 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Constraint-based graph network simulator
Dec 16, 2021


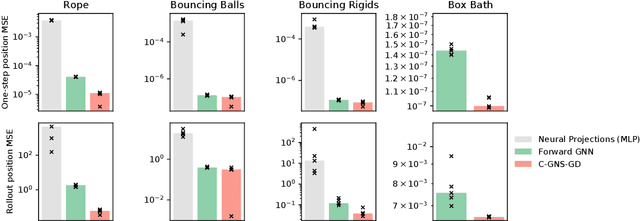
In the rapidly advancing area of learned physical simulators, nearly all methods train forward models that directly predict future states from input states. However, many traditional simulation engines use a constraint-based approach instead of direct prediction. Here we present a framework for constraint-based learned simulation, where a scalar constraint function is implemented as a neural network, and future predictions are computed as the solutions to optimization problems under these learned constraints. We implement our method using a graph neural network as the constraint function and gradient descent as the constraint solver. The architecture can be trained by standard backpropagation. We test the model on a variety of challenging physical domains, including simulated ropes, bouncing balls, colliding irregular shapes and splashing fluids. Our model achieves better or comparable performance to top learned simulators. A key advantage of our model is the ability to generalize to more solver iterations at test time to improve the simulation accuracy. We also show how hand-designed constraints can be added at test time to satisfy objectives which were not present in the training data, which is not possible with forward approaches. Our constraint-based framework is applicable to any setting where forward learned simulators are used, and demonstrates how learned simulators can leverage additional inductive biases as well as the techniques from the field of numerical methods.
Inferential Theory for Granular Instrumental Variables in High Dimensions
Jan 17, 2022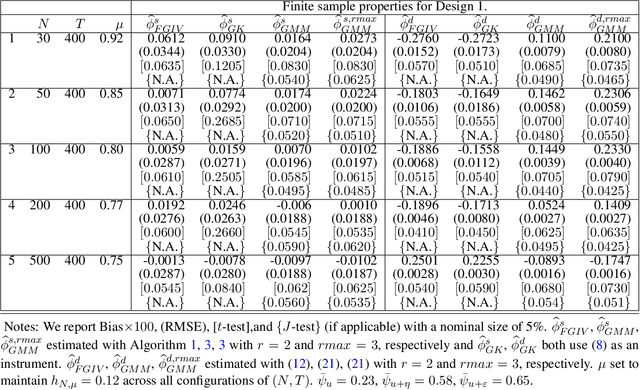
