three-dimensional data volumes at high rates with high sparsity (many zeros) and non-Gaussian value distribution. This makes direct application of popular ML compression methods, as well as conventional data compression methods, suboptimal. To address these obstacles, this work introduces a dual-head autoencoder to resolve sparsity and regression simultaneously, called \textit{Bicephalous Convolutional AutoEncoder} (BCAE). This method shows advantages both in compression fidelity and ratio compared to traditional data compression methods, such as MGARD, SZ, and ZFP. To achieve similar fidelity, the best performer among the traditional methods can reach only half the compression ratio of BCAE. Moreover, a thorough ablation study of the BCAE method shows that a dedicated segmentation decoder improves the reconstruction.
Profile Guided Optimization without Profiles: A Machine Learning Approach
Dec 24, 2021

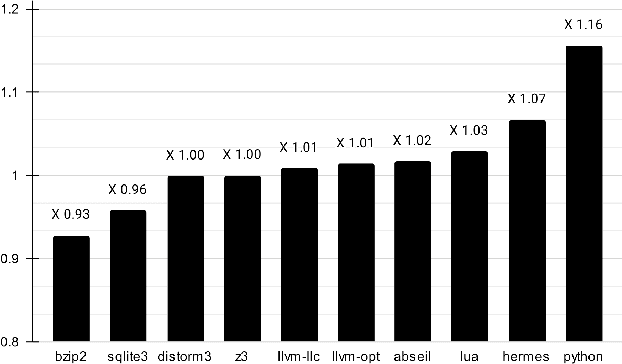
Profile guided optimization is an effective technique for improving the optimization ability of compilers based on dynamic behavior, but collecting profile data is expensive, cumbersome, and requires regular updating to remain fresh. We present a novel statistical approach to inferring branch probabilities that improves the performance of programs that are compiled without profile guided optimizations. We perform offline training using information that is collected from a large corpus of binaries that have branch probabilities information. The learned model is used by the compiler to predict the branch probabilities of regular uninstrumented programs, which the compiler can then use to inform optimization decisions. We integrate our technique directly in LLVM, supplementing the existing human-engineered compiler heuristics. We evaluate our technique on a suite of benchmarks, demonstrating some gains over compiling without profile information. In deployment, our technique requires no profiling runs and has negligible effect on compilation time.
Transfer Learning for Fault Diagnosis of Transmission Lines
Jan 20, 2022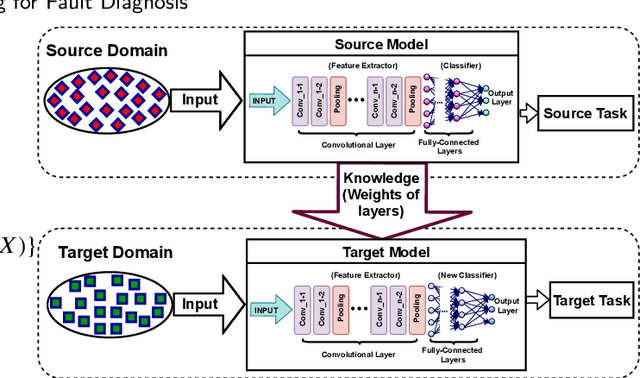
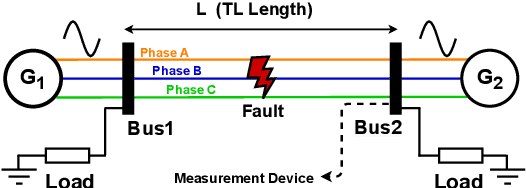
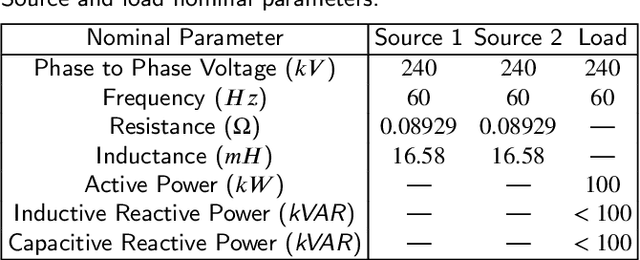
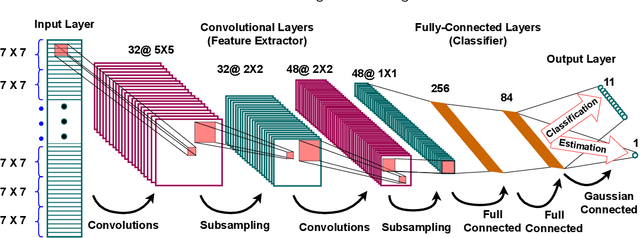
Recent artificial intelligence-based methods have shown great promise in the use of neural networks for real-time sensing and detection of transmission line faults and estimation of their locations. The expansion of power systems including transmission lines with various lengths have made a fault detection, classification, and location estimation process more challenging. Transmission line datasets are stream data which are continuously collected by various sensors and hence, require generalized and fast fault diagnosis approaches. Newly collected datasets including voltages and currents might not have enough and accurate labels (fault and no fault) that are useful to train neural networks. In this paper, a novel transfer learning framework based on a pre-trained LeNet-5 convolutional neural network is proposed. This method is able to diagnose faults for different transmission line lengths and impedances by transferring the knowledge from a source convolutional neural network to predict a dissimilar target dataset. By transferring this knowledge, faults from various transmission lines, without having enough labels, can be diagnosed faster and more efficiently compared to the existing methods. To prove the feasibility and effectiveness of this methodology, seven different datasets that include various lengths of transmission lines are used. The robustness of the proposed methodology against generator voltage fluctuation, variation in fault distance, fault inception angle, fault resistance, and phase difference between the two generators are well shown, thus proving its practical values in the fault diagnosis of transmission lines.
