 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid Reinforcement Learning-Based Eco-Driving Strategy for Connected and Automated Vehicles at Signalized Intersections
Jan 28, 2022
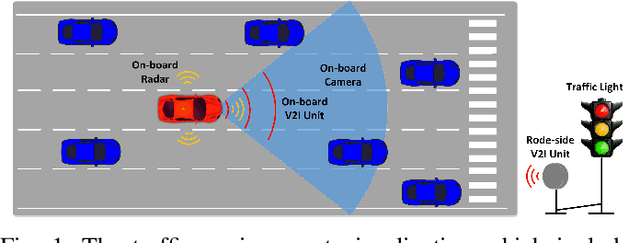
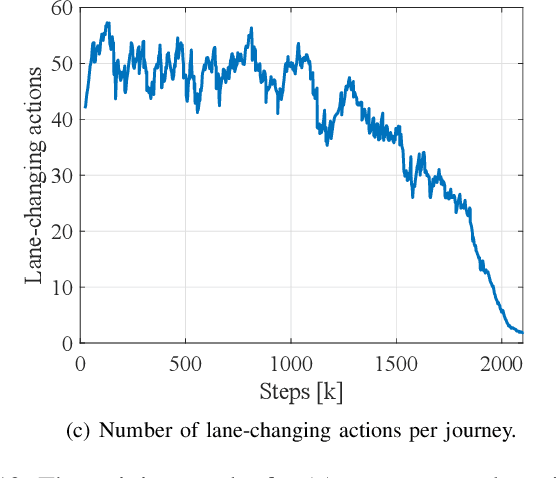
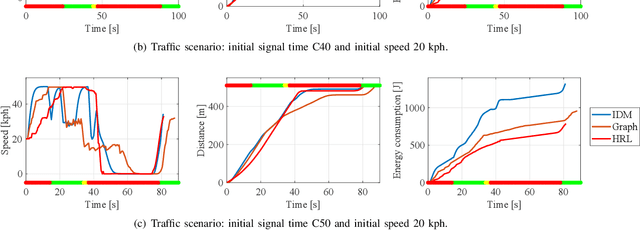
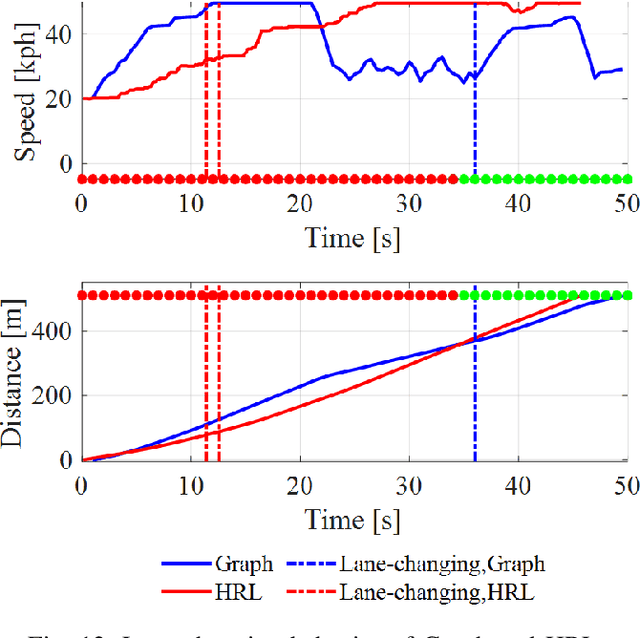
Taking advantage of both vehicle-to-everything (V2X) communication and automated driving technology, connected and automated vehicles are quickly becoming one of the transformative solutions to many transportation problems. However, in a mixed traffic environment at signalized intersections, it is still a challenging task to improve overall throughput and energy efficiency considering the complexity and uncertainty in the traffic system. In this study, we proposed a hybrid reinforcement learning (HRL) framework which combines the rule-based strategy and the deep reinforcement learning (deep RL) to support connected eco-driving at signalized intersections in mixed traffic. Vision-perceptive methods are integrated with vehicle-to-infrastructure (V2I) communications to achieve higher mobility and energy efficiency in mixed connected traffic. The HRL framework has three components: a rule-based driving manager that operates the collaboration between the rule-based policies and the RL policy; a multi-stream neural network that extracts the hidden features of vision and V2I information; and a deep RL-based policy network that generate both longitudinal and lateral eco-driving actions. In order to evaluate our approach, we developed a Unity-based simulator and designed a mixed-traffic intersection scenario. Moreover, several baselines were implemented to compare with our new design, and numerical experiments were conducted to test the performance of the HRL model. The experiments show that our HRL method can reduce energy consumption by 12.70% and save 11.75% travel time when compared with a state-of-the-art model-based Eco-Driving approach.
