 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model, sample, and epoch-wise descents: exact solution of gradient flow in the random feature model
Oct 22, 2021
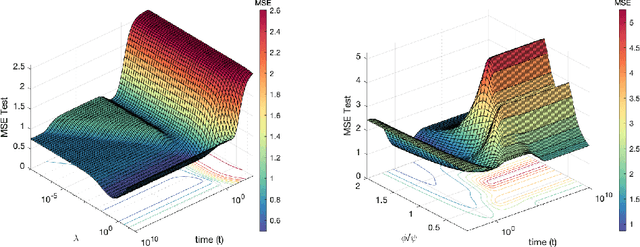
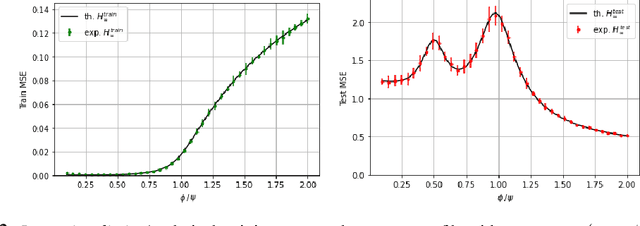
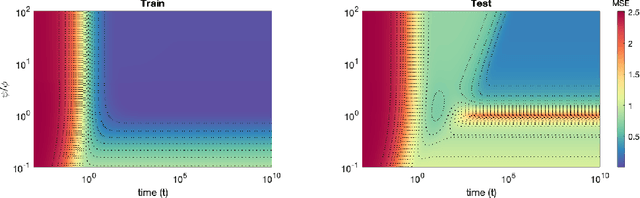
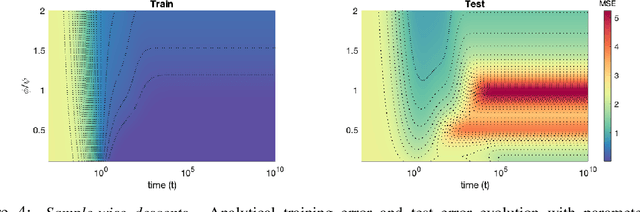
Recent evidence has shown the existence of a so-called double-descent and even triple-descent behavior for the generalization error of deep-learning models. This important phenomenon commonly appears in implemented neural network architectures, and also seems to emerge in epoch-wise curves during the training process. A recent line of research has highlighted that random matrix tools can be used to obtain precise analytical asymptotics of the generalization (and training) errors of the random feature model. In this contribution, we analyze the whole temporal behavior of the generalization and training errors under gradient flow for the random feature model. We show that in the asymptotic limit of large system size the full time-evolution path of both errors can be calculated analytically. This allows us to observe how the double and triple descents develop over time, if and when early stopping is an option, and also observe time-wise descent structures. Our techniques are based on Cauchy complex integral representations of the errors together with recent random matrix methods based on linear pencils.
Exploring the Impact of Virtualization on the Usability of the Deep Learning Applications
Dec 17, 2021
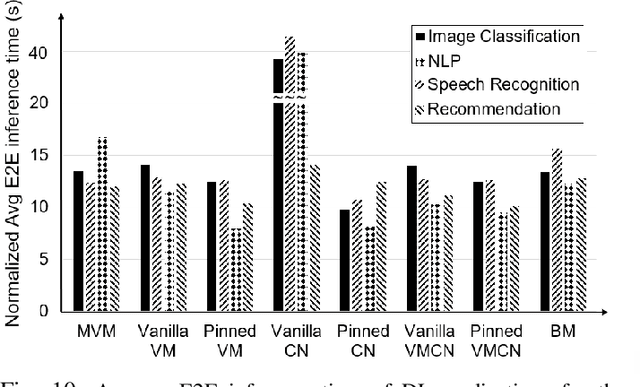
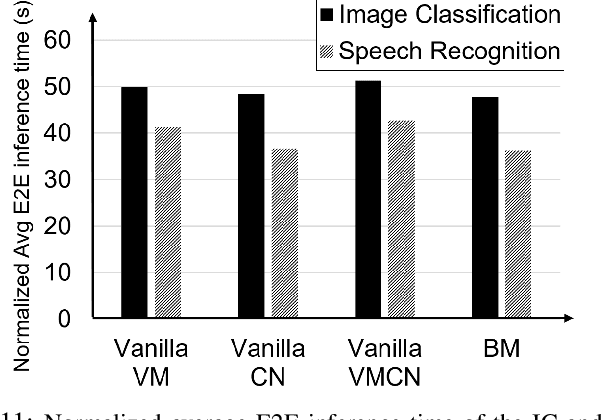
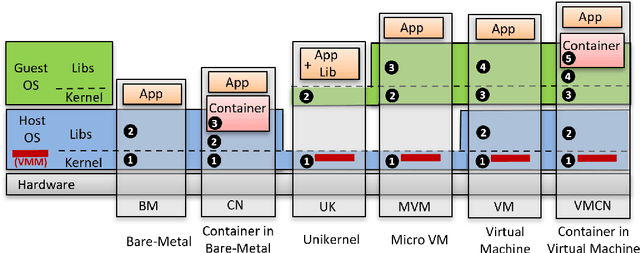
Deep Learning-based (DL) applications are becoming increasingly popular and advancing at an unprecedented pace. While many research works are being undertaken to enhance Deep Neural Networks (DNN) -- the centerpiece of DL applications -- practical deployment challenges of these applications in the Cloud and Edge systems, and their impact on the usability of the applications have not been sufficiently investigated. In particular, the impact of deploying different virtualization platforms, offered by the Cloud and Edge, on the usability of DL applications (in terms of the End-to-End (E2E) inference time) has remained an open question. Importantly, resource elasticity (by means of scale-up), CPU pinning, and processor type (CPU vs GPU) configurations have shown to be influential on the virtualization overhead. Accordingly, the goal of this research is to study the impact of these potentially decisive deployment options on