 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On Mixing Times of Metropolized Algorithm With Optimization Step (MAO) : A New Framework
Dec 01, 2021
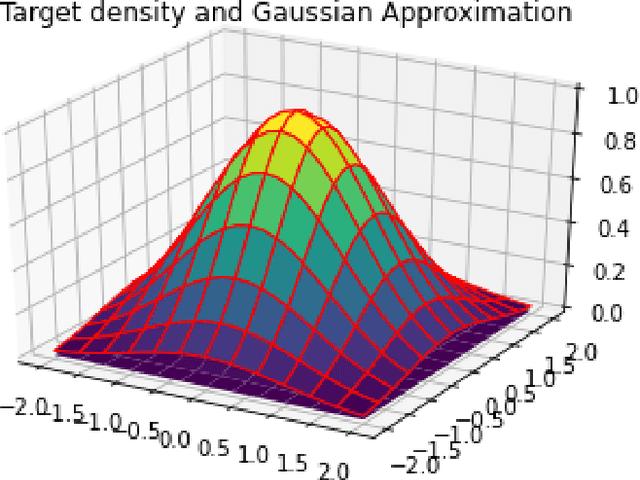
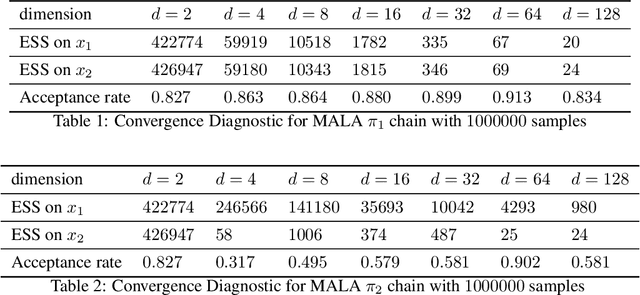
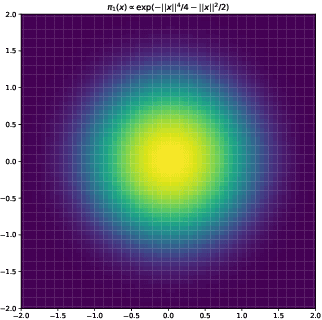
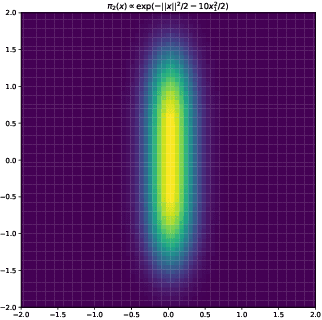
In this paper, we consider sampling from a class of distributions with thin tails supported on $\mathbb{R}^d$ and make two primary contributions. First, we propose a new Metropolized Algorithm With Optimization Step (MAO), which is well suited for such targets. Our algorithm is capable of sampling from distributions where the Metropolis-adjusted Langevin algorithm (MALA) is not converging or lacking in theoretical guarantees. Second, we derive upper bounds on the mixing time of MAO. Our results are supported by simulations on multiple target distributions.
