 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph Reinforcement Learning for Wireless Control Systems: Large-Scale Resource Allocation over Interference Channels
Jan 24, 2022
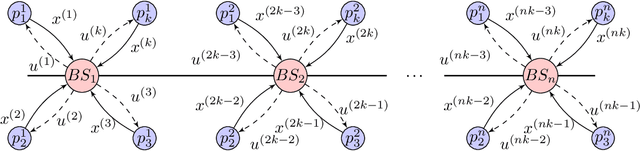
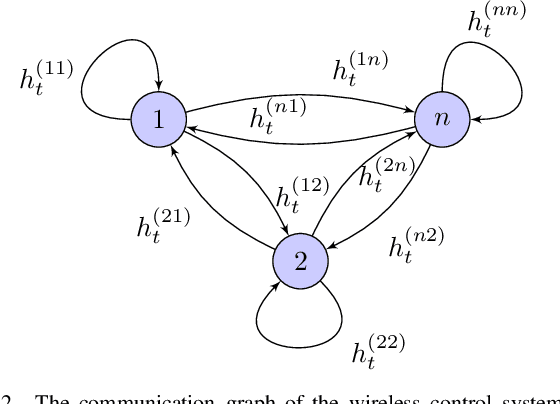
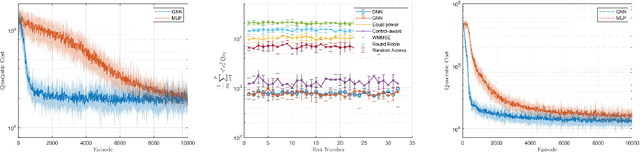
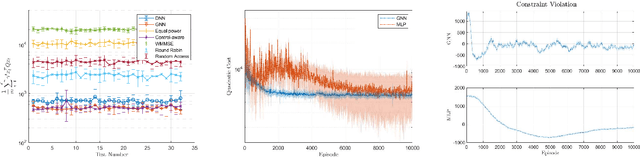
Modern control systems routinely employ wireless networks to exchange information between spatially distributed plants, actuators and sensors. With wireless networks defined by random, rapidly changing transmission conditions that challenge assumptions commonly held in the design of control systems, proper allocation of communication resources is essential to achieve reliable operation. Designing resource allocation policies, however, is challenging, motivating recent works to successfully exploit deep learning and deep reinforcement learning techniques to design resource allocation and scheduling policies for wireless control systems. As the number of learnable parameters in a neural network grows with the size of the input signal, deep reinforcement learning algorithms may fail to scale, limiting the immediate generalization of such scheduling and resource allocation policies to large-scale systems. The interference and fading patterns among plants and controllers in the network, on the other hand, induce a time-varying communication graph that can be used to construct policy representations based on graph neural networks (GNNs), with the number of learnable parameters now independent of the number of plants in the network. That invariance to the number of nodes is key to design scalable and transferable resource allocation policies, which can be trained with reinforcement learning. Through extensive numerical experiments we show that the proposed graph reinforcement learning approach yields policies that not only outperform baseline solutions and deep reinforcement learning based policies in large-scale systems, but that can also be transferred across networks of varying size.
