 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Broadband Radar Invisibility with Time-Dependent Metasurfaces
Apr 20, 2021

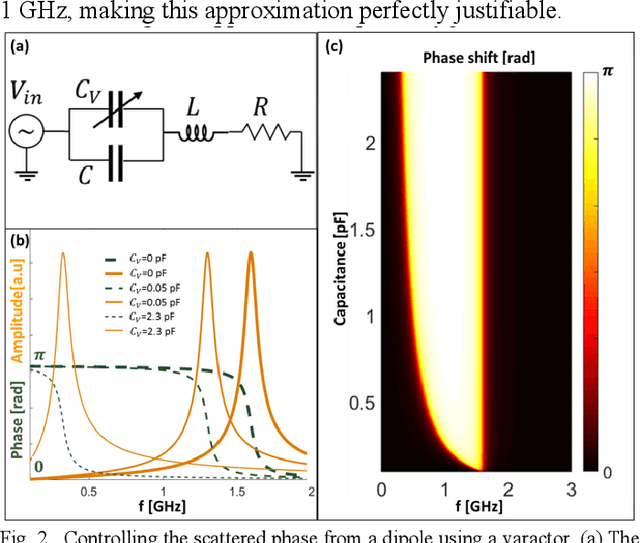
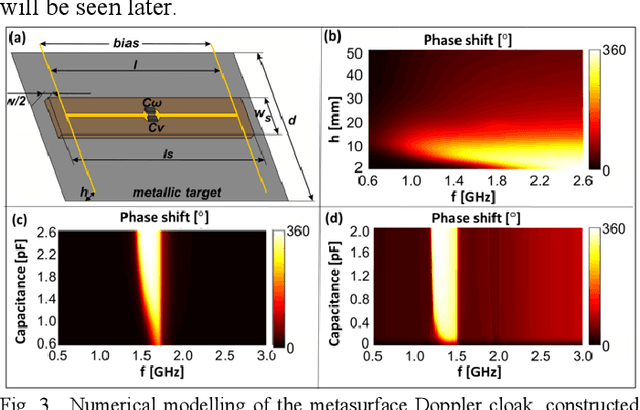

Concealing objects from interrogation has been a primary objective since the integration of radars into surveillance systems. Metamaterial-based invisibility cloaking, which was considered a promising solution, did not yet succeed in delivering reliable performance against real radar systems, mainly due to its narrow operational bandwidth. Here we propose an approach, which addresses the issue from a signal-processing standpoint and, as a result, is capable of coping with the vast majority of unclassified radar systems by exploiting vulnerabilities in their design. In particular, we demonstrate complete concealment of a 0.25 square meter moving metal plate from an investigating radar system, operating in a broad frequency range approaching 20% bandwidth around the carrier of 1.5GHz. The key element of the radar countermeasure is a temporally modulated coating. This auxiliary structure is designed to dynamically and controllably adjust the reflected phase of the impinging radar signal, which acquires a user-defined Doppler shift. A special case of interest is imposing a frequency shift that compensates for the real Doppler signatures originating from the motion of the target. In this case the radar will consider the target static, even though it is moving. As a result, the reflected echo will be discarded by the clutter removal filter, which is an inherent part of any modern radar system that is designed to operate in real conditions. This signal-processing loophole allows rendering the target invisible to the radar even though it scatters electromagnetic radiation. This application claims the benefit of patent number 273995, filed on April 16 2020.
