 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Comparative study of 3D object detection frameworks based on LiDAR data and sensor fusion techniques
Feb 05, 2022
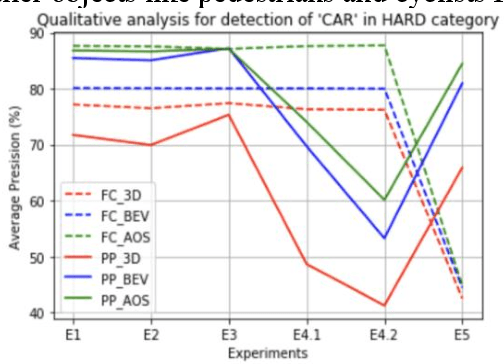
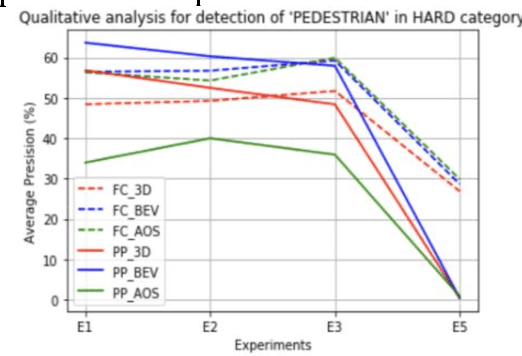
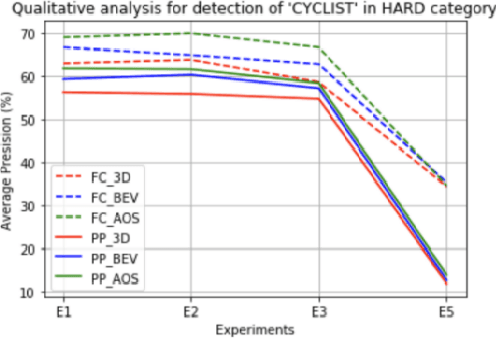
Estimating and understanding the surroundings of the vehicle precisely forms the basic and crucial step for the autonomous vehicle. The perception system plays a significant role in providing an accurate interpretation of a vehicle's environment in real-time. Generally, the perception system involves various subsystems such as localization, obstacle (static and dynamic) detection, and avoidance, mapping systems, and others. For perceiving the environment, these vehicles will be equipped with various exteroceptive (both passive and active) sensors in particular cameras, Radars, LiDARs, and others. These systems are equipped with deep learning techniques that transform the huge amount of data from the sensors into semantic information on which the object detection and localization tasks are performed. For numerous driving tasks, to provide accurate results, the location and depth information of a particular object is necessary. 3D object detection methods, by utilizing the additional pose data from the sensors such as LiDARs, stereo cameras, provides information on the size and location of the object. Based on recent research, 3D object detection frameworks performing object detection and localization on LiDAR data and sensor fusion techniques show significant improvement in their performance. In this work, a comparative study of the effect of using LiDAR data for object detection frameworks and the performance improvement seen by using sensor fusion techniques are performed. Along with discussing various state-of-the-art methods in both the cases, performing experimental analysis, and providing future research directions.