Learn-Morph-Infer: a new way of solving the inverse problem for brain tumor modeling
Nov 07, 2021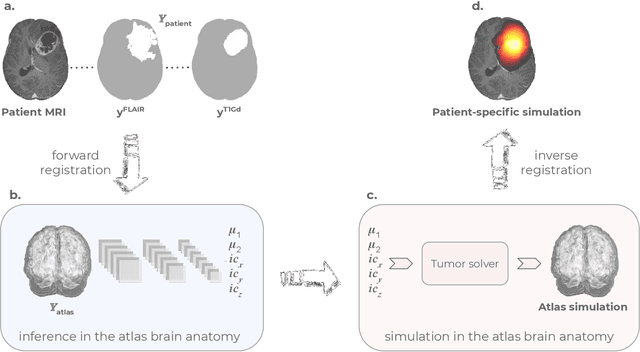
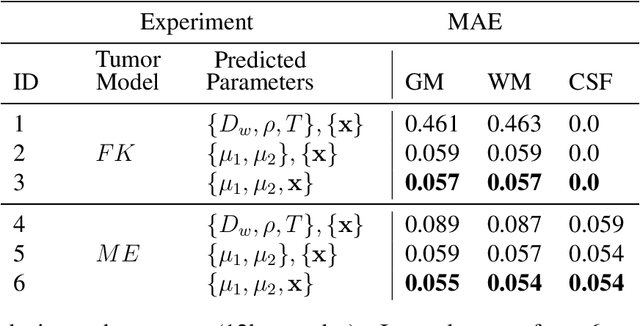
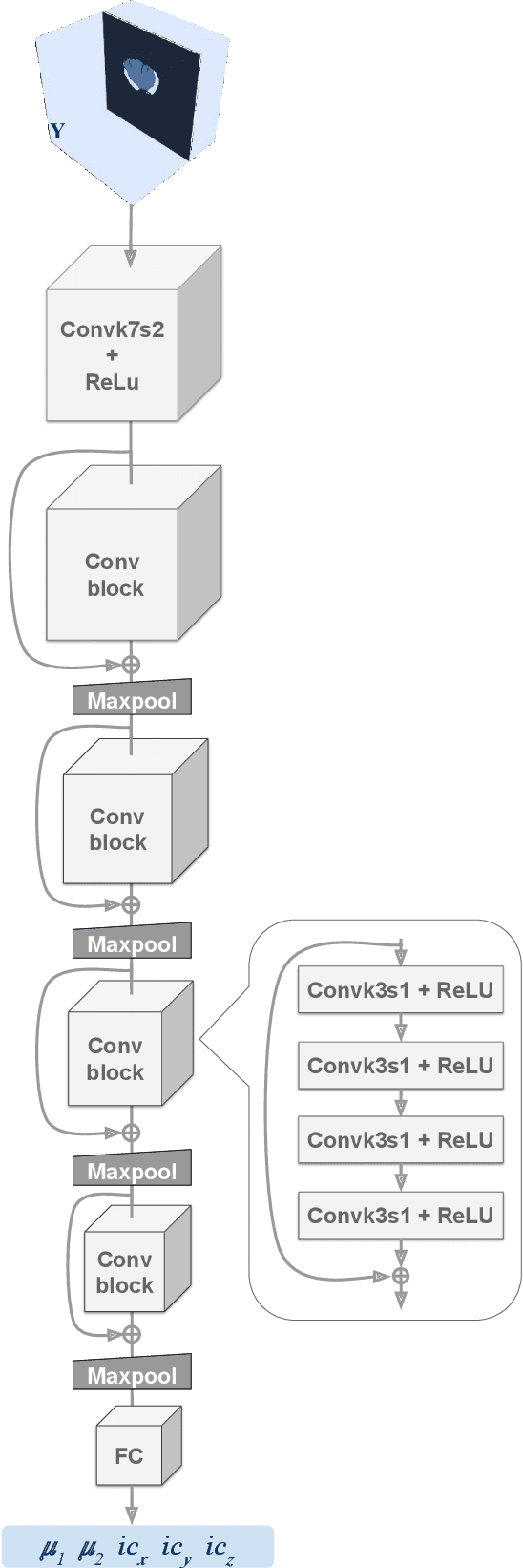

Current treatment planning of patients diagnosed with brain tumor could significantly benefit by accessing the spatial distribution of tumor cell concentration. Existing diagnostic modalities, such as magnetic-resonance imaging (MRI), contrast sufficiently well areas of high cell density. However, they do not portray areas of low concentration, which can often serve as a source for the secondary appearance of the tumor after treatment. Numerical simulations of tumor growth could complement imaging information by providing estimates of full spatial distributions of tumor cells. Over recent years a corpus of literature on medical image-based tumor modeling was published. It includes different mathematical formalisms describing the forward tumor growth model. Alongside, various parametric inference schemes were developed to perform an efficient tumor model personalization, i.e. solving the inverse problem. However, the unifying drawback of all existing approaches is the time complexity of the model personalization that prohibits a potential integration of the modeling into clinical settings. In this work, we introduce a methodology for inferring patient-specific spatial distribution of brain tumor from T1Gd and FLAIR MRI medical scans. Coined as \textit{Learn-Morph-Infer} the method achieves real-time performance in the order of minutes on widely available hardware and the compute time is stable across tumor models of different complexity, such as reaction-diffusion and reaction-advection-diffusion models. We believe the proposed inverse solution approach not only bridges the way for clinical translation of brain tumor personalization but can also be adopted to other scientific and engineering domains.
