 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data Heterogeneity-Robust Federated Learning via Group Client Selection in Industrial IoT
Feb 03, 2022
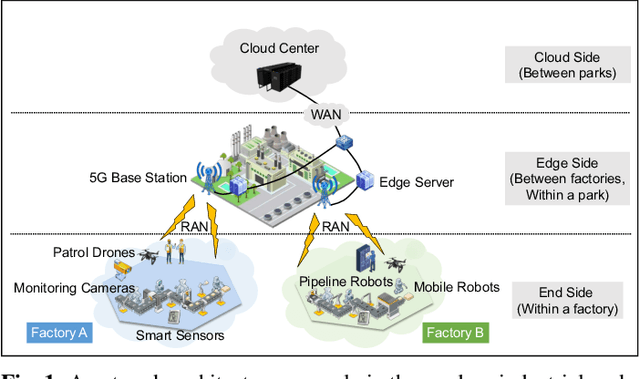
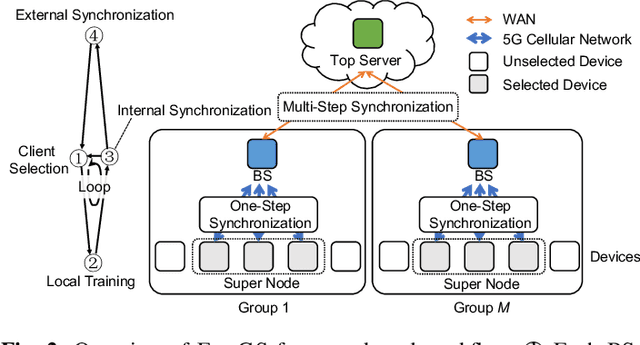


Nowadays, the industrial Internet of Things (IIoT) has played an integral role in Industry 4.0 and produced massive amounts of data for industrial intelligence. These data locate on decentralized devices in modern factories. To protect the confidentiality of industrial data, federated learning (FL) was introduced to collaboratively train shared machine learning models. However, the local data collected by different devices skew in class distribution and degrade industrial FL performance. This challenge has been widely studied at the mobile edge, but they ignored the rapidly changing streaming data and clustering nature of factory devices, and more seriously, they may threaten data security. In this paper, we propose FedGS, which is a hierarchical cloud-edge-end FL framework for 5G empowered industries, to improve industrial FL performance on non-i.i.d. data. Taking advantage of naturally clustered factory devices, FedGS uses a gradient-based binary permutation algorithm (GBP-CS) to select a subset of devices within each factory and build homogeneous super nodes participating in FL training. Then, we propose a compound-step synchronization protocol to coordinate the training process within and among these super nodes, which shows great robustness against data heterogeneity. The proposed methods are time-efficient and can adapt to dynamic environments, without exposing confidential industrial data in risky manipulation. We prove that FedGS has better convergence performance than FedAvg and give a relaxed condition under which FedGS is more communication-efficient. Extensive experiments show that FedGS improves accuracy by 3.5% and reduces training rounds by 59% on average, confirming its superior effectiveness and efficiency on non-i.i.d. data.
