 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real Time Video based Heart and Respiration Rate Monitoring
Jun 04, 2021
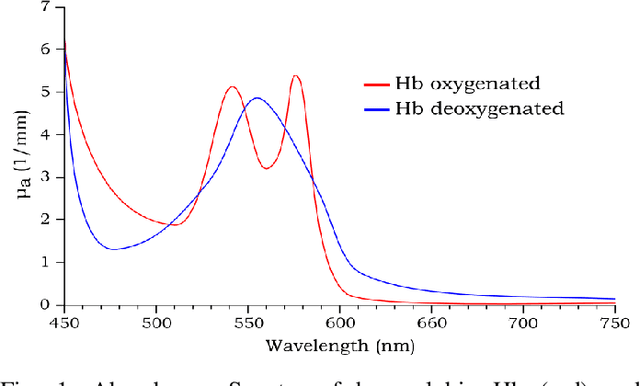


In recent years, research about monitoring vital signs by smartphones grows significantly. There are some special sensors like Electrocardiogram (ECG) and Photoplethysmographic (PPG) to detect heart rate (HR) and respiration rate (RR). Smartphone cameras also can measure HR by detecting and processing imaging Photoplethysmographic (iPPG) signals from the video of a user's face. Indeed, the variation in the intensity of the green channel can be measured by the iPPG signals of the video. This study aimed to provide a method to extract heart rate and respiration rate using the video of individuals' faces. The proposed method is based on measuring fluctuations in the Hue, and can therefore extract both HR and RR from the video of a user's face. The proposed method is evaluated by performing on 25 healthy individuals. For each subject, 20 seconds video of his/her face is recorded. Results show that the proposed approach of measuring iPPG using Hue gives more accurate rates than the Green channel.
Reusing Trained Layers of Convolutional Neural Networks to Shorten Hyperparameters Tuning Time
Jun 16, 2020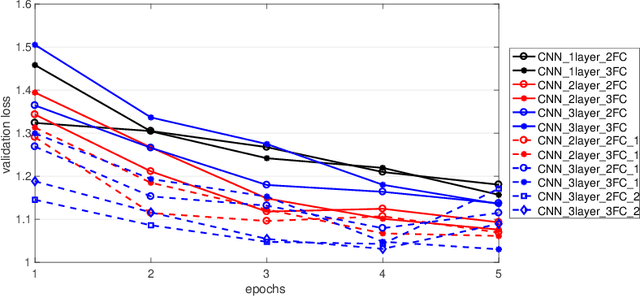

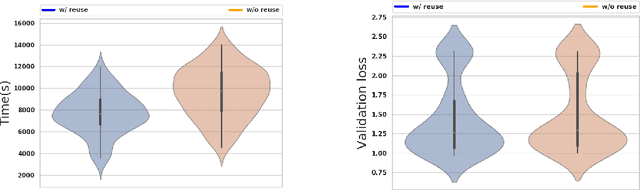
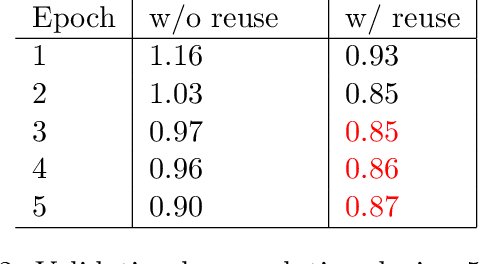
Hyperparameters tuning is a time-consuming approach, particularly when the architecture of the neural network is decided as part of this process. For instance, in convolutional neural networks (CNNs), the selection of the number and the characteristics of the hidden (convolutional) layers may be decided. This implies that the search process involves the training of all these candidate network architectures. This paper describes a proposal to reuse the weights of hidden (convolutional) layers among different trainings to shorten this process. The rationale is that if a set of convolutional layers have been trained to solve a given problem, the weights calculated in this training may be useful when a new convolutional layer is added to the network architecture. This idea has been tested using the CIFAR-10 dataset, testing different CNNs architectures with up to 3 convolutional layers and up to 3 fully connected layers. The experiments compare the training time and the validation loss when reusing and not reusing convolutional layers. They confirm that this strategy reduces the training time while it even increases the accuracy of the resulting neural network. This finding opens up the future possibility of integrating this strategy in existing AutoML methods with the purpose of reducing the total search time.
