 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NeuralProphet: Explainable Forecasting at Scale
Nov 29, 2021

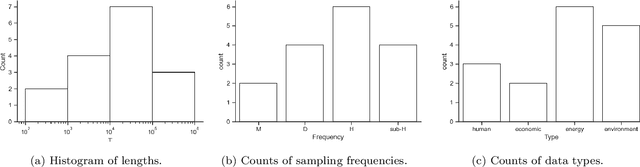
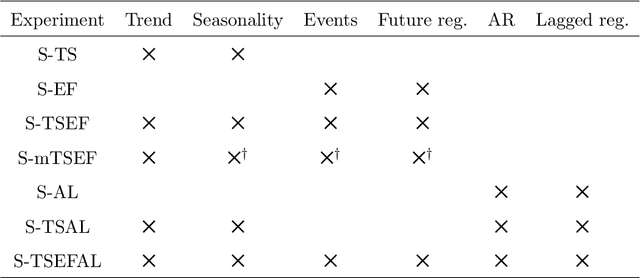
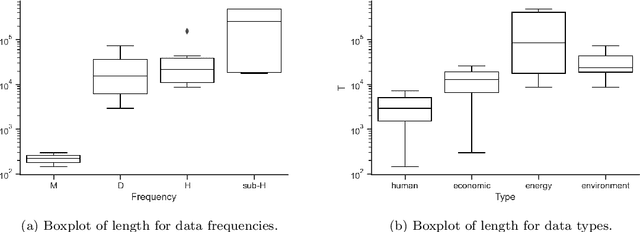
We introduce NeuralProphet, a successor to Facebook Prophet, which set an industry standard for explainable, scalable, and user-friendly forecasting frameworks. With the proliferation of time series data, explainable forecasting remains a challenging task for business and operational decision making. Hybrid solutions are needed to bridge the gap between interpretable classical methods and scalable deep learning models. We view Prophet as a precursor to such a solution. However, Prophet lacks local context, which is essential for forecasting the near-term future and is challenging to extend due to its Stan backend. NeuralProphet is a hybrid forecasting framework based on PyTorch and trained with standard deep learning methods, making it easy for developers to extend the framework. Local context is introduced with auto-regression and covariate modules, which can be configured as classical linear regression or as Neural Networks. Otherwise, NeuralProphet retains the design philosophy of Prophet and provides the same basic model components. Our results demonstrate that NeuralProphet produces interpretable forecast components of equivalent or superior quality to Prophet on a set of generated time series. NeuralProphet outperforms Prophet on a diverse collection of real-world datasets. For short to medium-term forecasts, NeuralProphet improves forecast accuracy by 55 to 92 percent.
Autonomous, Mobile Manipulation in a Wall-building Scenario: Team LARICS at MBZIRC 2020
Jan 28, 2022

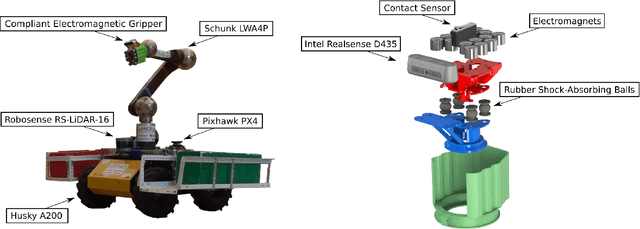
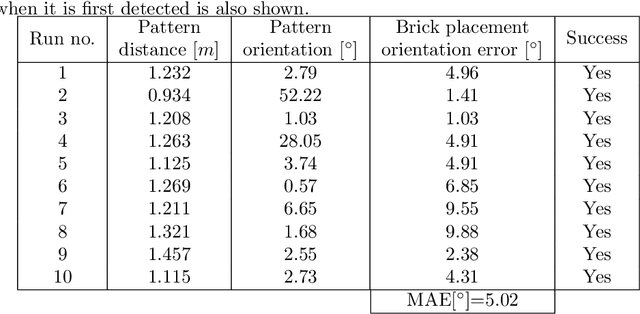
In this paper we present our hardware design and control approaches for a mobile manipulation platform used in Challenge 2 of the MBZIRC 2020 competition. In this challenge, a team of UAVs and a single UGV collaborate in an autonomous, wall-building scenario, motivated by construction automation and large-scale robotic 3D printing. The robots must be able, autonomously, to detect, manipulate, and transport bricks in an unstructured, outdoor environment. Our control approach is based on a state machine that dictates which controllers are active at each stage of the Challenge. In the first stage our UGV uses visual servoing and local controllers to approach the target object without considering its orientation. The second stage consists of detecting the object's global pose using OpenCV-based processing of RGB-D image and point-cloud data, and calculating an alignment goal within a global map. The map is built with Google Cartographer and is based on onboard LIDAR, IMU, and GPS data. Motion control in the second stage is realized using the ROS Move Base package with Time-Elastic Band trajectory optimization. Visual servo algorithms guide the vehicle in local object-approach movement and the arm in manipulating bricks. To ensure a stable grasp of the brick's magnetic patch, we developed a passively-compliant, electromagnetic gripper with tactile feedback. Our fully-autonomous UGV performed well in Challenge 2 and in post-competition evaluations of its brick pick-and-place algorithms.