Computational Complexity of Normalizing Constants for the Product of Determinantal Point Processes
Nov 28, 2021
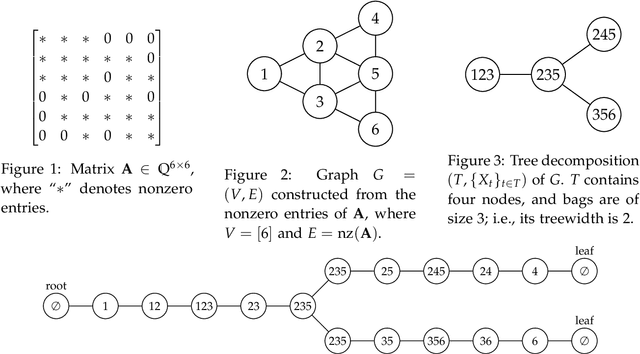
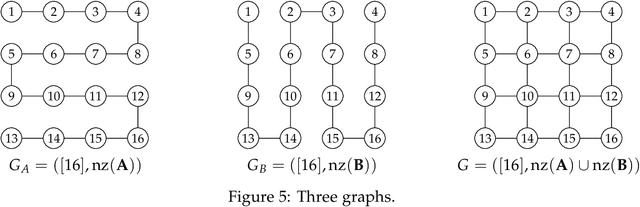
We consider the product of determinantal point processes (DPPs), a point process whose probability mass is proportional to the product of principal minors of multiple matrices, as a natural, promising generalization of DPPs. We study the computational complexity of computing its normalizing constant, which is among the most essential probabilistic inference tasks. Our complexity-theoretic results (almost) rule out the existence of efficient algorithms for this task unless the input matrices are forced to have favorable structures. In particular, we prove the following: (1) Computing $\sum_S\det({\bf A}_{S,S})^p$ exactly for every (fixed) positive even integer $p$ is UP-hard and Mod$_3$P-hard, which gives a negative answer to an open question posed by Kulesza and Taskar. (2) $\sum_S\det({\bf A}_{S,S})\det({\bf B}_{S,S})\det({\bf C}_{S,S})$ is NP-hard to approximate within a factor of $2^{O(|I|^{1-\epsilon})}$ or $2^{O(n^{1/\epsilon})}$ for any $\epsilon>0$, where $|I|$ is the input size and $n$ is the order of the input matrix. This result is stronger than the #P-hardness for the case of two matrices derived by Gillenwater. (3) There exists a $k^{O(k)}n^{O(1)}$-time algorithm for computing $\sum_S\det({\bf A}_{S,S})\det({\bf B}_{S,S})$, where $k$ is the maximum rank of $\bf A$ and $\bf B$ or the treewidth of the graph formed by nonzero entries of $\bf A$ and $\bf B$. Such parameterized algorithms are said to be fixed-parameter tractable. These results can be extended to the fixed-size case. Further, we present two applications of fixed-parameter tractable algorithms given a matrix $\bf A$ of treewidth $w$: (4) We can compute a $2^{\frac{n}{2p-1}}$-approximation to $\sum_S\det({\bf A}_{S,S})^p$ for any fractional number $p>1$ in $w^{O(wp)}n^{O(1)}$ time. (5) We can find a $2^{\sqrt n}$-approximation to unconstrained MAP inference in $w^{O(w\sqrt n)}n^{O(1)}$ time.
Synchromesh: Reliable code generation from pre-trained language models
Jan 26, 2022

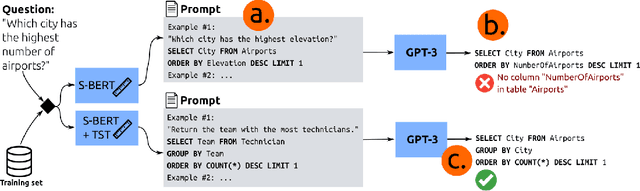
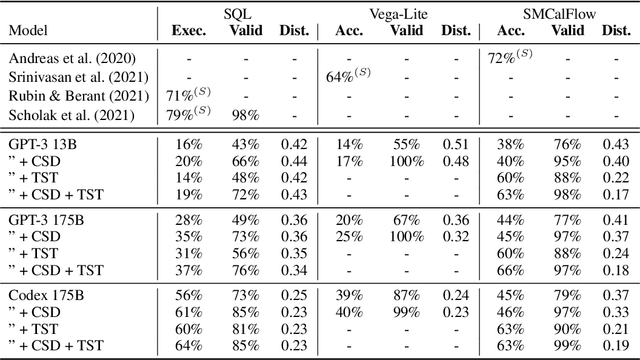
Large pre-trained language models have been used to generate code,providing a flexible interface for synthesizing programs from natural language specifications. However, they often violate syntactic and semantic rules of their output language, limiting their practical usability. In this paper, we propose Synchromesh: a framework for substantially improving the reliability of pre-trained models for code generation. Synchromesh comprises two components. First, it retrieves few-shot examples from a training bank using Target Similarity Tuning (TST), a novel method for semantic example selection. TST learns to recognize utterances that describe similar target programs despite differences in surface natural language features. Then, Synchromesh feeds the examples to a pre-trained language model and samples programs using Constrained Semantic Decoding (CSD): a general framework for constraining the output to a set of valid programs in the target language. CSD leverages constraints on partial outputs to sample complete correct programs, and needs neither re-training nor fine-tuning of the language model. We evaluate our methods by synthesizing code from natural language descriptions using GPT-3 and Codex in three real-world languages: SQL queries, Vega-Lite visualizations and SMCalFlow programs. These domains showcase rich constraints that CSD is able to enforce, including syntax, scope, typing rules, and contextual logic. We observe substantial complementary gains from CSD and TST in prediction accuracy and in effectively preventing run-time errors.