the E2E performance, thus, usability of the DL applications. To that end, we measure the impact of four popular execution platforms (namely, bare-metal, virtual machine (VM), container, and container in VM) on the E2E inference time of four types of DL applications, upon changing processor configuration (scale-up, CPU pinning) and processor types. This study reveals a set of interesting and sometimes counter-intuitive findings that can be used as best practices by Cloud solution architects to efficiently deploy DL applications in various systems. The notable finding is that the solution architects must be aware of the DL application characteristics, particularly, their pre- and post-processing requirements, to be able to optimally choose and configure an execution platform, determine the use of GPU, and decide the efficient scale-up range.
TEGDetector: A Phishing Detector that Knows Evolving Transaction Behaviors
Nov 26, 2021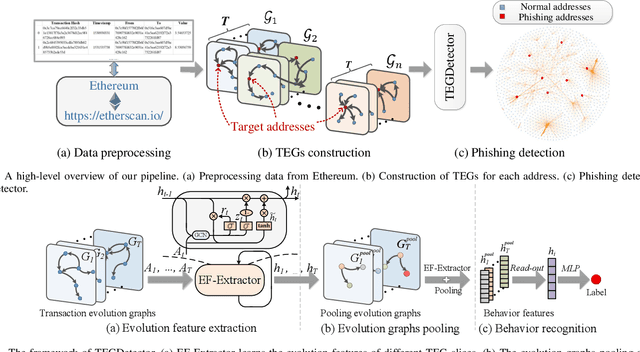
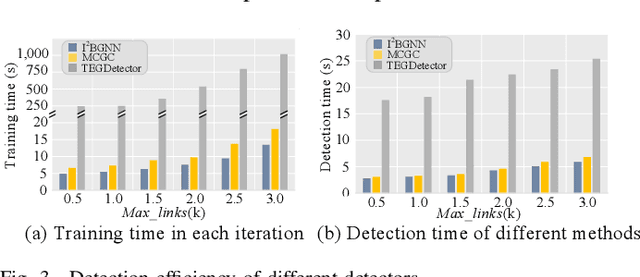
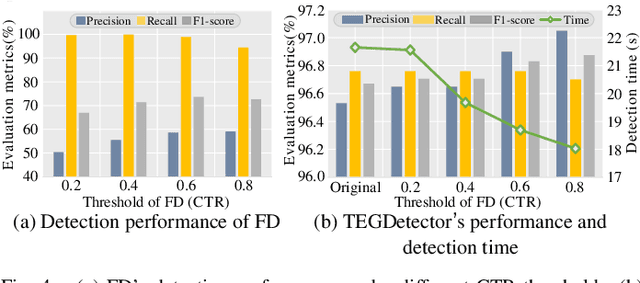
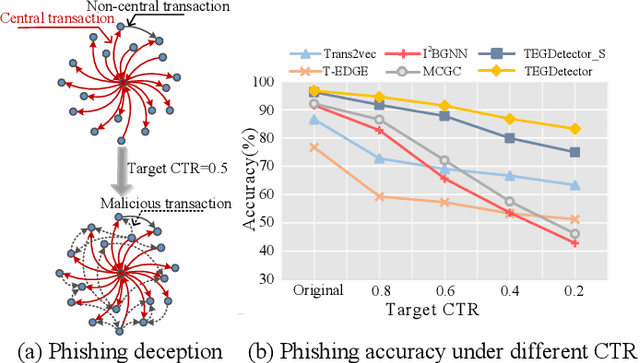
Recently, phishing scams have posed a significant threat to blockchains. Phishing detectors direct their efforts in hunting phishing addresses. Most of the detectors extract target addresses' transaction behavior features by random walking or constructing static subgraphs. The random walking methods,unfortunately, usually miss structural information due to limited sampling sequence length, while the static subgraph methods tend to ignore temporal features lying in the evolving transaction behaviors. More importantly, their performance undergoes severe degradation when the malicious users intentionally hide phishing behaviors. To address these challenges, we propose TEGDetector, a dynamic graph classifier that learns the evolving behavior features from transaction evolution graphs (TEGs). First, we cast the transaction series into multiple time slices, capturing the target address's transaction behaviors in different periods. Then, we provide a fast non-parametric phishing detector to narrow down the search space of suspicious addresses. Finally, TEGDetector considers both the spatial and temporal evolutions towards a complete characterization of the evolving transaction behaviors. Moreover, TEGDetector utilizes adaptively learnt time coefficient to pay distinct attention to different periods, which provides several novel insights. Extensive experiments on the large-scale Ethereum transaction dataset demonstrate that the proposed method achieves state-of-the-art detection performance.