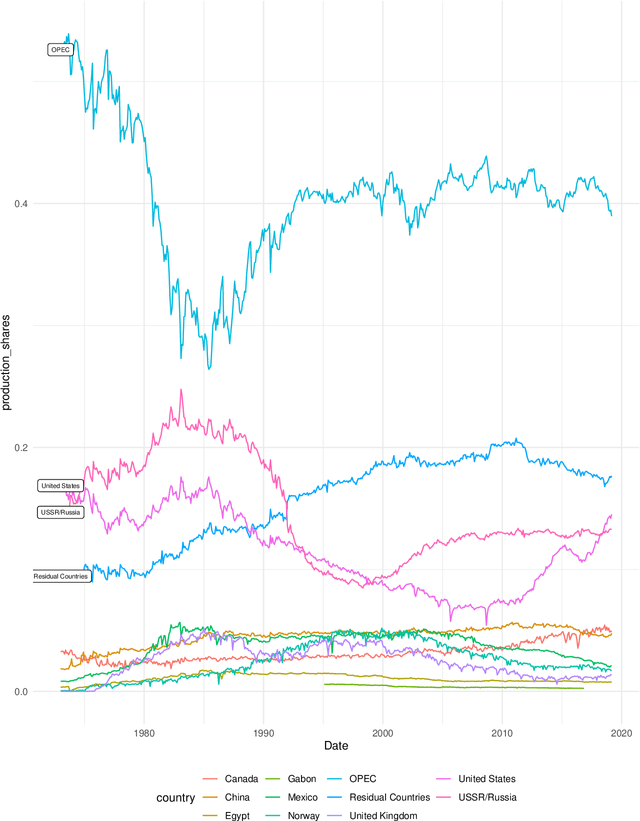
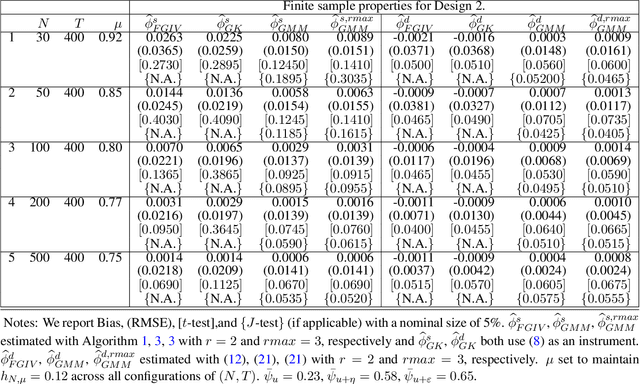
The Granular Instrumental Variables (GIV) methodology exploits panels with factor error structures to construct instruments to estimate structural time series models with endogeneity even after controlling for latent factors. We extend the GIV methodology in several dimensions. First, we extend the identification procedure to a large $N$ and large $T$ framework, which depends on the asymptotic Herfindahl index of the size distribution of $N$ cross-sectional units. Second, we treat both the factors and loadings as unknown and show that the sampling error in the estimated instrument and factors is negligible when considering the limiting distribution of the structural parameters. Third, we show that the sampling error in the high-dimensional precision matrix is negligible in our estimation algorithm. Fourth, we overidentify the structural parameters with additional constructed instruments, which leads to efficiency gains. Monte Carlo evidence is presented to support our asymptotic theory and application to the global crude oil market leads to new results.
Bayesian Learning via Neural Schrödinger-Föllmer Flows
Dec 07, 2021
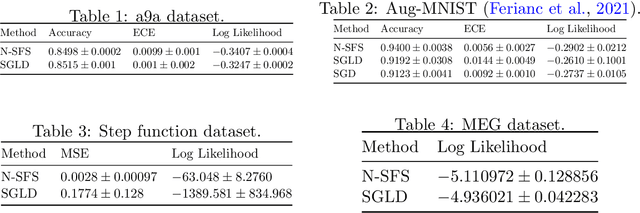
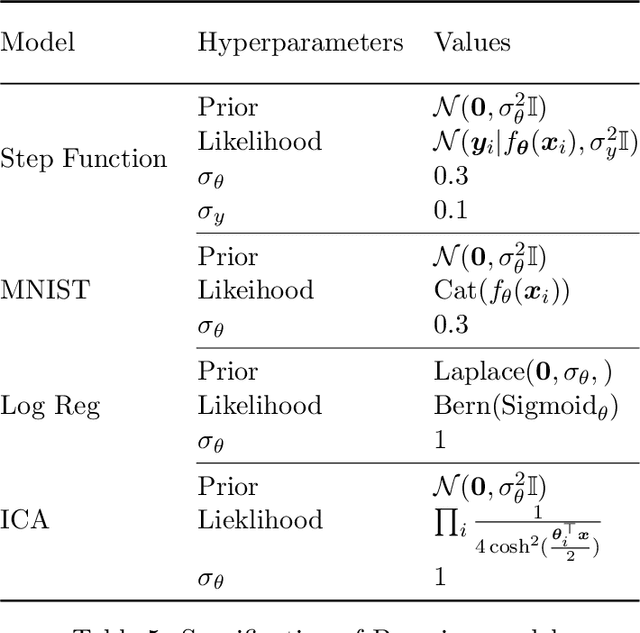
In this work we explore a new framework for approximate Bayesian inference in large datasets based on stochastic control. We advocate stochastic control as a finite time and low variance alternative to popular steady-state methods such as stochastic gradient Langevin dynamics (SGLD). Furthermore, we discuss and adapt the existing theoretical guarantees of this framework and establish connections to already existing VI routines in SDE-based models.
