 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable and Decentralized Algorithms for Anomaly Detection via Learning-Based Controlled Sensing
Dec 08, 2021
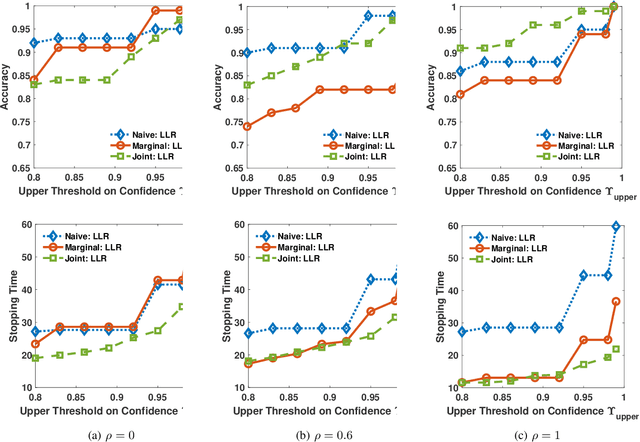
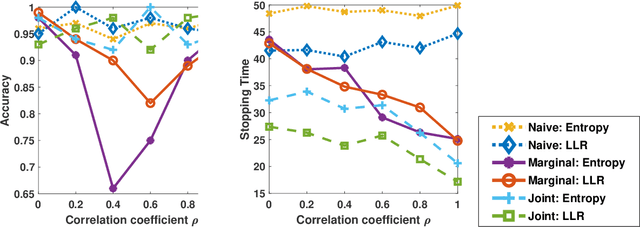
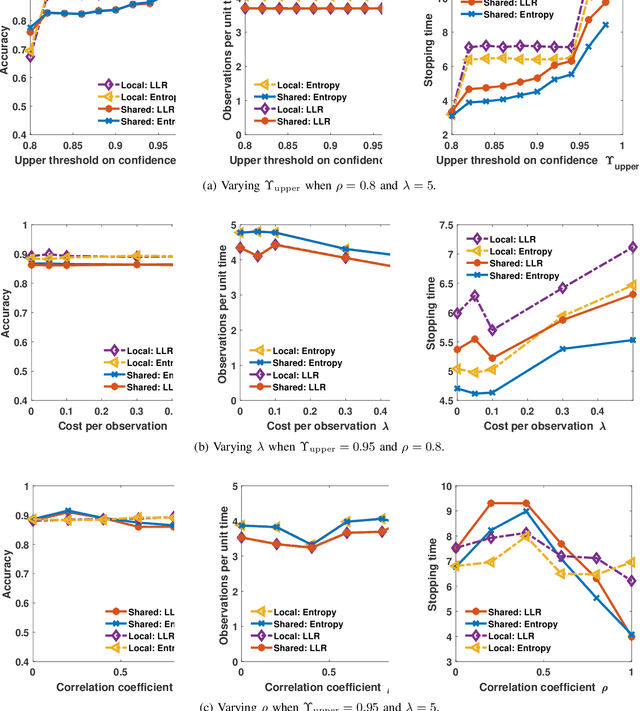
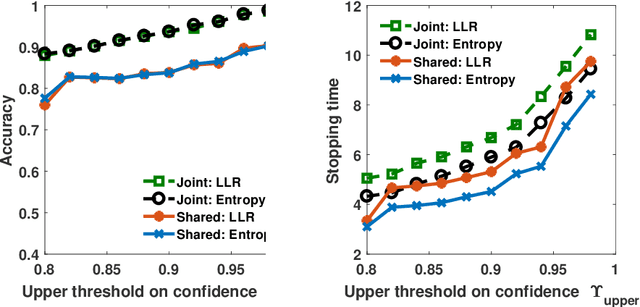
We address the problem of sequentially selecting and observing processes from a given set to find the anomalies among them. The decision-maker observes a subset of the processes at any given time instant and obtains a noisy binary indicator of whether or not the corresponding process is anomalous. In this setting, we develop an anomaly detection algorithm that chooses the processes to be observed at a given time instant, decides when to stop taking observations, and declares the decision on anomalous processes. The objective of the detection algorithm is to identify the anomalies with an accuracy exceeding the desired value while minimizing the delay in decision making. We devise a centralized algorithm where the processes are jointly selected by a common agent as well as a decentralized algorithm where the decision of whether to select a process is made independently for each process. Our algorithms rely on a Markov decision process defined using the marginal probability of each process being normal or anomalous, conditioned on the observations. We implement the detection algorithms using the deep actor-critic reinforcement learning framework. Unlike prior work on this topic that has exponential complexity in the number of processes, our algorithms have computational and memory requirements that are both polynomial in the number of processes. We demonstrate the efficacy of these algorithms using numerical experiments by comparing them with state-of-the-art methods.
