 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Choice of General Purpose Classifiers in Learned Bloom Filters: An Initial Analysis Within Basic Filters
Dec 13, 2021
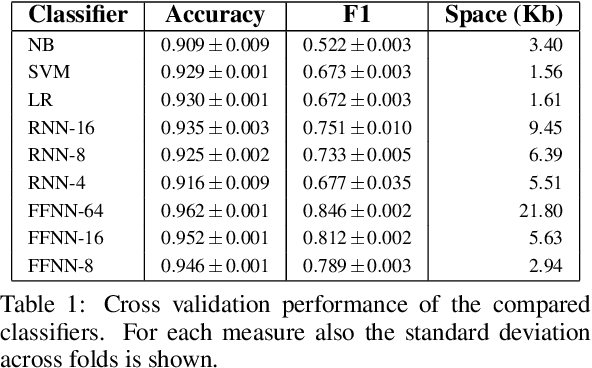
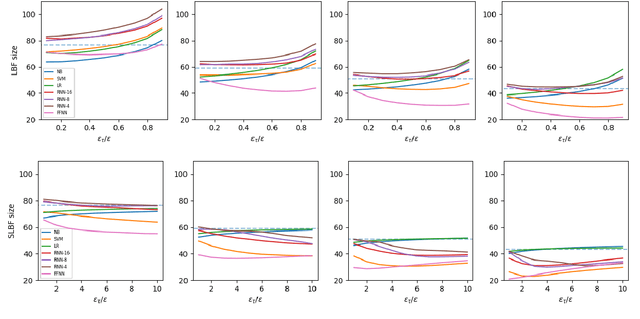
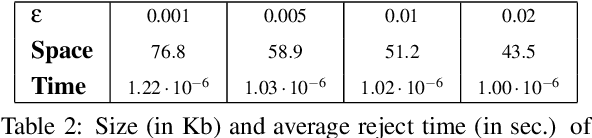
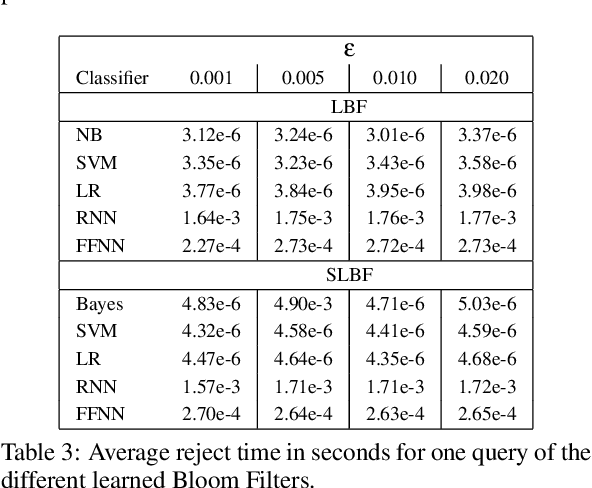
Bloom Filters are a fundamental and pervasive data structure. Within the growing area of Learned Data Structures, several Learned versions of Bloom Filters have been considered, yielding advantages over classic Filters. Each of them uses a classifier, which is the Learned part of the data structure. Although it has a central role in those new filters, and its space footprint as well as classification time may affect the performance of the Learned Filter, no systematic study of which specific classifier to use in which circumstances is available. We report progress in this area here, providing also initial guidelines on which classifier to choose among five classic classification paradigms.