Changepoint Analysis of Topic Proportions in Temporal Text Data
Nov 29, 2021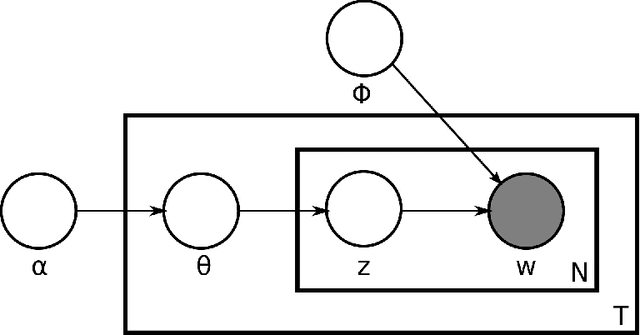
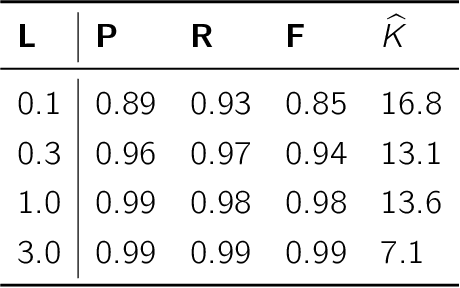
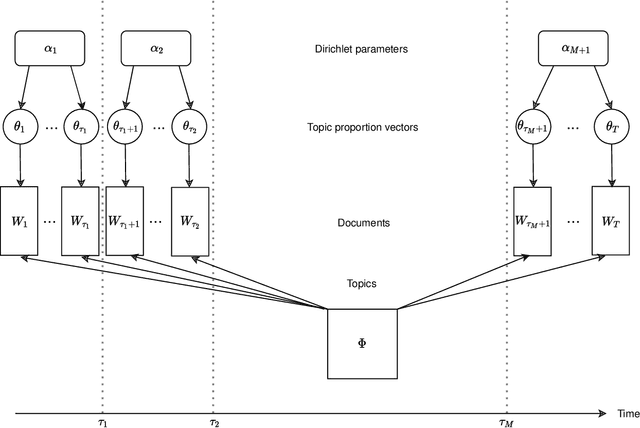
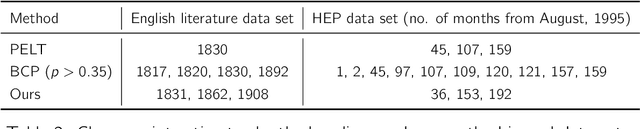
Changepoint analysis deals with unsupervised detection and/or estimation of time-points in time-series data, when the distribution generating the data changes. In this article, we consider \emph{offline} changepoint detection in the context of large scale textual data. We build a specialised temporal topic model with provisions for changepoints in the distribution of topic proportions. As full likelihood based inference in this model is computationally intractable, we develop a computationally tractable approximate inference procedure. More specifically, we use sample splitting to estimate topic polytopes first and then apply a likelihood ratio statistic together with a modified version of the wild binary segmentation algorithm of Fryzlewicz et al. (2014). Our methodology facilitates automated detection of structural changes in large corpora without the need of manual processing by domain experts. As changepoints under our model correspond to changes in topic structure, the estimated changepoints are often highly interpretable as marking the surge or decline in popularity of a fashionable topic. We apply our procedure on two large datasets: (i) a corpus of English literature from the period 1800-1922 (Underwoodet al., 2015); (ii) abstracts from the High Energy Physics arXiv repository (Clementet al., 2019). We obtain some historically well-known changepoints and discover some new ones.