Challenges in Migrating Imperative Deep Learning Programs to Graph Execution: An Empirical Study
Jan 24, 2022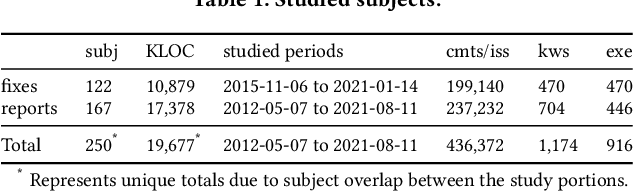
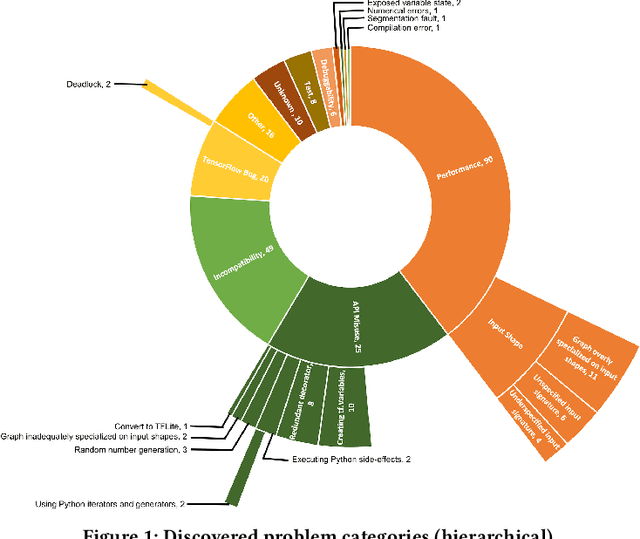
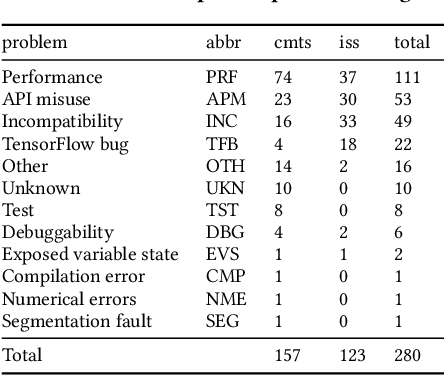

Efficiency is essential to support responsiveness w.r.t. ever-growing datasets, especially for Deep Learning (DL) systems. DL frameworks have traditionally embraced deferred execution-style DL code that supports symbolic, graph-based Deep Neural Network (DNN) computation. While scalable, such development tends to produce DL code that is error-prone, non-intuitive, and difficult to debug. Consequently, more natural, less error-prone imperative DL frameworks encouraging eager execution have emerged but at the expense of run-time performance. While hybrid approaches aim for the "best of both worlds," the challenges in applying them in the real world are largely unknown. We conduct a data-driven analysis of challenges -- and resultant bugs -- involved in writing reliable yet performant imperative DL code by studying 250 open-source projects, consisting of 19.7 MLOC, along with 470 and 446 manually examined code patches and bug reports, respectively. The results indicate that hybridization: (i) is prone to API misuse, (ii) can result in performance degradation -- the opposite of its intention, and (iii) has limited application due to execution mode incompatibility. We put forth several recommendations, best practices, and anti-patterns for effectively hybridizing imperative DL code, potentially benefiting DL practitioners, API designers, tool developers, and educators.
