 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spherical Convolution empowered FoV Prediction in 360-degree Video Multicast with Limited FoV Feedback
Jan 29, 2022
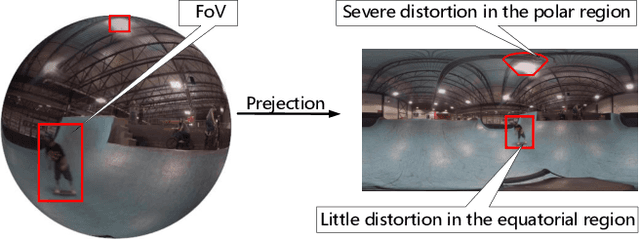

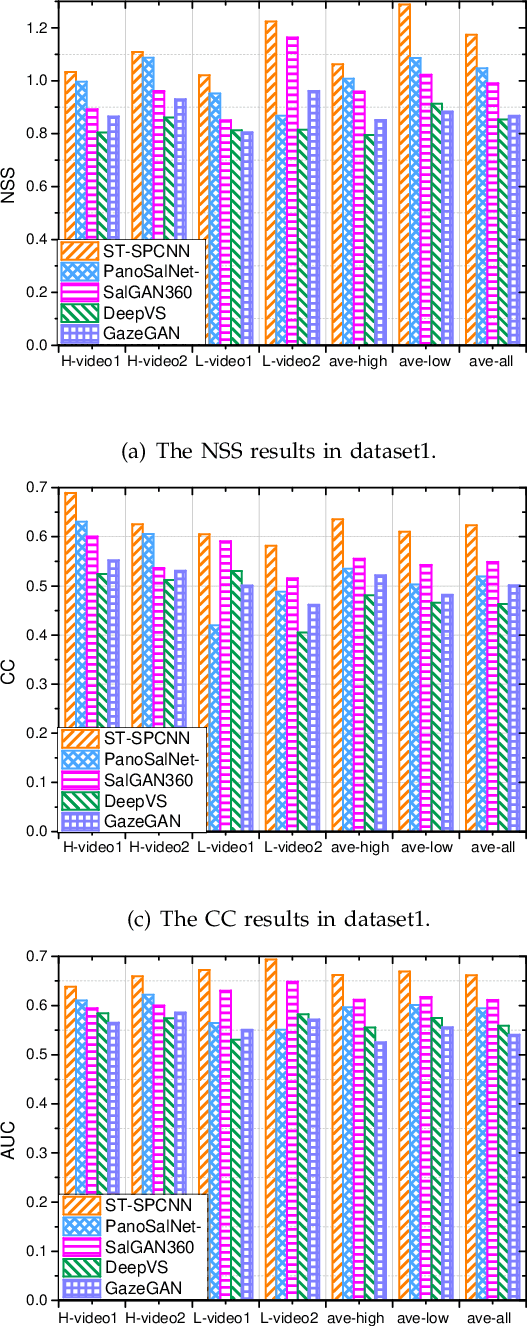
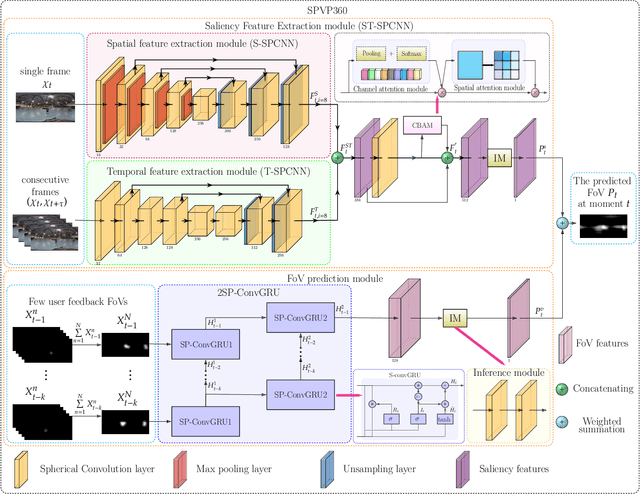
Field of view (FoV) prediction is critical in 360-degree video multicast, which is a key component of the emerging Virtual Reality (VR) and Augmented Reality (AR) applications. Most of the current prediction methods combining saliency detection and FoV information neither take into account that the distortion of projected 360-degree videos can invalidate the weight sharing of traditional convolutional networks, nor do they adequately consider the difficulty of obtaining complete multi-user FoV information, which degrades the prediction performance. This paper proposes a spherical convolution-empowered FoV prediction method, which is a multi-source prediction framework combining salient features extracted from 360-degree video with limited FoV feedback information. A spherical convolution neural network (CNN) is used instead of a traditional two-dimensional CNN to eliminate the problem of weight sharing failure caused by video projection distortion. Specifically, salient spatial-temporal features are extracted through a spherical convolution-based saliency detection model, after which the limited feedback FoV information is represented as a time-series model based on a spherical convolution-empowered gated recurrent unit network. Finally, the extracted salient video features are combined to predict future user FoVs. The experimental results show that the performance of the proposed method is better than other prediction methods.
