 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Can Old TREC Collections Reliably Evaluate Modern Neural Retrieval Models?
Jan 26, 2022
Neural retrieval models are generally regarded as fundamentally different from the retrieval techniques used in the late 1990's when the TREC ad hoc test collections were constructed. They thus provide the opportunity to empirically test the claim that pooling-built test collections can reliably evaluate retrieval systems that did not contribute to the construction of the collection (in other words, that such collections can be reusable). To test the reusability claim, we asked TREC assessors to judge new pools created from new search results for the TREC-8 ad hoc collection. These new search results consisted of five new runs (one each from three transformer-based models and two baseline runs that use BM25) plus the set of TREC-8 submissions that did not previously contribute to pools. The new runs did retrieve previously unseen documents, but the vast majority of those documents were not relevant. The ranking of all runs by mean evaluation score when evaluated using the official TREC-8 relevance judgment set and the newly expanded relevance set are almost identical, with Kendall's tau correlations greater than 0.99. Correlations for individual topics are also high. The TREC-8 ad hoc collection was originally constructed using deep pools over a diverse set of runs, including several effective manual runs. Its judgment budget, and hence construction cost, was relatively large. However, it does appear that the expense was well-spent: even with the advent of neural techniques, the collection has stood the test of time and remains a reliable evaluation instrument as retrieval techniques have advanced.
SSP-Net: Scalable Sequential Pyramid Networks for Real-Time 3D Human Pose Regression
Sep 04, 2020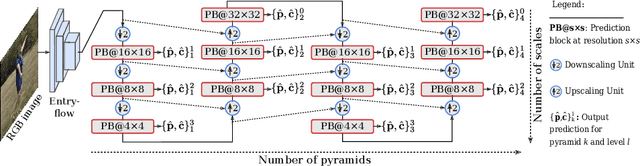
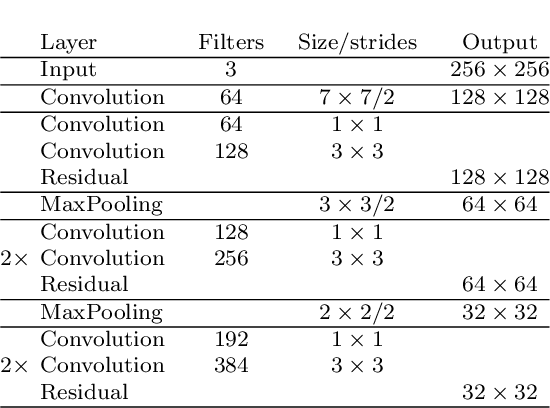
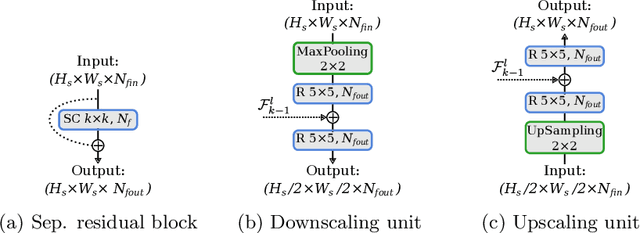
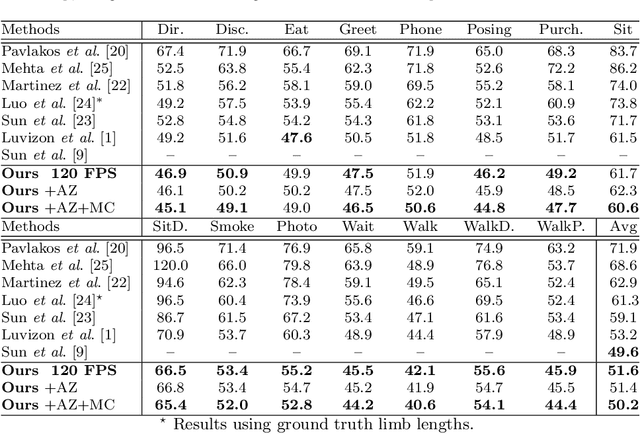
In this paper we propose a highly scalable convolutional neural network, end-to-end trainable, for real-time 3D human pose regression from still RGB images. We call this approach the Scalable Sequential Pyramid Networks (SSP-Net) as it is trained with refined supervision at multiple scales in a sequential manner. Our network requires a single training procedure and is capable of producing its best predictions at 120 frames per second (FPS), or acceptable predictions at more than 200 FPS when cut at test time. We show that the proposed regression approach is invariant to the size of feature maps, allowing our method to perform multi-resolution intermediate supervisions and reaching results comparable to the state-of-the-art with very low resolution feature maps. We demonstrate the accuracy and the effectiveness of our method by providing extensive experiments on two of the most important publicly available datasets for 3D pose estimation, Human3.6M and MPI-INF-3DHP. Additionally, we provide relevant insights about our decisions on the network architecture and show its flexibility to meet the best precision-speed compromise.