ReforesTree: A Dataset for Estimating Tropical Forest Carbon Stock with Deep Learning and Aerial Imagery
Jan 26, 2022
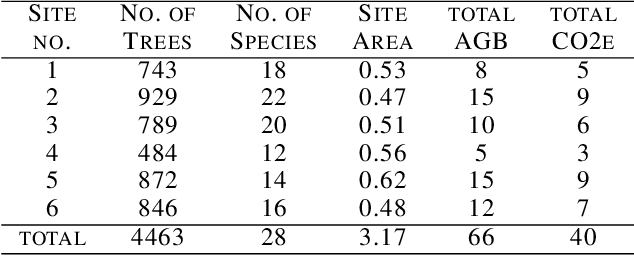
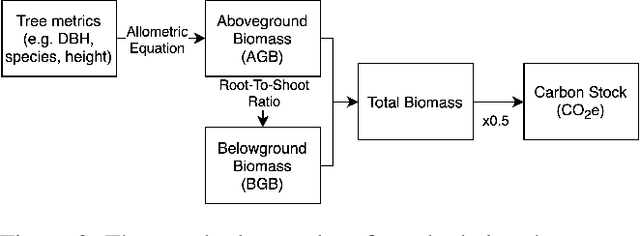
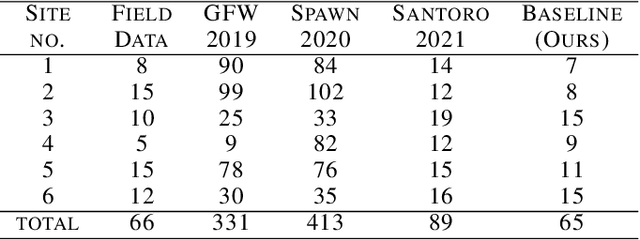
Forest biomass is a key influence for future climate, and the world urgently needs highly scalable financing schemes, such as carbon offsetting certifications, to protect and restore forests. Current manual forest carbon stock inventory methods of measuring single trees by hand are time, labour, and cost-intensive and have been shown to be subjective. They can lead to substantial overestimation of the carbon stock and ultimately distrust in forest financing. The potential for impact and scale of leveraging advancements in machine learning and remote sensing technologies is promising but needs to be of high quality in order to replace the current forest stock protocols for certifications. In this paper, we present ReforesTree, a benchmark dataset of forest carbon stock in six agro-forestry carbon offsetting sites in Ecuador. Furthermore, we show that a deep learning-based end-to-end model using individual tree detection from low cost RGB-only drone imagery is accurately estimating forest carbon stock within official carbon offsetting certification standards. Additionally, our baseline CNN model outperforms state-of-the-art satellite-based forest biomass and carbon stock estimates for this type of small-scale, tropical agro-forestry sites. We present this dataset to encourage machine learning research in this area to increase accountability and transparency of monitoring, verification and reporting (MVR) in carbon offsetting projects, as well as scaling global reforestation financing through accurate remote sensing.
A Letter on Convergence of In-Parameter-Linear Nonlinear Neural Architectures with Gradient Learnings
Nov 25, 2021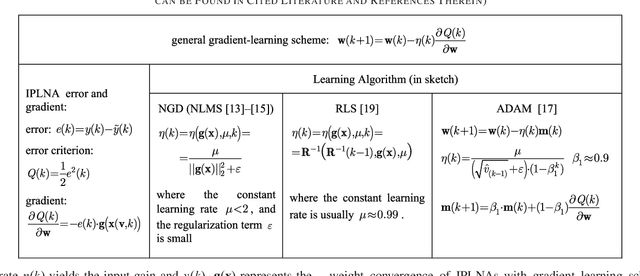
This letter summarizes and proves the concept of bounded-input bounded-state (BIBS) stability for weight convergence of a broad family of in-parameter-linear nonlinear neural architectures as it generally applies to a broad family of incremental gradient learning algorithms. A practical BIBS convergence condition results from the derived proofs for every individual learning point or batches for real-time applications.