AlphaFold Accelerates Artificial Intelligence Powered Drug Discovery: Efficient Discovery of a Novel Cyclin-dependent Kinase 20 (CDK20) Small Molecule Inhibitor
Jan 21, 2022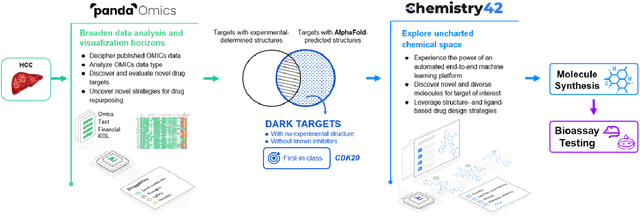

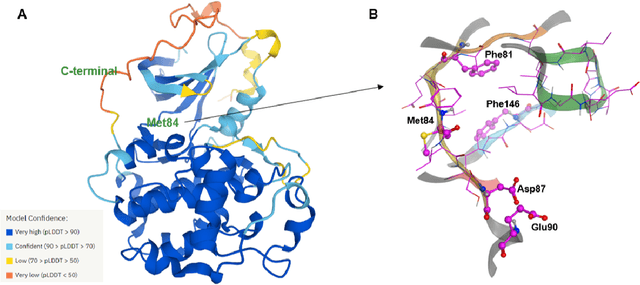
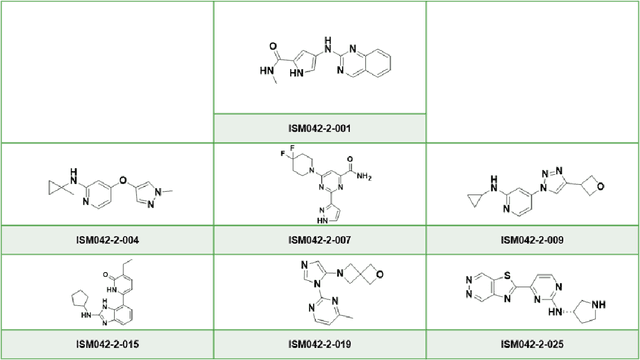
The AlphaFold computer program predicted protein structures for the whole human genome, which has been considered as a remarkable breakthrough both in artificial intelligence (AI) application and structural biology. Despite the varying confidence level, these predicted structures still could significantly contribute to the structure-based drug design of novel targets, especially the ones with no or limited structural information. In this work, we successfully applied AlphaFold in our end-to-end AI-powered drug discovery engines constituted of a biocomputational platform PandaOmics and a generative chemistry platform Chemistry42, to identify a first-in-class hit molecule of a novel target without an experimental structure starting from target selection towards hit identification in a cost- and time-efficient manner. PandaOmics provided the targets of interest and Chemistry42 generated the molecules based on the AlphaFold predicted structure, and the selected molecules were synthesized and tested in biological assays. Through this approach, we identified a small molecule hit compound for CDK20 with a Kd value of 8.9 +/- 1.6 uM (n = 4) within 30 days from target selection and after only synthesizing 7 compounds. To the best of our knowledge, this is the first reported small molecule targeting CDK20 and more importantly, this work is the first demonstration of AlphaFold application in the hit identification process in early drug discovery.
Emotions as abstract evaluation criteria in biological and artificial intelligences
Nov 30, 2021
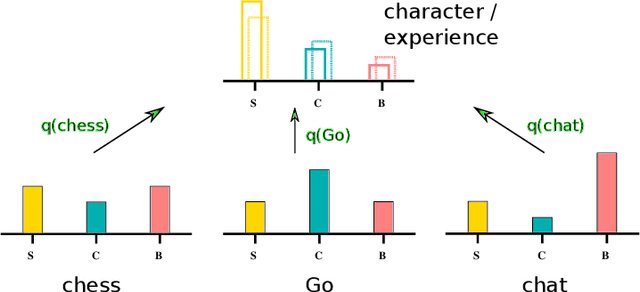
Biological as well as advanced artificial intelligences (AIs) need to decide which goals to pursue. We review nature's solution to the time allocation problem, which is based on a continuously readjusted categorical weighting mechanism we experience introspectively as emotions. One observes phylogenetically that the available number of emotional states increases hand in hand with the cognitive capabilities of animals and that raising levels of intelligence entail ever larger sets of behavioral options. Our ability to experience a multitude of potentially conflicting feelings is in this view not a leftover of a more primitive heritage, but a generic mechanism for attributing values to behavioral options that can not be specified at birth. In this view, emotions are essential for understanding the mind. For concreteness, we propose and discuss a framework which mimics emotions on a functional level. Based on time allocation via emotional stationarity (TAES), emotions are implemented as abstract criteria, such as satisfaction, challenge and boredom, which serve to evaluate activities that have been carried out. The resulting timeline of experienced emotions is compared with the `character' of the agent, which is defined in terms of a preferred distribution of emotional states. The long-term goal of the agent, to align experience with character, is achieved by optimizing the frequency for selecting individual tasks. Upon optimization, the statistics of emotion experience becomes stationary.