GOSH: Task Scheduling Using Deep Surrogate Models in Fog Computing Environments
Dec 16, 2021
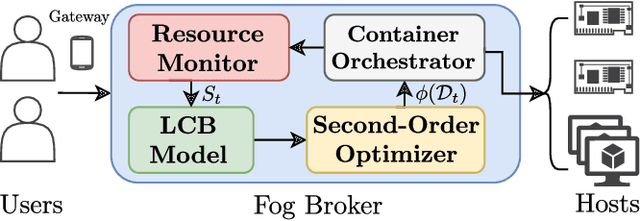
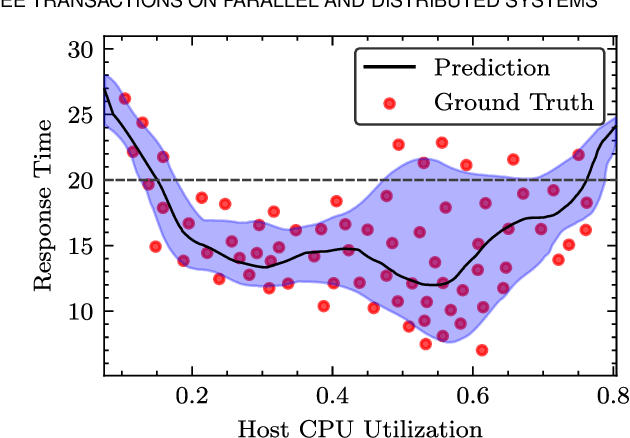
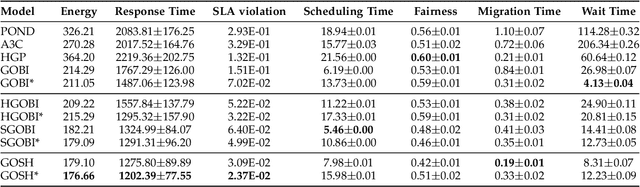
Recently, intelligent scheduling approaches using surrogate models have been proposed to efficiently allocate volatile tasks in heterogeneous fog environments. Advances like deterministic surrogate models, deep neural networks (DNN) and gradient-based optimization allow low energy consumption and response times to be reached. However, deterministic surrogate models, which estimate objective values for optimization, do not consider the uncertainties in the distribution of the Quality of Service (QoS) objective function that can lead to high Service Level Agreement (SLA) violation rates. Moreover, the brittle nature of DNN training and prevent such models from reaching minimal energy or response times. To overcome these difficulties, we present a novel scheduler: GOSH i.e. Gradient Based Optimization using Second Order derivatives and Heteroscedastic Deep Surrogate Models. GOSH uses a second-order gradient based optimization approach to obtain better QoS and reduce the number of iterations to converge to a scheduling decision, subsequently lowering the scheduling time. Instead of a vanilla DNN, GOSH uses a Natural Parameter Network to approximate objective scores. Further, a Lower Confidence Bound optimization approach allows GOSH to find an optimal trade-off between greedy minimization of the mean latency and uncertainty reduction by employing error-based exploration. Thus, GOSH and its co-simulation based extension GOSH*, can adapt quickly and reach better objective scores than baseline methods. We show that GOSH* reaches better objective scores than GOSH, but it is suitable only for high resource availability settings, whereas GOSH is apt for limited resource settings. Real system experiments for both GOSH and GOSH* show significant improvements against the state-of-the-art in terms of energy consumption, response time and SLA violations by up to 18, 27 and 82 percent, respectively.