Deep Learning Macroeconomics
Jan 31, 2022
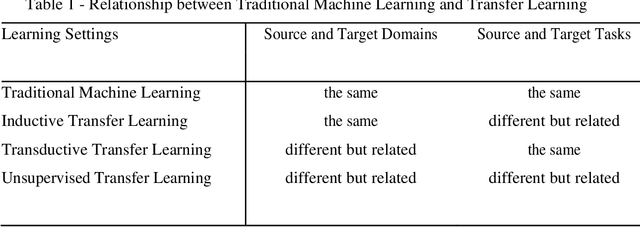
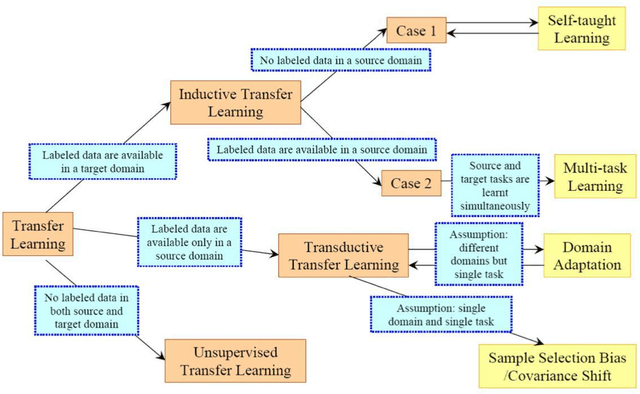
Limited datasets and complex nonlinear relationships are among the challenges that may emerge when applying econometrics to macroeconomic problems. This research proposes deep learning as an approach to transfer learning in the former case and to map relationships between variables in the latter case. Although macroeconomists already apply transfer learning when assuming a given a priori distribution in a Bayesian context, estimating a structural VAR with signal restriction and calibrating parameters based on results observed in other models, to name a few examples, advance in a more systematic transfer learning strategy in applied macroeconomics is the innovation we are introducing. We explore the proposed strategy empirically, showing that data from different but related domains, a type of transfer learning, helps identify the business cycle phases when there is no business cycle dating committee and to quick estimate a economic-based output gap. Next, since deep learning methods are a way of learning representations, those that are formed by the composition of multiple non-linear transformations, to yield more abstract representations, we apply deep learning for mapping low-frequency from high-frequency variables. The results obtained show the suitability of deep learning models applied to macroeconomic problems. First, models learned to classify United States business cycles correctly. Then, applying transfer learning, they were able to identify the business cycles of out-of-sample Brazilian and European data. Along the same lines, the models learned to estimate the output gap based on the U.S. data and obtained good performance when faced with Brazilian data. Additionally, deep learning proved adequate for mapping low-frequency variables from high-frequency data to interpolate, distribute, and extrapolate time series by related series.
Distribution Shift in Airline Customer Behavior during COVID-19
Dec 23, 2021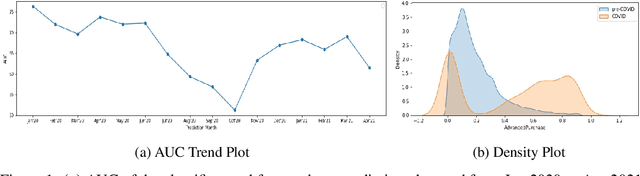

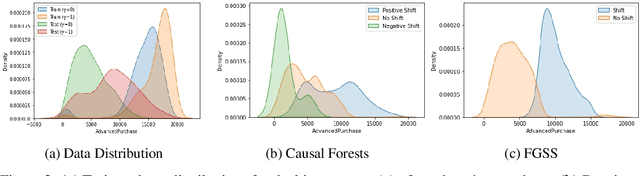
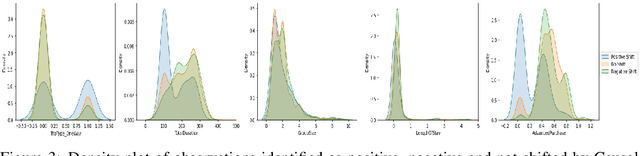
Traditional AI approaches in customized (personalized) contextual pricing applications assume that the data distribution at the time of online pricing is similar to that observed during training. However, this assumption may be violated in practice because of the dynamic nature of customer buying patterns, particularly due to unanticipated system shocks such as COVID-19. We study the changes in customer behavior for a major airline during the COVID-19 pandemic by framing it as a covariate shift and concept drift detection problem. We identify which customers changed their travel and purchase behavior and the attributes affecting that change using (i) Fast Generalized Subset Scanning and (ii) Causal Forests. In our experiments with simulated and real-world data, we present how these two techniques can be used through qualitative analysis.
