 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TFCN: Temporal-Frequential Convolutional Network for Single-Channel Speech Enhancement
Jan 03, 2022
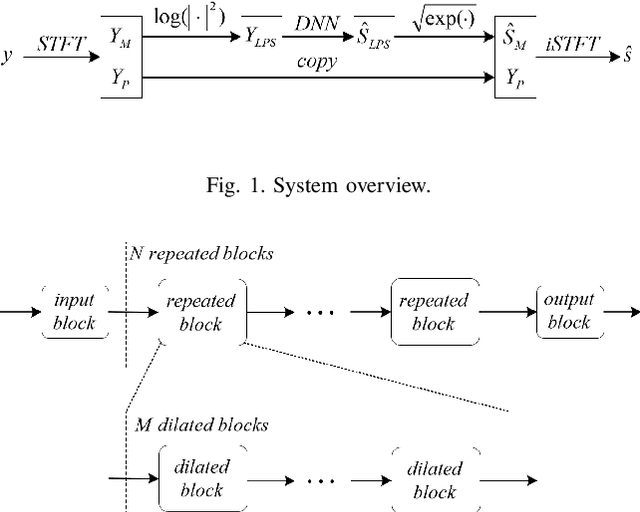
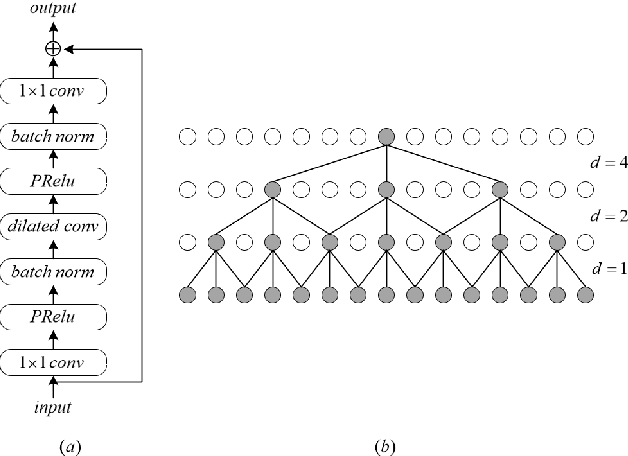
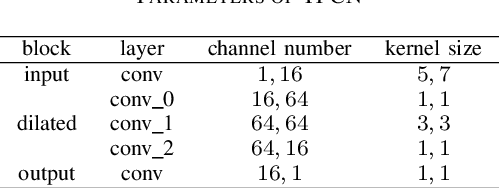
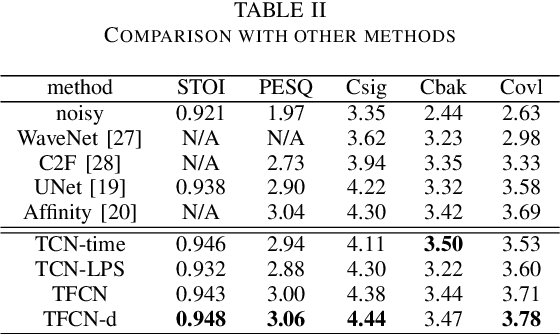
Deep learning based single-channel speech enhancement tries to train a neural network model for the prediction of clean speech signal. There are a variety of popular network structures for single-channel speech enhancement, such as TCNN, UNet, WaveNet, etc. However, these structures usually contain millions of parameters, which is an obstacle for mobile applications. In this work, we proposed a light weight neural network for speech enhancement named TFCN. It is a temporal-frequential convolutional network constructed of dilated convolutions and depth-separable convolutions. We evaluate the performance of TFCN in terms of Short-Time Objective Intelligibility (STOI), perceptual evaluation of speech quality (PESQ) and a series of composite metrics named Csig, Cbak and Covl. Experimental results show that compared with TCN and several other state-of-the-art algorithms, the proposed structure achieves a comparable performance with only 93,000 parameters. Further improvement can be achieved at the cost of more parameters, by introducing dense connections and depth-separable convolutions with normal ones. Experiments also show that the proposed structure can work well both in causal and non-causal situations.
