 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian Learning via Neural Schrödinger-Föllmer Flows
Nov 26, 2021

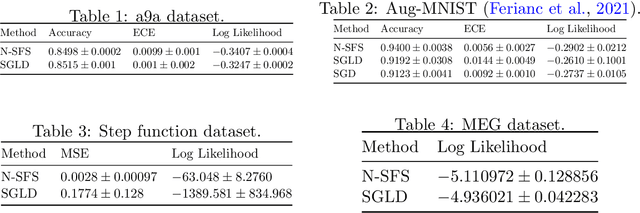
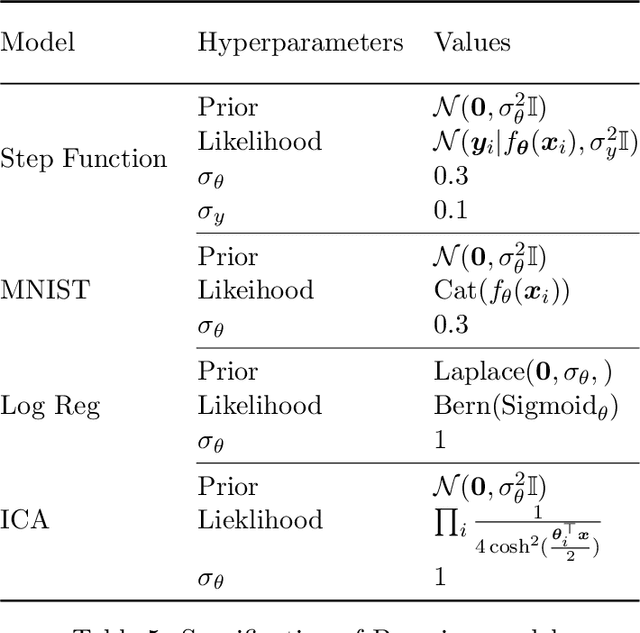
In this work we explore a new framework for approximate Bayesian inference in large datasets based on stochastic control. We advocate stochastic control as a finite time alternative to popular steady-state methods such as stochastic gradient Langevin dynamics (SGLD). Furthermore, we discuss and adapt the existing theoretical guarantees of this framework and establish connections to already existing VI routines in SDE-based models.
Time Series Forecasting Using LSTM Networks: A Symbolic Approach
Mar 12, 2020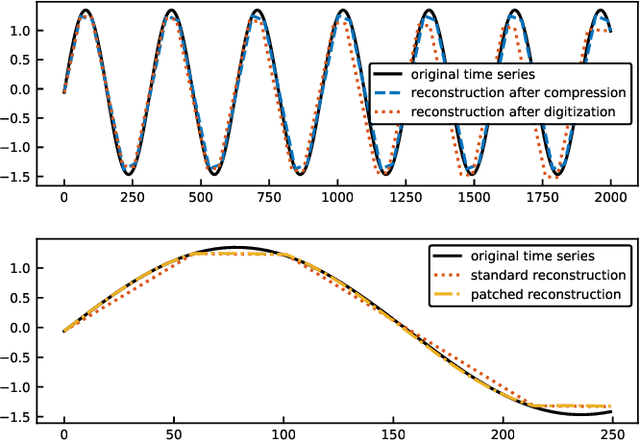
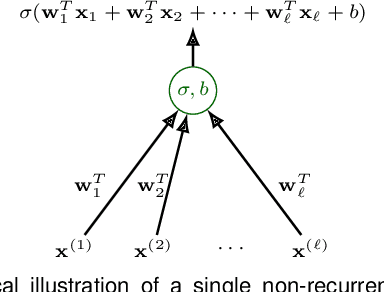
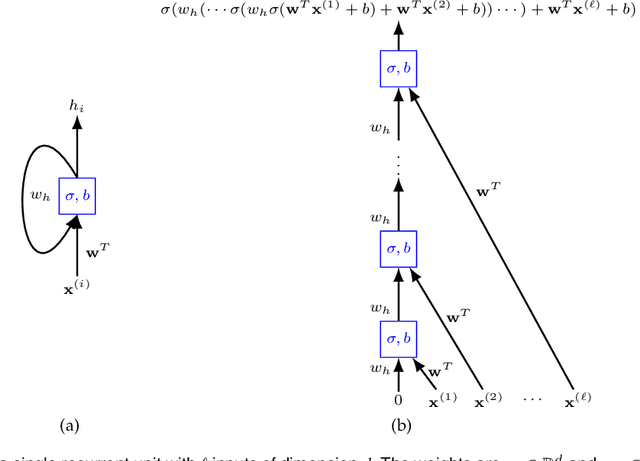
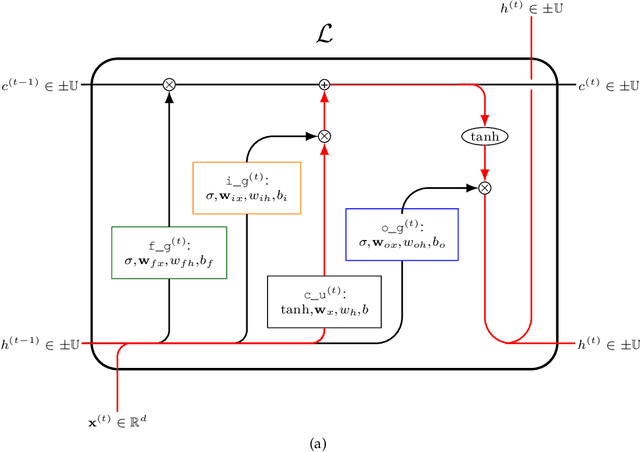
Machine learning methods trained on raw numerical time series data exhibit fundamental limitations such as a high sensitivity to the hyper parameters and even to the initialization of random weights. A combination of a recurrent neural network with a dimension-reducing symbolic representation is proposed and applied for the purpose of time series forecasting. It is shown that the symbolic representation can help to alleviate some of the aforementioned problems and, in addition, might allow for faster training without sacrificing the forecast performance.