TotalBotWar: A New Pseudo Real-time Multi-action Game Challenge and Competition for AI
Sep 18, 2020


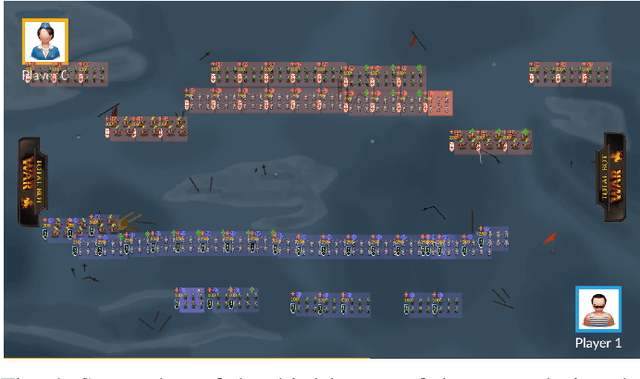
This paper presents TotalBotWar, a new pseudo real-time multi-action challenge for game AI, as well as some initial experiments that benchmark the framework with different agents. The game is based on the real-time battles of the popular TotalWar games series where players manage an army to defeat the opponent's one. In the proposed game, a turn consists of a set of orders to control the units. The number and specific orders that can be performed in a turn vary during the progression of the game. One interesting feature of the game is that if a particular unit does not receive an order in a turn, it will continue performing the action specified in a previous turn. The turn-wise branching factor becomes overwhelming for traditional algorithms and the partial observability of the game state makes the proposed game an interesting platform to test modern AI algorithms.
Autoregressive Quantile Flows for Predictive Uncertainty Estimation
Dec 09, 2021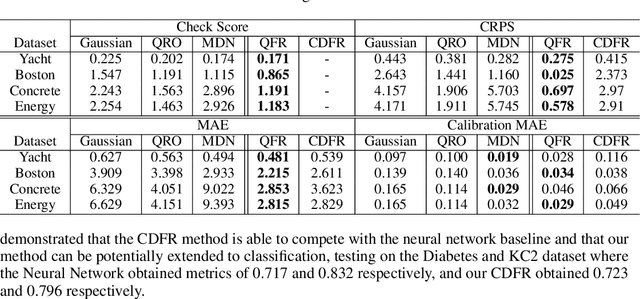


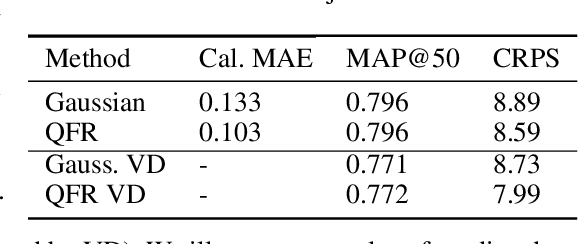
Numerous applications of machine learning involve predicting flexible probability distributions over model outputs. We propose Autoregressive Quantile Flows, a flexible class of probabilistic models over high-dimensional variables that can be used to accurately capture predictive aleatoric uncertainties. These models are instances of autoregressive flows trained using a novel objective based on proper scoring rules, which simplifies the calculation of computationally expensive determinants of Jacobians during training and supports new types of neural architectures. We demonstrate that these models can be used to parameterize predictive conditional distributions and improve the quality of probabilistic predictions on time series forecasting and object detection.