Server-Side Stepsizes and Sampling Without Replacement Provably Help in Federated Optimization
Jan 26, 2022

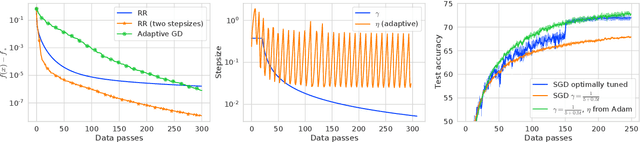
We present a theoretical study of server-side optimization in federated learning. Our results are the first to show that the widely popular heuristic of scaling the client updates with an extra parameter is very useful in the context of Federated Averaging (FedAvg) with local passes over the client data. Each local pass is performed without replacement using Random Reshuffling, which is a key reason we can show improved complexities. In particular, we prove that whenever the local stepsizes are small, and the update direction is given by FedAvg in conjunction with Random Reshuffling over all clients, one can take a big leap in the obtained direction and improve rates for convex, strongly convex, and non-convex objectives. In particular, in non-convex regime we get an enhancement of the rate of convergence from $\mathcal{O}\left(\varepsilon^{-3}\right)$ to $\mathcal{O}\left(\varepsilon^{-2}\right)$. This result is new even for Random Reshuffling performed on a single node. In contrast, if the local stepsizes are large, we prove that the noise of client sampling can be controlled by using a small server-side stepsize. To the best of our knowledge, this is the first time that local steps provably help to overcome the communication bottleneck. Together, our results on the advantage of large and small server-side stepsizes give a formal justification for the practice of adaptive server-side optimization in federated learning. Moreover, we consider a variant of our algorithm that supports partial client participation, which makes the method more practical.