WiSig: A Large-Scale WiFi Signal Dataset for Receiver and Channel Agnostic RF Fingerprinting
Jan 12, 2022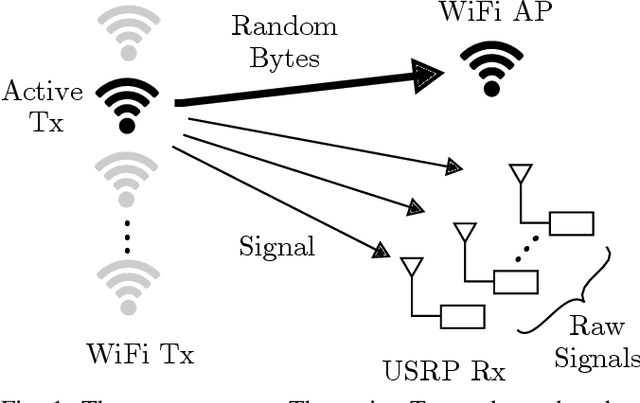
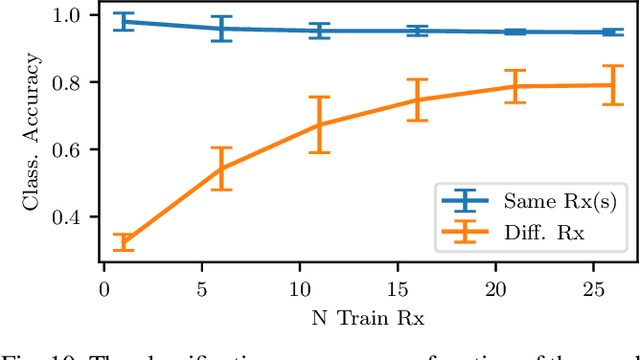
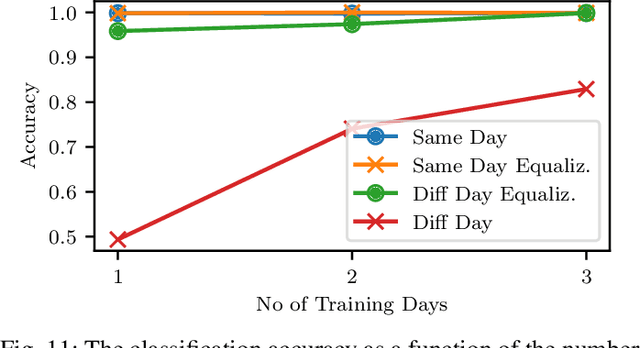
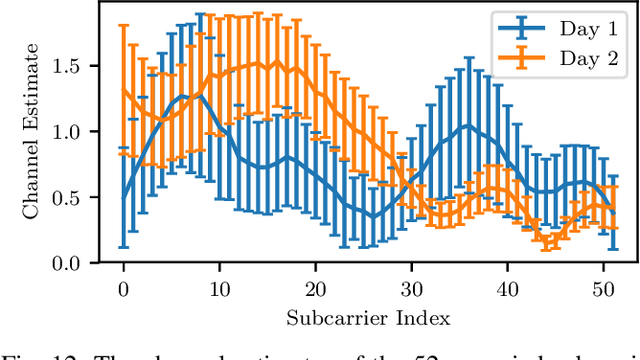
RF fingerprinting leverages circuit-level variability of transmitters to identify them using signals they send. Signals used for identification are impacted by a wireless channel and receiver circuitry, creating additional impairments that can confuse transmitter identification. Eliminating these impairments or just evaluating them, requires data captured over a prolonged period of time, using many spatially separated transmitters and receivers. In this paper, we present WiSig; a large scale WiFi dataset containing 10 million packets captured from 174 off-the-shelf WiFi transmitters and 41 USRP receivers over 4 captures spanning a month. WiSig is publicly available, not just as raw captures, but as conveniently pre-processed subsets of limited size, along with the scripts and examples. A preliminary evaluation performed using WiSig shows that changing receivers, or using signals captured on a different day can significantly degrade a trained classifier's performance. While capturing data over more days or more receivers limits the degradation, it is not always feasible and novel data-driven approaches are needed. WiSig provides the data to develop and evaluate these approaches towards channel and receiver agnostic transmitter fingerprinting.