Detection of fake faces in videos
Jan 28, 2022
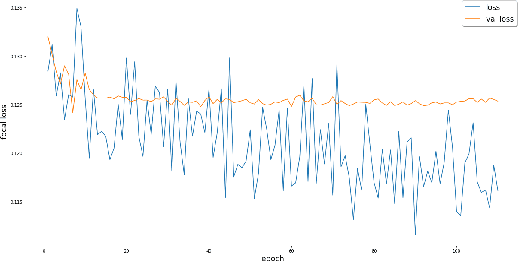
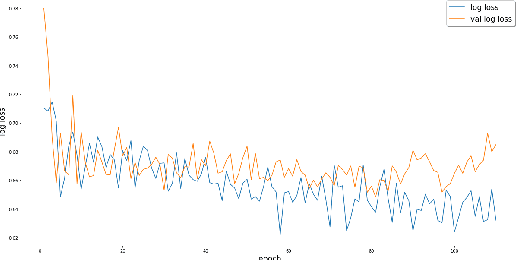

: Deep learning methodologies have been used to create applications that can cause threats to privacy, democracy and national security and could be used to further amplify malicious activities. One of those deep learning-powered applications in recent times is synthesized videos of famous personalities. According to Forbes, Generative Adversarial Networks(GANs) generated fake videos growing exponentially every year and the organization known as Deeptrace had estimated an increase of deepfakes by 84% from the year 2018 to 2019. They are used to generate and modify human faces, where most of the existing fake videos are of prurient non-consensual nature, of which its estimates to be around 96% and some carried out impersonating personalities for cyber crime. In this paper, available video datasets are identified and a pretrained model BlazeFace is used to detect faces, and a ResNet and Xception ensembled architectured neural network trained on the dataset to achieve the goal of detection of fake faces in videos. The model is optimized over a loss value and log loss values and evaluated over its F1 score. Over a sample of data, it is observed that focal loss provides better accuracy, F1 score and loss as the gamma of the focal loss becomes a hyper parameter. This provides a k-folded accuracy of around 91% at its peak in a training cycle with the real world accuracy subjected to change over time as the model decays.
Neural Fields in Visual Computing and Beyond
Nov 29, 2021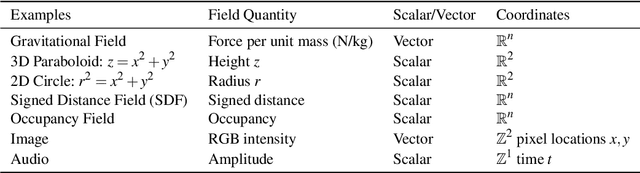
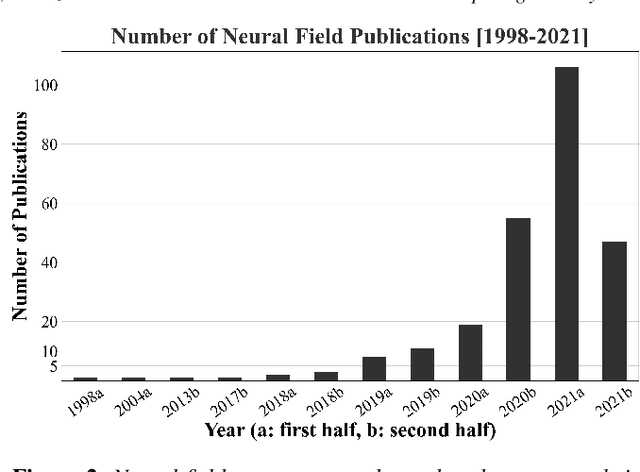

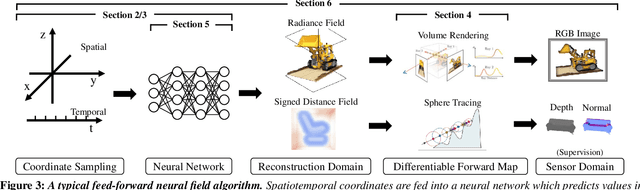
Recent advances in machine learning have created increasing interest in solving visual computing problems using a class of coordinate-based neural networks that parametrize physical properties of scenes or objects across space and time. These methods, which we call neural fields, have seen successful application in the synthesis of 3D shapes and image, animation of human bodies, 3D reconstruction, and pose estimation. However, due to rapid progress in a short time, many papers exist but a comprehensive review and formulation of the problem has not yet emerged. In this report, we address this limitation by providing context, mathematical grounding, and an extensive review of literature on neural fields. This report covers research along two dimensions. In Part I, we focus on techniques in neural fields by identifying common components of neural field methods, including different representations, architectures, forward mapping, and generalization methods. In Part II, we focus on applications of neural fields to different problems in visual computing, and beyond (e.g., robotics, audio). Our review shows the breadth of topics already covered in visual computing, both historically and in current incarnations, demonstrating the improved quality, flexibility, and capability brought by neural fields methods. Finally, we present a companion website that contributes a living version of this review that can be continually updated by the community.