Adaptive Instance Distillation for Object Detection in Autonomous Driving
Jan 26, 2022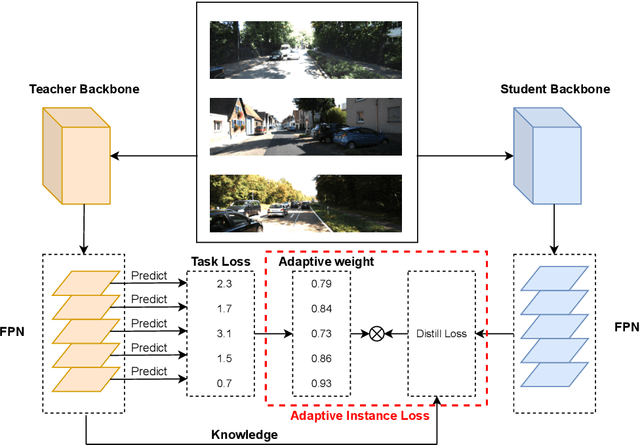


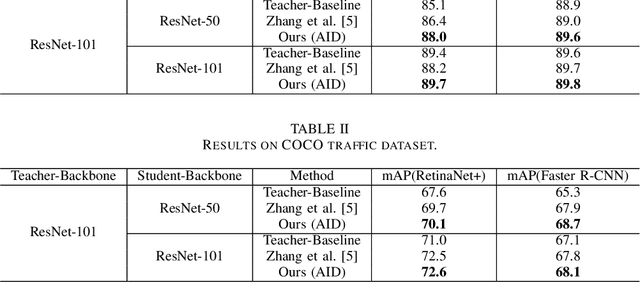
In recent years, knowledge distillation (KD) has been widely used as an effective way to derive efficient models. Through imitating a large teacher model, a lightweight student model can achieve comparable performance with more efficiency. However, most existing knowledge distillation methods are focused on classification tasks. Only a limited number of studies have applied knowledge distillation to object detection, especially in time-sensitive autonomous driving scenarios. We propose the Adaptive Instance Distillation (AID) method to selectively impart knowledge from the teacher to the student for improving the performance of knowledge distillation. Unlike previous KD methods that treat all instances equally, our AID can attentively adjust the distillation weights of instances based on the teacher model's prediction loss. We verified the effectiveness of our AID method through experiments on the KITTI and the COCO traffic datasets. The results show that our method improves the performance of existing state-of-the-art attention-guided and non-local distillation methods and achieves better distillation results on both single-stage and two-stage detectors. Compared to the baseline, our AID led to an average of 2.7% and 2.05% mAP increases for single-stage and two-stage detectors, respectively. Furthermore, our AID is also shown to be useful for self-distillation to improve the teacher model's performance.
