 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DBC-Forest: Deep forest with binning confidence screening
Dec 25, 2021
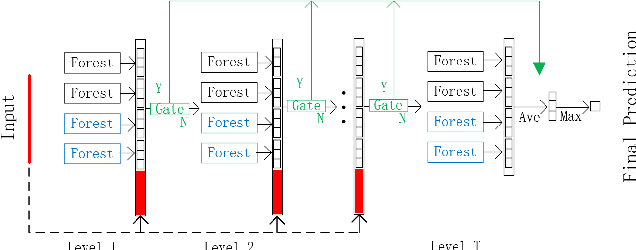
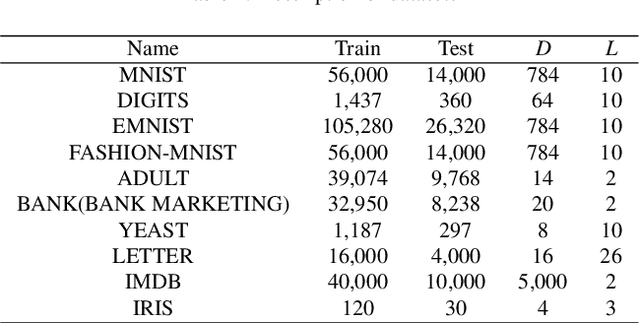
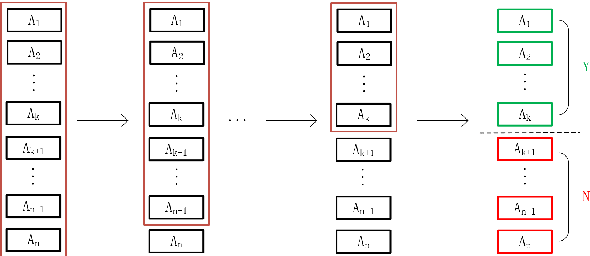
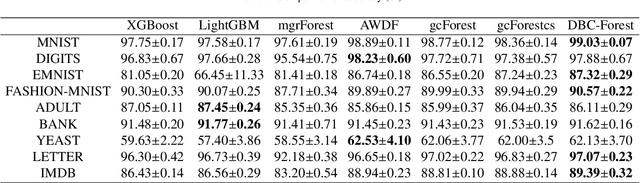
As a deep learning model, deep confidence screening forest (gcForestcs) has achieved great success in various applications. Compared with the traditional deep forest approach, gcForestcs effectively reduces the high time cost by passing some instances in the high-confidence region directly to the final stage. However, there is a group of instances with low accuracy in the high-confidence region, which are called mis-partitioned instances. To find these mis-partitioned instances, this paper proposes a deep binning confidence screening forest (DBC-Forest) model, which packs all instances into bins based on their confidences. In this way, more accurate instances can be passed to the final stage, and the performance is improved. Experimental results show that DBC-Forest achieves highly accurate predictions for the same hyperparameters and is faster than other similar models to achieve the same accuracy.
Fast Hand Detection in Collaborative Learning Environments
Oct 13, 2021

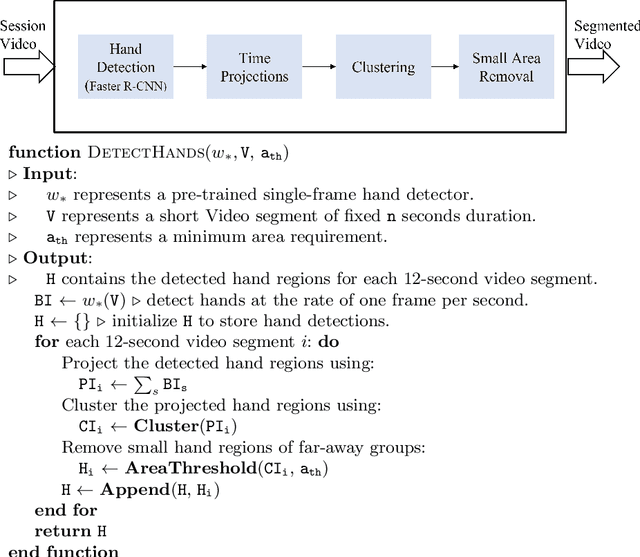

Long-term object detection requires the integration of frame-based results over several seconds. For non-deformable objects, long-term detection is often addressed using object detection followed by video tracking. Unfortunately, tracking is inapplicable to objects that undergo dramatic changes in appearance from frame to frame. As a related example, we study hand detection over long video recordings in collaborative learning environments. More specifically, we develop long-term hand detection methods that can deal with partial occlusions and dramatic changes in appearance. Our approach integrates object-detection, followed by time projections, clustering, and small region removal to provide effective hand detection over long videos. The hand detector achieved average precision (AP) of 72% at 0.5 intersection over union (IoU). The detection results were improved to 81% by using our optimized approach for data augmentation. The method runs at 4.7x the real-time with AP of 81% at 0.5 intersection over the union. Our method reduced the number of false-positive hand detections by 80% by improving IoU ratios from 0.2 to 0.5. The overall hand detection system runs at 4x real-time.
