 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GOSH: Task Scheduling Using Deep Surrogate Models in Fog Computing Environments
Dec 16, 2021

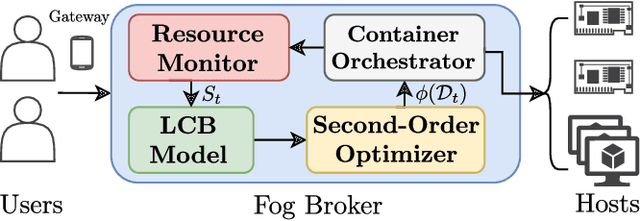
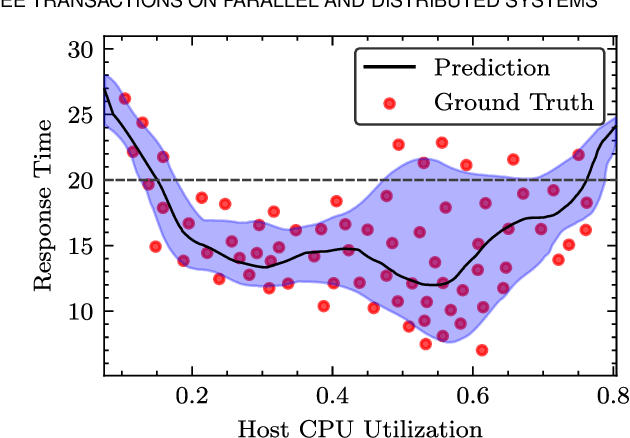
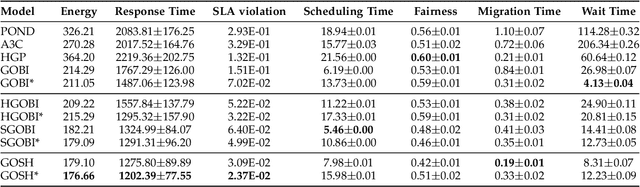
Recently, intelligent scheduling approaches using surrogate models have been proposed to efficiently allocate volatile tasks in heterogeneous fog environments. Advances like deterministic surrogate models, deep neural networks (DNN) and gradient-based optimization allow low energy consumption and response times to be reached. However, deterministic surrogate models, which estimate objective values for optimization, do not consider the uncertainties in the distribution of the Quality of Service (QoS) objective function that can lead to high Service Level Agreement (SLA) violation rates. Moreover, the brittle nature of DNN training and prevent such models from reaching minimal energy or response times. To overcome these difficulties, we present a novel scheduler: GOSH i.e. Gradient Based Optimization using Second Order derivatives and Heteroscedastic Deep Surrogate Models. GOSH uses a second-order gradient based optimization approach to obtain better QoS and reduce the number of iterations to converge to a scheduling decision, subsequently lowering the scheduling time. Instead of a vanilla DNN, GOSH uses a Natural Parameter Network to approximate objective scores. Further, a Lower Confidence Bound optimization approach allows GOSH to find an optimal trade-off between greedy minimization of the mean latency and uncertainty reduction by employing error-based exploration. Thus, GOSH and its co-simulation based extension GOSH*, can adapt quickly and reach better objective scores than baseline methods. We show that GOSH* reaches better objective scores than GOSH, but it is suitable only for high resource availability settings, whereas GOSH is apt for limited resource settings. Real system experiments for both GOSH and GOSH* show significant improvements against the state-of-the-art in terms of energy consumption, response time and SLA violations by up to 18, 27 and 82 percent, respectively.