Vision in adverse weather: Augmentation using CycleGANs with various object detectors for robust perception in autonomous racing
Jan 10, 2022
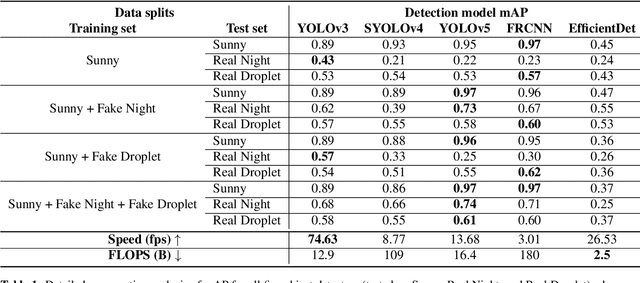
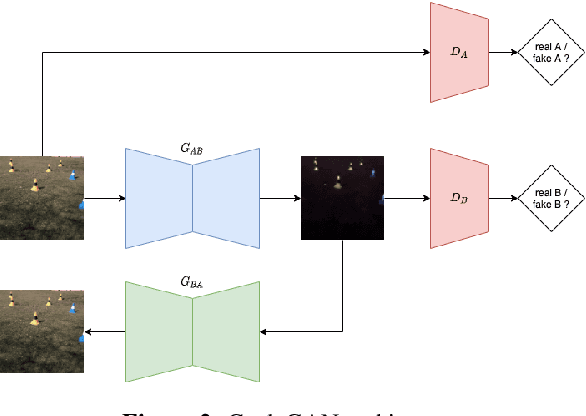

In an autonomous driving system, perception - identification of features and objects from the environment - is crucial. In autonomous racing, high speeds and small margins demand rapid and accurate detection systems. During the race, the weather can change abruptly, causing significant degradation in perception, resulting in ineffective manoeuvres. In order to improve detection in adverse weather, deep-learning-based models typically require extensive datasets captured in such conditions - the collection of which is a tedious, laborious, and costly process. However, recent developments in CycleGAN architectures allow the synthesis of highly realistic scenes in multiple weather conditions. To this end, we introduce an approach of using synthesised adverse condition datasets in autonomous racing (generated using CycleGAN) to improve the performance of four out of five state-of-the-art detectors by an average of 42.7 and 4.4 mAP percentage points in the presence of night-time conditions and droplets, respectively. Furthermore, we present a comparative analysis of five object detectors - identifying the optimal pairing of detector and training data for use during autonomous racing in challenging conditions.