Sentence Embeddings and High-speed Similarity Search for Fast Computer Assisted Annotation of Legal Documents
Dec 21, 2021
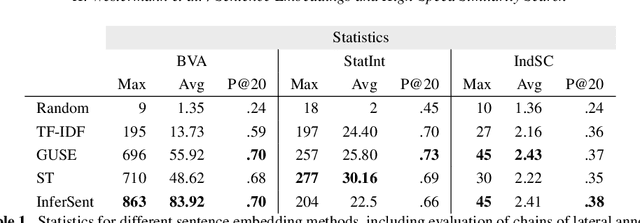
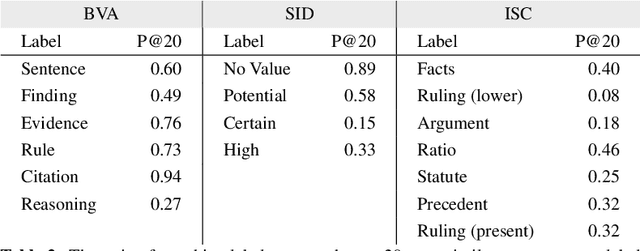
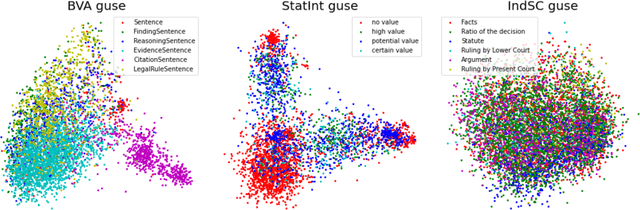
Human-performed annotation of sentences in legal documents is an important prerequisite to many machine learning based systems supporting legal tasks. Typically, the annotation is done sequentially, sentence by sentence, which is often time consuming and, hence, expensive. In this paper, we introduce a proof-of-concept system for annotating sentences "laterally." The approach is based on the observation that sentences that are similar in meaning often have the same label in terms of a particular type system. We use this observation in allowing annotators to quickly view and annotate sentences that are semantically similar to a given sentence, across an entire corpus of documents. Here, we present the interface of the system and empirically evaluate the approach. The experiments show that lateral annotation has the potential to make the annotation process quicker and more consistent.