AI-Driven Demodulators for Nonlinear Receivers in Shared Spectrum with High-Power Blockers
Jan 24, 2022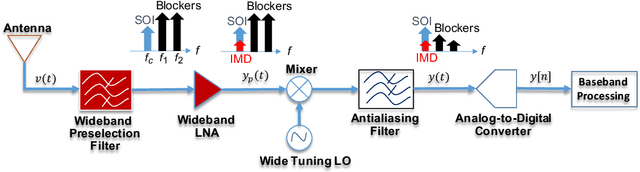
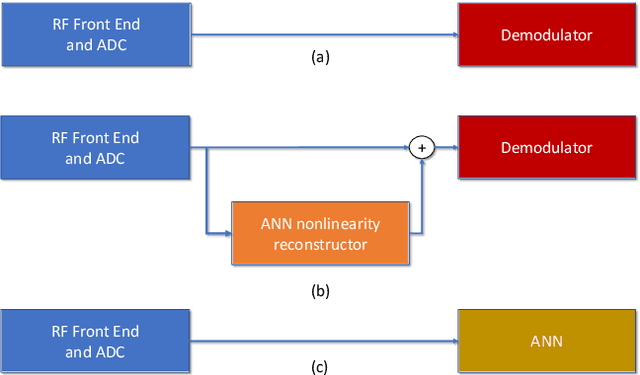
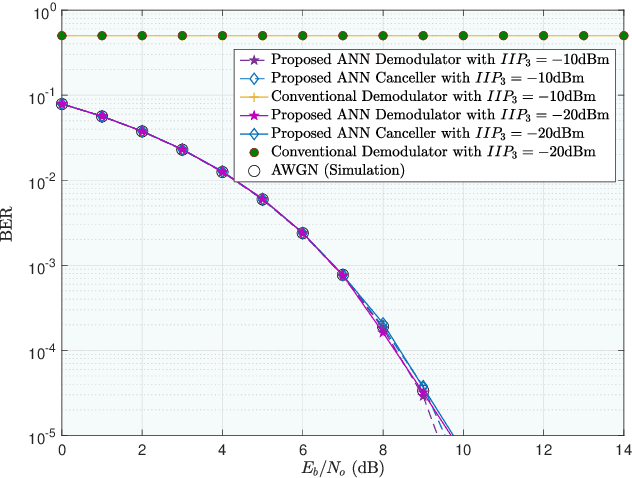
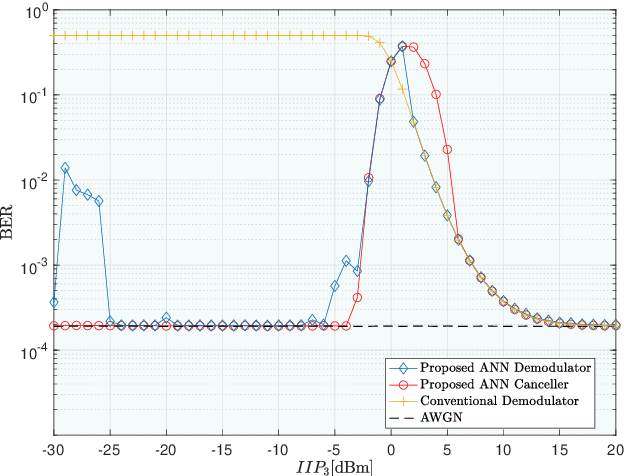
Research has shown that communications systems and receivers suffer from high power adjacent channel signals, called blockers, that drive the radio frequency (RF) front end into nonlinear operation. Since simple systems, such as the Internet of Things (IoT), will coexist with sophisticated communications transceivers, radars and other spectrum consumers, these need to be protected employing a simple, yet adaptive solution to RF nonlinearity. This paper therefore proposes a flexible data driven approach that uses a simple artificial neural network (ANN) to aid in the removal of the third order intermodulation distortion (IMD) as part of the demodulation process. We introduce and numerically evaluate two artificial intelligence (AI)-enhanced receivers-ANN as the IMD canceler and ANN as the demodulator. Our results show that a simple ANN structure can significantly improve the bit error rate (BER) performance of nonlinear receivers with strong blockers and that the ANN architecture and configuration depends mainly on the RF front end characteristics, such as the third order intercept point (IP3). We therefore recommend that receivers have hardware tags and ways to monitor those over time so that the AI and software radio processing stack can be effectively customized and automatically updated to deal with changing operating conditions.