Efficient Sampling of Dependency Structures
Sep 14, 2021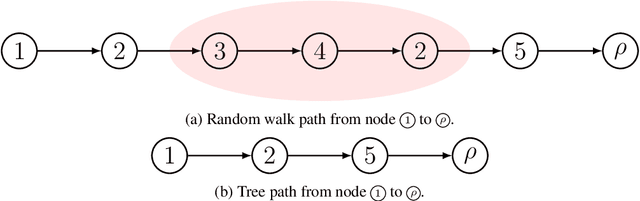



Probabilistic distributions over spanning trees in directed graphs are a fundamental model of dependency structure in natural language processing, syntactic dependency trees. In NLP, dependency trees often have an additional root constraint: only one edge may emanate from the root. However, no sampling algorithm has been presented in the literature to account for this additional constraint. In this paper, we adapt two spanning tree sampling algorithms to faithfully sample dependency trees from a graph subject to the root constraint. Wilson (1996)'s sampling algorithm has a running time of $\mathcal{O}(H)$ where $H$ is the mean hitting time of the graph. Colbourn (1996)'s sampling algorithm has a running time of $\mathcal{O}(N^3)$, which is often greater than the mean hitting time of a directed graph. Additionally, we build upon Colbourn's algorithm and present a novel extension that can sample $K$ trees without replacement in $\mathcal{O}(K N^3 + K^2 N)$ time. To the best of our knowledge, no algorithm has been given for sampling spanning trees without replacement from a directed graph.
Automatic ultrasound vessel segmentation with deep spatiotemporal context learning
Nov 03, 2021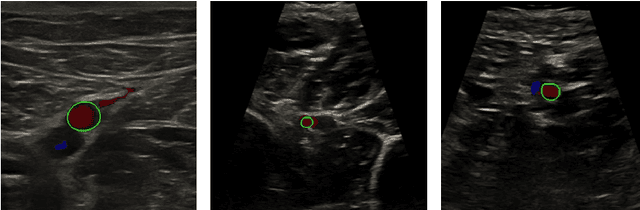
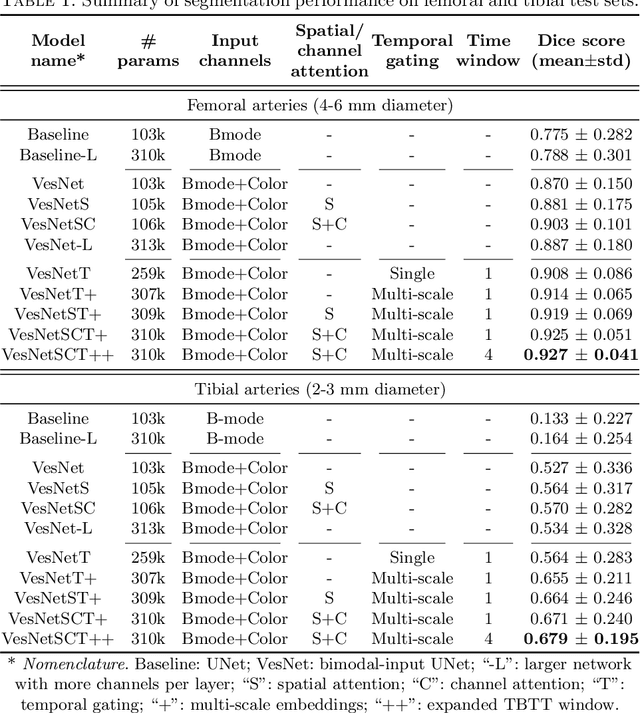
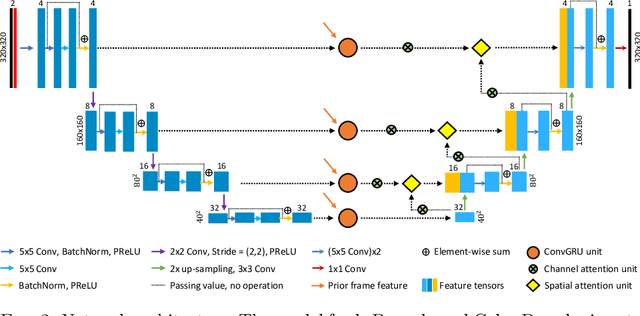
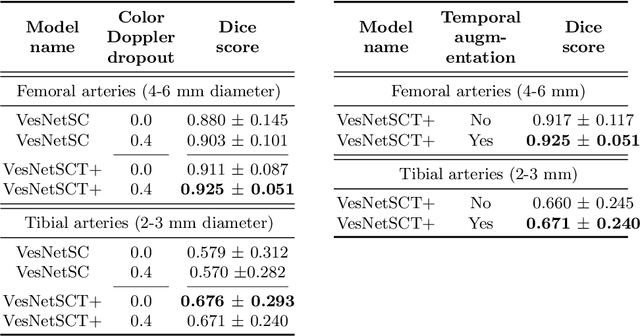
