 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid Sequential Recommender via Time-aware Attentive Memory Network
May 18, 2020
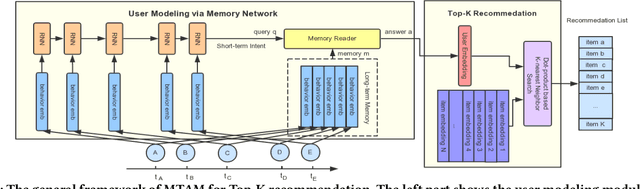
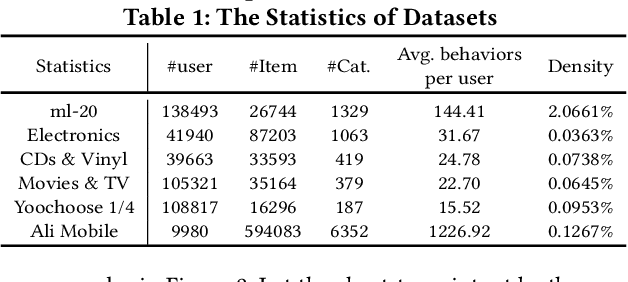
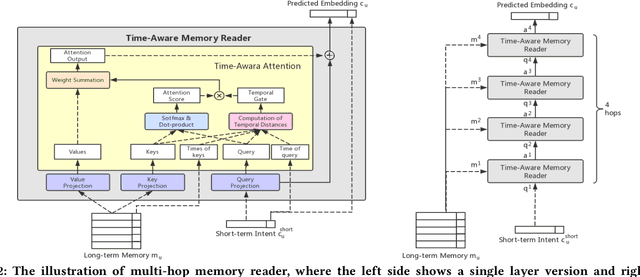
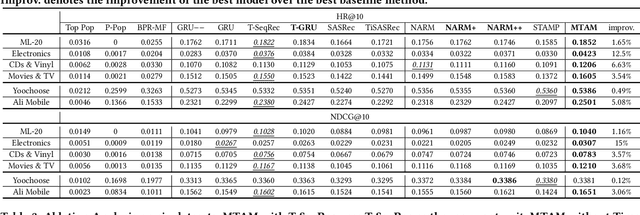
Recommendation systems aim to assist users to discover most preferred contents from an ever-growing corpus of items. Although recommenders have been greatly improved by deep learning, they still faces several challenges: (1) Behaviors are much more complex than words in sentences, so traditional attentive and recurrent models may fail in capturing the temporal dynamics of user preferences. (2) The preferences of users are multiple and evolving, so it is difficult to integrate long-term memory and short-term intent. In this paper, we propose a temporal gating methodology to improve attention mechanism and recurrent units, so that temporal information can be considered in both information filtering and state transition. Additionally, we propose a Multi-hop Time-aware Attentive Memory network (MTAM) to integrate long-term and short-term preferences. We use the proposed time-aware GRU network to learn the short-term intent and maintain prior records in user memory. We treat the short-term intent as a query and design a multi-hop memory reading operation via the proposed time-aware attention to generate user representation based on the current intent and long-term memory. Our approach is scalable for candidate retrieval tasks and can be viewed as a non-linear generalization of latent factorization for dot-product based Top-K recommendation. Finally, we conduct extensive experiments on six benchmark datasets and the experimental results demonstrate the effectiveness of our MTAM and temporal gating methodology.