Disaster mapping from satellites: damage detection with crowdsourced point labels
Nov 05, 2021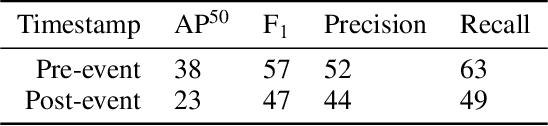


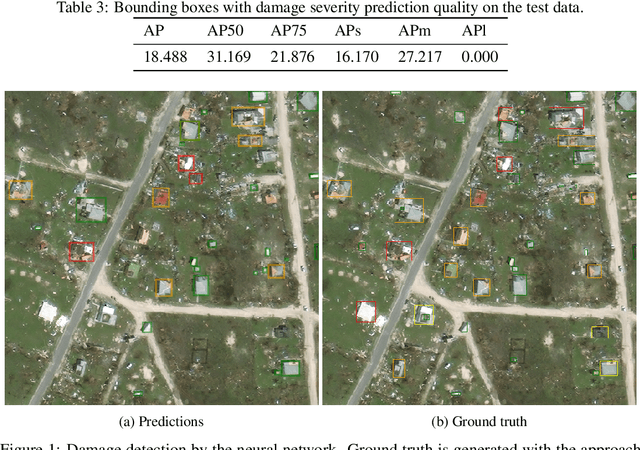
High-resolution satellite imagery available immediately after disaster events is crucial for response planning as it facilitates broad situational awareness of critical infrastructure status such as building damage, flooding, and obstructions to access routes. Damage mapping at this scale would require hundreds of expert person-hours. However, a combination of crowdsourcing and recent advances in deep learning reduces the effort needed to just a few hours in real time. Asking volunteers to place point marks, as opposed to shapes of actual damaged areas, significantly decreases the required analysis time for response during the disaster. However, different volunteers may be inconsistent in their marking. This work presents methods for aggregating potentially inconsistent damage marks to train a neural network damage detector.
PiP-X: Online feedback motion planning/replanning in dynamic environments using invariant funnels
Feb 01, 2022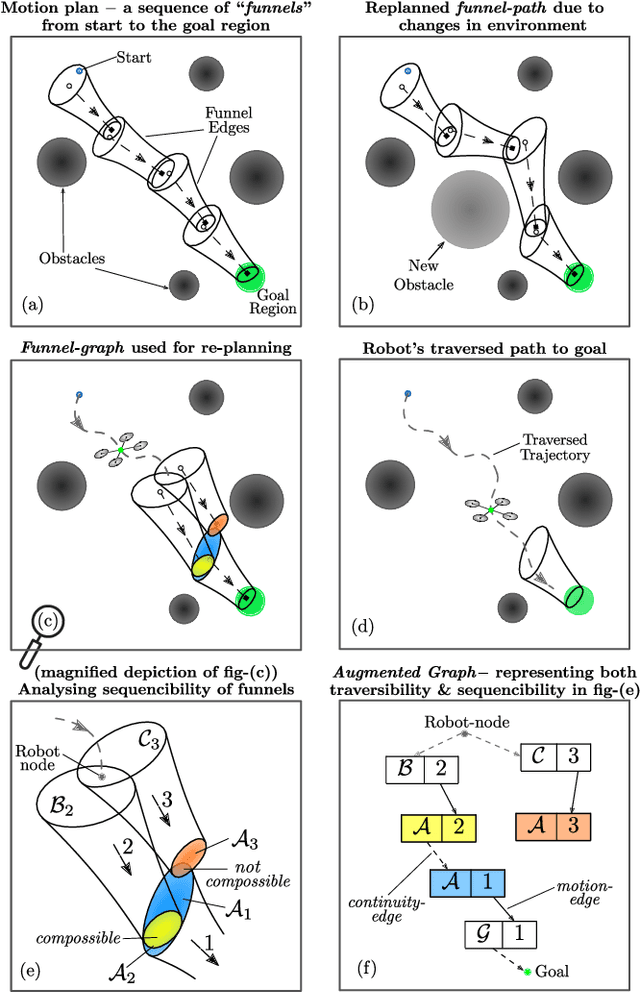
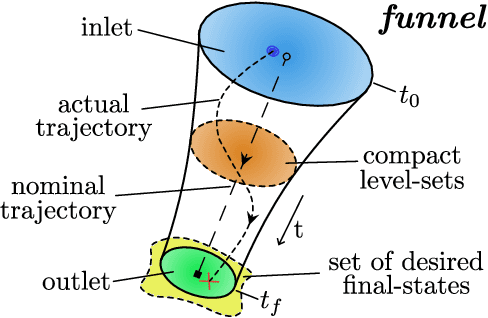
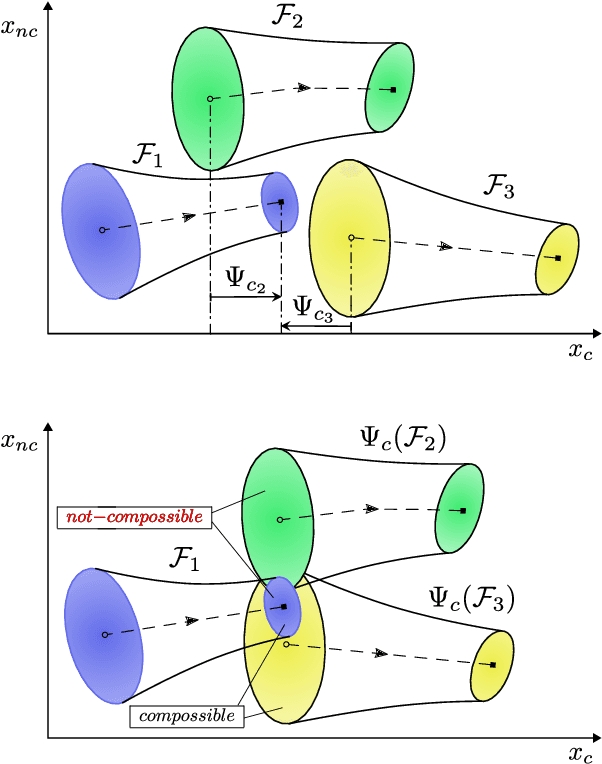
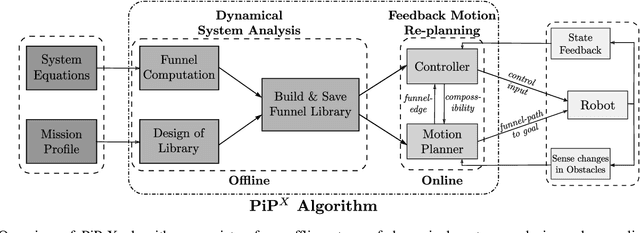