Reliable Probability Intervals For Classification Using Inductive Venn Predictors Based on Distance Learning
Oct 07, 2021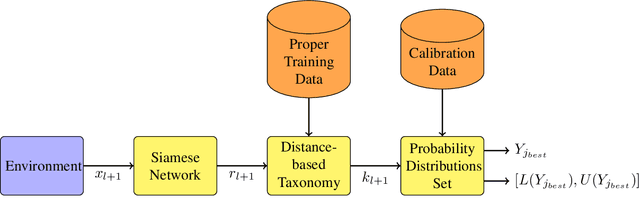
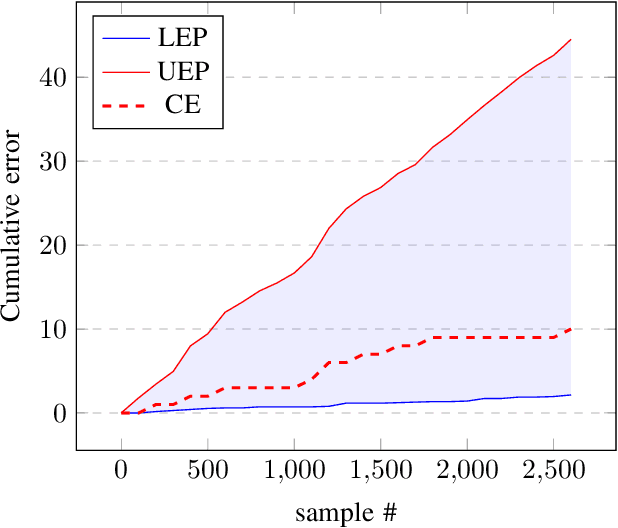

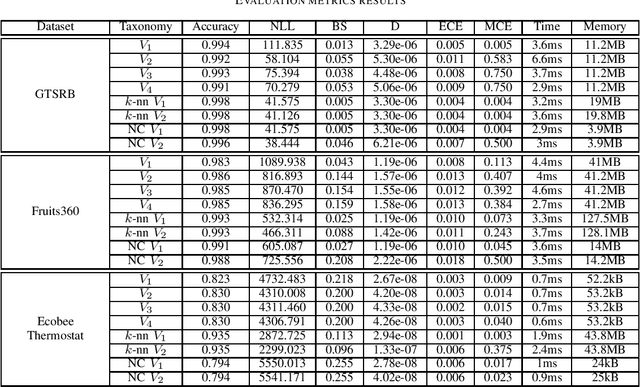
Deep neural networks are frequently used by autonomous systems for their ability to learn complex, non-linear data patterns and make accurate predictions in dynamic environments. However, their use as black boxes introduces risks as the confidence in each prediction is unknown. Different frameworks have been proposed to compute accurate confidence measures along with the predictions but at the same time introduce a number of limitations like execution time overhead or inability to be used with high-dimensional data. In this paper, we use the Inductive Venn Predictors framework for computing probability intervals regarding the correctness of each prediction in real-time. We propose taxonomies based on distance metric learning to compute informative probability intervals in applications involving high-dimensional inputs. Empirical evaluation on image classification and botnet attacks detection in Internet-of-Things (IoT) applications demonstrates improved accuracy and calibration. The proposed method is computationally efficient, and therefore, can be used in real-time.