Attention-based Proposals Refinement for 3D Object Detection
Jan 26, 2022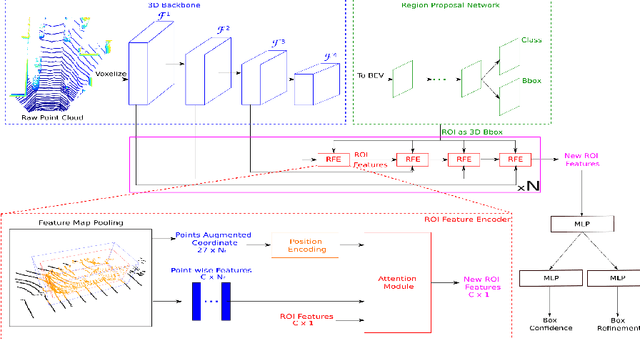
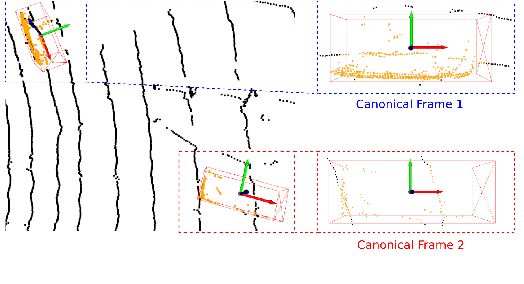
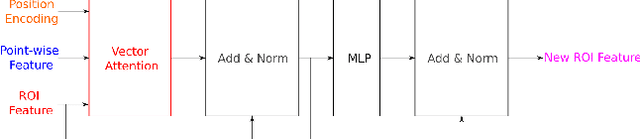
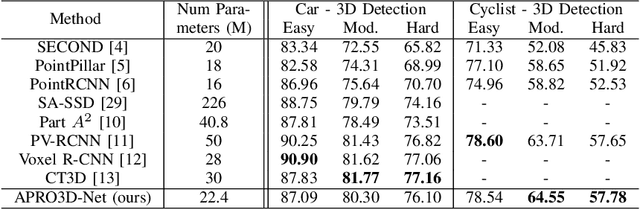
Recent advances in 3D object detection is made by developing the refinement stage for voxel-based Region Proposal Networks (RPN) to better strike the balance between accuracy and efficiency. A popular approach among state-of-the-art frameworks is to divide proposals, or Regions of Interest (ROI), into grids and extract feature for each grid location before synthesizing them to form ROI feature. While achieving impressive performances, such an approach involves a number of hand crafted components (e.g. grid sampling, set abstraction) which requires expert knowledge to be tuned correctly. This paper proposes a data-driven approach to ROI feature computing named APRO3D-Net which consists of a voxel-based RPN and a refinement stage made of Vector Attention. Unlike the original multi-head attention, Vector Attention assigns different weights to different channels within a point feature, thus being able to capture a more sophisticated relation between pooled points and ROI. Experiments on KITTI \textit{validation} set show that our method achieves competitive performance of 84.84 AP for class Car at Moderate difficulty while having the least parameters compared to closely related methods and attaining a quasi-real time inference speed at 15 FPS on NVIDIA V100 GPU. The code is released in https://github.com/quan-dao/APRO3D-Net.
Efficient learning of hidden state LTI state space models of unknown order
Feb 03, 2022The aim of this paper is to address two related estimation problems arising in the setup of hidden state linear time invariant (LTI) state space systems when the dimension of the hidden state is unknown. Namely, the estimation of any finite number of the system's Markov parameters and the estimation of a minimal realization for the system, both from the partial observation of a single trajectory. For both problems, we provide statistical guarantees in the form of various estimation error upper bounds, $\rank$ recovery conditions, and sample complexity estimates. Specifically, we first show that the low $\rank$ solution of the Hankel penalized least square estimator satisfies an estimation error in $S_p$-norms for $p \in [1,2]$ that captures the effect of the system order better than the existing operator norm upper bound for the simple least square. We then provide a stability analysis for an estimation procedure based on a variant of the Ho-Kalman algorithm that improves both the dependence on the dimension and the least singular value of the Hankel matrix of the Markov parameters. Finally, we propose an estimation algorithm for the minimal realization that uses both the Hankel penalized least square estimator and the Ho-Kalman based estimation procedure and guarantees with high probability that we recover the correct order of the system and satisfies a new fast rate in the $S_2$-norm with a polynomial reduction in the dependence on the dimension and other parameters of the problem.