Quick Streaming Algorithms for Maximization of Monotone Submodular Functions in Linear Time
Sep 10, 2020
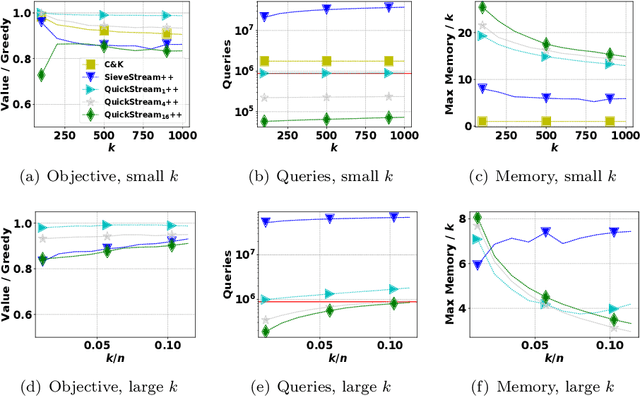
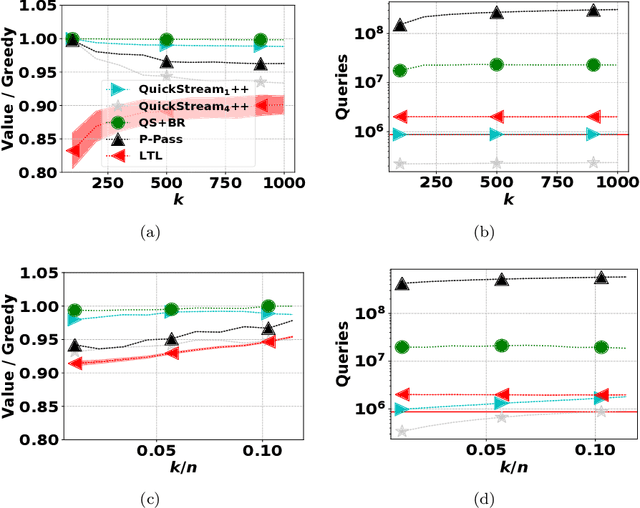
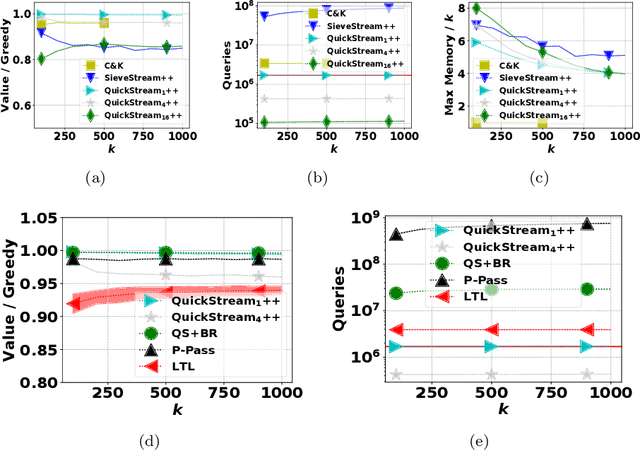
We consider the problem of monotone, submodular maximization over a ground set of size $n$ subject to cardinality constraint $k$. For this problem, we introduce streaming algorithms with linearquery complexity and linear number of arithmetic operations; these algorithms are the first deterministic algorithms for submodular maximization that require a linear number of arithmetic operations. Specifically, for any $c \ge 1, \epsilon > 0$, we propose a single-pass, deterministic streaming algorithm with ratio $1/(4c)-\epsilon$, query complexity $\lceil n / c \rceil + c$, memory complexity $O(k \log k)$, and $O(n)$ total running time. As $k \to \infty$, the ratio converges to $(1 - 1/e)/(c + 1)$. In addition, we propose a deterministic, multi-pass streaming algorithm with $O(1 / \epsilon)$ passes that achieves ratio $1-1/e - \epsilon$ in $O(n/\epsilon)$ queries, $O(k \log (k))$ memory, and $O(n)$ time. We prove a lower bound that implies no constant-factor approximation exists using $o(n)$ queries, even if queries to infeasible sets are allowed. An experimental analysis demonstrates that our algorithms require fewer queries (often substantially less than $n$) to achieve better objective value than the current state-of-the-art algorithms.