Towards cyber-physical systems robust to communication delays: A differential game approach
Sep 21, 2021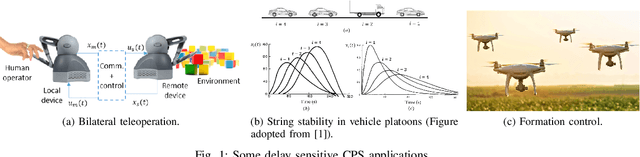
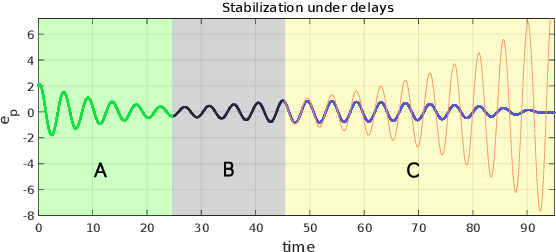
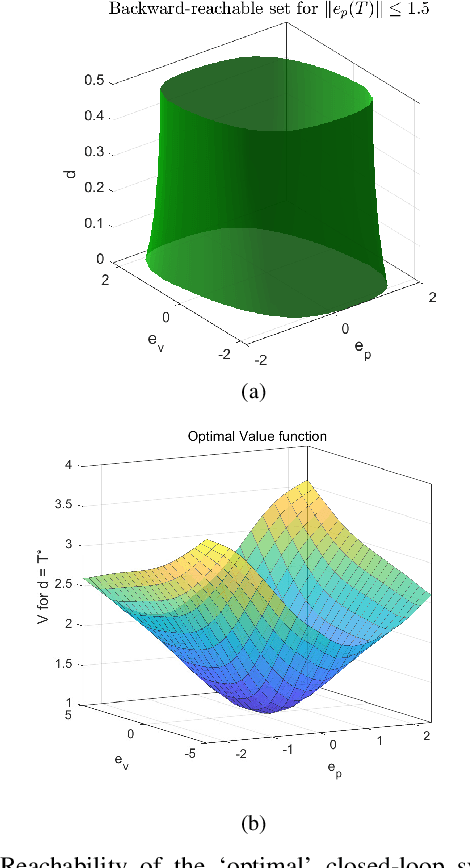
Collaboration between interconnected cyber-physical systems is becoming increasingly pervasive. Time-delays in communication channels between such systems are known to induce catastrophic failure modes, like high frequency oscillations in robotic manipulators in bilateral teleoperation or string instability in platoons of autonomous vehicles. This paper considers nonlinear time-delay systems representing coupled robotic agents, and proposes controllers that are robust to time-varying communication delays. We introduce approximations that allow the delays to be considered as implicit control inputs themselves, and formulate the problem as a zero-sum differential game between the stabilizing controllers and the delays acting adversarially. The ensuing optimal control law is finally compared to known results from Lyapunov-Krasovskii based approaches via numerical experiments.