Data-Driven Offline Optimization For Architecting Hardware Accelerators
Oct 20, 2021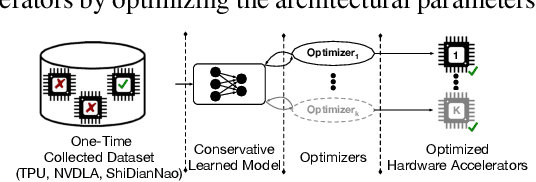
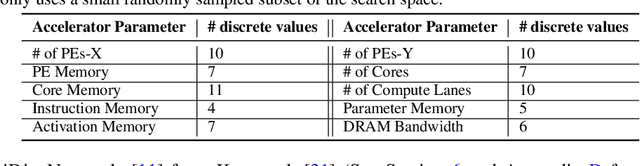
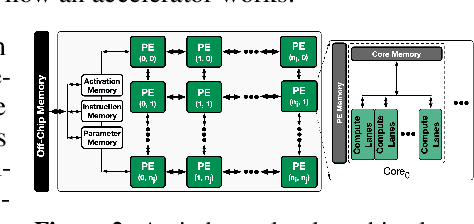
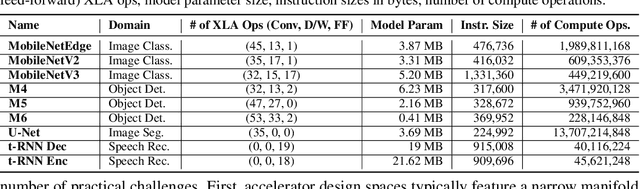
Industry has gradually moved towards application-specific hardware accelerators in order to attain higher efficiency. While such a paradigm shift is already starting to show promising results, designers need to spend considerable manual effort and perform a large number of time-consuming simulations to find accelerators that can accelerate multiple target applications while obeying design constraints. Moreover, such a "simulation-driven" approach must be re-run from scratch every time the set of target applications or design constraints change. An alternative paradigm is to use a "data-driven", offline approach that utilizes logged simulation data, to architect hardware accelerators, without needing any form of simulations. Such an approach not only alleviates the need to run time-consuming simulation, but also enables data reuse and applies even when set of target applications changes. In this paper, we develop such a data-driven offline optimization method for designing hardware accelerators, dubbed PRIME, that enjoys all of these properties. Our approach learns a conservative, robust estimate of the desired cost function, utilizes infeasible points, and optimizes the design against this estimate without any additional simulator queries during optimization. PRIME architects accelerators -- tailored towards both single and multiple applications -- improving performance upon state-of-the-art simulation-driven methods by about 1.54x and 1.20x, while considerably reducing the required total simulation time by 93% and 99%, respectively. In addition, PRIME also architects effective accelerators for unseen applications in a zero-shot setting, outperforming simulation-based methods by 1.26x.
