 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Linear-Time Variational Integrators in Maximal Coordinates
Feb 26, 2020
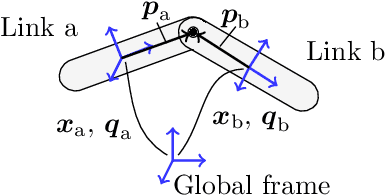
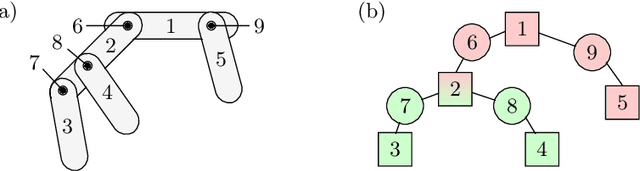
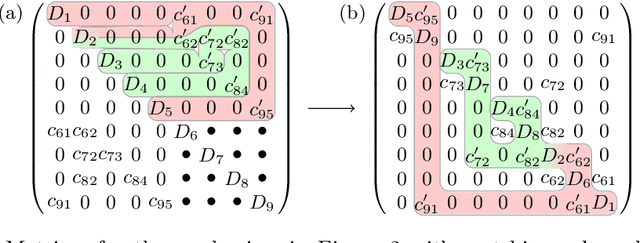
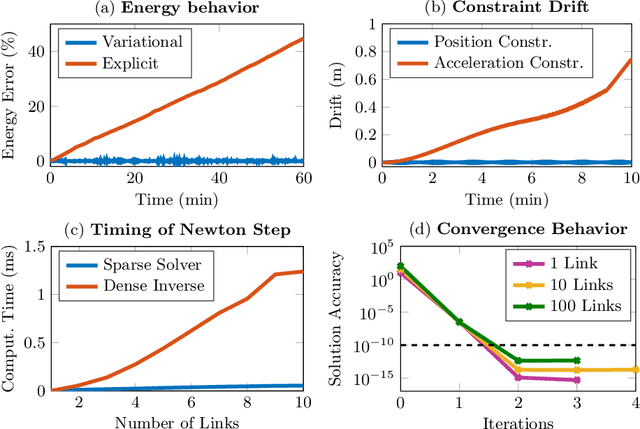
Most dynamic simulation tools parameterize the configuration of multi-body robotic systems using minimal coordinates, also called generalized or joint coordinates. However, maximal-coordinate approaches have several advantages over minimal-coordinate parameterizations, including native handling of closed kinematic loops and nonholonomic constraints. This paper describes a linear-time variational integrator that is formulated in maximal coordinates. Due to its variational formulation, the algorithm does not suffer from constraint drift and has favorable energy and momentum conservation properties. A sparse matrix factorization technique allows the dynamics of a loop-free articulated mechanism with $n$ links to be computed in $O(n)$ (linear) time. Additional constraints that introduce loops can also be handled by the algorithm without incurring much computational overhead. Experimental results show that our approach offers speed competitive with state-of-the-art minimal-coordinate algorithms while outperforming them in several scenarios, especially when dealing with closed loops and configuration singularities.