Supervised Feature Subset Selection and Feature Ranking for Multivariate Time Series without Feature Extraction
May 01, 2020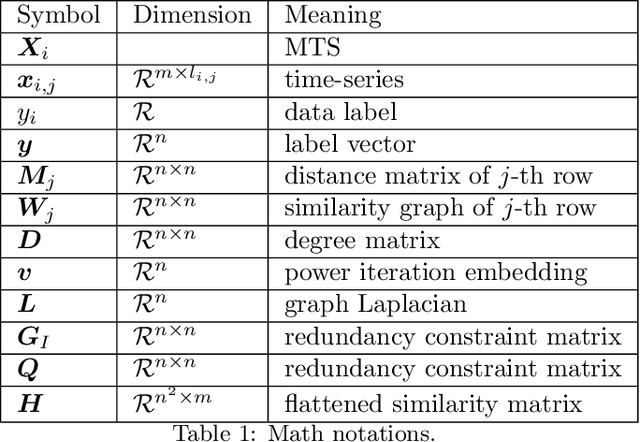
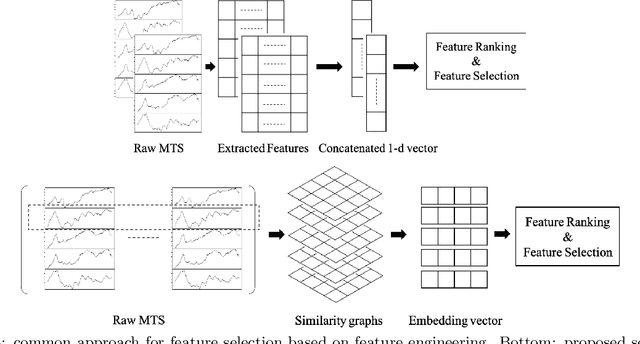
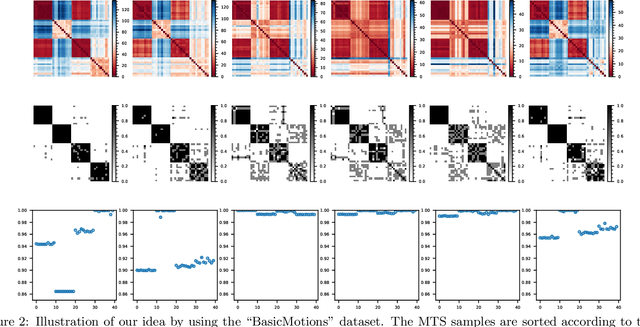
We introduce supervised feature ranking and feature subset selection algorithms for multivariate time series (MTS) classification. Unlike most existing supervised/unsupervised feature selection algorithms for MTS our techniques do not require a feature extraction step to generate a one-dimensional feature vector from the time series. Instead it is based on directly computing similarity between individual time series and assessing how well the resulting cluster structure matches the labels. The techniques are amenable to heterogeneous MTS data, where the time series measurements may have different sampling resolutions, and to multi-modal data.
Spatiotemporal Clustering with Neyman-Scott Processes via Connections to Bayesian Nonparametric Mixture Models
Jan 14, 2022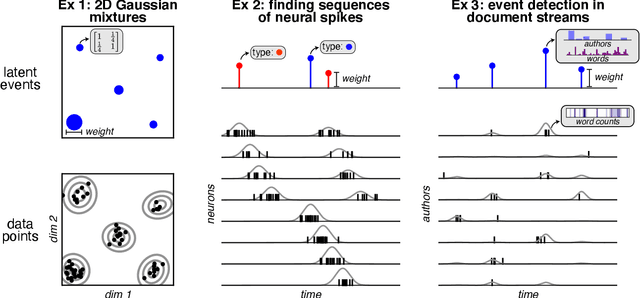

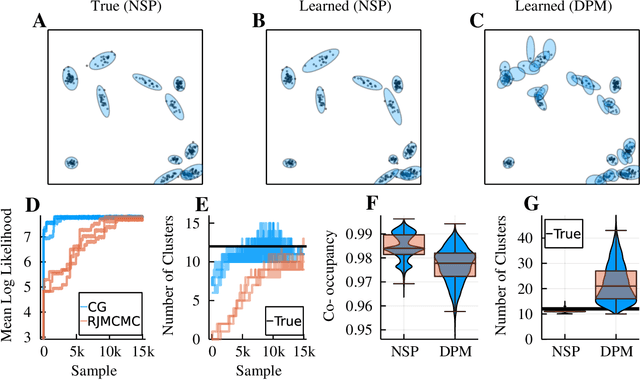
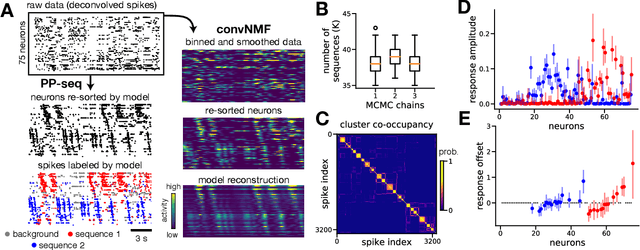
Neyman-Scott processes (NSPs) are point process models that generate clusters of points in time or space. They are natural models for a wide range of phenomena, ranging from neural spike trains to document streams. The clustering property is achieved via a doubly stochastic formulation: first, a set of latent events is drawn from a Poisson process; then, each latent event generates a set of observed data points according to another Poisson process. This construction is similar to Bayesian nonparametric mixture models like the Dirichlet process mixture model (DPMM) in that the number of latent events (i.e. clusters) is a random variable, but the point process formulation makes the NSP especially well suited to modeling spatiotemporal data. While many specialized algorithms have been developed for DPMMs, comparatively fewer works have focused on inference in NSPs. Here, we present novel connections between NSPs and DPMMs, with the key link being a third class of Bayesian mixture models called mixture of finite mixture models (MFMMs). Leveraging this connection, we adapt the standard collapsed Gibbs sampling algorithm for DPMMs to enable scalable Bayesian inference on NSP models. We demonstrate the potential of Neyman-Scott processes on a variety of applications including sequence detection in neural spike trains and event detection in document streams.