Identifying Adversarial Attacks on Text Classifiers
Jan 21, 2022

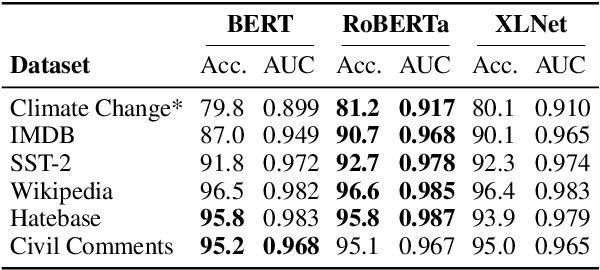
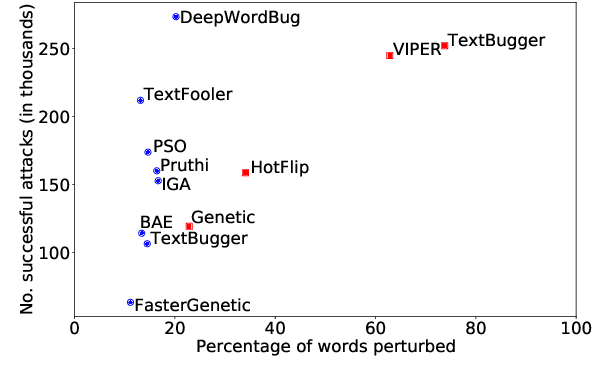
The landscape of adversarial attacks against text classifiers continues to grow, with new attacks developed every year and many of them available in standard toolkits, such as TextAttack and OpenAttack. In response, there is a growing body of work on robust learning, which reduces vulnerability to these attacks, though sometimes at a high cost in compute time or accuracy. In this paper, we take an alternate approach -- we attempt to understand the attacker by analyzing adversarial text to determine which methods were used to create it. Our first contribution is an extensive dataset for attack detection and labeling: 1.5~million attack instances, generated by twelve adversarial attacks targeting three classifiers trained on six source datasets for sentiment analysis and abuse detection in English. As our second contribution, we use this dataset to develop and benchmark a number of classifiers for attack identification -- determining if a given text has been adversarially manipulated and by which attack. As a third contribution, we demonstrate the effectiveness of three classes of features for these tasks: text properties, capturing content and presentation of text; language model properties, determining which tokens are more or less probable throughout the input; and target model properties, representing how the text classifier is influenced by the attack, including internal node activations. Overall, this represents a first step towards forensics for adversarial attacks against text classifiers.
Stability and Identification of Random Asynchronous Linear Time-Invariant Systems
Dec 08, 2020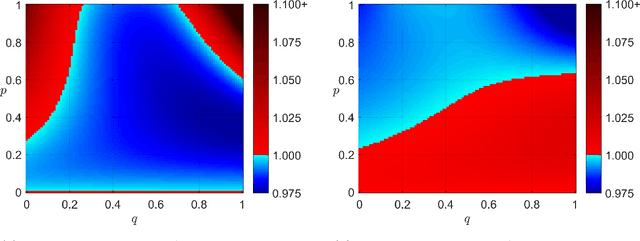

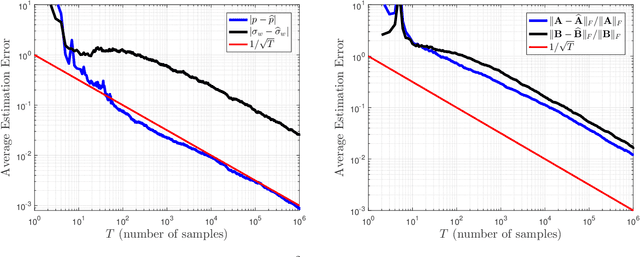
In many computational tasks and dynamical systems, asynchrony and randomization are naturally present and have been considered as ways to increase the speed and reduce the cost of computation while compromising the accuracy and convergence rate. In this work, we show the additional benefits of randomization and asynchrony on the stability of linear dynamical systems. We introduce a natural model for random asynchronous linear time-invariant (LTI) systems which generalizes the standard (synchronous) LTI systems. In this model, each state variable is updated randomly and asynchronously with some probability according to the underlying system dynamics. We examine how the mean-square stability of random asynchronous LTI systems vary with respect to randomization and asynchrony. Surprisingly, we show that the stability of random asynchronous LTI systems does not imply or is not implied by the stability of the synchronous variant of the system and an unstable synchronous system can be stabilized via randomization and/or asynchrony. We further study a special case of the introduced model, namely randomized LTI systems, where each state element is updated randomly with some fixed but unknown probability. We consider the problem of system identification of unknown randomized LTI systems using the precise characterization of mean-square stability via extended Lyapunov equation. For unknown randomized LTI systems, we propose a systematic identification method to recover the underlying dynamics. Given a single input/output trajectory, our method estimates the model parameters that govern the system dynamics, the update probability of state variables, and the noise covariance using the correlation matrices of collected data and the extended Lyapunov equation. Finally, we empirically demonstrate that the proposed method consistently recovers the underlying system dynamics with the optimal rate.