Towards Cardiac Intervention Assistance: Hardware-aware Neural Architecture Exploration for Real-Time 3D Cardiac Cine MRI Segmentation
Aug 17, 2020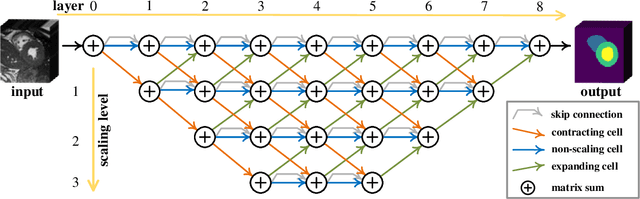
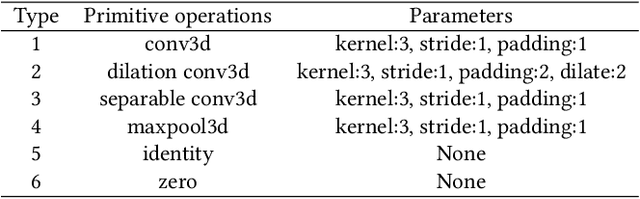
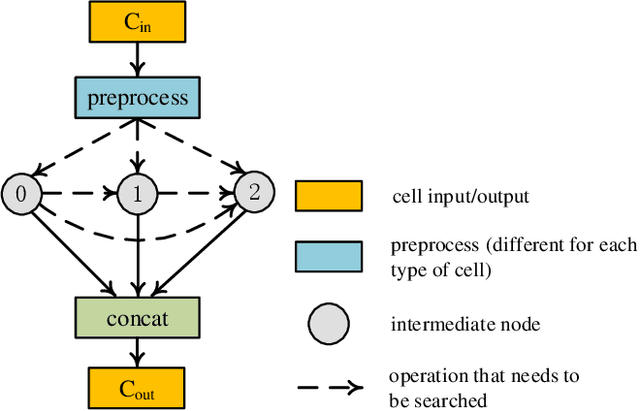
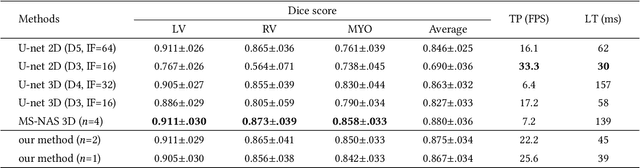
Real-time cardiac magnetic resonance imaging (MRI) plays an increasingly important role in guiding various cardiac interventions. In order to provide better visual assistance, the cine MRI frames need to be segmented on-the-fly to avoid noticeable visual lag. In addition, considering reliability and patient data privacy, the computation is preferably done on local hardware. State-of-the-art MRI segmentation methods mostly focus on accuracy only, and can hardly be adopted for real-time application or on local hardware. In this work, we present the first hardware-aware multi-scale neural architecture search (NAS) framework for real-time 3D cardiac cine MRI segmentation. The proposed framework incorporates a latency regularization term into the loss function to handle real-time constraints, with the consideration of underlying hardware. In addition, the formulation is fully differentiable with respect to the architecture parameters, so that stochastic gradient descent (SGD) can be used for optimization to reduce the computation cost while maintaining optimization quality. Experimental results on ACDC MICCAI 2017 dataset demonstrate that our hardware-aware multi-scale NAS framework can reduce the latency by up to 3.5 times and satisfy the real-time constraints, while still achieving competitive segmentation accuracy, compared with the state-of-the-art NAS segmentation framework.
Private Robust Estimation by Stabilizing Convex Relaxations
Dec 07, 2021We give the first polynomial time and sample $(\epsilon, \delta)$-differentially private (DP) algorithm to estimate the mean, covariance and higher moments in the presence of a constant fraction of adversarial outliers. Our algorithm succeeds for families of distributions that satisfy two well-studied properties in prior works on robust estimation: certifiable subgaussianity of directional moments and certifiable hypercontractivity of degree 2 polynomials. Our recovery guarantees hold in the "right affine-invariant norms": Mahalanobis distance for mean, multiplicative spectral and relative Frobenius distance guarantees for covariance and injective norms for higher moments. Prior works obtained private robust algorithms for mean estimation of subgaussian distributions with bounded covariance. For covariance estimation, ours is the first efficient algorithm (even in the absence of outliers) that succeeds without any condition-number assumptions. Our algorithms arise from a new framework that provides a general blueprint for modifying convex relaxations for robust estimation to satisfy strong worst-case stability guarantees in the appropriate parameter norms whenever the algorithms produce witnesses of correctness in their run. We verify such guarantees for a modification of standard sum-of-squares (SoS) semidefinite programming relaxations for robust estimation. Our privacy guarantees are obtained by combining stability guarantees with a new "estimate dependent" noise injection mechanism in which noise scales with the eigenvalues of the estimated covariance. We believe this framework will be useful more generally in obtaining DP counterparts of robust estimators. Independently of our work, Ashtiani and Liaw [AL21] also obtained a polynomial time and sample private robust estimation algorithm for Gaussian distributions.