Joint Liver and Hepatic Lesion Segmentation using a Hybrid CNN with Transformer Layers
Jan 26, 2022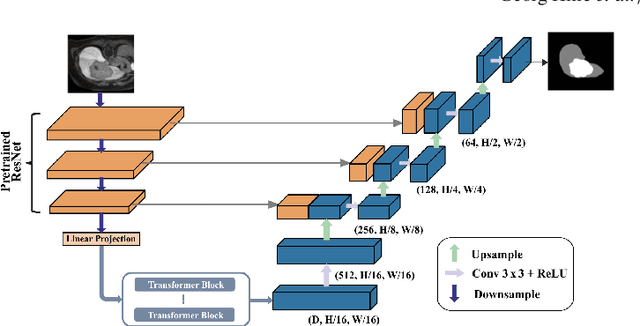
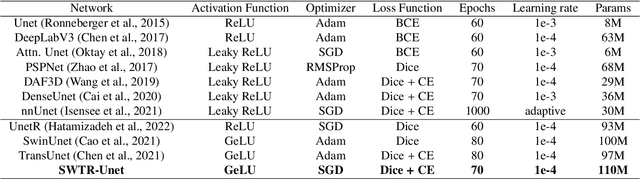
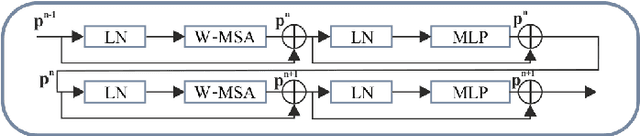
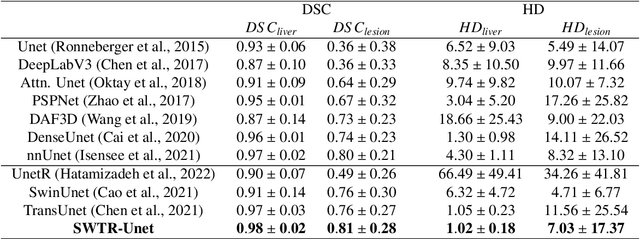
Deep learning-based segmentation of the liver and hepatic lesions therein steadily gains relevance in clinical practice due to the increasing incidence of liver cancer each year. Whereas various network variants with overall promising results in the field of medical image segmentation have been developed over the last years, almost all of them struggle with the challenge of accurately segmenting hepatic lesions. This lead to the idea of combining elements of convolutional and transformerbased architectures to overcome the existing limitations. This work presents a hybrid network called SWTR-Unet, consisting of a pretrained ResNet, transformer blocks as well as a common Unet-style decoder path. This network was applied to clinical liver MRI, as well as to the publicly available CT data of the liver tumor segmentation (LiTS) challenge. Additionally, multiple state-of-the-art networks were implemented and applied to both datasets, ensuring a direct comparability. Furthermore, correlation analysis and an ablation study were carried out, to investigate various influencing factors on the segmentation accuracy of our presented method. With Dice similarity scores of averaged 98 +- 2 % for liver and 81 +- 28 % lesion segmentation on the MRI dataset and 97 +- 2 % and 79 +- 25 %, respectively on the CT dataset, the proposed SWTR-Unet outperforms each of the additionally implemented state-of-the-art networks. The achieved segmentation accuracy was found to be on par with manually performed expert segmentations as indicated by interobserver variabilities for liver lesion segmentation. In conclusion, the presented method could save valuable time and resources in clinical practice.