* Published in IEEE International Conference on Omni-Layer Intelligent Systems (COINS), 2021
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 16, 2022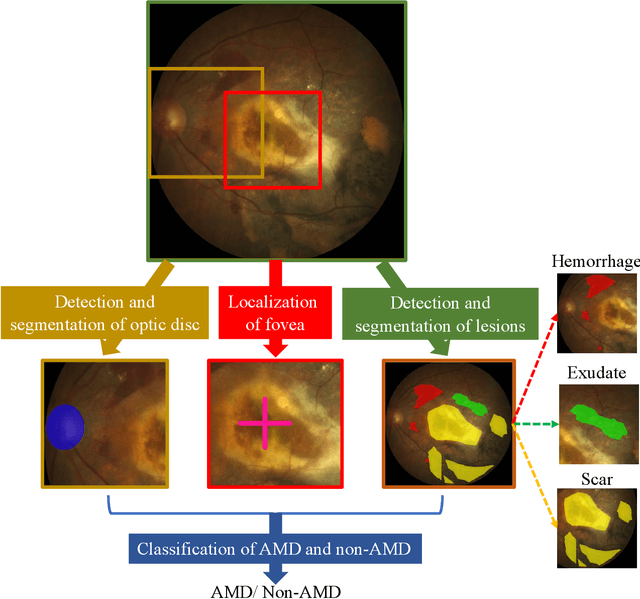

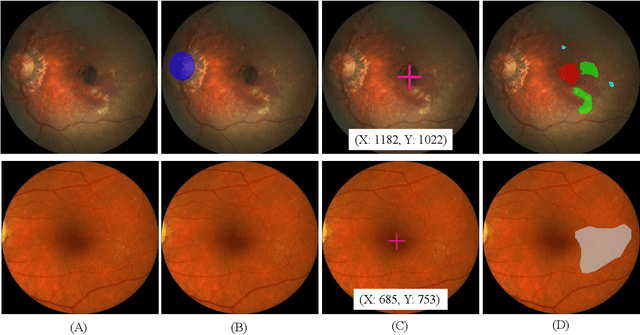
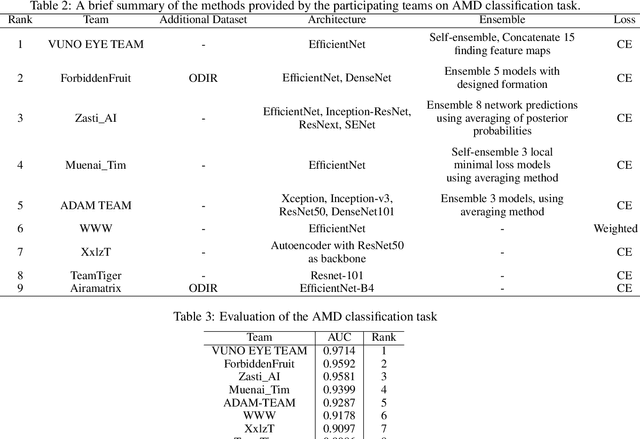
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
Machine learning time series regressions with an application to nowcasting
May 28, 2020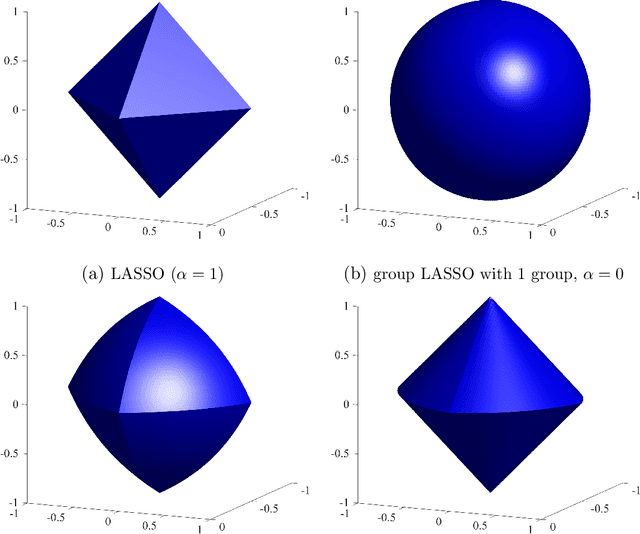

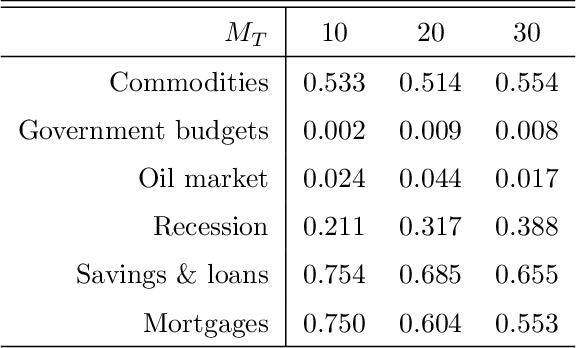
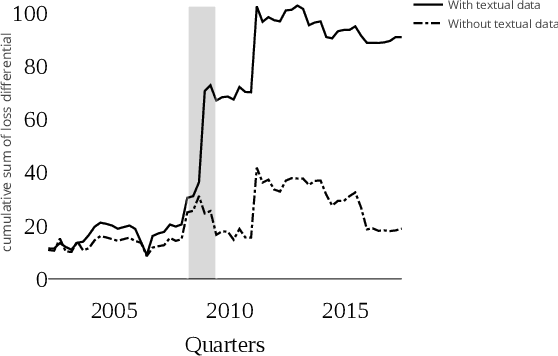
This paper introduces structured machine learning regressions for high-dimensional time series data potentially sampled at different frequencies. The sparse-group LASSO estimator can take advantage of such time series data structures and outperforms the unstructured LASSO. We establish oracle inequalities for the sparse-group LASSO estimator within a framework that allows for the mixing processes and recognizes that the financial and the macroeconomic data may have heavier than exponential tails. An empirical application to nowcasting US GDP growth indicates that the estimator performs favorably compared to other alternatives and that the text data can be a useful addition to more traditional numerical data.
