 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HiSTGNN: Hierarchical Spatio-temporal Graph Neural Networks for Weather Forecasting
Jan 22, 2022
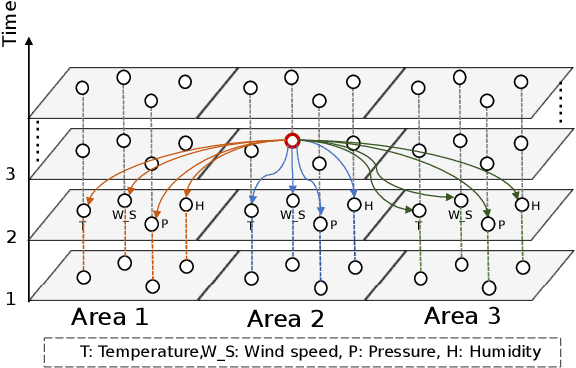
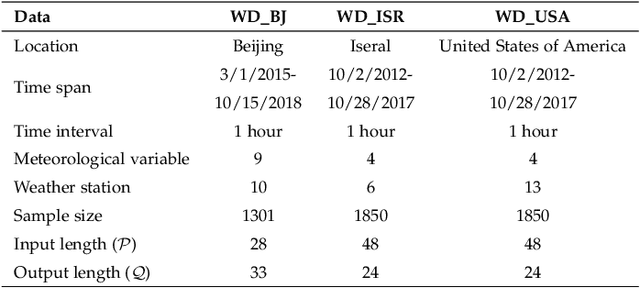
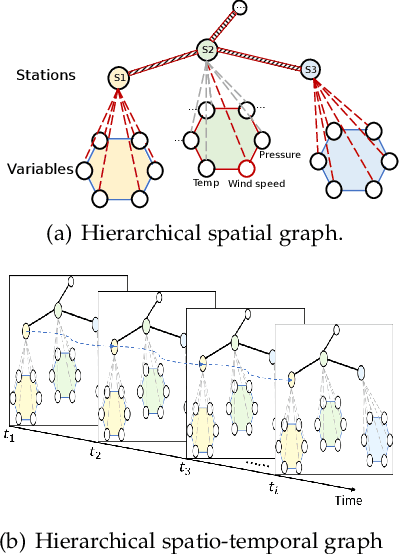
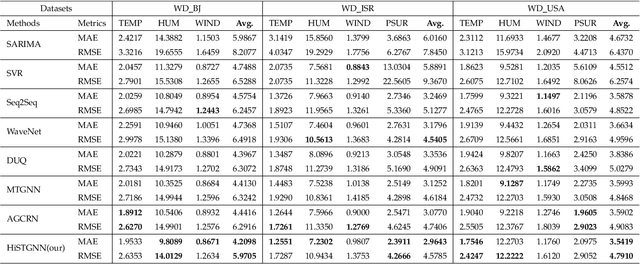
Weather Forecasting is an attractive challengeable task due to its influence on human life and complexity in atmospheric motion. Supported by massive historical observed time series data, the task is suitable for data-driven approaches, especially deep neural networks. Recently, the Graph Neural Networks (GNNs) based methods have achieved excellent performance for spatio-temporal forecasting. However, the canonical GNNs-based methods only individually model the local graph of meteorological variables per station or the global graph of whole stations, lacking information interaction between meteorological variables in different stations. In this paper, we propose a novel Hierarchical Spatio-Temporal Graph Neural Network (HiSTGNN) to model cross-regional spatio-temporal correlations among meteorological variables in multiple stations. An adaptive graph learning layer and spatial graph convolution are employed to construct self-learning graph and study hidden dependency among nodes of variable-level and station-level graph. For capturing temporal pattern, the dilated inception as the backbone of gate temporal convolution is designed to model long and various meteorological trends. Moreover, a dynamic interaction learning is proposed to build bidirectional information passing in hierarchical graph. Experimental results on three real-world meteorological datasets demonstrate the superior performance of HiSTGNN beyond 7 baselines and it reduces the errors by 4.2% to 11.6% especially compared to state-of-the-art weather forecasting method.