An Artificial Intelligence Dataset for Solar Energy Locations in India
Jan 31, 2022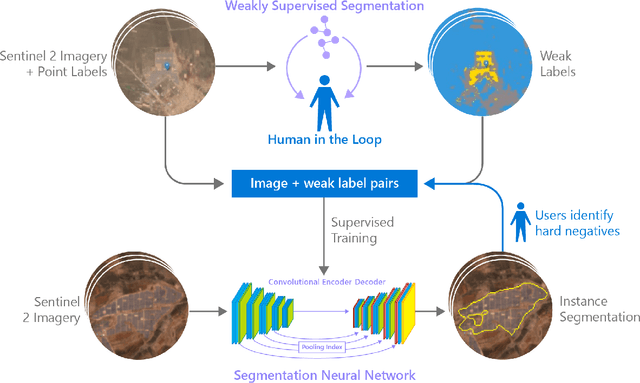
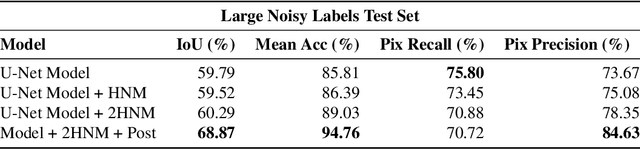


Rapid development of renewable energy sources, particularly solar photovoltaics, is critical to mitigate climate change. As a result, India has set ambitious goals to install 300 gigawatts of solar energy capacity by 2030. Given the large footprint projected to meet these renewable energy targets the potential for land use conflicts over environmental and social values is high. To expedite development of solar energy, land use planners will need access to up-to-date and accurate geo-spatial information of PV infrastructure. The majority of recent studies use either predictions of resource suitability or databases that are either developed thru crowdsourcing that often have significant sampling biases or have time lags between when projects are permitted and when location data becomes available. Here, we address this shortcoming by developing a spatially explicit machine learning model to map utility-scale solar projects across India. Using these outputs, we provide a cumulative measure of the solar footprint across India and quantified the degree of land modification associated with land cover types that may cause conflicts. Our analysis indicates that over 74\% of solar development In India was built on landcover types that have natural ecosystem preservation, and agricultural values. Thus, with a mean accuracy of 92\% this method permits the identification of the factors driving land suitability for solar projects and will be of widespread interest for studies seeking to assess trade-offs associated with the global decarbonization of green-energy systems. In the same way, our model increases the feasibility of remote sensing and long-term monitoring of renewable energy deployment targets.