Nash Convergence of Mean-Based Learning Algorithms in First Price Auctions
Oct 08, 2021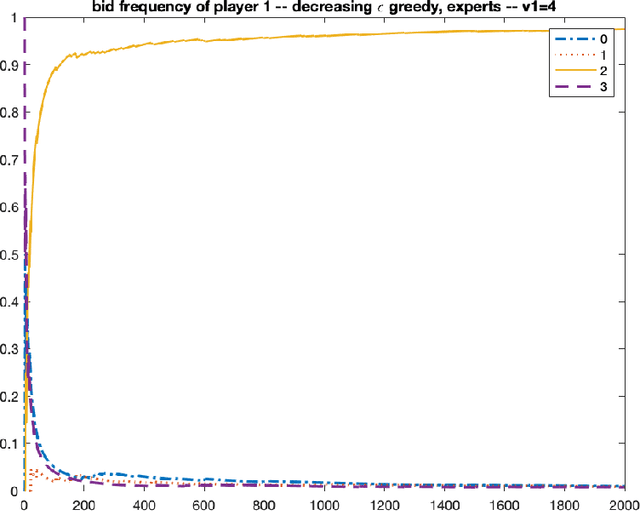
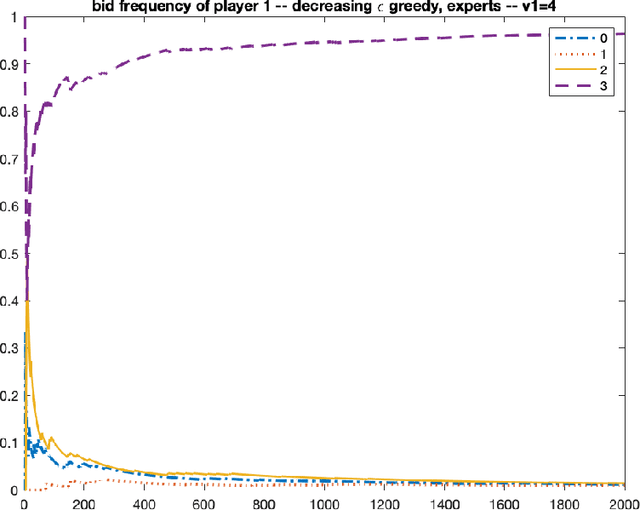
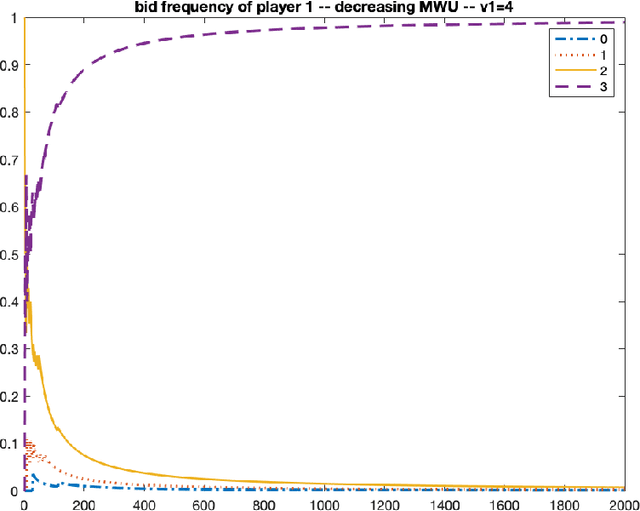
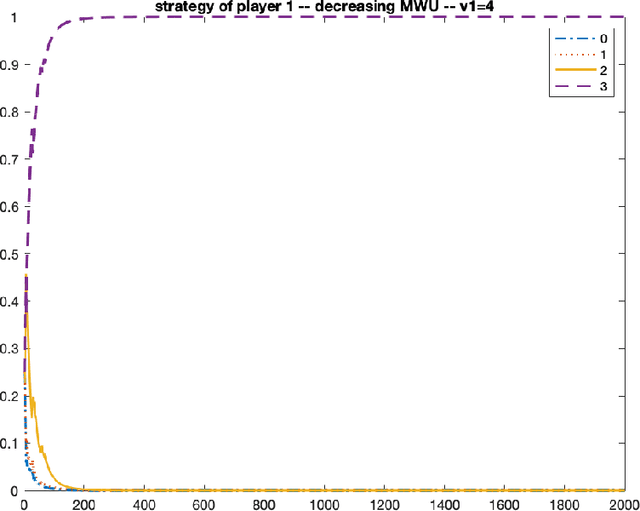
We consider repeated first price auctions where each bidder, having a deterministic type, learns to bid using a mean-based learning algorithm. We completely characterize the Nash convergence property of the bidding dynamics in two senses: (1) time-average: the fraction of rounds where bidders play a Nash equilibrium approaches to 1 in the limit; (2) last-iterate: the mixed strategy profile of bidders approaches to a Nash equilibrium in the limit. Specifically, the results depend on the number of bidders with the highest value: - If the number is at least three, the bidding dynamics almost surely converges to a Nash equilibrium of the auction, both in time-average and in last-iterate. - If the number is two, the bidding dynamics almost surely converges to a Nash equilibrium in time-average but not necessarily in last-iterate. - If the number is one, the bidding dynamics may not converge to a Nash equilibrium in time-average nor in last-iterate. Our discovery opens up new possibilities in the study of convergence dynamics of learning algorithms.
Adaptive Activation-based Structured Pruning