A 1.5GS/s 8b Pipelined-SAR ADC with Output Level Shifting Settling Technique in 14nm CMOS
Jan 08, 2022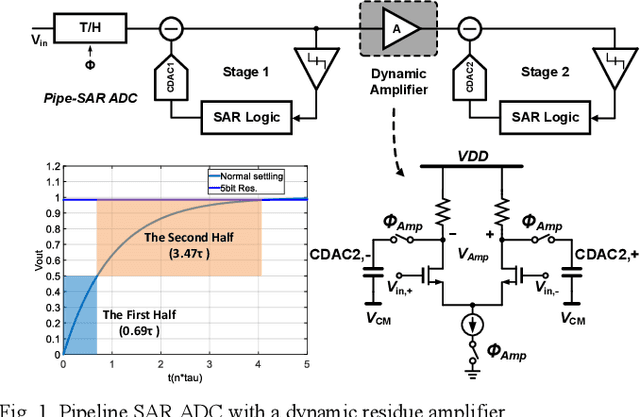
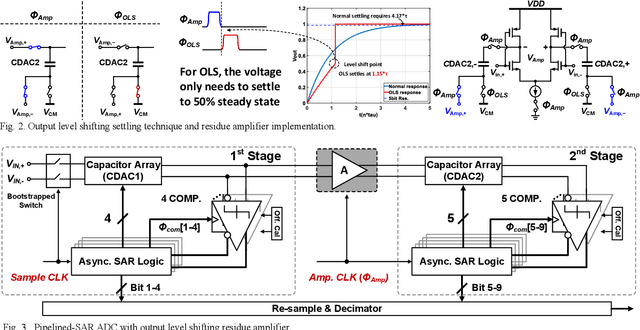
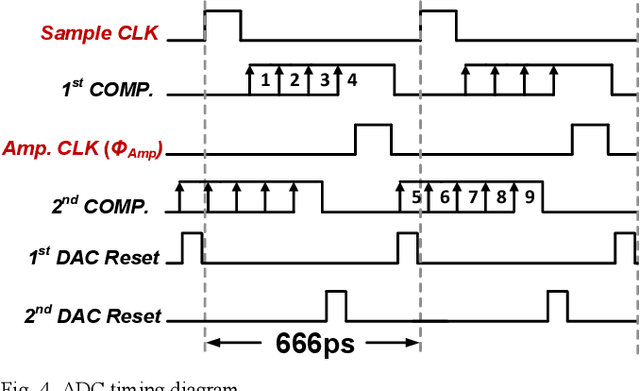
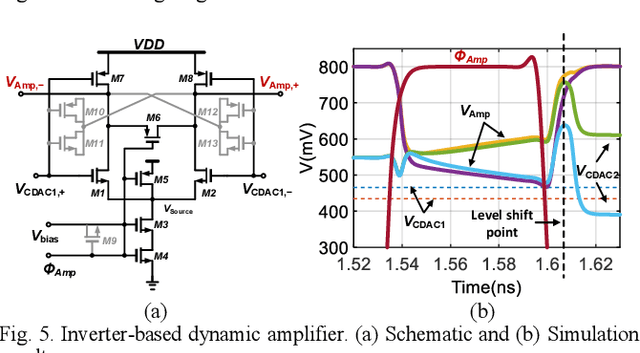
A single channel 1.5GS/s 8-bit pipelined-SAR ADC utilizes a novel output level shifting (OLS) settling technique to reduce the power and enable low-voltage operation of the dynamic residue amplifier. The ADC consists of a 4-bit first stage and a 5-bit second stage, with 1-bit redundancy to relax the offset, gain, and settling requirements of the first stage. Employing the OLS technique allows for an inter-stage gain of ~4 from the dynamic residue amplifier with a settling time that is only 28% of a conventional CML amplifier. The ADC's conversion speed is further improved with the use of parallel comparators in the two asynchronous stages. Fabricated in a 14nm FinFET technology, the ADC occupies 0.0013mm2 core area and operates with a 0.8V supply. 6.6-bit ENOB is achieved at Nyquist while consuming 2.4mW, resulting in an FOM of 16.7fJ/conv.-step.
* it is a 4 page and 9 figure IEEE Custom Integrated Circuit Conference paper
Reinforcement Learning with Sparse Rewards using Guidance from Offline Demonstration
Feb 13, 2022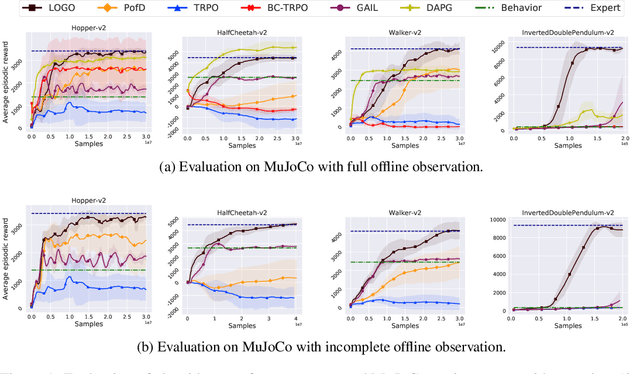
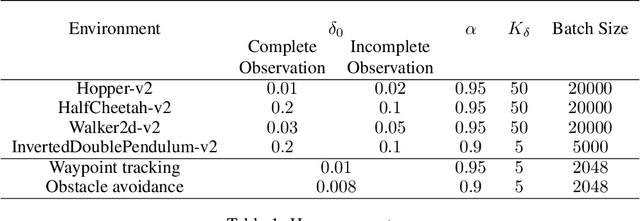
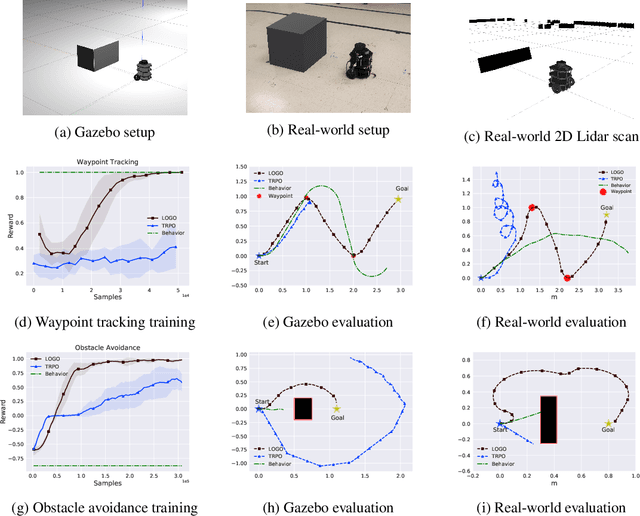
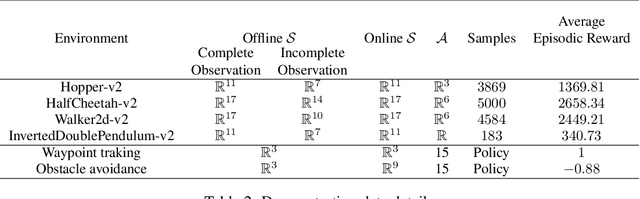