Bayesian nonparametric shared multi-sequence time series segmentation
Jan 27, 2020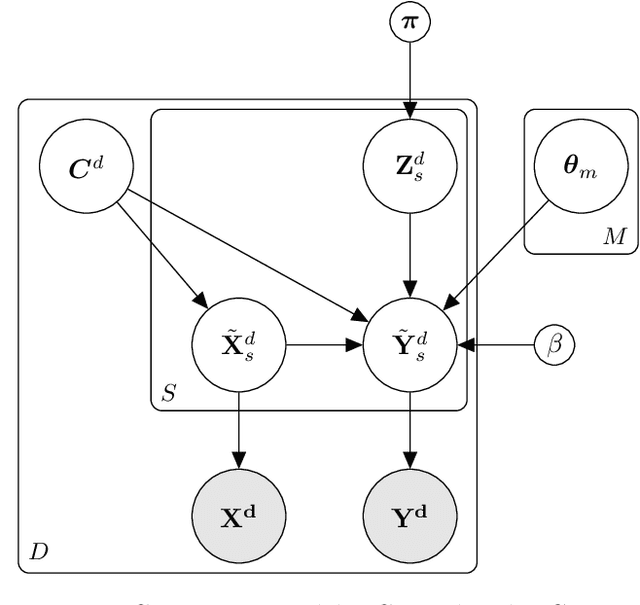
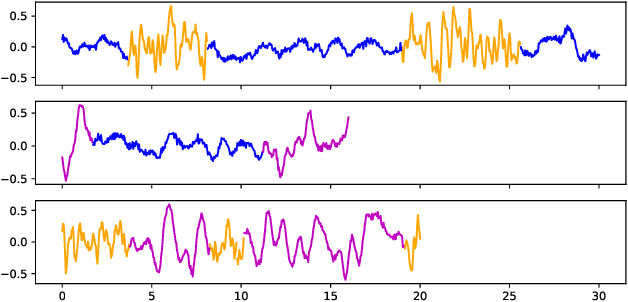
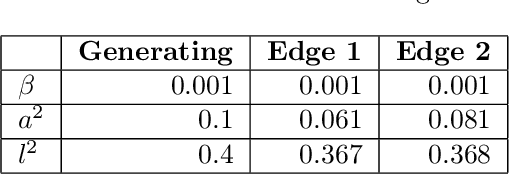
In this paper, we introduce a method for segmenting time series data using tools from Bayesian nonparametrics. We consider the task of temporal segmentation of a set of time series data into representative stationary segments. We use Gaussian process (GP) priors to impose our knowledge about the characteristics of the underlying stationary segments, and use a nonparametric distribution to partition the sequences into such segments, formulated in terms of a prior distribution on segment length. Given the segmentation, the model can be viewed as a variant of a Gaussian mixture model where the mixture components are described using the covariance function of a GP. We demonstrate the effectiveness of our model on synthetic data as well as on real time-series data of heartbeats where the task is to segment the indicative types of beats and to classify the heartbeat recordings into classes that correspond to healthy and abnormal heart sounds.