CodeMapping: Real-Time Dense Mapping for Sparse SLAM using Compact Scene Representations
Jul 19, 2021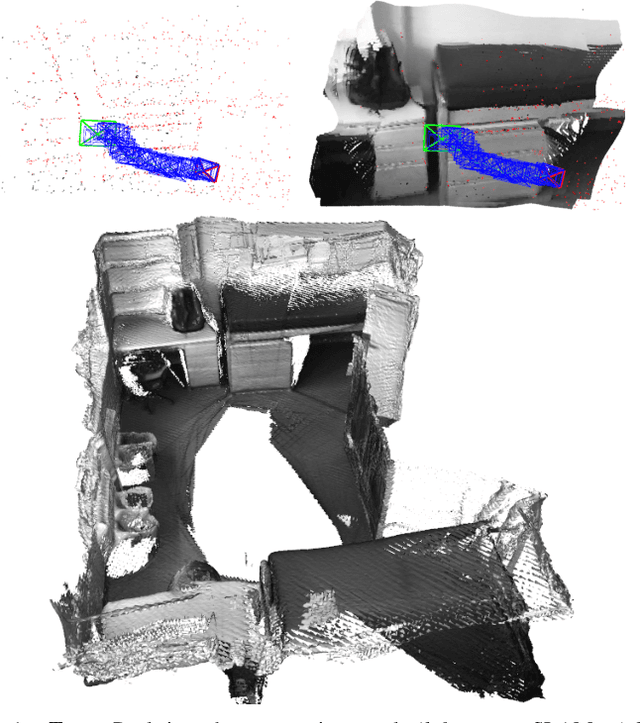

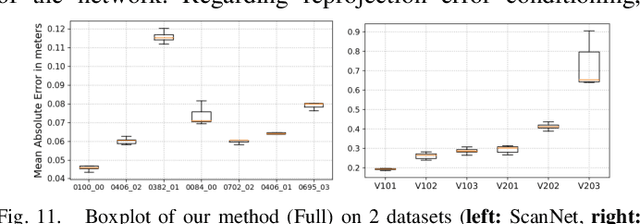

We propose a novel dense mapping framework for sparse visual SLAM systems which leverages a compact scene representation. State-of-the-art sparse visual SLAM systems provide accurate and reliable estimates of the camera trajectory and locations of landmarks. While these sparse maps are useful for localization, they cannot be used for other tasks such as obstacle avoidance or scene understanding. In this paper we propose a dense mapping framework to complement sparse visual SLAM systems which takes as input the camera poses, keyframes and sparse points produced by the SLAM system and predicts a dense depth image for every keyframe. We build on CodeSLAM and use a variational autoencoder (VAE) which is conditioned on intensity, sparse depth and reprojection error images from sparse SLAM to predict an uncertainty-aware dense depth map. The use of a VAE then enables us to refine the dense depth images through multi-view optimization which improves the consistency of overlapping frames. Our mapper runs in a separate thread in parallel to the SLAM system in a loosely coupled manner. This flexible design allows for integration with arbitrary metric sparse SLAM systems without delaying the main SLAM process. Our dense mapper can be used not only for local mapping but also globally consistent dense 3D reconstruction through TSDF fusion. We demonstrate our system running with ORB-SLAM3 and show accurate dense depth estimation which could enable applications such as robotics and augmented reality.
A Robust and Efficient Multi-Scale Seasonal-Trend Decomposition
Sep 18, 2021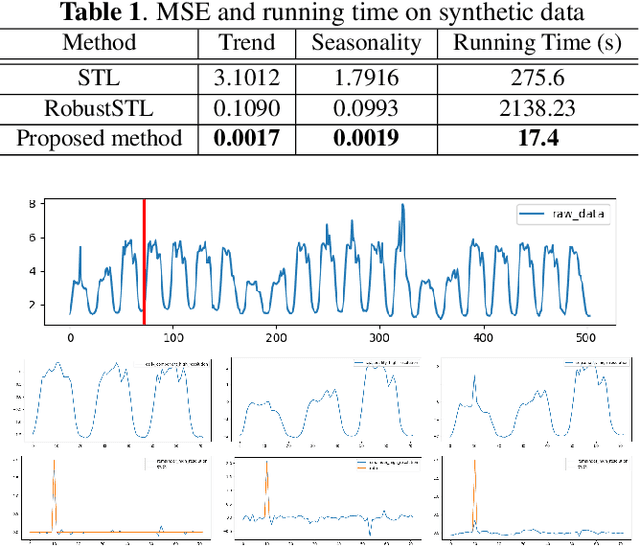
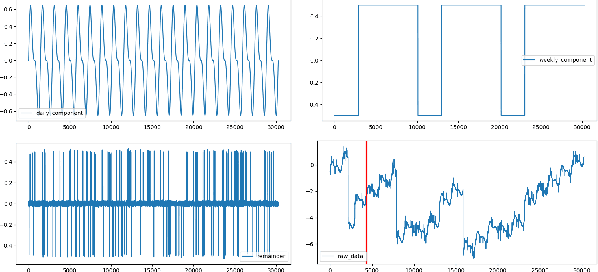
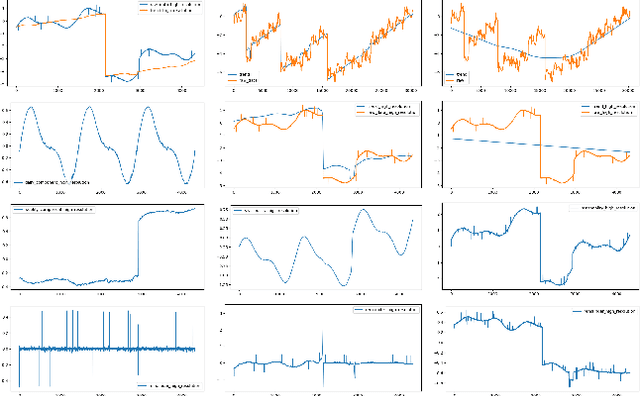