An Automatic Control System with Human-in-the-Loop for Training Skydiving Maneuvers: Proof-of-Concept Experiment
Jan 20, 2022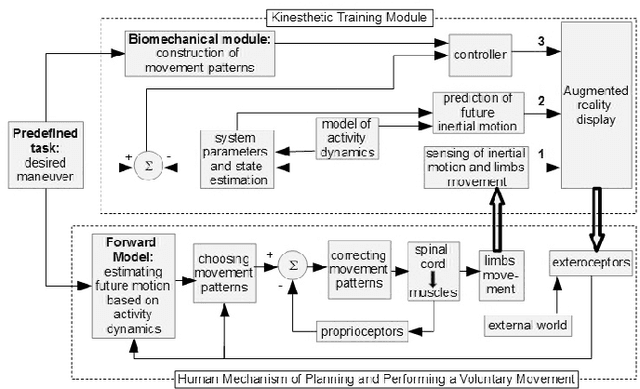
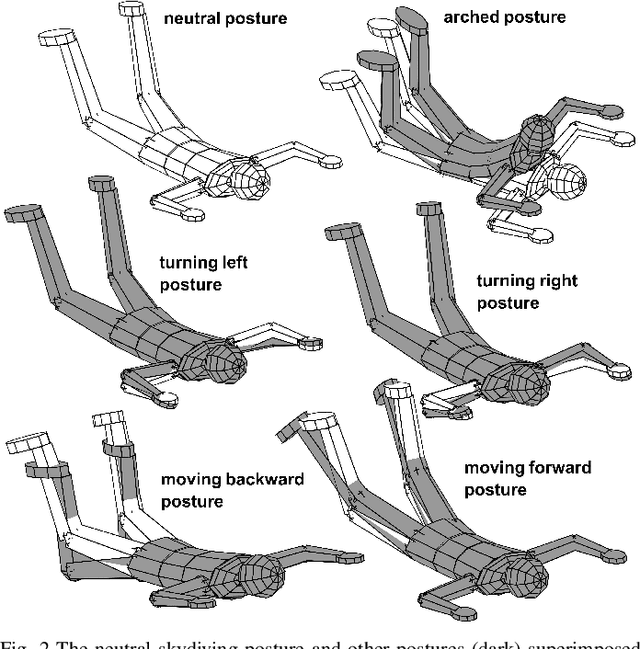
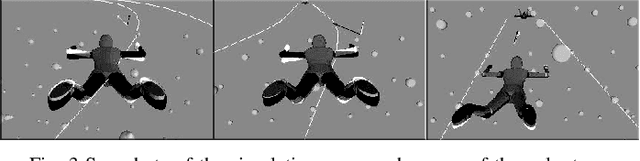
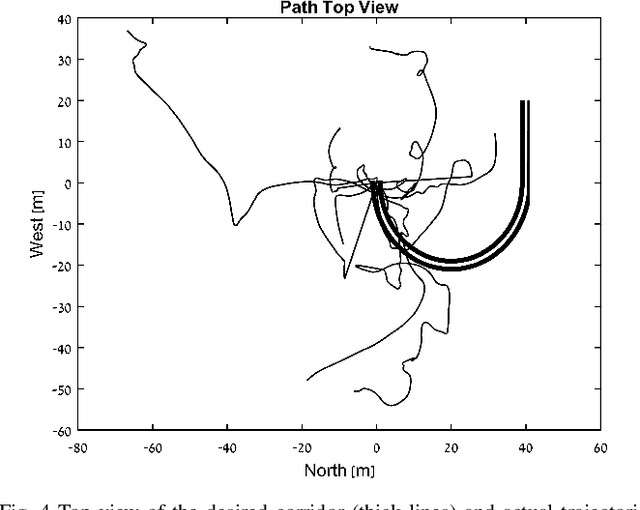
A real-time motion training system for skydiving is proposed. Aerial maneuvers are performed by changing the body posture and thus deflecting the surrounding airflow. The natural learning process is extremely slow due to unfamiliar free-fall dynamics, stress induced blocking of kinesthetic feedback, and complexity of the required movements. The key idea is to augment the learner with an automatic control system that would be able to perform the trained activity if it had direct access to the learner's body as an actuator. The aiding system will supply the following visual cues to the learner: 1. Feedback of the current body posture; 2. The body posture that would bring the body to perform the desired maneuver; 3. Prediction of the future inertial position and orientation if the body retains its present posture. The system will enable novices to maintain stability in free-fall and perceive the unfamiliar environmental dynamics, thus accelerating the initial stages of skill acquisition. This paper presents results of a Proof-of-Concept experiment, whereby humans controlled a virtual skydiver free-falling in a computer simulation, by the means of their bodies. This task was impossible without the aiding system, enabling all participants to complete the task at the first attempt.