TG-GAN: Deep Generative Models for Continuously-time Temporal Graph Generation
May 17, 2020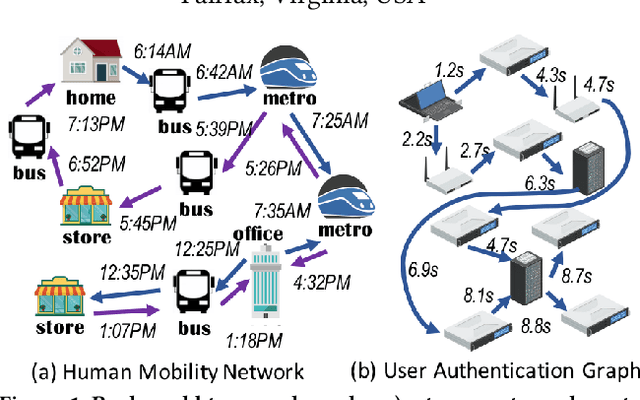
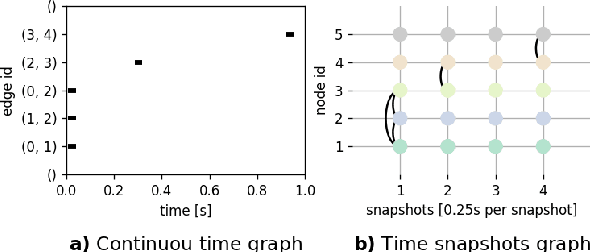
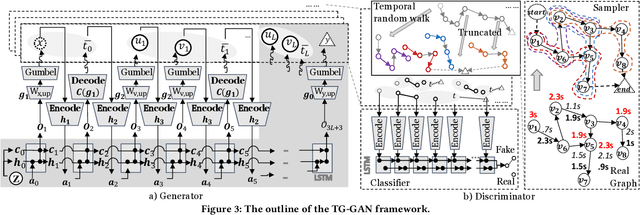
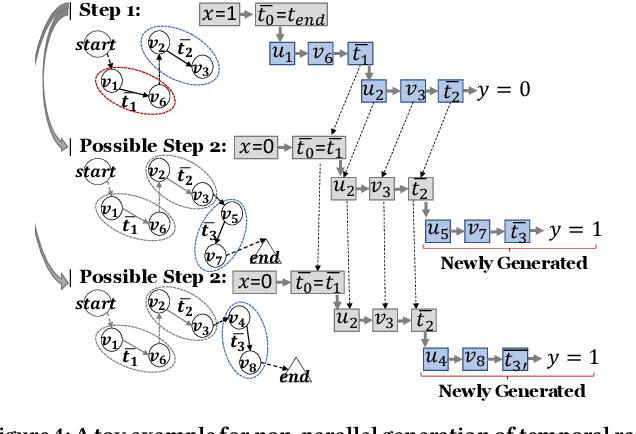
Recently deep generative models for static networks have been under active development and achieved significant success in application areas such as molecule design. However, many real-world problems involve temporal graphs whose topology and attribute values evolve dynamically over time, such as in the cases of protein folding, human mobility networks, and social network growth. However, deep generative models for temporal graphs has rarely been well explored yet and existing techniques for static graphs are not up to the task for temporal graphs since they cannot 1) encode and decode continuously-varying graph topology chronologically, 2) enforce validity via temporal constraints, and 3) ensure efficiency for information-lossless temporal resolution. To address these challenges, we propose a new model, called "Temporal Graph Generative Adversarial Network" (TG-GAN) for continuous-time temporal graph generation, by modeling the deep generative process for truncated temporal random walks and their compositions. Specifically, we first propose a novel temporal graph generator that jointly model truncated edge sequences, time budgets, and node attributes, with novel activation functions that enforce temporal validity constraints under recurrent architecture. In addition, a new temporal graph discriminator is proposed, which combines time and node encoding operations over a recurrent architecture to distinguish the generated sequences from the real ones sampled by a newly-developed truncated temporal random walk sampler. Extensive experiments on both synthetic and real-world datasets demonstrate TG-GAN significantly ourperforms the comparison methods in efficiency and effectiveness.