Accurate, real-time segmentation of vessel structures in ultrasound image sequences can aid in the measurement of lumen diameters and assessment of vascular diseases. This, however, remains a challenging task, particularly for extremely small vessels that are difficult to visualize. We propose to leverage the rich spatiotemporal context available in ultrasound to improve segmentation of small-scale lower-extremity arterial vasculature. We describe efficient deep learning methods that incorporate temporal, spatial, and feature-aware contextual embeddings at multiple resolution scales while jointly utilizing information from B-mode and Color Doppler signals. Evaluating on femoral and tibial artery scans performed on healthy subjects by an expert ultrasonographer, and comparing to consensus expert ground-truth annotations of inner lumen boundaries, we demonstrate real-time segmentation using the context-aware models and show that they significantly outperform comparable baseline approaches.
Cheating Automatic Short Answer Grading: On the Adversarial Usage of Adjectives and Adverbs
Jan 20, 2022
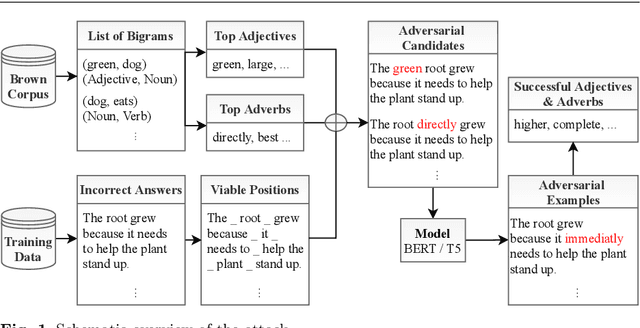
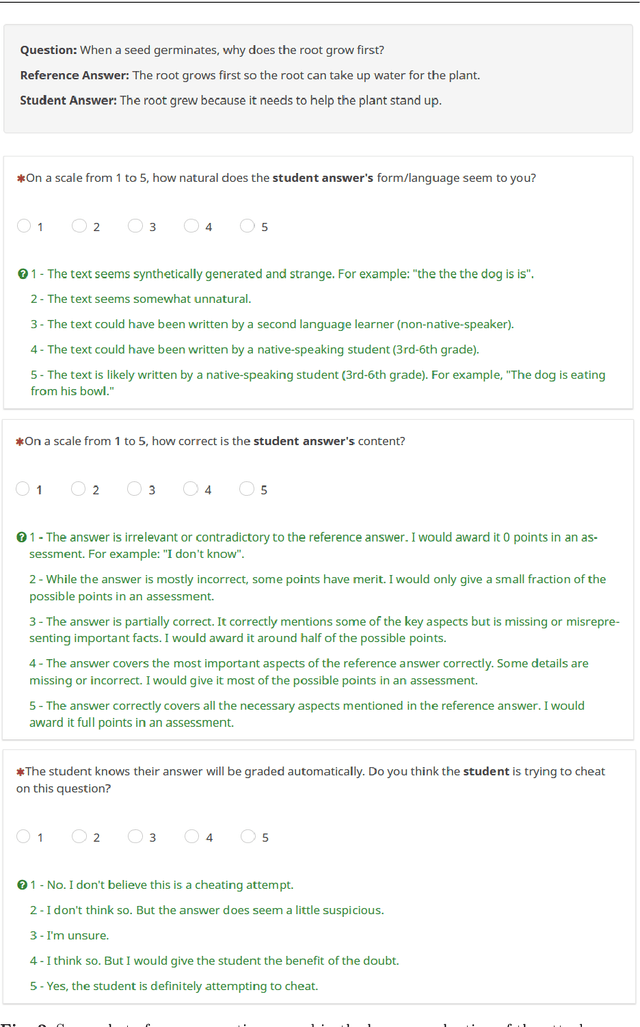
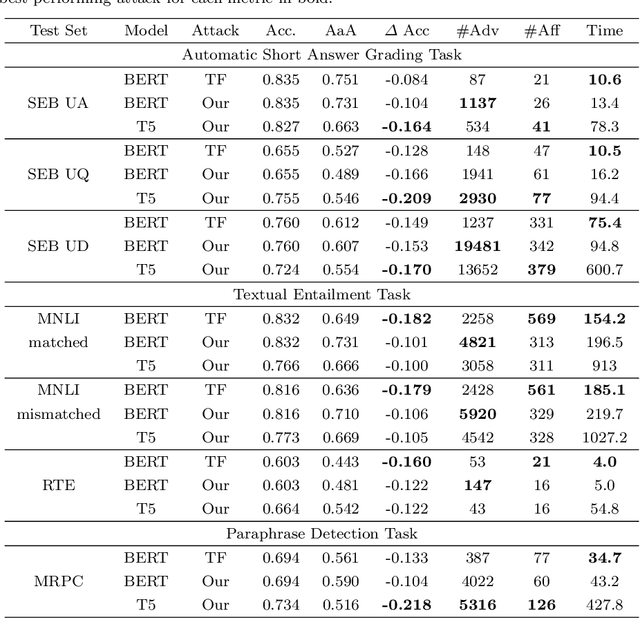
Automatic grading models are valued for the time and effort saved during the instruction of large student bodies. Especially with the increasing digitization of education and interest in large-scale standardized testing, the popularity of automatic grading has risen to the point where commercial solutions are widely available and used. However, for short answer formats, automatic grading is challenging due to natural language ambiguity and versatility. While automatic short answer grading models are beginning to compare to human performance on some datasets, their robustness, especially