Generation of Synthetic Rat Brain MRI scans with a 3D Enhanced Alpha-GAN
Dec 27, 2021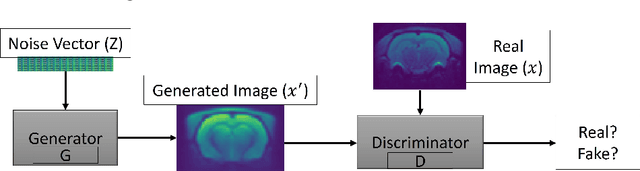
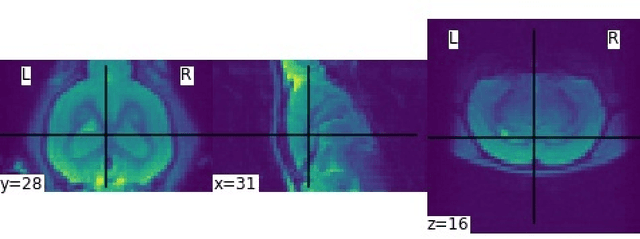
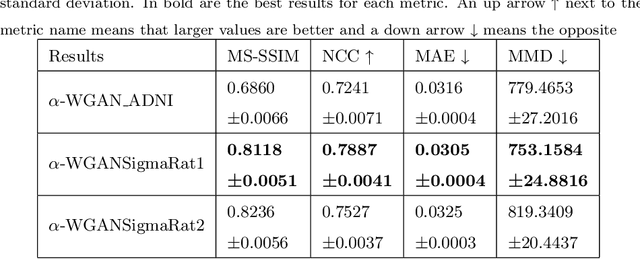
Translational brain research using Magnetic Resonance Imaging (MRI) is becoming increasingly popular as animal models are an essential part of scientific studies and ultra-high-field scanners become more available. Some drawbacks of MRI are MRI scanner availability, and the time needed to perform a full scanning session (it usually takes over 30 minutes). Data protection laws and 3R ethical rule also make it difficult to create large data sets for training Deep Learning models. Generative Adversarial Networks (GAN) have been shown capable of performing data augmentation with higher quality than other techniques. In this work, the alpha-GAN architecture is used to test its ability to generate realistic 3D MRI scans of the rat brain. As far as the authors are aware, this is the first time an approach based on GANs is used for data augmentation in preclinical data. The generated scans are evaluated using various qualitative and quantitative metrics. A Turing test performed by 4 experts has shown that the generated scans can trick almost any expert. The generated scans were also used to evaluate their impact on the performance of an existing deep learning model developed for rat brain segmentation of white matter, grey matter, and cerebrospinal fluid. The models were compared using the Dice score. The best results for the segmentation of whole brain and white matter were achieved when 174 real scans and 348 synthetic ones were used, with improvements of 0.0172 and 0.0129. The use of 174 real scans and 87 synthetic ones led to improvements of 0.0038 and 0.0764 of grey matter and cerebrospinal fluid segmentation. Thus, by using the proposed new normalisation layer and loss functions, it was possible to improve the realism of the generated rat MRI scans and it was demonstrated that using the data generated improved the segmentation model more than using conventional data augmentation.
Fourier Representations for Black-Box Optimization over Categorical Variables
Feb 08, 2022
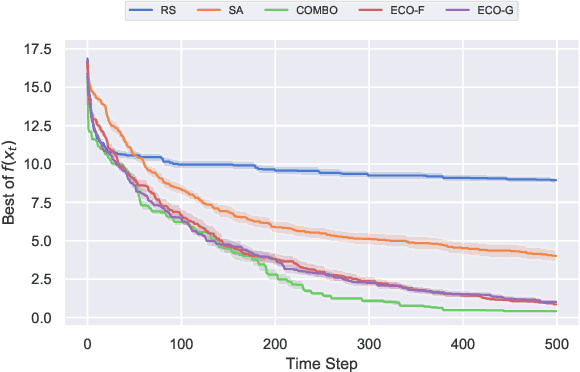
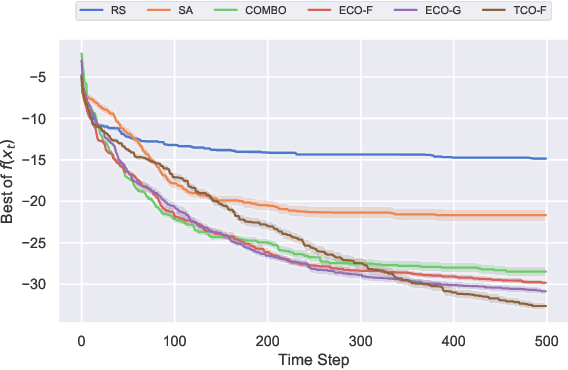
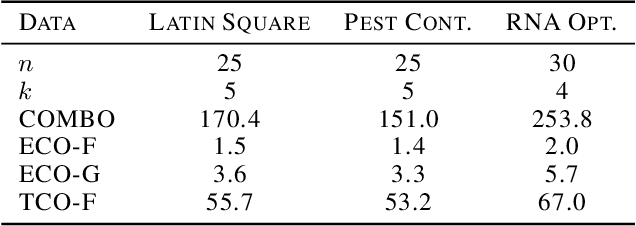
Optimization of real-world black-box functions defined over purely categorical variables is an active area of research. In particular, optimization and design of biological sequences with specific functional or structural properties have a profound impact in medicine, materials science, and biotechnology. Standalone search algorithms, such as simulated annealing (SA) and Monte Carlo tree search (MCTS), are typically used for such optimization problems. In order to improve the performance and sample efficiency of such algorithms, we propose to use existing methods in conjunction with a surrogate model for the black-box evaluations over purely categorical variables. To this end, we present two different representations, a group-theoretic Fourier expansion and an abridged one-hot encoded Boolean Fourier expansion. To learn such representations, we consider two different settings to update our surrogate model. First, we utilize an adversarial online regression setting where Fourier characters of each representation are considered as experts and their respective coefficients are updated via an exponential weight update rule each time the black box is evaluated. Second, we consider a Bayesian setting where queries are selected via Thompson sampling and the posterior is updated via a sparse Bayesian regression model (over our proposed representation) with a regularized horseshoe prior. Numerical experiments over synthetic benchmarks as well as real-world RNA sequence optimization and design problems demonstrate the representational power of the proposed methods, which achieve competitive or superior performance compared to state-of-the-art counterparts, while improving the computation cost and/or sample efficiency, substantially.