On reducing the order of arm-passes bandit streaming algorithms under memory bottleneck
Nov 30, 2021
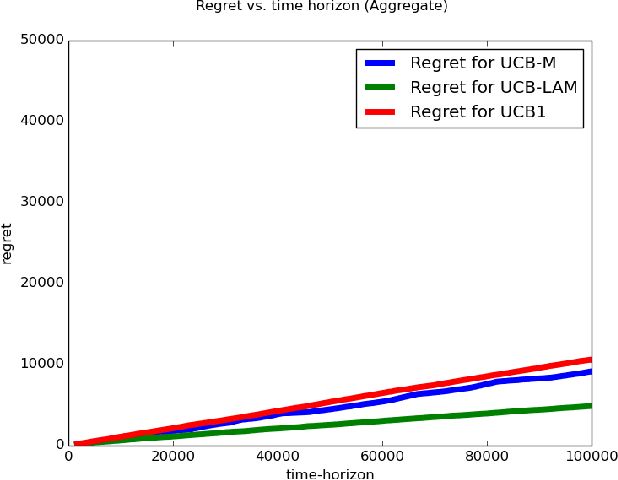
In this work we explore multi-arm bandit streaming model, especially in cases where the model faces resource bottleneck. We build over existing algorithms conditioned by limited arm memory at any instance of time. Specifically, we improve the amount of streaming passes it takes for a bandit algorithm to incur a $O(\sqrt{T\log(T)})$ regret by a logarithmic factor, and also provide 2-pass algorithms with some initial conditions to incur a similar order of regret.
Parameter Efficient Deep Probabilistic Forecasting
Dec 06, 2021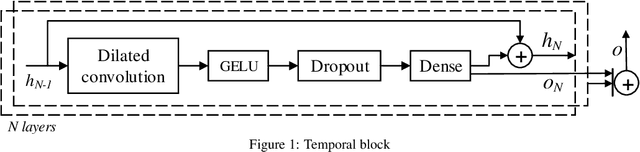

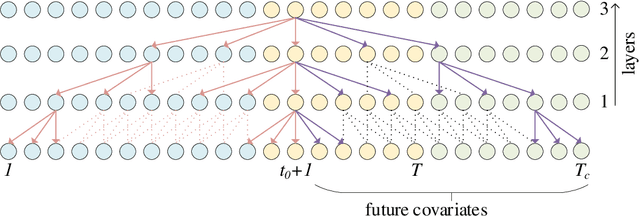
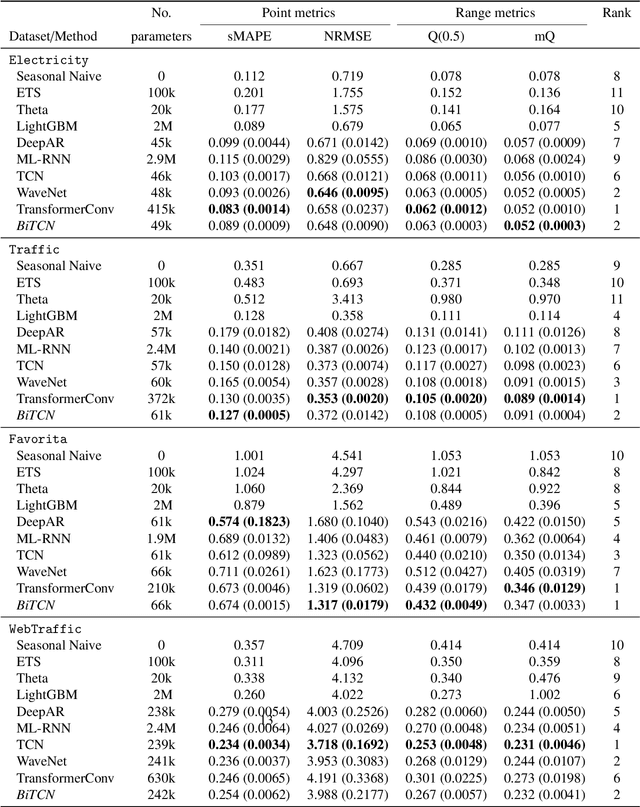
Probabilistic time series forecasting is crucial in many application domains such as retail, ecommerce, finance, or biology. With the increasing availability of large volumes of data, a number of neural architectures have been proposed for this problem. In particular, Transformer-based methods achieve state-of-the-art performance on real-world benchmarks. However, these methods require a large number of parameters to be learned, which imposes high memory requirements on the computational resources for training such models. To address this problem, we introduce a novel Bidirectional Temporal Convolutional Network (BiTCN), which requires an order of magnitude less parameters than a common Transformer-based approach. Our model combines two Temporal Convolutional Networks (TCNs): the first network encodes future covariates of the time series, whereas the second network encodes past observations and covariates. We jointly estimate the parameters of an output distribution via these two networks. Experiments on four real-world datasets show that our method performs on par with four state-of-the-art probabilistic forecasting methods, including a Transformer-based approach and WaveNet, on two point metrics (sMAPE, NRMSE) as well as on a set of range metrics (quantile loss percentiles) in the majority of cases. Secondly, we demonstrate that our method requires significantly less parameters than Transformer-based methods, which means the model can be trained faster with significantly lower memory requirements, which as a consequence reduces the infrastructure cost for deploying these models.