A major challenge in real-world reinforcement learning (RL) is the sparsity of reward feedback. Often, what is available is an intuitive but sparse reward function that only indicates whether the task is completed partially or fully. However, the lack of carefully designed, fine grain feedback implies that most existing RL algorithms fail to learn an acceptable policy in a reasonable time frame. This is because of the large number of exploration actions that the policy has to perform before it gets any useful feedback that it can learn from. In this work, we address this challenging problem by developing an algorithm that exploits the offline demonstration data generated by a sub-optimal behavior policy for faster and efficient online RL in such sparse reward settings. The proposed algorithm, which we call the Learning Online with Guidance Offline (LOGO) algorithm, merges a policy improvement step with an additional policy guidance step by using the offline demonstration data. The key idea is that by obtaining guidance from - not imitating - the offline data, LOGO orients its policy in the manner of the sub-optimal policy, while yet being able to learn beyond and approach optimality. We provide a theoretical analysis of our algorithm, and provide a lower bound on the performance improvement in each learning episode. We also extend our algorithm to the even more challenging incomplete observation setting, where the demonstration data contains only a censored version of the true state observation. We demonstrate the superior performance of our algorithm over state-of-the-art approaches on a number of benchmark environments with sparse rewards and censored state. Further, we demonstrate the value of our approach via implementing LOGO on a mobile robot for trajectory tracking and obstacle avoidance, where it shows excellent performance.
Nash Convergence of Mean-Based Learning Algorithms in First Price Auctions
Oct 08, 2021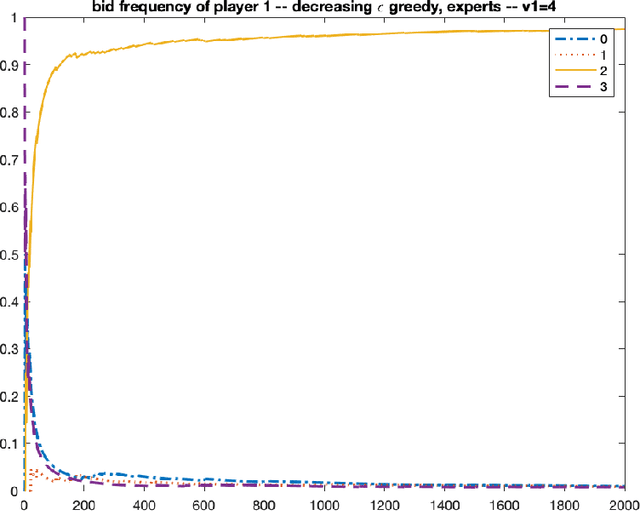
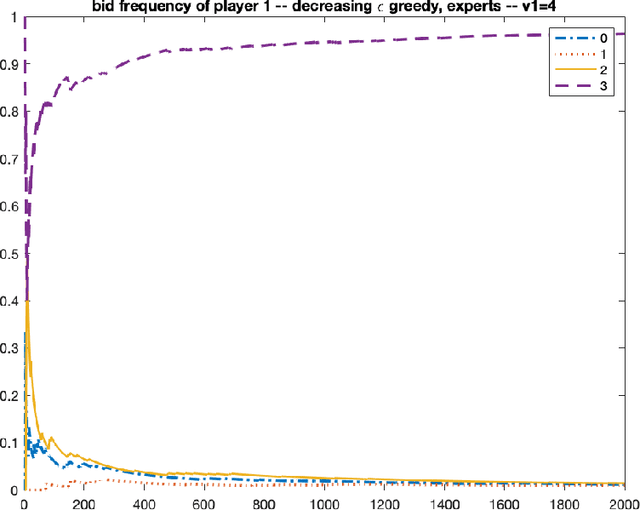
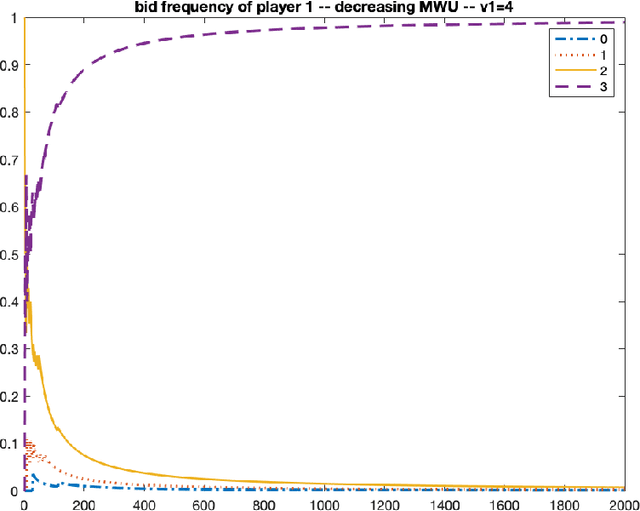
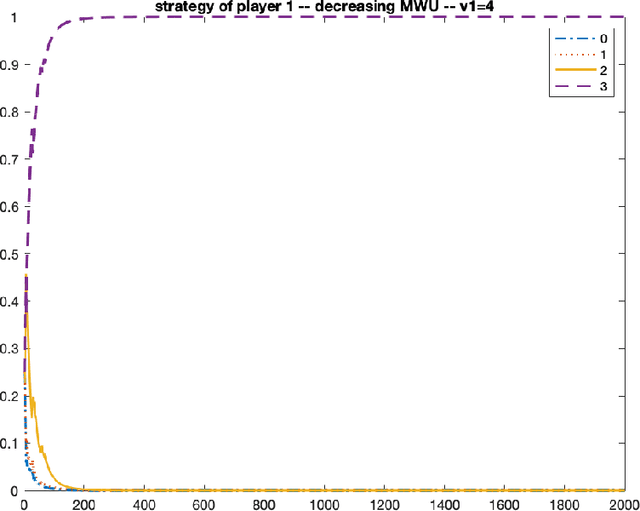
We consider repeated first price auctions where each bidder, having a deterministic type, learns to bid using a mean-based learning algorithm. We completely characterize the Nash convergence property of the bidding dynamics in two senses: (1) time-average: the fraction of rounds where bidders play a Nash equilibrium approaches to 1 in the limit; (2) last-iterate: the mixed strategy profile of bidders approaches to a Nash equilibrium in the limit. Specifically, the results depend on the number of bidders with the highest value: - If the number is at least three, the bidding dynamics almost surely converges to a Nash equilibrium of the auction, both in time-average and in last-iterate. - If the number is two, the bidding dynamics almost surely converges to a Nash equilibrium in time-average but not necessarily in last-iterate. - If the number is one, the bidding dynamics may not converge to a Nash equilibrium in time-average nor in last-iterate. Our discovery opens up new possibilities in the study of convergence dynamics of learning algorithms.