Real-Time Video Inference on Edge Devices via Adaptive Model Streaming
Jun 11, 2020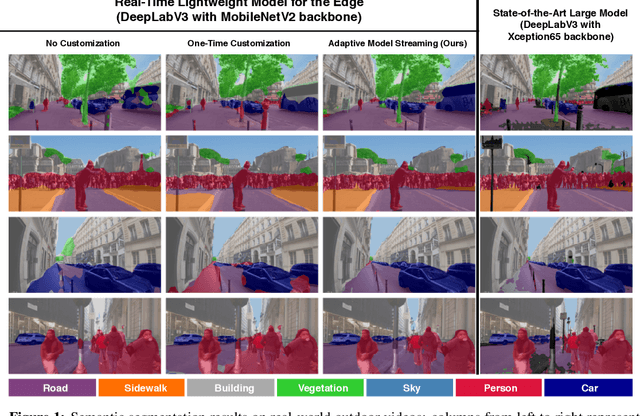

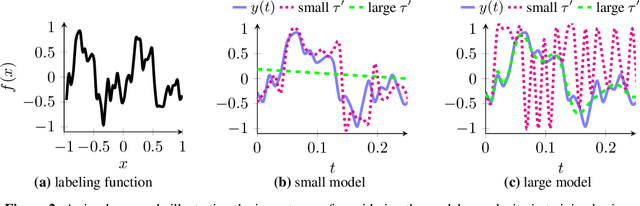
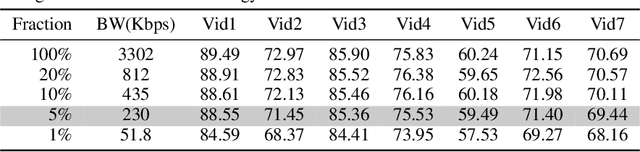
Real-time video inference on compute-limited edge devices like mobile phones and drones is challenging due to the high computation cost of Deep Neural Network models. In this paper we propose Adaptive Model Streaming (AMS), a cloud-assisted approach to real-time video inference on edge devices. The key idea in AMS is to use online learning to continually adapt a lightweight model running on an edge device to boost its performance on the video scenes in real-time. The model is trained in a cloud server and is periodically sent to the edge device. We discuss the challenges of online learning for video and present a practical design that takes into account the edge device, cloud server, and network bandwidth resource limitations. On the task of video semantic segmentation, our experimental results show 5.1--17.0 percent mean Intersection-over-Union improvement compared to a pre-trained model on several real-world videos. Our prototype can perform video segmentation at 30 frames-per-second with 40 milliseconds camera-to-label latency on a Samsung Galaxy S10+ mobile phone, using less than 400Kbps uplink and downlink bandwidth on the device.
TTDM: A Travel Time Difference Model for Next Location Prediction
Mar 16, 2020
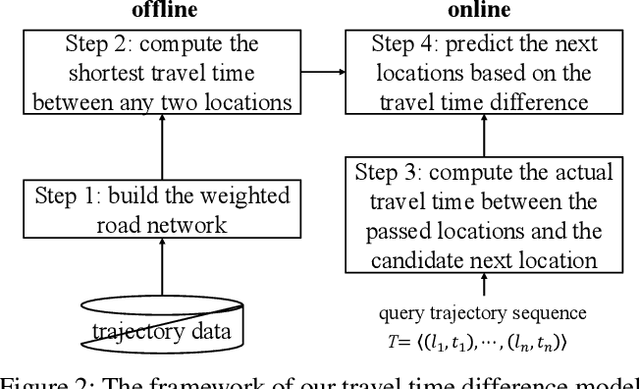
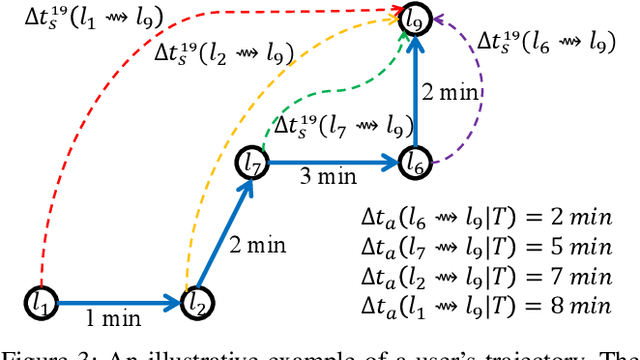
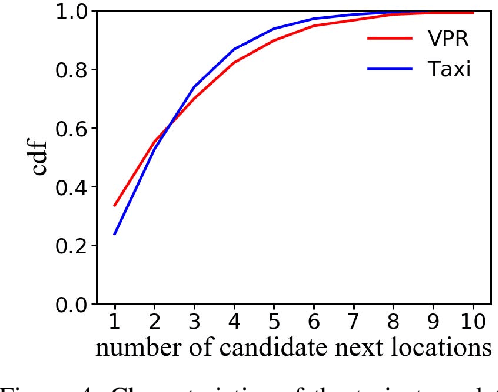
Next location prediction is of great importance for many location-based applications and provides essential intelligence to business and governments. In existing studies, a common approach to next location prediction is to learn the sequential transitions with massive historical trajectories based on conditional probability. Unfortunately, due to the time and space complexity, these methods (e.g., Markov models) only use the just passed locations to predict next locations, without considering all the passed locations in