Early Classification of Time Series. Cost-based Optimization Criterion and Algorithms
May 20, 2020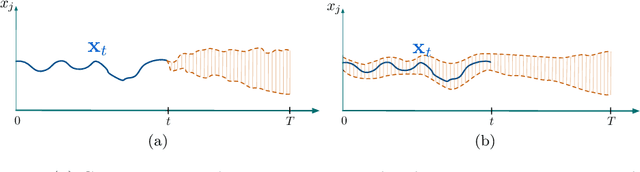
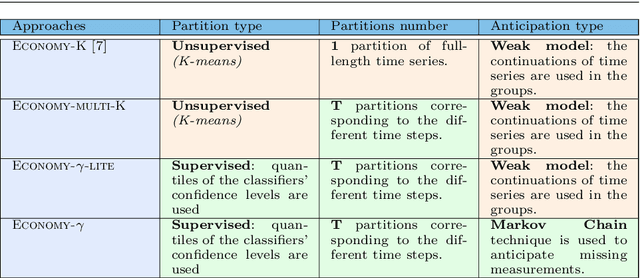
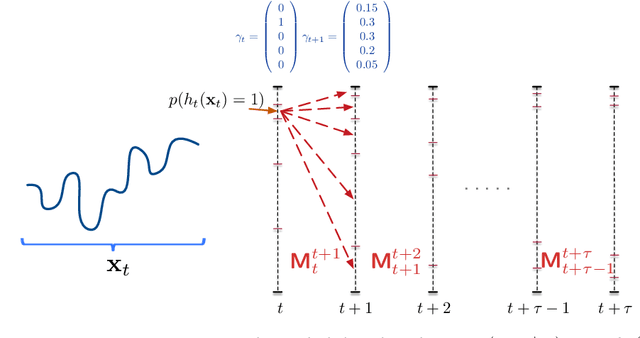
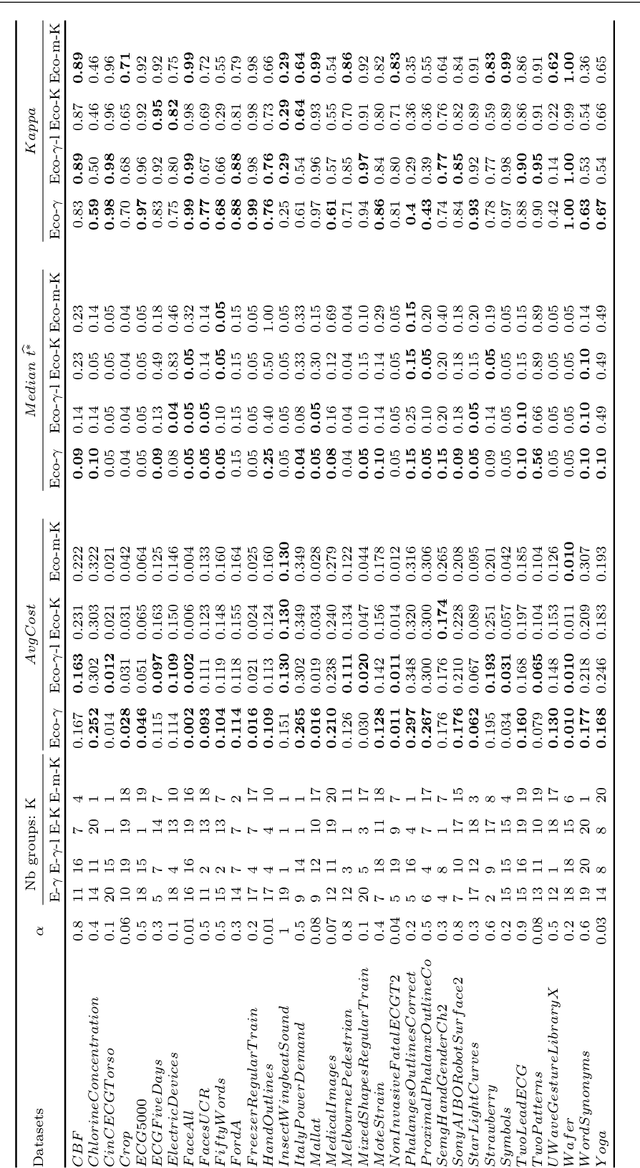
An increasing number of applications require to recognize the class of an incoming time series as quickly as possible without unduly compromising the accuracy of the prediction. In this paper, we put forward a new optimization criterion which takes into account both the cost of misclassification and the cost of delaying the decision. Based on this optimization criterion, we derived a family of non-myopic algorithms which try to anticipate the expected future gain in information in balance with the cost of waiting. In one class of algorithms, unsupervised-based, the expectations use the clustering of time series, while in a second class, supervised-based, time series are grouped according to the confidence level of the classifier used to label them. Extensive experiments carried out on real data sets using a large range of delay cost functions show that the presented algorithms are able to satisfactorily solving the earliness vs. accuracy trade-off, with the supervised-based approaches faring better than the unsupervised-based ones. In addition, all these methods perform better in a wide variety of conditions than a state of the art method based on a myopic strategy which is recognized as very competitive.