Explaining Naive Bayes and Other Linear Classifiers with Polynomial Time and Delay
Aug 13, 2020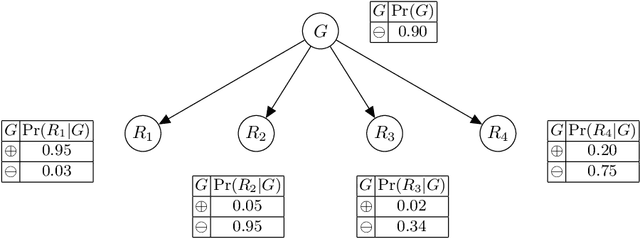
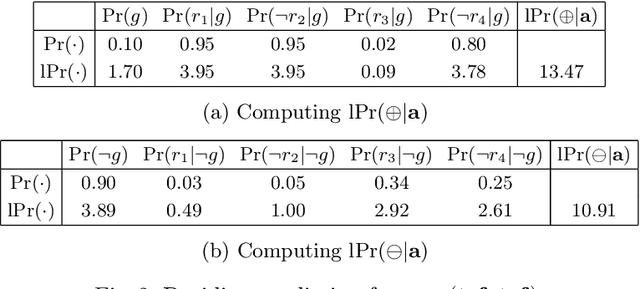
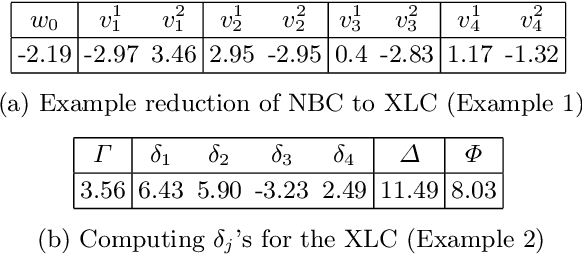
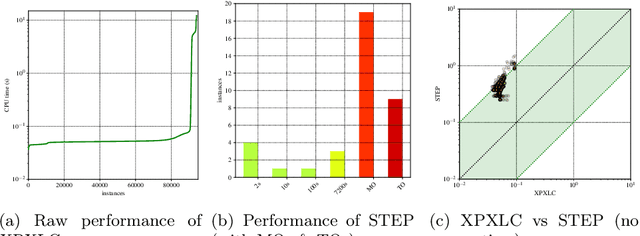
Recent work proposed the computation of so-called PI-explanations of Naive Bayes Classifiers (NBCs). PI-explanations are subset-minimal sets of feature-value pairs that are sufficient for the prediction, and have been computed with state-of-the-art exact algorithms that are worst-case exponential in time and space. In contrast, we show that the computation of one PI-explanation for an NBC can be achieved in log-linear time, and that the same result also applies to the more general class of linear classifiers. Furthermore, we show that the enumeration of PI-explanations can be obtained with polynomial delay. Experimental results demonstrate the performance gains of the new algorithms when compared with earlier work. The experimental results also investigate ways to measure the quality of heuristic explanations
Coarsening the Granularity: Towards Structurally Sparse Lottery Tickets
Feb 09, 2022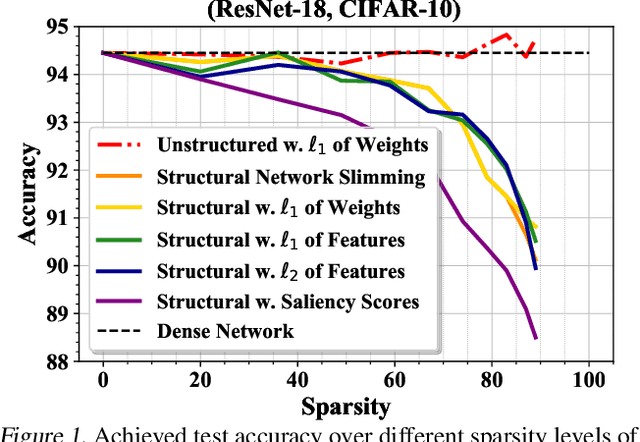
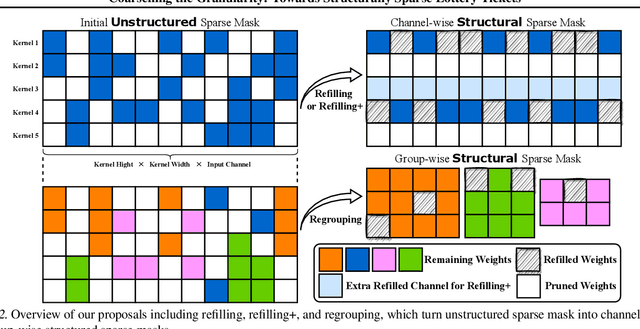
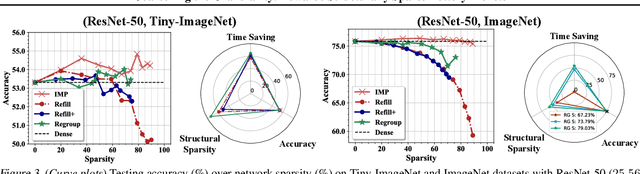
The lottery ticket hypothesis (LTH) has shown that dense models contain highly sparse subnetworks (i.e., winning tickets) that can be trained in isolation to match full accuracy. Despite many exciting efforts being made, there is one "commonsense" seldomly challenged: a winning ticket is found by iterative magnitude pruning (IMP) and hence the resultant pruned subnetworks have only unstructured sparsity. That gap limits the appeal of winning tickets in practice, since the highly irregular sparse patterns are challenging to accelerate on hardware. Meanwhile, directly substituting structured pruning for unstructured pruning in IMP damages performance more severely and is usually unable to locate winning tickets. In this paper, we demonstrate the first positive result that a structurally sparse winning ticket can be effectively found in general. The core idea is to append "post-processing techniques" after each round of (unstructured) IMP, to enforce the formation of structural sparsity. Specifically, we first "re-fill" pruned elements back in some channels