 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Nonlinear Time Series Classification Using Bispectrum-based Deep Convolutional Neural Networks
Mar 04, 2020
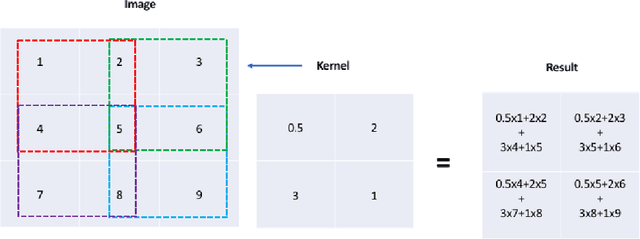
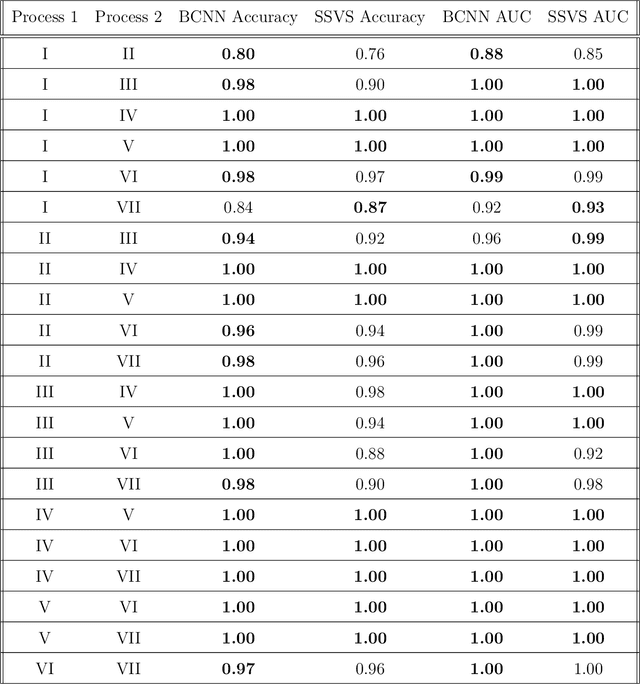
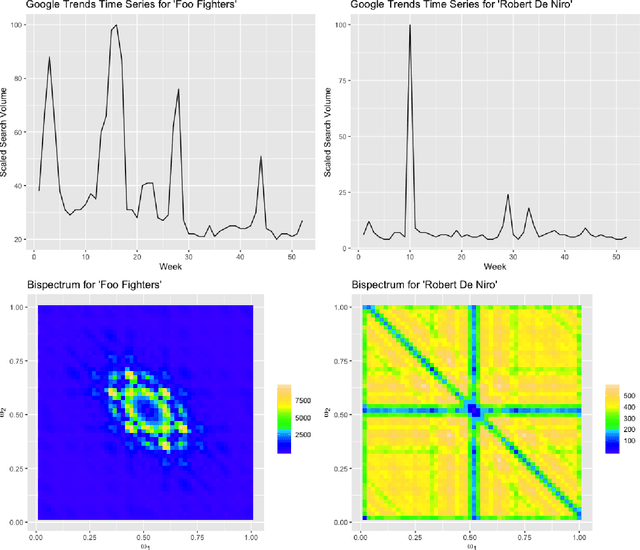
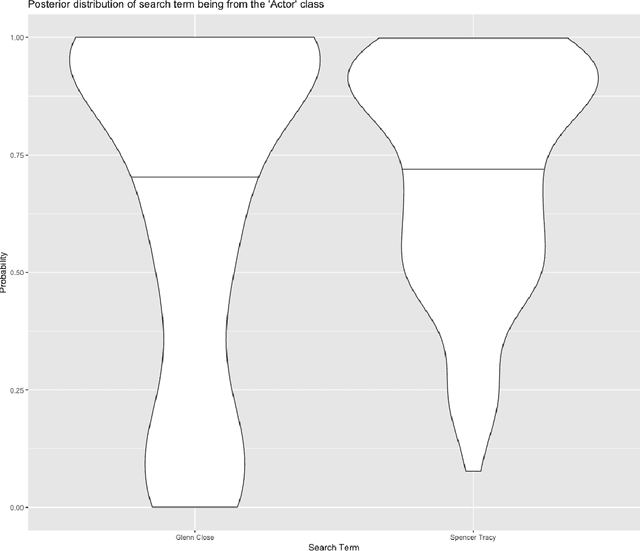
Time series classification using novel techniques has experienced a recent resurgence and growing interest from statisticians, subject-domain scientists, and decision makers in business and industry. This is primarily due to the ever increasing amount of big and complex data produced as a result of technological advances. A motivating example is that of Google trends data, which exhibit highly nonlinear behavior. Although a rich literature exists for addressing this problem, existing approaches mostly rely on first and second order properties of the time series, since they typically assume linearity of the underlying process. Often, these are inadequate for effective classification of nonlinear time series data such as Google Trends data. Given these methodological deficiencies and the abundance of nonlinear time series that persist among real-world phenomena, we introduce an approach that merges higher order spectral analysis (HOSA) with deep convolutional neural networks (CNNs) for classifying time series. The effectiveness of our approach is illustrated using simulated data and two motivating industry examples that involve Google trends data and electronic device energy consumption data.