Dynamic Time Warp Convolutional Networks
Nov 05, 2019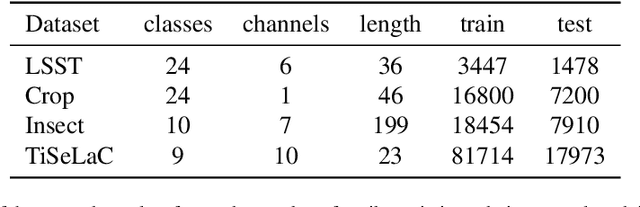
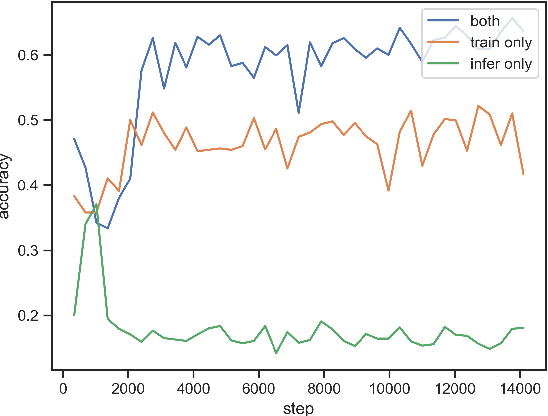
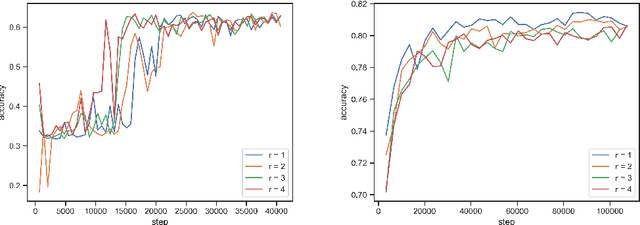
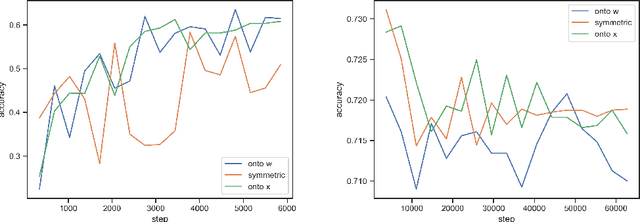
Where dealing with temporal sequences it is fair to assume that the same kind of deformations that motivated the development of the Dynamic Time Warp algorithm could be relevant also in the calculation of the dot product ("convolution") in a 1-D convolution layer. In this work a method is proposed for aligning the convolution filter and the input where they are locally out of phase utilising an algorithm similar to the Dynamic Time Warp. The proposed method enables embedding a non-parametric warping of temporal sequences for increasing similarity directly in deep networks and can expand on the generalisation capabilities and the capacity of standard 1-D convolution layer where local sequential deformations are present in the input. Experimental results demonstrate the proposed method exceeds or matches the standard 1-D convolution layer in terms of the maximum accuracy achieved on a number of time series classification tasks. In addition the impact of different hyperparameters settings is investigated given different datasets and the results support the conclusions of previous work done in relation to the choice of DTW parameter values. The proposed layer can be freely integrated with other typical layers to compose deep artificial neural networks of an arbitrary architecture that are trained using standard stochastic gradient descent.
Generation of Synthetic Rat Brain MRI scans with a 3D Enhanced Alpha-GAN
Jan 01, 2022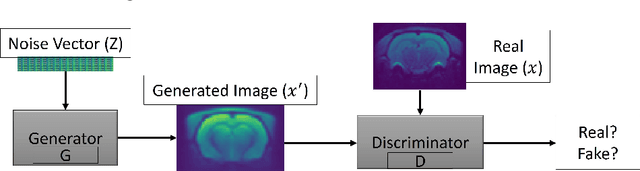
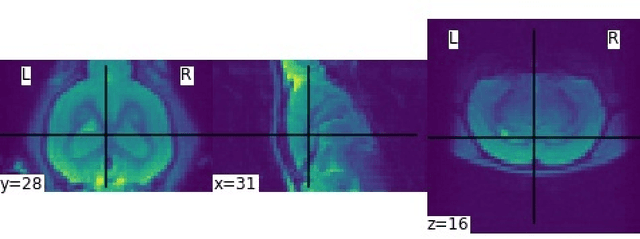
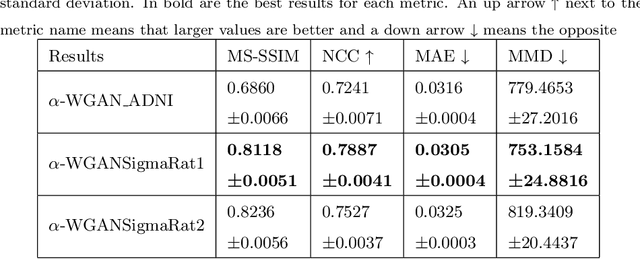
Translational brain research using Magnetic Resonance Imaging (MRI) is becoming increasingly popular as animal models are an essential part of scientific studies and more ultra-high-field scanners are becoming available. Some disadvantages of MRI are the availability of MRI scanners and the time required for a full scanning session (it usually takes over 30 minutes). Privacy laws and the 3Rs ethics rule also make it difficult to