Category-Association Based Similarity Matching for Novel Object Pick-and-Place Task
Jan 27, 2022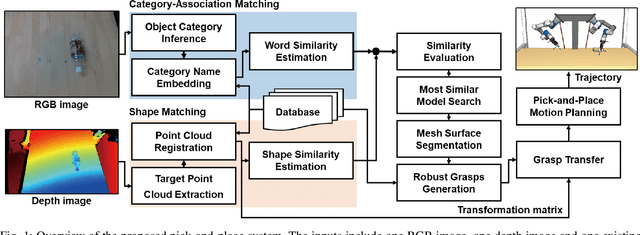
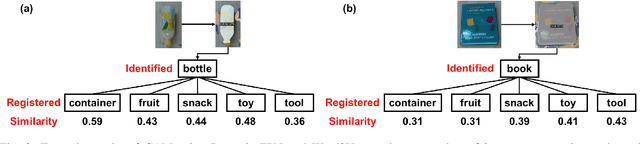
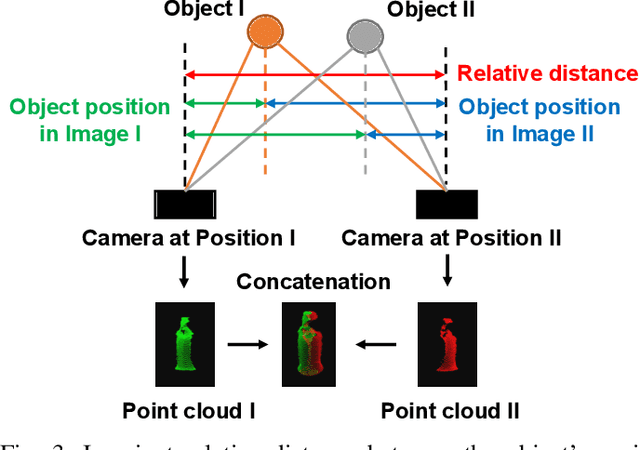
Robotic pick-and-place has been researched for a long time to cope with uncertainty of novel objects and changeable environments. Past works mainly focus on learning-based methods to achieve high precision. However, they have difficulty being generalized for the limitation of specified training models. To break through this drawback of learning-based approaches, we introduce a new perspective of similarity matching between novel objects and a known database based on category-association to achieve pick-and-place tasks with high accuracy and stabilization. We calculate the category name similarity using word embedding to quantify the semantic similarity between the categories of known models and the target real-world objects. With a similar model identified by a similarity prediction function, we preplan a series of robust grasps and imitate them to plan new grasps on the real-world target object. We also propose a distance-based method to infer the in-hand posture of objects and adjust small rotations to achieve stable placements under uncertainty. Through a real-world robotic pick-and-place experiment with a dozen of in-category and out-of-category novel objects, our method achieved an average success rate of 90.6% and 75.9% respectively, validating the capacity of generalization to diverse objects.