Jan 21, 2022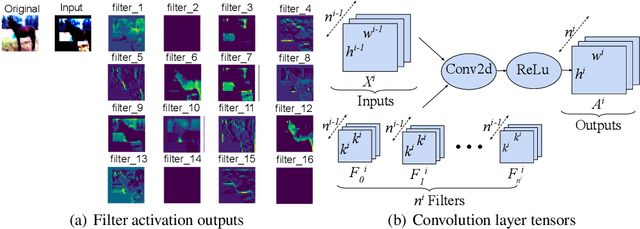
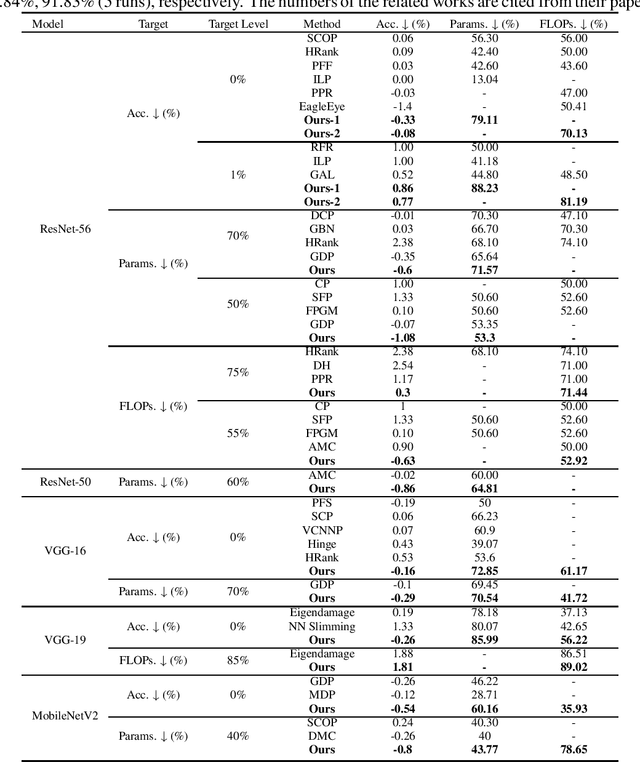
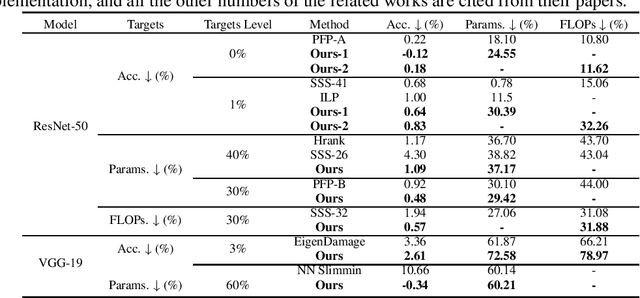
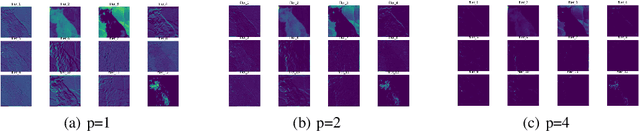
Pruning is a promising approach to compress complex deep learning models in order to deploy them on resource-constrained edge devices. However, many existing pruning solutions are based on unstructured pruning, which yield models that cannot efficiently run on commodity hardware, and require users to manually explore and tune the pruning process, which is time consuming and often leads to sub-optimal results. To address these limitations, this paper presents an adaptive, activation-based, structured pruning approach to automatically and efficiently generate small, accurate, and hardware-efficient models that meet user requirements. First, it proposes iterative structured pruning using activation-based attention feature maps to effectively identify and prune unimportant filters. Then, it proposes adaptive pruning policies for automatically meeting the pruning objectives of accuracy-critical, memory-constrained, and latency-sensitive tasks. A comprehensive evaluation shows that the proposed method can substantially outperform the state-of-the-art structured pruning works on CIFAR-10 and ImageNet datasets. For example, on ResNet-56 with CIFAR-10, without