Transfer RL across Observation Feature Spaces via Model-Based Regularization
Jan 01, 2022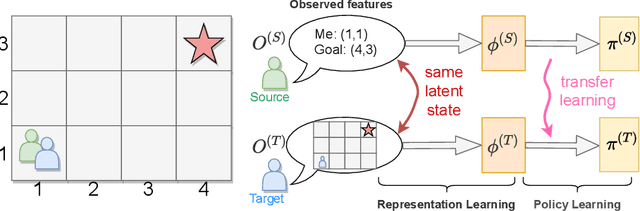
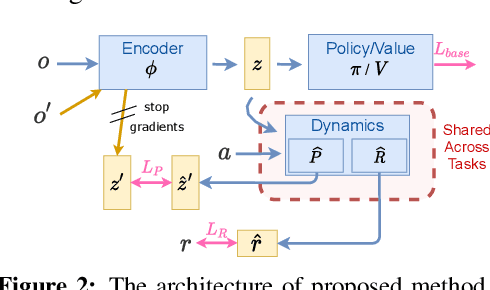
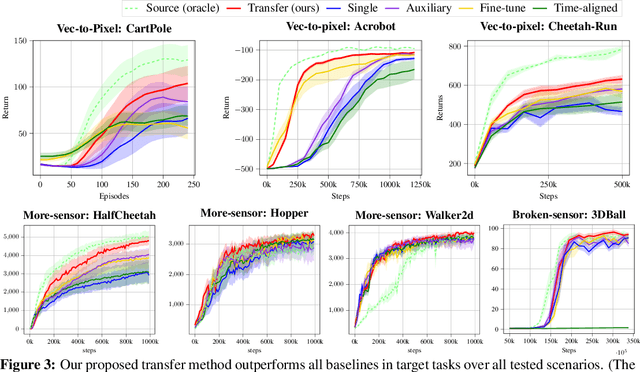
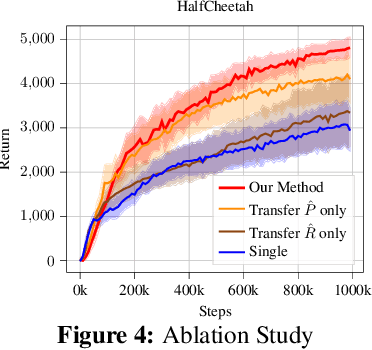
In many reinforcement learning (RL) applications, the observation space is specified by human developers and restricted by physical realizations, and may thus be subject to dramatic changes over time (e.g. increased number of observable features). However, when the observation space changes, the previous policy will likely fail due to the mismatch of input features, and another policy must be trained from scratch, which is inefficient in terms of computation and sample complexity. Following theoretical insights, we propose a novel algorithm which extracts the latent-space dynamics in the source task, and transfers the dynamics model to the target task to use as a model-based regularizer. Our algorithm works for drastic changes of observation space (e.g. from vector-based observation to image-based observation), without any inter-task mapping or any prior knowledge of the target task. Empirical results show that our algorithm significantly improves the efficiency and stability of learning in the target task.