Many real-world time series exhibit multiple seasonality with different lengths. The removal of seasonal components is crucial in numerous applications of time series, including forecasting and anomaly detection. However, many seasonal-trend decomposition algorithms suffer from high computational cost and require a large amount of data when multiple seasonal components exist, especially when the periodic length is long. In this paper, we propose a general and efficient multi-scale seasonal-trend decomposition algorithm for time series with multiple seasonality. We first down-sample the original time series onto a lower resolution, and then convert it to a time series with single seasonality. Thus, existing seasonal-trend decomposition algorithms can be applied directly to obtain the rough estimates of trend and the seasonal component corresponding to the longer periodic length. By considering the relationship between different resolutions, we formulate the recovery of different components on the high resolution as an optimization problem, which is solved efficiently by our alternative direction multiplier method (ADMM) based algorithm. Our experimental results demonstrate the accurate decomposition results with significantly improved efficiency.
* Accepted by 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2021)
Recent Trends in Artificial Intelligence-inspired Electronic Thermal Management
Dec 26, 2021
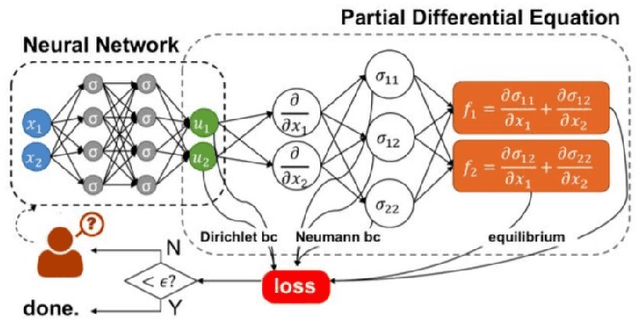
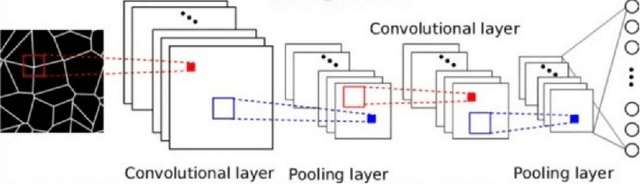
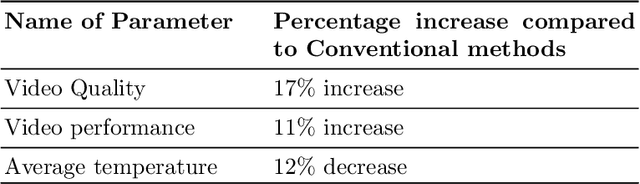
The rise of computation-based methods in thermal management has gained immense attention in recent years due to the ability of deep learning to solve complex 'physics' problems, which are otherwise difficult to be approached using conventional techniques. Thermal management is required in electronic systems to keep them from overheating and burning, enhancing their efficiency and lifespan. For a long time, numerical techniques have been employed to aid in the thermal management of electronics. However, they come with some limitations. To increase the effectiveness of traditional numerical approaches and address the drawbacks faced in conventional approaches, researchers have looked at using artificial intelligence at various stages of the thermal management process. The present study discusses in detail, the current uses of deep learning in the domain of 'electronic' thermal management.