Opportunities of Hybrid Model-based Reinforcement Learning for Cell Therapy Manufacturing Process Development and Control
Jan 10, 2022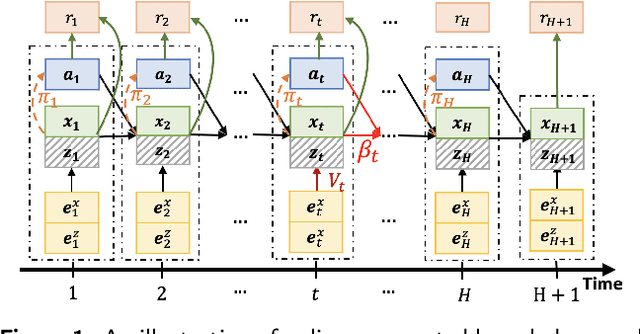
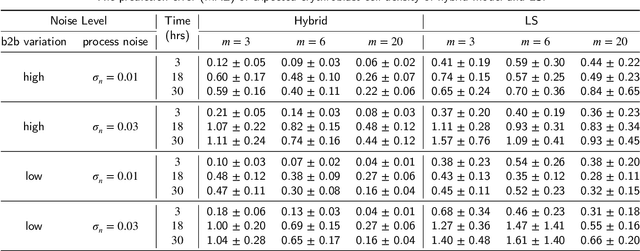
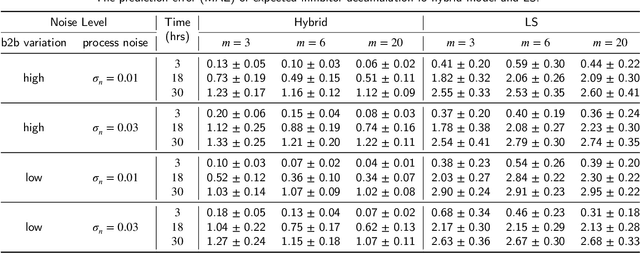
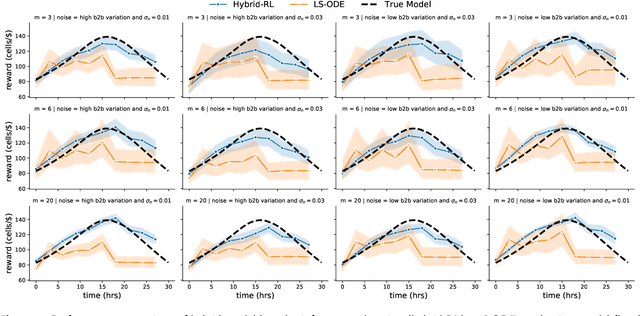
Driven by the key challenges of cell therapy manufacturing, including high complexity, high uncertainty, and very limited process data, we propose a stochastic optimization framework named "hybrid-RL" to efficiently guide process development and control. We first create the bioprocess probabilistic knowledge graph that is a hybrid model characterizing the understanding of biomanufacturing process mechanisms and quantifying inherent stochasticity, such as batch-to-batch variation and bioprocess noise. It can capture the key features, including nonlinear reactions, time-varying kinetics, and partially observed bioprocess state. This hybrid model can leverage on existing mechanistic models and facilitate the learning from process data. Given limited process data, a computational sampling approach is used to generate posterior samples quantifying the model estimation uncertainty. Then, we introduce hybrid model-based Bayesian reinforcement learning (RL), accounting for both inherent stochasticity and model uncertainty, to guide optimal, robust, and interpretable decision making, which can overcome the key challenges of cell therapy manufacturing. In the empirical study, cell therapy manufacturing examples are used to demonstrate that the proposed hybrid-RL framework can outperform the classical deterministic mechanistic model assisted process optimization.