Delay-Oriented Distributed Scheduling Using Graph Neural Networks
Nov 13, 2021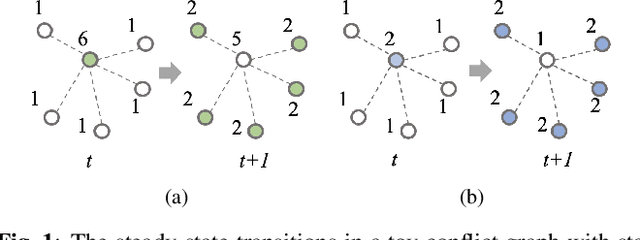
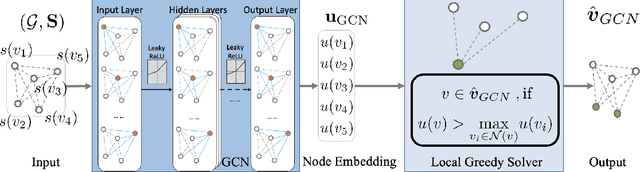
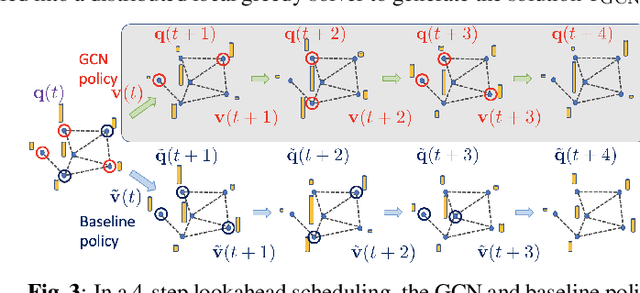
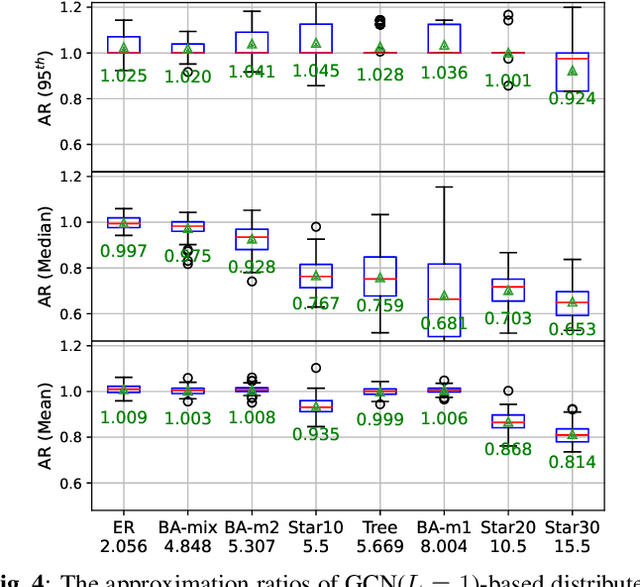
In wireless multi-hop networks, delay is an important metric for many applications. However, the max-weight scheduling algorithms in the literature typically focus on instantaneous optimality, in which the schedule is selected by solving a maximum weighted independent set (MWIS) problem on the interference graph at each time slot. These myopic policies perform poorly in delay-oriented scheduling, in which the dependency between the current backlogs of the network and the schedule of the previous time slot needs to be considered. To address this issue, we propose a delay-oriented distributed scheduler based on graph convolutional networks (GCNs). In a nutshell, a trainable GCN module generates node embeddings that capture the network topology as well as multi-step lookahead backlogs, before calling a distributed greedy MWIS solver. In small- to medium-sized wireless networks with heterogeneous transmit power, where a few central links have many interfering neighbors, our proposed distributed scheduler can outperform the myopic schedulers based on greedy and instantaneously optimal MWIS solvers, with good generalizability across graph models and minimal increase in communication complexity.