create large datasets for training deep learning models. Generative Adversarial Networks (GANs) can perform data augmentation with higher quality than other techniques. In this work, the alpha-GAN architecture is used to test its ability to produce realistic 3D MRI scans of the rat brain. As far as the authors are aware, this is the first time that a GAN-based approach has been used for data augmentation in preclinical data. The generated scans are evaluated using various qualitative and quantitative metrics. A Turing test conducted by 4 experts has shown that the generated scans can trick almost any expert. The generated scans were also used to evaluate their impact on the performance of an existing deep learning model developed for segmenting the rat brain into white matter, grey matter and cerebrospinal fluid. The models were compared using the Dice score. The best results for whole brain and white matter segmentation were obtained when 174 real scans and 348 synthetic scans were used, with improvements of 0.0172 and 0.0129, respectively. Using 174 real scans and 87 synthetic scans resulted in improvements of 0.0038 and 0.0764 for grey matter and CSF segmentation, respectively. Thus, by using the proposed new normalisation layer and loss functions, it was possible to improve the realism of the generated rat MRI scans and it was shown that using the generated data improved the segmentation model more than using the conventional data augmentation.
Logarithmic Continual Learning
Jan 17, 2022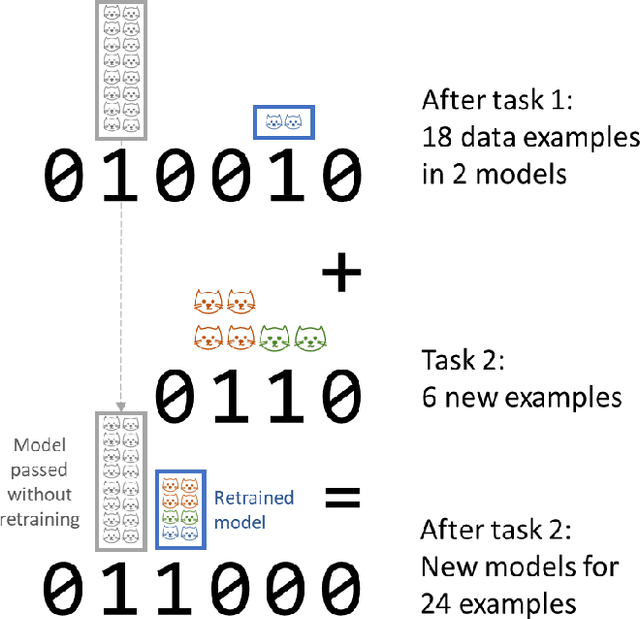
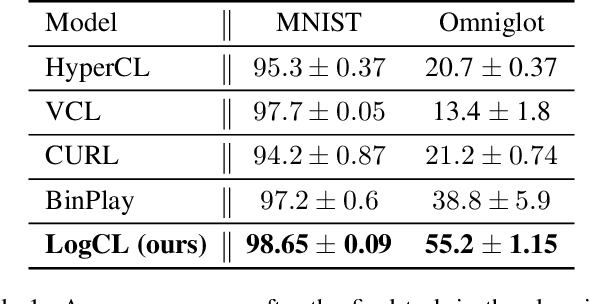
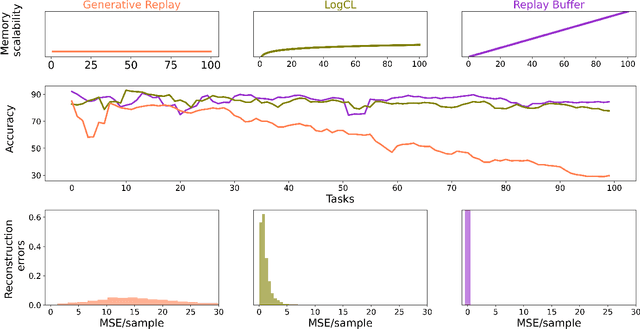
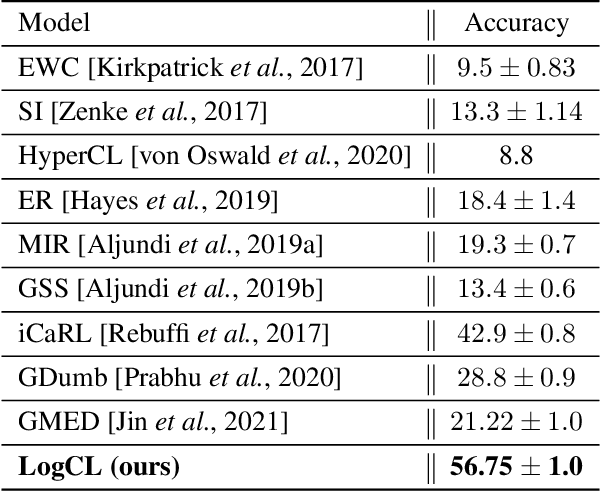
We introduce a neural network architecture that logarithmically reduces the number of self-rehearsal steps in the generative rehearsal of continually learned models. In continual learning (CL), training samples come in subsequent tasks, and the trained model can access only a single task at a time. To replay previous samples, contemporary CL methods bootstrap generative models and train them recursively with a combination of current and regenerated past data. This recurrence leads to superfluous computations as the same past samples