Attention based Broadly Self-guided Network for Low light Image Enhancement
Dec 15, 2021
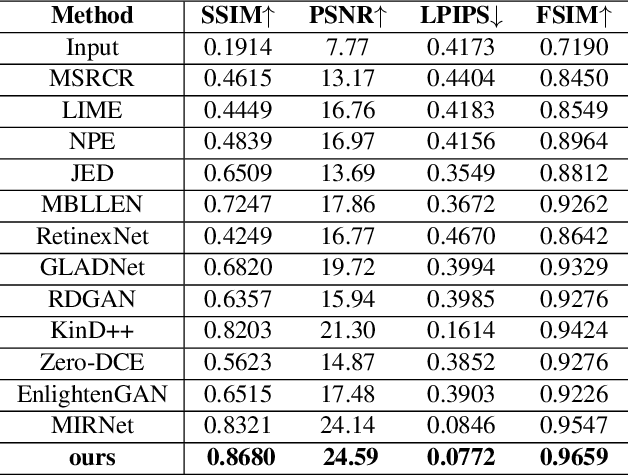
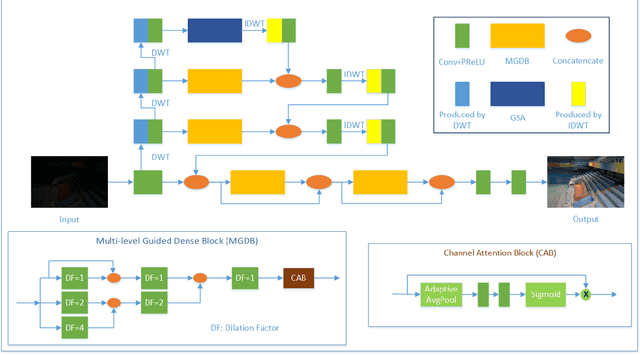
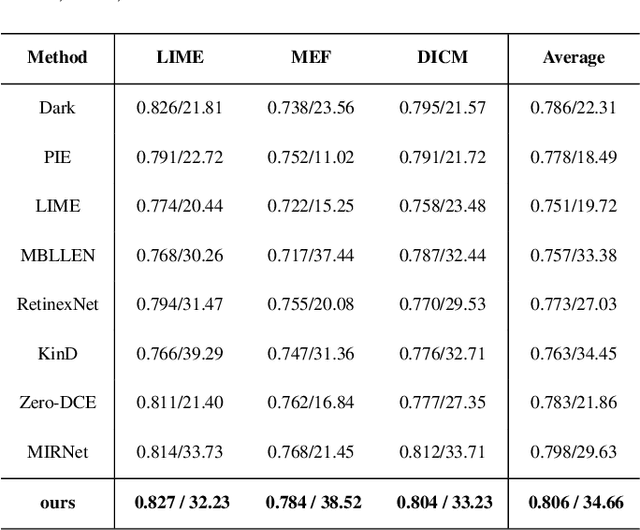
During the past years,deep convolutional neural networks have achieved impressive success in low-light Image Enhancement.Existing deep learning methods mostly enhance the ability of feature extraction by stacking network structures and deepening the depth of the network.which causes more runtime cost on single image.In order to reduce inference time while fully extracting local features and global features.Inspired by SGN,we propose a Attention based Broadly self-guided network (ABSGN) for real world low-light image Enhancement.such a broadly strategy is able to handle the noise at different exposures.The proposed network is validated by many mainstream benchmark.Additional experimental results show that the proposed network outperforms most of state-of-the-art low-light image Enhancement solutions.