Efficient Dynamic Graph Representation Learning at Scale
Dec 14, 2021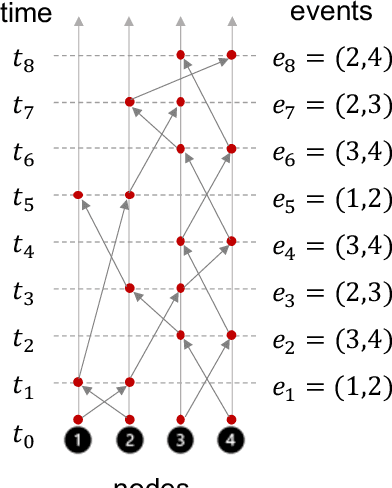
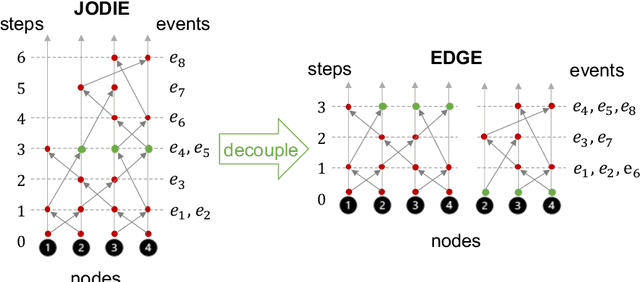
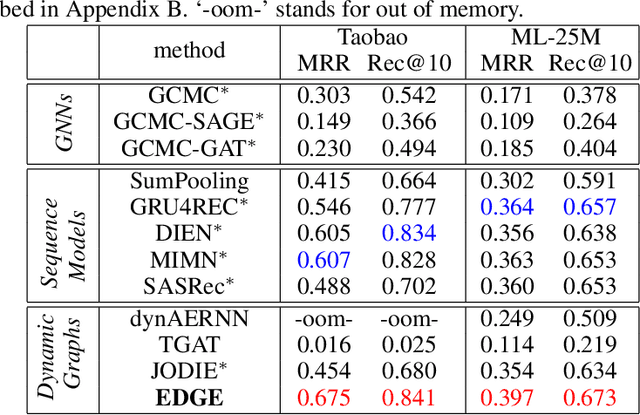
Dynamic graphs with ordered sequences of events between nodes are prevalent in real-world industrial applications such as e-commerce and social platforms. However, representation learning for dynamic graphs has posed great computational challenges due to the time and structure dependency and irregular nature of the data, preventing such models from being deployed to real-world applications. To tackle this challenge, we propose an efficient algorithm, Efficient Dynamic Graph lEarning (EDGE), which selectively expresses certain temporal dependency via training loss to improve the parallelism in computations. We show that EDGE can scale to dynamic graphs with millions of nodes and hundreds of millions of temporal events and achieve new state-of-the-art (SOTA) performance.
Optimizing Diffusion Rate and Label Reliability in a Graph-Based Semi-supervised Classifier
Jan 10, 2022
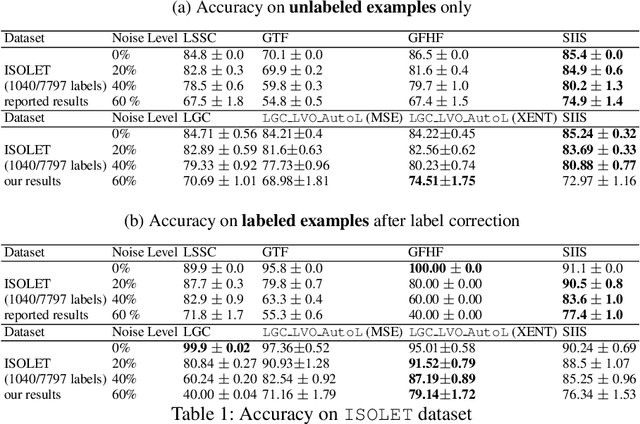
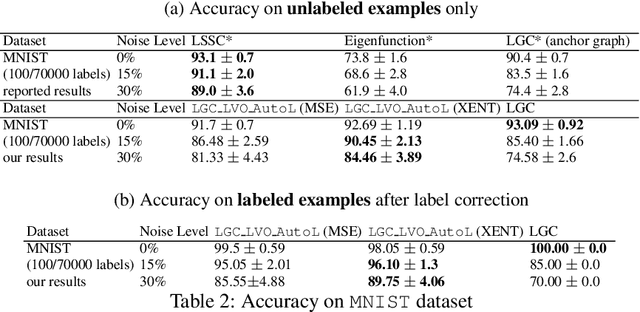
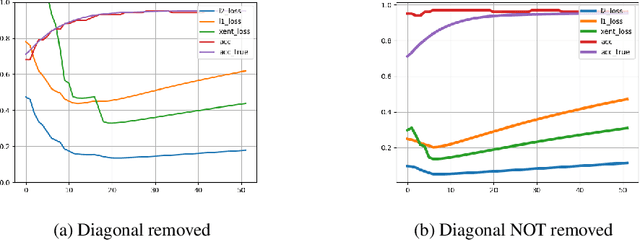
Semi-supervised learning has received attention from researchers, as it allows one to exploit the structure of unlabeled data to achieve competitive classification results with much fewer labels than supervised approaches. The Local and Global Consistency (LGC) algorithm is one of the most well-known graph-based semi-supervised (GSSL) classifiers. Notably, its solution can be written as a linear combination of the known labels. The coefficients of this linear combination depend on a parameter $\alpha$, determining the decay of the reward over time when reaching labeled vertices in a random walk. In this work, we discuss how removing the self-influence of a labeled instance may be beneficial, and how it relates to leave-one-out error. Moreover, we propose to minimize this leave-one-out