Targetless Calibration of LiDAR-IMU System Based on Continuous-time Batch Estimation
Jul 29, 2020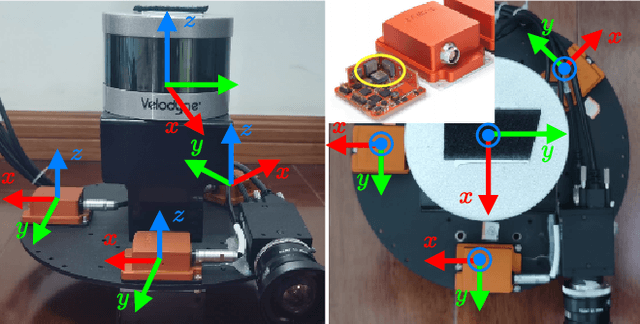
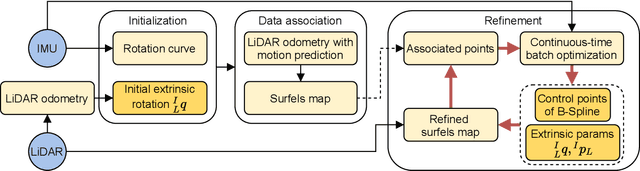

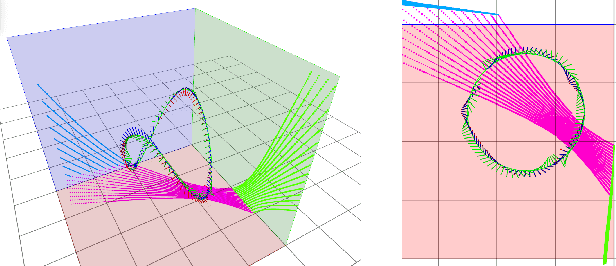
Sensor calibration is the fundamental block for a multi-sensor fusion system. This paper presents an accurate and repeatable LiDAR-IMU calibration method (termed LI-Calib), to calibrate the 6-DOF extrinsic transformation between the 3D LiDAR and the Inertial Measurement Unit (IMU). % Regarding the high data capture rate for LiDAR and IMU sensors, LI-Calib adopts a continuous-time trajectory formulation based on B-Spline, which is more suitable for fusing high-rate or asynchronous measurements than discrete-time based approaches. % Additionally, LI-Calib decomposes the space into cells and identifies the planar segments for data association, which renders the calibration problem well-constrained in usual scenarios without any artificial targets. We validate the proposed calibration approach on both simulated and real-world experiments. The results demonstrate the high accuracy and good repeatability of the proposed method in common human-made scenarios. To benefit the research community, we open-source our code at \url{https://github.com/APRIL-ZJU/lidar_IMU_calib}
Improving Out-of-Distribution Robustness via Selective Augmentation
Jan 02, 2022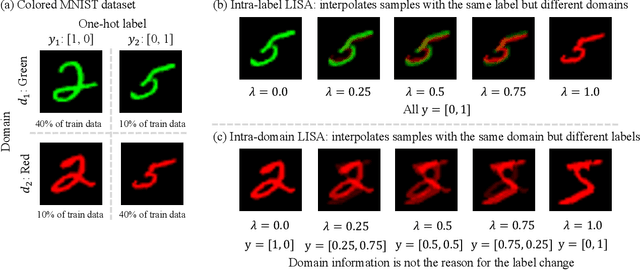
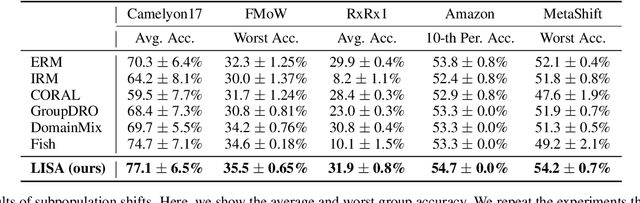
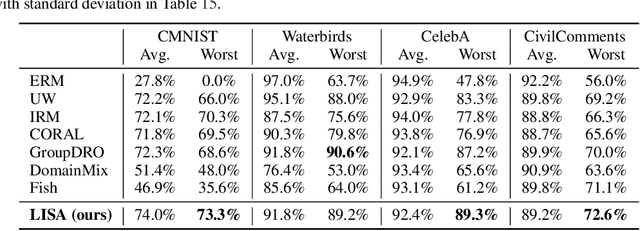
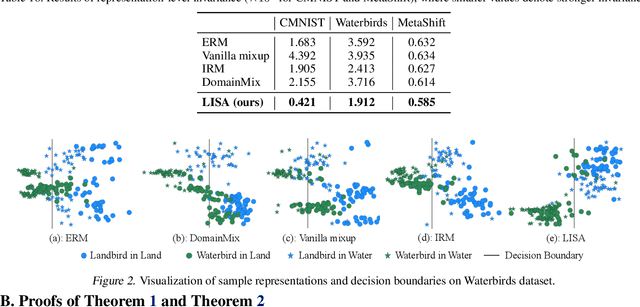
Machine learning algorithms typically assume that training and test examples are drawn from the same distribution. However, distribution shift is a common problem in real-world applications and can cause models to perform dramatically worse at test time. In this paper, we specifically consider the problems of domain shifts and subpopulation shifts (eg. imbalanced data). While prior works often seek to explicitly regularize internal representations and predictors of the model to be domain invariant, we instead aim to regularize the whole function without restricting the model's internal representations. This leads to a simple mixup-based technique which learns invariant functions via selective augmentation called LISA. LISA selectively interpolates samples either with the same labels but different domains or with the same domain but different labels. We analyze a linear setting and theoretically show how LISA leads to a smaller worst-group error. Empirically, we study the effectiveness of LISA on nine benchmarks ranging from subpopulation shifts to domain shifts, and we find that LISA consistently outperforms other state-of-the-art methods.