deemed to be important, and then "re-group" non-zero elements to create flexible group-wise structural patterns. Both our identified channel- and group-wise structural subnetworks win the lottery, with substantial inference speedups readily supported by existing hardware. Extensive experiments, conducted on diverse datasets across multiple network backbones, consistently validate our proposal, showing that the hardware acceleration roadblock of LTH is now removed. Specifically, the structural winning tickets obtain up to {64.93%, 64.84%, 64.84%} running time savings at {36% ~ 80%, 74%, 58%} sparsity on {CIFAR, Tiny-ImageNet, ImageNet}, while maintaining comparable accuracy. Codes are available in https://github.com/VITA-Group/Structure-LTH.
FastSGD: A Fast Compressed SGD Framework for Distributed Machine Learning
Dec 08, 2021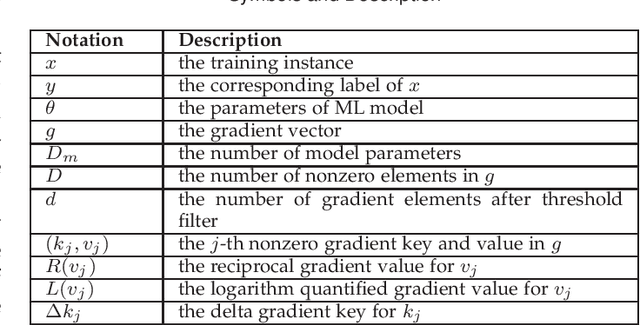
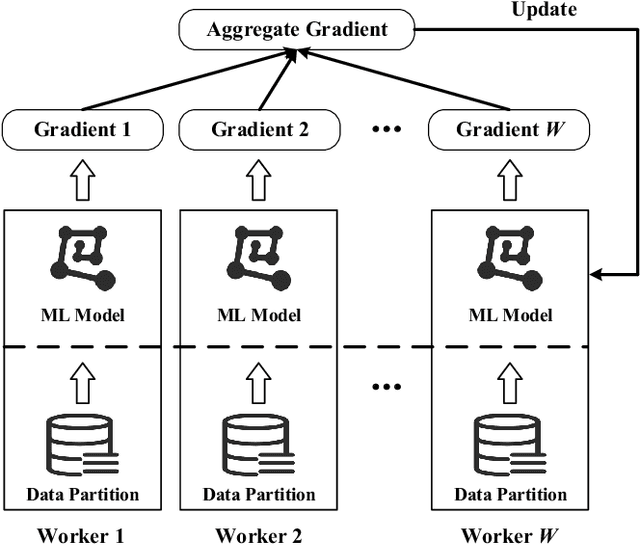
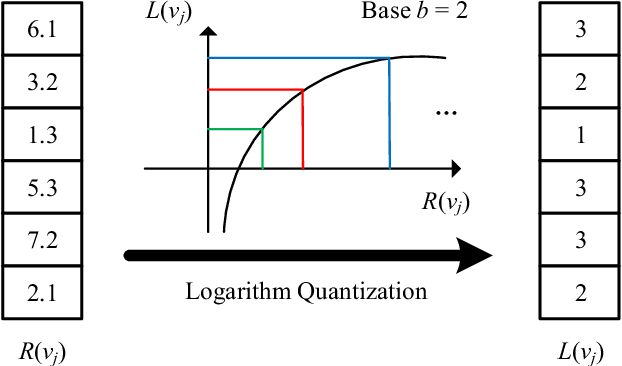
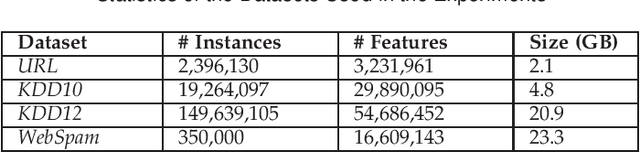
With the rapid increase of big data, distributed Machine Learning (ML) has been widely applied in training large-scale models. Stochastic Gradient Descent (SGD) is arguably the workhorse algorithm of ML. Distributed ML models trained by SGD involve large amounts of gradient communication, which limits the scalability of distributed ML. Thus, it is important to compress the gradients for reducing communication. In this paper, we propose FastSGD, a Fast compressed SGD framework for distributed ML. To achieve a high compression ratio at a low cost, FastSGD represents the gradients as key-value pairs, and compresses both the gradient keys and values in linear time complexity. For the gradient value compression, FastSGD first uses a reciprocal mapper to transform original values into reciprocal values, and then, it utilizes a logarithm quantization to further reduce reciprocal values to small integers. Finally, FastSGD filters reduced gradient integers by a given threshold. For the gradient key compression, FastSGD provides an adaptive fine-grained delta encoding method to store gradient keys with fewer bits. Extensive experiments on practical ML models and datasets demonstrate that FastSGD achieves the compression ratio up to 4 orders of magnitude, and accelerates the convergence time up to 8x, compared with state-of-the-art methods.