Compute, Time and Energy Characterization of Encoder-Decoder Networks with Automatic Mixed Precision Training
Aug 18, 2020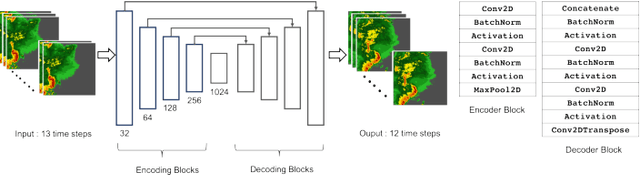
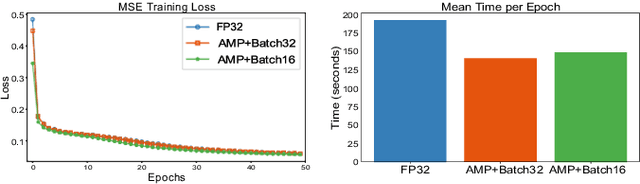
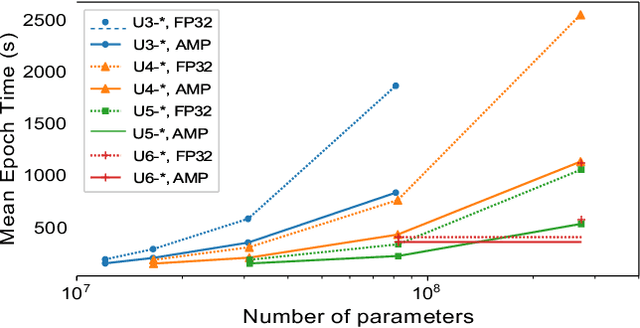
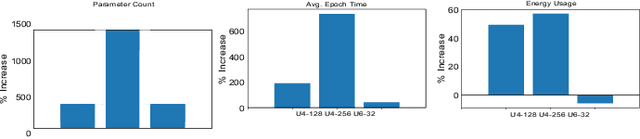
Deep neural networks have shown great success in many diverse fields. The training of these networks can take significant amounts of time, compute and energy. As datasets get larger and models become more complex, the exploration of model architectures becomes prohibitive. In this paper we examine the compute, energy and time costs of training a UNet based deep neural network for the problem of predicting short term weather forecasts (called precipitation Nowcasting). By leveraging a combination of data distributed and mixed-precision training, we explore the design space for this problem. We also show that larger models with better performance come at a potentially incremental cost if appropriate optimizations are used. We show that it is possible to achieve a significant improvement in training time by leveraging mixed-precision training without sacrificing model performance. Additionally, we find that a 1549% increase in the number of trainable parameters for a network comes at a relatively smaller 63.22% increase in energy usage for a UNet with 4 encoding layers.
StyleMesh: Style Transfer for Indoor 3D Scene Reconstructions
Dec 02, 2021
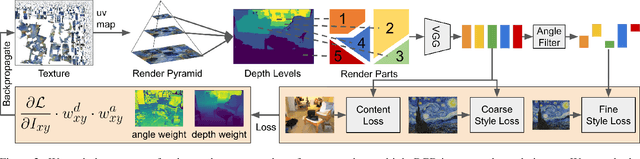
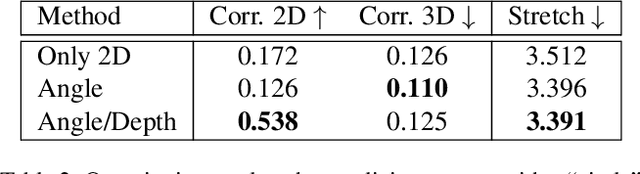
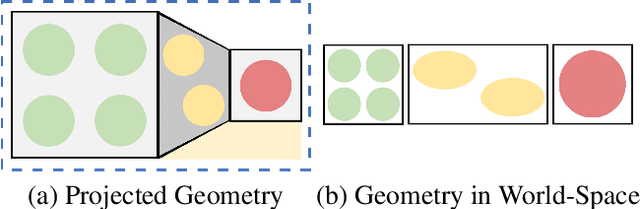
We apply style transfer on mesh reconstructions of indoor scenes. This enables VR applications like experiencing 3D environments painted in the style of a favorite artist. Style transfer typically operates on 2D images, making stylization of a mesh challenging. When optimized over a variety of poses, stylization patterns become stretched out and inconsistent in size. On the other hand, model-based 3D style transfer methods exist that allow stylization from a sparse set of images, but they require a network at inference time. To this end, we optimize an explicit texture for the reconstructed mesh of a scene and stylize it jointly from all available input images. Our depth- and angle-aware optimization leverages surface normal and depth data of the underlying mesh to create a uniform and consistent stylization for the whole scene. Our experiments show that our method creates sharp and detailed results for the complete scene without view-dependent artifacts. Through extensive ablation studies, we show that the proposed 3D awareness enables style transfer to be applied to the 3D domain of a mesh. Our method can be used to render a stylized mesh in real-time with traditional rendering pipelines.
DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Jan 10, 2022
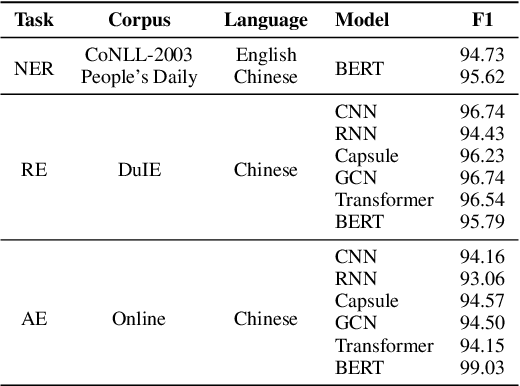
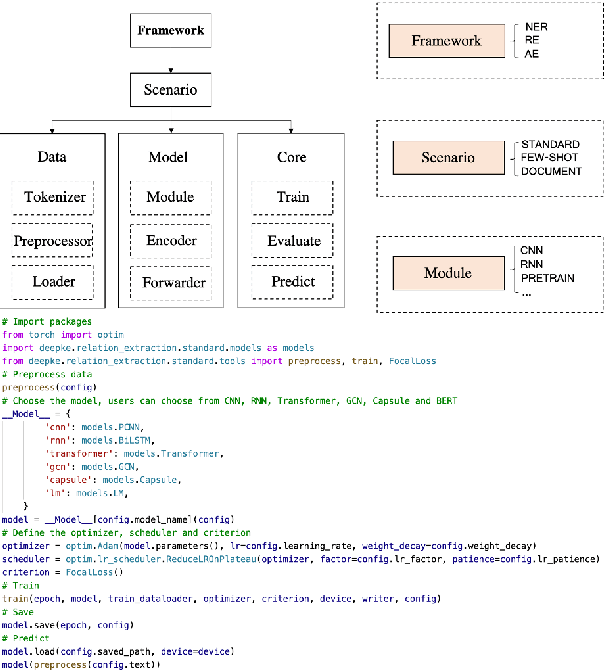
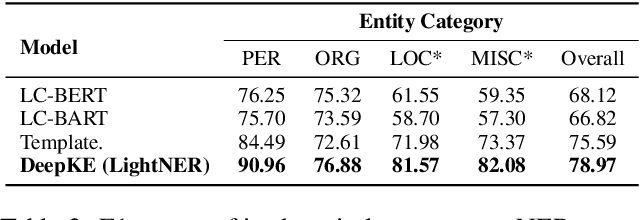
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE (Deep learning based Knowledge Extraction), supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different tasks and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Besides, we present an online platform in \url{http://deepke.zjukg.cn/} for real-time extraction of various tasks. DeepKE has been equipped with Google Colab tutorials and comprehensive documents for beginners. We release the source code at \url{https://github.com/zjunlp/DeepKE}, with a demo video.
Weakly Supervised Scene Text Detection using Deep Reinforcement Learning
Jan 13, 2022


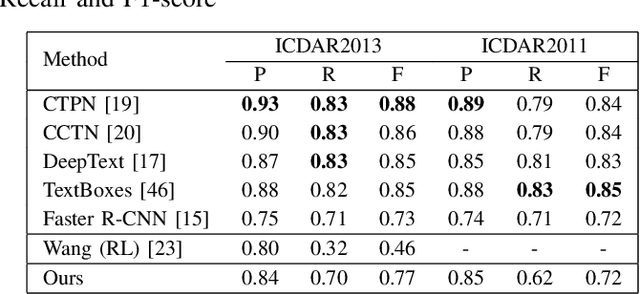
The challenging field of scene text detection requires complex data annotation, which is time-consuming and expensive. Techniques, such as weak supervision, can reduce the amount of data needed. In this paper we propose a weak supervision method for scene text detection, which makes use of reinforcement learning (RL). The reward received by the RL agent is estimated by a neural network, instead of being inferred from ground-truth labels. First, we enhance an existing supervised RL approach to text detection with several training optimizations, allowing us to close the performance gap to regression-based algorithms. We then use our proposed system in a weakly- and semi-supervised training on real-world data. Our results show that training in a weakly supervised setting is feasible. However, we find that using our model in a semi-supervised setting , e.g. when combining labeled synthetic data with unannotated real-world data, produces the best results.