MMSys'22 Grand Challenge on AI-based Video Production for Soccer
Feb 02, 2022

Soccer has a considerable market share of the global sports industry, and the interest in viewing videos from soccer games continues to grow. In this respect, it is important to provide game summaries and highlights of the main game events. However, annotating and producing events and summaries often require expensive equipment and a lot of tedious, cumbersome, manual labor. Therefore, automating the video production pipeline providing fast game highlights at a much lower cost is seen as the "holy grail". In this context, recent developments in Artificial Intelligence (AI) technology have shown great potential. Still, state-of-the-art approaches are far from being adequate for practical scenarios that have demanding real-time requirements, as well as strict performance criteria (where at least the detection of official events such as goals and cards must be 100% accurate). In addition, event detection should be thoroughly enhanced by annotation and classification, proper clipping, generating short descriptions, selecting appropriate thumbnails for highlight clips, and finally, combining the event highlights into an overall game summary, similar to what is commonly aired during sports news. Even though the event tagging operation has by far received the most attention, an end-to-end video production pipeline also includes various other operations which serve the overall purpose of automated soccer analysis. This challenge aims to assist the automation of such a production pipeline using AI. In particular, we focus on the enhancement operations that take place after an event has been detected, namely event clipping (Task 1), thumbnail selection (Task 2), and game summarization (Task 3). Challenge website: https://mmsys2022.ie/authors/grand-challenge.
Bayesian nonparametric shared multi-sequence time series segmentation
Jan 27, 2020
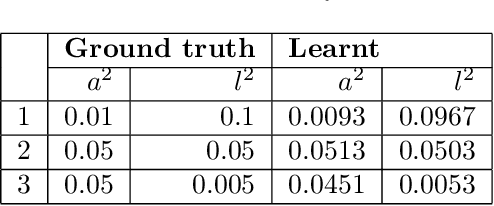
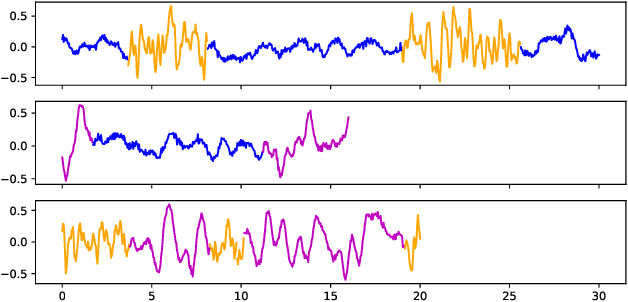
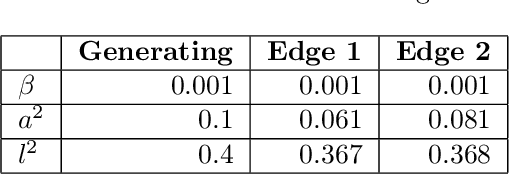
In this paper, we introduce a method for segmenting time series data using tools from Bayesian nonparametrics. We consider the task of temporal segmentation of a set of time series data into representative stationary segments. We use Gaussian process (GP) priors to impose our knowledge about the characteristics of the underlying stationary segments, and use a nonparametric distribution to partition the sequences into such segments, formulated in terms of a prior distribution on segment length. Given the segmentation, the model can be viewed as a variant of a Gaussian mixture model where the mixture components are described using the covariance function of a GP. We demonstrate the effectiveness of our model on synthetic data as well as on real time-series data of heartbeats where the task is to segment the indicative types of beats and to classify the heartbeat recordings into classes that correspond to healthy and abnormal heart sounds.