Profile Guided Optimization without Profiles: A Machine Learning Approach
Jan 04, 2022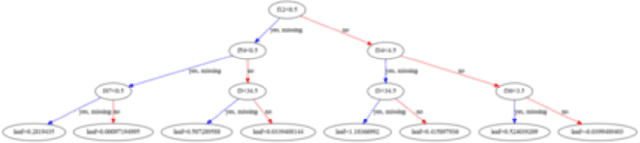

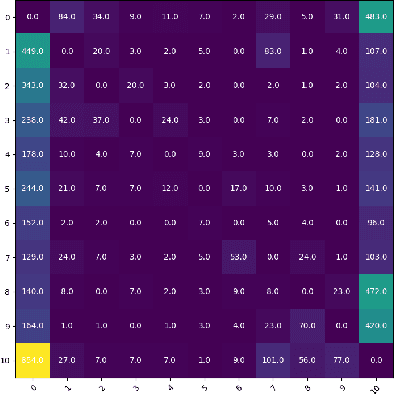
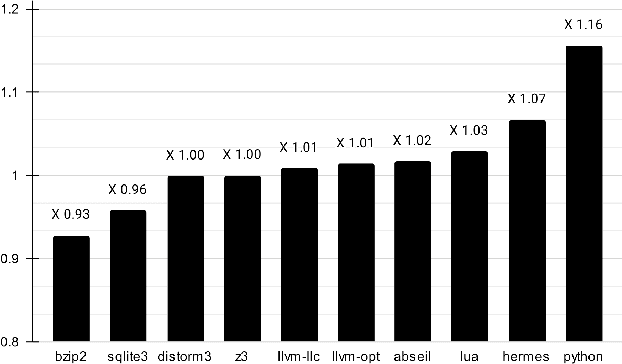
Profile guided optimization is an effective technique for improving the optimization ability of compilers based on dynamic behavior, but collecting profile data is expensive, cumbersome, and requires regular updating to remain fresh. We present a novel statistical approach to inferring branch probabilities that improves the performance of programs that are compiled without profile guided optimizations. We perform offline training using information that is collected from a large corpus of binaries that have branch probabilities information. The learned model is used by the compiler to predict the branch probabilities of regular uninstrumented programs, which the compiler can then use to inform optimization decisions. We integrate our technique directly in LLVM, supplementing the existing human-engineered compiler heuristics. We evaluate our technique on a suite of benchmarks, demonstrating some gains over compiling without profile information. In deployment, our technique requires no profiling runs and has negligible effect on compilation time.