Improving Across-Dataset Brain Tissue Segmentation Using Transformer
Jan 21, 2022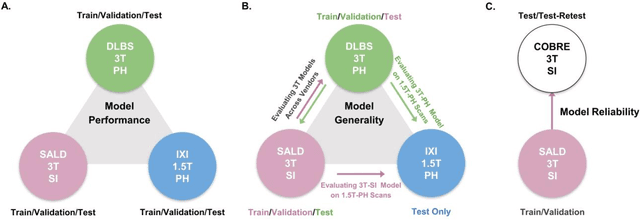
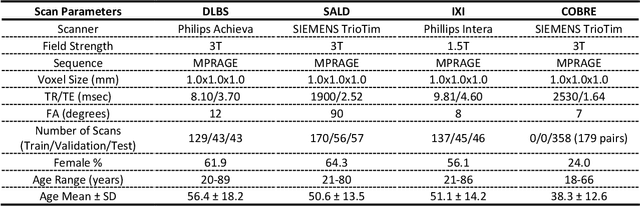
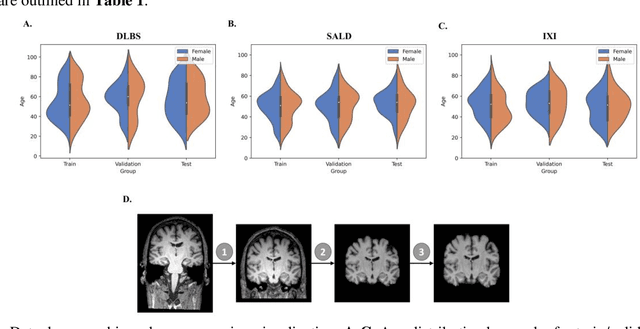
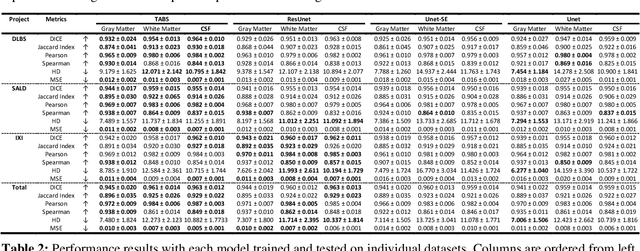
Brain tissue segmentation has demonstrated great utility in quantifying MRI data through Voxel-Based Morphometry and highlighting subtle structural changes associated with various conditions within the brain. However, manual segmentation is highly labor-intensive, and automated approaches have struggled due to properties inherent to MRI acquisition, leaving a great need for an effective segmentation tool. Despite the recent success of deep convolutional neural networks (CNNs) for brain tissue segmentation, many such solutions do not generalize well to new datasets, which is critical for a reliable solution. Transformers have demonstrated success in natural image segmentation and have recently been applied to 3D medical image segmentation tasks due to their ability to capture long-distance relationships in the input where the local receptive fields of CNNs struggle. This study introduces a novel CNN-Transformer hybrid architecture designed for brain tissue segmentation. We validate our model's performance across four multi-site T1w MRI datasets, covering different vendors, field strengths, scan parameters, time points, and neuropsychiatric conditions. In all situations, our model achieved the greatest generality and reliability. Out method is inherently robust and can serve as a valuable tool for brain-related T1w MRI studies. The code for the TABS network is available at: https://github.com/raovish6/TABS.
