 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LLMs Among Us: Generative AI Participating in Digital Discourse
Feb 08, 2024
The emergence of Large Language Models (LLMs) has great potential to reshape the landscape of many social media platforms. While this can bring promising opportunities, it also raises many threats, such as biases and privacy concerns, and may contribute to the spread of propaganda by malicious actors. We developed the "LLMs Among Us" experimental framework on top of the Mastodon social media platform for bot and human participants to communicate without knowing the ratio or nature of bot and human participants. We built 10 personas with three different LLMs, GPT-4, LLama 2 Chat, and Claude. We conducted three rounds of the experiment and surveyed participants after each round to measure the ability of LLMs to pose as human participants without human detection. We found that participants correctly identified the nature of other users in the experiment only 42% of the time despite knowing the presence of both bots and humans. We also found that the choice of persona had substantially more impact on human perception than the choice of mainstream LLMs.
UFO: A UI-Focused Agent for Windows OS Interaction
Feb 08, 2024We introduce UFO, an innovative UI-Focused agent to fulfill user requests tailored to applications on Windows OS, harnessing the capabilities of GPT-Vision. UFO employs a dual-agent framework to meticulously observe and analyze the graphical user interface (GUI) and control information of Windows applications. This enables the agent to seamlessly navigate and operate within individual applications and across them to fulfill user requests, even when spanning multiple applications. The framework incorporates a control interaction module, facilitating action grounding without human intervention and enabling fully automated execution. Consequently, UFO transforms arduous and time-consuming processes into simple tasks achievable solely through natural language commands. We conducted testing of UFO across 9 popular Windows applications, encompassing a variety of scenarios reflective of users' daily usage. The results, derived from both quantitative metrics and real-case studies, underscore the superior effectiveness of UFO in fulfilling user requests. To the best of our knowledge, UFO stands as the first UI agent specifically tailored for task completion within the Windows OS environment. The open-source code for UFO is available on https://github.com/microsoft/UFO.
Sample Complexity Characterization for Linear Contextual MDPs
Feb 05, 2024Contextual Markov decision processes (CMDPs) describe a class of reinforcement learning problems in which the transition kernels and reward functions can change over time with different MDPs indexed by a context variable. While CMDPs serve as an important framework to model many real-world applications with time-varying environments, they are largely unexplored from theoretical perspective. In this paper, we study CMDPs under two linear function approximation models: Model I with context-varying representations and common linear weights for all contexts; and Model II with common representations for all contexts and context-varying linear weights. For both models, we propose novel model-based algorithms and show that they enjoy guaranteed $\epsilon$-suboptimality gap with desired polynomial sample complexity. In particular, instantiating our result for the first model to the tabular CMDP improves the existing result by removing the reachability assumption. Our result for the second model is the first-known result for such a type of function approximation models. Comparison between our results for the two models further indicates that having context-varying features leads to much better sample efficiency than having common representations for all contexts under linear CMDPs.
REACT: Two Datasets for Analyzing Both Human Reactions and Evaluative Feedback to Robots Over Time
Jan 31, 2024Recent work in Human-Robot Interaction (HRI) has shown that robots can leverage implicit communicative signals from users to understand how they are being perceived during interactions. For example, these signals can be gaze patterns, facial expressions, or body motions that reflect internal human states. To facilitate future research in this direction, we contribute the REACT database, a collection of two datasets of human-robot interactions that display users' natural reactions to robots during a collaborative game and a photography scenario. Further, we analyze the datasets to show that interaction history is an important factor that can influence human reactions to robots. As a result, we believe that future models for interpreting implicit feedback in HRI should explicitly account for this history. REACT opens up doors to this possibility in the future.
Masked LoGoNet: Fast and Accurate 3D Image Analysis for Medical Domain
Feb 09, 2024Standard modern machine-learning-based imaging methods have faced challenges in medical applications due to the high cost of dataset construction and, thereby, the limited labeled training data available. Additionally, upon deployment, these methods are usually used to process a large volume of data on a daily basis, imposing a high maintenance cost on medical facilities. In this paper, we introduce a new neural network architecture, termed LoGoNet, with a tailored self-supervised learning (SSL) method to mitigate such challenges. LoGoNet integrates a novel feature extractor within a U-shaped architecture, leveraging Large Kernel Attention (LKA) and a dual encoding strategy to capture both long-range and short-range feature dependencies adeptly. This is in contrast to existing methods that rely on increasing network capacity to enhance feature extraction. This combination of novel techniques in our model is especially beneficial in medical image segmentation, given the difficulty of learning intricate and often irregular body organ shapes, such as the spleen. Complementary, we propose a novel SSL method tailored for 3D images to compensate for the lack of large labeled datasets. The method combines masking and contrastive learning techniques within a multi-task learning framework and is compatible with both Vision Transformer (ViT) and CNN-based models. We demonstrate the efficacy of our methods in numerous tasks across two standard datasets (i.e., BTCV and MSD). Benchmark comparisons with eight state-of-the-art models highlight LoGoNet's superior performance in both inference time and accuracy.