SPAMs: Structured Implicit Parametric Models
Jan 20, 2022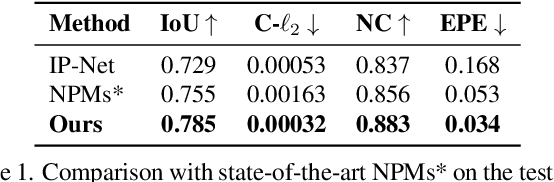
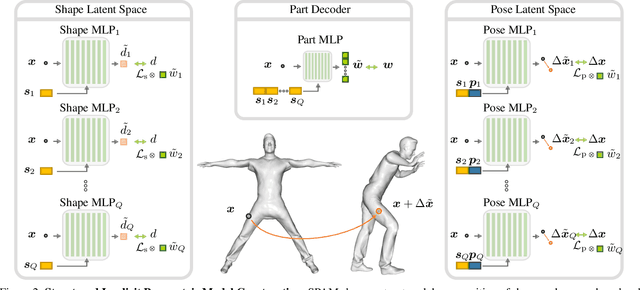
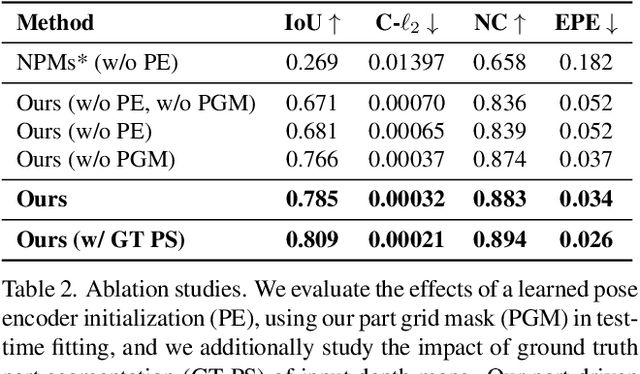

Parametric 3D models have formed a fundamental role in modeling deformable objects, such as human bodies, faces, and hands; however, the construction of such parametric models requires significant manual intervention and domain expertise. Recently, neural implicit 3D representations have shown great expressibility in capturing 3D shape geometry. We observe that deformable object motion is often semantically structured, and thus propose to learn Structured-implicit PArametric Models (SPAMs) as a deformable object representation that structurally decomposes non-rigid object motion into part-based disentangled representations of shape and pose, with each being represented by deep implicit functions. This enables a structured characterization of object movement, with part decomposition characterizing a lower-dimensional space in which we can establish coarse motion correspondence. In particular, we can leverage the part decompositions at test time to fit to new depth sequences of unobserved shapes, by establishing part correspondences between the input observation and our learned part spaces; this guides a robust joint optimization between the shape and pose of all parts, even under dramatic motion sequences. Experiments demonstrate that our part-aware shape and pose understanding lead to state-of-the-art performance in reconstruction and tracking of depth sequences of complex deforming object motion. We plan to release models to the public at https://pablopalafox.github.io/spams.
Neural Architecture Searching for Facial Attributes-based Depression Recognition
Jan 24, 2022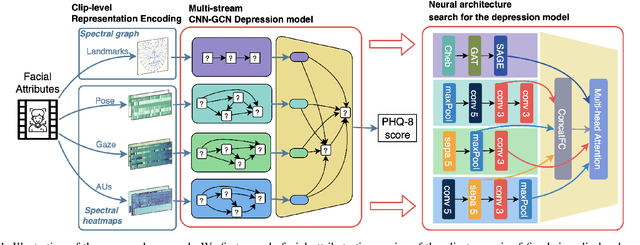
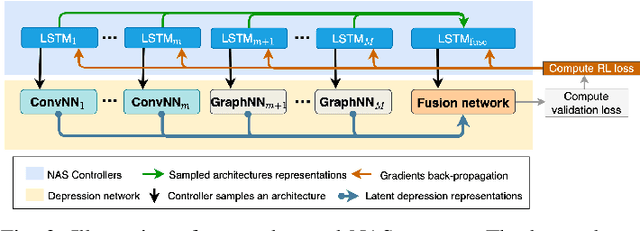
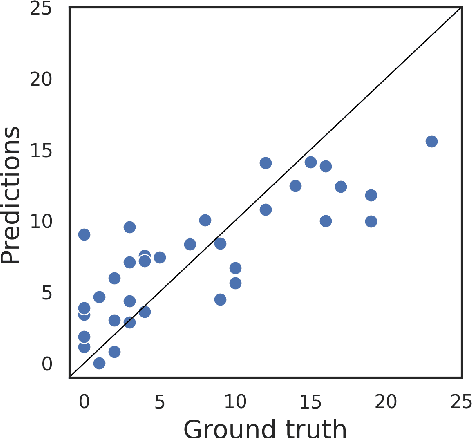
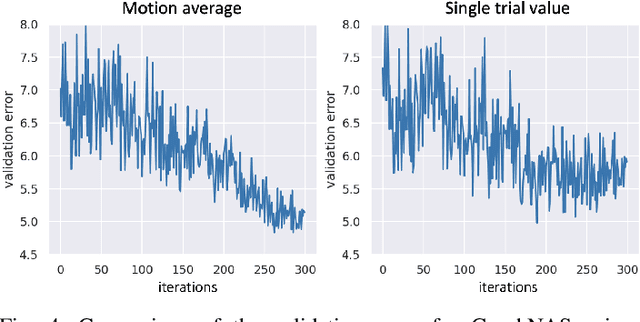
Recent studies show that depression can be partially reflected from human facial attributes. Since facial attributes have various data structure and carry different information, existing approaches fail to specifically consider the optimal way to extract depression-related features from each of them, as well as investigates the best fusion strategy. In this paper, we propose to extend Neural Architecture Search (NAS) technique for designing an optimal model for multiple facial attributes-based depression recognition, which can be efficiently and robustly implemented in a small dataset. Our