Supporting Optimal Phase Space Reconstructions Using Neural Network Architecture for Time Series Modeling
Jun 19, 2020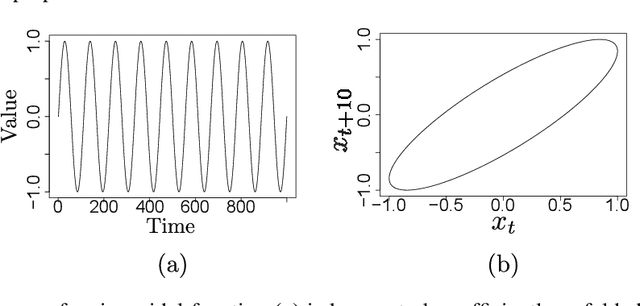
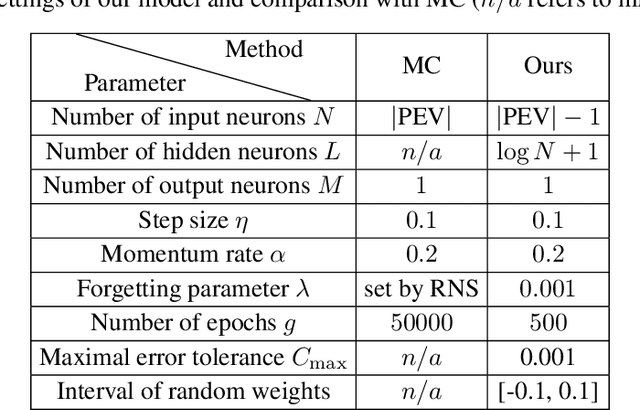
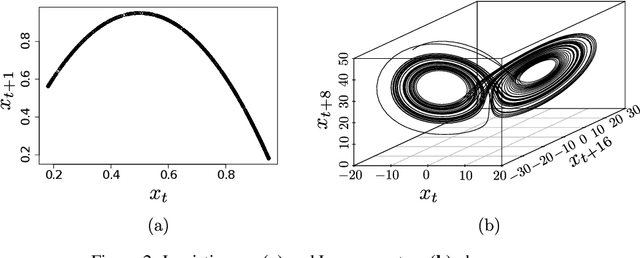
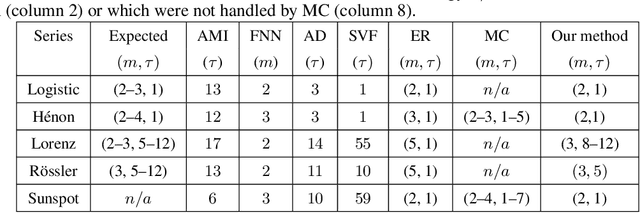
The reconstruction of phase spaces is an essential step to analyze time series according to Dynamical System concepts. A regression performed on such spaces unveils the relationships among system states from which we can derive their generating rules, that is, the most probable set of functions responsible for generating observations along time. In this sense, most approaches rely on Takens' embedding theorem to unfold the phase space, which requires the embedding dimension and the time delay. Moreover, although several methods have been proposed to empirically estimate those parameters, they still face limitations due to their lack of consistency and robustness, which has motivated this paper. As an alternative, we here propose an artificial neural network with a forgetting mechanism to implicitly learn the phase spaces properties, whatever they are. Such network trains on forecasting errors and, after converging, its architecture is used to estimate the embedding parameters. Experimental results confirm that our approach is either as competitive as or better than most state-of-the-art strategies while revealing the temporal relationship among time-series observations.
Bayesian Learning via Neural Schrödinger-Föllmer Flows
Nov 26, 2021
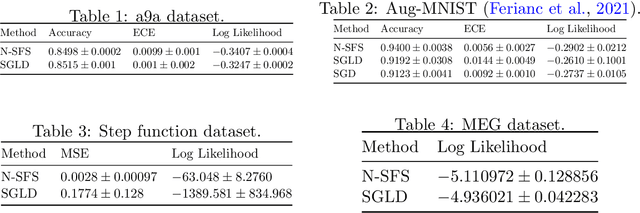
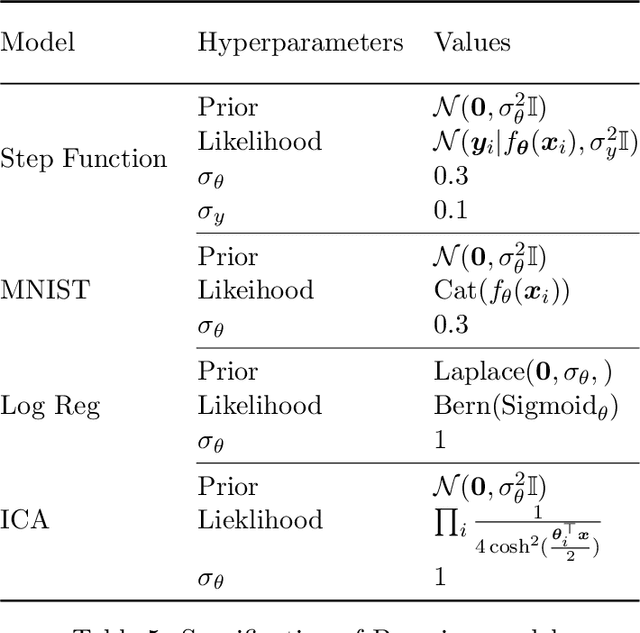
In this work we explore a new framework for approximate Bayesian inference in large datasets based on stochastic control. We advocate stochastic control as a finite time alternative to popular steady-state methods such as stochastic gradient Langevin dynamics (SGLD). Furthermore, we discuss and adapt the existing theoretical guarantees of this framework and establish connections to already existing VI routines in SDE-based models.