any accuracy drop, our method achieves the largest parameter reduction (79.11%), outperforming the related works by 22.81% to 66.07%, and the largest FLOPs reduction (70.13%), outperforming the related works by 14.13% to 26.53%.
Real Time Video based Heart and Respiration Rate Monitoring
Jun 04, 2021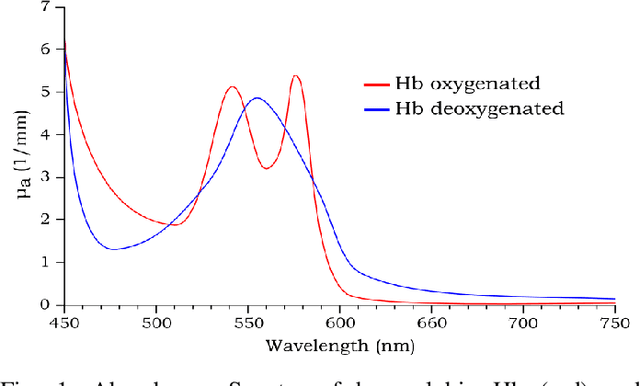


In recent years, research about monitoring vital signs by smartphones grows significantly. There are some special sensors like Electrocardiogram (ECG) and Photoplethysmographic (PPG) to detect heart rate (HR) and respiration rate (RR). Smartphone cameras also can measure HR by detecting and processing imaging Photoplethysmographic (iPPG) signals from the video of a user's face. Indeed, the variation in the intensity of the green channel can be measured by the iPPG signals of the video. This study aimed to provide a method to extract heart rate and respiration rate using the video of individuals' faces. The proposed method is based on measuring fluctuations in the Hue, and can therefore extract both HR and RR from the video of a user's face. The proposed method is evaluated by performing on 25 healthy individuals. For each subject, 20 seconds video of his/her face is recorded. Results show that the proposed approach of measuring iPPG using Hue gives more accurate rates than the Green channel.