Scalable 3D Semantic Segmentation for Gun Detection in CT Scans
Dec 07, 2021
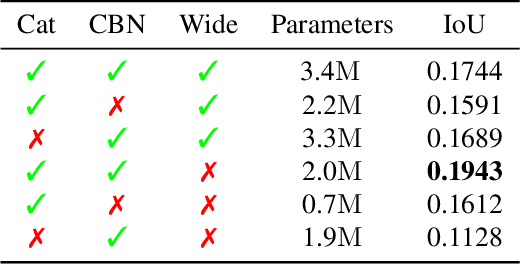
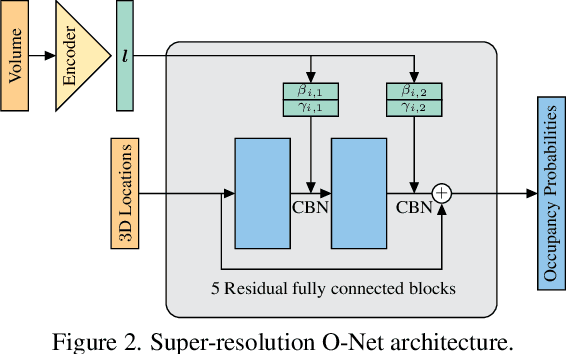
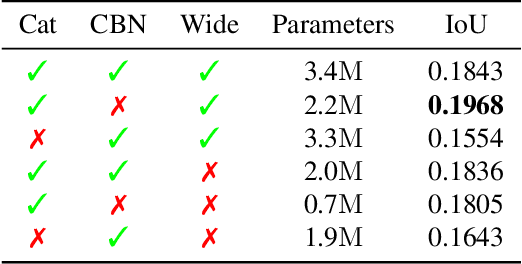
With the increased availability of 3D data, the need for solutions processing those also increased rapidly. However, adding dimension to already reliably accurate 2D approaches leads to immense memory consumption and higher computational complexity. These issues cause current hardware to reach its limitations, with most methods forced to reduce the input resolution drastically. Our main contribution is a novel deep 3D semantic segmentation method for gun detection in baggage CT scans that enables fast training and low video memory consumption for high-resolution voxelized volumes. We introduce a moving pyramid approach that utilizes multiple forward passes at inference time for segmenting an instance.
Formalising the Foundations of Discrete Reinforcement Learning in Isabelle/HOL
Dec 11, 2021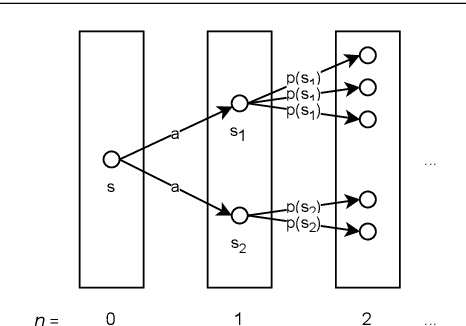
We present a formalisation of finite Markov decision processes with rewards in the Isabelle theorem prover. We focus on the foundations required for dynamic programming and the use of reinforcement learning agents over such processes. In particular, we derive the Bellman equation from first principles (in both scalar and vector form), derive a vector calculation that produces the expected value of any policy p, and go on to prove the existence of a universally optimal policy where there is a discounting factor less than one. Lastly, we prove that the value iteration and the policy iteration algorithms work in finite time, producing an epsilon-optimal and a fully optimal policy respectively.