Short-term Multi-horizon Residential Electric Load Forecasting using Deep Learning and Signal Decomposition Methods
Feb 01, 2022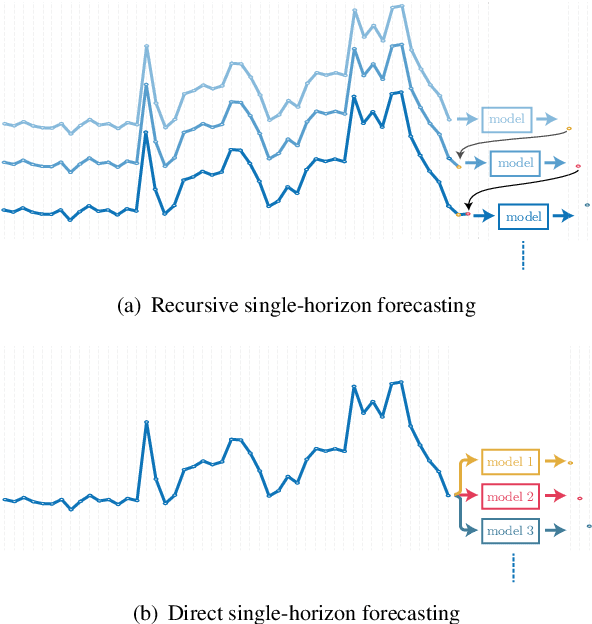

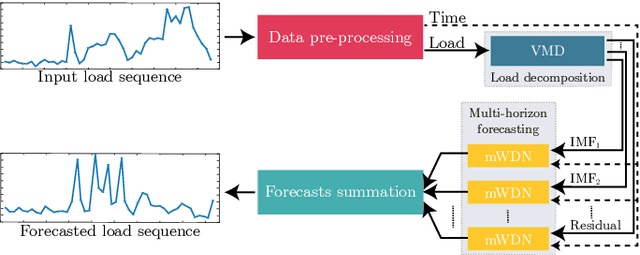
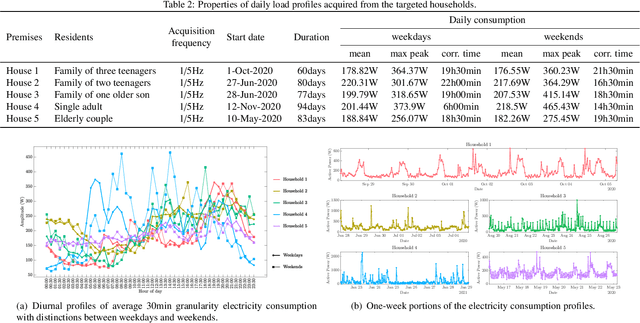
With the booming growth of advanced digital technologies, it has become possible for users as well as distributors of energy to obtain detailed and timely information about the electricity consumption of households. These technologies can also be used to forecast the household's electricity consumption (a.k.a. the load). In this paper, we investigate the use of Variational Mode Decomposition and deep learning techniques to improve the accuracy of the load forecasting problem. Although this problem has been studied in the literature, selecting an appropriate decomposition level and a deep learning technique providing better forecasting performance have garnered comparatively less attention. This study bridges this gap by studying the effect of six decomposition levels and five distinct deep learning networks. The raw load profiles are first decomposed into intrinsic mode functions using the Variational Mode Decomposition in order to mitigate their non-stationary aspect. Then, day, hour, and past electricity consumption data are fed as a three-dimensional input sequence to a four-level Wavelet Decomposition Network model. Finally, the forecast sequences related to the different intrinsic mode functions are combined to form the aggregate forecast sequence. The proposed method was assessed using load profiles of five Moroccan households from the Moroccan buildings' electricity consumption dataset (MORED) and was benchmarked against state-of-the-art time-series models and a baseline persistence model.