Neural Fitted Q Iteration based Optimal Bidding Strategy in Real Time Reactive Power Market_1
Jan 07, 2021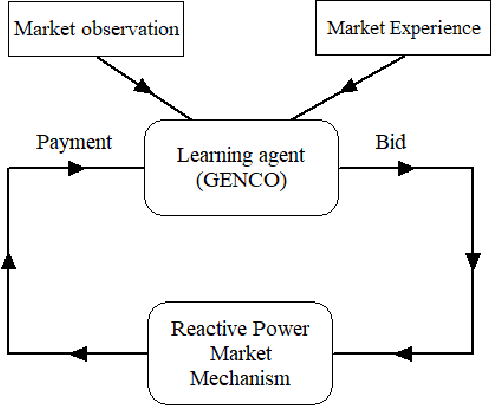
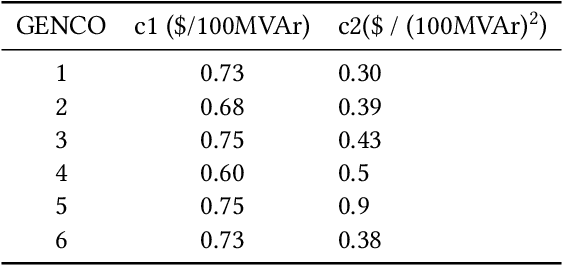
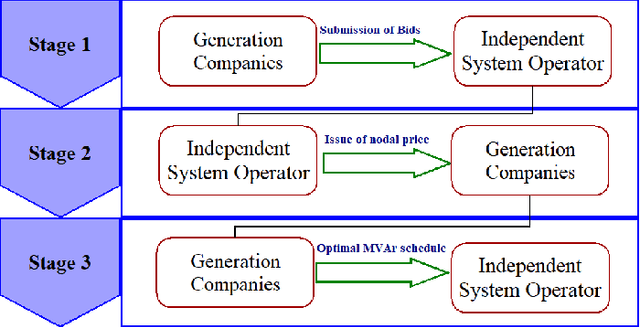
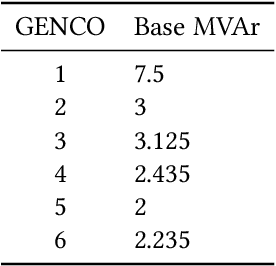
In real time electricity markets, the objective of generation companies while bidding is to maximize their profit. The strategies for learning optimal bidding have been formulated through game theoretical approaches and stochastic optimization problems. Similar studies in reactive power markets have not been reported so far because the network voltage operating conditions have an increased impact on reactive power markets than on active power markets. Contrary to active power markets, the bids of rivals are not directly related to fuel costs in reactive power markets. Hence, the assumption of a suitable probability distribution function is unrealistic, making the strategies adopted in active power markets unsuitable for learning optimal bids in reactive power market mechanisms. Therefore, a bidding strategy is to be learnt from market observations and experience in imperfect oligopolistic competition-based markets. In this paper, a pioneer work on learning optimal bidding strategies from observation and experience in a three-stage reactive power market is reported.
Soft Sensing Transformer: Hundreds of Sensors are Worth a Single Word
Nov 10, 2021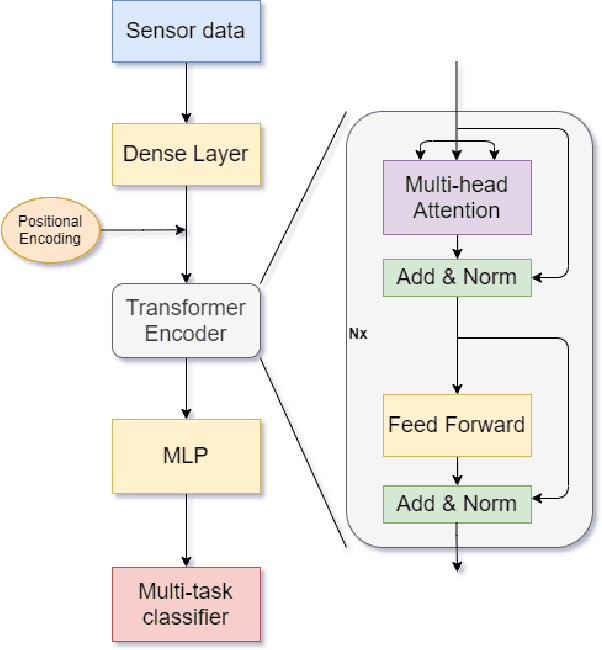

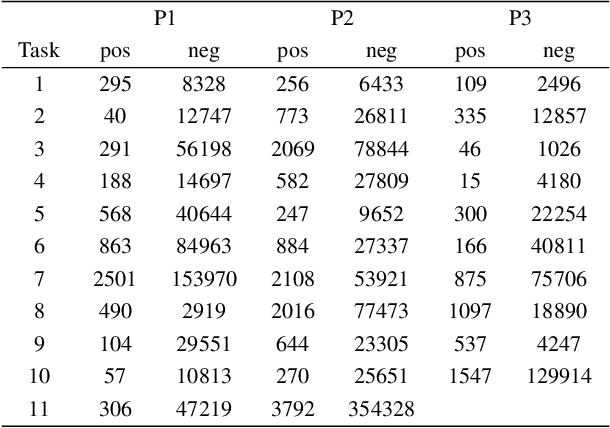
With the rapid development of AI technology in recent years, there have been many studies with deep learning models in soft sensing area. However, the models have become more complex, yet, the data sets remain limited: researchers are fitting million-parameter models with hundreds of data samples, which is insufficient to exercise the effectiveness of their models and thus often fail to perform when implemented in industrial applications. To solve this long-lasting problem, we are providing large