DACFL: Dynamic Average Consensus Based Federated Learning in Decentralized Topology
Nov 10, 2021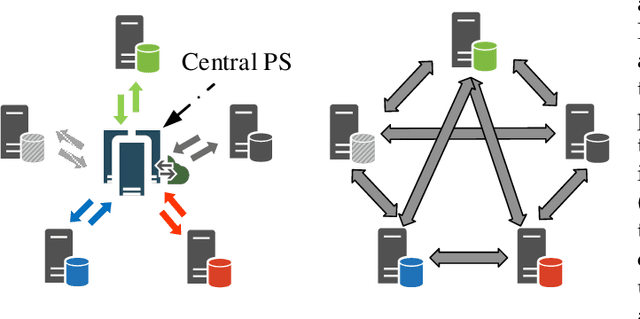

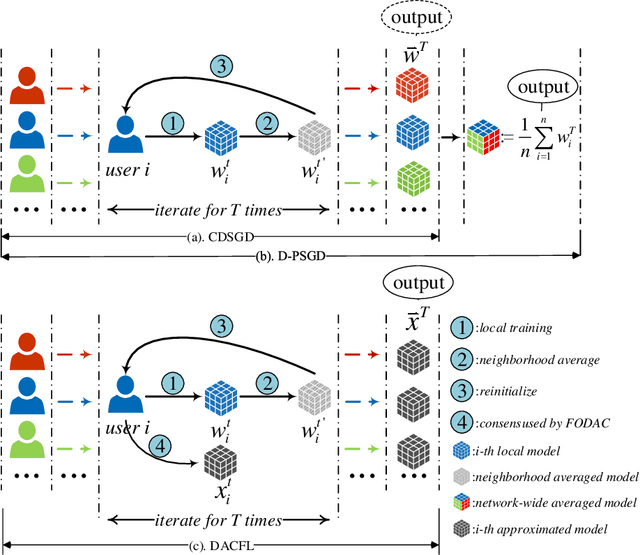
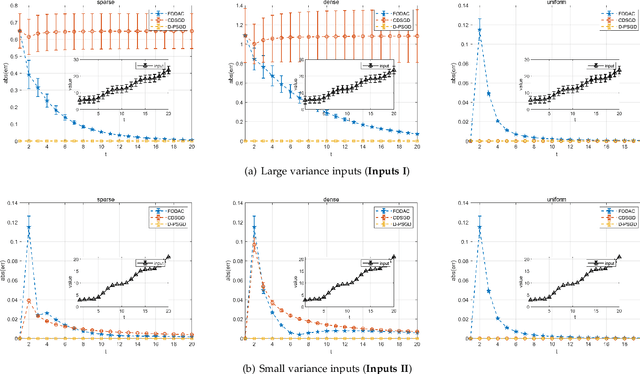
Federated learning (FL) is a burgeoning distributed machine learning framework where a central parameter server (PS) coordinates many local users to train a globally consistent model. Conventional federated learning inevitably relies on a centralized topology with a PS. As a result, it will paralyze once the PS fails. To alleviate such a single point failure, especially on the PS, some existing work has provided decentralized FL (DFL) implementations like CDSGD and D-PSGD to facilitate FL in a decentralized topology. However, there are still some problems with these methods, e.g., significant divergence between users' final models in CDSGD and a network-wide model average necessity in D-PSGD. In order to solve these deficiency, this paper devises a new DFL implementation coined as DACFL, where each user trains its model using its own training data and exchanges the intermediate models with its neighbors through a symmetric and doubly stochastic matrix. The DACFL treats the progress of each user's local training as a discrete-time process and employs a first order dynamic average consensus (FODAC) method to track the \textit{average model} in the absence of the PS. In this paper, we also provide a theoretical convergence analysis of DACFL on the premise of i.i.d data to strengthen its rationality. The experimental results on MNIST, Fashion-MNIST and CIFAR-10 validate the feasibility of our solution in both time-invariant and time-varying network topologies, and declare that DACFL outperforms D-PSGD and CDSGD in most cases.
Probabilistic spatial clustering based on the Self Discipline Learning (SDL) model of autonomous learning
Jan 07, 2022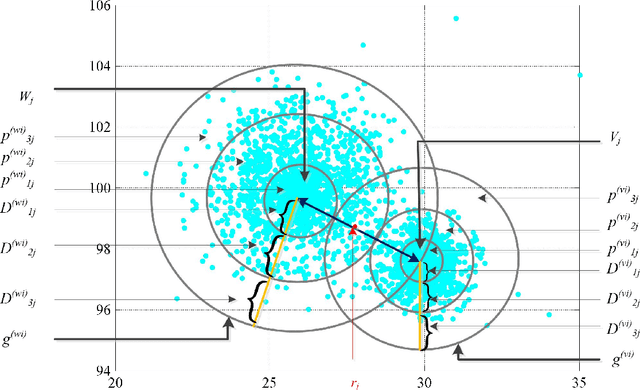
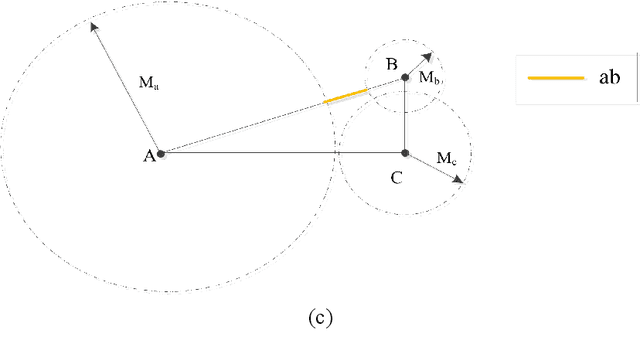
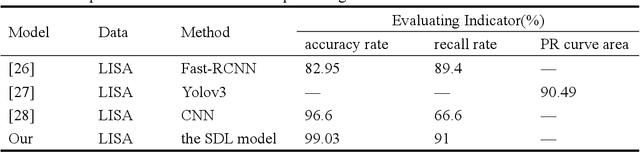
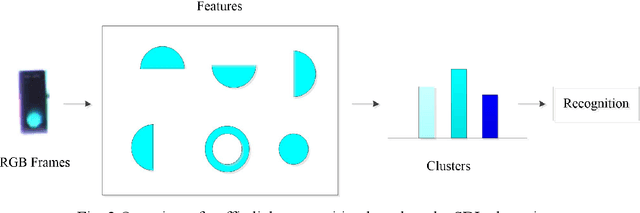