approach first conducts a warmer up step to the feature extractor of each facial attribute, aiming to largely reduce the search space and providing customized architecture, where each feature extractor can be either a Convolution Neural Networks (CNN) or Graph Neural Networks (GNN). Then, we conduct an end-to-end architecture search for all feature extractors and the fusion network, allowing the complementary depression cues to be optimally combined with less redundancy. The experimental results on AVEC 2016 dataset show that the model explored by our approach achieves breakthrough performance with 27\% and 30\% RMSE and MAE improvements over the existing state-of-the-art. In light of these findings, this paper provides solid evidences and a strong baseline for applying NAS to time-series data-based mental health analysis.
Autonomous, Mobile Manipulation in a Wall-building Scenario: Team LARICS at MBZIRC 2020
Jan 28, 2022

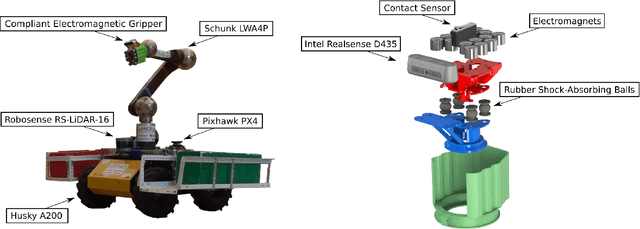
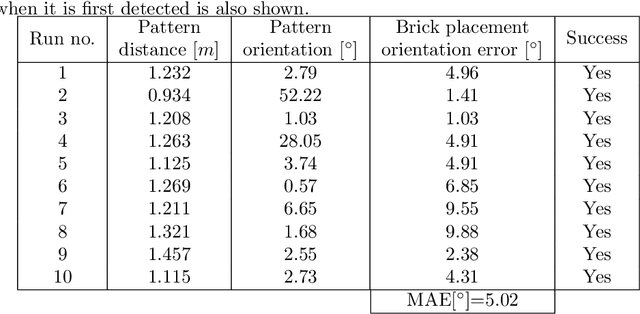
In this paper we present our hardware design and control approaches for a mobile manipulation platform used in Challenge 2 of the MBZIRC 2020 competition. In this challenge, a team of UAVs and a single UGV collaborate in an autonomous, wall-building scenario, motivated by construction automation and large-scale robotic 3D printing. The robots must be able, autonomously, to detect, manipulate, and transport bricks in an unstructured, outdoor environment. Our control approach is based on a state machine that dictates which controllers are active at each stage of the Challenge. In the first stage our UGV uses visual servoing and local controllers to approach the target object without considering its orientation. The second stage consists of detecting the object's global pose using OpenCV-based processing of RGB-D image and point-cloud data, and calculating an alignment goal within a global map. The map is built with Google Cartographer and is based on onboard LIDAR, IMU, and GPS data. Motion control in the second stage is realized using the ROS Move Base package with Time-Elastic Band trajectory optimization. Visual servo algorithms guide the vehicle in local object-approach movement and the arm in manipulating bricks. To ensure a stable grasp of the brick's magnetic patch, we developed a passively-compliant, electromagnetic gripper with tactile feedback. Our fully-autonomous UGV performed well in Challenge 2 and in post-competition evaluations of its brick pick-and-place algorithms.