Letter-level Online Writer Identification
Dec 06, 2021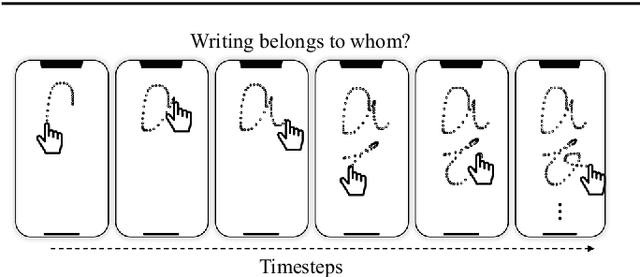
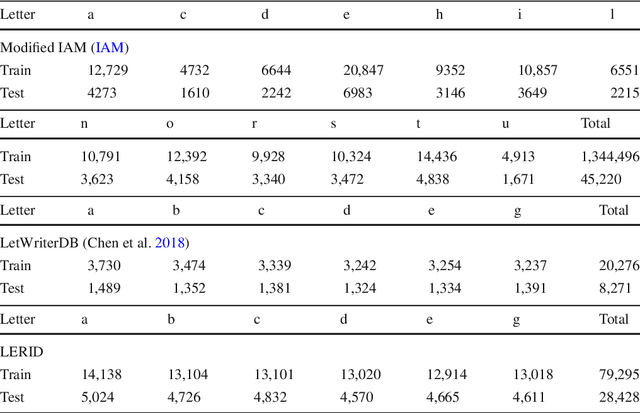
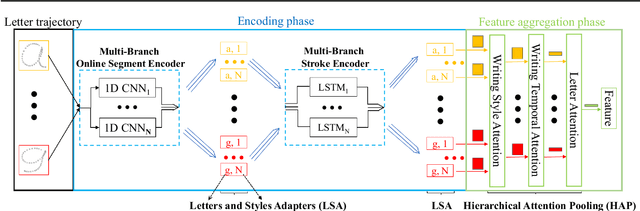

Writer identification (writer-id), an important field in biometrics, aims to identify a writer by their handwriting. Identification in existing writer-id studies requires a complete document or text, limiting the scalability and flexibility of writer-id in realistic applications. To make the application of writer-id more practical (e.g., on mobile devices), we focus on a novel problem, letter-level online writer-id, which requires only a few trajectories of written letters as identification cues. Unlike text-\ document-based writer-id which has rich context for identification, there are much fewer clues to recognize an author from only a few single letters. A main challenge is that a person often writes a letter in different styles from time to time. We refer to this problem as the variance of online writing styles (Var-O-Styles). We address the Var-O-Styles in a capture-normalize-aggregate fashion: Firstly, we extract different features of a letter trajectory by a carefully designed multi-branch encoder, in an attempt to capture different online writing styles. Then we convert all these style features to a reference style feature domain by a novel normalization layer. Finally, we aggregate the normalized features by a hierarchical attention pooling (HAP), which fuses all the input letters with multiple writing styles into a compact feature vector. In addition, we also contribute a large-scale LEtter-level online wRiter IDentification dataset (LERID) for evaluation. Extensive comparative experiments demonstrate the effectiveness of the proposed framework.