Rejection sampling from shape-constrained distributions in sublinear time
May 29, 2021
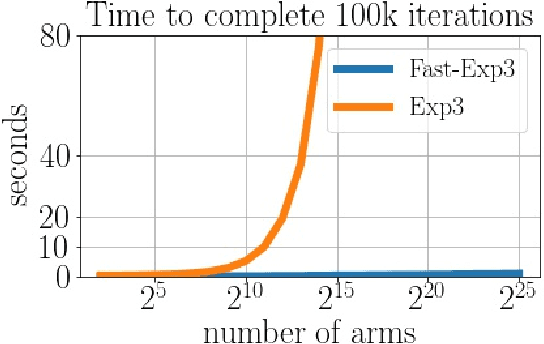
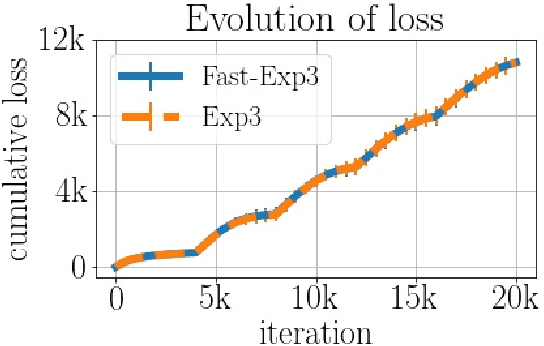
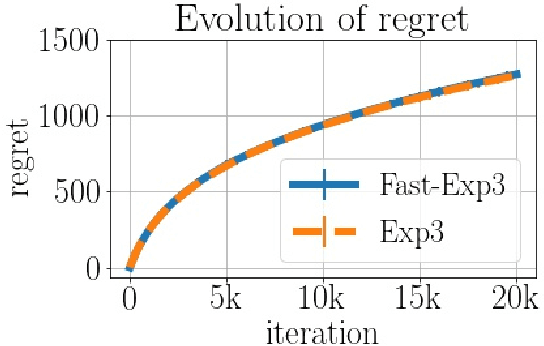
We consider the task of generating exact samples from a target distribution, known up to normalization, over a finite alphabet. The classical algorithm for this task is rejection sampling, and although it has been used in practice for decades, there is surprisingly little study of its fundamental limitations. In this work, we study the query complexity of rejection sampling in a minimax framework for various classes of discrete distributions. Our results provide new algorithms for sampling whose complexity scales sublinearly with the alphabet size. When applied to adversarial bandits, we show that a slight modification of the Exp3 algorithm reduces the per-iteration complexity from $\mathcal O(K)$ to $\mathcal O(\log^2 K)$, where $K$ is the number of arms.
FedMed-GAN: Federated Multi-Modal Unsupervised Brain Image Synthesis
Jan 22, 2022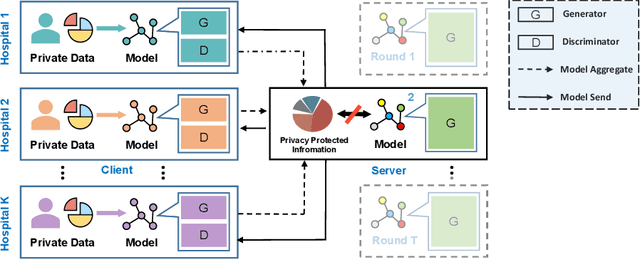

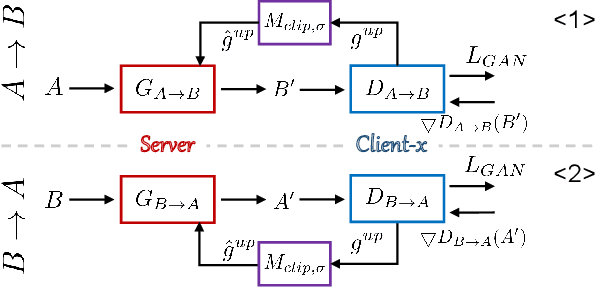
Utilizing the paired multi-modal neuroimaging data has been proved to be effective to investigate human cognitive activities and certain pathologies. However, it is not practical to obtain the full set of paired neuroimaging data centrally since the collection faces several constraints, e.g., high examination costs, long acquisition time, and even image corruption. In addition, most of the paired neuroimaging data are dispersed into different medical institutions and cannot group together for centralized training considering the privacy issues. Under the circumstance, there is a clear need to launch federated learning and facilitate the integration of other unpaired data from different hospitals or data owners. In this paper, we build up a new benchmark for federated multi-modal unsupervised brain image synthesis (termed as FedMed-GAN) to bridge the gap between federated learning and medical GAN. Moreover, based on the similarity of edge information across multi-modal neuroimaging data, we propose a novel edge loss to solve the generative mode collapse issue of FedMed-GAN and mitigate the performance drop resulting from differential privacy. Compared with the state-of-the-art method shown in our built benchmark, our novel edge loss could significantly speed up the generator convergence rate without sacrificing performance under different unpaired data distribution settings.