Processing M.A. Castrén's Materials: Multilingual Typed and Handwritten Manuscripts
Dec 28, 2021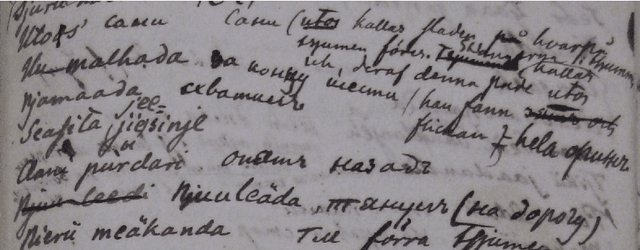
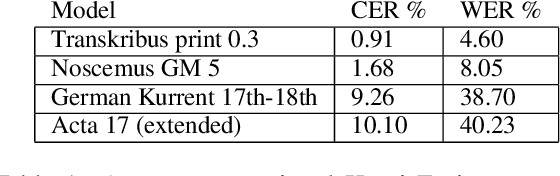
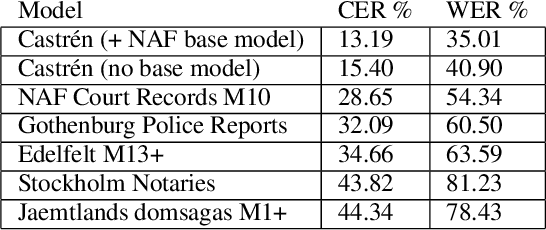
The study forms a technical report of various tasks that have been performed on the materials collected and published by Finnish ethnographer and linguist, Matthias Alexander Castr\'en (1813-1852). The Finno-Ugrian Society is publishing Castr\'en's manuscripts as new critical and digital editions, and at the same time different research groups have also paid attention to these materials. We discuss the workflows and technical infrastructure used, and consider how datasets that benefit different computational tasks could be created to further improve the usability of these materials, and also to aid the further processing of similar archived collections. We specifically focus on the parts of the collections that are processed in a way that improves their usability in more technical applications, complementing the earlier work on the cultural and linguistic aspects of these materials. Most of these datasets are openly available in Zenodo. The study points to specific areas where further research is needed, and provides benchmarks for text recognition tasks.
Choose Your Programming Copilot: A Comparison of the Program Synthesis Performance of GitHub Copilot and Genetic Programming
Nov 15, 2021
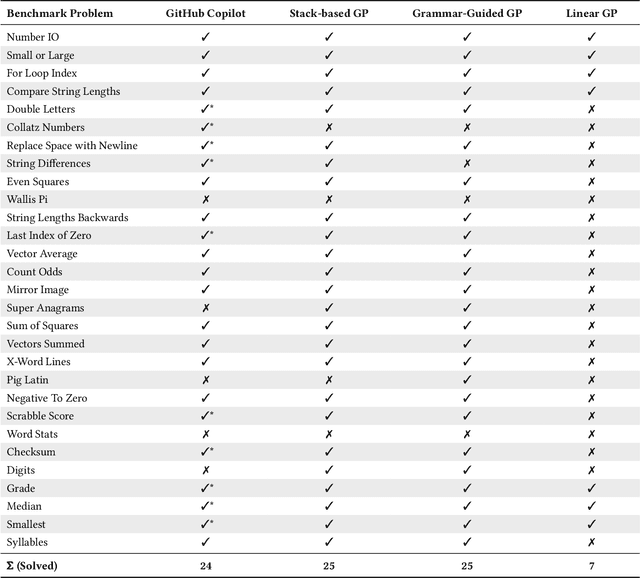

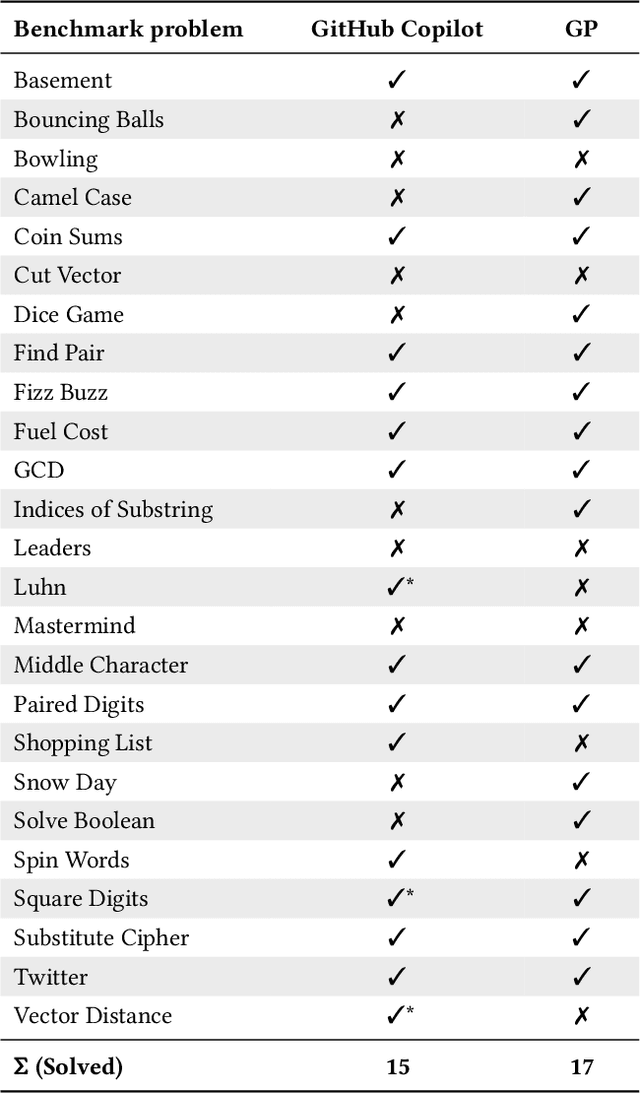
GitHub Copilot, an extension for the Visual Studio Code development environment powered by the large-scale language model Codex, makes automatic program synthesis available for software developers. This model has been extensively studied in the field of deep learning, however, a comparison to genetic programming, which is also known for its performance in automatic program synthesis, has not yet been carried out. In this paper, we evaluate GitHub Copilot on standard program synthesis benchmark problems and compare the achieved results with those from the genetic programming literature. In addition, we discuss the performance of both approaches. We find that the performance of the two approaches on the benchmark problems is quite similar, however, in