the trajectory. In this paper, we seek to enhance the prediction performance by considering the travel time from all the passed locations in the query trajectory to a candidate next location. In particular, we propose a novel method, called Travel Time Difference Model (TTDM), which exploits the difference between the shortest travel time and the actual travel time to predict next locations. Further, we integrate the TTDM with a Markov model via a linear interpolation to yield a joint model, which computes the probability of reaching each possible next location and returns the top-rankings as results. We have conducted extensive experiments on two real datasets: the vehicle passage record (VPR) data and the taxi trajectory data. The experimental results demonstrate significant improvements in prediction accuracy over existing solutions. For example, compared with the Markov model, the top-1 accuracy improves by 40% on the VPR data and by 15.6% on the Taxi data.
Recent Trends in Artificial Intelligence-inspired Electronic Thermal Management
Dec 26, 2021
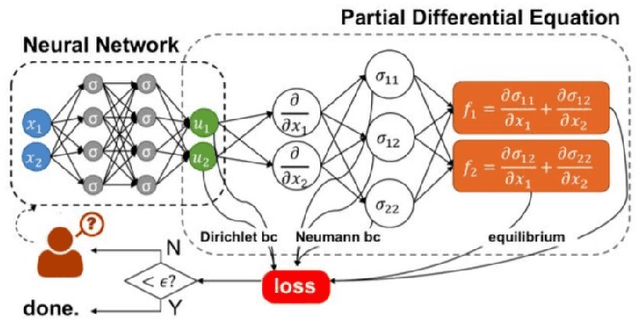
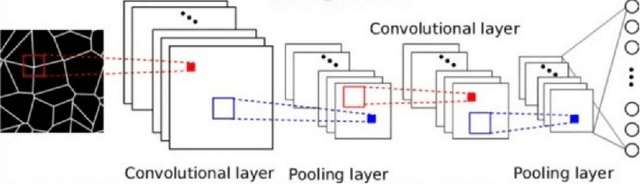
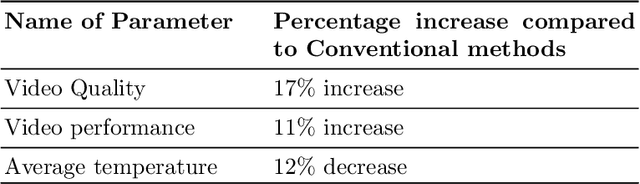
The rise of computation-based methods in thermal management has gained immense attention in recent years due to the ability of deep learning to solve complex 'physics' problems, which are otherwise difficult to be approached using conventional techniques. Thermal management is required in electronic systems to keep them from overheating and burning, enhancing their efficiency and lifespan. For a long time, numerical techniques have been employed to aid in the thermal management of electronics. However, they come with some limitations. To increase the effectiveness of traditional numerical approaches and address the drawbacks faced in conventional approaches, researchers have looked at using artificial intelligence at various stages of the thermal management process. The present study discusses in detail, the current uses of deep learning in the domain of 'electronic' thermal management.