loss with automatic differentiation. Within this framework, we propose methods to estimate label reliability and diffusion rate. Optimizing the diffusion rate is more efficiently accomplished with a spectral representation. Results show that the label reliability approach competes with robust L1-norm methods and that removing diagonal entries reduces the risk of overfitting and leads to suitable criteria for parameter selection.
Deep Reinforcement Learning for Electric Vehicle Routing Problem with Time Windows
Oct 05, 2020
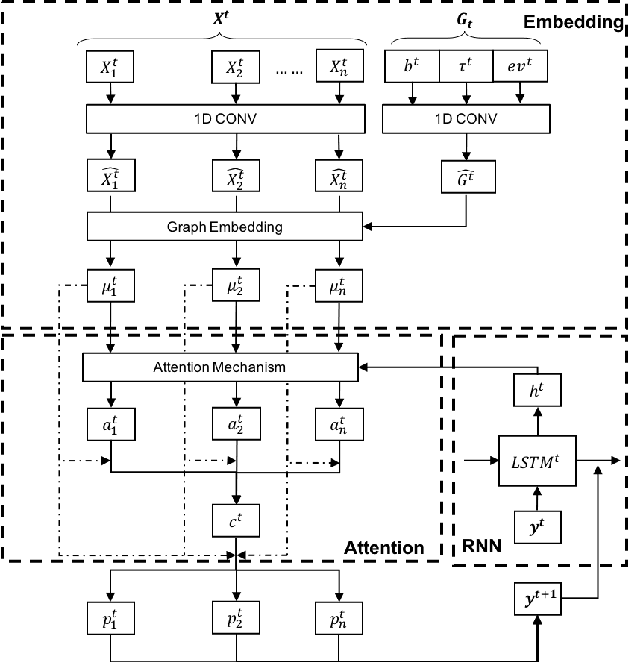
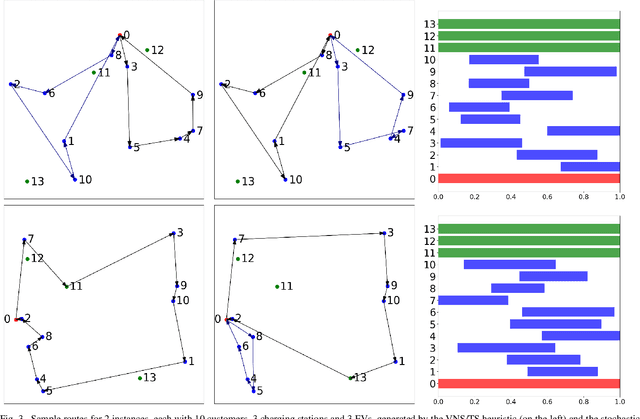
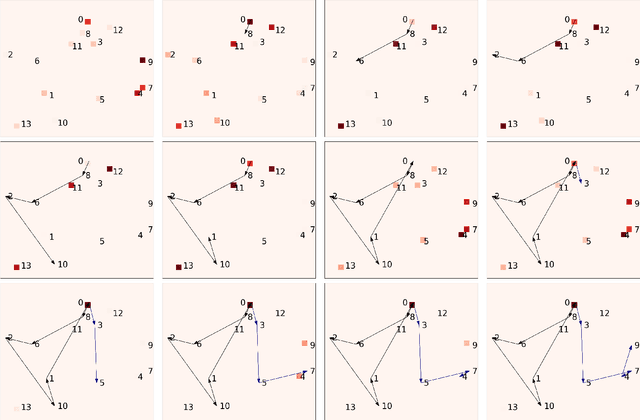
The past decade has seen a rapid penetration of electric vehicles (EV) in the market, more and more logistics and transportation companies start to deploy EVs for service provision. In order to model the operations of a commercial EV fleet, we utilize the EV routing problem with time windows (EVRPTW). In this research, we propose an end-to-end deep reinforcement learning framework to solve the EVRPTW. In particular, we develop an attention model incorporating the pointer network and a graph embedding technique to parameterize a stochastic policy for solving the EVRPTW. The model is then trained using policy gradient with rollout baseline. Our numerical studies show that the proposed model is able to efficiently solve EVRPTW instances of large sizes that are not solvable with any existing approaches.
Analysis of lane-change conflict between cars and trucks at merging section using UAV video data
Jan 05, 2022The freeway on-ramp merging section is often identified as a crash-prone spot due to the high frequency of traffic conflicts. Very few traffic conflict analysis studies comprehensively consider different vehicle types at freeway merging section. Thus, the main objective of this study is to analyse conflicts between different vehicle types at freeway merging section. Field data are collected by Unmanned Aerial Vehicle (UAV) at merging areas in Shanghai, China. Vehicle extraction method is utilized to obtain vehicle trajectories. Time-to-collision (TTC) is utilized as the surrogate safety measure. TTC of car-car conflicts are the smallest while TTC of truck-truck conflicts are the largest. Traffic conflicts frequently occur at on-ramp and acceleration lane. Results show the spatial distribution of lane-change conflicts is significantly different between different vehicle types, suggesting that vehicle drivers should maintain safe distance especially car drivers. Besides, in order to decrease lane-change conflict at merging area, traffic management agencies are suggested to change dotted lie to solid lane at the beginning of acceleration lane.
Large-scale nonlinear Granger causality: A data-driven, multivariate approach to recovering directed networks from short time-series data
Sep 10, 2020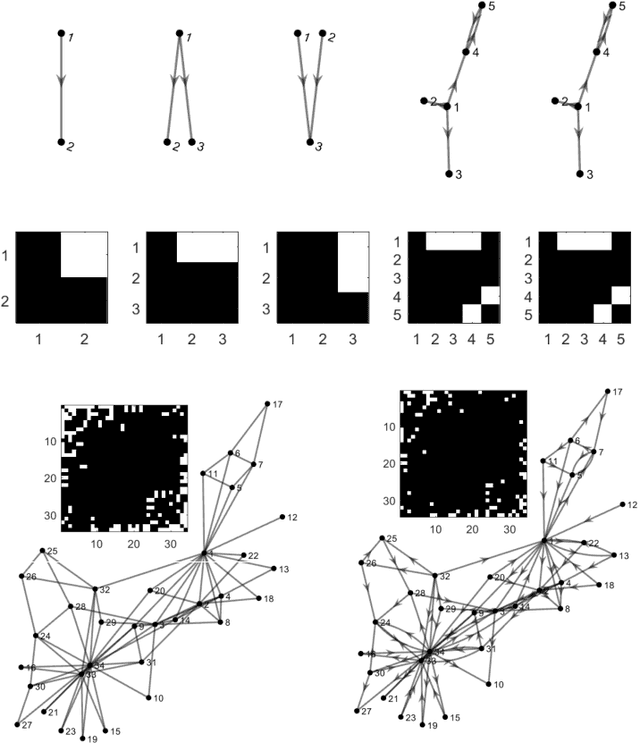
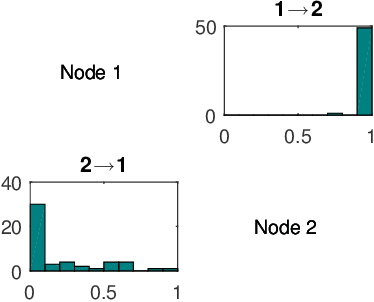
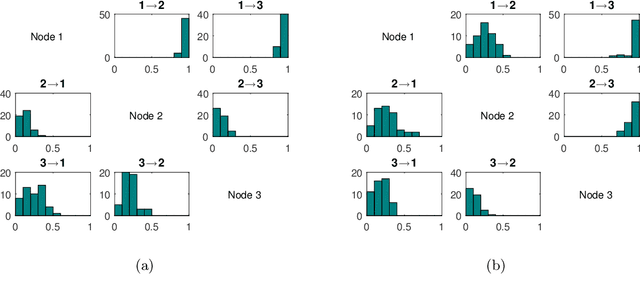
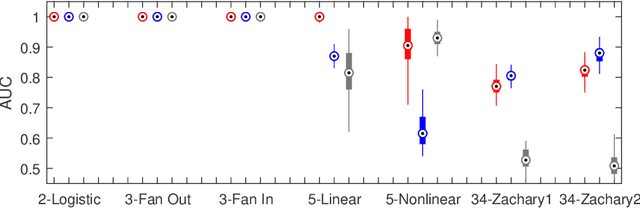
To gain insight into complex systems it is a key challenge to infer nonlinear causal directional relations from observational time-series data. Specifically, estimating causal relationships between interacting components in large systems with only short recordings over few temporal observations remains an important, yet unresolved problem. Here, we introduce a large-scale Nonlinear Granger Causality (lsNGC) approach for inferring directional, nonlinear, multivariate causal interactions between system components from short high-dimensional time-series recordings. By modeling interactions with nonlinear state-space transformations from limited observational data, lsNGC identifies casual relations with no explicit a priori assumptions on functional interdependence between component time-series in a computationally efficient manner. Additionally, our method provides a mathematical formulation revealing statistical significance