comparison to GitHub Copilot, the program synthesis approaches based on genetic programming are not yet mature enough to support programmers in practical software development. Genetic programming usually needs a huge amount of expensive hand-labeled training cases and takes too much time to generate solutions. Furthermore, source code generated by genetic programming approaches is often bloated and difficult to understand. For future work on program synthesis with genetic programming, we suggest researchers to focus on improving the execution time, readability, and usability.
Non-asymptotic Convergence Analysis of Two Time-scale (Natural) Actor-Critic Algorithms
May 08, 2020As an important type of reinforcement learning algorithms, actor-critic (AC) and natural actor-critic (NAC) algorithms are often executed in two ways for finding optimal policies. In the first nested-loop design, actor's one update of policy is followed by an entire loop of critic's updates of the value function, and the finite-sample analysis of such AC and NAC algorithms have been recently well established. The second two time-scale design, in which actor and critic update simultaneously but with different learning rates, has much fewer tuning parameters than the nested-loop design and is hence substantially easier to implement. Although two time-scale AC and NAC have been shown to converge in the literature, the finite-sample convergence rate has not been established. In this paper, we provide the first such non-asymptotic convergence rate for two time-scale AC and NAC under Markovian sampling and with actor having general policy class approximation. We show that two time-scale AC requires the overall sample complexity at the order of $\mathcal{O}(\epsilon^{-2.5}\log^3(\epsilon^{-1}))$ to attain an $\epsilon$-accurate stationary point, and two time-scale NAC requires the overall sample complexity at the order of $\mathcal{O}(\epsilon^{-4}\log^2(\epsilon^{-1}))$ to attain an $\epsilon$-accurate global optimal point. We develop novel techniques for bounding the bias error of the actor due to dynamically changing Markovian sampling and for analyzing the convergence rate of the linear critic with dynamically changing base functions and transition kernel.