Interpretable Real-Time Win Prediction for Honor of Kings, a Popular Mobile MOBA Esport
Aug 14, 2020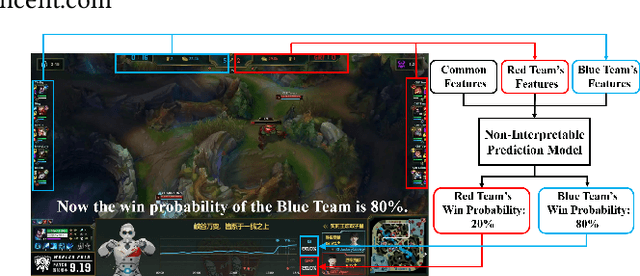

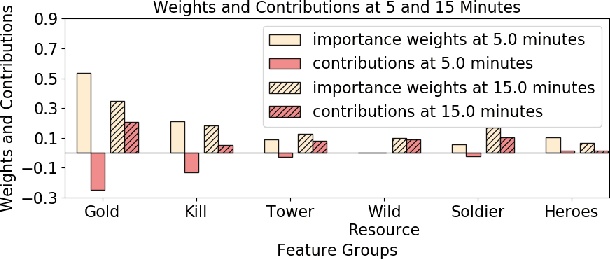
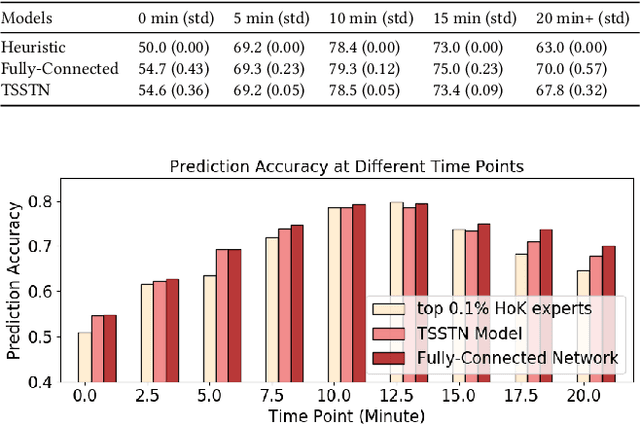
With the rapid prevalence and explosive development of MOBA esports (Multiplayer Online Battle Arena electronic sports), many research efforts have been devoted to automatically predicting the game results (win predictions). While this task has great potential in various applications such as esports live streaming and game commentator AI systems, previous studies suffer from two major limitations: 1) insufficient real-time input features and high-quality training data; 2) non-interpretable inference processes of the black-box prediction models. To mitigate these issues, we collect and release a large-scale dataset that contains real-time game records with rich input features of the popular MOBA game Honor of Kings. For interpretable predictions, we propose a Two-Stage Spatial-Temporal Network (TSSTN) that can not only provide accurate real-time win predictions but also attribute the ultimate prediction results to the contributions of different features for interpretability. Experiment results and applications in real-world live streaming scenarios show that the proposed TSSTN model is effective both in prediction accuracy and interpretability.
A Robust and Efficient Multi-Scale Seasonal-Trend Decomposition
Sep 18, 2021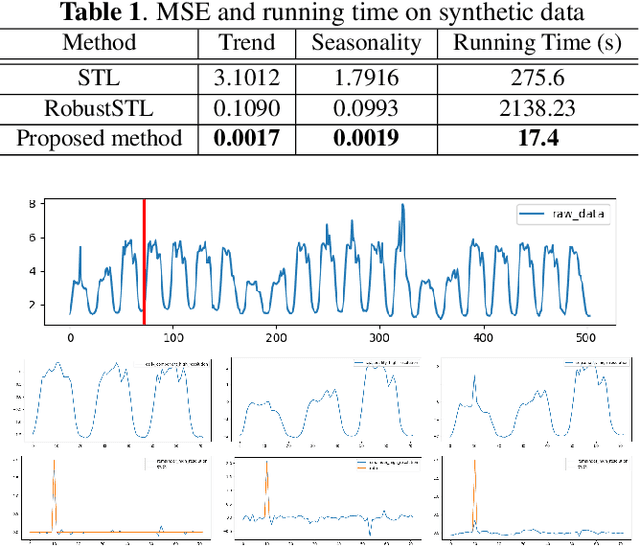
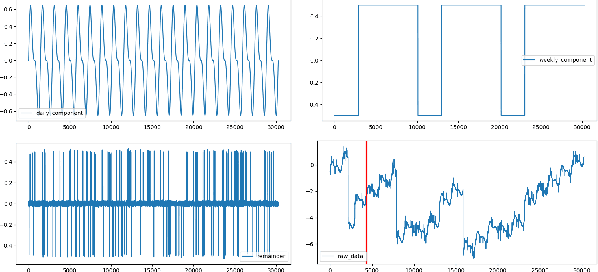
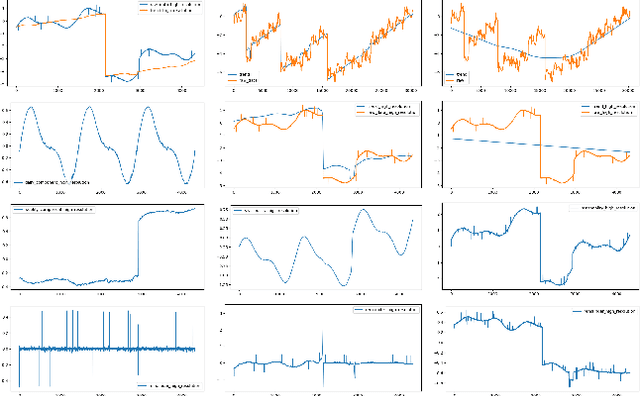