An EEG-based approach for Parkinson's disease diagnosis using Capsule network
Dec 27, 2021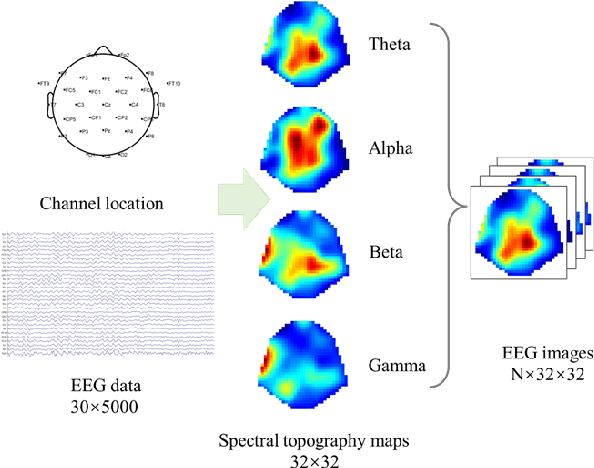
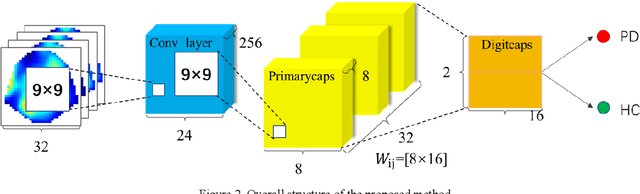
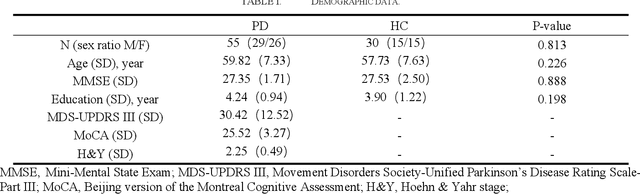
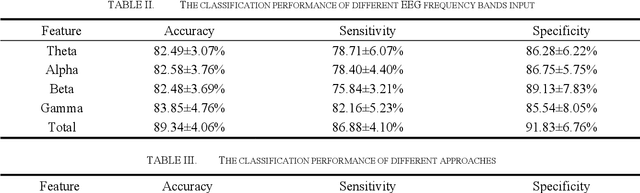
As the second most common neurodegenerative disease, Parkinson's disease has caused serious problems worldwide. However, the cause and mechanism of PD are not clear, and no systematic early diagnosis and treatment of PD have been established, many patients with PD have not been diagnosed or misdiagnosed. In this paper, we proposed an EEG-based approach to diagnosing Parkinson's disease, it mapping the frequency band energy of EEG signals to 2-dimensional images using the interpolation method and identifying classification using CapsNet, achieved 89.34% classification accuracy for short-time EEG sections, which exceeds the conventional SVM model.A comparison of separate classification accuracy across different EEG bands revealed the highest accuracy in the gamma bands, suggesting that we need pay more attention to the changes in gamma band changes in the early stages of PD.
Subexponential-Time Algorithms for Sparse PCA
Jul 26, 2019We study the computational cost of recovering a unit-norm sparse principal component $x \in \mathbb{R}^n$ planted in a random matrix, in either the Wigner or Wishart spiked model (observing either $W + \lambda xx^\top$ with $W$ drawn from the Gaussian orthogonal ensemble, or $N$ independent samples from $\mathcal{N}(0, I_n + \beta xx^\top)$, respectively). Prior work has shown that when the signal-to-noise ratio ($\lambda$ or $\beta\sqrt{N/n}$, respectively) is a small constant and the fraction of nonzero entries in the planted vector is $\|x\|_0 / n = \rho$, it is possible to recover $x$ in polynomial time if $\rho \lesssim 1/\sqrt{n}$. While it is possible to recover $x$ in exponential time under the weaker condition $\rho \ll 1$, it is believed that polynomial-time recovery is impossible unless $\rho \lesssim 1/\sqrt{n}$. We investigate the precise amount of time required for recovery in the "possible but hard" regime $1/\sqrt{n} \ll \rho \ll 1$ by exploring the power of subexponential-time algorithms, i.e., algorithms running in time $\exp(n^\delta)$ for some constant $\delta \in (0,1)$. For any $1/\sqrt{n} \ll \rho \ll 1$, we give a recovery algorithm with runtime roughly $\exp(\rho^2 n)$, demonstrating a smooth tradeoff between sparsity and runtime. Our family of algorithms interpolates smoothly between two existing algorithms: the polynomial-time diagonal thresholding algorithm and the $\exp(\rho n)$-time exhaustive search algorithm. Furthermore, by analyzing the low-degree likelihood ratio, we give rigorous evidence suggesting that the tradeoff achieved by our algorithms is optimal.