StAnD: A Dataset of Linear Static Analysis Problems
Jan 14, 2022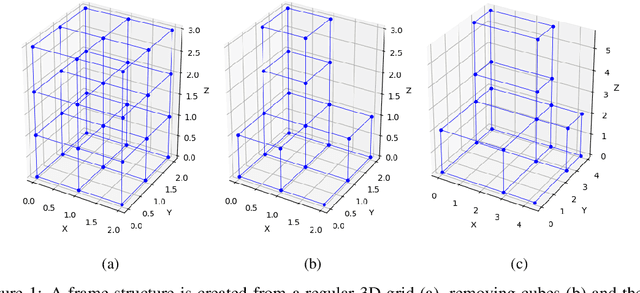

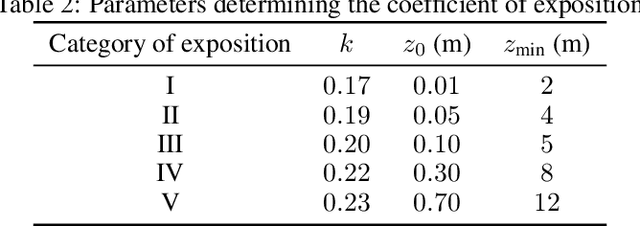
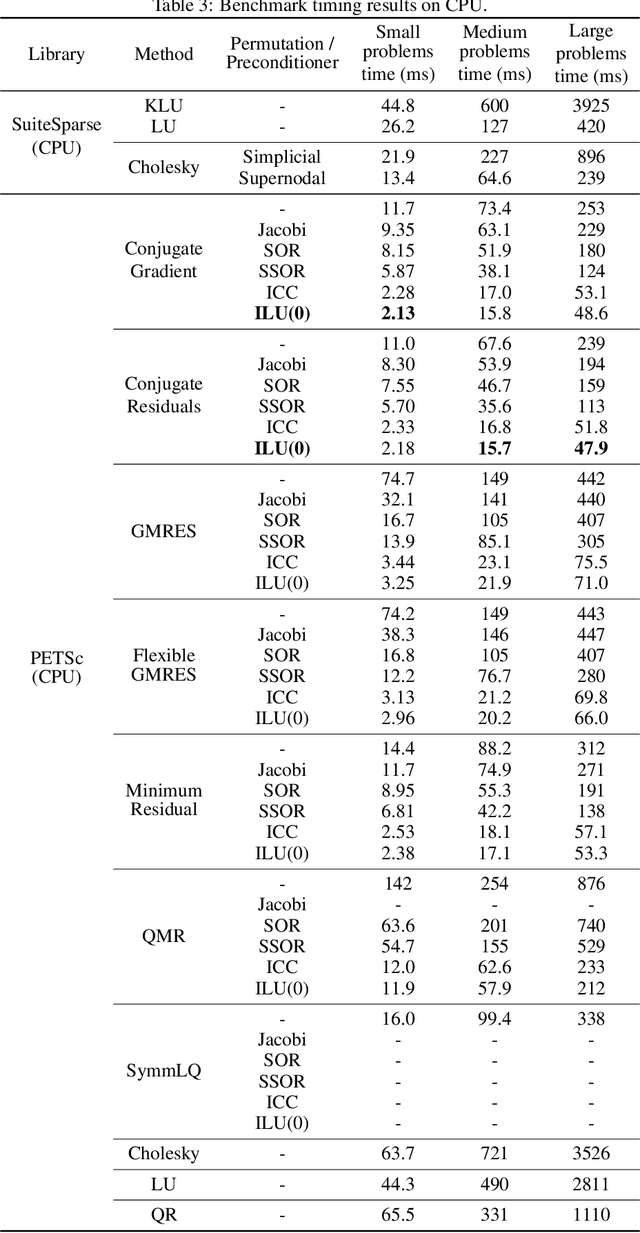
Static analysis of structures is a fundamental step for determining the stability of structures. Both linear and non-linear static analyses consist of the resolution of sparse linear systems obtained by the finite element method. The development of fast and optimized solvers for sparse linear systems appearing in structural engineering requires data to compare existing approaches, tune algorithms or to evaluate new ideas. We introduce the Static Analysis Dataset (StAnD) containing 303.000 static analysis problems obtained applying realistic loads to simulated frame structures. Along with the dataset, we publish a detailed benchmark comparison of the running time of existing solvers both on CPU and GPU. We release the code used to generate the dataset and benchmark existing solvers on Github. To the best of our knowledge, this is the largest dataset for static analysis problems and it is the first public dataset of sparse linear systems (containing both the matrix and a realistic constant term).