Kalman Filtering with Adversarial Corruptions
Nov 11, 2021Here we revisit the classic problem of linear quadratic estimation, i.e. estimating the trajectory of a linear dynamical system from noisy measurements. The celebrated Kalman filter gives an optimal estimator when the measurement noise is Gaussian, but is widely known to break down when one deviates from this assumption, e.g. when the noise is heavy-tailed. Many ad hoc heuristics have been employed in practice for dealing with outliers. In a pioneering work, Schick and Mitter gave provable guarantees when the measurement noise is a known infinitesimal perturbation of a Gaussian and raised the important question of whether one can get similar guarantees for large and unknown perturbations. In this work we give a truly robust filter: we give the first strong provable guarantees for linear quadratic estimation when even a constant fraction of measurements have been adversarially corrupted. This framework can model heavy-tailed and even non-stationary noise processes. Our algorithm robustifies the Kalman filter in the sense that it competes with the optimal algorithm that knows the locations of the corruptions. Our work is in a challenging Bayesian setting where the number of measurements scales with the complexity of what we need to estimate. Moreover, in linear dynamical systems past information decays over time. We develop a suite of new techniques to robustly extract information across different time steps and over varying time scales.
Socioeconomic disparities and COVID-19: the causal connections
Jan 18, 2022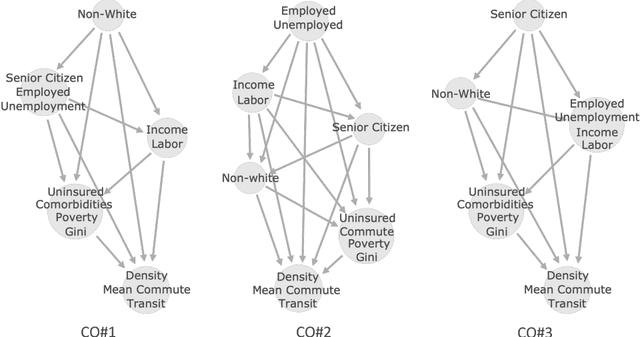
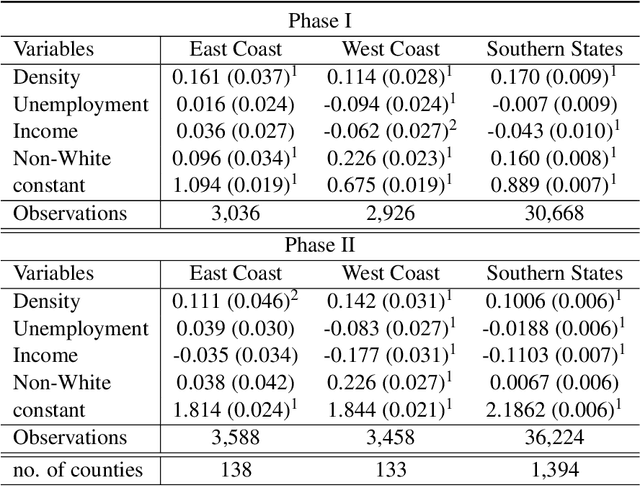
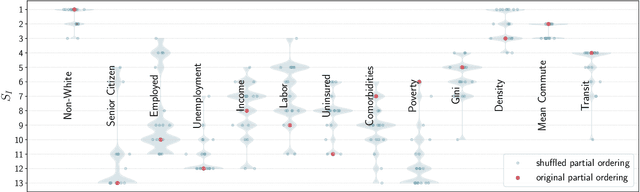
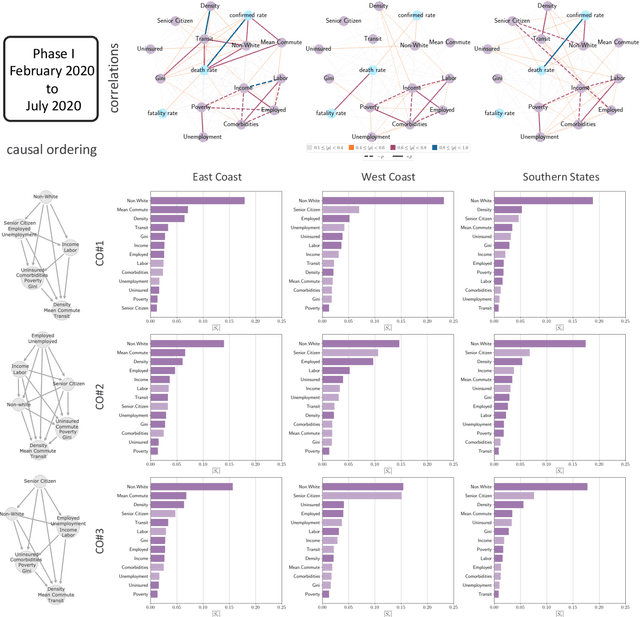
The analysis of causation is a challenging task that can be approached in various ways. With the increasing use of machine learning based models in computational socioeconomics, explaining these models while taking causal connections into account is a necessity. In this work, we advocate the use of an explanatory framework from cooperative game theory augmented with $do$ calculus, namely causal Shapley values. Using causal Shapley values, we analyze socioeconomic disparities that have a causal link to the spread of