SLISEMAP: Explainable Dimensionality Reduction
Jan 12, 2022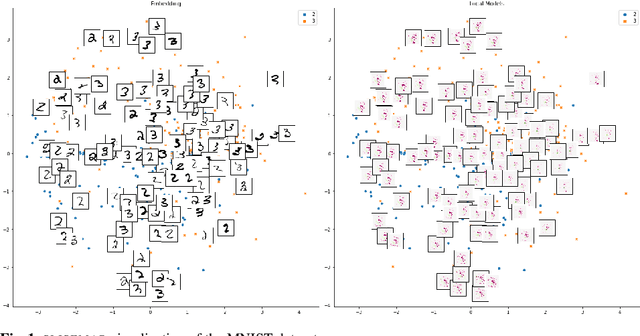
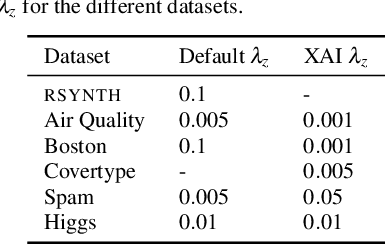
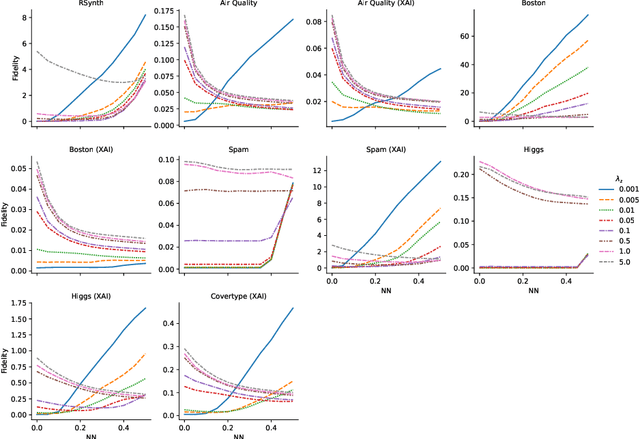
Existing explanation methods for black-box supervised learning models generally work by building local models that explain the models behaviour for a particular data item. It is possible to make global explanations, but the explanations may have low fidelity for complex models. Most of the prior work on explainable models has been focused on classification problems, with less attention on regression. We propose a new manifold visualization method, SLISEMAP, that at the same time finds local explanations for all of the data items and builds a two-dimensional visualization of model space such that the data items explained by the same model are projected nearby. We provide an open source implementation of our methods, implemented by using GPU-optimized PyTorch library. SLISEMAP works both on classification and regression models. We compare SLISEMAP to most popular dimensionality reduction methods and some local explanation methods. We provide mathematical derivation of our problem and show that SLISEMAP provides fast and stable visualizations that can be used to explain and understand black box regression and classification models.