Neural Fitted Q Iteration based Optimal Bidding Strategy in Real Time Reactive Power Market_1
Jan 07, 2021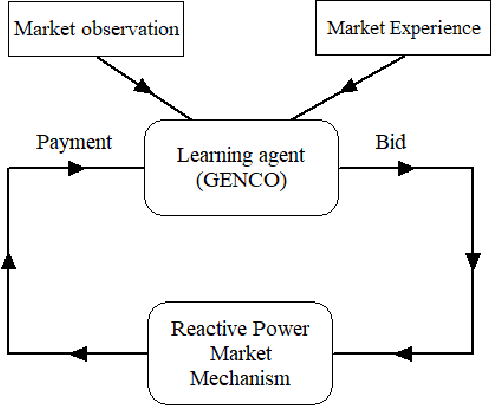
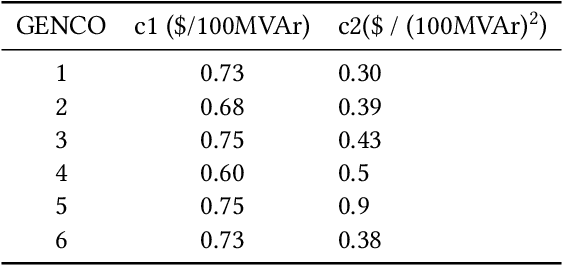
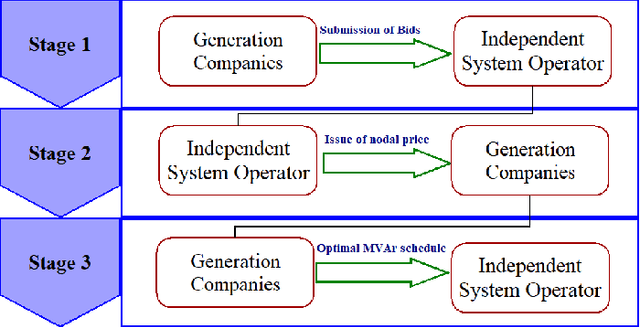
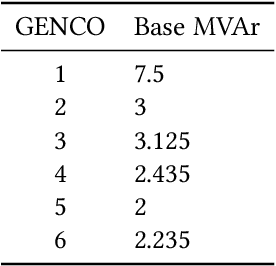
In real time electricity markets, the objective of generation companies while bidding is to maximize their profit. The strategies for learning optimal bidding have been formulated through game theoretical approaches and stochastic optimization problems. Similar studies in reactive power markets have not been reported so far because the network voltage operating conditions have an increased impact on reactive power markets than on active power markets. Contrary to active power markets, the bids of rivals are not directly related to fuel costs in reactive power markets. Hence, the assumption of a suitable probability distribution function is unrealistic, making the strategies adopted in active power markets unsuitable for learning optimal bids in reactive power market mechanisms. Therefore, a bidding strategy is to be learnt from market observations and experience in imperfect oligopolistic competition-based markets. In this paper, a pioneer work on learning optimal bidding strategies from observation and experience in a three-stage reactive power market is reported.
Detection of fake faces in videos
Jan 28, 2022
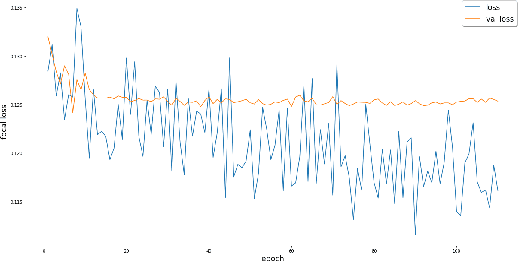
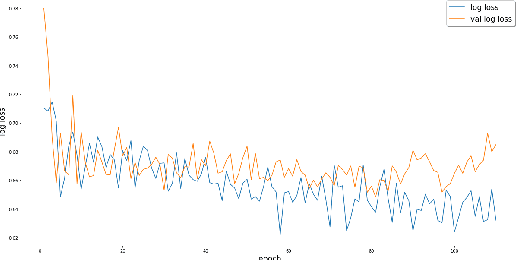

: Deep learning methodologies have been used to create applications that can cause threats to privacy, democracy and national security and could be used to further amplify malicious activities. One of those deep learning-powered applications in recent times is synthesized videos of famous personalities. According to Forbes, Generative Adversarial Networks(GANs) generated fake videos growing exponentially every year and the organization known as Deeptrace had estimated an increase of deepfakes by 84% from the year 2018 to 2019. They are used to generate and modify human faces, where most of the existing fake videos are of prurient non-consensual nature, of which its estimates to be around 96% and some carried out impersonating personalities for cyber crime. In this paper, available video datasets are identified and a pretrained model BlazeFace is used to detect faces, and a ResNet and Xception ensembled architectured neural network trained on the dataset to achieve the goal of detection of fake faces in videos. The model is optimized over a loss value and log loss values and evaluated over its F1 score. Over a sample of data, it is observed that focal loss provides better accuracy, F1 score and loss as the gamma of the focal loss becomes a hyper parameter. This provides a k-folded accuracy of around 91% at its peak in a training cycle with the real world accuracy subjected to change over time as the model decays.