Many real-world time series exhibit multiple seasonality with different lengths. The removal of seasonal components is crucial in numerous applications of time series, including forecasting and anomaly detection. However, many seasonal-trend decomposition algorithms suffer from high computational cost and require a large amount of data when multiple seasonal components exist, especially when the periodic length is long. In this paper, we propose a general and efficient multi-scale seasonal-trend decomposition algorithm for time series with multiple seasonality. We first down-sample the original time series onto a lower resolution, and then convert it to a time series with single seasonality. Thus, existing seasonal-trend decomposition algorithms can be applied directly to obtain the rough estimates of trend and the seasonal component corresponding to the longer periodic length. By considering the relationship between different resolutions, we formulate the recovery of different components on the high resolution as an optimization problem, which is solved efficiently by our alternative direction multiplier method (ADMM) based algorithm. Our experimental results demonstrate the accurate decomposition results with significantly improved efficiency.
* Accepted by 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2021)
One System to Rule them All: a Universal Intent Recognition System for Customer Service Chatbots
Dec 15, 2021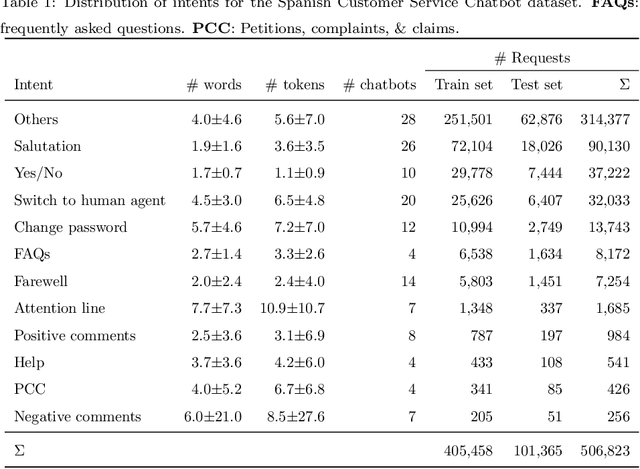
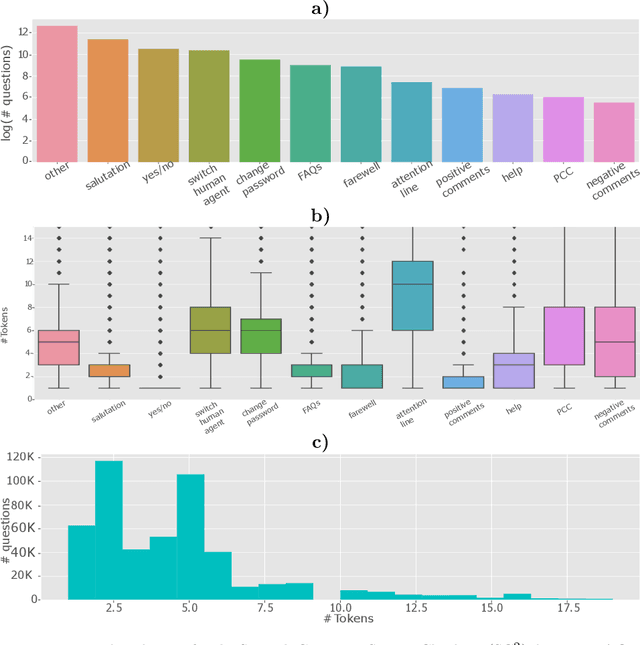
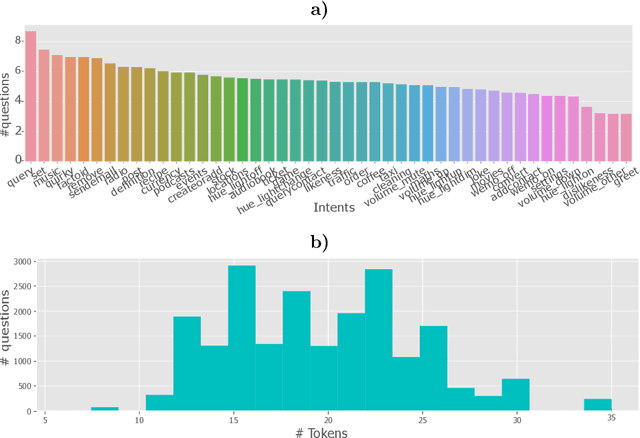
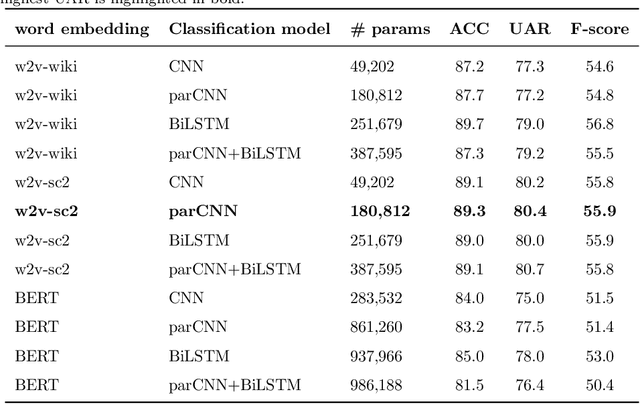
Customer service chatbots are conversational systems designed to provide information to customers about products/services offered by different companies. Particularly, intent recognition is one of the core components in the natural language understating capabilities of a chatbot system. Among the different intents that a chatbot is trained to recognize, there is a set of them that is universal to any customer service chatbot. Universal intents may include salutation, switch the conversation to a human agent, farewells, among others. A system to recognize those universal intents will be very helpful to optimize the training process of specific customer service chatbots. We propose the development of a universal intent recognition system, which is trained to recognize a selected group of 11 intents that are common in 28 different chatbots. The proposed system is trained considering state-of-the-art word-embedding models such as word2vec and BERT, and deep classifiers based on convolutional and recurrent neural networks. The proposed model is able to discriminate between those universal intents with a balanced accuracy up to 80.4\%. In addition, the proposed system is equally accurate to recognize intents expressed both in short and long text requests. At the same time, misclassification errors often occurs between intents with very similar semantic fields such as farewells and positive comments. The proposed system will be very helpful to optimize the training process of a customer service chatbot because some of the intents will be already available and detected by our system. At the same time, the proposed approach will be a suitable base model to train more specific chatbots by applying transfer learning strategies.