are regenerated after each task, and the reconstruction quality successively degrades. In this work, we address these limitations and propose a new generative rehearsal architecture that requires at most logarithmic number of retraining for each sample. Our approach leverages allocation of past data in a~set of generative models such that most of them do not require retraining after a~task. The experimental evaluation of our logarithmic continual learning approach shows the superiority of our method with respect to the state-of-the-art generative rehearsal methods.
Leveraging Experience in Lifelong Multi-Agent Pathfinding
Feb 09, 2022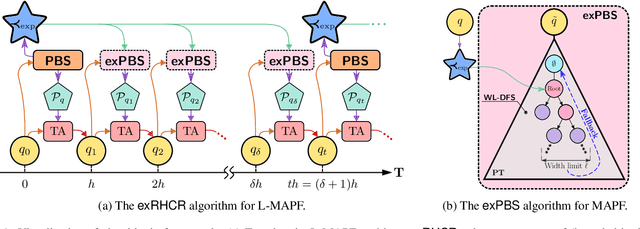
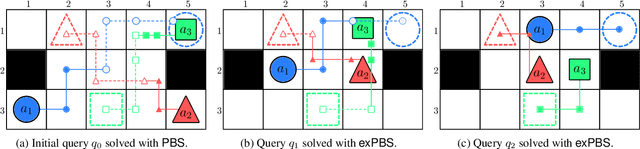
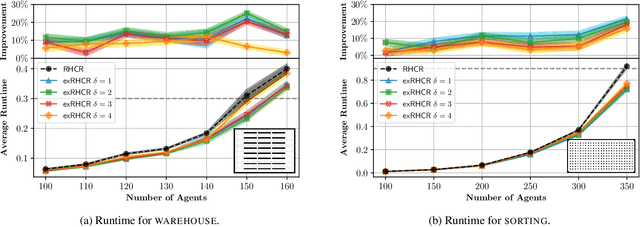
In Lifelong Multi-Agent Path Finding (L-MAPF) a team of agents performs a stream of tasks consisting of multiple locations to be visited by the agents on a shared graph while avoiding collisions with one another. L-MAPF is typically tackled by partitioning it into multiple consecutive, and hence similar, "one-shot" MAPF queries with a single task assigned to each agent, as in the Rolling-Horizon Collision Resolution (RHCR) algorithm. Thus, a solution to one query informs the next query, which leads to similarity with respect to the agents' start and goal positions, and how collisions need to be resolved from one query to the next. Thus, experience from solving one MAPF query can potentially be used to speedup solving the next one. Despite this intuition, current L-MAPF planners solve consecutive MAPF queries from scratch. In this paper, we introduce a new RHCR-inspired approach called exRHCR, which exploits experience in its constituent MAPF queries. In particular, exRHCR employs a new extension of Priority-Based Search (PBS), a state-of-the-art MAPF solver. Our extension, called exPBS, allows to warm-start the search with the priorities between agents used by PBS in the previous MAPF instances. We demonstrate empirically that exRHCR solves L-MAPF up to 25% faster than RHCR, and allows to increase throughput for given task streams by as much as 3%-16% by increasing the number of agents we can cope with for a given time budget.