Computing kinodynamically feasible motion plans and repairing them on-the-fly as the environment changes is a challenging, yet relevant problem in robot-navigation. We propose a novel online single-query sampling-based motion re-planning algorithm - PiP-X, using finite-time invariant sets - funnels. We combine concepts from sampling-based methods, nonlinear systems analysis and control theory to create a single framework that enables feedback motion re-planning for any general nonlinear dynamical system in dynamic workspaces. A volumetric funnel-graph is constructed using sampling-based methods, and an optimal funnel-path from robot configuration to a desired goal region is then determined by computing the shortest-path subtree in it. Analysing and formally quantifying the stability of trajectories using Lyapunov level-set theory ensures kinodynamic feasibility and guaranteed set-invariance of the solution-paths. The use of incremental search techniques and a pre-computed library of motion-primitives ensure that our method can be used for quick online rewiring of controllable motion plans in densely cluttered and dynamic environments. We represent traversability and sequencibility of trajectories together in the form of an augmented directed-graph, helping us leverage discrete graph-based replanning algorithms to efficiently recompute feasible and controllable motion plans that are volumetric in nature. We validate our approach on a simulated 6DOF quadrotor platform in a variety of scenarios within a maze and random forest environment. From repeated experiments, we analyse the performance in terms of algorithm-success and length of traversed-trajectory.