Quality Metric Guided Portrait Line Drawing Generation from Unpaired Training Data
Feb 08, 2022
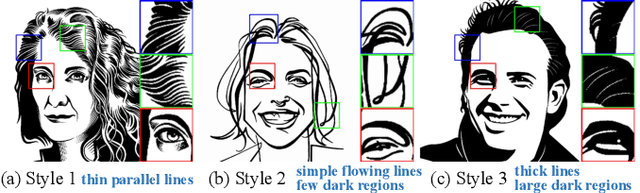
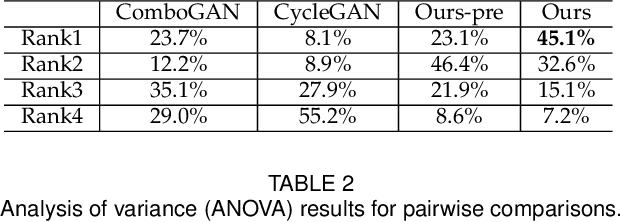

Face portrait line drawing is a unique style of art which is highly abstract and expressive. However, due to its high semantic constraints, many existing methods learn to generate portrait drawings using paired training data, which is costly and time-consuming to obtain. In this paper, we propose a novel method to automatically transform face photos to portrait drawings using unpaired training data with two new features; i.e., our method can (1) learn to generate high quality portrait drawings in multiple styles using a single network and (2) generate portrait drawings in a "new style" unseen in the training data. To achieve these benefits, we (1) propose a novel quality metric for portrait drawings which is learned from human perception, and (2) introduce a quality loss to guide the network toward generating better looking portrait drawings. We observe that existing unpaired translation methods such as CycleGAN tend to embed invisible reconstruction information indiscriminately in the whole drawings due to significant information imbalance between the photo and portrait drawing domains, which leads to important facial features missing. To address this problem, we propose a novel asymmetric cycle mapping that enforces the reconstruction information to be visible and only embedded in the selected facial regions. Along with localized discriminators for important facial regions, our method well preserves all important facial features in the generated drawings. Generator dissection further explains that our model learns to incorporate face semantic information during drawing generation. Extensive experiments including a user study show that our model outperforms state-of-the-art methods.
Efficient Device Scheduling with Multi-Job Federated Learning
Dec 11, 2021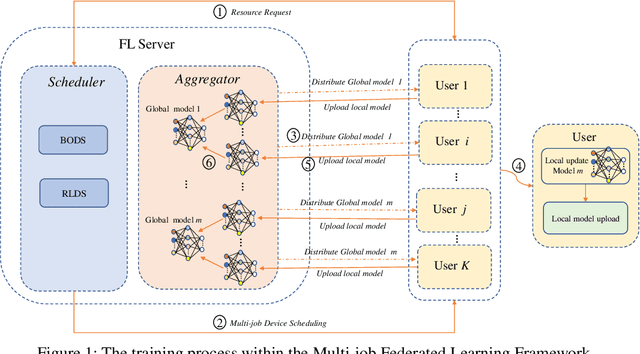
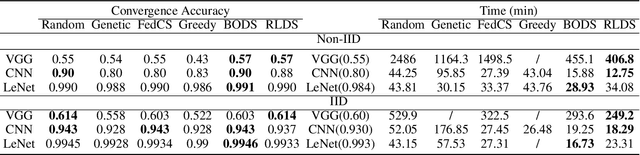
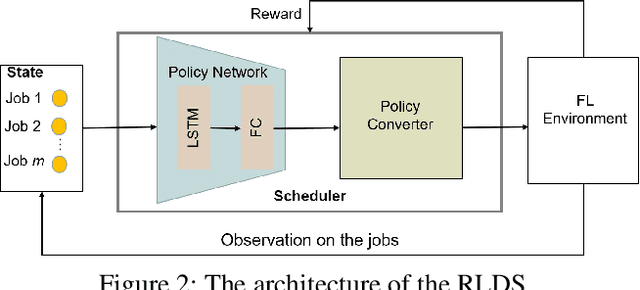
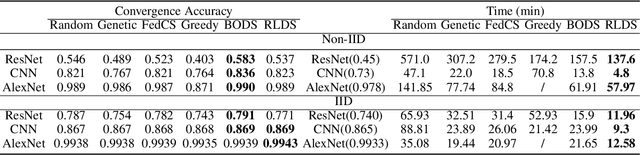
Recent years have witnessed a large amount of decentralized data in multiple (edge) devices of end-users, while the aggregation of the decentralized data remains difficult for machine learning jobs due to laws or regulations. Federated Learning (FL) emerges as an effective approach to handling decentralized data without sharing the sensitive raw data, while collaboratively training global machine learning models. The servers in FL need to select (and schedule) devices during the training process. However, the scheduling of devices for multiple jobs with FL remains a critical and open problem. In this paper, we propose a novel multi-job FL framework to enable the parallel training process of multiple jobs. The framework consists of a system model and two scheduling methods. In the system model, we propose a parallel training process of multiple jobs, and construct a cost model based on the training time and the data fairness of various devices during the training process of diverse jobs. We propose a reinforcement learning-based method and a Bayesian optimization-based method to schedule devices for multiple jobs while minimizing the cost. We conduct extensive experimentation with multiple jobs and datasets. The experimental results show that our proposed approaches significantly outperform baseline approaches in terms of training time (up to 8.67 times faster) and accuracy (up to 44.6% higher).