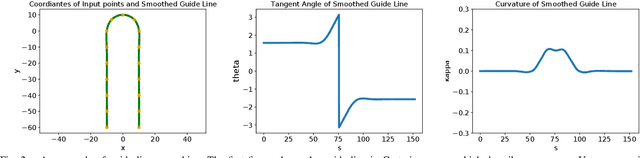
Optimal Trajectory Generation for Autonomous Vehicles Under Centripetal Acceleration Constraints for In-lane Driving Scenarios
Dec 03, 2021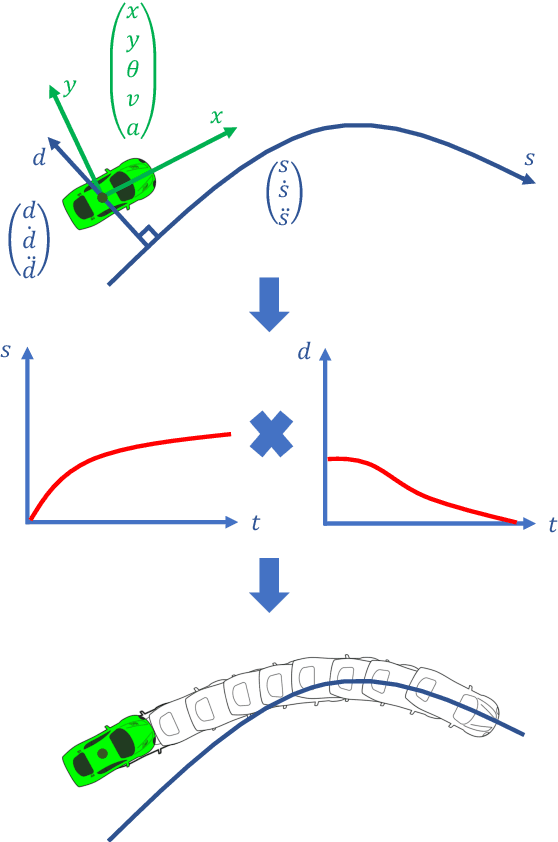
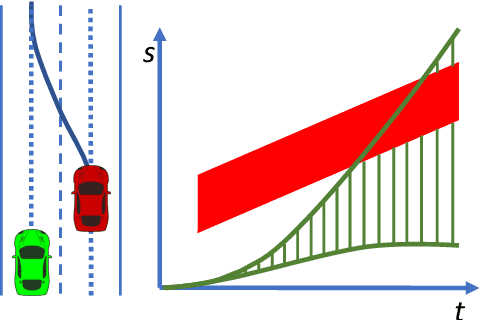
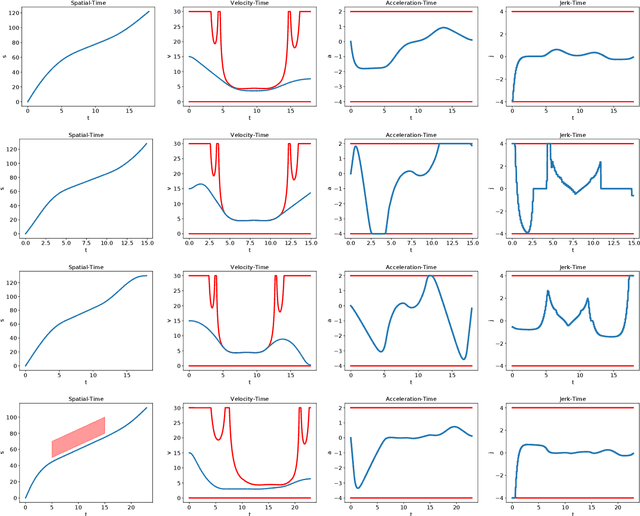
This paper presents a noval method that generates optimal trajectories for autonomous vehicles for in-lane driving scenarios. The method computes a trajectory using a two-phase optimization procedure. In the first phase, the optimization procedure generates a close-form driving guide line with differetiable curvatures. In the second phase, the procedure takes the driving guide line as input, and outputs dynamically feasible, jerk and time optimal trajectories for vehicles driving along the guide line. This method is especially useful for generating trajectories at curvy road where the vehicles need to apply frequent accelerations and decelerations to accommodate centripetal acceleration limits.