Soft Sensing Transformer: Hundreds of Sensors are Worth a Single Word
Nov 10, 2021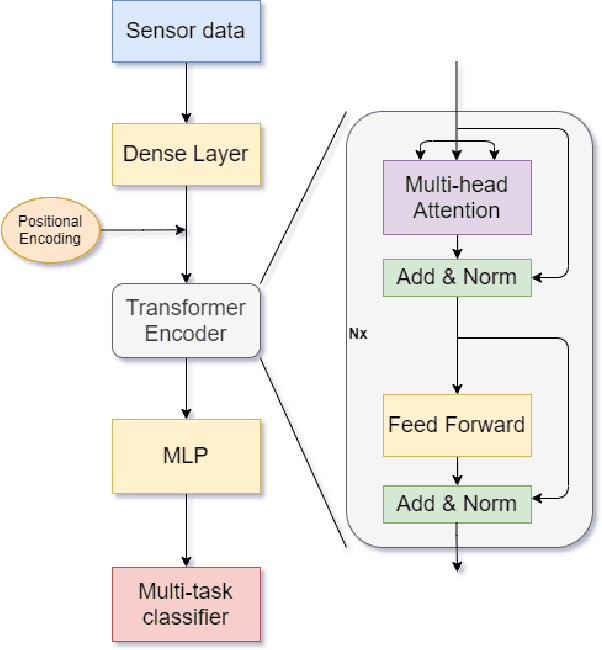

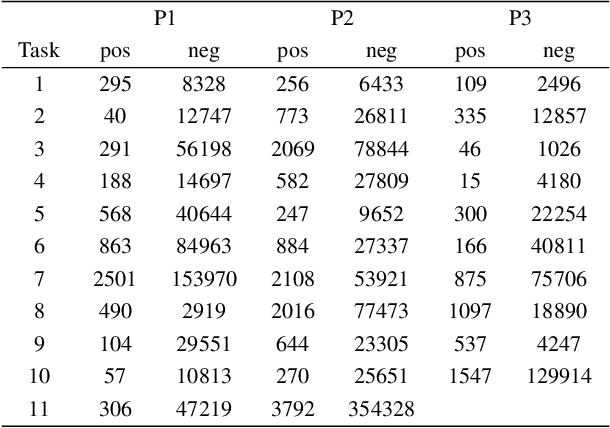
With the rapid development of AI technology in recent years, there have been many studies with deep learning models in soft sensing area. However, the models have become more complex, yet, the data sets remain limited: researchers are fitting million-parameter models with hundreds of data samples, which is insufficient to exercise the effectiveness of their models and thus often fail to perform when implemented in industrial applications. To solve this long-lasting problem, we are providing large scale, high dimensional time series manufacturing sensor data from Seagate Technology to the public. We demonstrate the challenges and effectiveness of modeling industrial big data by a Soft Sensing Transformer model on these data sets. Transformer is used because, it has outperformed state-of-the-art techniques in Natural Language Processing, and since then has also performed well in the direct application to computer vision without introduction of image-specific inductive biases. We observe the similarity of a sentence structure to the sensor readings and process the multi-variable sensor readings in a time series in a similar manner of sentences in natural language. The high-dimensional time-series data is formatted into the same shape of embedded sentences and fed into the transformer model. The results show that transformer model outperforms the benchmark models in soft sensing field based on auto-encoder and long short-term memory (LSTM) models. To the best of our knowledge, we are the first team in academia or industry to benchmark the performance of original transformer model with large-scale numerical soft sensing data.