Large-scale nonlinear Granger causality: A data-driven, multivariate approach to recovering directed networks from short time-series data
Sep 10, 2020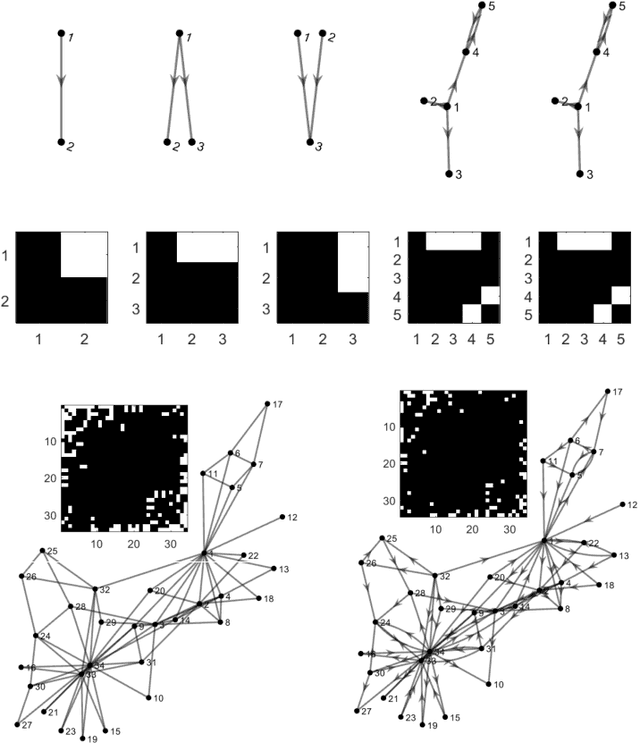
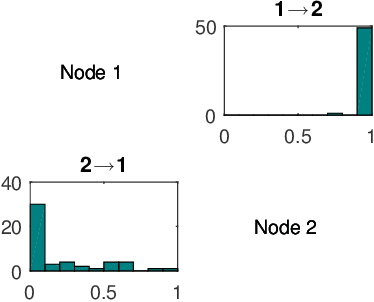
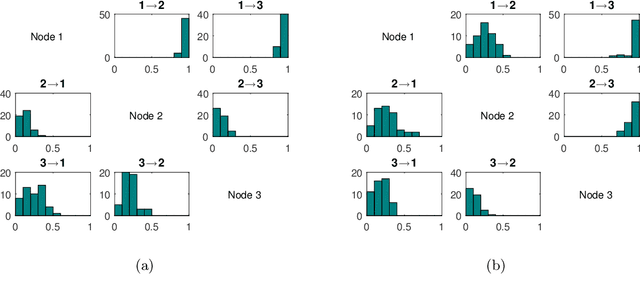
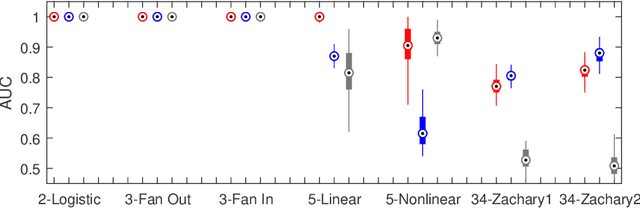
To gain insight into complex systems it is a key challenge to infer nonlinear causal directional relations from observational time-series data. Specifically, estimating causal relationships between interacting components in large systems with only short recordings over few temporal observations remains an important, yet unresolved problem. Here, we introduce a large-scale Nonlinear Granger Causality (lsNGC) approach for inferring directional, nonlinear, multivariate causal interactions between system components from short high-dimensional time-series recordings. By modeling interactions with nonlinear state-space transformations from limited observational data, lsNGC identifies casual relations with no explicit a priori assumptions on functional interdependence between component time-series in a computationally efficient manner. Additionally, our method provides a mathematical formulation revealing statistical significance of inferred causal relations. We extensively study the ability of lsNGC to recovering network structure from two-node to thirty-four node chaotic time-series systems. Our results suggest that lsNGC captures meaningful interactions from limited observational data, where it performs favorably when compared to traditionally used methods. Finally, we demonstrate the applicability of lsNGC to estimating causality in large, real-world systems by inferring directional nonlinear, multivariate causal relationships among a large number of relatively short time-series acquired from functional Magnetic Resonance Imaging (fMRI) data of the human brain.