Supervised and Self-supervised Pretraining Based COVID-19 Detection Using Acoustic Breathing/Cough/Speech Signals
Jan 22, 2022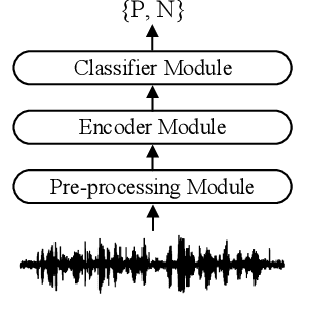
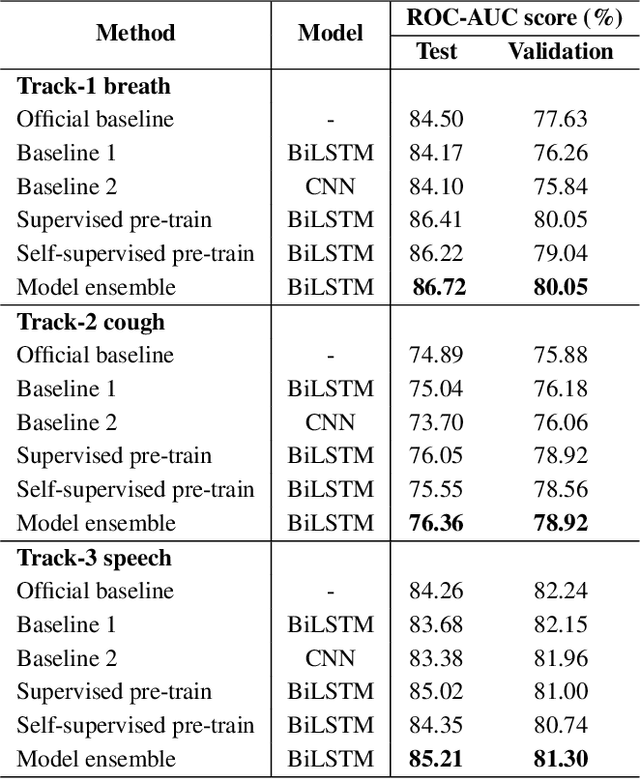
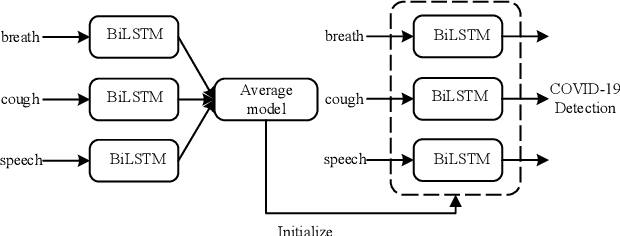
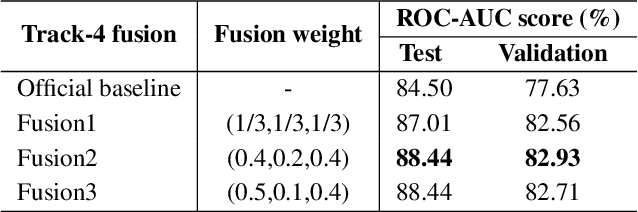
In this work, we propose a bi-directional long short-term memory (BiLSTM) network based COVID-19 detection method using breath/speech/cough signals. By using the acoustic signals to train the network, respectively, we can build individual models for three tasks, whose parameters are averaged to obtain an average model, which is then used as the initialization for the BiLSTM model training of each task. This initialization method can significantly improve the performance on the three tasks, which surpasses the official baseline results. Besides, we also utilize a public pre-trained model wav2vec2.0 and pre-train it using the official DiCOVA datasets. This wav2vec2.0 model is utilized to extract high-level features of the sound as the model input to replace conventional mel-frequency cepstral coefficients (MFCC) features. Experimental results reveal that using high-level features together with MFCC features can improve the performance. To further improve the performance, we also deploy some preprocessing techniques like silent segment removal, amplitude normalization and time-frequency mask. The proposed detection model is evaluated on the DiCOVA dataset and results show that our method achieves an area under curve (AUC) score of 88.44% on blind test in the fusion track.