scale, high dimensional time series manufacturing sensor data from Seagate Technology to the public. We demonstrate the challenges and effectiveness of modeling industrial big data by a Soft Sensing Transformer model on these data sets. Transformer is used because, it has outperformed state-of-the-art techniques in Natural Language Processing, and since then has also performed well in the direct application to computer vision without introduction of image-specific inductive biases. We observe the similarity of a sentence structure to the sensor readings and process the multi-variable sensor readings in a time series in a similar manner of sentences in natural language. The high-dimensional time-series data is formatted into the same shape of embedded sentences and fed into the transformer model. The results show that transformer model outperforms the benchmark models in soft sensing field based on auto-encoder and long short-term memory (LSTM) models. To the best of our knowledge, we are the first team in academia or industry to benchmark the performance of original transformer model with large-scale numerical soft sensing data.
No News is Good News: A Critique of the One Billion Word Benchmark
Oct 25, 2021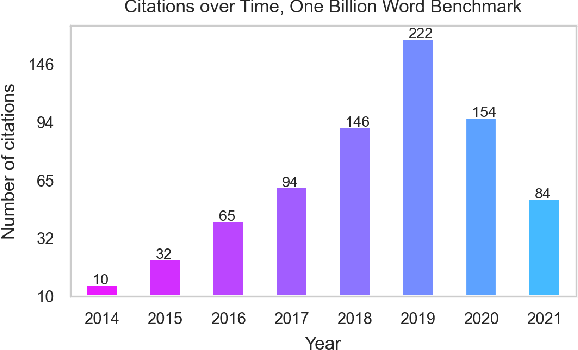
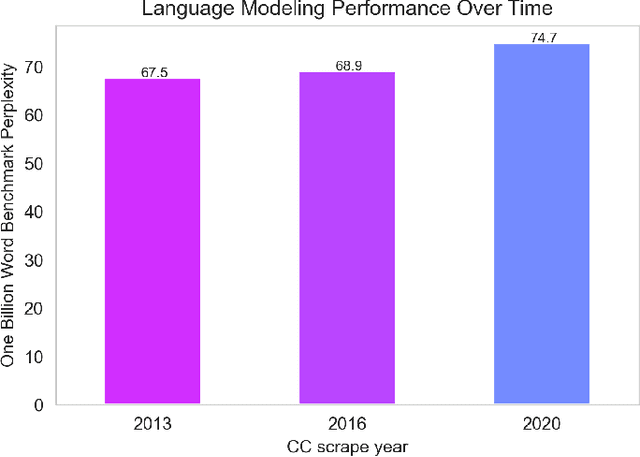
The One Billion Word Benchmark is a dataset derived from the WMT 2011 News Crawl, commonly used to measure language modeling ability in natural language processing. We train models solely on Common Crawl web scrapes partitioned by year, and demonstrate that they perform worse on this task over time due to distributional shift. Analysis of this corpus reveals that it contains several examples of harmful text, as well as outdated references to current events. We suggest that the temporal nature of news and its distribution shift over time makes it poorly suited for measuring language modeling ability, and discuss potential impact and considerations for researchers building language models and evaluation datasets.