COVID-19 in the USA. We study several phases of the disease spread to show how the causal connections change over time. We perform a causal analysis using random effects models and discuss the correspondence between the two methods to verify our results. We show the distinct advantages a non-linear machine learning models have over linear models when performing a multivariate analysis, especially since the machine learning models can map out non-linear correlations in the data. In addition, the causal Shapley values allow for including the causal structure in the variable importance computed for the machine learning model.
ISNet: Costless and Implicit Image Segmentation for Deep Classifiers, with Application in COVID-19 Detection
Feb 01, 2022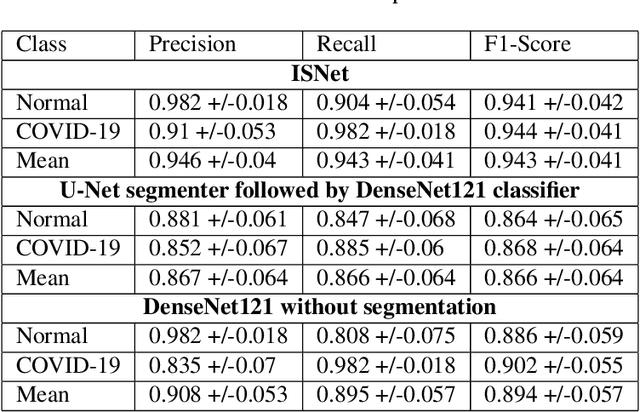

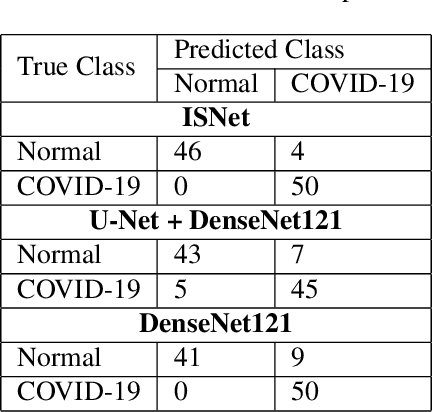

In this work we propose a novel deep neural network (DNN) architecture, ISNet, to solve the task of image segmentation followed by classification, substituting the common pipeline of two networks by a single model. We designed the ISNet for high flexibility and performance: it allows virtually any classification neural network architecture to analyze a common image as if it had been previously segmented. Furthermore, in relation to the original classifier, the ISNet does not cause any increment in computational cost or architectural changes at run-time. To accomplish this, we introduce the concept of optimizing DNNs for relevance segmentation in heatmaps created by Layer-wise Relevance Propagation (LRP), which proves to be equivalent to the classification of previously segmented images. We apply an ISNet based on a DenseNet121 classifier to solve the task of COVID-19 detection in chest X-rays. We compare the model to a U-net (performing lung segmentation) followed by a DenseNet121, and to a standalone DenseNet121. Due to the implicit segmentation, the ISNet precisely ignored the X-ray regions outside of the lungs; it achieved 94.5 +/-4.1% mean accuracy with an external database, showing strong generalization capability and surpassing the other models' performances by 6 to 7.9%. ISNet presents a fast and light methodology to perform classification preceded by segmentation, while also being more accurate than standard pipelines.