DCF-ASN: Coarse-to-fine Real-time Visual Tracking via Discriminative Correlation Filter and Attentional Siamese Network
Mar 19, 2021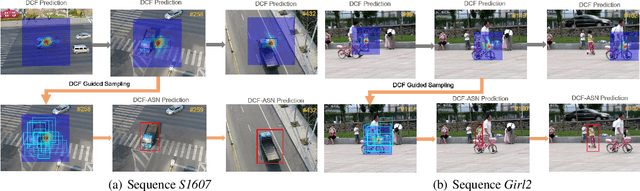
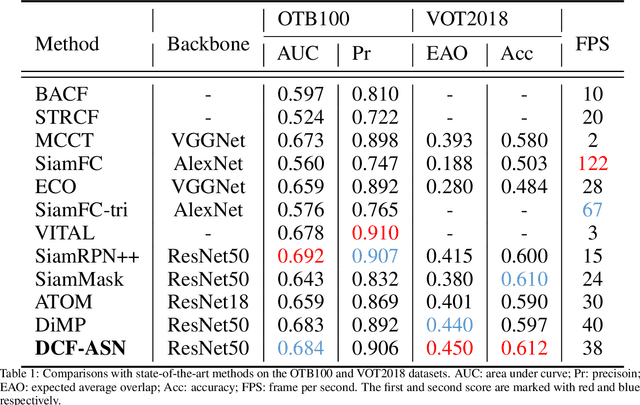
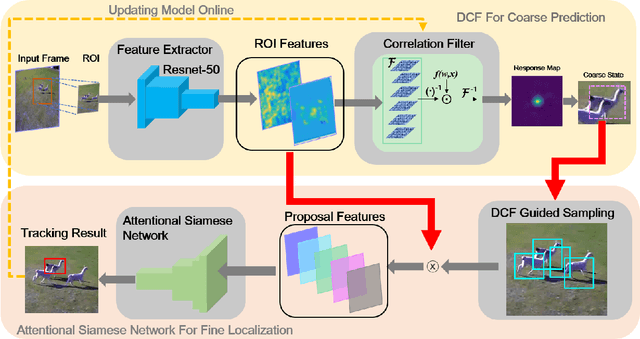

Discriminative correlation filters (DCF) and siamese networks have achieved promising performance on visual tracking tasks thanks to their superior computational efficiency and reliable similarity metric learning, respectively. However, how to effectively take advantages of powerful deep networks, while maintaining the real-time response of DCF, remains a challenging problem. Embedding the cross-correlation operator as a separate layer into siamese networks is a popular choice to enhance the tracking accuracy. Being a key component of such a network, the correlation layer is updated online together with other parts of the network. Yet, when facing serious disturbance, fused trackers may still drift away from the target completely due to accumulated errors. To address these issues, we propose a coarse-to-fine tracking framework, which roughly infers the target state via an online-updating DCF module first and subsequently, finely locates the target through an offline-training asymmetric siamese network (ASN). Benefitting from the guidance of DCF and the learned channel weights obtained through exploiting the given ground-truth template, ASN refines feature representation and implements precise target localization. Systematic experiments on five popular tracking datasets demonstrate that the proposed DCF-ASN achieves the state-of-the-art performance while exhibiting good tracking efficiency.