Autoencoder-based time series clustering with energy applications
Feb 10, 2020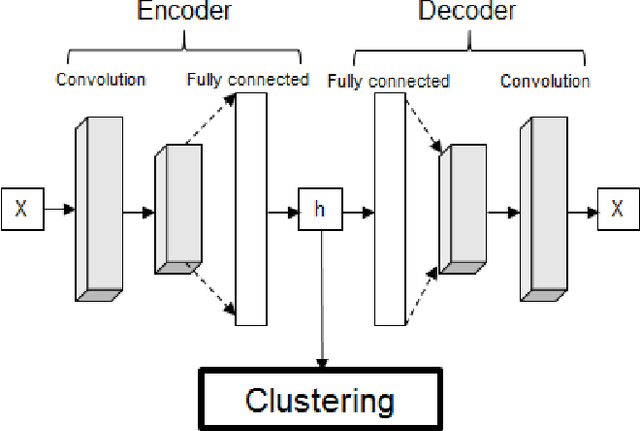
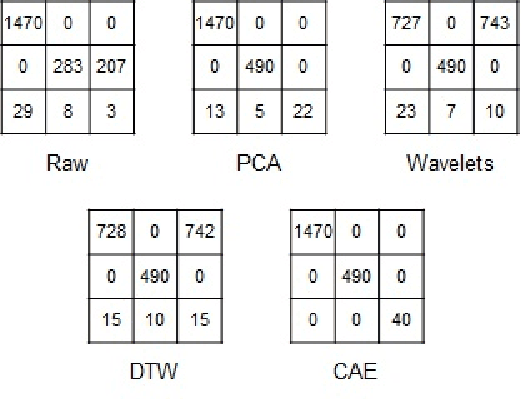

Time series clustering is a challenging task due to the specific nature of the data. Classical approaches do not perform well and need to be adapted either through a new distance measure or a data transformation. In this paper we investigate the combination of a convolutional autoencoder and a k-medoids algorithm to perfom time series clustering. The convolutional autoencoder allows to extract meaningful features and reduce the dimension of the data, leading to an improvement of the subsequent clustering. Using simulation and energy related data to validate the approach, experimental results show that the clustering is robust to outliers thus leading to finer clusters than with standard methods.
Learning Fine-Grained Motion Embedding for Landscape Animation
Sep 06, 2021

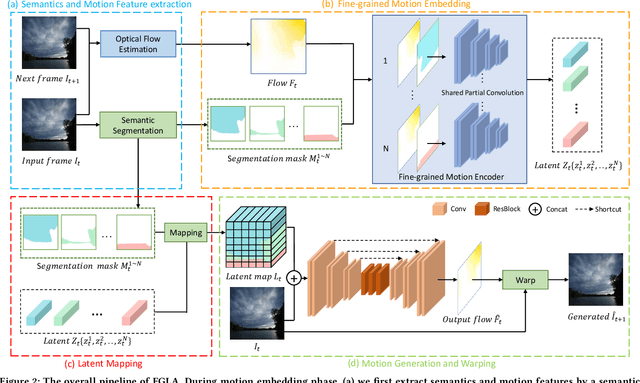
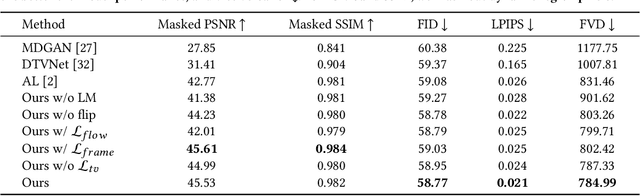
In this paper we focus on landscape animation, which aims to generate time-lapse videos from a single landscape image. Motion is crucial for landscape animation as it determines how objects move in videos. Existing methods are able to generate appealing videos by learning motion from real time-lapse videos. However, current methods suffer from inaccurate motion generation, which leads to unrealistic video results. To tackle this problem, we propose a model named FGLA to generate high-quality and realistic videos by learning Fine-Grained motion embedding for Landscape Animation. Our model consists of two parts: (1) a motion encoder which embeds time-lapse motion in a fine-grained way. (2) a motion generator which generates realistic motion to animate input images. To train and evaluate on diverse time-lapse videos, we build the largest high-resolution Time-lapse video dataset with Diverse scenes, namely Time-lapse-D, which includes 16,874 video clips with over 10 million frames. Quantitative and qualitative experimental results demonstrate the superiority of our method. In particular, our method achieves relative improvements by 19% on LIPIS and 5.6% on FVD compared with state-of-the-art methods on our dataset. A user study carried out with 700 human subjects shows that our approach visually outperforms existing methods by a large margin.