Unsupervised clustering algorithm can effectively reduce the dimension of high-dimensional unlabeled data, thus reducing the time and space complexity of data processing. However, the traditional clustering algorithm needs to set the upper bound of the number of categories in advance, and the deep learning clustering algorithm will fall into the problem of local optimum. In order to solve these problems, a probabilistic spatial clustering algorithm based on the Self Discipline Learning(SDL) model is proposed. The algorithm is based on the Gaussian probability distribution of the probability space distance between vectors, and uses the probability scale and maximum probability value of the probability space distance as the distance measurement judgment, and then determines the category of each sample according to the distribution characteristics of the data set itself. The algorithm is tested in Laboratory for Intelligent and Safe Automobiles(LISA) traffic light data set, the accuracy rate is 99.03%, the recall rate is 91%, and the effect is achieved.
TYPIC: A Corpus of Template-Based Diagnostic Comments on Argumentation
Jan 18, 2022



Providing feedback on the argumentation of learner is essential for development of critical thinking skills, but it takes a lot of time and effort. To reduce the burden on teachers, we aim to automate a process of giving feedback, especially giving diagnostic comments which point out the weaknesses inherent in the argumentation. It is advisable to give specific diagnostic comments so that learners can recognize the diagnosis without misunderstanding. However, it is not obvious how the task of providing specific diagnostic comments should be formulated. We present a formulation of the task as template selection and slot filling to make an automatic evaluation easier and the behavior of the model more tractable. The key to the formulation is the possibility of creating a template set that is sufficient for practical use. In this paper, we define three criteria that a template set should satisfy: expressiveness, informativeness, and uniqueness, and verify the feasibility to create a template set that satisfies these criteria as a first trial. We will show that it is feasible through an annotation study that converts diagnostic comments given in text into a template format. The corpus used in the annotation study is publicly available.