Local approximation of operators
Feb 13, 2022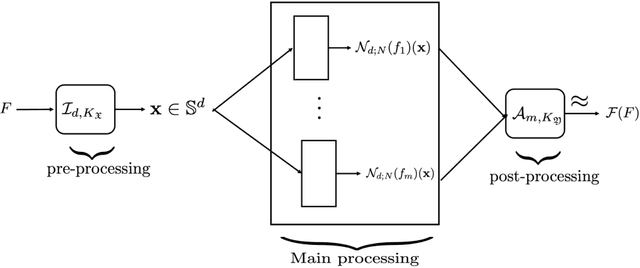
Many applications, such as system identification, classification of time series, direct and inverse problems in partial differential equations, and uncertainty quantification lead to the question of approximation of a non-linear operator between metric spaces $\mathfrak{X}$ and $\mathfrak{Y}$. We study the problem of determining the degree of approximation of a such operators on a compact subset $K_\mathfrak{X}\subset \mathfrak{X}$ using a finite amount of information. If $\mathcal{F}: K_\mathfrak{X}\to K_\mathfrak{Y}$, a well established strategy to approximate $\mathcal{F}(F)$ for some $F\in K_\mathfrak{X}$ is to encode $F$ (respectively, $\mathcal{F}(F)$) in terms of a finite number $d$ (repectively $m$) of real numbers. Together with appropriate reconstruction algorithms (decoders), the problem reduces to the approximation of $m$ functions on a compact subset of a high dimensional Euclidean space $\mathbb{R}^d$, equivalently, the unit sphere $\mathbb{S}^d$ embedded in $\mathbb{R}^{d+1}$. The problem is challenging because $d$, $m$, as well as the complexity of the approximation on $\mathbb{S}^d$ are all large, and it is necessary to estimate the accuracy keeping track of the inter-dependence of all the approximations involved. In this paper, we establish constructive methods to do this efficiently; i.e., with the constants involved in the estimates on the approximation on $\\mathbb{S}^d$ being $\mathcal{O}(d^{1/6})$. We study different smoothness classes for the operators, and also propose a method for approximation of $\mathcal{F}(F)$ using only information in a small neighborhood of $F$, resulting in an effective reduction in the number of parameters involved. To further mitigate the problem of large number of parameters, we propose prefabricated networks, resulting in a substantially smaller number of effective parameters.
Leveraging The Topological Consistencies of Learning in Deep Neural Networks
Nov 30, 2021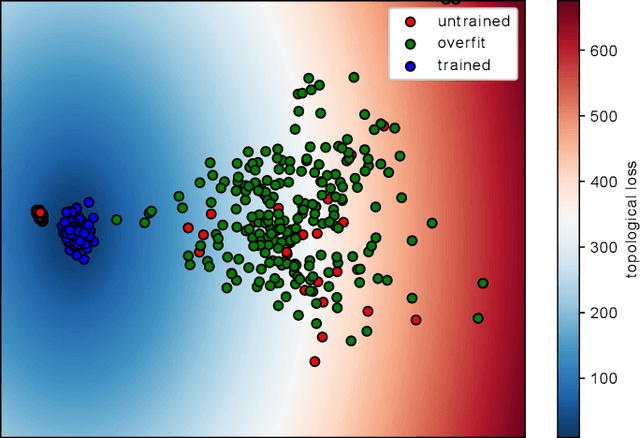

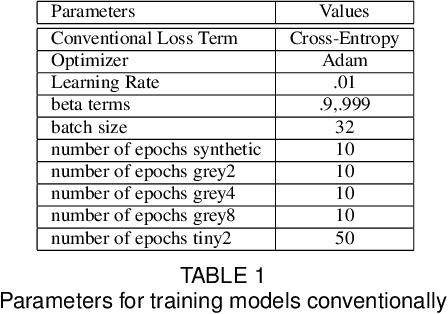
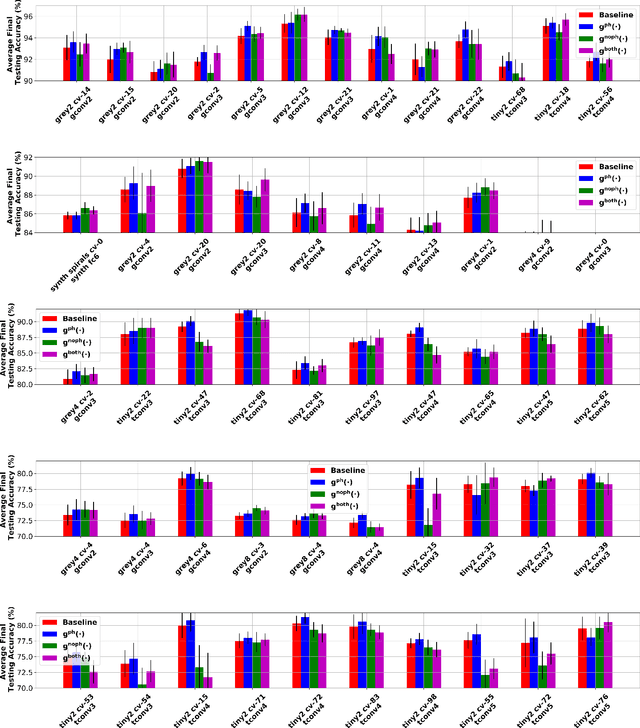
Recently, methods have been developed to accurately predict the testing performance of a Deep Neural Network (DNN) on a particular task, given statistics of its underlying topological structure. However, further leveraging this newly found insight for practical applications is intractable due to the high computational cost in terms of time and memory. In this work, we define a new class of topological features that accurately characterize the progress of learning while being quick to compute during running time. Additionally, our proposed topological features are readily equipped for backpropagation, meaning that they can be incorporated in end-to-end training. Our newly developed practical topological characterization of DNNs allows for an additional set of applications. We first show we can predict the performance of a DNN without a testing set and without the need for high-performance computing. We also demonstrate our topological characterization of DNNs is effective in estimating task similarity. Lastly, we show we can induce learning in DNNs by actively constraining the DNN's topological structure. This opens up new avenues in constricting the underlying structure of DNNs in a meta-learning framework.