Multimodal perception for dexterous manipulation
Dec 28, 2021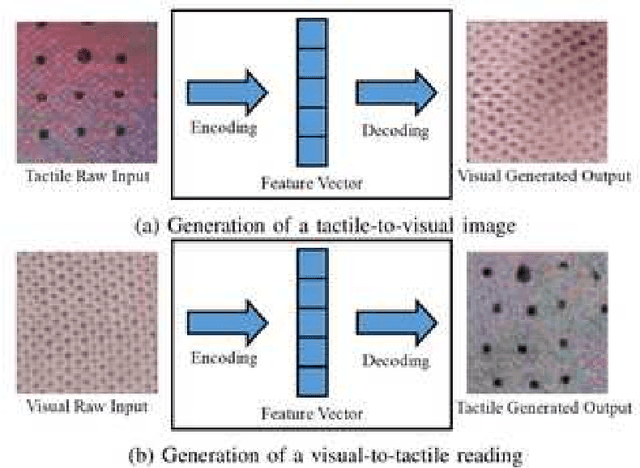
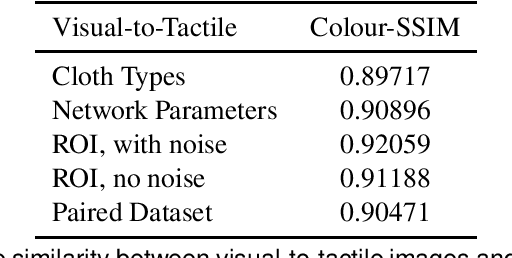
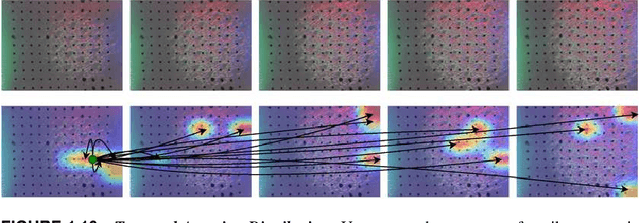
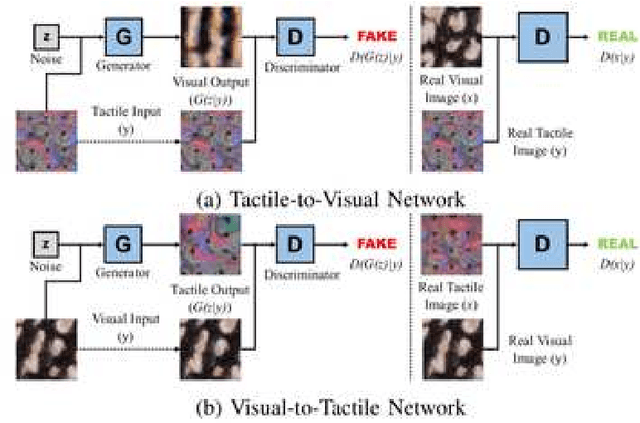
Humans usually perceive the world in a multimodal way that vision, touch, sound are utilised to understand surroundings from various dimensions. These senses are combined together to achieve a synergistic effect where the learning is more effectively than using each sense separately. For robotics, vision and touch are two key senses for the dexterous manipulation. Vision usually gives us apparent features like shape, color, and the touch provides local information such as friction, texture, etc. Due to the complementary properties between visual and tactile senses, it is desirable for us to combine vision and touch for a synergistic perception and manipulation. Many researches have been investigated about multimodal perception such as cross-modal learning, 3D reconstruction, multimodal translation with vision and touch. Specifically, we propose a cross-modal sensory data generation framework for the translation between vision and touch, which is able to generate realistic pseudo data. By using this cross-modal translation method, it is desirable for us to make up inaccessible data, helping us to learn the object's properties from different views. Recently, the attention mechanism becomes a popular method either in visual perception or in tactile perception. We propose a spatio-temporal attention model for tactile texture recognition, which takes both spatial features and time dimension into consideration. Our proposed method not only pays attention to the salient features in each spatial feature, but also models the temporal correlation in the through the time. The obvious improvement proves the efficiency of our selective attention mechanism. The spatio-temporal attention method has potential in many applications such as grasping, recognition, and multimodal perception.