Leveraging The Topological Consistencies of Learning in Deep Neural Networks
Nov 30, 2021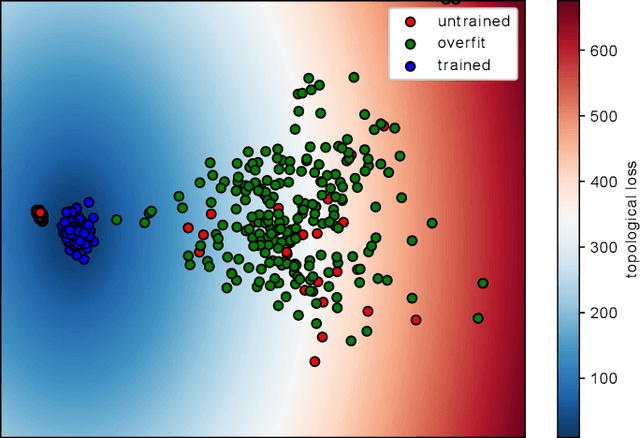

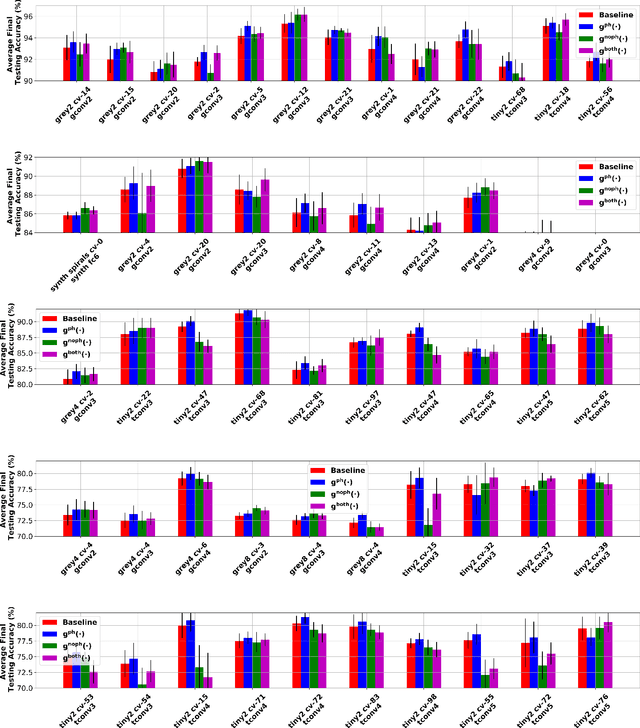
Recently, methods have been developed to accurately predict the testing performance of a Deep Neural Network (DNN) on a particular task, given statistics of its underlying topological structure. However, further leveraging this newly found insight for practical applications is intractable due to the high computational cost in terms of time and memory. In this work, we define a new class of topological features that accurately characterize the progress of learning while being quick to compute during running time. Additionally, our proposed topological features are readily equipped for backpropagation, meaning that they can be incorporated in end-to-end training. Our newly developed practical topological characterization of DNNs allows for an additional set of applications. We first show we can predict the performance of a DNN without a testing set and without the need for high-performance computing. We also demonstrate our topological characterization of DNNs is effective in estimating task similarity. Lastly, we show we can induce learning in DNNs by actively constraining the DNN's topological structure. This opens up new avenues in constricting the underlying structure of DNNs in a meta-learning framework.