Multi-Task Network Pruning and Embedded Optimization for Real-time Deployment in ADAS
Jan 19, 2021
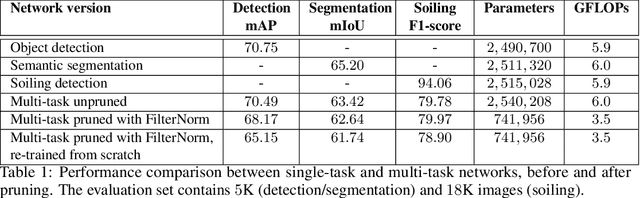
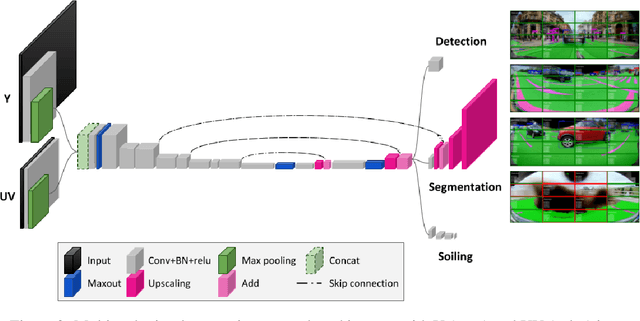
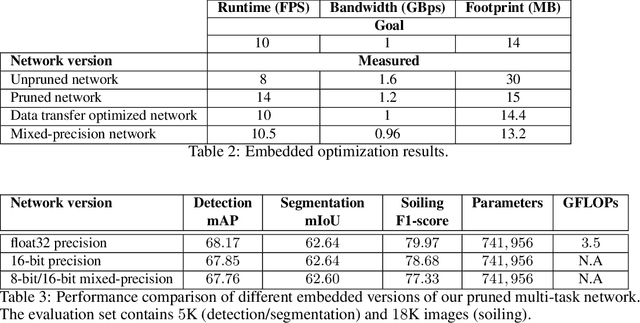
Camera-based Deep Learning algorithms are increasingly needed for perception in Automated Driving systems. However, constraints from the automotive industry challenge the deployment of CNNs by imposing embedded systems with limited computational resources. In this paper, we propose an approach to embed a multi-task CNN network under such conditions on a commercial prototype platform, i.e. a low power System on Chip (SoC) processing four surround-view fisheye cameras at 10 FPS. The first focus is on designing an efficient and compact multi-task network architecture. Secondly, a pruning method is applied to compress the CNN, helping to reduce the runtime and memory usage by a factor of 2 without lowering the performances significantly. Finally, several embedded optimization techniques such as mixed-quantization format usage and efficient data transfers between different memory areas are proposed to ensure real-time execution and avoid bandwidth bottlenecks. The approach is evaluated on the hardware platform, considering embedded detection performances, runtime and memory bandwidth. Unlike most works from the literature that focus on classification task, we aim here to study the effect of pruning and quantization on a compact multi-task network with object detection, semantic segmentation and soiling detection tasks.