Wasserstein proximal operators describe score-based generative models and resolve memorization
Feb 09, 2024We focus on the fundamental mathematical structure of score-based generative models (SGMs). We first formulate SGMs in terms of the Wasserstein proximal operator (WPO) and demonstrate that, via mean-field games (MFGs), the WPO formulation reveals mathematical structure that describes the inductive bias of diffusion and score-based models. In particular, MFGs yield optimality conditions in the form of a pair of coupled partial differential equations: a forward-controlled Fokker-Planck (FP) equation, and a backward Hamilton-Jacobi-Bellman (HJB) equation. Via a Cole-Hopf transformation and taking advantage of the fact that the cross-entropy can be related to a linear functional of the density, we show that the HJB equation is an uncontrolled FP equation. Second, with the mathematical structure at hand, we present an interpretable kernel-based model for the score function which dramatically improves the performance of SGMs in terms of training samples and training time. In addition, the WPO-informed kernel model is explicitly constructed to avoid the recently studied memorization effects of score-based generative models. The mathematical form of the new kernel-based models in combination with the use of the terminal condition of the MFG reveals new explanations for the manifold learning and generalization properties of SGMs, and provides a resolution to their memorization effects. Finally, our mathematically informed, interpretable kernel-based model suggests new scalable bespoke neural network architectures for high-dimensional applications.
Model Editing with Canonical Examples
Feb 09, 2024We introduce model editing with canonical examples, a setting in which (1) a single learning example is provided per desired behavior, (2) evaluation is performed exclusively out-of-distribution, and (3) deviation from an initial model is strictly limited. A canonical example is a simple instance of good behavior, e.g., The capital of Mauritius is Port Louis) or bad behavior, e.g., An aspect of researchers is coldhearted). The evaluation set contains more complex examples of each behavior (like a paragraph in which the capital of Mauritius is called for.) We create three datasets and modify three more for model editing with canonical examples, covering knowledge-intensive improvements, social bias mitigation, and syntactic edge cases. In our experiments on Pythia language models, we find that LoRA outperforms full finetuning and MEMIT. We then turn to the Backpack language model architecture because it is intended to enable targeted improvement. The Backpack defines a large bank of sense vectors--a decomposition of the different uses of each word--which are weighted and summed to form the output logits of the model. We propose sense finetuning, which selects and finetunes a few ($\approx$ 10) sense vectors for each canonical example, and find that it outperforms other finetuning methods, e.g., 4.8% improvement vs 0.3%. Finally, we improve GPT-J-6B by an inference-time ensemble with just the changes from sense finetuning of a 35x smaller Backpack, in one setting outperforming editing GPT-J itself (4.1% vs 1.0%).
Low Complexity Turbo SIC-MMSE Detection for Orthogonal Time Frequency Space Modulation
Jan 19, 2024Recently, orthogonal time frequency space (OTFS) modulation has garnered considerable attention due to its robustness against doubly-selective wireless channels. In this paper, we propose a low-complexity iterative successive interference cancellation based minimum mean squared error (SIC-MMSE) detection algorithm for zero-padded OTFS (ZP-OTFS) modulation. In the proposed algorithm, signals are detected based on layers processed by multiple SIC-MMSE linear filters for each sub-channel, with interference on the targeted signal layer being successively canceled either by hard or soft information. To reduce the complexity of computing individual layer filter coefficients, we also propose a novel filter coefficients recycling approach in place of generating the exact form of MMSE filter weights. Moreover, we design a joint detection and decoding algorithm for ZP-OTFS to enhance error performance. Compared to the conventional SIC-MMSE detection, our proposed algorithms outperform other linear detectors, e.g., maximal ratio combining (MRC), for ZP-OTFS with up to 3 dB gain while maintaining comparable computation complexity.