Optimizing Diffusion Rate and Label Reliability in a Graph-Based Semi-supervised Classifier
Jan 10, 2022
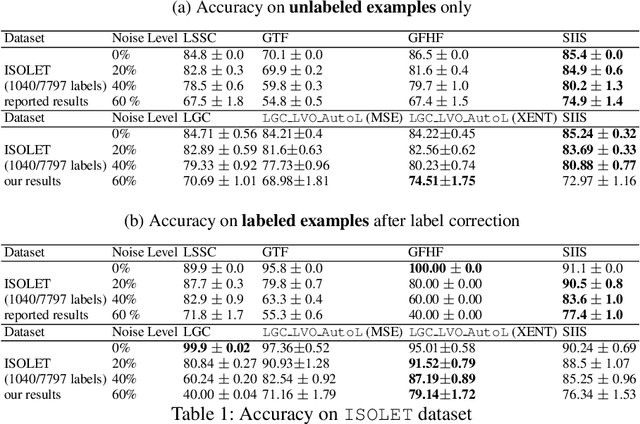
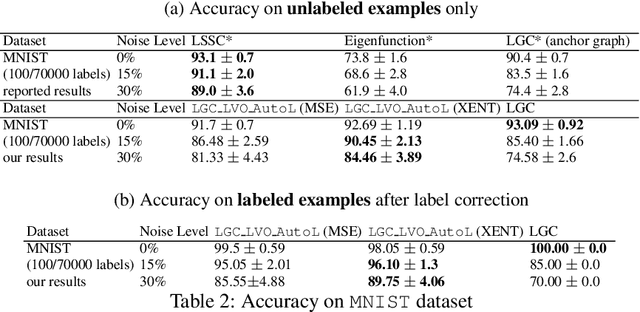
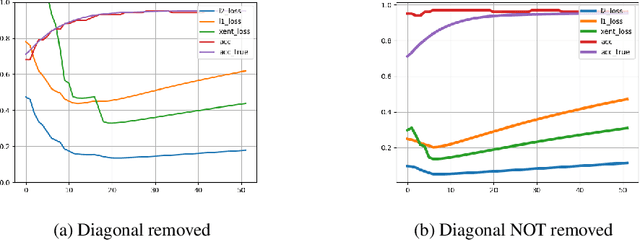
Semi-supervised learning has received attention from researchers, as it allows one to exploit the structure of unlabeled data to achieve competitive classification results with much fewer labels than supervised approaches. The Local and Global Consistency (LGC) algorithm is one of the most well-known graph-based semi-supervised (GSSL) classifiers. Notably, its solution can be written as a linear combination of the known labels. The coefficients of this linear combination depend on a parameter $\alpha$, determining the decay of the reward over time when reaching labeled vertices in a random walk. In this work, we discuss how removing the self-influence of a labeled instance may be beneficial, and how it relates to leave-one-out error. Moreover, we propose to minimize this leave-one-out loss with automatic differentiation. Within this framework, we propose methods to estimate label reliability and diffusion rate. Optimizing the diffusion rate is more efficiently accomplished with a spectral representation. Results show that the label reliability approach competes with robust L1-norm methods and that removing diagonal entries reduces the risk of overfitting and leads to suitable criteria for parameter selection.