Block Policy Mirror Descent
Jan 15, 2022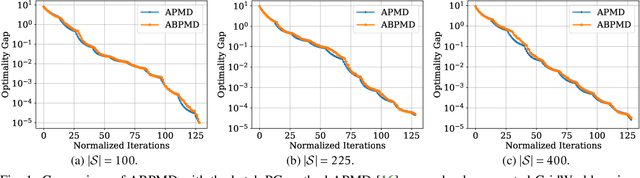
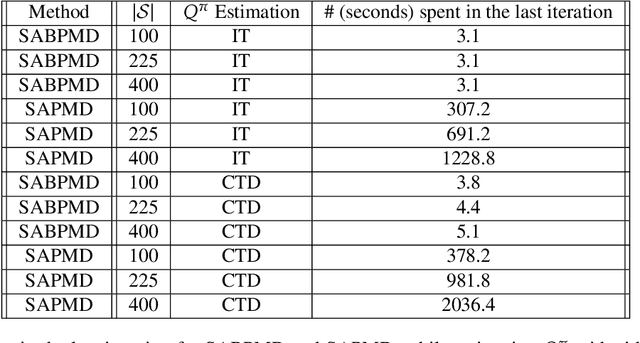
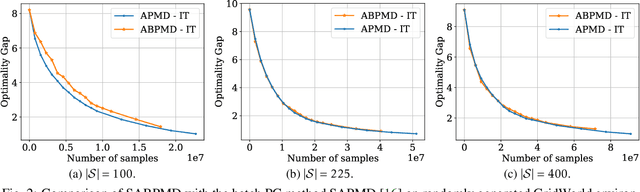
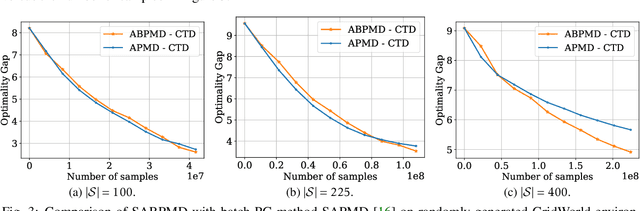
In this paper, we present a new class of policy gradient (PG) methods, namely the block policy mirror descent (BPMD) methods for solving a class of regularized reinforcement learning (RL) problems with (strongly) convex regularizers. Compared to the traditional PG methods with batch update rule, which visit and update the policy for every state, BPMD methods have cheap per-iteration computation via a partial update rule that performs the policy update on a sampled state. Despite the nonconvex nature of the problem and a partial update rule, BPMD methods achieve fast linear convergence to the global optimality. We further extend BPMD methods to the stochastic setting, by utilizing stochastic first-order information constructed from samples. We establish $\cO(1/\epsilon)$ (resp. $\cO(1/\epsilon^2)$) sample complexity for the strongly convex (resp. non-strongly convex) regularizers, with different procedures for constructing the stochastic first-order information, where $\epsilon$ denotes the target accuracy. To the best of our knowledge, this is the first time that block coordinate descent methods have been developed and analyzed for policy optimization in reinforcement learning.
Optimal SQ Lower Bounds for Learning Halfspaces with Massart Noise
Jan 24, 2022We give tight statistical query (SQ) lower bounds for learnining halfspaces in the presence of Massart noise. In particular, suppose that all labels are corrupted with probability at most $\eta$. We show that for arbitrary $\eta \in [0,1/2]$ every SQ algorithm achieving misclassification error better than $\eta$ requires queries of superpolynomial accuracy or at least a superpolynomial number of queries. Further, this continues to hold even if the information-theoretically optimal error $\mathrm{OPT}$ is as small as $\exp\left(-\log^c(d)\right)$, where $d$ is the dimension and $0 < c < 1$ is an arbitrary absolute constant, and an overwhelming fraction of examples are noiseless. Our lower bound matches known polynomial time algorithms, which are also implementable in the SQ framework. Previously, such lower bounds only ruled out algorithms achieving error $\mathrm{OPT} + \epsilon$ or error better than $\Omega(\eta)$ or, if $\eta$ is close to $1/2$, error $\eta - o_\eta(1)$, where the term $o_\eta(1)$ is constant in $d$ but going to 0 for $\eta$ approaching $1/2$. As a consequence, we also show that achieving misclassification error better than $1/2$ in the $(A,\alpha)$-Tsybakov model is SQ-hard for $A$ constant and $\alpha$ bounded away from 1.