Vector Quantized Diffusion Model for Text-to-Image Synthesis
Nov 29, 2021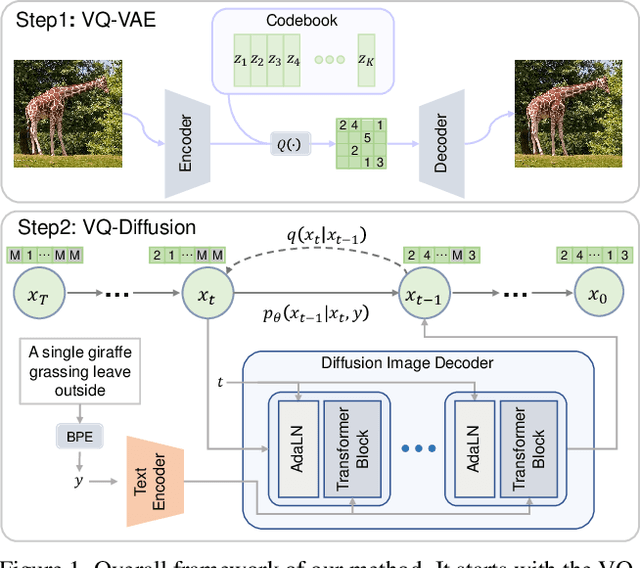
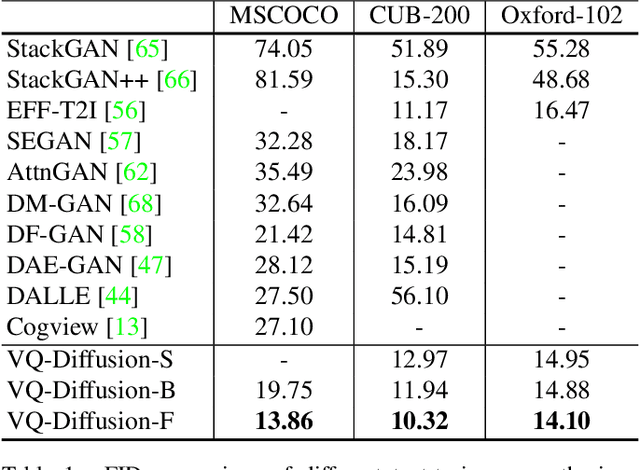

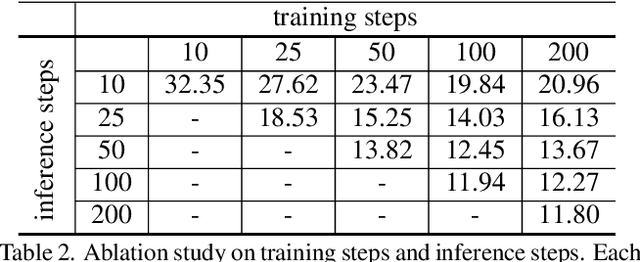
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
A/B/n Testing with Control in the Presence of Subpopulations
Oct 29, 2021
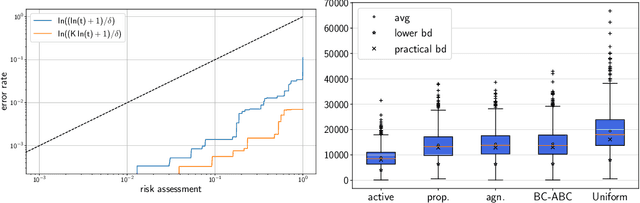

Motivated by A/B/n testing applications, we consider a finite set of distributions (called \emph{arms}), one of which is treated as a \emph{control}. We assume that the population is stratified into homogeneous subpopulations. At every time step, a subpopulation is sampled and an arm is chosen: the resulting observation is an independent draw from the arm conditioned on the subpopulation. The quality of each arm is assessed through a weighted combination of its subpopulation means. We propose a strategy for sequentially choosing one arm per time step so as to discover as fast as possible which arms, if any, have higher weighted expectation than the control. This strategy is shown to be asymptotically optimal in the following sense: if $\tau_\delta$ is the first time when the strategy ensures that it is able to output the correct answer with probability at least $1-\delta$, then $\mathbb{E}[\tau_\delta]$ grows linearly with $\log(1/\delta)$ at the exact optimal rate. This rate is identified in the paper in three different settings: (1) when the experimenter does not observe the subpopulation information, (2) when the subpopulation of each sample is observed but not chosen, and (3) when the experimenter can select the subpopulation from which each response is sampled. We illustrate the efficiency of the proposed strategy with numerical simulations on synthetic and real data collected from an A/B/n experiment.