Attention-based Proposals Refinement for 3D Object Detection
Jan 26, 2022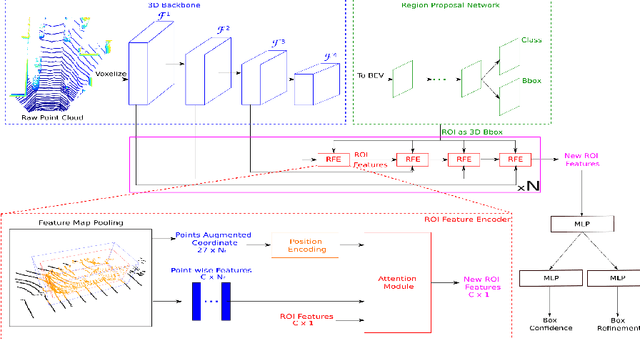
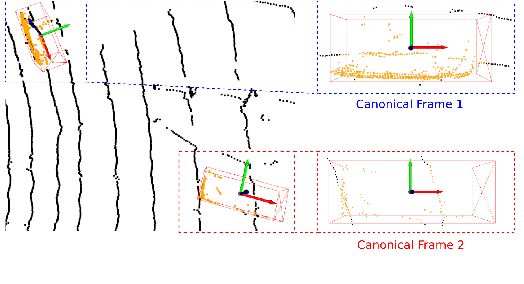
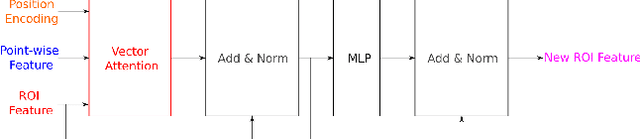
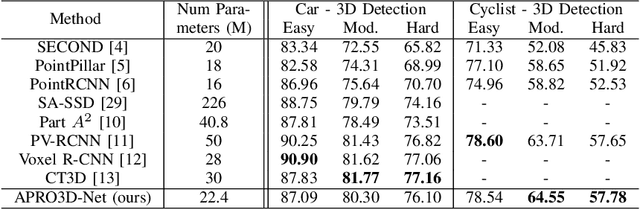
Recent advances in 3D object detection is made by developing the refinement stage for voxel-based Region Proposal Networks (RPN) to better strike the balance between accuracy and efficiency. A popular approach among state-of-the-art frameworks is to divide proposals, or Regions of Interest (ROI), into grids and extract feature for each grid location before synthesizing them to form ROI feature. While achieving impressive performances, such an approach involves a number of hand crafted components (e.g. grid sampling, set abstraction) which requires expert knowledge to be tuned correctly. This paper proposes a data-driven approach to ROI feature computing named APRO3D-Net which consists of a voxel-based RPN and a refinement stage made of Vector Attention. Unlike the original multi-head attention, Vector Attention assigns different weights to different channels within a point feature, thus being able to capture a more sophisticated relation between pooled points and ROI. Experiments on KITTI \textit{validation} set show that our method achieves competitive performance of 84.84 AP for class Car at Moderate difficulty while having the least parameters compared to closely related methods and attaining a quasi-real time inference speed at 15 FPS on NVIDIA V100 GPU. The code is released in https://github.com/quan-dao/APRO3D-Net.