Video Intelligence as a component of a Global Security system
Jan 12, 2022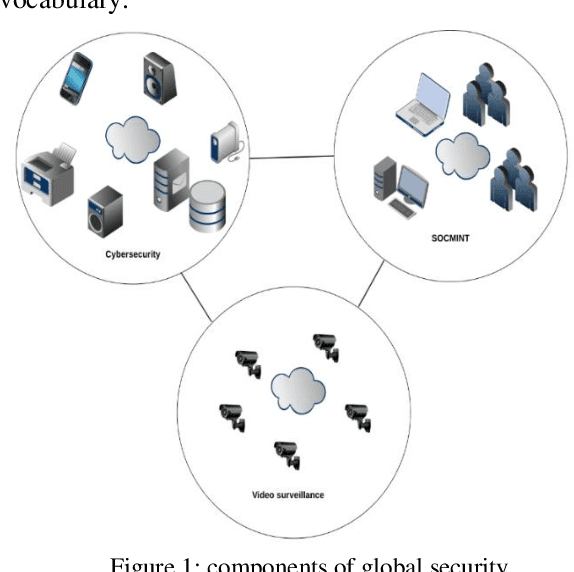
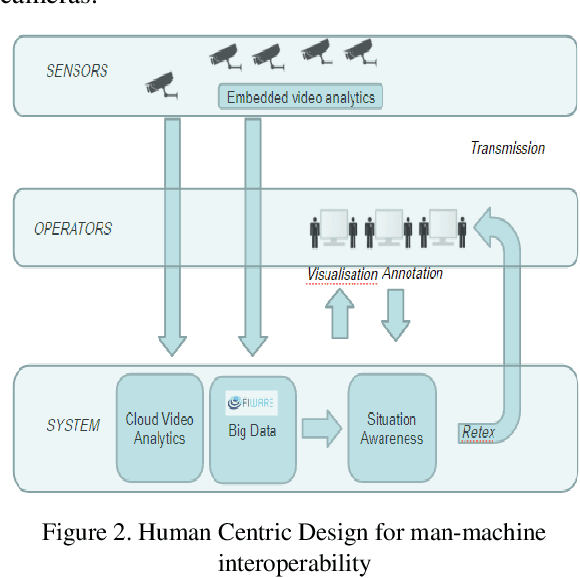
This paper describes the evolution of our research from video analytics to a global security system with focus on the video surveillance component. Indeed video surveillance has evolved from a commodity security tool up to the most efficient way of tracking perpetrators when terrorism hits our modern urban centers. As number of cameras soars, one could expect the system to leverage the huge amount of data carried through the video streams to provide fast access to video evidences, actionable intelligence for monitoring real-time events and enabling predictive capacities to assist operators in their surveillance tasks. This research explores a hybrid platform for video intelligence capture, automated data extraction, supervised Machine Learning for intelligently assisted urban video surveillance; Extension to other components of a global security system are discussed. Applying Knowledge Management principles in this research helps with deep problem understanding and facilitates the implementation of efficient information and experience sharing decision support systems providing assistance to people on the field as well as in operations centers. The originality of this work is also the creation of "common" human-machine and machine to machine language and a security ontology.
Unsupervised Adaptation of Semantic Segmentation Models without Source Data
Dec 04, 2021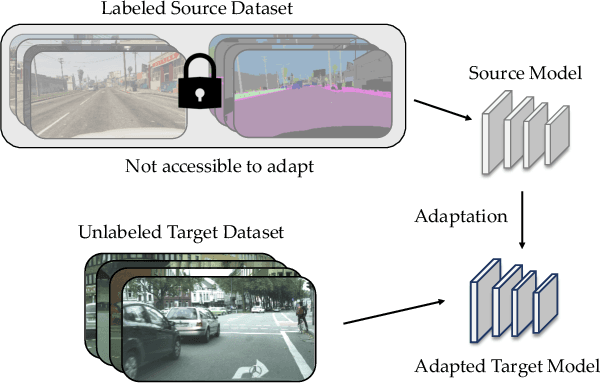
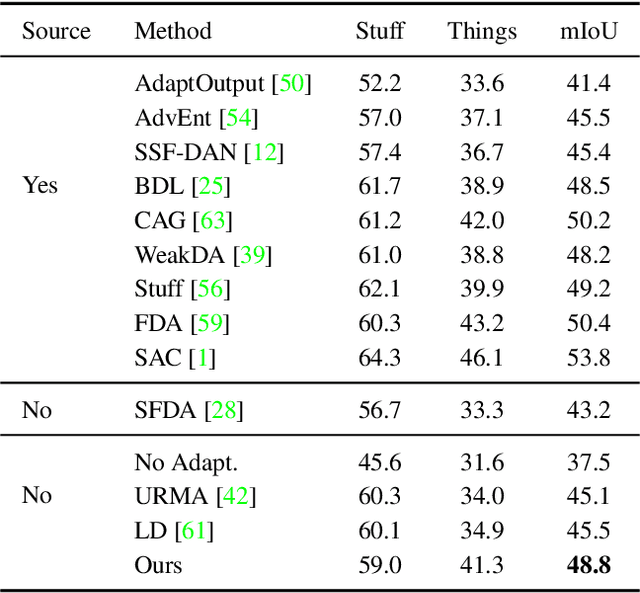
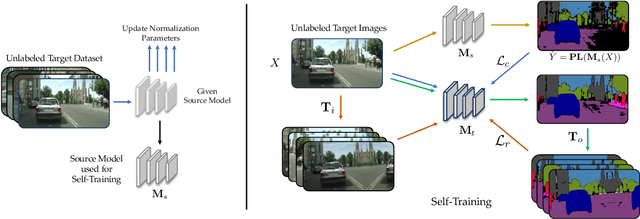
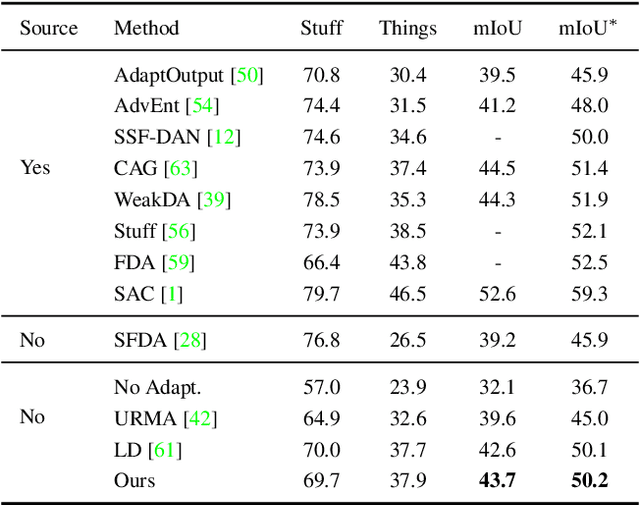
We consider the novel problem of unsupervised domain adaptation of source models, without access to the source data for semantic segmentation. Unsupervised domain adaptation aims to adapt a model learned on the labeled source data, to a new unlabeled target dataset. Existing methods assume that the source data is available along with the target data during adaptation. However, in practical scenarios, we may only have access to the source model and the unlabeled target data, but not the labeled source, due to reasons such as privacy, storage, etc. In this work, we propose a self-training approach to extract the knowledge from the source model. To compensate for the