Sequential Modeling with Multiple Attributes for Watchlist Recommendation in E-Commerce
Oct 24, 2021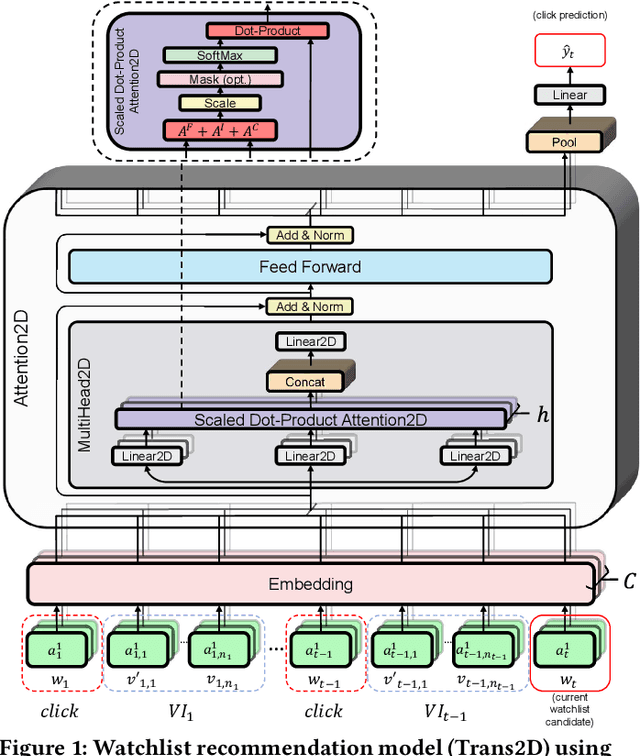
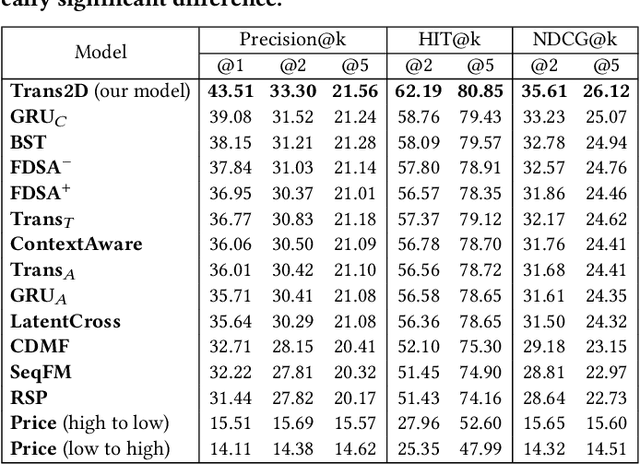

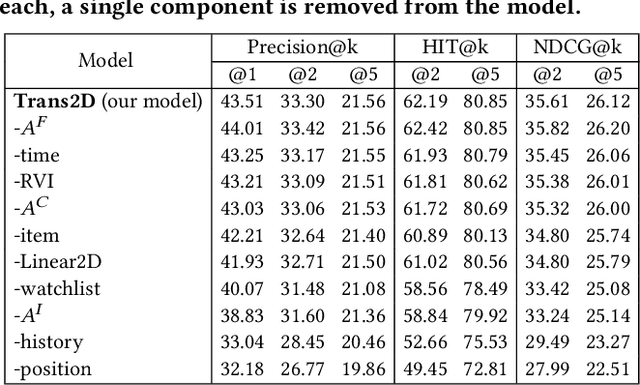
In e-commerce, the watchlist enables users to track items over time and has emerged as a primary feature, playing an important role in users' shopping journey. Watchlist items typically have multiple attributes whose values may change over time (e.g., price, quantity). Since many users accumulate dozens of items on their watchlist, and since shopping intents change over time, recommending the top watchlist items in a given context can be valuable. In this work, we study the watchlist functionality in e-commerce and introduce a novel watchlist recommendation task. Our goal is to prioritize which watchlist items the user should pay attention to next by predicting the next items the user will click. We cast this task as a specialized sequential recommendation task and discuss its characteristics. Our proposed recommendation model, Trans2D, is built on top of the Transformer architecture, where we further suggest a novel extended attention mechanism (Attention2D) that allows to learn complex item-item, attribute-attribute and item-attribute patterns from sequential-data with multiple item attributes. Using a large-scale watchlist dataset from eBay, we evaluate our proposed model, where we demonstrate its superiority compared to multiple state-of-the-art baselines, many of which are adapted for this task.