Tight Concentrations and Confidence Sequences from the Regret of Universal Portfolio
Oct 27, 2021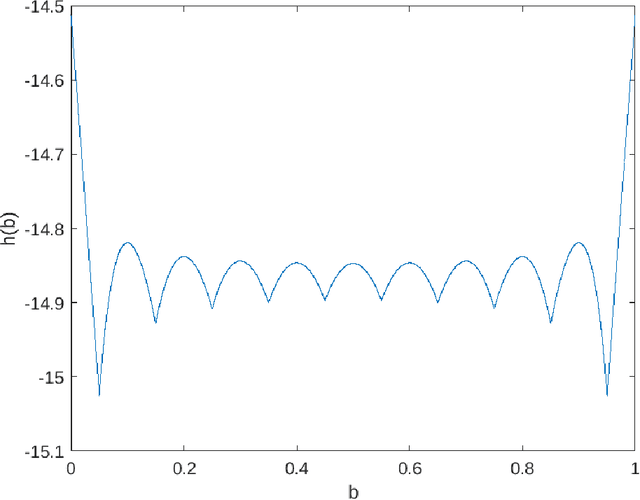
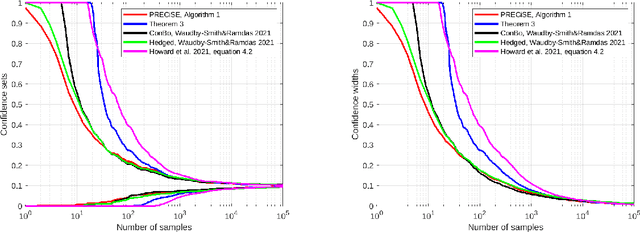
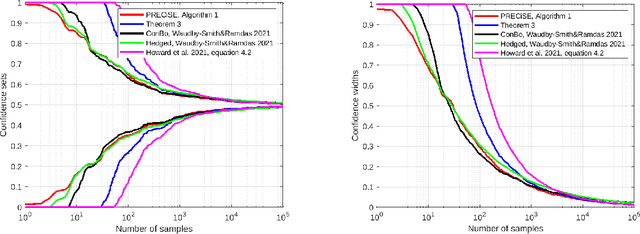
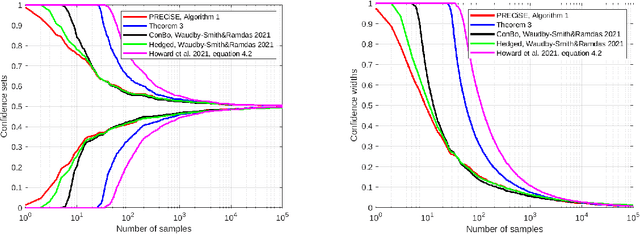
A classic problem in statistics is the estimation of the expectation of random variables from samples. This gives rise to the tightly connected problems of deriving concentration inequalities and confidence sequences, that is confidence intervals that hold uniformly over time. Jun and Orabona [COLT'19] have shown how to easily convert the regret guarantee of an online betting algorithm into a time-uniform concentration inequality. Here, we show that we can go even further: We show that the regret of a minimax betting algorithm gives rise to a new implicit empirical time-uniform concentration. In particular, we use a new data-dependent regret guarantee of the universal portfolio algorithm. We then show how to invert the new concentration in two different ways: in an exact way with a numerical algorithm and symbolically in an approximate way. Finally, we show empirically that our algorithms have state-of-the-art performance in terms of the width of the confidence sequences up to a moderately large amount of samples. In particular, our numerically obtained confidence sequences are never vacuous, even with a single sample.
Optimal Probing Sequences for Polarization-Multiplexed Coherent Phase OTDR
Nov 11, 2021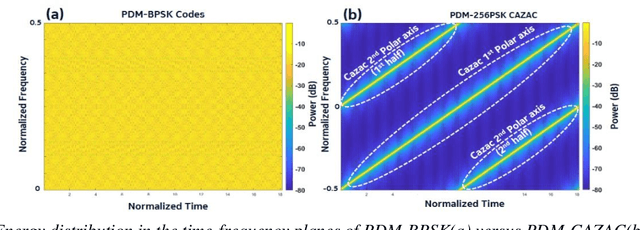
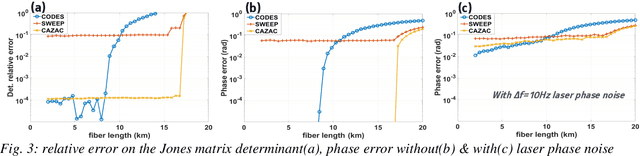
We introduce dual-polarization probing codes based on two circularly shifted frequency sweep signals enabling perfect channel estimation. This is achieved with a probing length equal to at least twice the fiber round-trip propagation time.