Robustness and Adaptability of Reinforcement Learning based Cooperative Autonomous Driving in Mixed-autonomy Traffic
Feb 02, 2022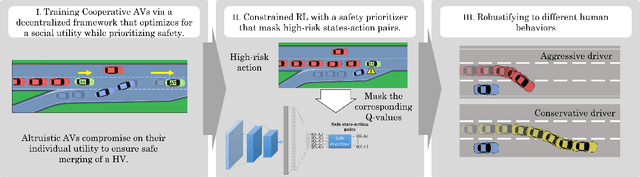
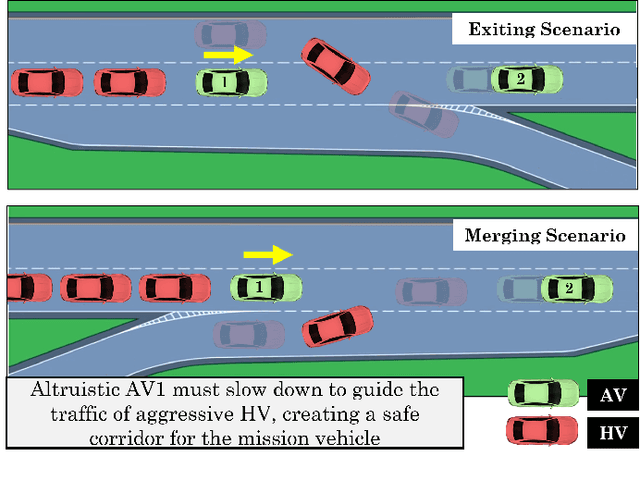
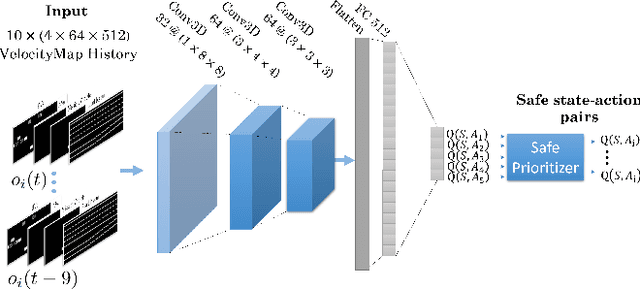
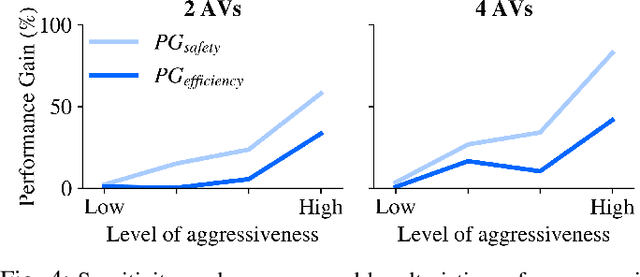
Building autonomous vehicles (AVs) is a complex problem, but enabling them to operate in the real world where they will be surrounded by human-driven vehicles (HVs) is extremely challenging. Prior works have shown the possibilities of creating inter-agent cooperation between a group of AVs that follow a social utility. Such altruistic AVs can form alliances and affect the behavior of HVs to achieve socially desirable outcomes. We identify two major challenges in the co-existence of AVs and HVs. First, social preferences and individual traits of a given human driver, e.g., selflessness and aggressiveness are unknown to an AV, and it is almost impossible to infer them in real-time during a short AV-HV interaction. Second, contrary to AVs that are expected to follow a policy, HVs do not necessarily follow a stationary policy and therefore are extremely hard to predict. To alleviate the above-mentioned challenges, we formulate the mixed-autonomy problem as a multi-agent reinforcement learning (MARL) problem and propose a decentralized framework and reward function for training cooperative AVs. Our approach enables AVs to learn the decision-making of HVs implicitly from experience, optimizes for a social utility while prioritizing safety and allowing adaptability; robustifying altruistic AVs to different human behaviors and constraining them to a safe action space. Finally, we investigate the robustness, safety and sensitivity of AVs to various HVs behavioral traits and present the settings in which the AVs can learn cooperative policies that are adaptable to different situations.