distribution shift from source to target, we first update only the normalization parameters of the network with the unlabeled target data. Then we employ confidence-filtered pseudo labeling and enforce consistencies against certain transformations. Despite being very simple and intuitive, our framework is able to achieve significant performance gains compared to directly applying the source model on the target data as reflected in our extensive experiments and ablation studies. In fact, the performance is just a few points away from the recent state-of-the-art methods which use source data for adaptation. We further demonstrate the generalisability of the proposed approach for fully test-time adaptation setting, where we do not need any target training data and adapt only during test-time.
Online Multi-horizon Transaction Metric Estimation with Multi-modal Learning in Payment Networks
Sep 22, 2021

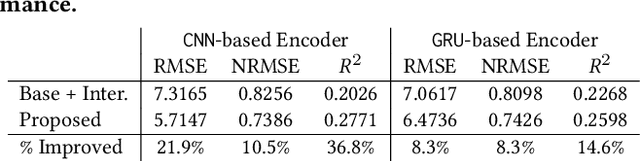
Predicting metrics associated with entities' transnational behavior within payment processing networks is essential for system monitoring. Multivariate time series, aggregated from the past transaction history, can provide valuable insights for such prediction. The general multivariate time series prediction problem has been well studied and applied across several domains, including manufacturing, medical, and entomology. However, new domain-related challenges associated with the data such as concept drift and multi-modality have surfaced in addition to the real-time requirements of handling the payment transaction data at scale. In this work, we study the problem of multivariate time series prediction for estimating transaction metrics associated with entities in the payment transaction database. We propose a model with five unique components to estimate the transaction metrics from multi-modality data. Four of these components capture interaction, temporal, scale, and shape perspectives, and the fifth component fuses these perspectives together. We also propose a hybrid offline/online training scheme to address concept drift in the data and fulfill the real-time requirements. Combining the estimation model with a graphical user interface, the prototype transaction metric estimation system has demonstrated its potential benefit as a tool for improving a payment processing company's system monitoring capability.