Lightweight Salient Object Detection in Optical Remote Sensing Images via Feature Correlation
Jan 20, 2022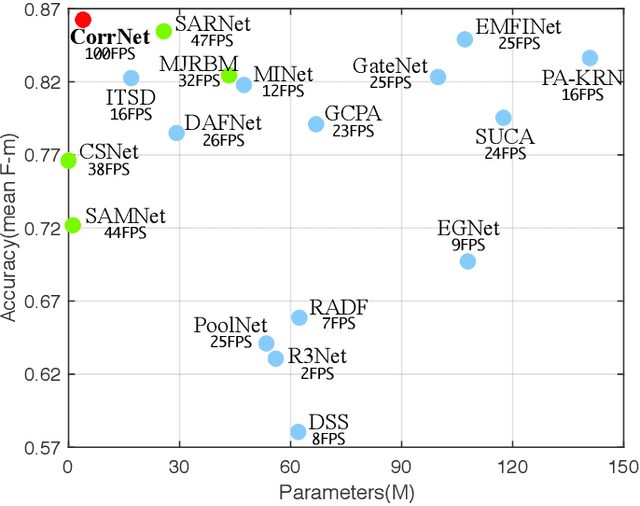
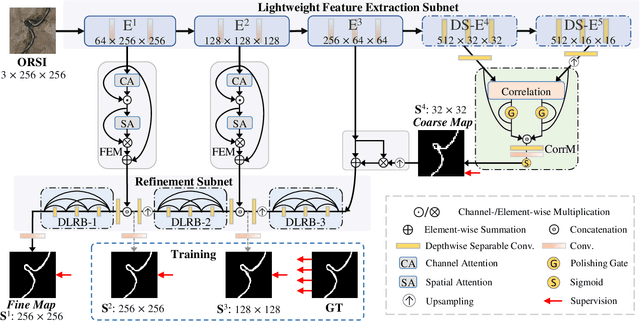
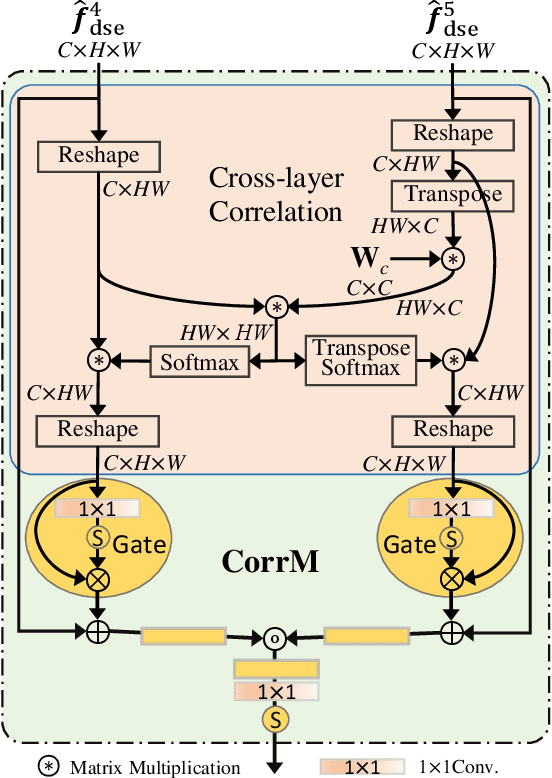
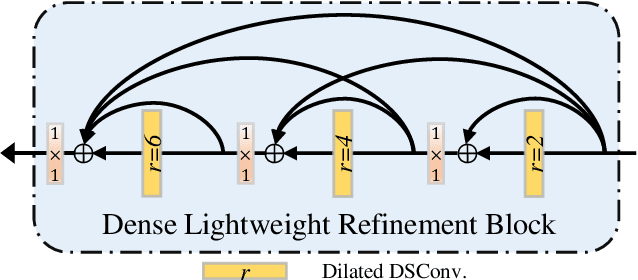
Salient object detection in optical remote sensing images (ORSI-SOD) has been widely explored for understanding ORSIs. However, previous methods focus mainly on improving the detection accuracy while neglecting the cost in memory and computation, which may hinder their real-world applications. In this paper, we propose a novel lightweight ORSI-SOD solution, named CorrNet, to address these issues. In CorrNet, we first lighten the backbone (VGG-16) and build a lightweight subnet for feature extraction. Then, following the coarse-to-fine strategy, we generate an initial coarse saliency map from high-level semantic features in a Correlation Module (CorrM). The coarse saliency map serves as the location guidance for low-level features. In CorrM, we mine the object location information between high-level semantic features through the cross-layer correlation operation. Finally, based on low-level detailed features, we refine the coarse saliency map in the refinement subnet equipped with Dense Lightweight Refinement Blocks, and produce the final fine saliency map. By reducing the parameters and computations of each component, CorrNet ends up having only 4.09M parameters and running with 21.09G FLOPs. Experimental results on two public datasets demonstrate that our lightweight CorrNet achieves competitive or even better performance compared with 26 state-of-the-art methods (including 16 large CNN-based methods and 2 lightweight methods), and meanwhile enjoys the clear memory and run time efficiency. The code and results of our method are available at https://github.com/MathLee/CorrNet.