Head and eye egocentric gesture recognition for human-robot interaction using eyewear cameras
Jan 27, 2022
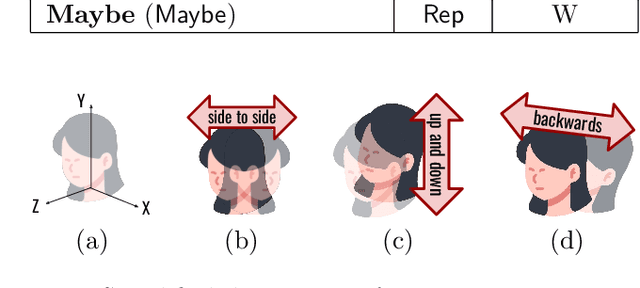
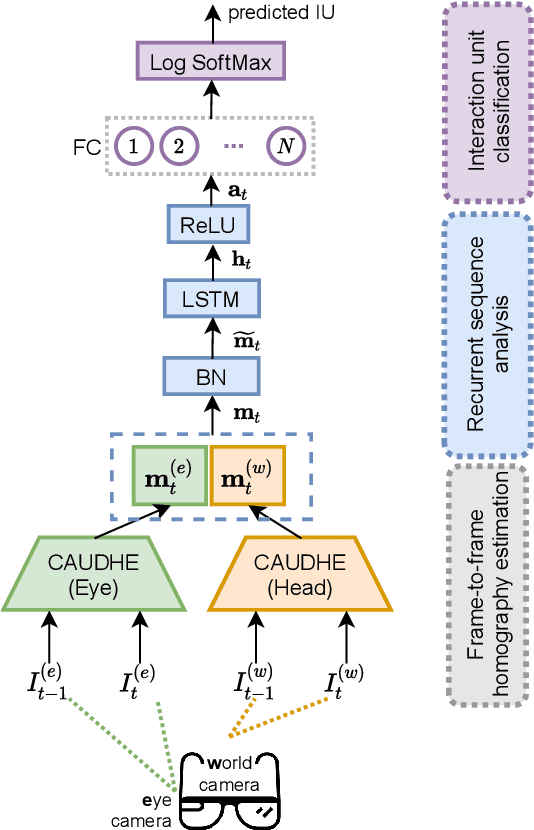
Non-verbal communication plays a particularly important role in a wide range of scenarios in Human-Robot Interaction (HRI). Accordingly, this work addresses the problem of human gesture recognition. In particular, we focus on head and eye gestures, and adopt an egocentric (first-person) perspective using eyewear cameras. We argue that this egocentric view offers a number of conceptual and technical benefits over scene- or robot-centric perspectives. A motion-based recognition approach is proposed, which operates at two temporal granularities. Locally, frame-to-frame homographies are estimated with a convolutional neural network (CNN). The output of this CNN is input to a long short-term memory (LSTM) to capture longer-term temporal visual relationships, which are relevant to characterize gestures. Regarding the configuration of the network architecture, one particularly interesting finding is that using the output of an internal layer of the homography CNN increases the recognition rate with respect to using the homography matrix itself. While this work focuses on action recognition, and no robot or user study has been conducted yet, the system has been de signed to meet real-time constraints. The encouraging results suggest that the proposed egocentric perspective is viable, and this proof-of-concept work provides novel and useful contributions to the exciting area of HRI.