Reinforcement Learning in Non-Stationary Discrete-Time Linear-Quadratic Mean-Field Games
Sep 10, 2020In this paper, we study large population multi-agent reinforcement learning (RL) in the context of discrete-time linear-quadratic mean-field games (LQ-MFGs). Our setting differs from most existing work on RL for MFGs, in that we consider a non-stationary MFG over an infinite horizon. We propose an actor-critic algorithm to iteratively compute the mean-field equilibrium (MFE) of the LQ-MFG. There are two primary challenges: i) the non-stationarity of the MFG induces a linear-quadratic tracking problem, which requires solving a backwards-in-time (non-causal) equation that cannot be solved by standard (causal) RL algorithms; ii) Most RL algorithms assume that the states are sampled from the stationary distribution of a Markov chain (MC), that is, the chain is already mixed, an assumption that is not satisfied for real data sources. We first identify that the mean-field trajectory follows linear dynamics, allowing the problem to be reformulated as a linear quadratic Gaussian problem. Under this reformulation, we propose an actor-critic algorithm that allows samples to be drawn from an unmixed MC. Finite-sample convergence guarantees for the algorithm are then provided. To characterize the performance of our algorithm in multi-agent RL, we have developed an error bound with respect to the Nash equilibrium of the finite-population game.
Real-time single image depth perception in the wild with handheld devices
Jun 10, 2020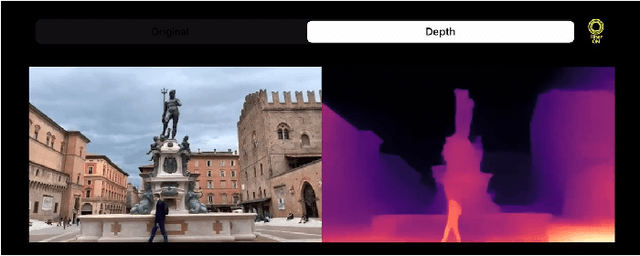
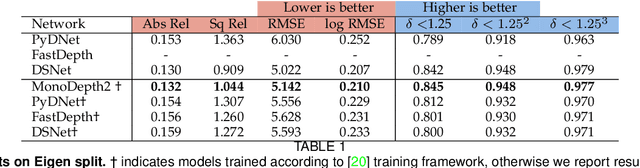
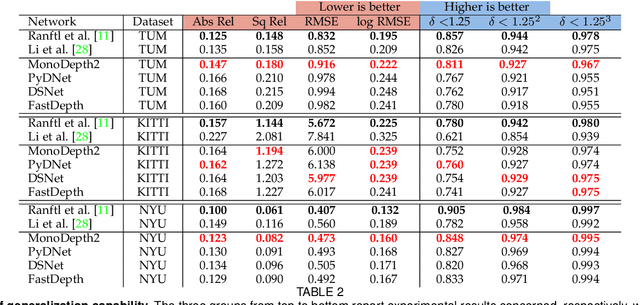
Depth perception is paramount to tackle real-world problems, ranging from autonomous driving to consumer applications. For the latter, depth estimation from a single image represents the most versatile solution, since a standard camera is available on almost any handheld device. Nonetheless, two main issues limit its practical deployment: i) the low reliability when deployed in-the-wild and ii) the demanding resource requirements to achieve real-time performance, often not compatible with such devices. Therefore, in this paper, we deeply investigate these issues showing how they are both addressable adopting appropriate network design and training strategies -- also outlining how to map the resulting networks on handheld devices to achieve real-time performance. Our thorough evaluation highlights the ability of such fast networks to generalize well to new environments, a crucial feature required to tackle the extremely varied contexts faced in real applications. Indeed, to further support this evidence, we report experimental results concerning real-time depth-aware augmented reality and image blurring with smartphones in-the-wild.