Revisiting Global Statistics Aggregation for Improving Image Restoration
Dec 08, 2021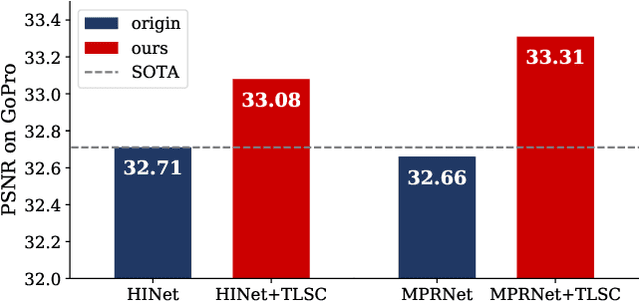
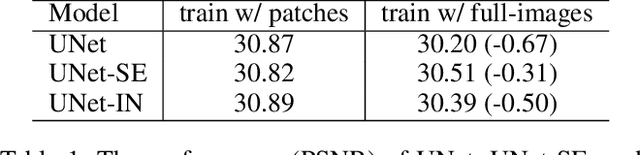
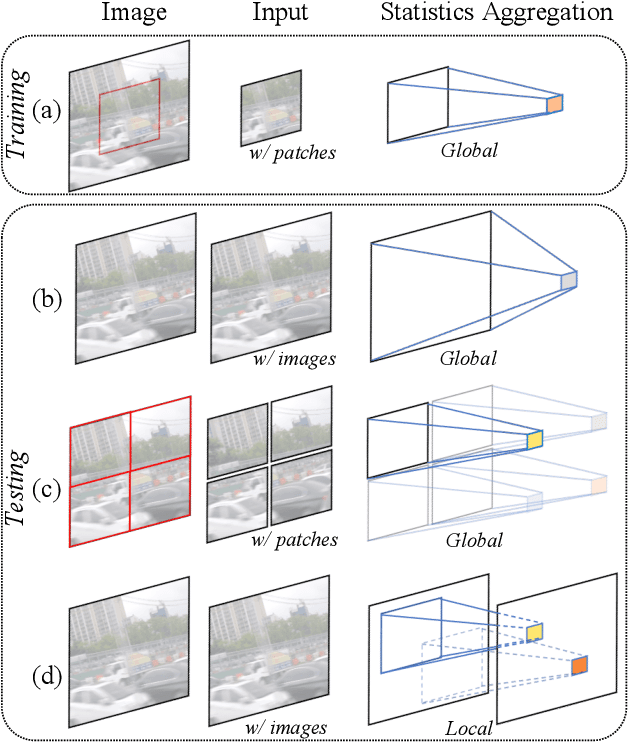
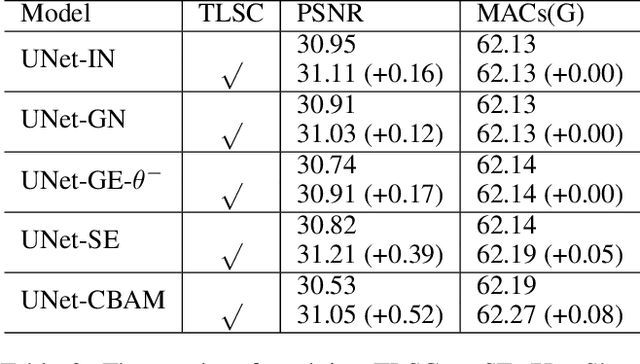
Global spatial statistics, which are aggregated along entire spatial dimensions, are widely used in top-performance image restorers. For example, mean, variance in Instance Normalization (IN) which is adopted by HINet, and global average pooling (i.e. mean) in Squeeze and Excitation (SE) which is applied to MPRNet. This paper first shows that statistics aggregated on the patches-based/entire-image-based feature in the training/testing phase respectively may distribute very differently and lead to performance degradation in image restorers. It has been widely overlooked by previous works. To solve this issue, we propose a simple approach, Test-time Local Statistics Converter (TLSC), that replaces the region of statistics aggregation operation from global to local, only in the test time. Without retraining or finetuning, our approach significantly improves the image restorer's performance. In particular, by extending SE with TLSC to the state-of-the-art models, MPRNet boost by 0.65 dB in PSNR on GoPro dataset, achieves 33.31 dB, exceeds the previous best result 0.6 dB. In addition, we simply apply TLSC to the high-level vision task, i.e. semantic segmentation, and achieves competitive results. Extensive quantity and quality experiments are conducted to demonstrate TLSC solves the issue with marginal costs while significant gain. The code is available at https://github.com/megvii-research/tlsc.