Exploring System Performance of Continual Learning for Mobile and Embedded Sensing Applications
Oct 25, 2021
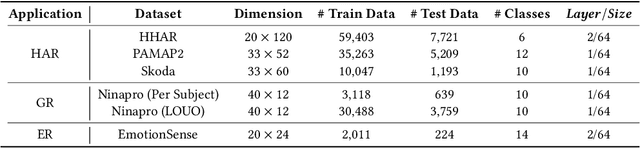
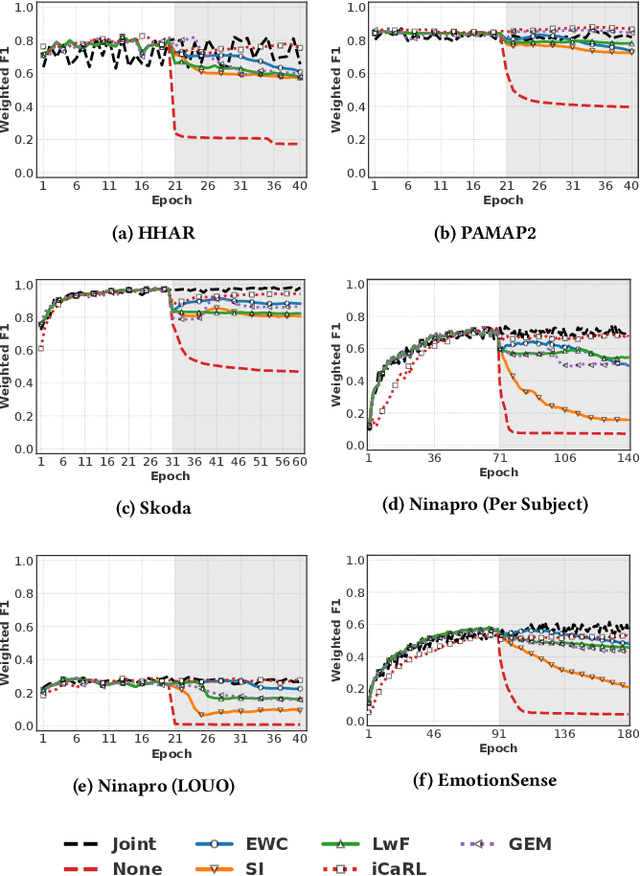
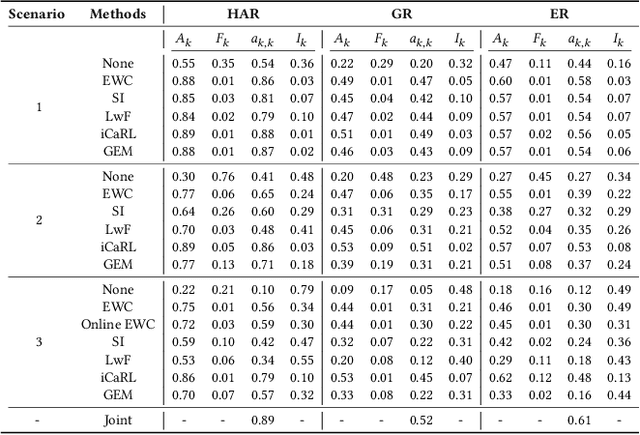
Continual learning approaches help deep neural network models adapt and learn incrementally by trying to solve catastrophic forgetting. However, whether these existing approaches, applied traditionally to image-based tasks, work with the same efficacy to the sequential time series data generated by mobile or embedded sensing systems remains an unanswered question. To address this void, we conduct the first comprehensive empirical study that quantifies the performance of three predominant continual learning schemes (i.e., regularization, replay, and replay with examples) on six datasets from three mobile and embedded sensing applications in a range of scenarios having different learning complexities. More specifically, we implement an end-to-end continual learning framework on edge devices. Then we investigate the generalizability, trade-offs between performance, storage, computational costs, and memory footprint of different continual learning methods. Our findings suggest that replay with exemplars-based schemes such as iCaRL has the best performance trade-offs, even in complex scenarios, at the expense of some storage space (few MBs) for training examples (1% to 5%). We also demonstrate for the first time that it is feasible and practical to run continual learning on-device with a limited memory budget. In particular, the latency on two types of mobile and embedded devices suggests that both incremental learning time (few seconds - 4 minutes) and training time (1 - 75 minutes) across datasets are acceptable, as training could happen on the device when the embedded device is charging thereby ensuring complete data privacy. Finally, we present some guidelines for practitioners who want to apply a continual learning paradigm for mobile sensing tasks.