Sketch2PQ: Freeform Planar Quadrilateral Mesh Design via a Single Sketch
Jan 23, 2022
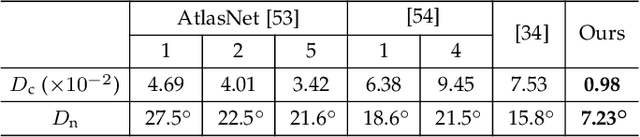
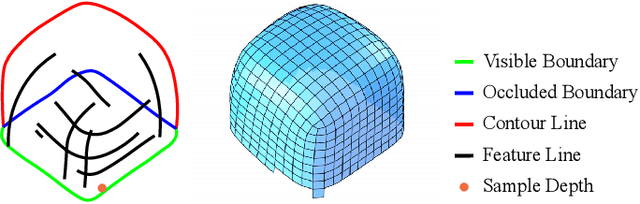
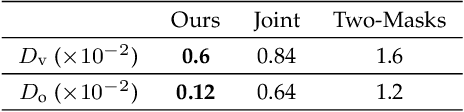
The freeform architectural modeling process often involves two important stages: concept design and digital modeling. In the first stage, architects usually sketch the overall 3D shape and the panel layout on a physical or digital paper briefly. In the second stage, a digital 3D model is created using the sketching as the reference. The digital model needs to incorporate geometric requirements for its components, such as planarity of panels due to consideration of construction costs, which can make the modeling process more challenging. In this work, we present a novel sketch-based system to bridge the concept design and digital modeling of freeform roof-like shapes represented as planar quadrilateral (PQ) meshes. Our system allows the user to sketch the surface boundary and contour lines under axonometric projection and supports the sketching of occluded regions. In addition, the user can sketch feature lines to provide directional guidance to the PQ mesh layout. Given the 2D sketch input, we propose a deep neural network to infer in real-time the underlying surface shape along with a dense conjugate direction field, both of which are used to extract the final PQ mesh. To train and validate our network, we generate a large synthetic dataset that mimics architect sketching of freeform quadrilateral patches. The effectiveness and usability of our system are demonstrated with quantitative and qualitative evaluation as well as user studies.
QuALITY: Question Answering with Long Input Texts, Yes!
Dec 16, 2021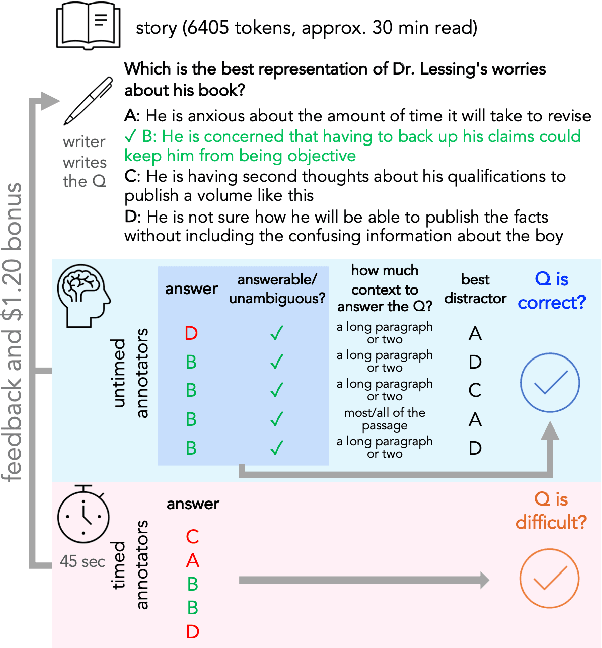


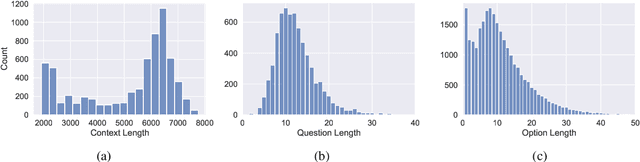
To enable building and testing models on long-document comprehension, we introduce QuALITY, a multiple-choice QA dataset with context passages in English that have an average length of about 5,000 tokens, much longer than typical current models can process. Unlike in prior work with passages, our questions are written and validated by contributors who have read the entire passage, rather than relying on summaries or excerpts. In addition, only half of the questions are answerable by annotators working under tight time constraints, indicating that skimming and simple search are not enough to consistently perform well. Current models perform poorly on this task (55.4%) and significantly lag behind human performance (93.5%).