SSP-Net: Scalable Sequential Pyramid Networks for Real-Time 3D Human Pose Regression
Sep 04, 2020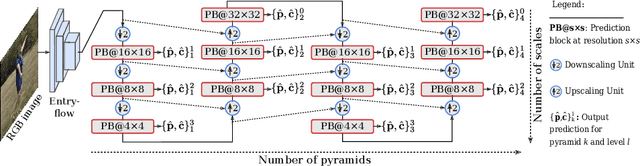
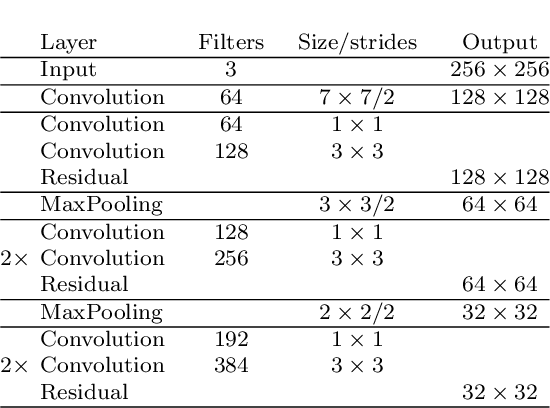
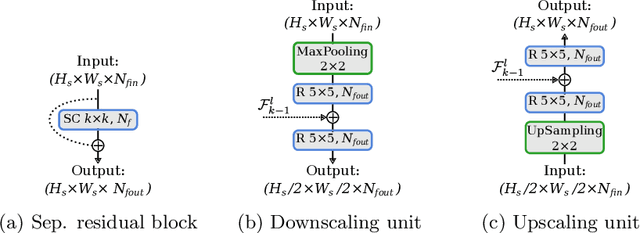
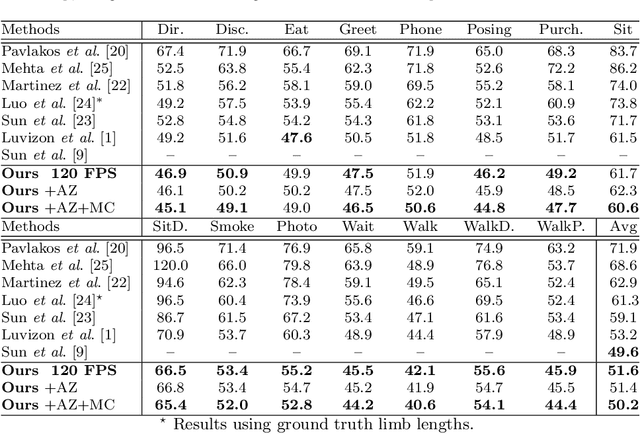
In this paper we propose a highly scalable convolutional neural network, end-to-end trainable, for real-time 3D human pose regression from still RGB images. We call this approach the Scalable Sequential Pyramid Networks (SSP-Net) as it is trained with refined supervision at multiple scales in a sequential manner. Our network requires a single training procedure and is capable of producing its best predictions at 120 frames per second (FPS), or acceptable predictions at more than 200 FPS when cut at test time. We show that the proposed regression approach is invariant to the size of feature maps, allowing our method to perform multi-resolution intermediate supervisions and reaching results comparable to the state-of-the-art with very low resolution feature maps. We demonstrate the accuracy and the effectiveness of our method by providing extensive experiments on two of the most important publicly available datasets for 3D pose estimation, Human3.6M and MPI-INF-3DHP. Additionally, we provide relevant insights about our decisions on the network architecture and show its flexibility to meet the best precision-speed compromise.