Image-based Navigation in Real-World Environments via Multiple Mid-level Representations: Fusion Models, Benchmark and Efficient Evaluation
Feb 02, 2022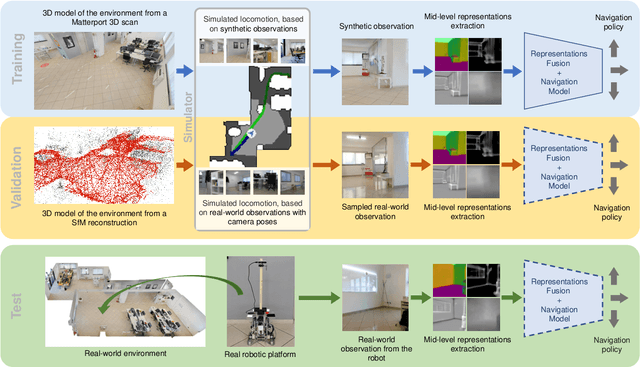
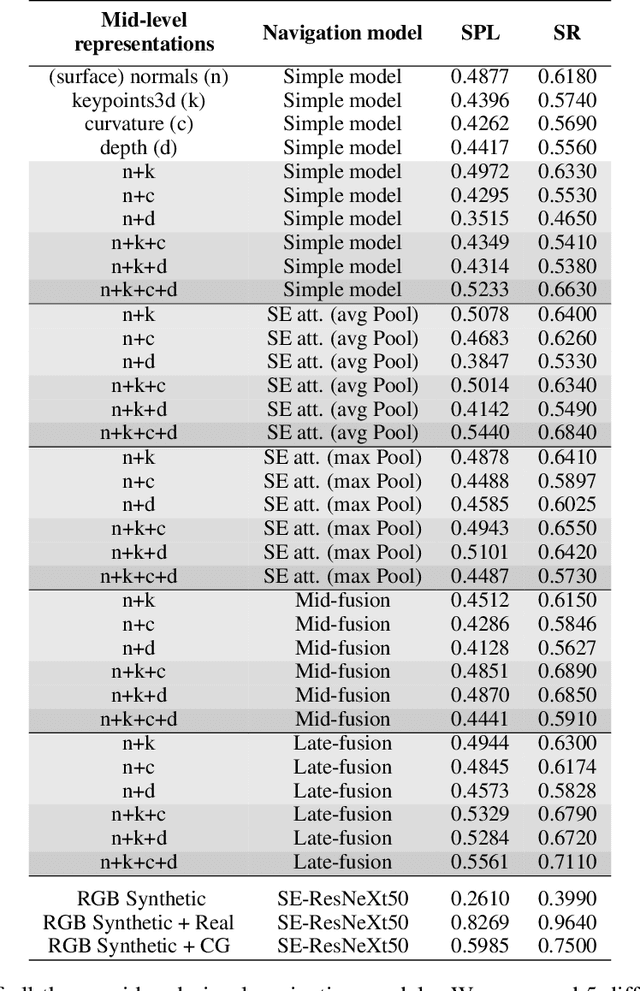


Navigating complex indoor environments requires a deep understanding of the space the robotic agent is acting into to correctly inform the navigation process of the agent towards the goal location. In recent learning-based navigation approaches, the scene understanding and navigation abilities of the agent are achieved simultaneously by collecting the required experience in simulation. Unfortunately, even if simulators represent an efficient tool to train navigation policies, the resulting models often fail when transferred into the real world. One possible solution is to provide the navigation model with mid-level visual representations containing important domain-invariant properties of the scene. But, what are the best representations that facilitate the transfer of a model to the real-world? How can they be combined? In this work we address these issues by proposing a benchmark of Deep Learning architectures to combine a range of mid-level visual representations, to perform a PointGoal navigation task following a Reinforcement Learning setup. All the proposed navigation models have been trained with the Habitat simulator on a synthetic office environment and have been tested on the same real-world environment using a real robotic platform. To efficiently assess their performance in a real context, a validation tool has been proposed to generate realistic navigation episodes inside the simulator. Our experiments showed that navigation models can benefit from the multi-modal input and that our validation tool can provide good estimation of the expected navigation performance in the real world, while saving time and resources. The acquired synthetic and real 3D models of the environment, together with the code of our validation tool built on top of Habitat, are publicly available at the following link: https://iplab.dmi.unict.it/EmbodiedVN/