Black-box Safety Analysis and Retraining of DNNs based on Feature Extraction and Clustering
Jan 14, 2022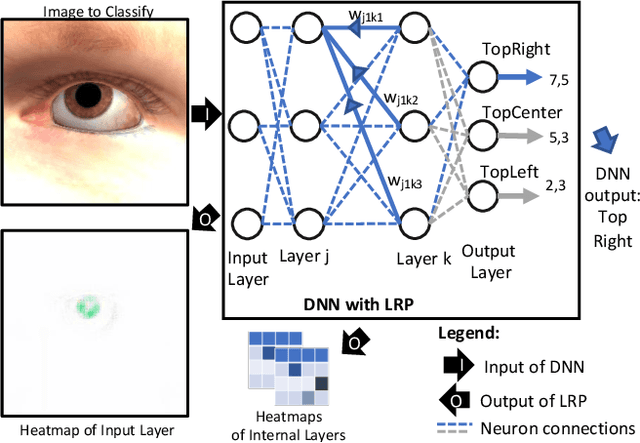
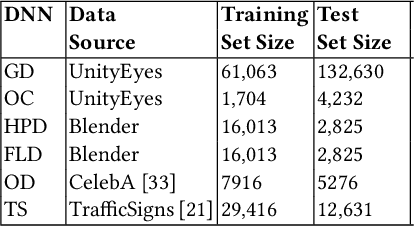
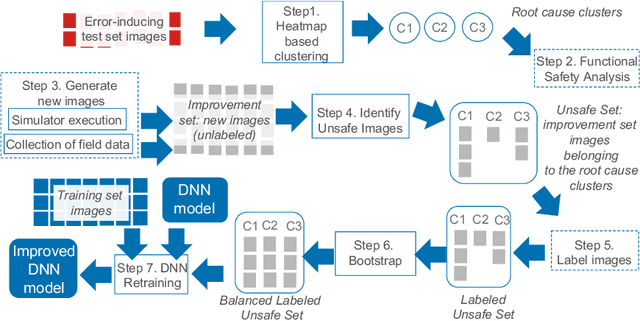
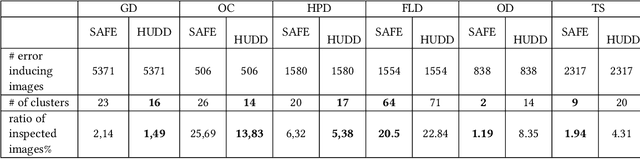
Deep neural networks (DNNs) have demonstrated superior performance over classical machine learning to support many features in safety-critical systems. Although DNNs are now widely used in such systems (e.g., self driving cars), there is limited progress regarding automated support for functional safety analysis in DNN-based systems. For example, the identification of root causes of errors, to enable both risk analysis and DNN retraining, remains an open problem. In this paper, we propose SAFE, a black-box approach to automatically characterize the root causes of DNN errors. SAFE relies on a transfer learning model pre-trained on ImageNet to extract the features from error-inducing images. It then applies a density-based clustering algorithm to detect arbitrary shaped clusters of images modeling plausible causes of error. Last, clusters are used to effectively retrain and improve the DNN. The black-box nature of SAFE is motivated by our objective not to require changes or even access to the DNN internals to facilitate adoption. Experimental results show the superior ability of SAFE in identifying different root causes of DNN errors based on case studies in the automotive domain. It also yields significant improvements in DNN accuracy after retraining, while saving significant execution time and memory when compared to alternatives.