Optimal Estimation and Computational Limit of Low-rank Gaussian Mixtures
Jan 22, 2022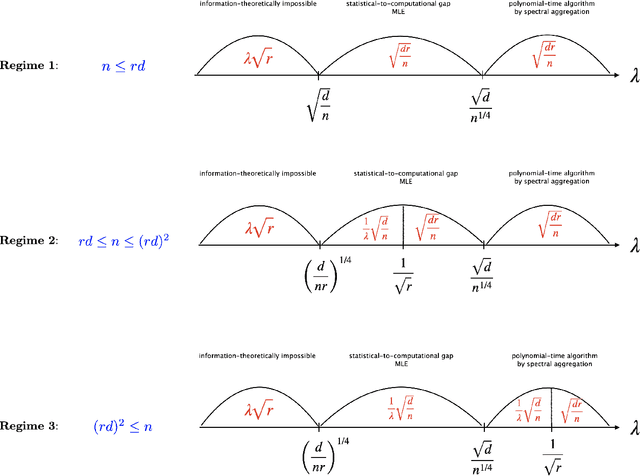
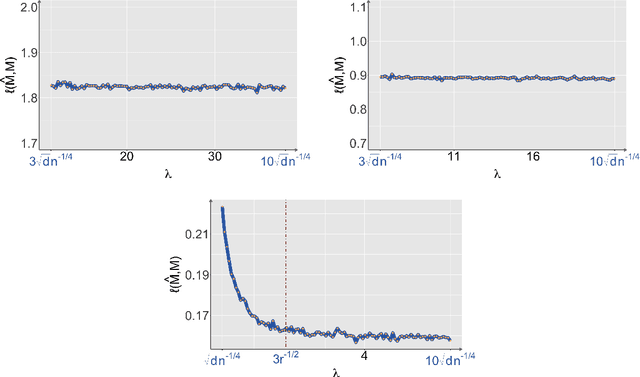
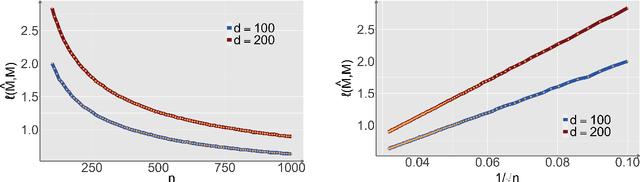
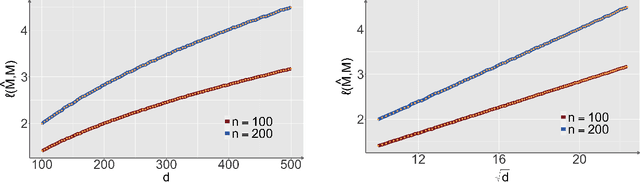
Structural matrix-variate observations routinely arise in diverse fields such as multi-layer network analysis and brain image clustering. While data of this type have been extensively investigated with fruitful outcomes being delivered, the fundamental questions like its statistical optimality and computational limit are largely under-explored. In this paper, we propose a low-rank Gaussian mixture model (LrMM) assuming each matrix-valued observation has a planted low-rank structure. Minimax lower bounds for estimating the underlying low-rank matrix are established allowing a whole range of sample sizes and signal strength. Under a minimal condition on signal strength, referred to as the information-theoretical limit or statistical limit, we prove the minimax optimality of a maximum likelihood estimator which, in general, is computationally infeasible. If the signal is stronger than a certain threshold, called the computational limit, we design a computationally fast estimator based on spectral aggregation and demonstrate its minimax optimality. Moreover, when the signal strength is smaller than the computational limit, we provide evidences based on the low-degree likelihood ratio framework to claim that no polynomial-time algorithm can consistently recover the underlying low-rank matrix. Our results reveal multiple phase transitions in the minimax error rates and the statistical-to-computational gap. Numerical experiments confirm our theoretical findings. We further showcase the merit of our spectral aggregation method on the worldwide food trading dataset.
MAC-ReconNet: A Multiple Acquisition Context based Convolutional Neural Network for MR Image Reconstruction using Dynamic Weight Prediction
Nov 09, 2021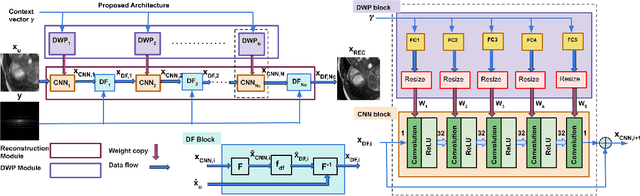

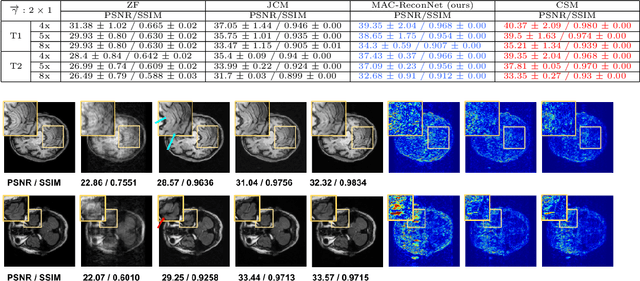
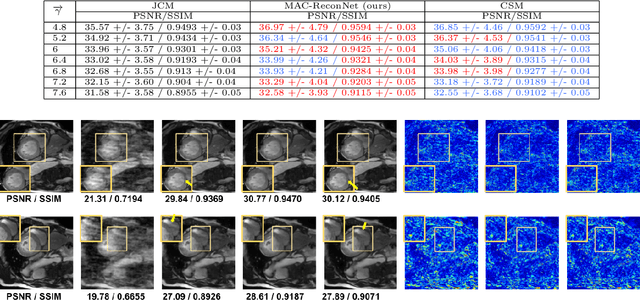
Convolutional Neural network-based MR reconstruction methods have shown to provide fast and high quality reconstructions. A primary drawback with a CNN-based model is that it lacks flexibility and can effectively operate only for a specific acquisition context limiting practical applicability. By acquisition context, we mean a specific combination of three input settings considered namely, the anatomy under study, undersampling mask pattern and acceleration factor for undersampling. The model could be trained jointly on images combining multiple contexts. However the model does not meet the performance of context specific models nor extensible to contexts unseen at train time. This necessitates a