Optimizing Memory in Reservoir Computers
Jan 05, 2022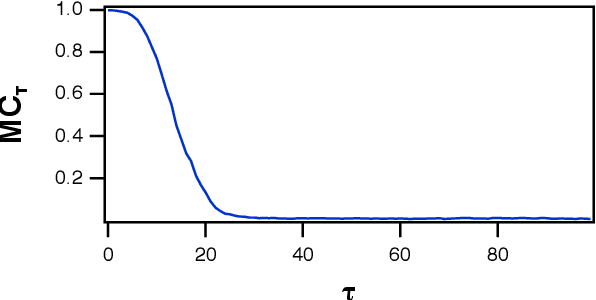
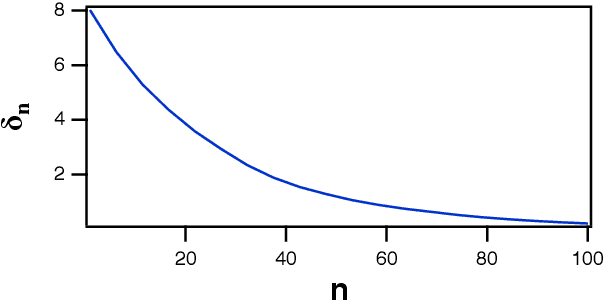
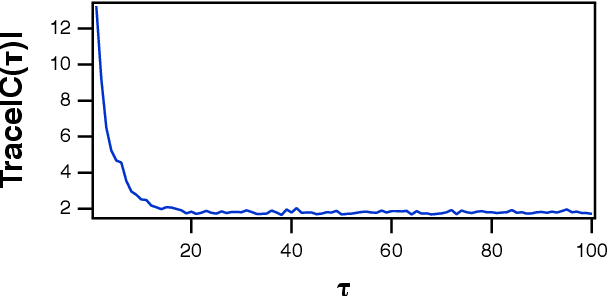
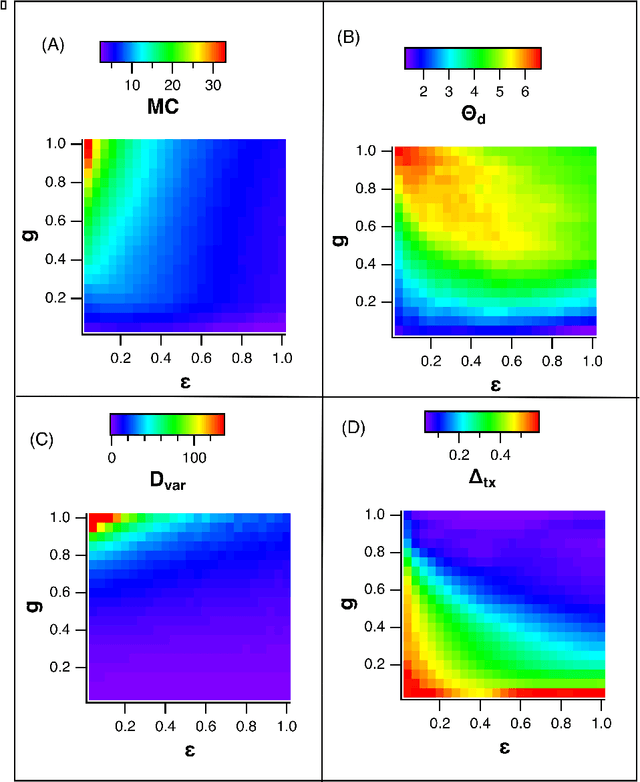
A reservoir computer is a way of using a high dimensional dynamical system for computation. One way to construct a reservoir computer is by connecting a set of nonlinear nodes into a network. Because the network creates feedback between nodes, the reservoir computer has memory. If the reservoir computer is to respond to an input signal in a consistent way (a necessary condition for computation), the memory must be fading; that is, the influence of the initial conditions fades over time. How long this memory lasts is important for determining how well the reservoir computer can solve a particular problem. In this paper I describe ways to vary the length of the fading memory in reservoir computers. Tuning the memory can be important to achieve optimal results in some problems; too much or too little memory degrades the accuracy of the computation.