FedMed-ATL: Misaligned Unpaired Brain Image Synthesis via Affine Transform Loss
Jan 29, 2022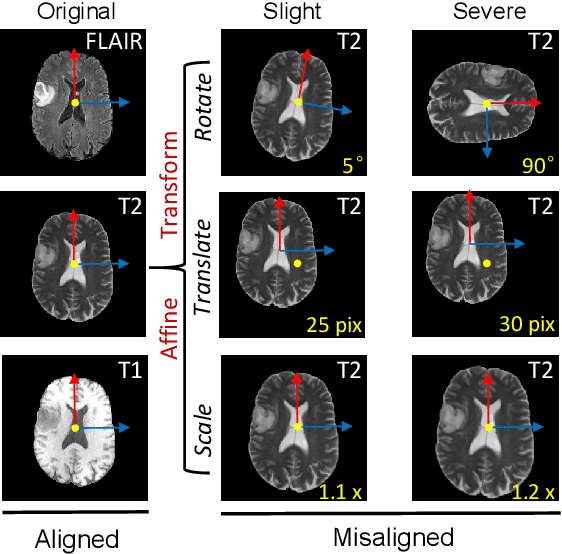
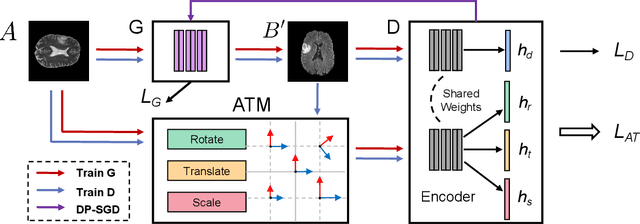
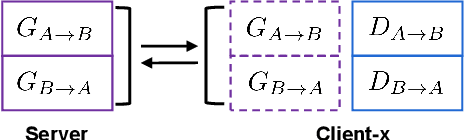
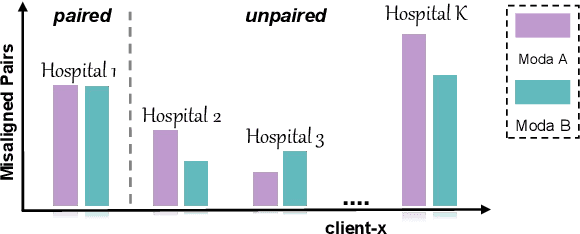
The existence of completely aligned and paired multi-modal neuroimaging data has proved its effectiveness in the diagnosis of brain diseases. However, collecting the full set of well-aligned and paired data is impractical or even luxurious, since the practical difficulties may include high cost, long time acquisition, image corruption, and privacy issues. Previously, the misaligned unpaired neuroimaging data (termed as MUD) are generally treated as noisy label. However, such a noisy label-based method could not work very well when misaligned data occurs distortions severely, for example, different angles of rotation. In this paper, we propose a novel federated self-supervised learning (FedMed) for brain image synthesis. An affine transform loss (ATL) was formulated to make use of severely distorted images without violating privacy legislation for the hospital. We then introduce a new data augmentation procedure for self-supervised training and fed it into three auxiliary heads, namely auxiliary rotation, auxiliary translation, and auxiliary scaling heads. The proposed method demonstrates advanced performance in both the quality of synthesized results under a severely misaligned and unpaired data setting, and better stability than other GAN-based algorithms. The proposed method also reduces the demand for deformable registration while encouraging to realize the usage of those misaligned and unpaired data. Experimental results verify the outstanding ability of our learning paradigm compared to other state-of-the-art approaches. Our code is available on the website: https://github.com/FedMed-Meta/FedMed-ATL
Optimal Localization with Sequential Pseudorange Measurements for Moving Users in a Time Division Broadcast Positioning System