A Marketplace for Trading AI Models based on Blockchain and Incentives for IoT Data
Dec 06, 2021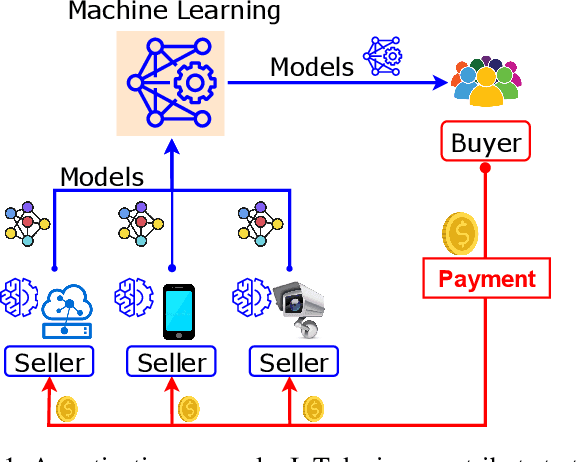
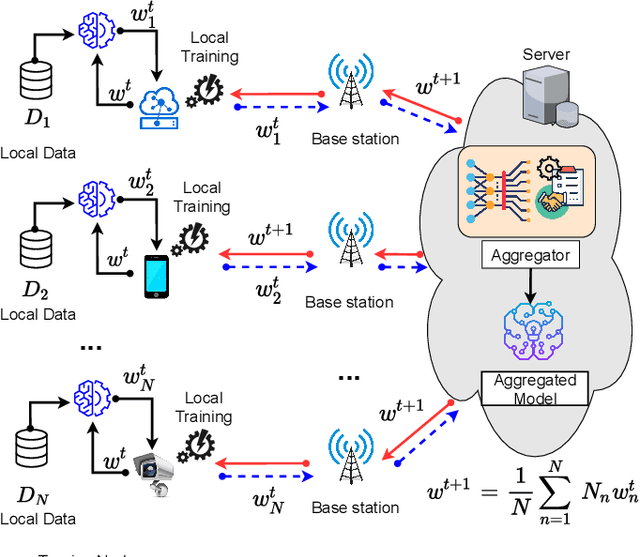
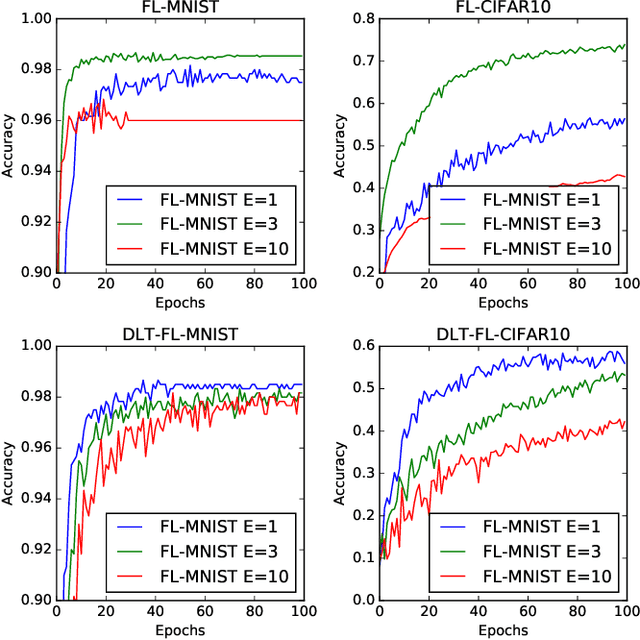
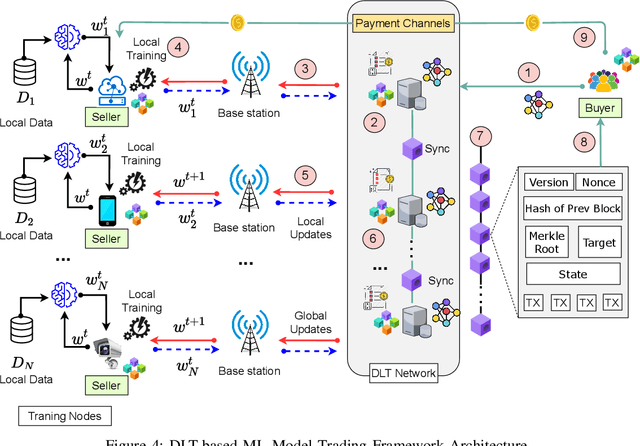
As Machine Learning (ML) models are becoming increasingly complex, one of the central challenges is their deployment at scale, such that companies and organizations can create value through Artificial Intelligence (AI). An emerging paradigm in ML is a federated approach where the learning model is delivered to a group of heterogeneous agents partially, allowing agents to train the model locally with their own data. However, the problem of valuation of models, as well the questions of incentives for collaborative training and trading of data/models, have received limited treatment in the literature. In this paper, a new ecosystem of ML model trading over a trusted Blockchain-based network is proposed. The buyer can acquire the model of interest from the ML market, and interested sellers spend local computations on their data to enhance that model's quality. In doing so, the proportional relation between the local data and the quality of trained models is considered, and the valuations of seller's data in training the models are estimated through the distributed Data Shapley Value (DSV). At the same time, the trustworthiness of the entire trading process is provided by the distributed Ledger Technology (DLT). Extensive experimental evaluation of the proposed approach shows a competitive run-time performance, with a 15\% drop in the cost of execution, and fairness in terms of incentives for the participants.