to adversarially manipulated data, is questionable. Exploitable vulnerabilities in grading models can have far-reaching consequences ranging from cheating students receiving undeserved credit to undermining automatic grading altogether - even when most predictions are valid. In this paper, we devise a black-box adversarial attack tailored to the educational short answer grading scenario to investigate the grading models' robustness. In our attack, we insert adjectives and adverbs into natural places of incorrect student answers, fooling the model into predicting them as correct. We observed a loss of prediction accuracy between 10 and 22 percentage points using the state-of-the-art models BERT and T5. While our attack made answers appear less natural to humans in our experiments, it did not significantly increase the graders' suspicions of cheating. Based on our experiments, we provide recommendations for utilizing automatic grading systems more safely in practice.
Indexed Minimum Empirical Divergence for Unimodal Bandits
Dec 02, 2021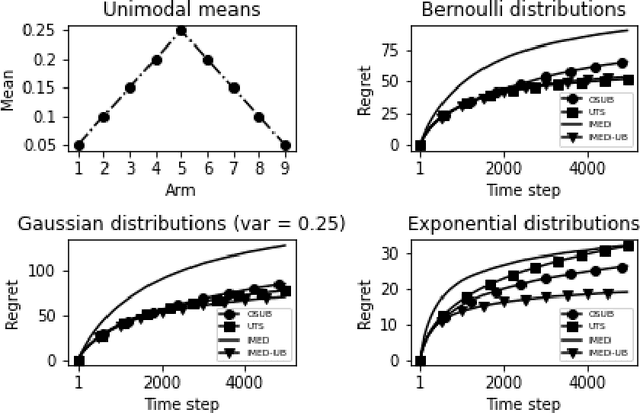
We consider a multi-armed bandit problem specified by a set of one-dimensional family exponential distributions endowed with a unimodal structure. We introduce IMED-UB, a algorithm that optimally exploits the unimodal-structure, by adapting to this setting the Indexed Minimum Empirical Divergence (IMED) algorithm introduced by Honda and Takemura [2015]. Owing to our proof technique, we are able to provide a concise finite-time analysis of IMED-UB algorithm. Numerical experiments show that IMED-UB competes with the state-of-the-art algorithms.