Exploration of Hyperdimensional Computing Strategies for Enhanced Learning on Epileptic Seizure Detection
Jan 24, 2022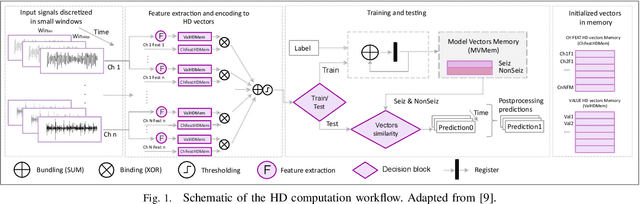
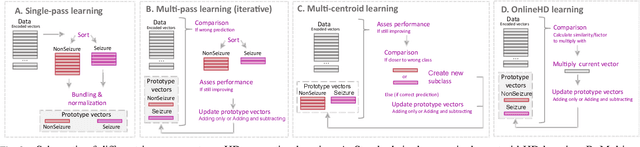
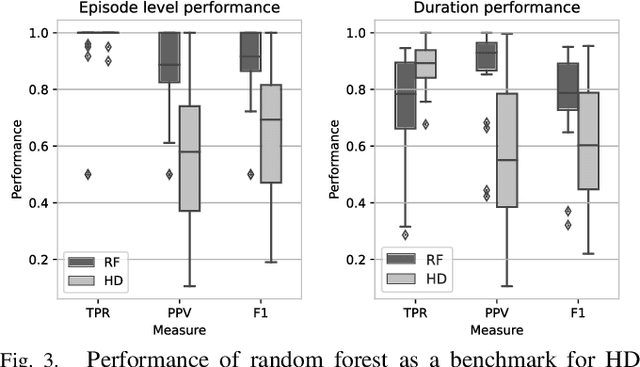
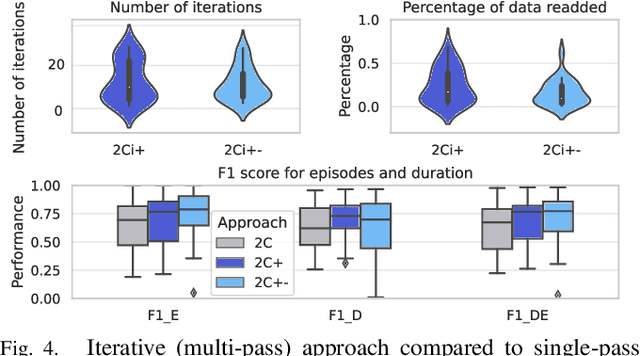
Wearable and unobtrusive monitoring and prediction of epileptic seizures has the potential to significantly increase the life quality of patients, but is still an unreached goal due to challenges of real-time detection and wearable devices design. Hyperdimensional (HD) computing has evolved in recent years as a new promising machine learning approach, especially when talking about wearable applications. But in the case of epilepsy detection, standard HD computing is not performing at the level of other state-of-the-art algorithms. This could be due to the inherent complexity of the seizures and their signatures in different biosignals, such as the electroencephalogram (EEG), the highly personalized nature, and the disbalance of seizure and non-seizure instances. In the literature, different strategies for improved learning of HD computing have been proposed, such as iterative (multi-pass) learning, multi-centroid learning and learning with sample weight ("OnlineHD"). Yet, most of them have not been tested on the challenging task of epileptic seizure detection, and it stays unclear whether they can increase the HD computing performance to the level of the current state-of-the-art algorithms, such as random forests. Thus, in this paper, we implement different learning strategies and assess their performance on an individual basis, or in combination, regarding detection performance and memory and computational requirements. Results show that the best-performing algorithm, which is a combination of multi-centroid and multi-pass, can indeed reach the performance of the random forest model on a highly unbalanced dataset imitating a real-life epileptic seizure detection application.