An EEG-based approach for Parkinson's disease diagnosis using Capsule network
Dec 27, 2021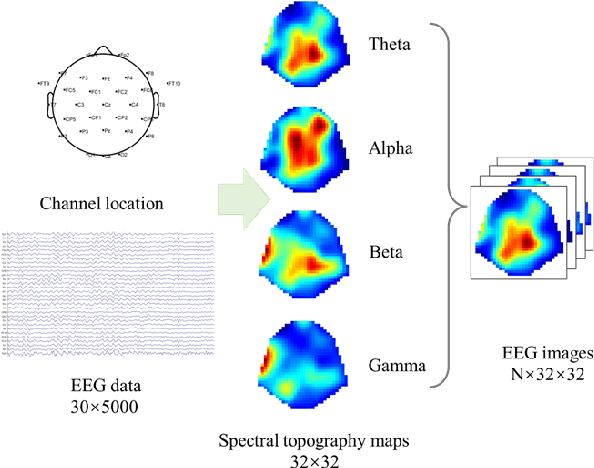
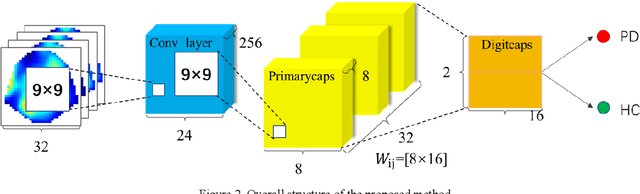
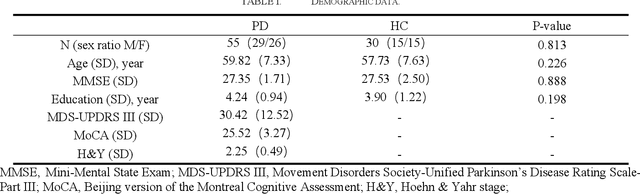
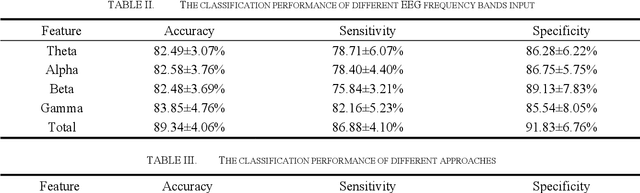
As the second most common neurodegenerative disease, Parkinson's disease has caused serious problems worldwide. However, the cause and mechanism of PD are not clear, and no systematic early diagnosis and treatment of PD have been established, many patients with PD have not been diagnosed or misdiagnosed. In this paper, we proposed an EEG-based approach to diagnosing Parkinson's disease, it mapping the frequency band energy of EEG signals to 2-dimensional images using the interpolation method and identifying classification using CapsNet, achieved 89.34% classification accuracy for short-time EEG sections, which exceeds the conventional SVM model.A comparison of separate classification accuracy across different EEG bands revealed the highest accuracy in the gamma bands, suggesting that we need pay more attention to the changes in gamma band changes in the early stages of PD.
Real-Time Optimization Of Web Publisher RTB Revenues
Jun 12, 2020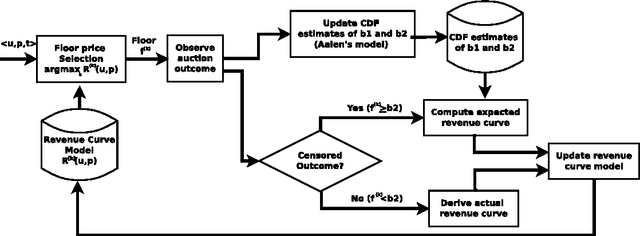
This paper describes an engine to optimize web publisher revenues from second-price auctions. These auctions are widely used to sell online ad spaces in a mechanism called real-time bidding (RTB). Optimization within these auctions is crucial for web publishers, because setting appropriate reserve prices can significantly increase revenue. We consider a practical real-world setting where the only available information before an auction occurs consists of a user identifier and an ad placement identifier. The real-world challenges we had to tackle consist mainly of tracking the dependencies on both the user and placement in an highly non-stationary environment and of dealing with censored bid observations. These challenges led us to make the following design choices: (i) we adopted a relatively simple non-parametric regression model of auction revenue based on an incremental time-weighted matrix factorization which implicitly builds adaptive users' and placements' profiles; (ii) we jointly used a non-parametric model to estimate the first and second bids' distribution when they are censored, based on an on-line extension of the Aalen's Additive model. Our engine is a component of a deployed system handling hundreds of web publishers across the world, serving billions of ads a day to hundreds of millions of visitors. The engine is able to predict, for each auction, an optimal reserve price in approximately one millisecond and yields a significant revenue increase for the web publishers.