Jan 05, 2021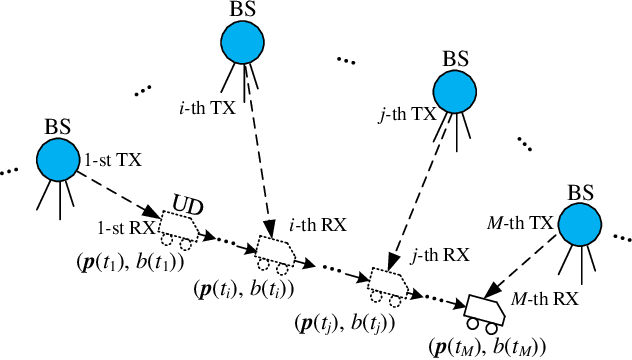
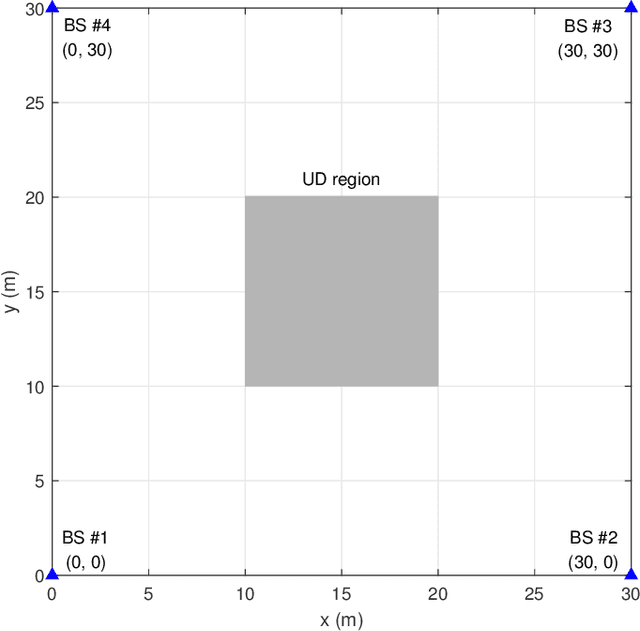
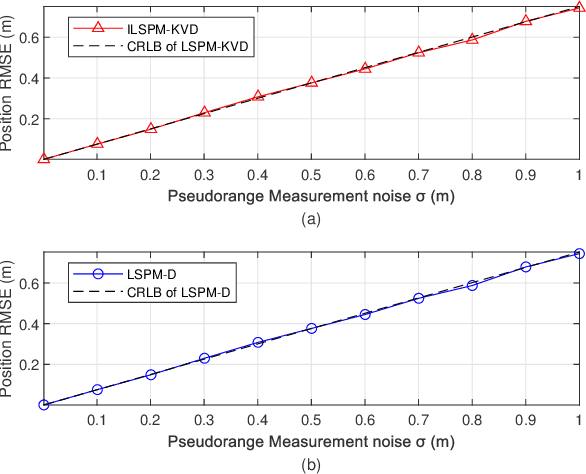
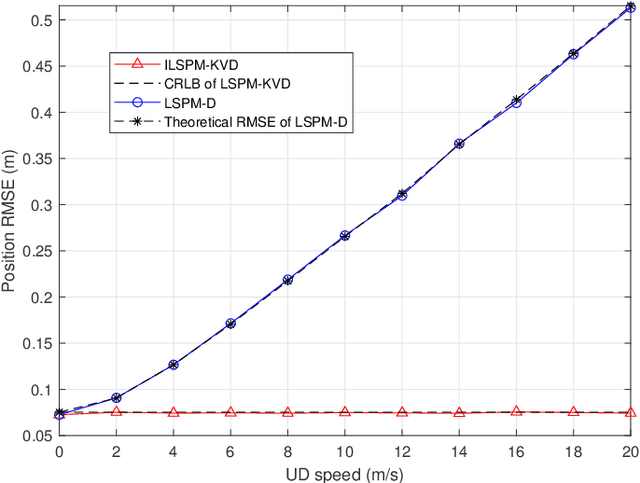
In a time division broadcast positioning system (TDBPS), a user device (UD) determines its position by obtaining sequential time-of-arrival (TOA) or pseudorange measurements from signals broadcast by multiple synchronized base stations (BSs). The existing localization method using sequential pseudorange measurements and a linear clock drift model for the TDPBS, namely LSPM-D, does not compensate the position displacement caused by the UD movement and will result in position error. In this paper, depending on the knowledge of the UD velocity, we develop a set of optimal localization methods for different cases. First, for known UD velocity, we develop the optimal localization method, namely LSPM-KVD, to compensate the movement-caused position error. We show that the LSPM-D is a special case of the LSPM-KVD when the UD is stationary with zero velocity. Second, for the case with unknown UD velocity, we develop a maximum likelihood (ML) method to jointly estimate the UD position and velocity, namely LSPM-UVD. Third, in the case that we have prior distribution information of the UD velocity, we present a maximum a posteriori (MAP) estimator for localization, namely LSPM-PVD. We derive the Cramer-Rao lower bound (CRLB) for all three estimators and analyze their localization error performance. We show that the position error of the LSPM-KVD increases as the assumed known velocity deviates from the true value. As expected, the LSPM-KVD has the smallest position error while the LSPM-PVD and the LSPM-UVD are more robust when the prior knowledge of the UD velocity is limited. Numerical results verify the theoretical analysis on the optimality and the positioning accuracy of the proposed methods.