Practitioner-Centric Approach for Early Incident Detection Using Crowdsourced Data for Emergency Services
Dec 03, 2021
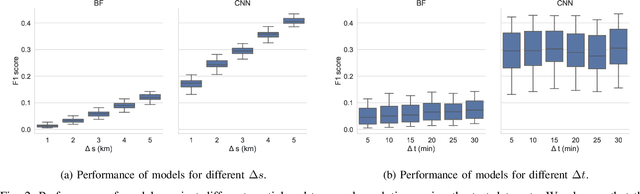
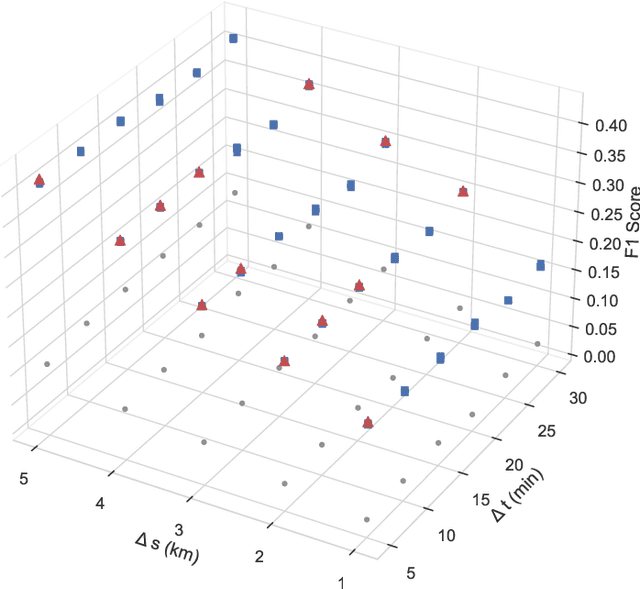
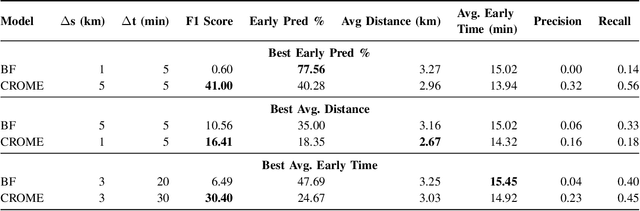
Emergency response is highly dependent on the time of incident reporting. Unfortunately, the traditional approach to receiving incident reports (e.g., calling 911 in the USA) has time delays. Crowdsourcing platforms such as Waze provide an opportunity for early identification of incidents. However, detecting incidents from crowdsourced data streams is difficult due to the challenges of noise and uncertainty associated with such data. Further, simply optimizing over detection accuracy can compromise spatial-temporal localization of the inference, thereby making such approaches infeasible for real-world deployment. This paper presents a novel problem formulation and solution approach for practitioner-centered incident detection using crowdsourced data by using emergency response management as a case-study. The proposed approach CROME (Crowdsourced Multi-objective Event Detection) quantifies the relationship between the performance metrics of incident classification (e.g., F1 score) and the requirements of model practitioners (e.g., 1 km. radius for incident detection). First, we show how crowdsourced reports, ground-truth historical data, and other relevant determinants such as traffic and weather can be used together in a Convolutional Neural Network (CNN) architecture for early detection of emergency incidents. Then, we use a Pareto optimization-based approach to optimize the output of the CNN in tandem with practitioner-centric parameters to balance detection accuracy and spatial-temporal localization. Finally, we demonstrate the applicability of this approach using crowdsourced data from Waze and traffic accident reports from Nashville, TN, USA. Our experiments demonstrate that the proposed approach outperforms existing approaches in incident detection while simultaneously optimizing the needs for real-world deployment and usability.
Scalable Machine Learning Architecture for Neonatal Seizure Detection on Ultra-Edge Devices
Nov 29, 2021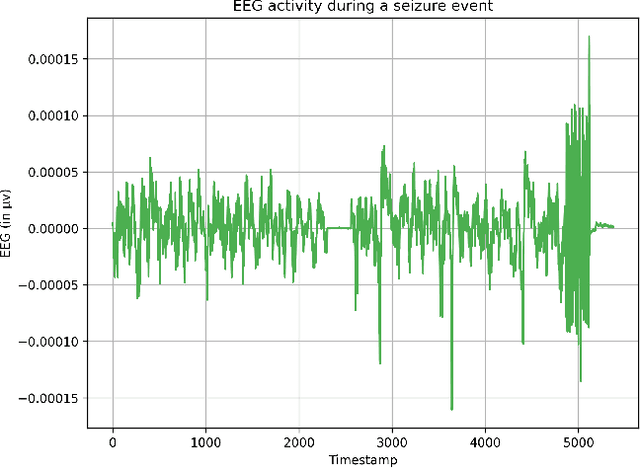
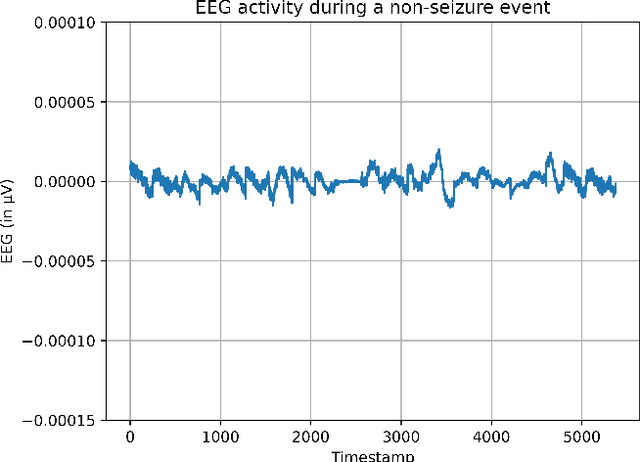
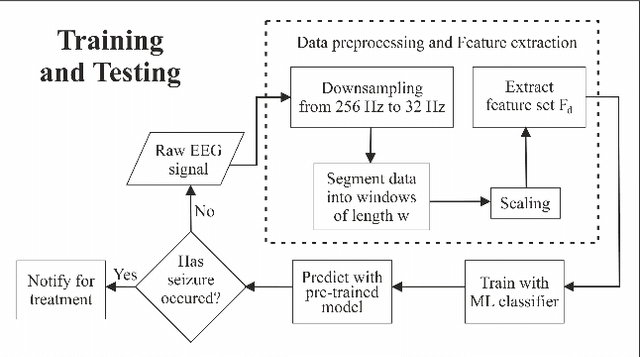
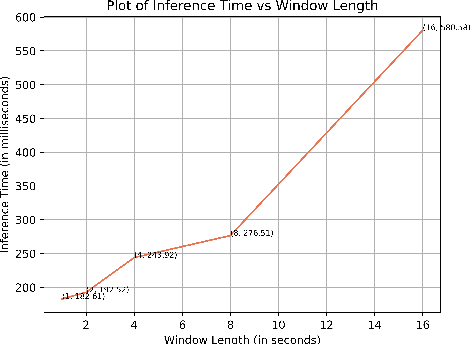