of inferred causal relations. We extensively study the ability of lsNGC to recovering network structure from two-node to thirty-four node chaotic time-series systems. Our results suggest that lsNGC captures meaningful interactions from limited observational data, where it performs favorably when compared to traditionally used methods. Finally, we demonstrate the applicability of lsNGC to estimating causality in large, real-world systems by inferring directional nonlinear, multivariate causal relationships among a large number of relatively short time-series acquired from functional Magnetic Resonance Imaging (fMRI) data of the human brain.
A study of the Multicriteria decision analysis based on the time-series features and a TOPSIS method proposal for a tensorial approach
Oct 21, 2020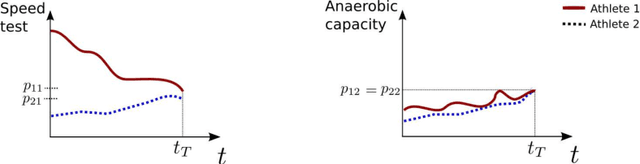
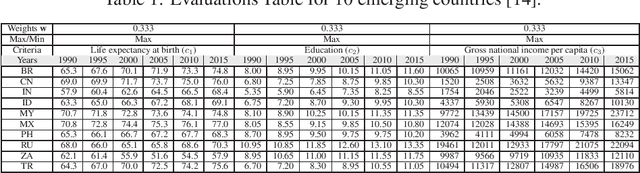
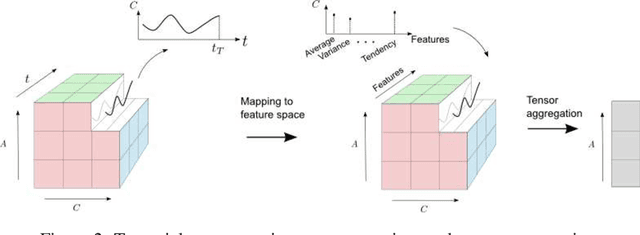
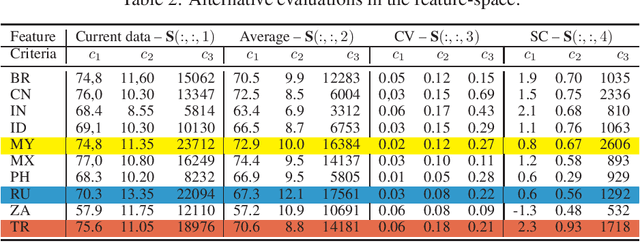
A number of Multiple Criteria Decision Analysis (MCDA) methods have been developed to rank alternatives based on several decision criteria. Usually, MCDA methods deal with the criteria value at the time the decision is made without considering their evolution over time. However, it may be relevant to consider the criteria' time series since providing essential information for decision-making (e.g., an improvement of the criteria). To deal with this issue, we propose a new approach to rank the alternatives based on the criteria time-series features (tendency, variance, etc.). In this novel approach, the data is structured in three dimensions, which require a more complex data structure, as the \textit{tensors}, instead of the classical matrix representation used in MCDA. Consequently, we propose an extension for the TOPSIS method to handle a tensor rather than a matrix. Computational results reveal that it is possible to rank the alternatives from a new perspective by considering meaningful decision-making information.