Double-Barreled Question Detection at Momentive
Feb 12, 2022
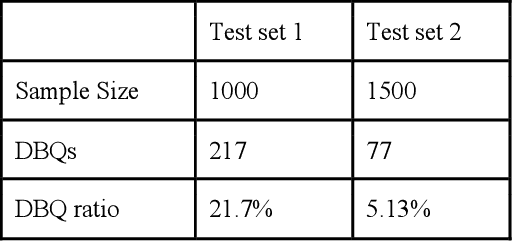
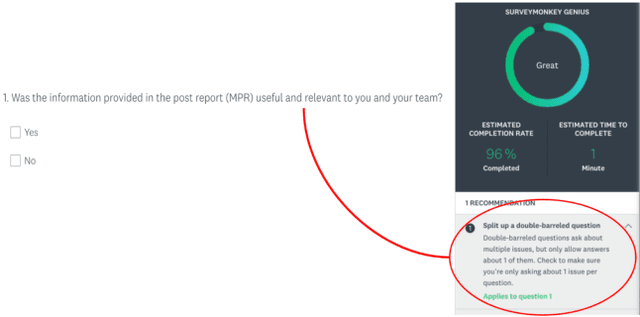
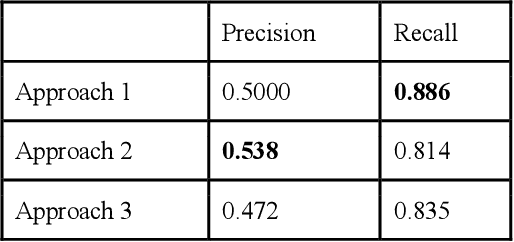
Momentive offers solutions in market research, customer experience, and enterprise feedback. The technology is gleaned from the billions of real responses to questions asked on the platform. However, people may create biased questions. A double-barreled question (DBQ) is a common type of biased question that asks two aspects in one question. For example, "Do you agree with the statement: The food is yummy, and the service is great.". This DBQ confuses survey respondents because there are two parts in a question. DBQs impact both the survey respondents and the survey owners. Momentive aims to detect DBQs and recommend survey creators to make a change towards gathering high quality unbiased survey data. Previous research work has suggested detecting DBQs by checking the existence of grammatical conjunction. While this is a simple rule-based approach, this method is error-prone because conjunctions can also exist in properly constructed questions. We present an end-to-end machine learning approach for DBQ classification in this work. We handled this imbalanced data using active learning, and compared state-of-the-art embedding algorithms to transform text data into vectors. Furthermore, we proposed a model interpretation technique propagating the vector-level SHAP values to a SHAP value for each word in the questions. We concluded that the word2vec subword embedding with maximum pooling is the optimal word embedding representation in terms of precision and running time in the offline experiments using the survey data at Momentive. The A/B test and production metrics indicate that this model brings a positive change to the business. To the best of our knowledge, this is the first machine learning framework for DBQ detection, and it successfully differentiates Momentive from the competitors. We hope our work sheds light on machine learning approaches for bias question detection.
A Flexible HLS Hoeffding Tree Implementation for Runtime Learning on FPGA
Dec 03, 2021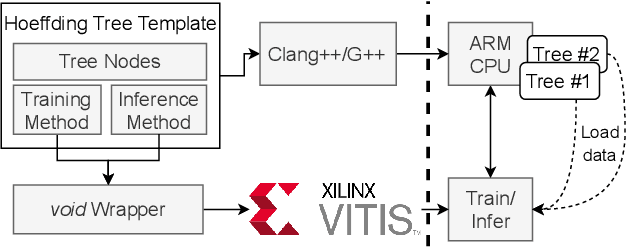

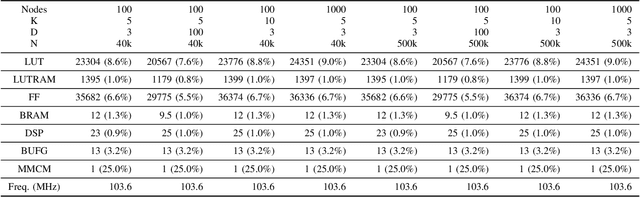
Decision trees are often preferred when implementing Machine Learning in embedded systems for their simplicity and scalability. Hoeffding Trees are a type of Decision Trees that take advantage of the Hoeffding Bound to allow them to learn patterns in data without having to continuously store the data samples for future reprocessing. This makes them especially suitable for deployment on embedded devices. In this work we highlight the features of an HLS implementation of the Hoeffding Tree. The implementation parameters include the feature size of the samples (D), the number of output classes (K), and the maximum number of nodes to which the tree is allowed to grow (Nd). We target a Xilinx MPSoC ZCU102, and evaluate: the design's resource requirements and clock frequency for different numbers of classes and feature size, the execution time on several synthetic datasets of varying sample sizes (N), number of output classes and the execution time and accuracy for two datasets from UCI. For a problem size of D3, K5, and N40000, a single decision tree operating at 103MHz is capable of 8.3x faster inference than the 1.2GHz ARM Cortex-A53 core. Compared to a reference implementation of the Hoeffding tree, we achieve comparable classification accuracy for the UCI datasets.