Keeping Deep Lithography Simulators Updated: Global-Local Shape-Based Novelty Detection and Active Learning
Jan 24, 2022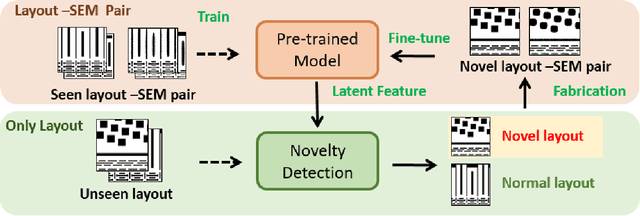
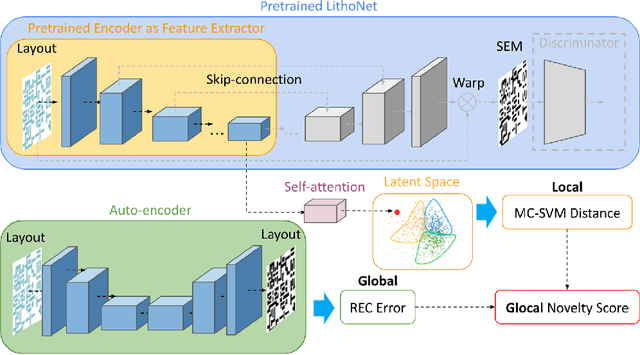
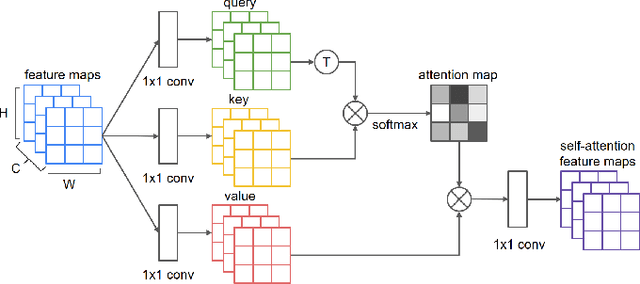
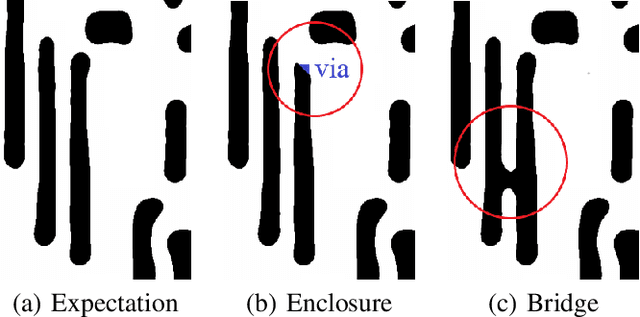
Learning-based pre-simulation (i.e., layout-to-fabrication) models have been proposed to predict the fabrication-induced shape deformation from an IC layout to its fabricated circuit. Such models are usually driven by pairwise learning, involving a training set of layout patterns and their reference shape images after fabrication. However, it is expensive and time-consuming to collect the reference shape images of all layout clips for model training and updating. To address the problem, we propose a deep learning-based layout novelty detection scheme to identify novel (unseen) layout patterns, which cannot be well predicted by a pre-trained pre-simulation model. We devise a global-local novelty scoring mechanism to assess the potential novelty of a layout by exploiting two subnetworks: an autoencoder and a pretrained pre-simulation model. The former characterizes the global structural dissimilarity between a given layout and training samples, whereas the latter extracts a latent code representing the fabrication-induced local deformation. By integrating the global dissimilarity with the local deformation boosted by a self-attention mechanism, our model can accurately detect novelties without the ground-truth circuit shapes of test samples. Based on the detected novelties, we further propose two active-learning strategies to sample a reduced amount of representative layouts most worthy to be fabricated for acquiring their ground-truth circuit shapes. Experimental results demonstrate i) our method's effectiveness in layout novelty detection, and ii) our active-learning strategies' ability in selecting representative novel layouts for keeping a learning-based pre-simulation model updated.