modification to the existing architecture in generating context specific weights so as to incorporate flexibility to multiple contexts. We propose a multiple acquisition context based network, called MAC-ReconNet for MRI reconstruction, flexible to multiple acquisition contexts and generalizable to unseen contexts for applicability in real scenarios. The proposed network has an MRI reconstruction module and a dynamic weight prediction (DWP) module. The DWP module takes the corresponding acquisition context information as input and learns the context-specific weights of the reconstruction module which changes dynamically with context at run time. We show that the proposed approach can handle multiple contexts based on cardiac and brain datasets, Gaussian and Cartesian undersampling patterns and five acceleration factors. The proposed network outperforms the naive jointly trained model and gives competitive results with the context-specific models both quantitatively and qualitatively. We also demonstrate the generalizability of our model by testing on contexts unseen at train time.
PARS: Pseudo-Label Aware Robust Sample Selection for Learning with Noisy Labels
Jan 26, 2022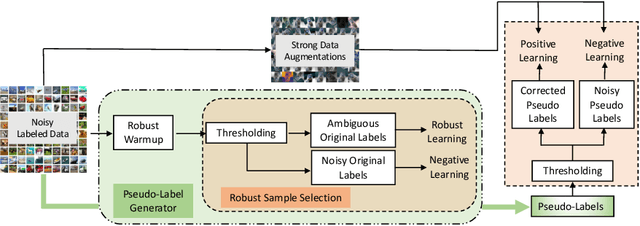
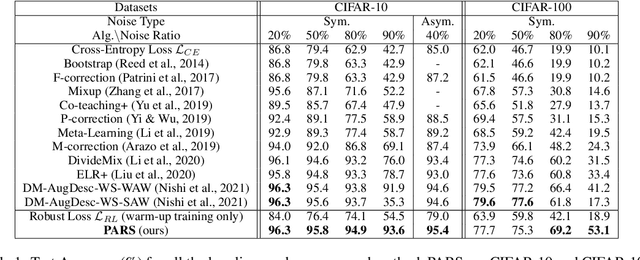

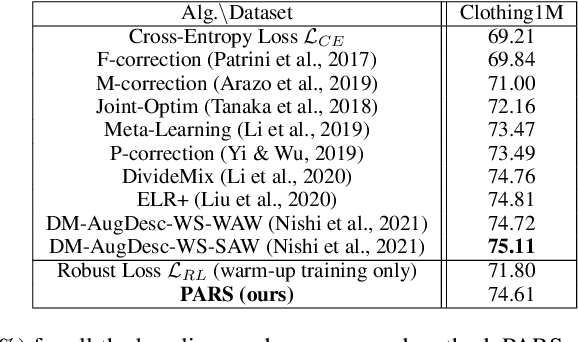
Acquiring accurate labels on large-scale datasets is both time consuming and expensive. To reduce the dependency of deep learning models on learning from clean labeled data, several recent research efforts are focused on learning with noisy labels. These methods typically fall into three design categories to learn a noise robust model: sample selection approaches, noise robust loss functions, or label correction methods. In this paper, we propose PARS: Pseudo-Label Aware Robust Sample Selection, a hybrid approach that combines the best from all three worlds in a joint-training framework to achieve robustness to noisy labels. Specifically, PARS exploits all training samples using both the raw/noisy labels and estimated/refurbished pseudo-labels via self-training, divides samples into an ambiguous and a noisy subset via loss analysis, and designs label-dependent noise-aware loss functions for both sets of filtered labels. Results show that PARS significantly outperforms the state of the art on extensive studies on the noisy CIFAR-10 and CIFAR-100 datasets, particularly on challenging high-noise and low-resource settings. In particular, PARS achieved an absolute 12% improvement in test accuracy on the CIFAR-100 dataset with 90% symmetric label noise, and an absolute 27% improvement in test accuracy when only 1/5 of the noisy labels are available during training as an additional restriction. On a real-world noisy dataset, Clothing1M, PARS achieves competitive results to the state of the art.