Online AutoML: An adaptive AutoML framework for online learning
Jan 24, 2022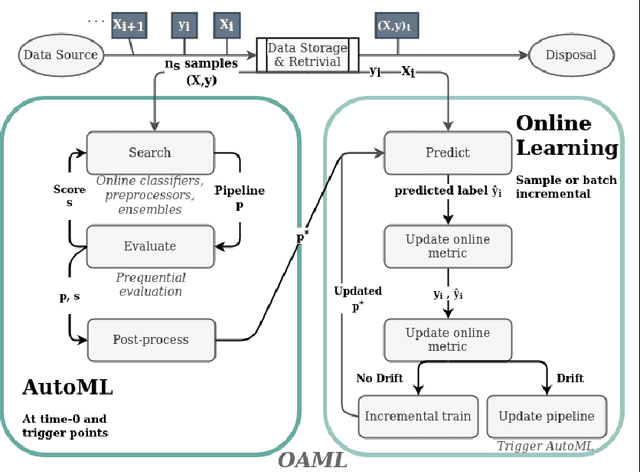
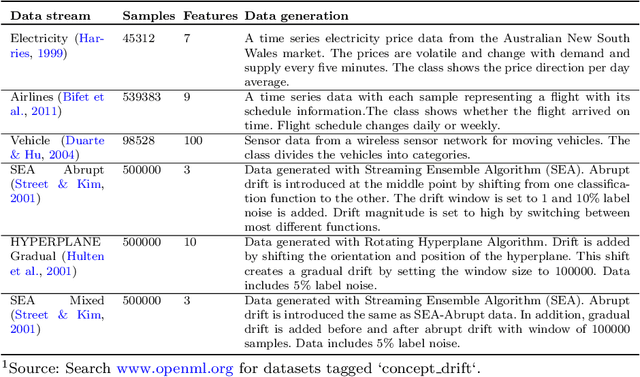
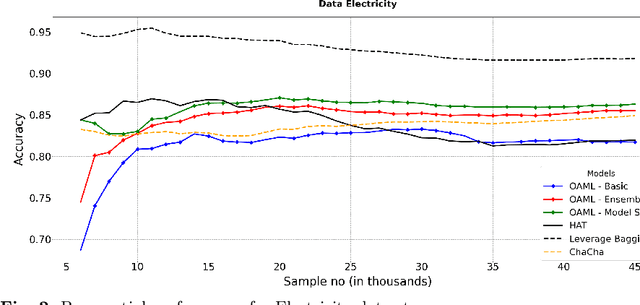
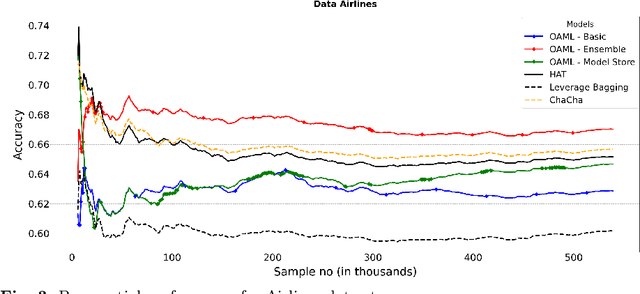
Automated Machine Learning (AutoML) has been used successfully in settings where the learning task is assumed to be static. In many real-world scenarios, however, the data distribution will evolve over time, and it is yet to be shown whether AutoML techniques can effectively design online pipelines in dynamic environments. This study aims to automate pipeline design for online learning while continuously adapting to data drift. For this purpose, we design an adaptive Online Automated Machine Learning (OAML) system, searching the complete pipeline configuration space of online learners, including preprocessing algorithms and ensembling techniques. This system combines the inherent adaptation capabilities of online learners with the fast automated pipeline (re)optimization capabilities of AutoML. Focusing on optimization techniques that can adapt to evolving objectives, we evaluate asynchronous genetic programming and asynchronous successive halving to optimize these pipelines continually. We experiment on real and artificial data streams with varying types of concept drift to test the performance and adaptation capabilities of the proposed system. The results confirm the utility of OAML over popular online learning algorithms and underscore the benefits of continuous pipeline redesign in the presence of data drift.