A Survey of Offline and Online Learning-Based Algorithms for Multirotor UAVs
Feb 06, 2024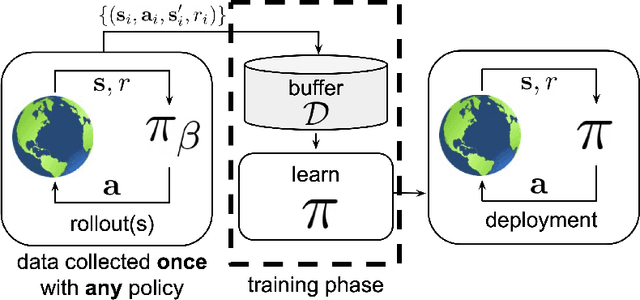
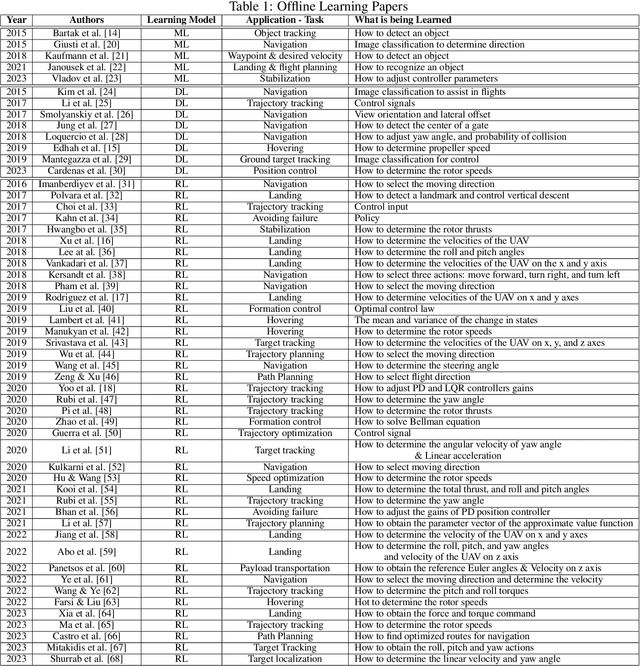
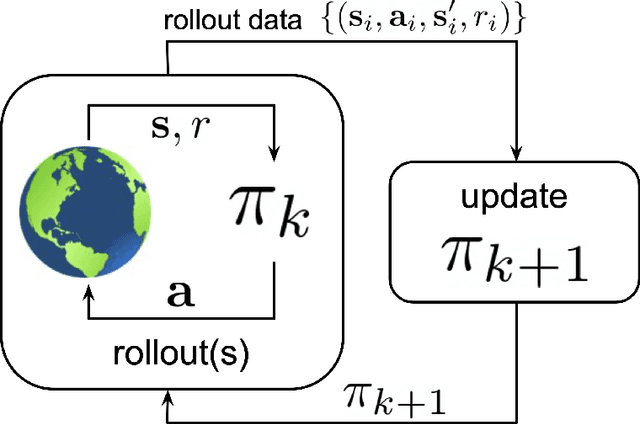
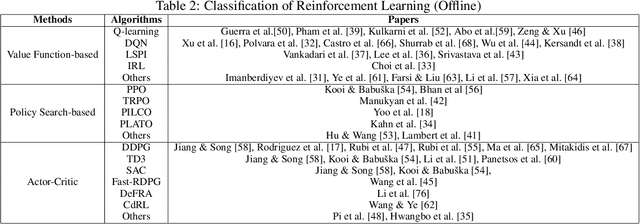
Multirotor UAVs are used for a wide spectrum of civilian and public domain applications. Navigation controllers endowed with different attributes and onboard sensor suites enable multirotor autonomous or semi-autonomous, safe flight, operation, and functionality under nominal and detrimental conditions and external disturbances, even when flying in uncertain and dynamically changing environments. During the last decade, given the faster-than-exponential increase of available computational power, different learning-based algorithms have been derived, implemented, and tested to navigate and control, among other systems, multirotor UAVs. Learning algorithms have been, and are used to derive data-driven based models, to identify parameters, to track objects, to develop navigation controllers, and to learn the environment in which multirotors operate. Learning algorithms combined with model-based control techniques have been proven beneficial when applied to multirotors. This survey summarizes published research since 2015, dividing algorithms, techniques, and methodologies into offline and online learning categories, and then, further classifying them into machine learning, deep learning, and reinforcement learning sub-categories. An integral part and focus of this survey are on online learning algorithms as applied to multirotors with the aim to register the type of learning techniques that are either hard or almost hard real-time implementable, as well as to understand what information is learned, why, and how, and how fast. The outcome of the survey offers a clear understanding of the recent state-of-the-art and of the type and kind of learning-based algorithms that may be implemented, tested, and executed in real-time.
Voronoi Candidates for Bayesian Optimization
Feb 07, 2024Bayesian optimization (BO) offers an elegant approach for efficiently optimizing black-box functions. However, acquisition criteria demand their own challenging inner-optimization, which can induce significant overhead. Many practical BO methods, particularly in high dimension, eschew a formal, continuous optimization of the acquisition function and instead search discretely over a finite set of space-filling candidates. Here, we propose to use candidates which lie on the boundary of the Voronoi tessellation of the current design points, so they are equidistant to two or more of them. We discuss strategies for efficient implementation by directly sampling the Voronoi boundary without explicitly generating the tessellation, thus accommodating large designs in high dimension. On a battery of test problems optimized via Gaussian processes with expected improvement, our proposed approach significantly improves the execution time of a multi-start continuous search without a loss in accuracy.