SSP-Net: Scalable Sequential Pyramid Networks for Real-Time 3D Human Pose Regression
Sep 04, 2020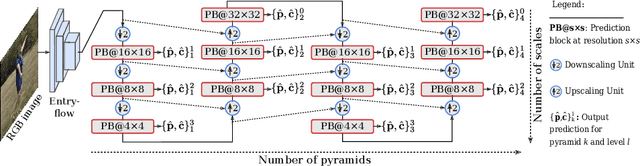
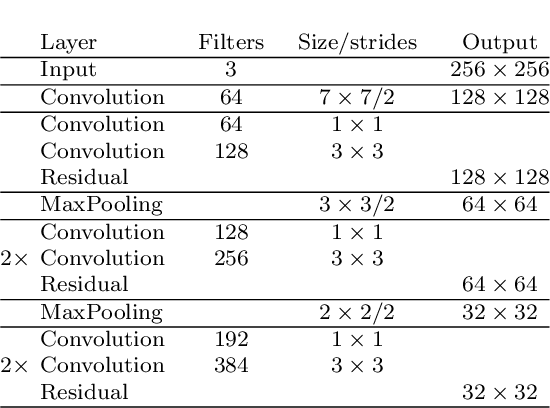
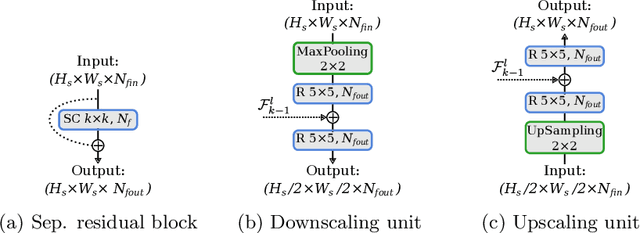
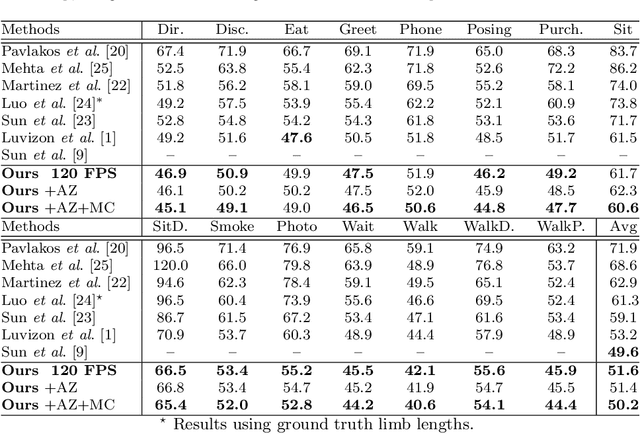
In this paper we propose a highly scalable convolutional neural network, end-to-end trainable, for real-time 3D human pose regression from still RGB images. We call this approach the Scalable Sequential Pyramid Networks (SSP-Net) as it is trained with refined supervision at multiple scales in a sequential manner. Our network requires a single training procedure and is capable of producing its best predictions at 120 frames per second (FPS), or acceptable predictions at more than 200 FPS when cut at test time. We show that the proposed regression approach is invariant to the size of feature maps, allowing our method to perform multi-resolution intermediate supervisions and reaching results comparable to the state-of-the-art with very low resolution feature maps. We demonstrate the accuracy and the effectiveness of our method by providing extensive experiments on two of the most important publicly available datasets for 3D pose estimation, Human3.6M and MPI-INF-3DHP. Additionally, we provide relevant insights about our decisions on the network architecture and show its flexibility to meet the best precision-speed compromise.