QuALITY: Question Answering with Long Input Texts, Yes!
Dec 16, 2021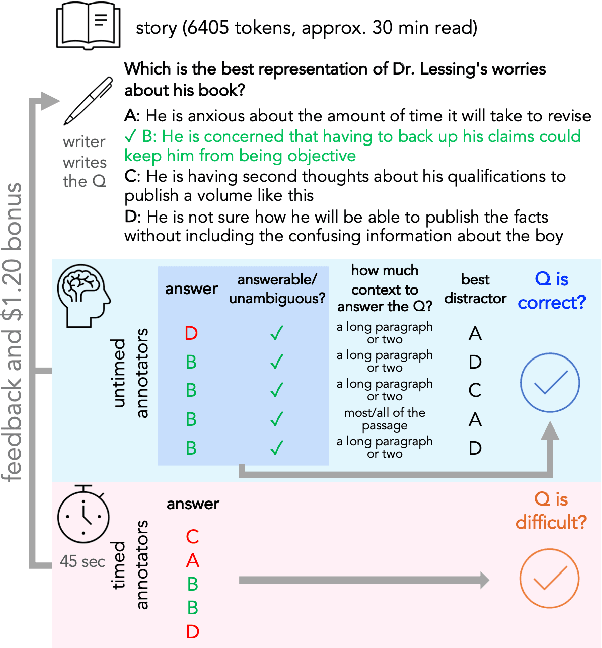


To enable building and testing models on long-document comprehension, we introduce QuALITY, a multiple-choice QA dataset with context passages in English that have an average length of about 5,000 tokens, much longer than typical current models can process. Unlike in prior work with passages, our questions are written and validated by contributors who have read the entire passage, rather than relying on summaries or excerpts. In addition, only half of the questions are answerable by annotators working under tight time constraints, indicating that skimming and simple search are not enough to consistently perform well. Current models perform poorly on this task (55.4%) and significantly lag behind human performance (93.5%).
Machine learning applications in time series hierarchical forecasting
Dec 01, 2019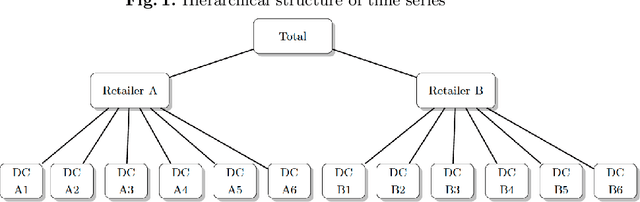
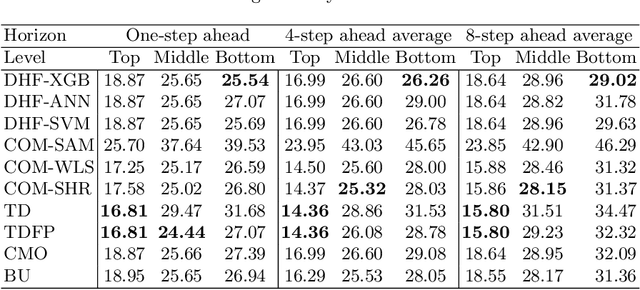
Hierarchical forecasting (HF) is needed in many situations in the supply chain (SC) because managers often need different levels of forecasts at different levels of SC to make a decision. Top-Down (TD), Bottom-Up (BU) and Optimal Combination (COM) are common HF models. These approaches are static and often ignore the dynamics of the series while disaggregating them. Consequently, they may fail to perform well if the investigated group of time series are subject to large changes such as during the periods of promotional sales. We address the HF problem of predicting real-world sales time series that are highly impacted by promotion. We use three machine learning (ML) models to capture sales variations over time. Artificial neural networks (ANN), extreme gradient boosting (XGboost), and support vector regression (SVR) algorithms are used to estimate the proportions of lower-level time series from the upper level. We perform an in-depth analysis of 61 groups of time series with different volatilities and show that ML models are competitive and outperform some well-established models in the literature.