Neonatal seizures are a commonly encountered neurological condition. They are the first clinical signs of a serious neurological disorder. Thus, rapid recognition and treatment are necessary to prevent serious fatalities. The use of electroencephalography (EEG) in the field of neurology allows precise diagnosis of several medical conditions. However, interpreting EEG signals needs the attention of highly specialized staff since the infant brain is developmentally immature during the neonatal period. Detecting seizures on time could potentially prevent the negative effects on the neurocognitive development of the infants. In recent years, neonatal seizure detection using machine learning algorithms have been gaining traction. Since there is a need for the classification of bio-signals to be computationally inexpensive in the case of seizure detection, this research presents a machine learning (ML) based architecture that operates with comparable predictive performance as previous models but with minimum level configuration. The proposed classifier was trained and tested on a public dataset of NICU seizures recorded at the Helsinki University Hospital. Our architecture achieved a best sensitivity of 87%, which is 6% more than that of the standard ML model chosen in this study. The model size of the ML classifier is optimized to just 4.84 KB with minimum prediction time of 182.61 milliseconds, thus enabling it to be deployed on wearable ultra-edge devices for quick and accurate response and obviating the need for cloud-based and other such exhaustive computational methods.
Adapting Bandit Algorithms for Settings with Sequentially Available Arms
Sep 30, 2021
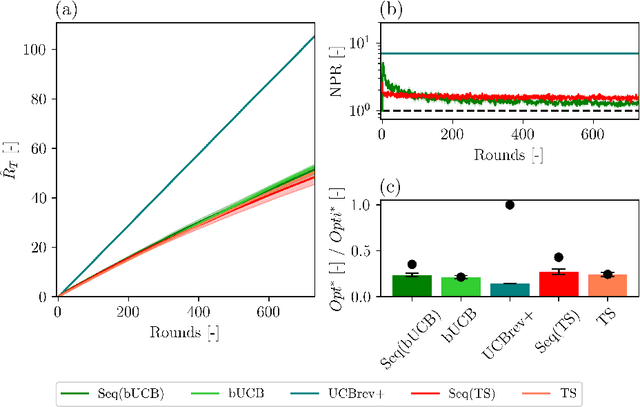
Although the classical version of the Multi-Armed Bandits (MAB) framework has been applied successfully to several practical problems, in many real-world applications, the possible actions are not presented to the learner simultaneously, such as in the Internet campaign management and environmental monitoring settings. Instead, in such applications, a set of options is presented sequentially to the learner within a time span, and this process is repeated throughout a time horizon. At each time, the learner is asked whether to select the proposed option or not. We define this scenario as the Sequential Pull/No-pull Bandit setting, and we propose a meta-algorithm, namely Sequential Pull/No-pull for MAB (Seq), to adapt any classical MAB policy to better suit this setting for both the regret minimization and best-arm identification problems. By allowing the selection of multiple arms within a round, the proposed meta-algorithm gathers more information, especially in the first rounds, characterized by a high uncertainty in the arms estimate value. At the same time, the adapted algorithms provide the same theoretical guarantees as the classical policy employed. The Seq meta-algorithm was extensively tested and compared with classical MAB policies on synthetic and real-world datasets from advertising and environmental monitoring applications, highlighting its good empirical performances.