A data-centric weak supervised learning for highway traffic incident detection
Dec 17, 2021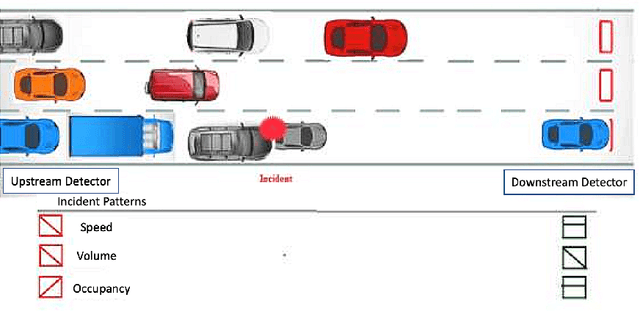
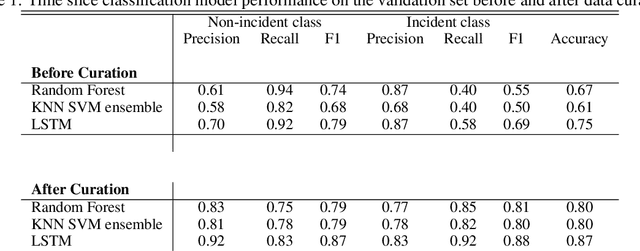
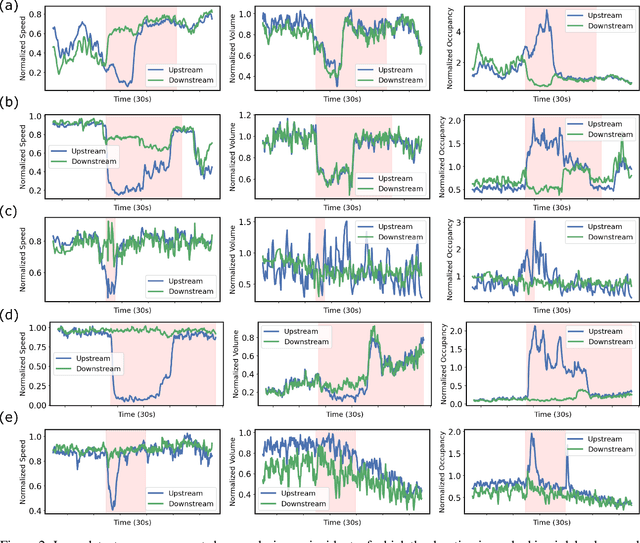
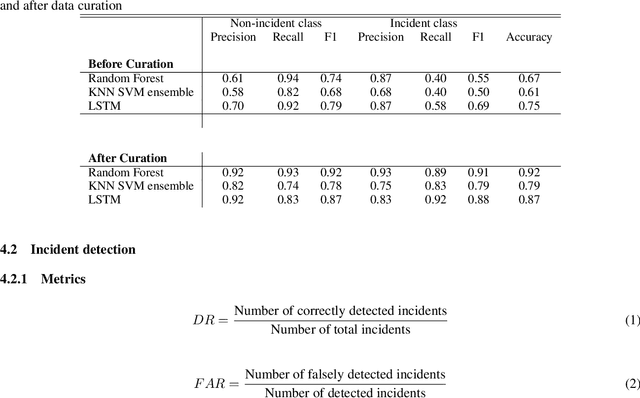
Using the data from loop detector sensors for near-real-time detection of traffic incidents in highways is crucial to averting major traffic congestion. While recent supervised machine learning methods offer solutions to incident detection by leveraging human-labeled incident data, the false alarm rate is often too high to be used in practice. Specifically, the inconsistency in the human labeling of the incidents significantly affects the performance of supervised learning models. To that end, we focus on a data-centric approach to improve the accuracy and reduce the false alarm rate of traffic incident detection on highways. We develop a weak supervised learning workflow to generate high-quality training labels for the incident data without the ground truth labels, and we use those generated labels in the supervised learning setup for final detection. This approach comprises three stages. First, we introduce a data preprocessing and curation pipeline that processes traffic sensor data to generate high-quality training data through leveraging labeling functions, which can be domain knowledge-related or simple heuristic rules. Second, we evaluate the training data generated by weak supervision using three supervised learning models -- random forest, k-nearest neighbors, and a support vector machine ensemble -- and long short-term memory classifiers. The results show that the accuracy of all of the models improves significantly after using the training data generated by weak supervision. Third, we develop an online real-time incident detection approach that leverages the model ensemble and the uncertainty quantification while detecting incidents. Overall, we show that our proposed weak supervised learning workflow achieves a high incident detection rate (0.90) and low false alarm rate (0.08).