Machine Learning Assisted Approach for Security-Constrained Unit Commitment
Nov 17, 2021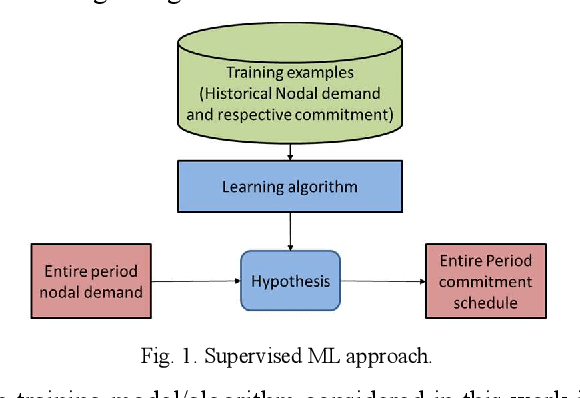
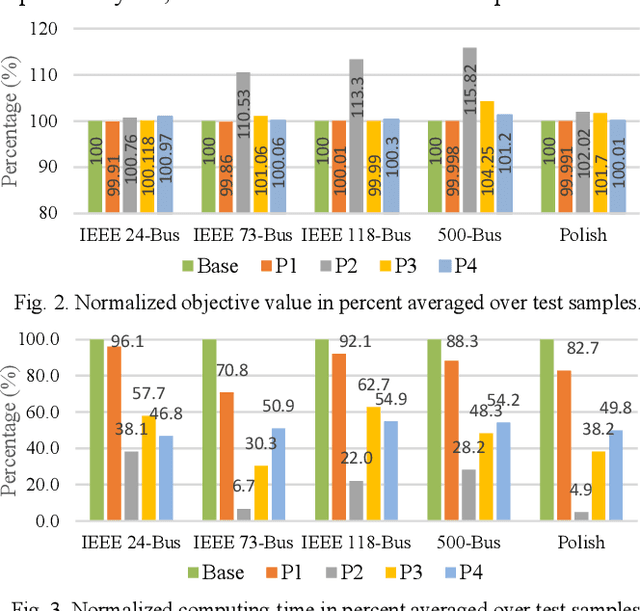
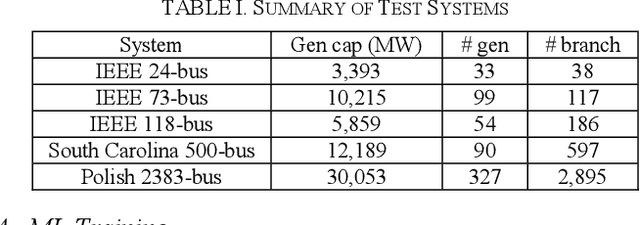
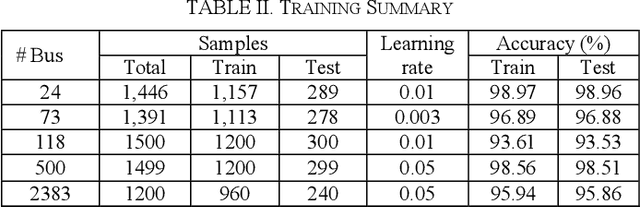
Security-constrained unit commitment (SCUC) which is used in the power system day-ahead generation scheduling is a mixed-integer linear programming problem that is computationally intensive. A good warm-start solution or a reduced-SCUC model can bring significant time savings. In this work, a novel approach is proposed to effectively utilize machine learning (ML) to provide a good starting solution and/or reduce the problem size of SCUC. An ML model using a logistic regression algorithm is proposed and trained using historical nodal demand profiles and the respective commitment schedules. The ML outputs are processed and analyzed to assist SCUC. The proposed approach is validated on several standard test systems namely, IEEE 24-bus system, IEEE 73-bus system, IEEE 118-bus system, synthetic South Carolina 500-bus system, and Polish 2383-bus system. Simulation results demonstrate that the prediction from the proposed machine learning model can provide a good warm-start solution and/or reduce the number of variables and constraints in SCUC with minimal loss in solution quality while substantially reducing the computing time.