Digital RIS (DRIS): The Future of Digital Beam Management in RIS-Assisted OWC Systems
Dec 18, 2021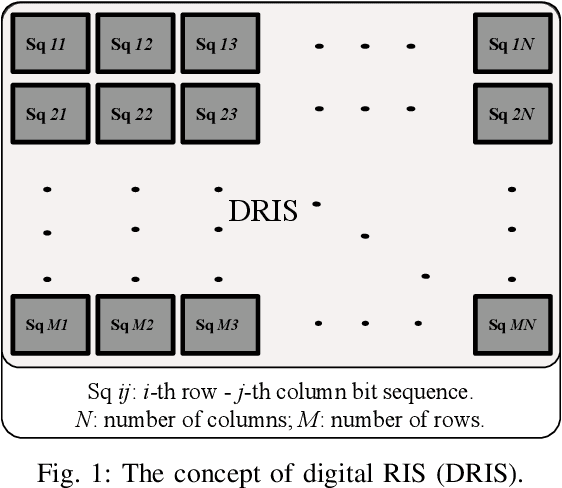
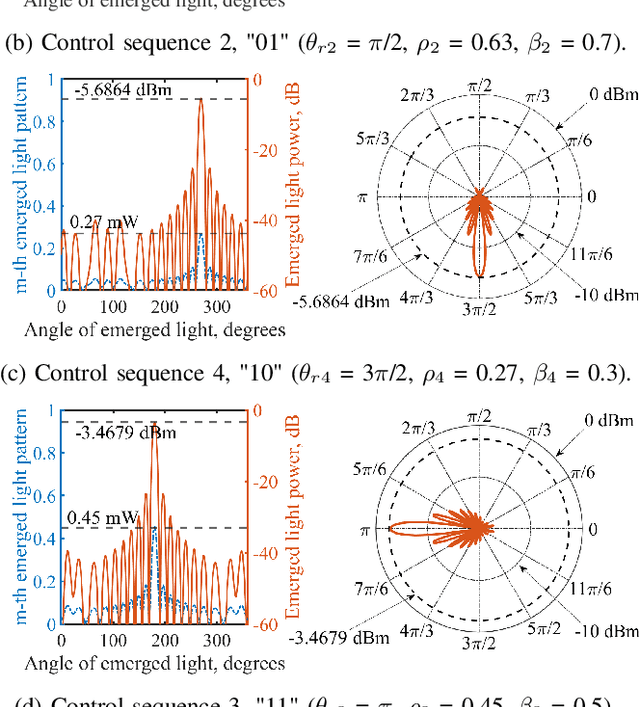
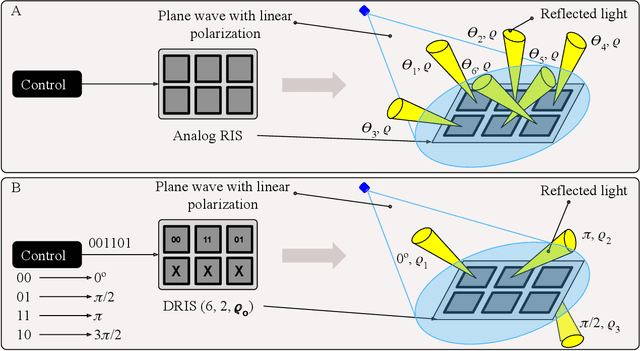
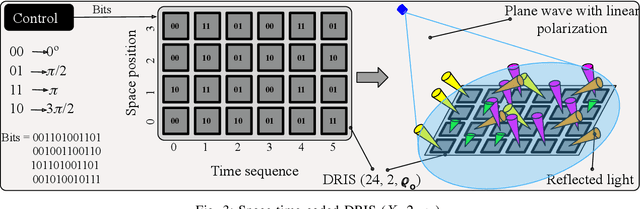
Reconfigurable intelligent surfaces (RIS) have been recently introduced to optical wireless communication (OWC) networks to resolve skip areas and improve the signal-to-noise ratio at the user's end. In OWC networks, RIS are based on mirrors or metasurfaces. Metasurfaces have evolved significantly over the last few years. As a result, coding, digital, programmable, and information metamaterials have been developed. The advantage of these materials is that they can enable digital signal processing (DSP) techniques. For the first time, this paper proposes the use of digital RIS (DRIS) in OWC systems. We discuss the concept of DRIS and the application of DSP methods to the physical material. In addition, we examine metamaterials for optical DRIS with liquid crystals serving as the front row material. Finally, we present a design example and discuss future research directions.