Enhancing operations management through smart sensors: measuring and improving well-being, interaction and performance of logistics workers
Dec 15, 2021
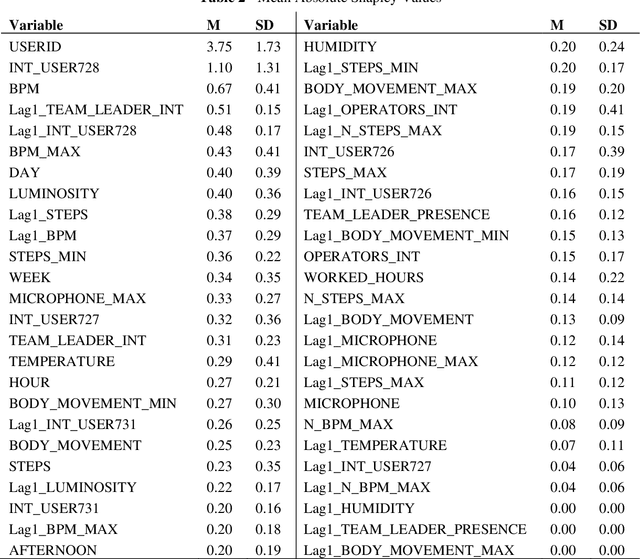
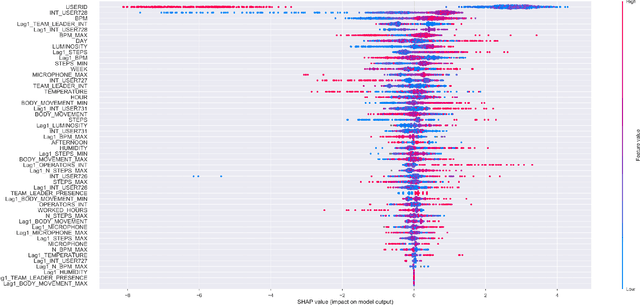
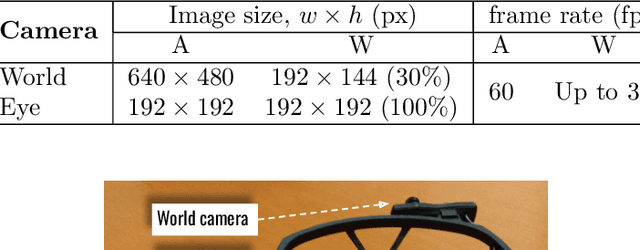
Purpose The purpose of the research is to conduct an exploratory investigation of the material handling activities of an Italian logistics hub. Wearable sensors and other smart tools were used for collecting human and environmental features during working activities. These factors were correlated with workers' performance and well-being. Design/methodology/approach Human and environmental factors play an important role in operations management activities since they significantly influence employees' performance, well-being and safety. Surprisingly, empirical studies about the impact of such aspects on logistics operations are still very limited. Trying to fill this gap, the research empirically explores human and environmental factors affecting the performance of logistics workers exploiting smart tools. Findings Results suggest that human attitudes, interactions, emotions and environmental conditions remarkably influence workers' performance and well-being, however, showing different relationships depending on individual characteristics of each worker. Practical implications The authors' research opens up new avenues for profiling employees and adopting an individualized human resource management, providing managers with an operational system capable to potentially check and improve workers' well-being and performance. Originality/value The originality of the study comes from the in-depth exploration of human and environmental factors using body-worn sensors during work activities, by recording individual, collaborative and environmental data in real-time. To the best of the authors' knowledge, the current paper is the first time that such a detailed analysis has been carried out in real-world logistics operations.