End-to-End Multi-Task Deep Learning and Model Based Control Algorithm for Autonomous Driving
Dec 16, 2021
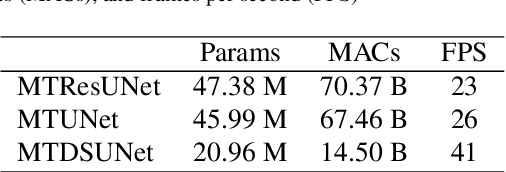


End-to-end driving with a deep learning neural network (DNN) has become a rapidly growing paradigm of autonomous driving in industry and academia. Yet safety measures and interpretability still pose challenges to this paradigm. We propose an end-to-end driving algorithm that integrates multi-task DNN, path prediction, and control models in a pipeline of data flow from sensory devices through these models to driving decisions. It provides quantitative measures to evaluate the holistic, dynamic, and real-time performance of end-to-end driving systems, and thus allows to quantify their safety and interpretability. The DNN is a modified UNet, a well known encoder-decoder neural network of semantic segmentation. It consists of one segmentation, one regression, and two classification tasks for lane segmentation, path prediction, and vehicle controls. We present three variants of the modified UNet architecture having different complexities, compare them on different tasks in four static measures for both single and multi-task (MT) architectures, and then identify the best one by two additional dynamic measures in real-time simulation. We also propose a learning- and model-based longitudinal controller using model predictive control method. With the Stanley lateral controller, our results show that MTUNet outperforms an earlier modified UNet in terms of curvature and lateral offset estimation on curvy roads at normal speed, which has been tested in a real car driving on real roads.
Consolidated learning -- a domain-specific model-free optimization strategy with examples for XGBoost and MIMIC-IV
Jan 27, 2022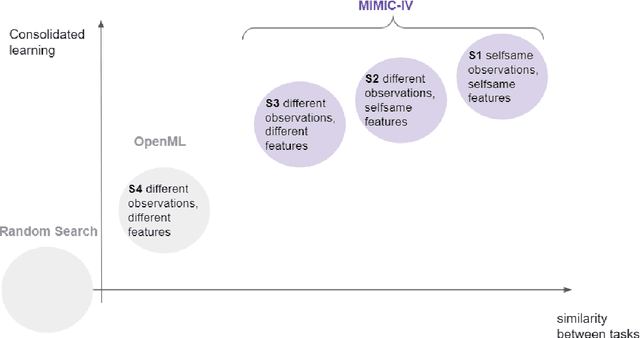
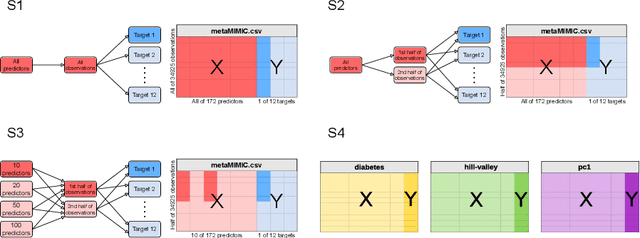
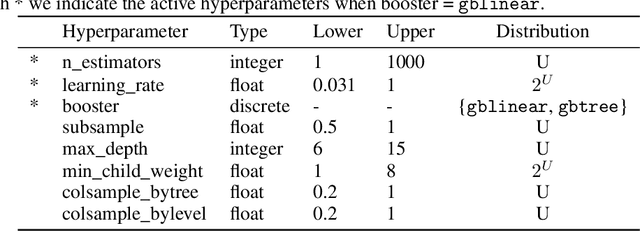
For many machine learning models, a choice of hyperparameters is a crucial step towards achieving high performance. Prevalent meta-learning approaches focus on obtaining good hyperparameters configurations with a limited computational budget for a completely new task based on the results obtained from the prior tasks. This paper proposes a new formulation of the tuning problem, called consolidated learning, more suited to practical challenges faced by model developers, in which a large number of predictive models are created on similar data sets. In such settings, we are interested in the total optimization time rather than tuning for a single task. We show that a carefully selected static portfolio of hyperparameters yields good results for anytime optimization, maintaining ease of use and implementation. Moreover, we point out how to construct such a portfolio for specific domains. The improvement in the optimization is possible due to more efficient transfer of hyperparameter configurations between similar tasks. We demonstrate the effectiveness of this approach through an empirical study for XGBoost algorithm and the collection of predictive tasks extracted from the MIMIC-IV medical database; however, consolidated learning is applicable in many others fields.