GIMIRec: Global Interaction Information Aware Multi-Interest Framework for Sequential Recommendation
Dec 16, 2021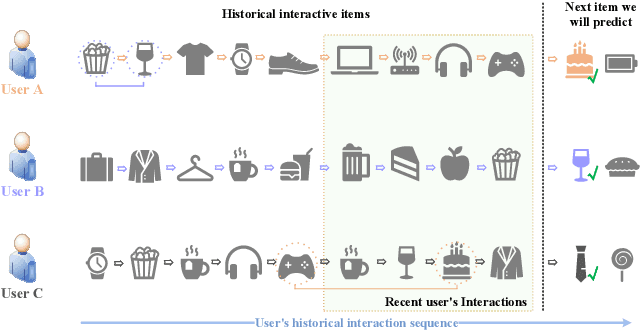
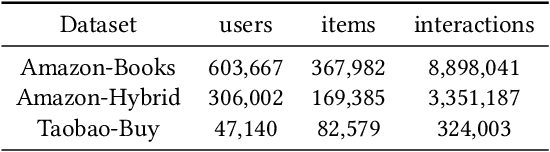
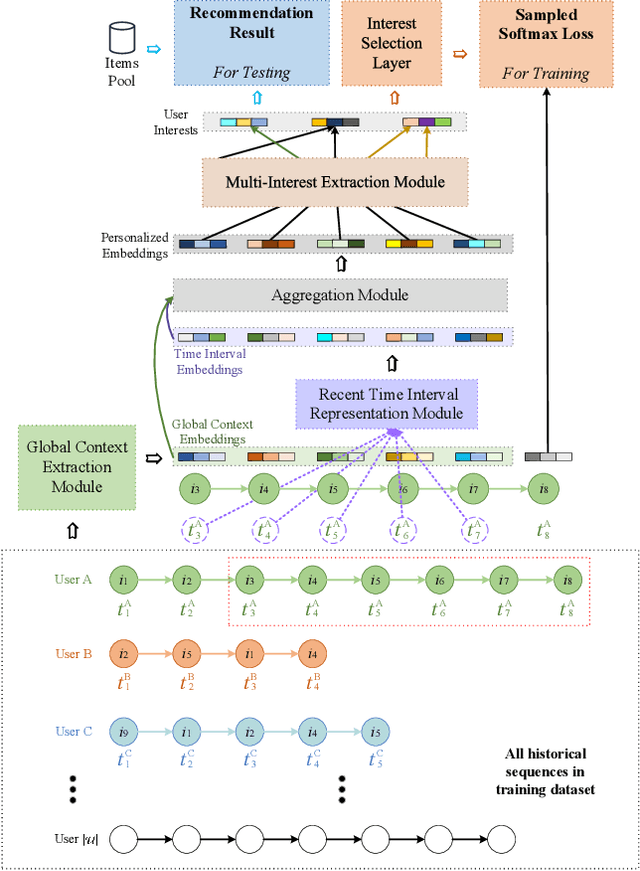
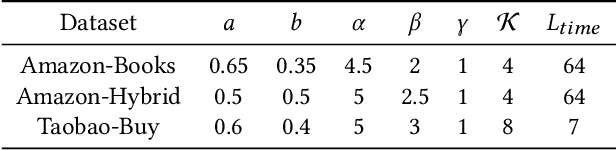
Sequential recommendation based on multi-interest framework models the user's recent interaction sequence into multiple different interest vectors, since a single low-dimensional vector cannot fully represent the diversity of user interests. However, most existing models only intercept users' recent interaction behaviors as training data, discarding a large amount of historical interaction sequences. This may raise two issues. On the one hand, data reflecting multiple interests of users is missing; on the other hand, the co-occurrence between items in historical user-item interactions is not fully explored. To tackle the two issues, this paper proposes a novel sequential recommendation model called "Global Interaction Aware Multi-Interest Framework for Sequential Recommendation (GIMIRec)". Specifically, a global context extraction module is firstly proposed without introducing any external information, which calculates a weighted co-occurrence matrix based on the constrained co-occurrence number of each item pair and their time interval from the historical interaction sequences of all users and then obtains the global context embedding of each item by using a simplified graph convolution. Secondly, the time interval of each item pair in the recent interaction sequence of each user is captured and combined with the global context item embedding to get the personalized item embedding. Finally, a self-attention based multi-interest framework is applied to learn the diverse interests of users for sequential recommendation. Extensive experiments on the three real-world datasets of Amazon-Books, Taobao-Buy and Amazon-Hybrid show that the performance of GIMIRec on the Recall, NDCG and Hit Rate indicators is significantly superior to that of the state-of-the-art methods. Moreover, the proposed global context extraction module can be easily transplanted to most sequential recommendation models.