* in press
Vehicle and License Plate Recognition with Novel Dataset for Toll Collection
Feb 11, 2022

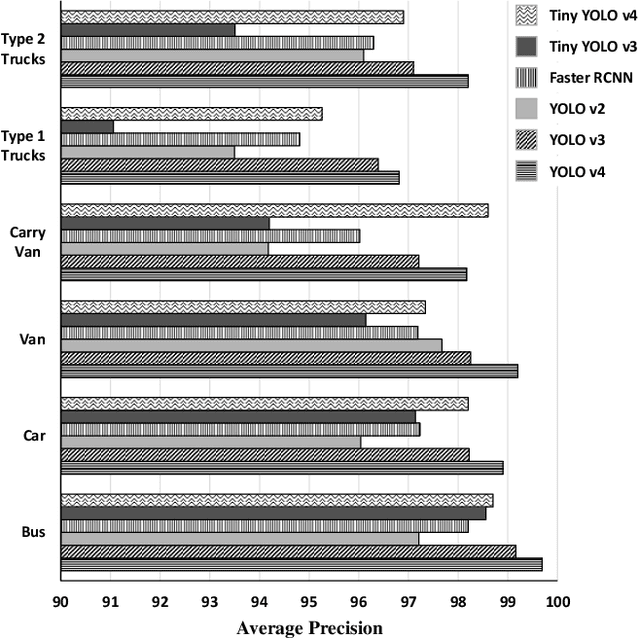

We propose an automatic framework for toll collection, consisting of three steps: vehicle type recognition, license plate localization, and reading. However, each of the three steps becomes non-trivial due to image variations caused by several factors. The traditional vehicle decorations on the front cause variations among vehicles of the same type. These decorations make license plate localization and recognition difficult due to severe background clutter and partial occlusions. Likewise, on most vehicles, specifically trucks, the position of the license plate is not consistent. Lastly, for license plate reading, the variations are induced by non-uniform font styles, sizes, and partially occluded letters and numbers. Our proposed framework takes advantage of both data availability and performance evaluation of the backbone deep learning architectures. We gather a novel dataset, \emph{Diverse Vehicle and License Plates Dataset (DVLPD)}, consisting of 10k images belonging to six vehicle types. Each image is then manually annotated for vehicle type, license plate, and its characters and digits. For each of the three tasks, we evaluate You Only Look Once (YOLO)v2, YOLOv3, YOLOv4, and FasterRCNN. For real-time implementation on a Raspberry Pi, we evaluate the lighter versions of YOLO named Tiny YOLOv3 and Tiny YOLOv4. The best Mean Average Precision (mAP@0.5) of 98.8% for vehicle type recognition, 98.5% for license plate detection, and 98.3% for license plate reading is achieved by YOLOv4, while its lighter version, i.e., Tiny YOLOv4 obtained a mAP of 97.1%, 97.4%, and 93.7% on vehicle type recognition, license plate detection, and license plate reading, respectively. The dataset and the training codes are available at https://github.com/usama-x930/VT-LPR
Online Action Detection in Streaming Videos with Time Buffers
Oct 06, 2020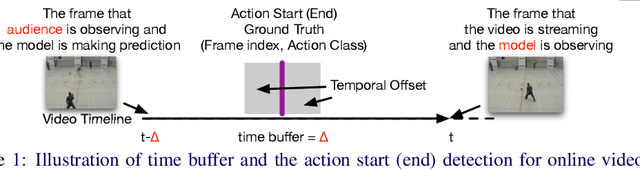
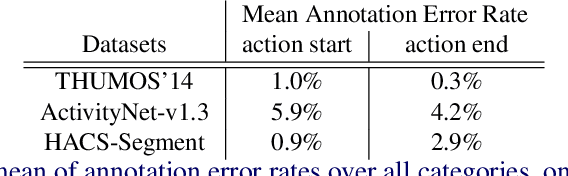

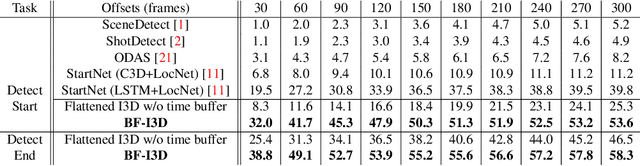
We formulate the problem of online temporal action detection in live streaming videos, acknowledging one important property of live streaming videos that there is normally a broadcast delay between the latest captured frame and the actual frame viewed by the audience. The standard setting of the online action detection task requires immediate prediction after a new frame is captured. We illustrate that its lack of consideration of the delay is imposing unnecessary constraints on the models and thus not suitable for this problem. We propose to adopt the problem setting that allows models to make use of the small `buffer time' incurred by the delay in live streaming videos. We design an action start and end detection framework for this online with buffer setting with two major components: flattened I3D and window-based suppression. Experiments on three standard temporal action detection benchmarks under the proposed setting demonstrate the effectiveness of the proposed framework. We show that by having a suitable problem setting for this problem with wide-applications, we can achieve much better detection accuracy than off-the-shelf online action detection models.