Exploring the Impact of Virtualization on the Usability of the Deep Learning Applications
Dec 17, 2021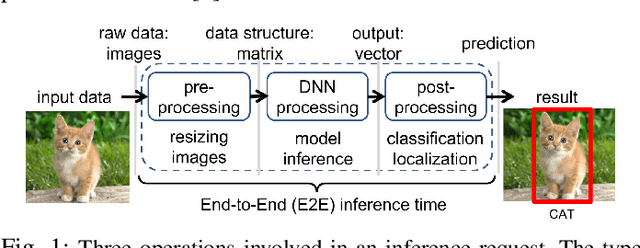
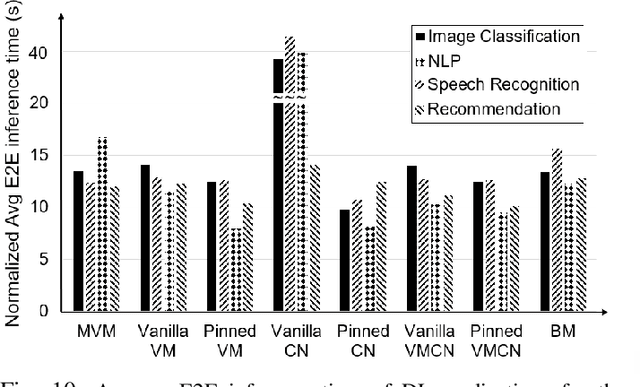
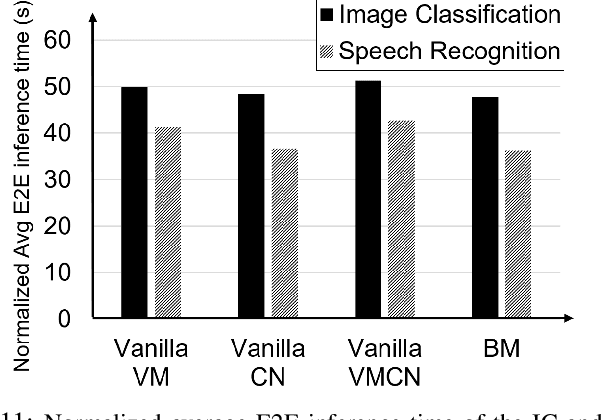
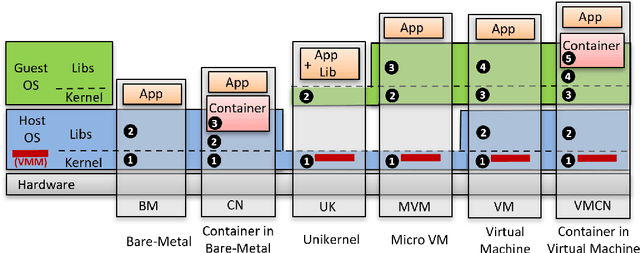
Deep Learning-based (DL) applications are becoming increasingly popular and advancing at an unprecedented pace. While many research works are being undertaken to enhance Deep Neural Networks (DNN) -- the centerpiece of DL applications -- practical deployment challenges of these applications in the Cloud and Edge systems, and their impact on the usability of the applications have not been sufficiently investigated. In particular, the impact of deploying different virtualization platforms, offered by the Cloud and Edge, on the usability of DL applications (in terms of the End-to-End (E2E) inference time) has remained an open question. Importantly, resource elasticity (by means of scale-up), CPU pinning, and processor type (CPU vs GPU) configurations have shown to be influential on the virtualization overhead. Accordingly, the goal of this research is to study the impact of these potentially decisive deployment options on the E2E performance, thus, usability of the DL applications. To that end, we measure the impact of four popular execution platforms (namely, bare-metal, virtual machine (VM), container, and container in VM) on the E2E inference time of four types of DL applications, upon changing processor configuration (scale-up, CPU pinning) and processor types. This study reveals a set of interesting and sometimes counter-intuitive findings that can be used as best practices by Cloud solution architects to efficiently deploy DL applications in various systems. The notable finding is that the solution architects must be aware of the DL application characteristics, particularly, their pre- and post-processing requirements, to be able to optimally choose and configure an execution platform, determine the use of GPU, and decide the efficient scale-up range.
Landscape of Neural Architecture Search across sensors: how much do they differ ?
Jan 17, 2022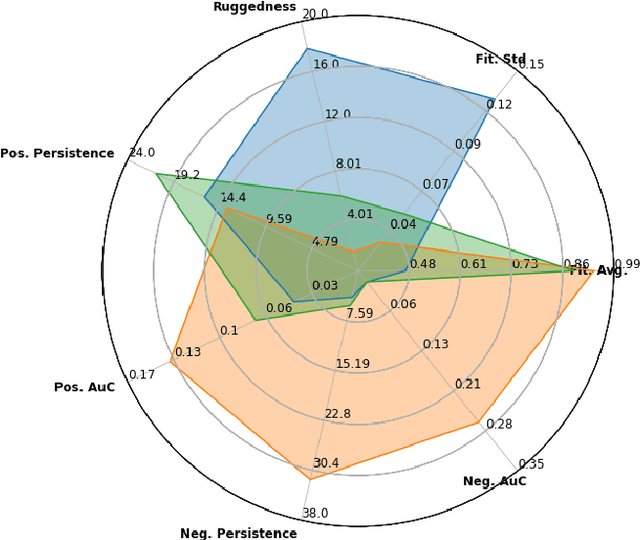
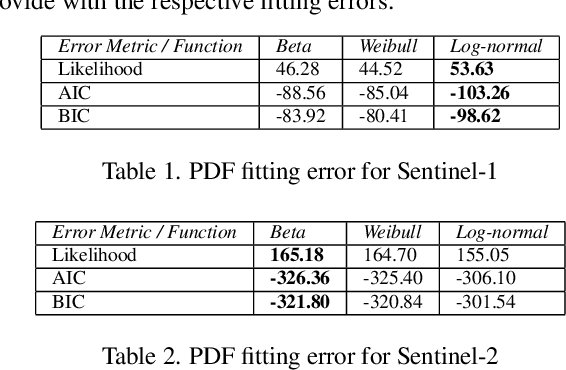

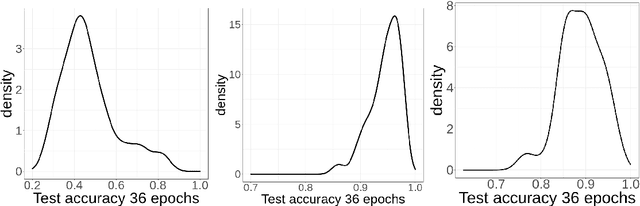
With the rapid rise of neural architecture search, the ability to understand its complexity from the perspective of a search algorithm is desirable. Recently, Traor\'e et al. have proposed the framework of Fitness Landscape Footprint to help describe and compare neural architecture search problems. It attempts at describing why a search strategy might be successful, struggle or fail on a target task. Our study leverages this methodology in the context of searching across sensors, including sensor data fusion. In particular, we apply the Fitness Landscape Footprint to the real-world image classification problem of So2Sat LCZ42, in order to identify the most beneficial sensor to our neural network hyper-parameter optimization problem. From the perspective of distributions of fitness, our findings indicate a similar behaviour of the search space for all sensors: the longer the training time, the larger the overall fitness, and more flatness in the landscapes (less ruggedness and deviation). Regarding sensors, the better the fitness they enable (Sentinel-2), the better the search trajectories (smoother, higher persistence). Results also indicate very similar search behaviour for sensors that can be decently fitted by the search space (Sentinel-2 and fusion).